
Programma
Ingegnere dei dati professionale in Python
40 h
I workflow e le pipeline di dati spesso richiedono un coordinamento preciso per garantire che le attività vengano eseguite nell'ordine corretto. Il grafo aciclico diretto (DAG) è uno strumento potente per gestire questi workflow in modo efficiente ed evitare errori.
In questo articolo esploreremo i DAG e la loro importanza nell'ingegneria dei dati, passeremo in rassegna alcune applicazioni e vedremo come usarli con un esempio pratico tramite Airflow.
Per capire cos'è un DAG, definiamo prima alcuni concetti chiave. In informatica, un grafo è una struttura dati non lineare composta da nodi e archi. I nodi rappresentano entità o oggetti, mentre gli archi collegano questi nodi e rappresentano relazioni o connessioni tra di essi.
In un grafo diretto, gli archi hanno una direzione specifica, che indica una relazione a senso unico tra i nodi. Ciò significa che se c'è un arco dal nodo A al nodo B, implica una connessione da A a B, ma non necessariamente da B ad A.
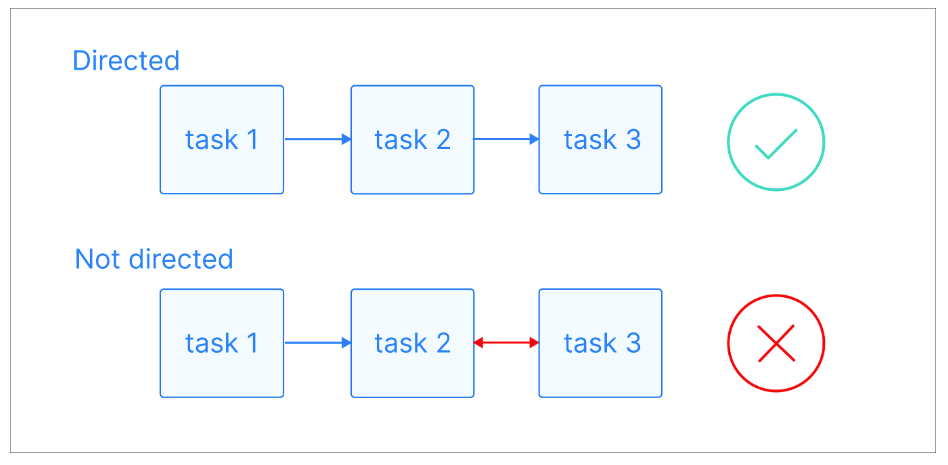
Spiegazione visiva dei grafi diretti. Fonte immagine: Astronomer
Un percorso è una sequenza di nodi collegati da archi diretti. Inizia da un nodo specifico e segue la direzione degli archi per raggiungere un altro nodo. Un percorso può avere qualsiasi lunghezza, da un singolo nodo a una sequenza di molti nodi, purché la direzione degli archi sia seguita coerentemente.
Ora che abbiamo alcune definizioni di base, vediamo cos'è un DAG: un DAG è un grafo diretto senza cicli diretti, in cui ogni nodo rappresenta un'attività specifica e ogni arco indica la dipendenza tra di esse.
