
Cursus
Ingénieur professionnel en données en Python
40 h
Les flux de données et les pipelines nécessitent souvent une coordination précise pour garantir que les tâches sont exécutées dans le bon ordre. Le graphe acyclique dirigé (DAG) est un outil puissant pour gérer efficacement ces flux de travail et éviter les erreurs.
Dans cet article, nous allons explorer les DAG et leur importance dans l'ingénierie des données, passer en revue certaines de leurs applications et comprendre comment les utiliser à l'aide d'un exemple pratique utilisant Airflow.
Pour comprendre ce qu'est un DAG, définissons d'abord quelques concepts clés. En informatique, ungraphe est une structure de données non linéaire composée de nœuds et d'arêtes. Les nœuds représentent des entités ou des objets individuels, tandis que les arêtes relient ces nœuds et représentent des relations ou des connexions entre eux.
Dans un graphe orienté, ces arêtes ont une direction spécifique, indiquant une relation à sens unique entre les nœuds. Cela signifie que s'il existe une arête du nœud A au nœud B, elle implique une connexion de A à B, mais pas nécessairement de B à A.
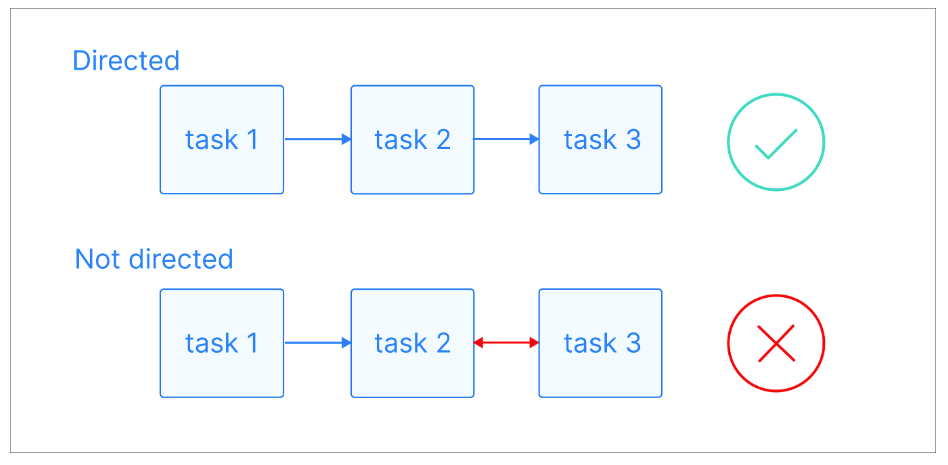
Explication visuelle des graphiques dirigés. Source de l'image : Astronome
Un chemin est une séquence de nœuds reliés par des arêtes directes. Il part d'un nœud spécifique et suit la direction des arêtes pour atteindre un autre nœud. Un chemin peut être de n'importe quelle longueur, d'un seul nœud à une séquence de plusieurs nœuds, tant que la direction des arêtes est suivie de manière cohérente.
Maintenant que nous disposons de quelques définitions de base, voyons ce qu'est un DAG : Un DAG est un graphe orienté sans cycles dirigés, où chaque nœud représente une tâche spécifique et chaque arête indique la dépendance entre ces tâches.
