
Cursus
Machine Learning met boomgebaseerde modellen in Python
5 Hr
117.3K
Laatst kreeg ik een sms van mijn bank:
“We hebben je kaart tijdelijk geblokkeerd. Is de transactie voor [bedrag] bij [verkoper] van jou?”
Gelukkig was ik het gewoon zelf, online shoppen op een onzalig tijdstip. Maar het zette me wel aan het denken… hoe markeert de bank verdachte transacties tussen de honderdduizenden die ze dagelijks verwerkt?
Fraude herkennen is een specifiek geval van een breder probleem in machine learning (ML), namelijk anomaliedetectie. Er zijn veel methoden om dit op te lossen, maar in deze blog focussen we op een van de populairste: Isolation Forests.
Fraude bestrijden, netwerken verdedigen, uitschieters vinden en defecte apparatuur signaleren lijken misschien verschillende problemen. Toch delen ze een kenmerk: er zijn geen duidelijke labels of definities van wat een anomalie is. In veel gevallen zijn anomalieën zeldzaam en subtiel, waardoor ze lastig te herkennen zijn tussen grote hoeveelheden normale data.
Eén manier om systemen voor anomaliedetectie te ontwikkelen is met predictive ML. Zo zouden we frauduleuze transacties kunnen verzamelen. Met kenmerken zoals transactiebedrag, tijd, locatie en type winkelier bouwen we dan een model dat deze onderscheidt van normale transacties. Het probleem is dat we met deze aanpak alleen fraude detecteren die lijkt op gevallen die we eerder hebben gezien.
Fraudeurs veranderen vaak hun strategie en proberen nieuwe manieren van fraude. Veel van die strategieën zijn totaal onverwacht. Daarom worden unsupervised methoden vaak gebruikt om anomalieën te detecteren. Die werken door alle transacties te vergelijken en exemplaren te identificeren met ongewone featurewaarden. Belangrijk: we hoeven transacties vooraf niet te labelen.
Fraude is niet het enige gedrag dat lastig te classificeren is. In de industrie kunnen machines op elk moment op onverwachte manieren falen. In cybersecurity worden voortdurend nieuwe aanvallen ontdekt en gepatcht. In de geneeskunde kunnen zeldzame aandoeningen schuilgaan tussen talloze testresultaten. Toepassingen zijn eindeloos, dus laten we bekijken hoe één unsupervised aanpak werkt om deze anomalieën te detecteren.
Zoals de naam al doet vermoeden, zijn Isolation Forests een boomgebaseerde methode. Ze lijken op Random Forests, maar de bouwstenen zijn anders.
Een Random Forest gebruikt beslisbomen met splits op basis van gini-onzuiverheid. Daarvoor is een targetvariabele nodig. Isolation Forests gebruiken in plaats daarvan Isolation Trees. De methode gebruikt een verzameling van deze bomen om anomaliescores voor elke instantie te berekenen.
Het is de moeite waard om te begrijpen hoe deze bouwsteen werkt voordat we anomaliescores berekenen. Stel, we proberen frauduleuze transacties te detecteren. Om het simpel te houden evalueren we 1000 transacties (instantie) en bekijken we twee variabelen uit onze dataset: het bedrag (x1) en tijdstip (x2) van een transactie.
Om een Isolation Tree te maken beginnen we met alle of een steekproef van instanties in de wortelnode. In Figuur 1 hieronder zie je dat we een steekproef van 256 instanties hebben (later meer over dat getal).
