
Track
Professional Data Engineer in Python
40 hr
Data workflows and pipelines often require precise coordination to guarantee tasks are executed in the correct order. The Directed Acyclic Graph (DAG) is a powerful tool for managing these workflows efficiently and avoiding errors.
In this article, we’ll explore DAGs and their importance in data engineering, review some of their applications, and understand how to use them using a hands-on example using Airflow.
To understand what a DAG is, let’s first define some key concepts. In computer science, a graph is a non-linear data structure that consists of nodes and edges. Nodes represent individual entities or objects, while edges connect these nodes and represent relationships or connections between them.
In a directed graph, those edges have a specific direction, indicating a one-way relationship between nodes. This means that if there's an edge from node A to node B, it implies a connection from A to B, but not necessarily from B to A.
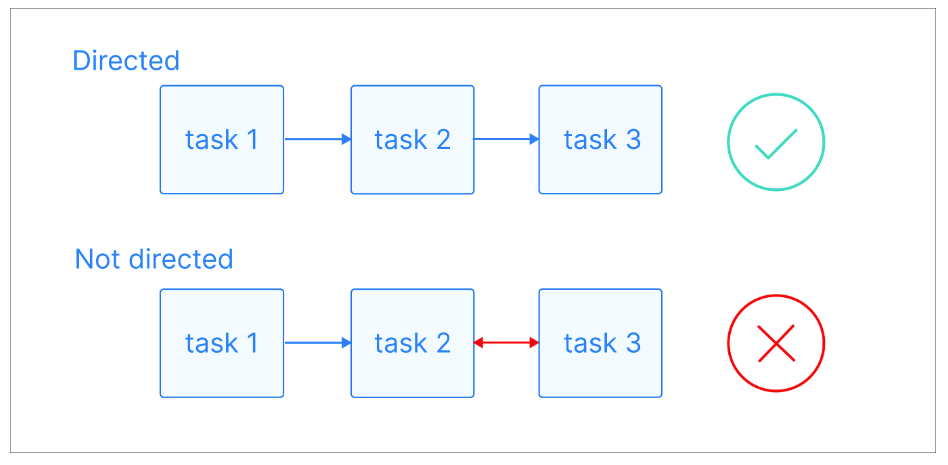
Directed graphs visual explanation. Image source: Astronomer
A path is a sequence of nodes connected by directed edges. It starts at a specific node and follows the direction of the edges to reach another node. A path can be of any length, from a single node to a sequence of many nodes, as long as the direction of the edges is followed consistently.
Now that we have some basic definitions, let's see what a DAG is: A DAG is a directed graph with no directed cycles, where each node represents a specific task, and each edge indicates the dependency between them.
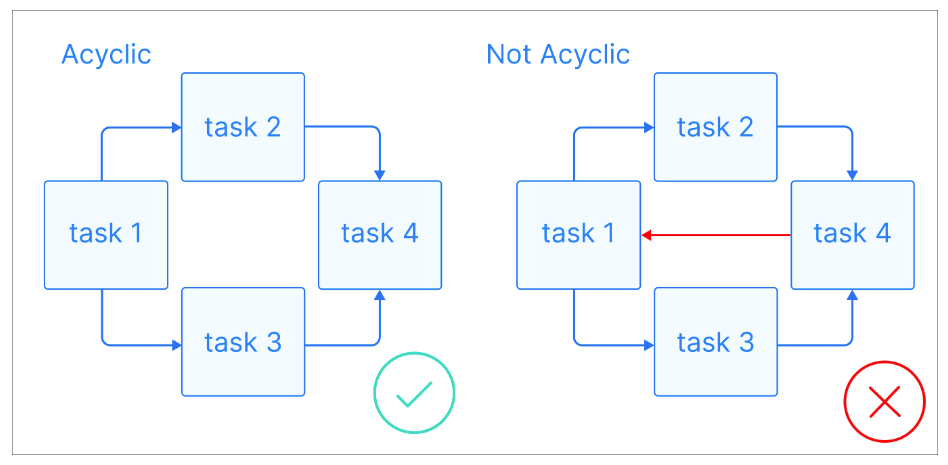 Acyclic graphs visual explanation. Image source: Astronomer
Acyclic graphs visual explanation. Image source: Astronomer
The key thing about DAGs is that they're acyclic, meaning that once you start at one node, you can only move forward, never returning to a previous node. This ensures tasks can be executed in order without leading to infinite loops. DAGs often have a hierarchical structure, where tasks are organized into levels or layers. Tasks at a higher level typically depend on completing tasks at lower levels.