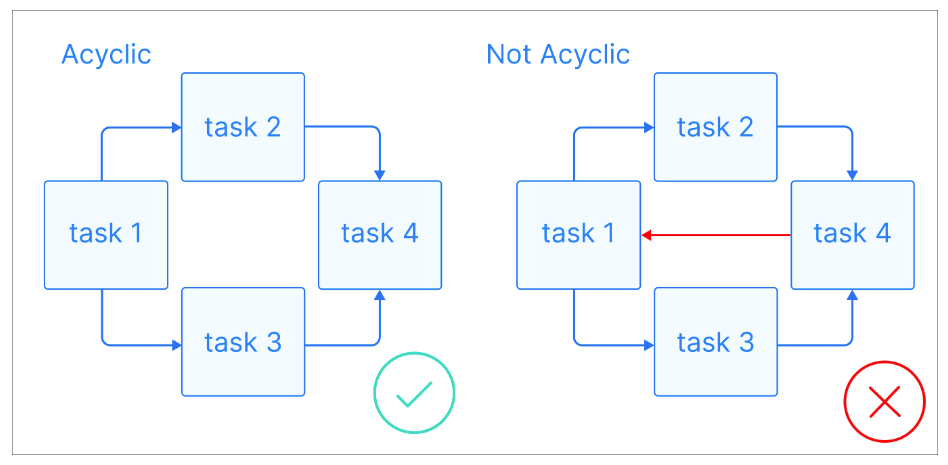 .Explication visuelle des graphes acycliques. Source de l'image : Astronome
.Explication visuelle des graphes acycliques. Source de l'image : Astronome
L'élément clé des DAG est qu'ils sont acycliques, ce qui signifie qu'une fois que vous commencez à un nœud, vous ne pouvez qu'aller de l'avant, sans jamais revenir à un nœud précédent. Cela garantit que les tâches peuvent être exécutées dans l'ordre sans entraîner de boucles infinies. Les DAG ont souvent une structure hiérarchique, où les tâches sont organisées en niveaux ou en couches. Les tâches d'un niveau supérieur dépendent généralement de l'accomplissement de tâches de niveaux inférieurs.
En tant qu'ingénieur de données ou personne effectuant des tâches d'ingénierie de données, vous êtes souvent confronté au défi de construire des pipelines de données complexes qui nécessitent l'exécution d'étapes, chacune d'entre elles dépendant de la précédente. C'est là que les DAG entrent en jeu !
Parce qu'ils peuvent représenter les tâches comme des nœuds et les dépendances comme des arêtes, les DAG imposent un ordre d'exécution logique, garantissant que les tâches sont exécutées de manière séquentielle sur la base de leurs dépendances. Cela permet d'éviter les erreurs et les incohérences liées à l'exécution des tâches dans le désordre. En outre, si une étape échoue, les DAG peuvent identifier et réexécuter les tâches concernées, ce qui permet d'économiser du temps et des efforts.
Si vous êtes novice en matière de construction de pipelines de données ou si vous souhaitez renforcer vos bases, le cours Understanding Data Engineering constitue un excellent point de départ.
La nature acyclique des DAG est l'une des principales caractéristiques qui les rend idéales pour les pipelines de données. Ils garantissent que les tâches peuvent être exécutées sans boucles infinies ni dépendances récursives susceptibles d'entraîner l'instabilité du système.
Prenons un exemple simple de pipeline de données :
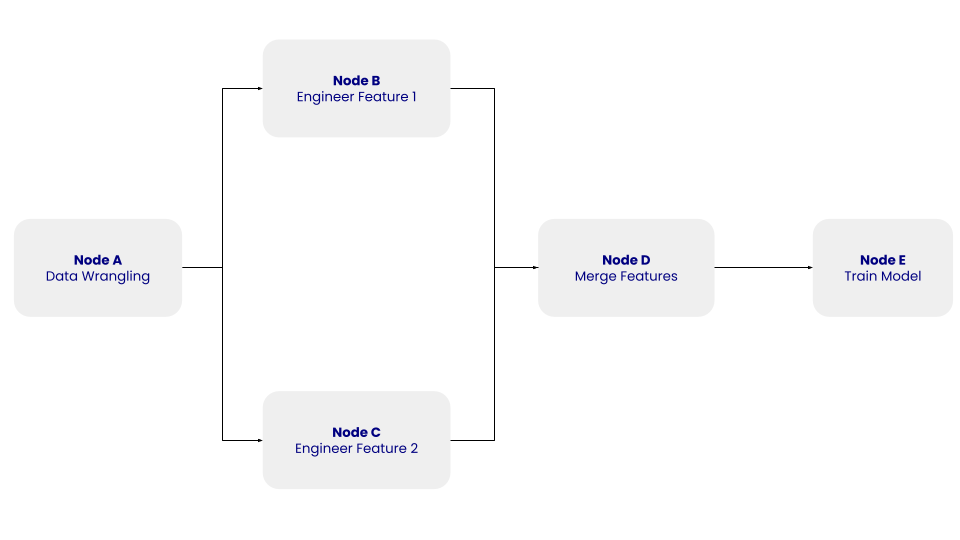 La structure de ce DAG simple avec les nœuds A, B, C, D et E et leurs dépendances. Image par l'auteur.
