
Program
Insinyur Data Profesional dalam Python
40 Hr
Alur kerja dan pipeline data sering memerlukan koordinasi yang presisi untuk menjamin tugas dieksekusi dalam urutan yang benar. Directed Acyclic Graph (DAG) adalah alat yang ampuh untuk mengelola alur kerja ini secara efisien dan menghindari kesalahan.
Dalam artikel ini, kita akan membahas DAG dan pentingnya dalam rekayasa data, meninjau beberapa penerapannya, serta memahami cara menggunakannya melalui contoh praktis menggunakan Airflow.
Untuk memahami apa itu DAG, mari terlebih dahulu mendefinisikan beberapa konsep kunci. Dalam ilmu komputer, sebuah graph adalah struktur data non-linear yang terdiri dari node dan edge. Node merepresentasikan entitas atau objek individual, sementara edge menghubungkan node-node tersebut dan merepresentasikan relasi atau koneksi di antara mereka.
Dalam graph berarah (directed graph), edge memiliki arah tertentu, yang menunjukkan relasi satu arah antar node. Artinya, jika ada edge dari node A ke node B, itu menyiratkan koneksi dari A ke B, namun tidak harus sebaliknya dari B ke A.
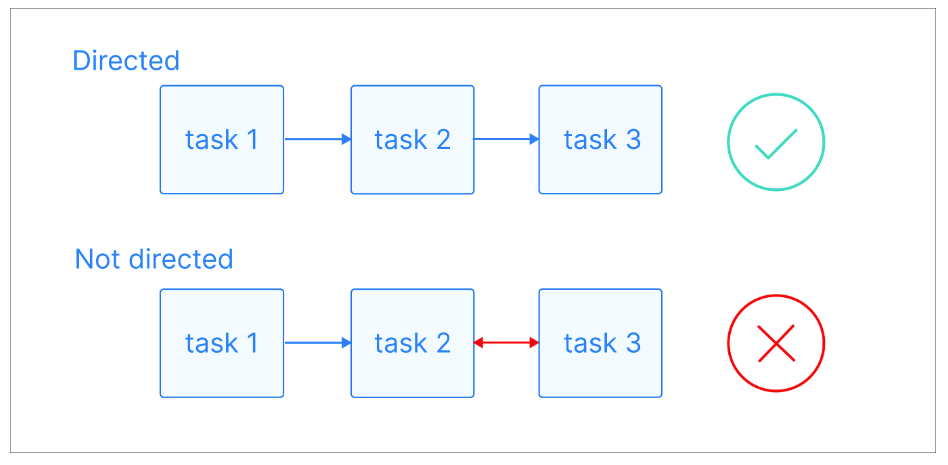
Penjelasan visual directed graphs. Sumber gambar: Astronomer
Sebuah path adalah urutan node yang terhubung oleh edge berarah. Path dimulai pada node tertentu dan mengikuti arah edge untuk mencapai node lain. Panjang path dapat bervariasi, dari satu node hingga rangkaian banyak node, selama arah edge diikuti secara konsisten.
Kini setelah kita memiliki beberapa definisi dasar, mari lihat apa itu DAG: DAG adalah graf berarah tanpa siklus berarah (acyclic), di mana setiap node mewakili tugas tertentu, dan setiap edge menunjukkan ketergantungan di antaranya.
