
Programa
Engenheiro de dados profissional Em Python
40 h
Os fluxos de trabalho e pipelines de dados geralmente exigem uma coordenação precisa para garantir que as tarefas sejam executadas na ordem correta. O DAG (Directed Acyclic Graph, gráfico acíclico dirigido) é uma ferramenta poderosa para gerenciar esses fluxos de trabalho com eficiência e evitar erros.
Neste artigo, exploraremos os DAGs e sua importância na engenharia de dados, analisaremos algumas de suas aplicações e entenderemos como usá-los por meio de um exemplo prático usando o Airflow.
Para entender o que é um DAG, vamos primeiro definir alguns conceitos-chave. Na ciência da computação, umgráfico é uma estrutura de dados não linear que consiste em nós e bordas. Os nós representam entidades ou objetos individuais, enquanto as bordas conectam esses nós e representam relacionamentos ou conexões entre eles.
Em um gráfico direcionado, essas bordas têm uma direção específica, indicando uma relação unidirecional entre os nós. Isso significa que, se houver uma borda do nó A para o nó B, isso implica uma conexão de A para B, mas não necessariamente de B para A.
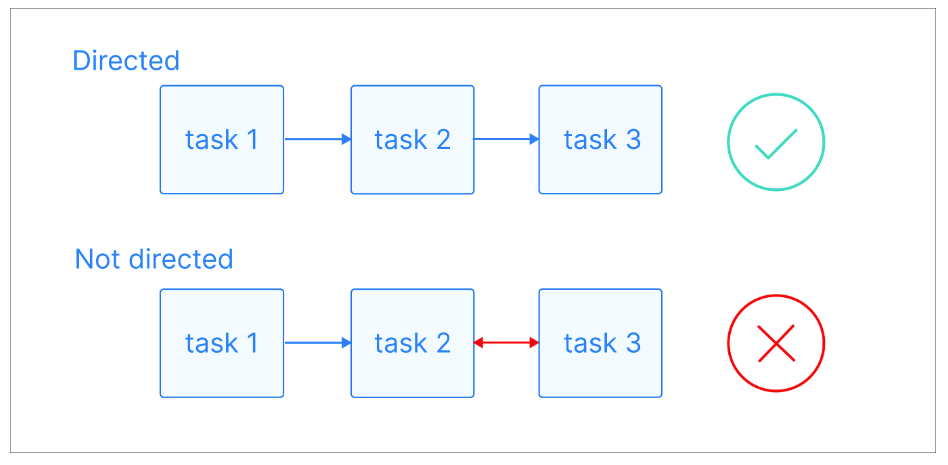
Explicação visual dos gráficos direcionados. Fonte da imagem: Astrônomo
Um caminho é uma sequência de nós conectados por bordas direcionadas. Ele começa em um nó específico e segue a direção das bordas para chegar a outro nó. Um caminho pode ter qualquer comprimento, de um único nó a uma sequência de muitos nós, desde que a direção das bordas seja seguida de forma consistente.
Agora que temos algumas definições básicas, vamos ver o que é um DAG: Um DAG é um gráfico direcionado sem ciclos direcionados, em que cada nó representa uma tarefa específica e cada borda indica a dependência entre eles.