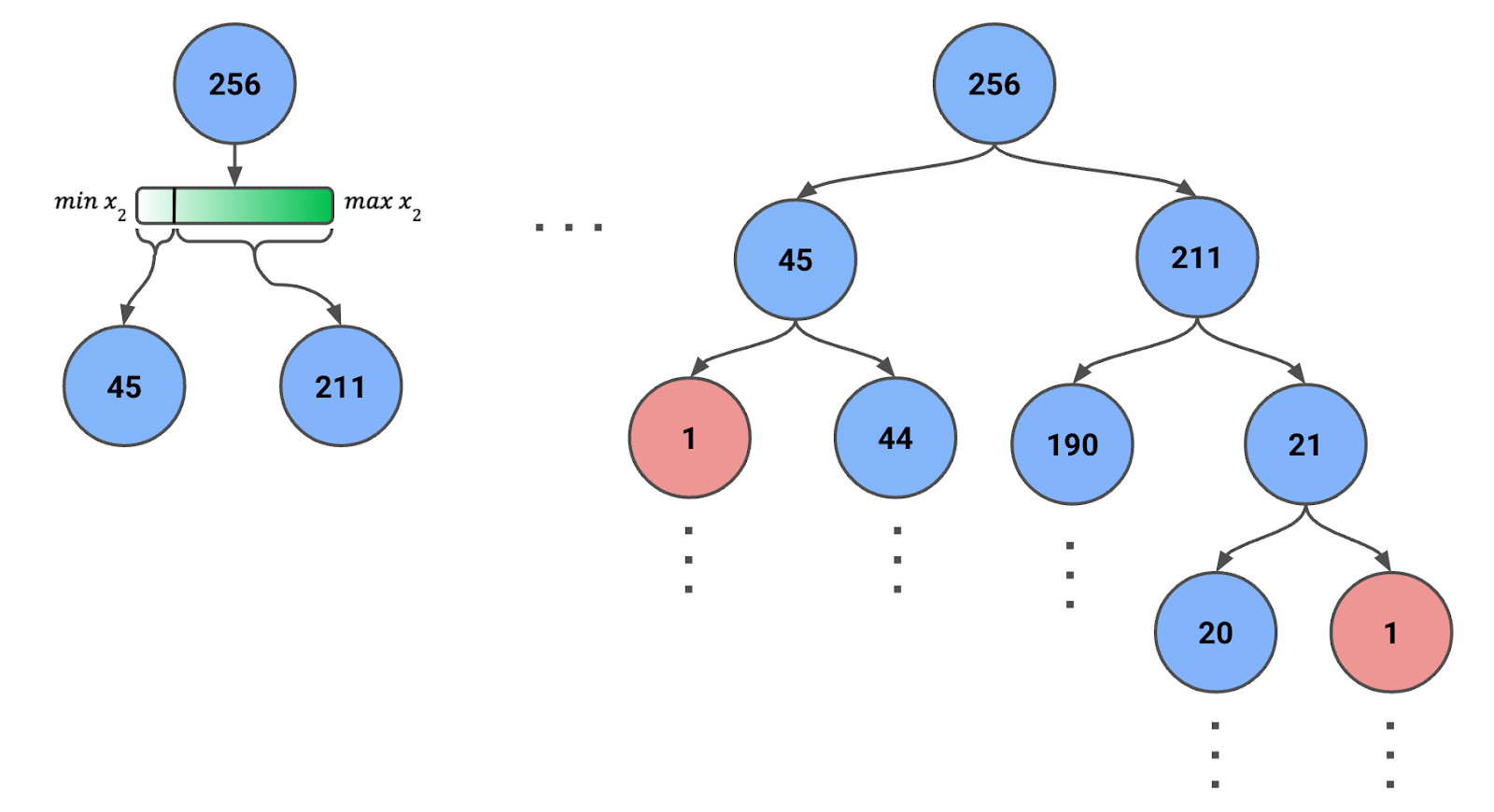
Figuur 1: Isolation Tree gemaakt met recursieve willekeurige splits. Het aantal instanties in elke node is aangegeven.
Vervolgens:
Let op dat het bereik van de feature bij elke stap verandert. We gebruiken dus de minimum- en maximumwaarden van de feature voor de instanties in de node. Deze dynamische aanpassing zorgt voor zinvolle splits en voorkomt dat nodes zonder instanties eindigen.
Figuur 2 hieronder geeft intuïtie waarom dit proces uitschieters isoleert. De instanties A, B, en C wijken af van de andere transacties.
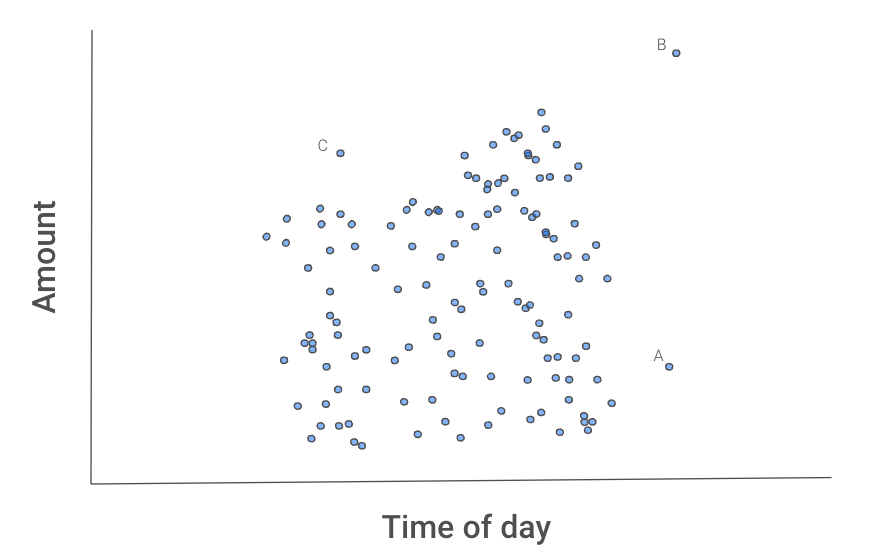
Figuur 2: Spreidingsdiagram van transacties
Waarschijnlijk wordt B als eerste geïsoleerd, omdat die met één splits op een van beide features van de rest te scheiden is.
A zou één splits op x2 nodig hebben.