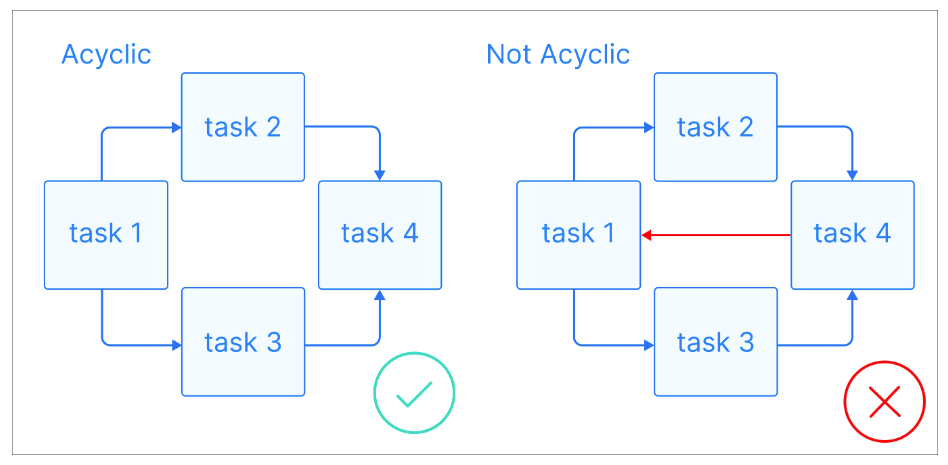 Penjelasan visual graf asiklik. Sumber gambar: Astronomer
Penjelasan visual graf asiklik. Sumber gambar: Astronomer
Hal terpenting tentang DAG adalah sifatnya yang asiklik, artinya setelah Anda mulai dari satu node, Anda hanya bisa bergerak maju dan tidak pernah kembali ke node sebelumnya. Ini memastikan tugas dapat dieksekusi berurutan tanpa menimbulkan loop tak berujung. DAG sering memiliki struktur hierarkis, di mana tugas diatur ke dalam tingkatan atau lapisan. Tugas pada tingkat yang lebih tinggi biasanya bergantung pada penyelesaian tugas di tingkat yang lebih rendah.
Sebagai data engineer atau seseorang yang menjalankan tugas rekayasa data, Anda sering dihadapkan pada tantangan membangun pipeline data yang kompleks yang memerlukan eksekusi langkah-langkah yang saling bergantung satu sama lain. Di sinilah DAG berperan!
Karena dapat merepresentasikan tugas sebagai node dan ketergantungan sebagai edge, DAG menegakkan urutan eksekusi yang logis, memastikan tugas dieksekusi secara berurutan berdasarkan ketergantungannya. Ini mencegah kesalahan dan inkonsistensi akibat menjalankan tugas tidak sesuai urutan. Selain itu, jika satu langkah gagal, DAG dapat mengidentifikasi dan menjalankan ulang tugas yang terpengaruh, menghemat waktu dan upaya.
Jika Anda baru dalam membangun pipeline data atau ingin memperkuat dasar-dasar, kursus Understanding Data Engineering adalah titik awal yang sangat baik.
Sifat asiklik dari DAG adalah salah satu karakteristik utama yang membuatnya ideal untuk pipeline data. DAG memastikan tugas dapat dieksekusi tanpa loop tak berujung atau ketergantungan rekursif yang dapat menyebabkan ketidakstabilan sistem.
Mari pertimbangkan contoh sederhana dari pipeline data:
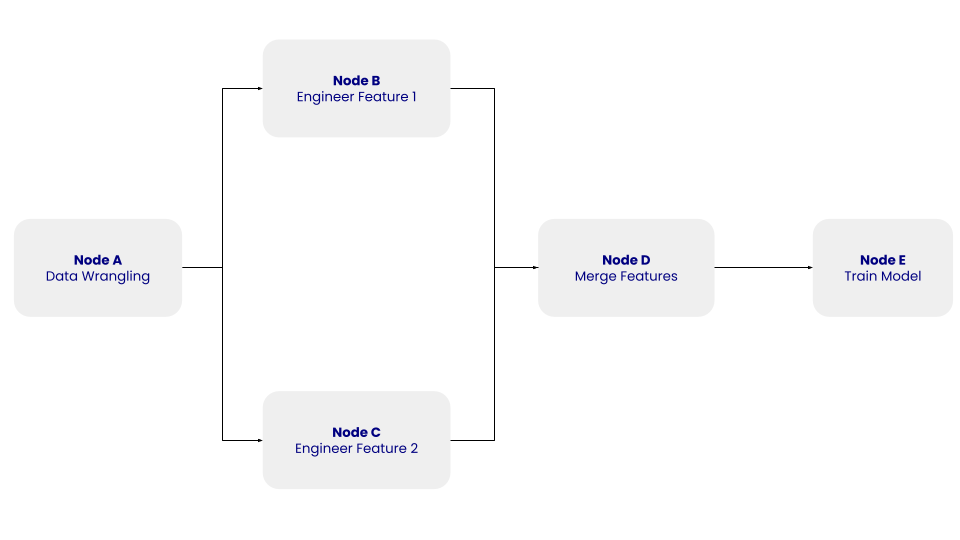 Struktur DAG sederhana dengan node A, B, C, D, dan E beserta ketergantungannya. Gambar oleh Penulis.