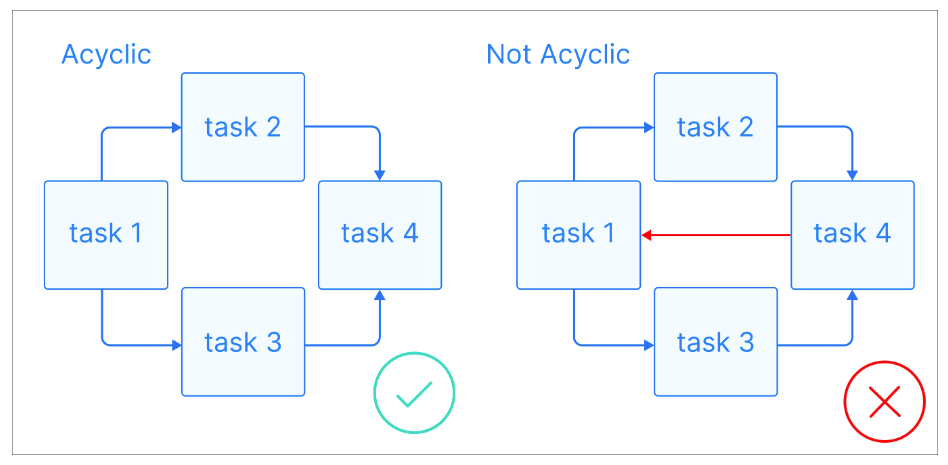 Explicação visual de gráficos acíclicos. Fonte da imagem: Astrônomo
Explicação visual de gráficos acíclicos. Fonte da imagem: Astrônomo
O principal aspecto dos DAGs é que eles são acíclicos, o que significa que, uma vez iniciado em um nó, você só pode seguir em frente, sem nunca retornar a um nó anterior. Isso garante que as tarefas possam ser executadas em ordem sem levar a loops infinitos. Os DAGs geralmente têm uma estrutura hierárquica, em que as tarefas são organizadas em níveis ou camadas. As tarefas em um nível mais alto geralmente dependem da conclusão de tarefas em níveis mais baixos.
Como engenheiro de dados ou como alguém que executa tarefas de engenharia de dados, você frequentemente se depara com o desafio de criar pipelines de dados complexos que exigem a execução de etapas, cada uma delas dependendo da anterior. É aí que entram os DAGs!
Como podem representar tarefas como nós e dependências como bordas, os DAGs impõem uma ordem de execução lógica, garantindo que as tarefas sejam executadas sequencialmente com base em suas dependências. Isso evita que erros e inconsistências causem a execução de tarefas fora de ordem. Além disso, se uma etapa falhar, os DAGs podem identificar e executar novamente as tarefas afetadas, economizando tempo e esforço.
Se você é novo na criação de pipelines de dados ou deseja fortalecer suas bases, o curso Understanding Data Engineering é um excelente ponto de partida.
A natureza acíclica dos DAGs é uma das principais características que os torna ideais para pipelines de dados. Eles garantem que as tarefas possam ser executadas sem loops infinitos ou dependências recursivas que podem resultar em instabilidade do sistema.
Vamos considerar um exemplo simples de um pipeline de dados:
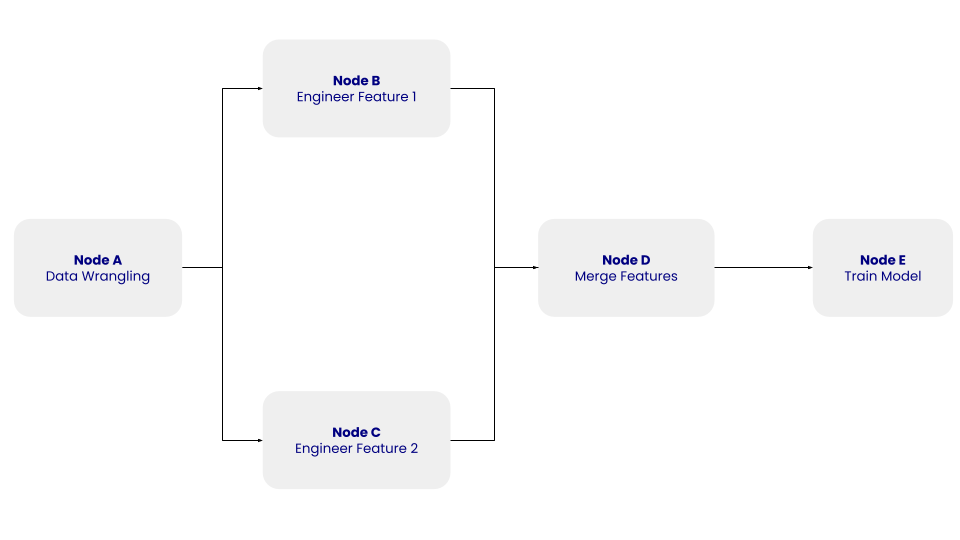 A estrutura desse DAG simples com os nós A, B, C, D e E e suas dependências. Imagem do autor.