As a data engineer or someone performing data engineering tasks, you are often faced with the challenge of building complex data pipelines that require executing steps, each one depending on the previous. That's where DAGs come in!
Because they can represent tasks as nodes and dependencies as edges, DAGs enforce a logical execution order, ensuring that tasks are executed sequentially based on their dependencies. This prevents errors and inconsistencies from running tasks out of order. Also, if one step fails, DAGs can identify and re-run the affected tasks, saving time and effort.
If you’re new to building data pipelines or want to strengthen your foundations, the Understanding Data Engineering course provides an excellent starting point.
The acyclic nature of DAGs is one of the key characteristics that makes them ideal for data pipelines. They ensure that tasks can be executed without infinite loops or recursive dependencies that can result in system instability.
Let's consider a simple example of a data pipeline:
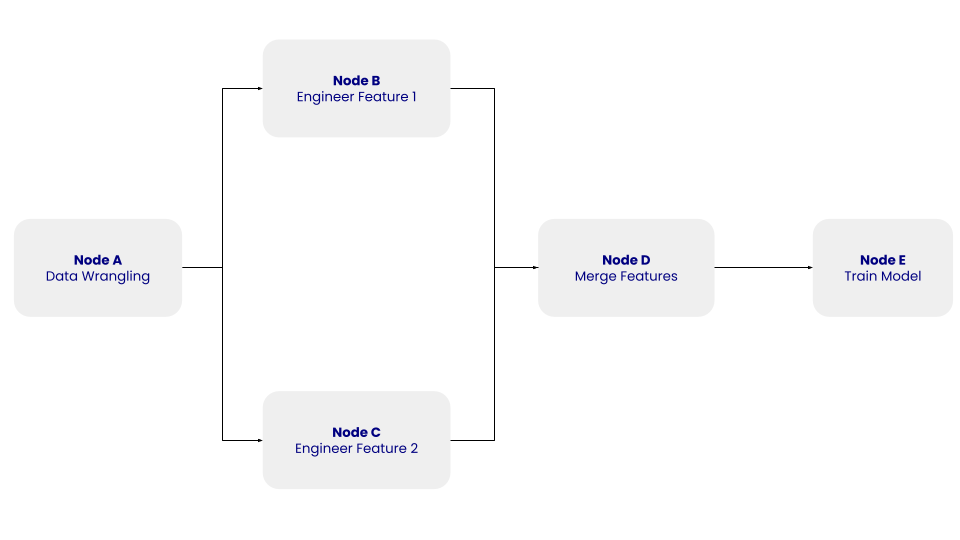 The structure of this simple DAG with nodes A, B, C, D, and E and their dependencies. Image by Author.
The structure of this simple DAG with nodes A, B, C, D, and E and their dependencies. Image by Author.
In the DAG above, node A represents the data wrangling step, which involves the data cleaning step, where the extracted data is cleaned and preprocessed. Node B and C represent the feature engineering steps, where the cleaned data is transformed independently into two features. Node D involves merging the features. Lastly, Node E represents the model training step, where a machine learning model is trained on the transformed data.
The DAG doesn’t care about what happens inside the tasks but the order in which they should be executed.
Moreover, DAGs enable you to create automated, scalable data workflows, especially in distributed systems and cloud environments. They break down complex data processing tasks into smaller, independent, manageable subtasks, which allow DAGs to perform parallel execution and efficient resource utilization. This scalability is particularly important when dealing with large datasets and complex data pipelines, as it enables cost-effective data processing.
