
Tracks
Kỹ sư dữ liệu chuyên nghiệp trong Python
40 giờ
Các quy trình và pipeline dữ liệu thường cần được phối hợp chính xác để đảm bảo tác vụ được thực thi theo đúng thứ tự. Directed Acyclic Graph (DAG) là một công cụ mạnh mẽ để quản lý hiệu quả các quy trình này và tránh lỗi.
Trong bài viết này, chúng ta sẽ khám phá DAG và tầm quan trọng của nó trong kỹ thuật dữ liệu, điểm qua một số ứng dụng, và tìm hiểu cách sử dụng chúng qua ví dụ thực hành với Airflow.
Để hiểu DAG là gì, trước hết hãy định nghĩa một số khái niệm then chốt. Trong khoa học máy tính, đồ thị (graph) là một cấu trúc dữ liệu phi tuyến gồm nút (node) và cạnh (edge). Nút biểu diễn các thực thể hay đối tượng riêng lẻ, còn cạnh kết nối các nút và biểu diễn mối quan hệ hay liên kết giữa chúng.
Trong đồ thị có hướng, các cạnh có hướng cụ thể, thể hiện mối quan hệ một chiều giữa các nút. Nghĩa là nếu có một cạnh từ nút A tới nút B, điều đó ngụ ý kết nối từ A tới B, nhưng không nhất thiết từ B trở lại A.
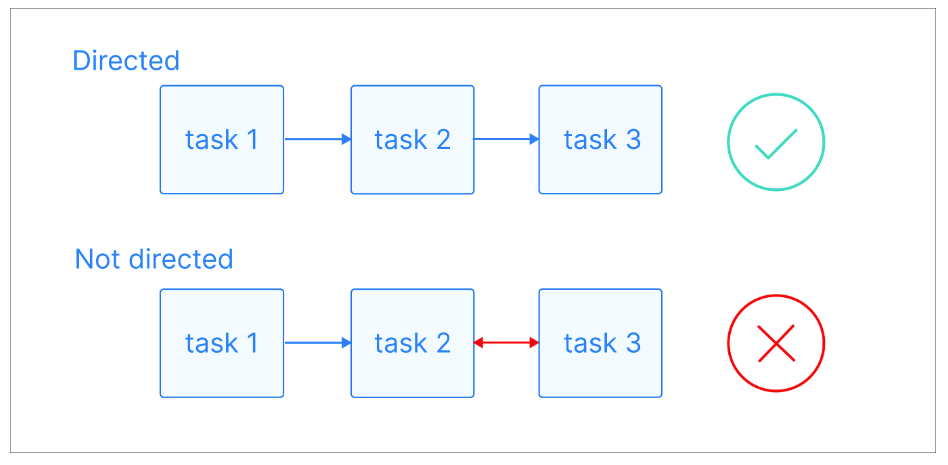
Giải thích trực quan về đồ thị có hướng. Nguồn ảnh: Astronomer
Một đường đi (path) là một chuỗi các nút được nối với nhau bởi các cạnh có hướng. Nó bắt đầu tại một nút cụ thể và theo hướng các cạnh để đi tới nút khác. Đường đi có thể có độ dài bất kỳ, từ một nút đơn đến một chuỗi nhiều nút, miễn là luôn tuân theo hướng của các cạnh.
Giờ ta đã có một số định nghĩa cơ bản, hãy xem DAG là gì: DAG là một đồ thị có hướng không chứa chu trình, trong đó mỗi nút biểu diễn một tác vụ cụ thể và mỗi cạnh cho biết sự phụ thuộc giữa các tác vụ.
