Leerpad
AI-basisprincipes
10 Hr
Algoritmen voor het doorlopen van grafen zijn fundamenteel voor veel toepassingen in de informatica, van gameontwikkeling tot robotica. Deze algoritmen zijn ontworpen om grafen te verkennen en te navigeren. Grafen zijn datastructuren die bestaan uit knooppunten (vertices) en randen (edges). Onder deze algoritmen springt het A*-algoritme eruit als een bijzonder efficiënte en veelzijdige aanpak om optimale paden te vinden.
Het A*-algoritme is een geïnformeerd zoekalgoritme, wat betekent dat het een heuristische functie gebruikt om de zoektocht richting het doel te sturen. Deze heuristische functie schat de kosten in om het doel vanuit een bepaald knooppunt te bereiken, waardoor het algoritme veelbelovende paden kan prioriteren en onnodige verkenningen kan vermijden.
In dit artikel bekijken we de kernconcepten van het A*-algoritme, de implementatie in Python, de toepassingsgebieden en de voordelen en beperkingen.
Wil je meer leren over programmeren in Python? Bekijk dan onze Introduction to Python for Developers Course-cursus.
Het A*-algoritme is een krachtig en veelgebruikt algoritme voor het doorlopen van grafen en het vinden van paden. Het vindt het kortste pad tussen een startknooppunt en een doelknooppunt in een gewogen graaf.
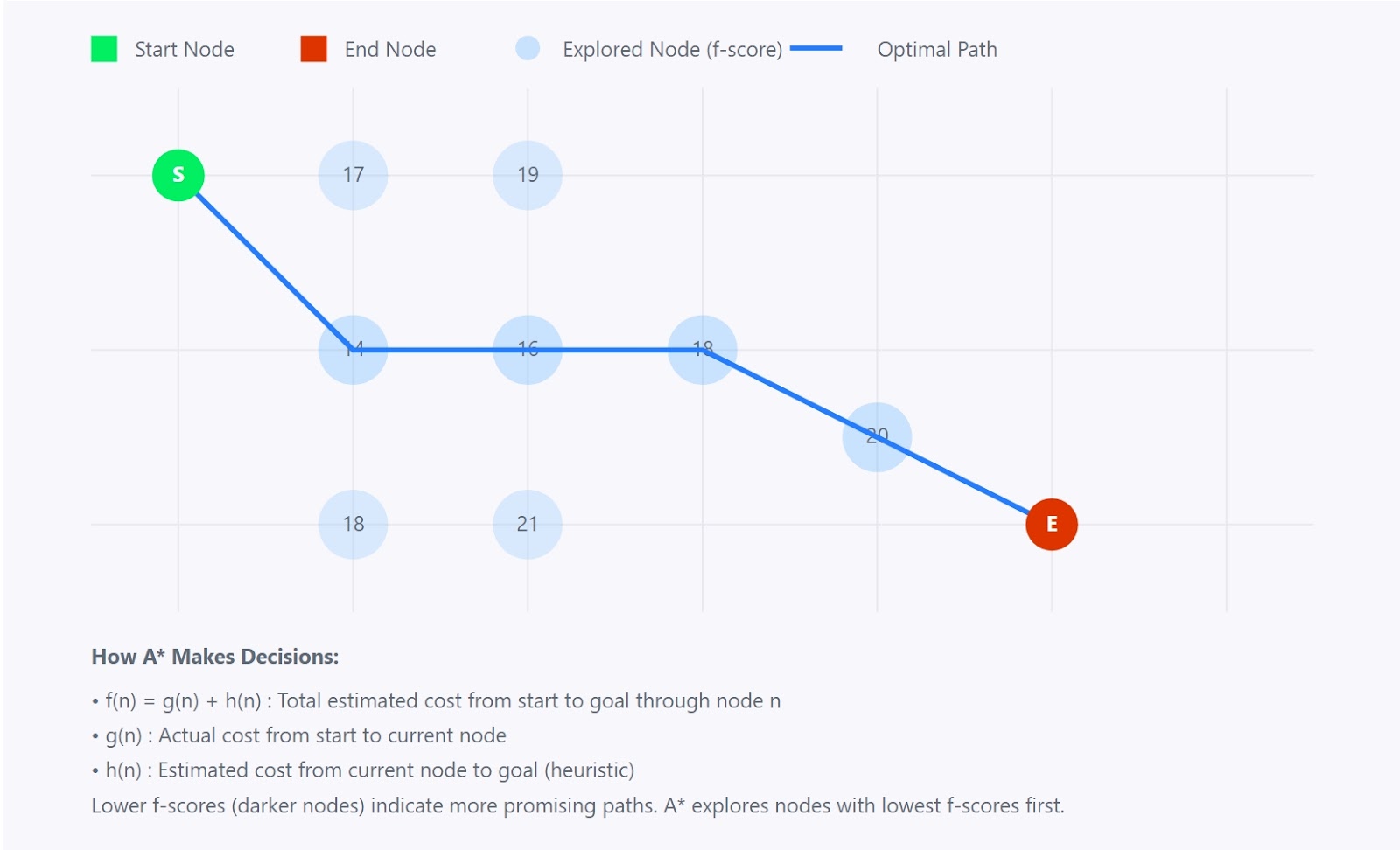
A*-algoritme