A estrutura desse DAG simples com os nós A, B, C, D e E e suas dependências. Imagem do autor.
No DAG acima, o nó A representa a etapa de preparação de dados, que envolve a etapa de limpeza de dados, na qual os dados extraídos são limpos e pré-processados. Os nós B e C representam as etapas de engenharia de recursos, em que os dados limpos são transformados independentemente em dois recursos. O nó D envolve a fusão dos recursos. Por fim, o nó E representa a etapa de treinamento do modelo, em que um modelo de aprendizado de máquina é treinado nos dados transformados.
O DAG não se importa com o que acontece dentro das tarefas, mas com a ordem em que elas devem ser executadas.
Além disso, os DAGs permitem que você crie fluxos de trabalho de dados automatizados e dimensionáveis, especialmente em sistemas distribuídos e ambientes de nuvem. Eles dividem tarefas complexas de processamento de dados em subtarefas menores, independentes e gerenciáveis, o que permite que os DAGs realizem a execução paralela e a utilização eficiente de recursos. Essa escalabilidade é particularmente importante ao lidar com grandes conjuntos de dados e pipelines de dados complexos, pois permite o processamento econômico de dados.
Por fim, os DAGs podem fornecer uma representação visual de qualquer pipeline de dados, o que ajuda você a entender e comunicar o fluxo de trabalho. Essa clareza visual é importante ao colaborar com outros membros da equipe ou partes interessadas não técnicas. Se você puder entender o fluxo de dados e as dependências entre as tarefas, será mais fácil identificar e corrigir problemas, otimizar a utilização de recursos e tomar decisões informadas sobre melhorias no pipeline.
O curso sobre ETL e ELT em Python é um ótimo recurso para você praticar a criação e a otimização de pipelines de dados.
Os DAGs foram amplamente adotados e têm diferentes aplicações na engenharia de dados. Falamos sobre alguns deles na seção anterior. Agora, vamos explorar alguns deles com mais detalhes.
Uma das aplicações mais comuns dos DAGs é a orquestração de processos de extração, transformação e carga (ETL). Os pipelines de ETL envolvem a extração de dados de várias fontes, transformando-os em um formato adequado e carregando-os em um sistema de destino.
Por exemplo, ferramentas como o Apache Airflow e o Luigi usam DAGs para orquestrar pipelines de ETL com eficiência. Um caso de uso prático pode envolver a integração de dados de um sistema CRM, transformando-os para que se alinhem às suas necessidades comerciais e carregando-os em um data warehouse da Snowflake para análise.
Você também pode aproveitar os DAGs para monitorar e registrar os tempos de execução de tarefas em seus processos de ETL. Isso pode ajudar a identificar gargalos ou tarefas que exigem otimização.
Os DAGs também são ótimos para gerenciar fluxos de trabalho de dados complexos que envolvem várias tarefas e dependências. Por exemplo, um fluxo de trabalho de aprendizado de máquina pode incluir tarefas como engenharia de recursos, treinamento de modelos e implantação de modelos.
Por exemplo, um DAG no Apache Airflow pode executar scripts de seleção de recursos e acionar o treinamento do modelo somente depois que os recursos forem processados, garantindo o gerenciamento de dependências e a reprodutibilidade.
Os DAGs são amplamente utilizados em pipelines de processamento de dados para gerenciar o fluxo de dados de várias fontes e transformá-lo em insights valiosos. Por exemplo, um DAG no Apache Spark pode processar dados de fluxo de cliques de um site, realizar a agregação para calcular a duração da sessão e alimentar um painel com os insights.
Os DAGs no Spark não são definidos explicitamente pelos usuários, mas são criados internamente pela estrutura para otimizar a execução das transformações.