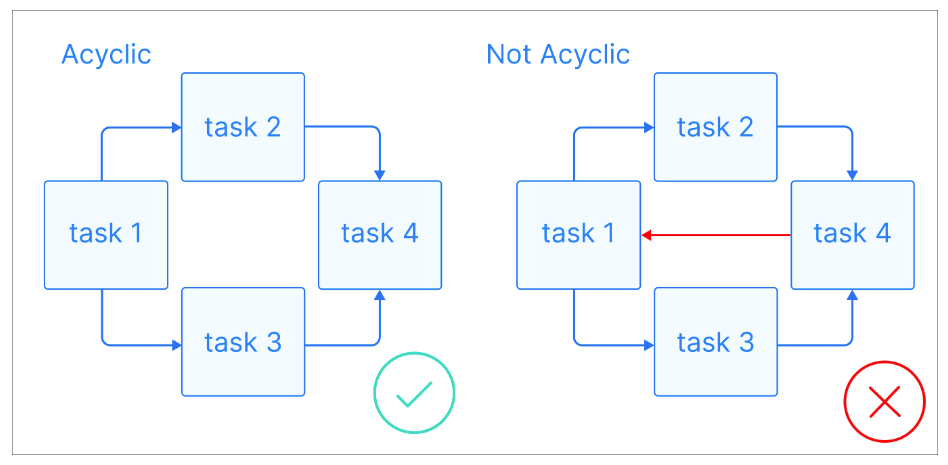 Spiegazione visiva dei grafi aciclici. Fonte immagine: Astronomer
Spiegazione visiva dei grafi aciclici. Fonte immagine: Astronomer
L'aspetto fondamentale dei DAG è che sono aciclici, il che significa che una volta partiti da un nodo si può solo procedere in avanti, senza tornare a un nodo precedente. Questo garantisce che le attività possano essere eseguite in ordine senza portare a loop infiniti. I DAG hanno spesso una struttura gerarchica, in cui le attività sono organizzate in livelli o layer. Le attività a un livello superiore dipendono tipicamente dal completamento di quelle ai livelli inferiori.
Come data engineer, o se svolgi attività di data engineering, ti trovi spesso ad affrontare la sfida di costruire pipeline di dati complesse che richiedono l'esecuzione di passaggi, ciascuno dipendente dal precedente. È qui che entrano in gioco i DAG!
Poiché possono rappresentare le attività come nodi e le dipendenze come archi, i DAG impongono un ordine logico di esecuzione, assicurando che le attività vengano eseguite in sequenza in base alle loro dipendenze. Questo previene errori e incoerenze derivanti dall'esecuzione delle attività fuori ordine. Inoltre, se un passaggio fallisce, i DAG possono identificare e rieseguire le attività interessate, facendo risparmiare tempo e fatica.
Se sei alle prime armi nella creazione di pipeline di dati o vuoi rafforzare le basi, il corso Understanding Data Engineering è un ottimo punto di partenza.
La natura aciclica dei DAG è una delle caratteristiche chiave che li rende ideali per le pipeline di dati. Garantiscono che le attività possano essere eseguite senza loop infiniti o dipendenze ricorsive che possono causare instabilità del sistema.
Consideriamo un semplice esempio di pipeline di dati:
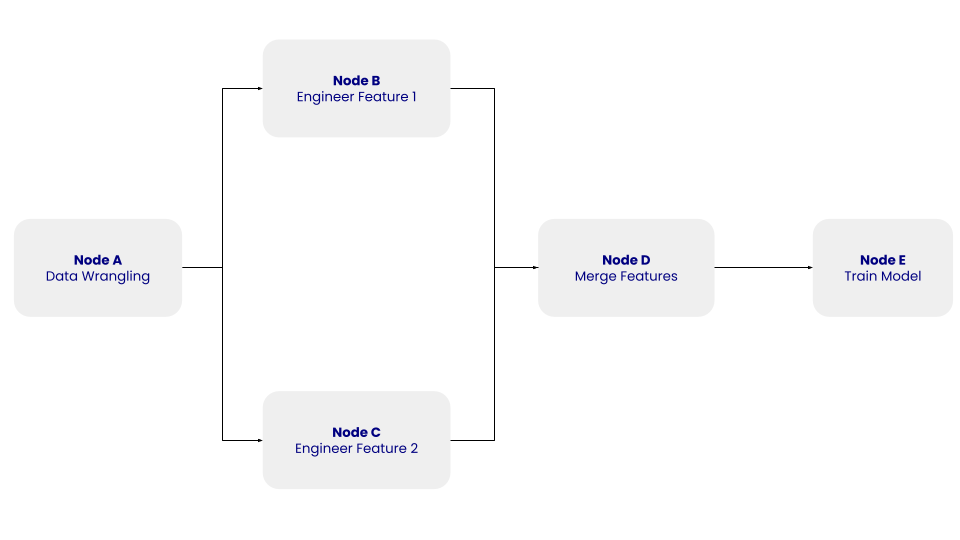 La struttura di questo semplice DAG con i nodi A, B, C, D ed E e le loro dipendenze. Immagine dell'autore.