Struktur DAG sederhana dengan node A, B, C, D, dan E beserta ketergantungannya. Gambar oleh Penulis.
Pada DAG di atas, node A merepresentasikan langkah data wrangling, yang mencakup langkah pembersihan data, di mana data hasil ekstraksi dibersihkan dan dipraproses. Node B dan C merepresentasikan langkah rekayasa fitur (feature engineering), di mana data yang telah dibersihkan diubah secara independen menjadi dua fitur. Node D melibatkan penggabungan fitur. Terakhir, node E merepresentasikan langkah pelatihan model, di mana model pembelajaran mesin dilatih pada data yang telah ditransformasikan.
DAG tidak peduli dengan apa yang terjadi di dalam tugas, melainkan urutan eksekusinya.
Selain itu, DAG memungkinkan Anda membuat alur kerja data yang otomatis dan dapat diskalakan, terutama dalam sistem terdistribusi dan lingkungan cloud. DAG memecah tugas pemrosesan data yang kompleks menjadi sub-tugas yang lebih kecil, independen, dan mudah dikelola, yang memungkinkan eksekusi paralel dan pemanfaatan sumber daya yang efisien. Skalabilitas ini sangat penting saat menangani dataset besar dan pipeline data yang kompleks, karena memungkinkan pemrosesan data yang hemat biaya.
Terakhir, DAG dapat memberikan representasi visual dari pipeline data apa pun, yang membantu Anda memahami dan mengomunikasikan alur kerja. Kejelasan visual ini penting saat berkolaborasi dengan anggota tim lain atau pemangku kepentingan non-teknis. Jika Anda dapat memahami aliran data dan ketergantungan antar tugas, akan lebih mudah untuk mengidentifikasi dan memperbaiki masalah, mengoptimalkan pemanfaatan sumber daya, serta membuat keputusan yang tepat tentang peningkatan pipeline.
Kursus ETL and ELT in Python merupakan sumber belajar yang sangat baik untuk latihan langsung dalam membuat dan mengoptimalkan pipeline data.
DAG telah banyak diadopsi dan memiliki berbagai penerapan dalam rekayasa data. Kita telah menyinggung beberapa di antaranya pada bagian sebelumnya. Sekarang, mari jelajahi beberapa di antaranya secara lebih mendalam.
Salah satu penerapan paling umum dari DAG adalah mengorkestrasi proses Extract, Transform, and Load (ETL). Pipeline ETL melibatkan ekstraksi data dari berbagai sumber, mentransformasikannya ke format yang sesuai, dan memuatnya ke sistem target.
Sebagai contoh, alat seperti Apache Airflow dan Luigi menggunakan DAG untuk mengorkestrasi pipeline ETL secara efisien. Penggunaan praktisnya dapat mencakup integrasi data dari sistem CRM, mentransformasikannya agar selaras dengan kebutuhan bisnis Anda, dan memuatnya ke gudang data Snowflake untuk analitik.
Anda juga dapat memanfaatkan DAG untuk memantau dan mencatat waktu eksekusi tugas dalam proses ETL. Hal ini dapat membantu mengidentifikasi bottleneck atau tugas yang perlu dioptimalkan.
DAG juga sangat baik untuk mengelola alur kerja data yang kompleks yang melibatkan banyak tugas dan ketergantungan. Sebagai contoh, alur kerja pembelajaran mesin mungkin mencakup tugas seperti rekayasa fitur, pelatihan model, dan penyebaran model.
Misalnya, sebuah DAG di Apache Airflow dapat mengeksekusi skrip pemilihan fitur dan memicu pelatihan model hanya setelah fitur selesai diproses, memastikan pengelolaan ketergantungan dan reproduktibilitas.
DAG banyak digunakan dalam pipeline pemrosesan data untuk mengelola aliran data dari berbagai sumber dan mengubahnya menjadi wawasan berharga. Misalnya, sebuah DAG di Apache Spark dapat memproses data clickstream dari situs web, melakukan agregasi untuk menghitung durasi sesi, dan memasukkan wawasan tersebut ke dalam dasbor.