Het A*-algoritme combineert de beste aspecten van twee andere algoritmen:
Stel je voor dat je de kortste route tussen twee steden op een kaart probeert te vinden. Terwijl Dijkstra's algoritme in alle richtingen zou verkennen en Best-First Search misschien recht op het doel af zou gaan (en zo mogelijk sluiproutes mist), doet A* iets slimmer. Het houdt rekening met zowel:
Deze combinatie helpt A* weloverwogen beslissingen te nemen over welk pad het daarna moet verkennen, waardoor het zowel efficiënt als nauwkeurig is.
Om het A*-algoritme te begrijpen, moet je vertrouwd zijn met deze basisconcepten:
In de volgende sectie gaan we dieper in op deze concepten en zien we hoe A* ze gebruikt om optimale paden te vinden.
De efficiëntie van het A*-algoritme komt voort uit de slimme evaluatie van paden met drie belangrijke componenten: g(n), h(n) en f(n). Deze componenten werken samen om het zoekproces naar de meest veelbelovende paden te leiden.
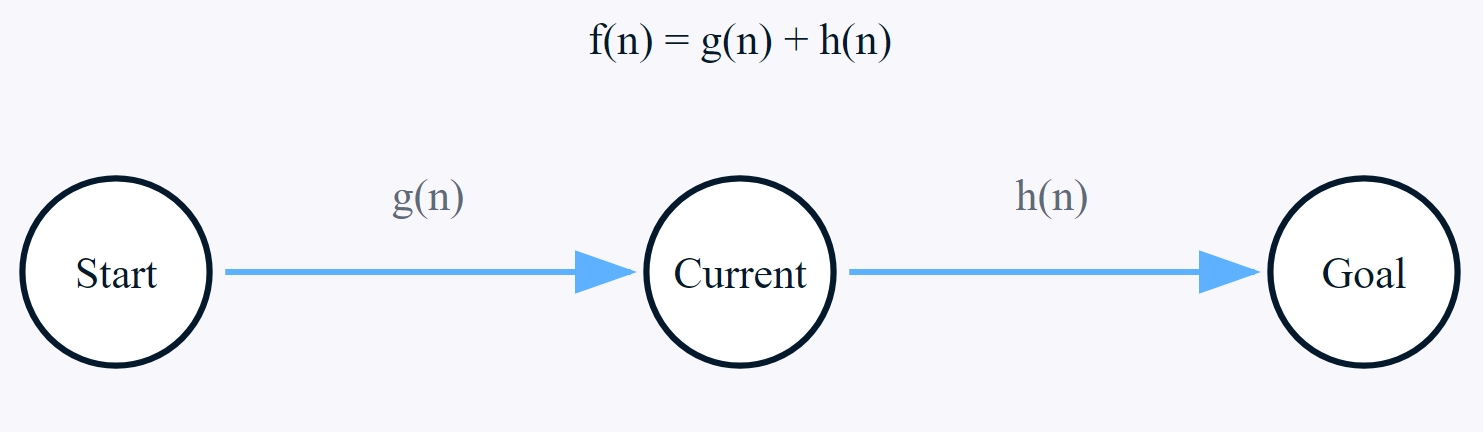
Kostenfunctie van het A*-algoritme
De padkostenfunctie g(n) vertegenwoordigt de exacte, bekende afstand van het initiële startknooppunt tot de huidige positie in onze zoektocht. In tegenstelling tot geschatte waarden is deze kost nauwkeurig en wordt berekend door alle individuele randgewichten op te tellen die we langs ons gekozen pad hebben doorkruist.