La struttura di questo semplice DAG con i nodi A, B, C, D ed E e le loro dipendenze. Immagine dell'autore.
Nel DAG sopra, il nodo A rappresenta la fase di wrangling dei dati, che include il passaggio di pulizia dei dati, in cui i dati estratti vengono puliti e preprocessati. I nodi B e C rappresentano le fasi di feature engineering, in cui i dati puliti vengono trasformati in modo indipendente in due caratteristiche. Il nodo D prevede l'unione delle caratteristiche. Infine, il nodo E rappresenta la fase di addestramento del modello, in cui un modello di machine learning viene addestrato sui dati trasformati.
Il DAG non si preoccupa di ciò che accade all'interno delle attività, ma dell'ordine in cui devono essere eseguite.
Inoltre, i DAG ti permettono di creare workflow di dati automatizzati e scalabili, soprattutto in sistemi distribuiti e ambienti cloud. Suddividono attività di elaborazione dati complesse in sottoattività più piccole, indipendenti e gestibili, consentendo esecuzione in parallelo e un uso efficiente delle risorse. Questa scalabilità è particolarmente importante quando si lavora con dataset di grandi dimensioni e pipeline complesse, perché consente un'elaborazione dei dati conveniente.
Infine, i DAG possono fornire una rappresentazione visiva di qualsiasi pipeline di dati, utile per comprendere e comunicare il workflow. Questa chiarezza visiva è importante quando collabori con altri membri del team o stakeholder non tecnici. Se riesci a capire il flusso di dati e le dipendenze tra le attività, è più facile individuare e risolvere problemi, ottimizzare l'utilizzo delle risorse e prendere decisioni informate sul miglioramento della pipeline.
Il corso su ETL ed ELT in Python è un'ottima risorsa per fare pratica nella creazione e ottimizzazione delle pipeline di dati.
I DAG sono stati ampiamente adottati e hanno diverse applicazioni nell'ingegneria dei dati. Ne abbiamo citate alcune nella sezione precedente. Ora esploriamone alcune più in dettaglio.
Una delle applicazioni più comuni dei DAG è l'orchestrazione dei processi di Extract, Transform, and Load (ETL). Le pipeline ETL prevedono l'estrazione di dati da varie fonti, la trasformazione in un formato adeguato e il caricamento in un sistema di destinazione.
Per esempio, strumenti come Apache Airflow e Luigi usano i DAG per orchestrare in modo efficiente le pipeline ETL. Un caso d'uso pratico potrebbe prevedere l'integrazione di dati da un sistema CRM, la loro trasformazione per allinearli alle esigenze aziendali e il caricamento in un data warehouse Snowflake per l'analisi.
Puoi anche sfruttare i DAG per monitorare e registrare i tempi di esecuzione delle attività nei tuoi processi ETL. Questo può aiutare a individuare colli di bottiglia o attività che richiedono ottimizzazione.
I DAG sono ottimi anche per gestire workflow di dati complessi che coinvolgono più attività e dipendenze. Ad esempio, un workflow di machine learning può includere attività come feature engineering, addestramento del modello e deployment del modello.
Per esempio, un DAG in Apache Airflow potrebbe eseguire script di selezione delle caratteristiche e avviare l'addestramento del modello solo dopo che le caratteristiche sono state processate, garantendo la gestione delle dipendenze e la riproducibilità.