La structure de ce DAG simple avec les nœuds A, B, C, D et E et leurs dépendances. Image par l'auteur.
Dans le DAG ci-dessus, le nœud A représente l'étape de traitement des données, qui implique l'étape de nettoyage des données, au cours de laquelle les données extraites sont nettoyées et prétraitées. Les nœuds B et C représentent les étapes de l'ingénierie des caractéristiques, au cours desquelles les données nettoyées sont transformées indépendamment en deux caractéristiques. Le nœud D consiste à fusionner les caractéristiques. Enfin, le nœud E représente l'étape de formation du modèle, au cours de laquelle un modèle d'apprentissage automatique est formé sur les données transformées.
Le DAG ne se préoccupe pas de ce qui se passe à l'intérieur des tâches, mais de l'ordre dans lequel elles doivent être exécutées.
En outre, les DAG vous permettent de créer des flux de données automatisés et évolutifs, notamment dans les systèmes distribués et les environnements cloud. Ils décomposent les tâches complexes de traitement des données en sous-tâches plus petites, indépendantes et gérables, ce qui permet aux DAG de réaliser une exécution parallèle et une utilisation efficace des ressources. Cette évolutivité est particulièrement importante lorsqu'il s'agit de traiter de grands ensembles de données et des pipelines de données complexes, car elle permet un traitement rentable des données.
Enfin, les DAG peuvent fournir une représentation visuelle de n'importe quel pipeline de données, ce qui vous aide à comprendre et à communiquer le flux de travail. Cette clarté visuelle est importante lorsque vous collaborez avec d'autres membres de l'équipe ou des parties prenantes non techniques. Si vous pouvez comprendre le flux de données et les dépendances entre les tâches, il est plus facile d'identifier et de résoudre les problèmes, d'optimiser l'utilisation des ressources et de prendre des décisions éclairées sur les améliorations à apporter au pipeline.
Le cours sur l'ETL et l'ELT en Python est une excellente ressource pour mettre en pratique la création et l'optimisation des pipelines de données.
Les DAG ont été largement adoptés et ont différentes applications dans l'ingénierie des données. Nous avons parlé de certains d'entre eux dans la section précédente. Examinons maintenant certains d'entre eux plus en détail.
L'une des applications les plus courantes des DAG est l'orchestration des processus d'extraction, de transformation et de chargement (ETL). Les pipelines ETL consistent à extraire des données de différentes sources, à les transformer dans un format approprié et à les charger dans un système cible.
Par exemple, des outils comme Apache Airflow et Luigi utilisent les DAG pour orchestrer efficacement les pipelines ETL. Un cas d'utilisation pratique pourrait consister à intégrer des données provenant d'un système de gestion de la relation client, à les transformer pour les aligner sur les besoins de votre entreprise et à les charger dans un entrepôt de données Snowflake à des fins d'analyse.
Vous pouvez également exploiter les DAG pour surveiller et consigner les durées d'exécution des tâches dans vos processus ETL. Cela permet d'identifier les goulets d'étranglement ou les tâches qui doivent être optimisées.
Les DAG sont également parfaits pour gérer des flux de données complexes qui impliquent des tâches et des dépendances multiples. Par exemple, un flux de travail d'apprentissage automatique peut inclure des tâches telles que l'ingénierie des fonctionnalités, la formation des modèles et le déploiement des modèles.
Par exemple, un DAG dans Apache Airflow pourrait exécuter des scripts de sélection de fonctionnalités et déclencher l'apprentissage du modèle seulement après le traitement des fonctionnalités, assurant ainsi la gestion des dépendances et la reproductibilité.