Wiskundig kunnen we voor een pad door de knooppunten n0 (startknooppunt) tot nk (huidig knooppunt) g(n) als volgt uitdrukken:
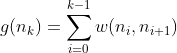
Waarbij:
Terwijl we door de graaf bewegen, stapelt deze waarde zich op en geeft ze een duidelijk beeld van de daadwerkelijke middelen (of dat nu afstand, tijd of een andere metriek is) die we hebben besteed om onze huidige positie te bereiken.
De heuristische functie h(n) geeft een geschatte kost van het huidige knooppunt naar het doelknooppunt en fungeert als de "geïnformeerde gok" van het algoritme over het resterende pad.
Wiskundig moet voor elk gegeven knooppunt n de heuristische schatting voldoen aan de voorwaarde h(n)≤h*(n) , waarbij h*(n) de werkelijke kost naar het doel is. Zo is de heuristiek toelaatbaar (admissible) doordat de echte kost nooit wordt overschat.
In rooster- of kaartachtige problemen zijn veelgebruikte heuristieken de Manhattan-afstand en Euclidische afstand. Voor coördinaten (x1,y1) van het huidige knooppunt en (x2,y2) van het doelknooppunt worden deze afstanden als volgt berekend:
![]()
![]()
De totale geschatte kost f(n) is de hoeksteen van het beslissingsproces van het A*-algoritme. Het combineert zowel de werkelijke padkosten als de heuristische schatting om het potentieel van elk knooppunt te beoordelen. Voor elk knooppunt n wordt deze kost berekend als:
![]()
Waarbij:
Het algoritme gebruikt deze gecombineerde waarde om strategisch te kiezen welk knooppunt vervolgens wordt verkend. Het selecteert steeds het knooppunt met de laagste f(n)-waarde uit de open lijst en zorgt zo voor een optimale balans tussen bekende kosten en geschatte resterende afstanden.
Het A*-algoritme onderhoudt twee essentiële lijsten
Open lijst:
Gesloten lijst:
Het algoritme selecteert voortdurend het knooppunt met de laagste f(n)-waarde uit de open lijst, evalueert het en verplaatst het naar de gesloten lijst, totdat het het doelknooppunt bereikt of vaststelt dat er geen pad bestaat.
Nu we de fundamentele componenten van A* begrijpen, bekijken we hoe ze in de praktijk samenkomen. De implementatie van het algoritme kan worden opgedeeld in duidelijke, logische stappen die deze concepten omzetten in een werkende oplossing voor padfinding.
Zo werkt het algoritme, stap voor stap:
function A_Star(start, goal):
// Initialize open and closed lists
openList = [start] // Nodes to be evaluated
closedList = [] // Nodes already evaluated
// Initialize node properties
start.g = 0 // Cost from start to start is 0
start.h = heuristic(start, goal) // Estimate to goal
start.f = start.g + start.h // Total estimated cost
start.parent = null // For path reconstruction
while openList is not empty:
// Get node with lowest f value - implement using a priority queue
// for faster retrieval of the best node
current = node in openList with lowest f value
// Check if we've reached the goal
if current = goal:
return reconstruct_path(current)
// Move current node from open to closed list
remove current from openList
add current to closedList
// Check all neighboring nodes
for each neighbor of current:
if neighbor in closedList:
continue // Skip already evaluated nodes
// Calculate tentative g score
tentative_g = current.g + distance(current, neighbor)
if neighbor not in openList:
add neighbor to openList
else if tentative_g >= neighbor.g:
continue // This path is not better
// This path is the best so far
neighbor.parent = current
neighbor.g = tentative_g
neighbor.h = heuristic(neighbor, goal)
neighbor.f = neighbor.g + neighbor.h
return failure // No path exists
function reconstruct_path(current):
path = []
while current is not null:
add current to beginning of path
current = current.parent
return pathLaten we elk onderdeel van deze implementatie doornemen:
Het algoritme begint met het opzetten van twee essentiële lijsten:
Elk knooppunt slaat vier cruciale stukken informatie op:
De kern van A* is de hoofdlus, die doorgaat totdat ofwel:
Tijdens elke iteratie doet het algoritme het volgende:
Voor elke buur doet het algoritme het volgende:
Zodra het doel is bereikt, werkt het algoritme achteruit via de parent-verwijzingen om het optimale pad van start naar doel te construeren.