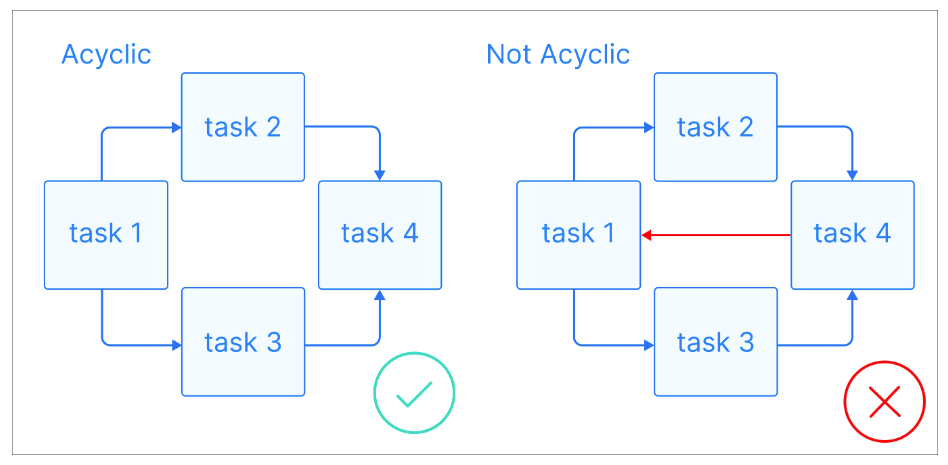 Giải thích trực quan về đồ thị vô chu trình. Nguồn ảnh: Astronomer
Giải thích trực quan về đồ thị vô chu trình. Nguồn ảnh: Astronomer
Điểm mấu chốt của DAG là tính vô chu trình, nghĩa là khi bạn bắt đầu tại một nút, bạn chỉ có thể đi tiếp về phía trước và không quay lại nút trước đó. Điều này đảm bảo các tác vụ được thực thi theo thứ tự mà không dẫn tới vòng lặp vô hạn. DAG thường có cấu trúc phân cấp, nơi các tác vụ được tổ chức theo tầng hoặc lớp. Các tác vụ ở tầng cao hơn thường phụ thuộc vào việc hoàn tất các tác vụ ở tầng thấp hơn.
Là một kỹ sư dữ liệu hoặc người thực hiện các tác vụ kỹ thuật dữ liệu, bạn thường đối mặt với thách thức xây dựng các pipeline dữ liệu phức tạp, nơi mỗi bước phụ thuộc vào bước trước. Đó chính là lúc DAG phát huy tác dụng!
Vì có thể biểu diễn tác vụ dưới dạng nút và quan hệ phụ thuộc dưới dạng cạnh, DAG áp đặt một thứ tự thực thi hợp lý, đảm bảo các tác vụ được chạy tuần tự dựa trên phụ thuộc của chúng. Điều này ngăn ngừa lỗi và sự không nhất quán do chạy sai thứ tự. Ngoài ra, nếu một bước thất bại, DAG có thể xác định và chạy lại các tác vụ bị ảnh hưởng, tiết kiệm thời gian và công sức.
Nếu bạn mới bắt đầu xây dựng pipeline dữ liệu hoặc muốn củng cố nền tảng, khóa học Understanding Data Engineering là điểm khởi đầu tuyệt vời.
Tính vô chu trình của DAG là một đặc điểm then chốt khiến chúng lý tưởng cho pipeline dữ liệu. Chúng đảm bảo các tác vụ được thực thi mà không có vòng lặp vô hạn hay phụ thuộc đệ quy có thể gây mất ổn định hệ thống.
Hãy xét một ví dụ đơn giản về pipeline dữ liệu:
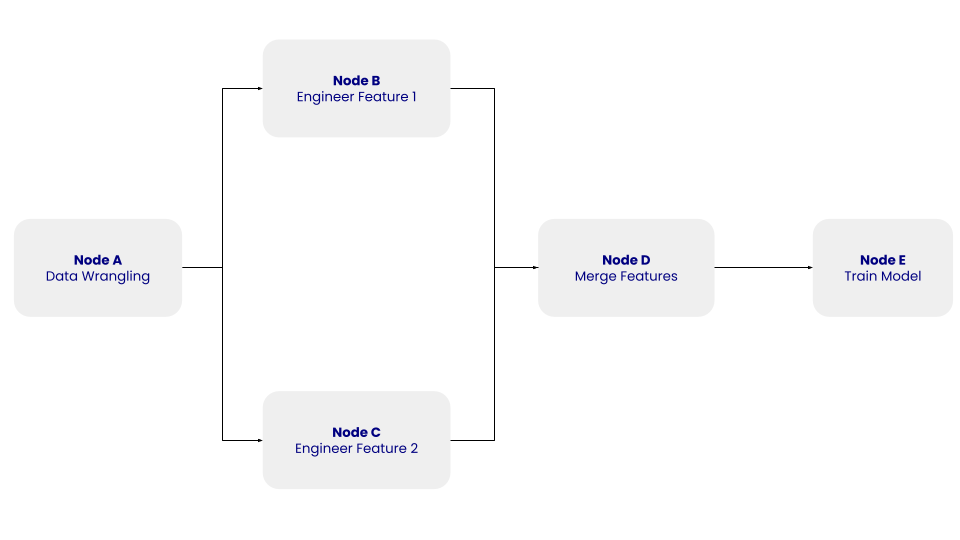 Cấu trúc của DAG đơn giản với các nút A, B, C, D, và E cùng quan hệ phụ thuộc. Ảnh: Tác giả.