No aprendizado de máquina, os DAGs ajudam na natureza iterativa e modular dos fluxos de trabalho. Eles permitem que você faça experiências com diferentes etapas de pré-processamento, algoritmos e hiperparâmetros, mantendo o pipeline organizado.
Ferramentas como o Kubeflow Pipelines e o MLflow usam DAGs para gerenciar fluxos de trabalho de aprendizado de máquina, permitindo a experimentação e a implantação contínuas. Por exemplo, você pode usar DAGs para habilitar pipelines de retreinamento acionados pela detecção de desvio de dados, garantindo que seus modelos permaneçam precisos e relevantes ao longo do tempo.
Você tem várias ferramentas que o ajudam a gerenciar e orquestrar DAGs de forma eficaz. Vamos explorar algumas das opções mais populares:
O Apache Airflow é uma plataforma amplamente usada para criar, programar e monitorar fluxos de trabalho. Ele é excelente para definir pipelines de dados complexos como DAGs. O Airflow oferece uma interface amigável para visualizar e gerenciar esses DAGs, facilitando a compreensão e a solução de problemas de fluxos de trabalho de dados. Sua flexibilidade e escalabilidade o tornaram a escolha ideal para muitas equipes de engenharia de dados.
O Prefect é uma ferramenta de orquestração moderna que simplifica a criação e o gerenciamento de fluxos de trabalho de dados. Ele oferece uma API baseada em Python para definir DAGs, facilitando a integração com o código Python existente. A Prefect prioriza a confiabilidade e a observabilidade, oferecendo recursos como novas tentativas automáticas, backfills e monitoramento robusto.
Dask é uma biblioteca de computação paralela para Python que gerencia fluxos de trabalho de dados distribuídos. Ele pode paralelizar os cálculos em vários núcleos ou máquinas, o que o torna ideal para tarefas de processamento de dados em grande escala. O Dask usa um modelo de execução baseado em DAG para agendar e coordenar tarefas, garantindo a utilização eficiente dos recursos.
O Kubeflow Pipelines é uma plataforma de código aberto para criar e implantar fluxos de trabalho de aprendizado de máquina dimensionáveis. Ele usa DAGs para definir fluxos de trabalho de ponta a ponta, desde o pré-processamento de dados até a implantação do modelo. Sua forte integração com o Kubernetes o torna uma excelente opção para executar fluxos de trabalho em ambientes de nuvem. O Kubeflow também fornece uma interface visual para gerenciar e monitorar fluxos de trabalho, oferecendo transparência e controle.
A Dagster é uma plataforma de orquestração projetada para fluxos de trabalho de dados modernos. Ele enfatiza a modularidade e a segurança de tipo, facilitando o teste e a manutenção de DAGs. O Dagster se integra a ferramentas populares como Apache Spark, Snowflake e dbt, o que o torna uma excelente opção para equipes de engenharia de dados com diversas tecnologias.
Antes de criar um DAG, você precisa configurar o Apache Airflow. Você pode instalá-lo usando o Docker ou um gerenciador de pacotes como o pip:
pip install apache-airflowDepois de instalado, você precisará configurar o servidor da Web e o agendador do Airflow. Isso envolve a configuração e a inicialização de conexões de banco de dados e a inicialização do servidor da Web:
airflow db init
airflow webserver --port 8080Com o Airflow configurado, você pode criar seu DAG. Você pode usar o Python para definir o DAG e suas tarefas da seguinte forma:
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG(
'simple_dag',
start_date=datetime(2023, 1, 1),
schedule_interval=None,
catchup=False
) as dag:
task1 = BashOperator(
task_id='task_1',
bash_command='echo "Hello, World!"'
)
task2 = BashOperator(
task_id='task_2',
bash_command='echo "This is task 2"'
)
task1 >> task2Neste exemplo, o DAG simples contém duas tarefas: task_1 e task_2. O operador >> define uma dependência entre as tarefas, garantindo que task_2 seja executado somente após a conclusão de task_1.