DAG di Spark tidak didefinisikan secara eksplisit oleh pengguna, melainkan dibuat secara internal oleh kerangka kerja untuk mengoptimalkan eksekusi transformasi.
Dalam pembelajaran mesin, DAG membantu sifat alur kerja yang iteratif dan modular. DAG memungkinkan Anda bereksperimen dengan berbagai langkah prapemrosesan, algoritme, dan hiperparameter sambil menjaga pipeline tetap terorganisasi.
Alat seperti Kubeflow Pipelines dan MLflow menggunakan DAG untuk mengelola alur kerja pembelajaran mesin, memungkinkan eksperimen dan penyebaran yang mulus. Misalnya, Anda dapat menggunakan DAG untuk mengaktifkan pipeline pelatihan ulang yang dipicu oleh deteksi pergeseran data (data drift), memastikan model Anda tetap akurat dan relevan seiring waktu.
Ada berbagai alat yang membantu Anda mengelola dan mengorkestrasi DAG secara efektif. Mari jelajahi beberapa opsi yang paling populer:
Apache Airflow adalah platform yang banyak digunakan untuk membuat, menjadwalkan, dan memantau alur kerja. Airflow unggul dalam mendefinisikan pipeline data yang kompleks sebagai DAG. Airflow menyediakan antarmuka yang ramah pengguna untuk memvisualisasikan dan mengelola DAG ini, sehingga mudah memahami dan menelusuri alur kerja data. Fleksibilitas dan skalabilitasnya menjadikannya pilihan utama banyak tim rekayasa data.
Prefect adalah alat orkestrasi modern yang menyederhanakan pembuatan dan pengelolaan alur kerja data. Prefect menawarkan API berbasis Python untuk mendefinisikan DAG, sehingga mudah diintegrasikan dengan kode Python yang sudah ada. Prefect memprioritaskan keandalan dan observabilitas, menyediakan fitur seperti percobaan ulang otomatis, backfill, dan pemantauan yang andal.
Dask adalah pustaka komputasi paralel untuk Python yang mengelola alur kerja data terdistribusi. Dask dapat memparalelkan komputasi di banyak inti atau mesin, menjadikannya ideal untuk tugas pemrosesan data skala besar. Dask menggunakan model eksekusi berbasis DAG untuk menjadwalkan dan mengoordinasikan tugas, memastikan pemanfaatan sumber daya yang efisien.
Kubeflow Pipelines adalah platform open-source untuk membangun dan menyebarkan alur kerja pembelajaran mesin yang dapat diskalakan. Kubeflow menggunakan DAG untuk mendefinisikan alur kerja end-to-end, dari prapemrosesan data hingga penyebaran model. Integrasinya yang erat dengan Kubernetes menjadikannya pilihan kuat untuk menjalankan alur kerja di lingkungan cloud. Kubeflow juga menyediakan antarmuka visual untuk mengelola dan memantau alur kerja, menawarkan transparansi dan kontrol.
Dagster adalah platform orkestrasi yang dirancang untuk alur kerja data modern. Dagster menekankan modularitas dan keamanan tipe (type safety), sehingga pengujian dan pemeliharaan DAG menjadi lebih mudah. Dagster terintegrasi dengan alat populer seperti Apache Spark, Snowflake, dan dbt, menjadikannya pilihan yang sangat baik bagi tim rekayasa data dengan teknologi yang beragam.
Sebelum membuat DAG, Anda perlu menyiapkan Apache Airflow. Anda dapat menginstalnya menggunakan Docker atau pengelola paket seperti pip:
pip install apache-airflowSetelah terpasang, Anda perlu mengonfigurasi web server dan scheduler Airflow. Ini melibatkan penyiapan dan inisialisasi koneksi basis data serta memulai web server:
airflow db init
airflow webserver --port 8080Dengan Airflow yang sudah siap, Anda dapat membuat DAG. Anda bisa menggunakan Python untuk mendefinisikan DAG dan tugas-tugasnya sebagai berikut:
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG(
'simple_dag',
start_date=datetime(2023, 1, 1),
schedule_interval=None,
catchup=False
) as dag:
task1 = BashOperator(
task_id='task_1',
bash_command='echo "Hello, World!"'