Cấu trúc của DAG đơn giản với các nút A, B, C, D, và E cùng quan hệ phụ thuộc. Ảnh: Tác giả.
Trong DAG ở trên, nút A đại diện cho bước xử lý dữ liệu thô, bao gồm bước làm sạch dữ liệu, nơi dữ liệu trích xuất được làm sạch và tiền xử lý. Nút B và C đại diện cho các bước kỹ thuật đặc trưng (feature engineering), nơi dữ liệu đã làm sạch được biến đổi độc lập thành hai đặc trưng. Nút D là bước hợp nhất các đặc trưng. Cuối cùng, nút E là bước huấn luyện mô hình, nơi một mô hình học máy được huấn luyện trên dữ liệu đã biến đổi.
DAG không quan tâm tới việc bên trong tác vụ diễn ra thế nào, mà tập trung vào thứ tự chúng cần được thực thi.
Hơn nữa, DAG cho phép bạn tạo các quy trình dữ liệu tự động, có khả năng mở rộng, đặc biệt trong hệ thống phân tán và môi trường đám mây. Chúng chia nhỏ các tác vụ xử lý dữ liệu phức tạp thành các tiểu tác vụ độc lập, dễ quản lý, cho phép thực thi song song và sử dụng tài nguyên hiệu quả. Tính mở rộng này đặc biệt quan trọng khi xử lý tập dữ liệu lớn và pipeline phức tạp, vì nó giúp xử lý dữ liệu với chi phí hợp lý.
Cuối cùng, DAG có thể cung cấp biểu diễn trực quan cho bất kỳ pipeline dữ liệu nào, giúp bạn hiểu và truyền đạt quy trình. Tính rõ ràng trực quan này quan trọng khi cộng tác với các thành viên khác trong nhóm hoặc bên liên quan không chuyên môn. Khi nắm được luồng dữ liệu và quan hệ phụ thuộc giữa các tác vụ, bạn sẽ dễ dàng phát hiện và khắc phục sự cố, tối ưu hoá sử dụng tài nguyên, và đưa ra quyết định sáng suốt về cải tiến pipeline.
Khóa học ETL và ELT bằng Python là nguồn tài liệu tuyệt vời để thực hành tạo và tối ưu hoá pipeline dữ liệu.
DAG được áp dụng rộng rãi với nhiều ứng dụng khác nhau trong kỹ thuật dữ liệu. Chúng ta đã đề cập một số trong phần trước. Giờ hãy đi sâu hơn vào một vài trường hợp.
Một trong những ứng dụng phổ biến nhất của DAG là điều phối các quy trình Extract, Transform, and Load (ETL). Pipeline ETL bao gồm trích xuất dữ liệu từ nhiều nguồn, chuyển đổi về định dạng phù hợp và nạp vào hệ thống đích.
Ví dụ, các công cụ như Apache Airflow và Luigi dùng DAG để điều phối pipeline ETL hiệu quả. Một tình huống thực tế có thể là tích hợp dữ liệu từ hệ thống CRM, chuyển đổi để phù hợp với nhu cầu kinh doanh của bạn, rồi nạp vào kho dữ liệu Snowflake phục vụ phân tích.
Bạn cũng có thể tận dụng DAG để theo dõi và ghi log thời gian chạy tác vụ trong quy trình ETL, giúp xác định nút thắt cổ chai hoặc các tác vụ cần tối ưu.
DAG cũng rất phù hợp để quản lý các quy trình dữ liệu phức tạp có nhiều tác vụ và phụ thuộc. Chẳng hạn, một quy trình học máy có thể gồm các tác vụ như kỹ thuật đặc trưng, huấn luyện mô hình và triển khai mô hình.
Ví dụ, một DAG trong Apache Airflow có thể chạy các script chọn đặc trưng và chỉ kích hoạt huấn luyện mô hình sau khi đặc trưng đã được xử lý, đảm bảo quản lý phụ thuộc và khả năng tái lập.