Lastly, DAGs can provide a visual representation of any data pipeline, which helps you understand and communicate the workflow. This visual clarity is important when collaborating with other team members or non-technical stakeholders. If you can understand the flow of data and the dependencies between tasks, it is easier to identify and fix issues, optimize resource utilization, and make informed decisions about pipeline improvements.
The course on ETL and ELT in Python is a great resource for hands-on practice with creating and optimizing data pipelines.
DAGs have been widely adopted and have different applications in data engineering. We talked about some of them in the previous section. Now, let’s explore some of them in more detail.
One of the most common applications of DAGs is orchestrating Extract, Transform, and Load (ETL) processes. ETL pipelines involve extracting data from various sources, transforming it into a suitable format, and loading it into a target system.
For example, tools like Apache Airflow and Luigi use DAGs to orchestrate ETL pipelines efficiently. A practical use case might involve integrating data from a CRM system, transforming it to align with your business needs, and loading it into a Snowflake data warehouse for analytics.
You can also leverage DAGs to monitor and log task runtimes in your ETL processes. This can help identify bottlenecks or tasks that require optimization.
DAGs are also great for managing complex data workflows that involve multiple tasks and dependencies. For example, a machine learning workflow might include tasks like feature engineering, model training, and model deployment.
For instance, a DAG in Apache Airflow might execute feature selection scripts and trigger model training only after the features are processed, ensuring dependency management and reproducibility.
DAGs are widely used in data processing pipelines to manage data flow from multiple sources and transform it into valuable insights. For example, a DAG in Apache Spark might process clickstream data from a website, perform aggregation to calculate session durations and feed the insights into a dashboard.
DAGs in Spark are not explicitly defined by users but are created internally by the framework to optimize the execution of transformations.
In machine learning, DAGs help with workflows' iterative and modular nature. They allow you to experiment with different preprocessing steps, algorithms, and hyperparameters while keeping the pipeline organized.
Tools like Kubeflow Pipelines and MLflow use DAGs to manage machine learning workflows, allowing for seamless experimentation and deployment. For example, you can use DAGs to enable retraining pipelines triggered by data drift detection, ensuring your models remain accurate and relevant over time.
You have various tools that help you manage and orchestrate DAGs effectively. Let's explore some of the most popular options:
Apache Airflow is a widely used platform for creating, scheduling, and monitoring workflows. It excels at defining complex data pipelines as DAGs. Airflow provides a user-friendly interface for visualizing and managing these DAGs, making it easy to understand and troubleshoot data workflows. Its flexibility and scalability have made it a go-to choice for many data engineering teams.
Prefect is a modern orchestration tool that simplifies the creation and management of data workflows. It offers a Python-based API for defining DAGs, making integrating with existing Python code easy. Prefect prioritizes reliability and observability, providing features like automatic retries, backfills, and robust monitoring.
Dask is a parallel computing library for Python that manages distributed data workflows. It can parallelize computations across multiple cores or machines, making it ideal for large-scale data processing tasks. Dask uses a DAG-based execution model to schedule and coordinate tasks, ensuring efficient resource utilization.
Kubeflow Pipelines is an open-source platform for building and deploying scalable machine learning workflows. It uses DAGs to define end-to-end workflows, from data preprocessing to model deployment. Its tight integration with Kubernetes makes it a strong choice for running workflows in cloud environments. Kubeflow also provides a visual interface for managing and monitoring workflows, offering transparency and control.
Dagster is an orchestration platform designed for modern data workflows. It emphasizes modularity and type safety, making testing and maintaining DAGs easier. Dagster integrates with popular tools like Apache Spark, Snowflake, and dbt, making it an excellent choice for data engineering teams with diverse technologies.