Deze systematische aanpak zorgt ervoor dat A* altijd het optimale pad vindt als:
In de volgende sectie vertalen we deze pseudocode naar een praktische Python-implementatie, compleet met visualisaties die je helpen te begrijpen hoe het algoritme de zoekruimte verkent.
Nu we de theorie en pseudocode begrijpen, implementeren we A* in Python. We maken een praktische implementatie die je als basis voor je eigen projecten kunt gebruiken. Om het concreet te maken, implementeren we het algoritme op een 2D-rooster—een veelvoorkomend scenario in games en robotica.
We importeren eerst de benodigde bibliotheken en maken een knooppuntstructuur die positie- en padvindinginformatie voor elk punt in onze zoekruimte opslaat.
from typing import List, Tuple, Dict, Set
import numpy as np
import heapq
from math import sqrt
def create_node(position: Tuple[int, int], g: float = float('inf'),
h: float = 0.0, parent: Dict = None) -> Dict:
"""
Create a node for the A* algorithm.
Args:
position: (x, y) coordinates of the node
g: Cost from start to this node (default: infinity)
h: Estimated cost from this node to goal (default: 0)
parent: Parent node (default: None)
Returns:
Dictionary containing node information
"""
return {
'position': position,
'g': g,
'h': h,
'f': g + h,
'parent': parent
}Om ons padvindingalgoritme te ondersteunen, maken we verschillende helperfuncties. Eerst implementeren we een functie om afstanden tussen punten te berekenen met Euclidische afstand.
Vervolgens voegen we een functie toe om geldige naburige posities in ons rooster te vinden, waarbij we grenzen en obstakels zorgvuldig controleren. Tot slot maken we een functie die ons helpt het pad te reconstrueren zodra we ons doel hebben gevonden.
def calculate_heuristic(pos1: Tuple[int, int], pos2: Tuple[int, int]) -> float:
"""
Calculate the estimated distance between two points using Euclidean distance.
"""
x1, y1 = pos1
x2, y2 = pos2
return sqrt((x2 - x1)**2 + (y2 - y1)**2)
def get_valid_neighbors(grid: np.ndarray, position: Tuple[int, int]) -> List[Tuple[int, int]]:
"""
Get all valid neighboring positions in the grid.
Args:
grid: 2D numpy array where 0 represents walkable cells and 1 represents obstacles
position: Current position (x, y)
Returns:
List of valid neighboring positions
"""
x, y = position
rows, cols = grid.shape
# All possible moves (including diagonals)
possible_moves = [
(x+1, y), (x-1, y), # Right, Left
(x, y+1), (x, y-1), # Up, Down
(x+1, y+1), (x-1, y-1), # Diagonal moves
(x+1, y-1), (x-1, y+1)
]
return [
(nx, ny) for nx, ny in possible_moves
if 0 <= nx < rows and 0 <= ny < cols # Within grid bounds
and grid[nx, ny] == 0 # Not an obstacle
]
def reconstruct_path(goal_node: Dict) -> List[Tuple[int, int]]:
"""
Reconstruct the path from goal to start by following parent pointers.
"""
path = []
current = goal_node
while current is not None:
path.append(current['position'])
current = current['parent']
return path[::-1] # Reverse to get path from start to goalLaten we nu ons algoritme implementeren. We gebruiken een prioriteitswachtrij om ervoor te zorgen dat we altijd eerst de meest veelbelovende paden verkennen.
Ons algoritme houdt twee verzamelingen bij: een open set voor knooppunten die we nog moeten verkennen en een gesloten set voor knooppunten die we al hebben gecontroleerd.