DAG được dùng rộng rãi trong pipeline xử lý dữ liệu để quản lý luồng dữ liệu từ nhiều nguồn và chuyển hoá thành insight giá trị. Ví dụ, một DAG trong Apache Spark có thể xử lý dữ liệu clickstream từ website, thực hiện tổng hợp để tính thời lượng phiên và đưa insight vào bảng điều khiển.
DAG trong Spark không do người dùng định nghĩa tường minh mà được tạo nội bộ bởi framework để tối ưu hóa việc thực thi các phép biến đổi.
Trong học máy, DAG hỗ trợ bản chất lặp lại và mô-đun của quy trình. Chúng cho phép bạn thử nghiệm các bước tiền xử lý, thuật toán và siêu tham số khác nhau, đồng thời giữ cho pipeline có tổ chức.
Các công cụ như Kubeflow Pipelines và MLflow dùng DAG để quản lý quy trình học máy, cho phép thử nghiệm và triển khai liền mạch. Ví dụ, bạn có thể dùng DAG để kích hoạt pipeline huấn luyện lại khi phát hiện trôi dạt dữ liệu, đảm bảo mô hình luôn chính xác và phù hợp theo thời gian.
Bạn có nhiều công cụ giúp quản lý và điều phối DAG hiệu quả. Hãy cùng điểm qua một số lựa chọn phổ biến:
Apache Airflow là nền tảng được sử dụng rộng rãi để tạo, lập lịch và giám sát quy trình công việc. Nó xuất sắc trong việc định nghĩa các pipeline dữ liệu phức tạp dưới dạng DAG. Airflow cung cấp giao diện thân thiện để trực quan hóa và quản lý DAG, giúp dễ dàng hiểu và khắc phục sự cố quy trình dữ liệu. Tính linh hoạt và khả năng mở rộng khiến nó trở thành lựa chọn hàng đầu của nhiều đội ngũ kỹ thuật dữ liệu.
Prefect là công cụ điều phối hiện đại giúp đơn giản hóa việc tạo và quản lý quy trình dữ liệu. Nó cung cấp API dựa trên Python để định nghĩa DAG, giúp dễ dàng tích hợp với mã Python hiện có. Prefect ưu tiên độ tin cậy và khả năng quan sát, cung cấp tính năng như tự động thử lại, backfill và giám sát mạnh mẽ.
Dask là thư viện tính toán song song cho Python, quản lý các quy trình dữ liệu phân tán. Nó có thể song song hóa tính toán trên nhiều lõi hoặc máy, phù hợp cho tác vụ xử lý dữ liệu quy mô lớn. Dask dùng mô hình thực thi dựa trên DAG để lập lịch và phối hợp tác vụ, đảm bảo sử dụng tài nguyên hiệu quả.
Kubeflow Pipelines là nền tảng mã nguồn mở để xây dựng và triển khai quy trình học máy có khả năng mở rộng. Nó dùng DAG để định nghĩa quy trình đầu-cuối, từ tiền xử lý dữ liệu đến triển khai mô hình. Nhờ tích hợp chặt với Kubernetes, đây là lựa chọn mạnh mẽ để chạy quy trình trong môi trường đám mây. Kubeflow cũng cung cấp giao diện trực quan để quản lý và giám sát quy trình, mang lại tính minh bạch và kiểm soát.
Dagster là nền tảng điều phối được thiết kế cho các quy trình dữ liệu hiện đại. Nó nhấn mạnh tính mô-đun và an toàn kiểu, giúp việc kiểm thử và bảo trì DAG dễ dàng hơn. Dagster tích hợp với các công cụ phổ biến như Apache Spark, Snowflake và dbt, là lựa chọn tuyệt vời cho đội ngũ kỹ thuật dữ liệu dùng đa dạng công nghệ.
Trước khi tạo DAG, bạn cần thiết lập Apache Airflow. Bạn có thể cài đặt bằng Docker hoặc trình quản lý gói như pip:
pip install apache-airflowSau khi cài đặt, bạn cần cấu hình web server và scheduler của Airflow. Việc này bao gồm thiết lập và khởi tạo kết nối cơ sở dữ liệu, rồi khởi động web server:
airflow db init
airflow webserver --port 8080Khi Airflow đã sẵn sàng, bạn có thể tạo DAG của mình. Bạn dùng Python để định nghĩa DAG và các tác vụ như sau:
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG(
'simple_dag',
start_date=datetime(2023, 1, 1),
schedule_interval=None,
catchup=False
) as dag:
task1 = BashOperator(
task_id='task_1',
bash_command='echo "Hello, World!"'