Before creating a DAG, you need to set up Apache Airflow. You can install it using Docker or a package manager like pip:
pip install apache-airflowOnce installed, you'll need to configure the Airflow web server and scheduler. This involves setting up and initializing database connections and starting the web server:
airflow db init
airflow webserver --port 8080With Airflow set up, you can create your DAG. You can use Python to define the DAG and its tasks as follows:
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG(
'simple_dag',
start_date=datetime(2023, 1, 1),
schedule_interval=None,
catchup=False
) as dag:
task1 = BashOperator(
task_id='task_1',
bash_command='echo "Hello, World!"'
)
task2 = BashOperator(
task_id='task_2',
bash_command='echo "This is task 2"'
)
task1 >> task2In this example, the simple DAG contains two tasks: task_1 and task_2. The >> operator sets a dependency between the tasks, ensuring that task_2 only executes after task_1 is complete.
Once your DAG is defined and deployed to Airflow, you can interact with it through the web interface.
DAGs will run in one of two ways:
schedule argument is very common.Every time you run a DAG, a new instance of that DAG, called DAG run, is created. DAG Runs can run in parallel for the same DAG, and each has a defined data interval, which identifies the period of data the tasks should operate on.
After triggering, you can monitor its progress in the DAG view, which visually represents the workflow.
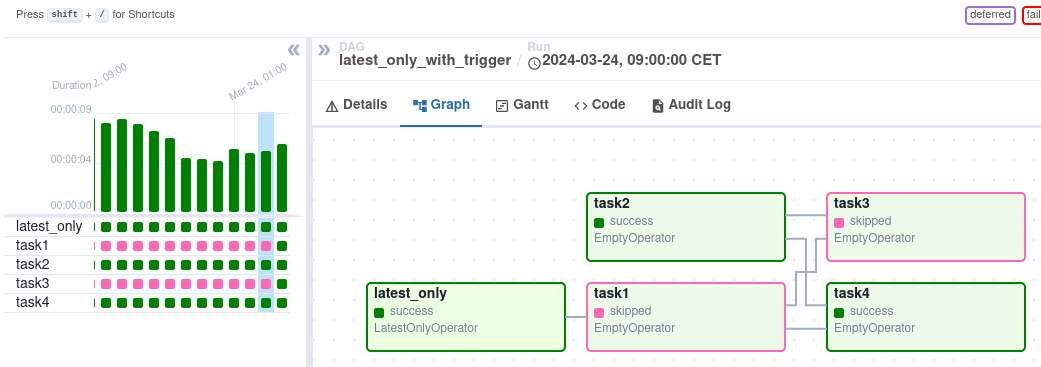 DAG view on Airflow interface. Image source: Airflow
DAG view on Airflow interface. Image source: Airflow
The Graph View offers a detailed look at a specific DAG run, showing task dependencies and execution times. The Task Instances view provides granular information about individual tasks, including their status, start and end times, and logs. You can examine task logs to troubleshoot errors and understand the root cause of failures. The Task Instances view also shows task duration, helping you identify potential performance issues.
DAGs are a fundamental concept in data engineering, providing a visual and structured way to represent complex workflows. Understanding nodes, edges, and dependencies helps you efficiently design and manage data pipelines.
DAGs are widely used to orchestrate ETL processes, manage data processing pipelines, and automate machine learning workflows. You can leverage tools like Apache Airflow, Prefect, and Dask to create and manage DAGs effectively. These tools provide user-friendly interfaces, scheduling capabilities, and advanced monitoring, error handling, and scaling features.
To get hands-on experience, this introductory course on Airflow in Python can help you learn to create and manage DAGs effectively. For a broader understanding of data engineering concepts and workflows, this course on understanding data engineering provides an excellent foundation!
Learn more about data engineering with these courses!
Track
Course
Course
blog
Tim Lu
12 min
blog
Jake Roach
9 min
blog
Kurtis Pykes
11 min
blog
Mike Shakhomirov
11 min
Tutorial
Jake Roach
Tutorial
Kurtis Pykes