)
task2 = BashOperator(
task_id='task_2',
bash_command='echo "This is task 2"'
)
task1 >> task2Dalam contoh ini, DAG sederhana berisi dua tugas: task_1 dan task_2. Operator >> menetapkan ketergantungan antara tugas, memastikan bahwa task_2 hanya dieksekusi setelah task_1 selesai.
Setelah DAG Anda didefinisikan dan dideploy ke Airflow, Anda dapat berinteraksi dengannya melalui antarmuka web.
DAG akan berjalan dengan salah satu dari dua cara:
schedule sangat umum dilakukan.Setiap kali Anda menjalankan DAG, sebuah instance baru dari DAG tersebut, yang disebut DAG run, akan dibuat. DAG run dapat berjalan paralel untuk DAG yang sama, dan masing-masing memiliki interval data yang didefinisikan, yang mengidentifikasi periode data yang harus dioperasikan oleh tugas.
Setelah dipicu, Anda dapat memantau progresnya di tampilan DAG, yang merepresentasikan alur kerja secara visual.
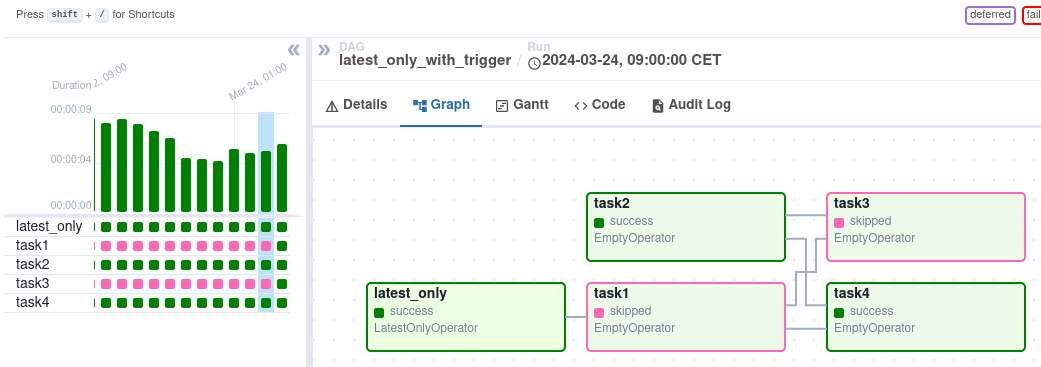 Tampilan DAG pada antarmuka Airflow. Sumber gambar: Airflow
Tampilan DAG pada antarmuka Airflow. Sumber gambar: Airflow
Tampilan Graph menawarkan pandangan terperinci tentang suatu DAG run tertentu, menampilkan ketergantungan tugas dan waktu eksekusi. Tampilan Task Instances memberikan informasi mendetail tentang tugas individual, termasuk status, waktu mulai dan selesai, serta log. Anda dapat menelaah log tugas untuk menelusuri kesalahan dan memahami akar penyebab kegagalan. Tampilan Task Instances juga menampilkan durasi tugas, membantu Anda mengidentifikasi potensi masalah kinerja.
DAG adalah konsep fundamental dalam rekayasa data, yang menyediakan cara visual dan terstruktur untuk merepresentasikan alur kerja yang kompleks. Memahami node, edge, dan ketergantungan membantu Anda merancang dan mengelola pipeline data secara efisien.
DAG banyak digunakan untuk mengorkestrasi proses ETL, mengelola pipeline pemrosesan data, dan mengotomatisasi alur kerja pembelajaran mesin. Anda dapat memanfaatkan alat seperti Apache Airflow, Prefect, dan Dask untuk membuat dan mengelola DAG secara efektif. Alat-alat ini menyediakan antarmuka yang ramah pengguna, kemampuan penjadwalan, serta fitur pemantauan, penanganan kesalahan, dan penskalaan yang canggih.
Untuk mendapatkan pengalaman langsung, kursus pengantar Airflow dalam Python ini dapat membantu Anda belajar membuat dan mengelola DAG secara efektif. Untuk pemahaman yang lebih luas tentang konsep dan alur kerja rekayasa data, kursus mengenai pemahaman rekayasa data ini menyediakan fondasi yang sangat baik!
Pelajari lebih lanjut tentang rekayasa data melalui kursus-kursus ini!
Program
Kursus
Kursus
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