Les DAG sont largement utilisés dans les pipelines de traitement de données pour gérer les flux de données provenant de sources multiples et les transformer en informations utiles. Par exemple, un DAG dans Apache Spark peut traiter les données de parcours de clics d'un site web, effectuer une agrégation pour calculer les durées de session et alimenter un tableau de bord avec ces informations.
Les DAG dans Spark ne sont pas explicitement définis par les utilisateurs mais sont créés en interne par le framework pour optimiser l'exécution des transformations.
Dans le domaine de l'apprentissage automatique, les DAG facilitent la nature itérative et modulaire des flux de travail. Ils vous permettent d'expérimenter différentes étapes de prétraitement, différents algorithmes et différents hyperparamètres tout en gardant le pipeline organisé.
Des outils tels que Kubeflow Pipelines et MLflow utilisent des DAG pour gérer les flux de travail d'apprentissage automatique, ce qui permet une expérimentation et un déploiement transparents. Par exemple, vous pouvez utiliser les DAG pour activer des pipelines de recyclage déclenchés par la détection de la dérive des données, afin de garantir que vos modèles restent précis et pertinents au fil du temps.
Vous disposez de plusieurs outils qui vous permettent de gérer et d'orchestrer efficacement les DAG. Examinons quelques-unes des options les plus populaires :
Apache Airflow est une plateforme largement utilisée pour créer, planifier et surveiller les flux de travail. Il excelle dans la définition de pipelines de données complexes sous forme de DAG. Airflow fournit une interface conviviale pour visualiser et gérer ces DAG, ce qui facilite la compréhension et le dépannage des flux de données. Sa flexibilité et son évolutivité en ont fait le choix privilégié de nombreuses équipes d'ingénierie des données.
Prefect est un outil d'orchestration moderne qui simplifie la création et la gestion des flux de données. Il offre une API basée sur Python pour définir les DAG, ce qui facilite l'intégration avec le code Python existant. Prefect donne la priorité à la fiabilité et à l'observabilité, en proposant des fonctionnalités telles que des tentatives automatiques, des remplissages et un suivi rigoureux.
Dask est une bibliothèque d'informatique parallèle pour Python qui gère les flux de données distribués. Il peut paralléliser les calculs sur plusieurs cœurs ou machines, ce qui le rend idéal pour les tâches de traitement de données à grande échelle. Dask utilise un modèle d'exécution basé sur un DAG pour planifier et coordonner les tâches, garantissant ainsi une utilisation efficace des ressources.
Kubeflow Pipelines est une plateforme open-source permettant de construire et de déployer des workflows d'apprentissage automatique évolutifs. Il utilise des DAG pour définir des flux de travail de bout en bout, du prétraitement des données au déploiement du modèle. Son intégration étroite avec Kubernetes en fait un choix solide pour l'exécution de flux de travail dans des environnements cloud. Kubeflow fournit également une interface visuelle pour la gestion et le suivi des flux de travail, offrant transparence et contrôle.
Dagster est une plateforme d'orchestration conçue pour les flux de données modernes. Il met l'accent sur la modularité et la sécurité des types, ce qui facilite les tests et la maintenance des DAG. Dagster s'intègre à des outils populaires comme Apache Spark, Snowflake et dbt, ce qui en fait un excellent choix pour les équipes d'ingénierie des données dotées de technologies diverses.
Avant de créer un DAG, vous devez configurer Apache Airflow. Vous pouvez l'installer en utilisant Docker ou un gestionnaire de paquets comme pip :
pip install apache-airflowUne fois installé, vous devrez configurer le serveur web et le programmateur Airflow. Il s'agit d'établir et d'initialiser les connexions à la base de données et de démarrer le serveur web :
airflow db init
airflow webserver --port 8080Une fois Airflow installé, vous pouvez créer votre DAG. Vous pouvez utiliser Python pour définir le DAG et ses tâches comme suit :
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG(
'simple_dag',
start_date=datetime(2023, 1, 1),
schedule_interval=None,
catchup=False
) as dag:
task1 = BashOperator(
task_id='task_1',
bash_command='echo "Hello, World!"'