Terwijl we het rooster verkennen, werken we de padkosten continu bij wanneer we betere routes vinden, totdat we ons doel bereiken.
def find_path(grid: np.ndarray, start: Tuple[int, int],
goal: Tuple[int, int]) -> List[Tuple[int, int]]:
"""
Find the optimal path using A* algorithm.
Args:
grid: 2D numpy array (0 = free space, 1 = obstacle)
start: Starting position (x, y)
goal: Goal position (x, y)
Returns:
List of positions representing the optimal path
"""
# Initialize start node
start_node = create_node(
position=start,
g=0,
h=calculate_heuristic(start, goal)
)
# Initialize open and closed sets
open_list = [(start_node['f'], start)] # Priority queue
open_dict = {start: start_node} # For quick node lookup
closed_set = set() # Explored nodes
while open_list:
# Get node with lowest f value
_, current_pos = heapq.heappop(open_list)
current_node = open_dict[current_pos]
# Check if we've reached the goal
if current_pos == goal:
return reconstruct_path(current_node)
closed_set.add(current_pos)
# Explore neighbors
for neighbor_pos in get_valid_neighbors(grid, current_pos):
# Skip if already explored
if neighbor_pos in closed_set:
continue
# Calculate new path cost
tentative_g = current_node['g'] + calculate_heuristic(current_pos, neighbor_pos)
# Create or update neighbor
if neighbor_pos not in open_dict:
neighbor = create_node(
position=neighbor_pos,
g=tentative_g,
h=calculate_heuristic(neighbor_pos, goal),
parent=current_node
)
heapq.heappush(open_list, (neighbor['f'], neighbor_pos))
open_dict[neighbor_pos] = neighbor
elif tentative_g < open_dict[neighbor_pos]['g']:
# Found a better path to the neighbor
neighbor = open_dict[neighbor_pos]
neighbor['g'] = tentative_g
neighbor['f'] = tentative_g + neighbor['h']
neighbor['parent'] = current_node
return [] # No path foundLaten we nu een visualisatiefunctie maken. Deze toont onze roosterindeling met eventuele obstakels, tekent ons berekende optimale pad en markeert duidelijk onze start- en doelposities.
import matplotlib.pyplot as plt
def visualize_path(grid: np.ndarray, path: List[Tuple[int, int]]):
"""
Visualize the grid and found path.
"""
plt.figure(figsize=(10, 10))
plt.imshow(grid, cmap='binary')
if path:
path = np.array(path)
plt.plot(path[:, 1], path[:, 0], 'b-', linewidth=3, label='Path')
plt.plot(path[0, 1], path[0, 0], 'go', markersize=15, label='Start')
plt.plot(path[-1, 1], path[-1, 0], 'ro', markersize=15, label='Goal')
plt.grid(True)
plt.legend(fontsize=12)
plt.title("A* Pathfinding Result")
plt.show()Zo gebruik je de implementatie:
# Create a sample grid
grid = np.zeros((20, 20)) # 20x20 grid, all free space initially
# Add some obstacles
grid[5:15, 10] = 1 # Vertical wall
grid[5, 5:15] = 1 # Horizontal wall
# Define start and goal positions
start_pos = (2, 2)
goal_pos = (18, 18)
# Find the path
path = find_path(grid, start_pos, goal_pos)
if path:
print(f"Path found with {len(path)} steps!")
visualize_path(grid, path)
else:
print("No path found!")Uitvoer
Path found with 22 steps!
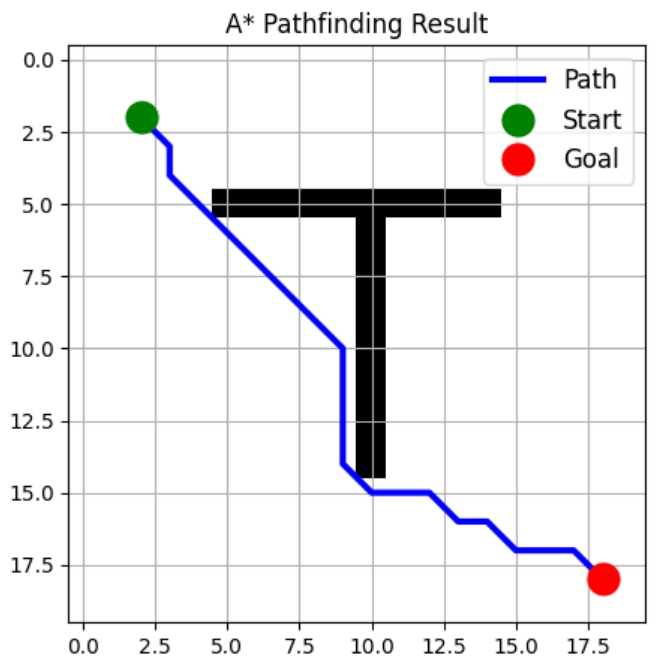
Deze implementatie is zowel efficiënt als uitbreidbaar. Je kunt haar eenvoudig aanpassen om:
In de volgende sectie bekijken we enkele praktische toepassingen van dit algoritme en zien we hoe het in realistische scenario's wordt gebruikt.