I DAG sono ampiamente utilizzati nelle pipeline di elaborazione dati per gestire il flusso di dati da più fonti e trasformarlo in insight di valore. Ad esempio, un DAG in Apache Spark potrebbe elaborare i dati di clickstream di un sito web, eseguire aggregazioni per calcolare la durata delle sessioni e alimentare un cruscotto con gli insight.
I DAG in Spark non sono definiti esplicitamente dagli utenti ma vengono creati internamente dal framework per ottimizzare l'esecuzione delle trasformazioni.
Nel machine learning, i DAG aiutano con la natura iterativa e modulare dei workflow. Ti permettono di sperimentare diversi passaggi di preprocessing, algoritmi e iperparametri mantenendo organizzata la pipeline.
Strumenti come Kubeflow Pipelines e MLflow usano i DAG per gestire i workflow di machine learning, consentendo sperimentazione e deployment senza soluzione di continuità. Per esempio, puoi usare i DAG per abilitare pipeline di riaddestramento attivate dal rilevamento di data drift, assicurando che i modelli restino accurati e pertinenti nel tempo.
Hai a disposizione vari strumenti che ti aiutano a gestire e orchestrare i DAG in modo efficace. Vediamo alcune delle opzioni più popolari:
Apache Airflow è una piattaforma ampiamente utilizzata per creare, schedulare e monitorare i workflow. Eccelle nel definire pipeline di dati complesse come DAG. Airflow fornisce un'interfaccia intuitiva per visualizzare e gestire questi DAG, facilitando la comprensione e la risoluzione dei problemi dei workflow di dati. La sua flessibilità e scalabilità lo hanno reso una scelta di riferimento per molti team di data engineering.
Prefect è uno strumento di orchestrazione moderno che semplifica la creazione e la gestione dei workflow di dati. Offre una API basata su Python per definire i DAG, facilitando l'integrazione con il codice Python esistente. Prefect dà priorità all'affidabilità e all'osservabilità, con funzionalità come retry automatici, backfill e monitoraggio robusto.
Dask è una libreria di calcolo parallelo per Python che gestisce workflow di dati distribuiti. Può parallelizzare le computazioni su più core o macchine, rendendolo ideale per attività di elaborazione dati su larga scala. Dask utilizza un modello di esecuzione basato su DAG per pianificare e coordinare le attività, garantendo un uso efficiente delle risorse.
Kubeflow Pipelines è una piattaforma open source per creare e distribuire workflow di machine learning scalabili. Utilizza i DAG per definire workflow end-to-end, dal preprocessing dei dati al deployment del modello. La sua stretta integrazione con Kubernetes lo rende una scelta solida per eseguire workflow in ambienti cloud. Kubeflow offre anche un'interfaccia visiva per gestire e monitorare i workflow, offrendo trasparenza e controllo.
Dagster è una piattaforma di orchestrazione progettata per i workflow di dati moderni. Enfatizza la modularità e la type safety, facilitando il testing e la manutenzione dei DAG. Dagster si integra con strumenti popolari come Apache Spark, Snowflake e dbt, risultando un'ottima scelta per team di data engineering con tecnologie eterogenee.
Prima di creare un DAG, devi configurare Apache Airflow. Puoi installarlo con Docker o con un gestore pacchetti come pip:
pip install apache-airflowUna volta installato, dovrai configurare il web server e lo scheduler di Airflow. Questo comporta la configurazione e l'inizializzazione delle connessioni al database e l'avvio del web server:
airflow db init
airflow webserver --port 8080Con Airflow configurato, puoi creare il tuo DAG. Puoi usare Python per definire il DAG e le sue attività come segue:
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG(
'simple_dag',
start_date=datetime(2023, 1, 1),
schedule_interval=None,
catchup=False
) as dag:
task1 = BashOperator(
task_id='task_1',
bash_command='echo "Hello, World!"'