)
task2 = BashOperator(
task_id='task_2',
bash_command='echo "This is task 2"'
)
task1 >> task2Dans cet exemple, le DAG simple contient deux tâches : task_1 et task_2. L'opérateur >> établit une dépendance entre les tâches, garantissant que task_2 ne s'exécute qu'une fois task_1 terminé.
Une fois que votre DAG est défini et déployé dans Airflow, vous pouvez interagir avec lui via l'interface web.
Les DAG fonctionnent de deux manières :
schedule.Chaque fois que vous exécutez un DAG, une nouvelle instance de ce DAG, appelée exécution du DAG, est créée. Les DAG Runs peuvent être exécutés en parallèle pour le même DAG, et chacun a un intervalle de données défini, qui identifie la période de données sur laquelle les tâches doivent fonctionner.
Après le déclenchement, vous pouvez suivre sa progression dans la vue DAG, qui représente visuellement le flux de travail.
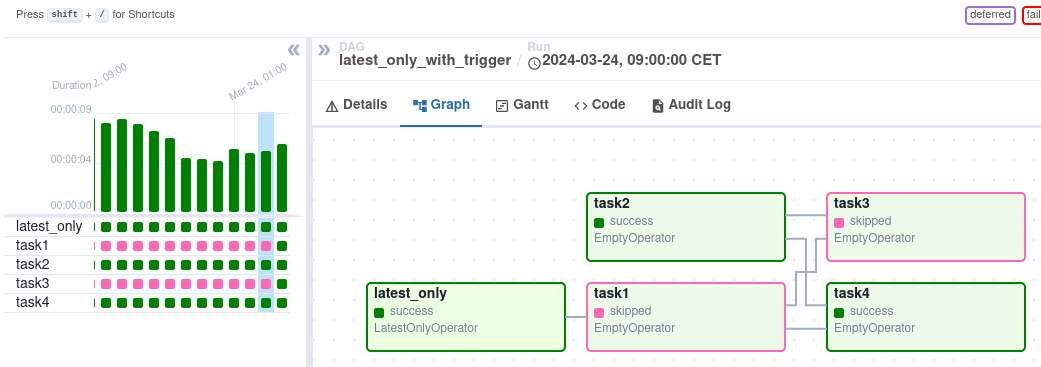 Vue DAG sur l'interface Airflow. Source de l'image : Airflow
Vue DAG sur l'interface Airflow. Source de l'image : Airflow
La vue dugraphique offre un aperçu détaillé de l'exécution d'un DAG spécifique, montrant les dépendances des tâches et les temps d'exécution. La vue Task Instances fournit des informations granulaires sur les tâches individuelles, y compris leur statut, les heures de début et de fin, et les journaux. Vous pouvez examiner les journaux des tâches pour résoudre les erreurs et comprendre la cause première des défaillances. La vue Task Instances indique également la durée des tâches, ce qui vous aide à identifier les problèmes de performance potentiels.
Les DAG sont un concept fondamental dans l'ingénierie des données, car ils fournissent un moyen visuel et structuré de représenter des flux de travail complexes. Comprendre les nœuds, les arêtes et les dépendances vous permet de concevoir et de gérer efficacement les pipelines de données.
Les DAG sont largement utilisés pour orchestrer les processus ETL, gérer les pipelines de traitement des données et automatiser les flux de travail d'apprentissage automatique. Vous pouvez tirer parti d'outils tels qu'Apache Airflow, Prefect et Dask pour créer et gérer efficacement des DAG. Ces outils offrent des interfaces conviviales, des capacités de planification et des fonctions avancées de surveillance, de traitement des erreurs et de mise à l'échelle.
Pour acquérir une expérience pratique, ce cours d'introduction à Airflow en Python peut vous aider à apprendre à créer et à gérer efficacement des DAG. Pour une compréhension plus large des concepts et des flux de travail de l' ingénierie des données, ce cours sur la compréhension de l'ingénierie des données constitue une excellente base !
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cursus
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Mark Pedigo
Tutoriel
Derrick Mwiti
Tutoriel
Moez Ali
Tutoriel
Sejal Jaiswal