Depois que o DAG for definido e implantado no Airflow, você poderá interagir com ele por meio da interface da Web.
Os DAGs serão executados de duas maneiras:
schedule.Sempre que você executa um DAG, é criada uma nova instância desse DAG, chamada de execução do DAG. As execuções de DAG podem ser executadas em paralelo para o mesmo DAG, e cada uma tem um intervalo de dados definido, que identifica o período de dados em que as tarefas devem operar.
Após o acionamento, você pode monitorar seu progresso na visualização DAG, que representa visualmente o fluxo de trabalho.
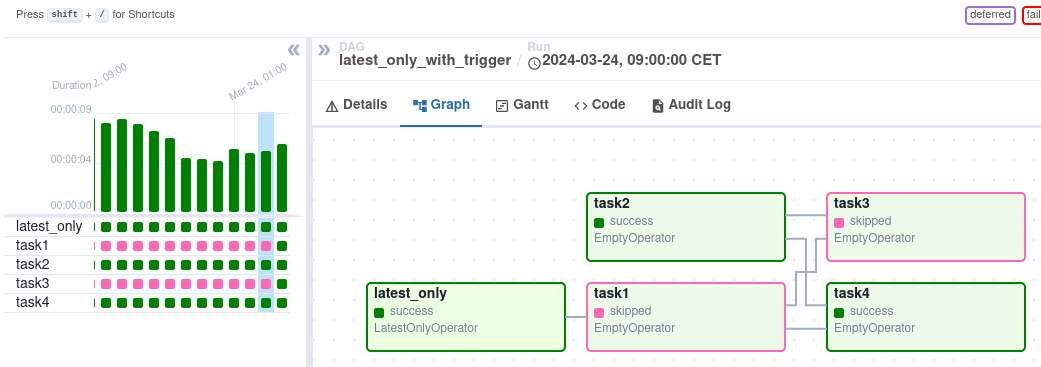 Visualização do DAG na do Visualização do DAG na interface do Airflow. Fonte da imagem: Fluxo de ar
Visualização do DAG na do Visualização do DAG na interface do Airflow. Fonte da imagem: Fluxo de ar
O Graph View oferece uma visão detalhada da execução de um DAG específico, mostrando as dependências de tarefas e os tempos de execução. A visualização Task Instances fornece informações detalhadas sobre tarefas individuais, incluindo status, horários de início e término e registros. Você pode examinar os logs de tarefas para solucionar erros e entender a causa raiz das falhas. A visualização Task Instances também mostra a duração da tarefa, ajudando você a identificar possíveis problemas de desempenho.
Os DAGs são um conceito fundamental na engenharia de dados, fornecendo uma maneira visual e estruturada de representar fluxos de trabalho complexos. Entender os nós, as bordas e as dependências ajuda você a projetar e gerenciar pipelines de dados com eficiência.
Os DAGs são amplamente usados para orquestrar processos de ETL, gerenciar pipelines de processamento de dados e automatizar fluxos de trabalho de aprendizado de máquina. Você pode aproveitar ferramentas como Apache Airflow, Prefect e Dask para criar e gerenciar DAGs com eficiência. Essas ferramentas oferecem interfaces fáceis de usar, recursos de agendamento e monitoramento avançado, tratamento de erros e recursos de dimensionamento.
Para obter experiência prática, este curso introdutório sobre Airflow em Python pode ajudar você a aprender a criar e gerenciar DAGs de forma eficaz. Para que você tenha uma compreensão mais ampla dos conceitos e fluxos de trabalho da engenharia de dados, este curso sobre como entender a engenharia de dados é uma excelente base!
Saiba mais sobre engenharia de dados com estes cursos!
Programa
Curso
Curso
blog
Tim Lu
12 min
blog
Kurtis Pykes
11 min
blog
Matt Crabtree
10 min
blog
DataCamp Team
11 min
Tutorial
Amberle McKee
Tutorial
Kurtis Pykes