)
task2 = BashOperator(
task_id='task_2',
bash_command='echo "This is task 2"'
)
task1 >> task2In questo esempio, il DAG semplice contiene due attività: task_1 e task_2. L'operatore >> imposta una dipendenza tra le attività, assicurando che task_2 venga eseguita solo dopo il completamento di task_1.
Una volta definito e distribuito il tuo DAG in Airflow, puoi interagirci tramite l'interfaccia web.
I DAG verranno eseguiti in due modi:
schedule è molto comune.Ogni volta che esegui un DAG, viene creata una nuova istanza di quel DAG, chiamata DAG run. I DAG run possono essere eseguiti in parallelo per lo stesso DAG e ciascuno ha un intervallo di dati definito, che identifica il periodo di dati su cui le attività devono operare.
Dopo l'attivazione, puoi monitorarne l'avanzamento nella vista DAG, che rappresenta visivamente il workflow.
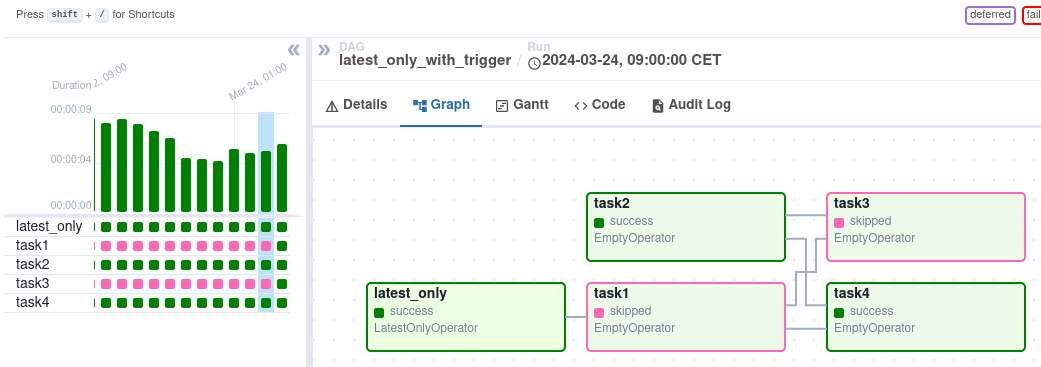 Vista DAG nell'interfaccia di Airflow. Fonte immagine: Airflow
Vista DAG nell'interfaccia di Airflow. Fonte immagine: Airflow
La vista Graph offre uno sguardo dettagliato a un DAG run specifico, mostrando le dipendenze tra le attività e i tempi di esecuzione. La vista Task Instances fornisce informazioni granulari sulle singole attività, compresi stato, orari di inizio e fine e log. Puoi esaminare i log delle attività per risolvere gli errori e capirne la causa radice. La vista Task Instances mostra anche la durata delle attività, aiutandoti a individuare potenziali problemi di performance.
I DAG sono un concetto fondamentale nell'ingegneria dei dati, poiché offrono un modo visivo e strutturato per rappresentare workflow complessi. Comprendere nodi, archi e dipendenze ti aiuta a progettare e gestire in modo efficiente le pipeline di dati.
I DAG sono ampiamente utilizzati per orchestrare processi ETL, gestire pipeline di elaborazione dati e automatizzare workflow di machine learning. Puoi sfruttare strumenti come Apache Airflow, Prefect e Dask per creare e gestire efficacemente i DAG. Questi strumenti offrono interfacce intuitive, funzionalità di schedulazione e funzionalità avanzate di monitoraggio, gestione degli errori e scalabilità.
Per fare pratica, questo corso introduttivo su Airflow in Python può aiutarti a imparare a creare e gestire i DAG in modo efficace. Per una comprensione più ampia dei concetti e dei workflow di data engineering, questo corso su understanding data engineering offre un'ottima base!
Scopri di più sull'ingegneria dei dati con questi corsi!
Programma
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