)
task2 = BashOperator(
task_id='task_2',
bash_command='echo "This is task 2"'
)
task1 >> task2Trong ví dụ này, DAG đơn giản gồm hai tác vụ: task_1 và task_2. Toán tử >> thiết lập quan hệ phụ thuộc giữa các tác vụ, đảm bảo task_2 chỉ chạy sau khi task_1 hoàn tất.
Khi DAG đã được định nghĩa và triển khai lên Airflow, bạn có thể tương tác với nó qua giao diện web.
DAG có thể chạy theo hai cách:
schedule là rất phổ biến.Mỗi lần bạn chạy một DAG, sẽ tạo ra một phiên bản mới của DAG đó, gọi là DAG run. Nhiều DAG Run có thể chạy song song cho cùng một DAG, và mỗi DAG Run có một khoảng dữ liệu được xác định, chỉ ra giai đoạn dữ liệu mà các tác vụ sẽ xử lý.
Sau khi kích hoạt, bạn có thể theo dõi tiến độ trong DAG view, nơi hiển thị trực quan quy trình làm việc.
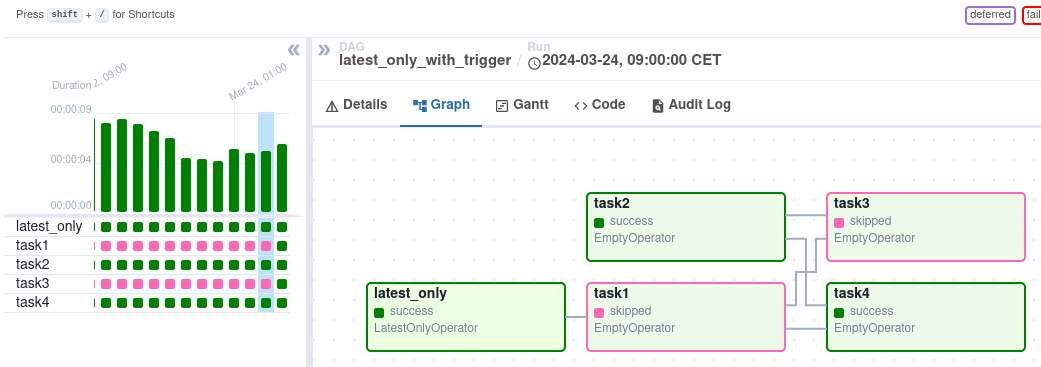 Giao diện xem DAG trên Airflow. Nguồn ảnh: Airflow
Giao diện xem DAG trên Airflow. Nguồn ảnh: Airflow
Chế độ xem Graph cung cấp cái nhìn chi tiết về một DAG run cụ thể, hiển thị phụ thuộc giữa tác vụ và thời gian thực thi. Chế độ xem Task Instances mang lại thông tin chi tiết về từng tác vụ, gồm trạng thái, thời gian bắt đầu và kết thúc, cùng nhật ký. Bạn có thể xem log tác vụ để khắc phục lỗi và hiểu nguyên nhân gốc rễ. Chế độ Task Instances cũng hiển thị thời lượng tác vụ, giúp bạn phát hiện vấn đề hiệu năng tiềm ẩn.
DAG là một khái niệm nền tảng trong kỹ thuật dữ liệu, cung cấp cách trực quan và có cấu trúc để biểu diễn các quy trình phức tạp. Hiểu về nút, cạnh và phụ thuộc giúp bạn thiết kế và quản lý pipeline dữ liệu hiệu quả.
DAG được sử dụng rộng rãi để điều phối quy trình ETL, quản lý pipeline xử lý dữ liệu và tự động hóa quy trình học máy. Bạn có thể tận dụng các công cụ như Apache Airflow, Prefect và Dask để tạo và quản lý DAG hiệu quả. Những công cụ này cung cấp giao diện thân thiện, khả năng lập lịch, cũng như tính năng giám sát nâng cao, xử lý lỗi và mở rộng.
Để trải nghiệm thực hành, khóa học nhập môn Airflow bằng Python có thể giúp bạn học cách tạo và quản lý DAG hiệu quả. Để có cái nhìn tổng quan hơn về các khái niệm và quy trình trong kỹ thuật dữ liệu, khóa học Understanding Data Engineering sẽ cung cấp nền tảng xuất sắc!
Tìm hiểu thêm về kỹ thuật dữ liệu với các khóa học này!
Tracks
Courses
Courses