De efficiëntie en flexibiliteit van A* maken het waardevol in talloze domeinen. Dit zijn de belangrijkste gebieden waarin het uitblinkt:
Het A*-zoekalgoritme wordt veel gebruikt in gameontwikkeling vanwege zijn optimale padvinding. Het verbetert de spelerservaring door realistischer en responsiever beweging van personages mogelijk te maken.
A* wordt veel gebruikt in navigatiesystemen om routes te optimaliseren, rekening houdend met factoren zoals afstand en mogelijke obstakels.
Het A*-algoritme is cruciaal voor robotica, waar efficiënte beweging essentieel is voor productiviteit en veiligheid.
A* wordt ook toegepast bij het optimaliseren van netwerkoperaties, waar efficiënt gebruik van middelen en routering van het grootste belang zijn.
Wat A* bijzonder waardevol maakt, is de aanpasbaarheid via aangepaste heuristische functies, waardoor je kunt optimaliseren voor verschillende metrieken zoals afstand, tijd of energieverbruik.
In de volgende sectie bekijken we enkele veelvoorkomende uitdagingen en optimalisatietechnieken om A* effectief te implementeren.
Hoewel A* krachtig is, vereist een effectieve implementatie dat je een aantal veelvoorkomende uitdagingen aanpakt. Het grootste struikelblok voor ontwikkelaars is het efficiënt omgaan met middelen, vooral bij grote zoekruimtes.
De belangrijkste uitdagingen zijn onder andere:
Gelukkig zijn er verschillende effectieve optimalisatiestrategieën om deze uitdagingen aan te pakken:
Wanneer prestaties cruciaal zijn, overweeg dan deze snelheidsverbeteringen:
Een bijzonder effectieve aanpak voor grote ruimtes is bilaterale zoektocht—tegelijkertijd zoeken vanaf het start- en doelpunt. Daarnaast kun je bij padvinding op roosters de prestaties aanzienlijk verbeteren door heuristische waarden vooraf te berekenen of gebruik te maken van lookuptabellen.
Kies optimalisatietechnieken op basis van jouw specifieke eisen en beperkingen. Het draait om de juiste balans tussen geheugengebruik en rekensnelheid voor jouw toepassing.
Het A*-algoritme is een fundamenteel hulpmiddel bij padvinding en het doorlopen van grafen. In deze gids hebben we de kernconcepten gezien, een praktische oplossing in Python geïmplementeerd en de diverse toepassingsgebieden onderzocht. De kracht van het algoritme ligt in de balans tussen nauwkeurigheid en efficiëntie, waardoor het van onschatbare waarde is in uiteenlopende domeinen, van gaming tot robotica.
Hoewel de implementatie van A* uitdagingen met zich meebrengt, kunnen de besproken optimalisatietechnieken je helpen efficiënte oplossingen te bouwen. Werk je aan games, plan je robotpaden of los je routeringsproblemen op, dan biedt inzicht in het A*-algoritme een krachtige aanpak om optimale paden in je toepassingen te vinden
Het bouwen van zulke geavanceerde algoritmen vereist een stevige basis in Python-programmeerconcepten en best practices. Wil je je Python-basis versterken en complexere algoritmen zoals A* aanpakken?
Til je programmeervaardigheden naar een hoger niveau met onze Intermediate Python for Developers Course-cursus, waarin je maatwerkfuncties onder de knie krijgt, essentiële modules verkent en geavanceerde applicaties bouwt.
Topcursussen op DataCamp
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