C kan langer duren, omdat je die met beide features moet isoleren. C heeft namelijk zowel een normaal bedrag als een normaal tijdstip, maar geen normaal bedrag voor dat tijdstip.
Misschien hebben we geluk en isoleren we een van deze instanties in één keer. Waarschijnlijker is dat het een paar pogingen kost. Het belangrijkste punt is dat gemiddeld B minder splits nodig heeft dan A, A minder dan C, en dat alle drie minder splits nodig hebben dan de overige transacties. Maar hoe vangen we dit gemiddelde gedrag?
Het aantal splits dat nodig is om een anomalie te isoleren bepaalt de padlengte naar de bladnode van de instantie. Als een bos van Isolation Trees consequent kortere paden oplevert voor bepaalde samples, zijn die samples waarschijnlijk anomalieën. We leggen dit gemiddelde gedrag vast door de padlengtes over alle bomen te aggregeren: het berekenen van een anomaliescore.
Om voor een instantie x een anomaliescore te berekenen, moeten we eerst een paar waarden definiëren:
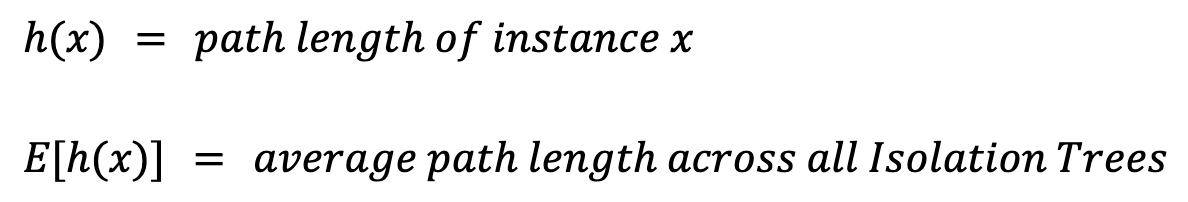
De padlengte, h(x), is het aantal randen (splits) dat je moet passeren om de bladnode van de instantie te bereiken. Simpelweg het gemiddelde E[h(x)] nemen, geeft problemen. Grotere bomen met meer instanties hebben namelijk langere paden, ook voor anomalieën. Om hiervoor te corrigeren, hebben we een normalisatiewaarde nodig op basis van de steekproefgrootte n:
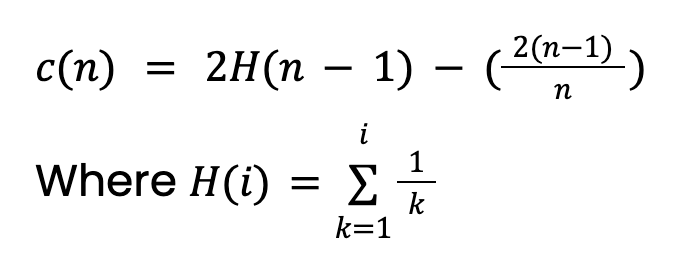
Deze waarde komt uit de theorie van binaire zoekbomen (BST). Ze geeft de gemiddelde padlengte van onsuccesvolle zoekopdrachten in BST. Omdat Isolation Trees qua structuur gelijkwaardig zijn aan BST’s, nemen we c(n) als de verwachte padlengte voor een instantie (anomalie of niet). Let op: deze waarde moet worden aangepast als we een maximale boomdiepte instellen.
Tot slot kunnen we onze anomaliescore s(x,n) berekenen:
 De score ligt tussen 0 en 1. Bij de interpretatie onderscheiden we drie scenario’s:
De score ligt tussen 0 en 1. Bij de interpretatie onderscheiden we drie scenario’s:
Met andere woorden: als de gemiddelde padlengte van een instantie korter is dan de verwachte gemiddelde padlengte, ligt de anomaliescore dichter bij 1. Maar zoals we bij de implementatie zullen zien, past het Scikit-learn-pakket de score verder aan.
Laten we de implementatie stap voor stap aanpakken en beginnen met de imports.
We gebruiken standaard Python-pakketten voor datahandling en visualisatie (regels 2-5). We gebruiken ook de Scikit-learn-implementatie van Isolation Forest (regel 7) en met het laatste pakket importeren we onze dataset (regel 8).
# Imports
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import IsolationForest
from ucimlrepo import fetch_ucirepoWe laden onze data rechtstreeks uit de UCI machine learning repository. We gebruiken de Air Quality-dataset (CC BY 4.0), met 9.358 metingen van de luchtkwaliteit door een sensor in een Italiaanse stad. In de context van deze dataset kun je een anomalie zien als een sensorwaarde die uitzonderlijk hoge vervuilingsniveaus aangeeft.
# Fetch dataset from UCI repository
air_quality = fetch_ucirepo(id=360)We doen wat opschoning voordat we het model toepassen. We beginnen met het selecteren van alle features uit de dataset (regel 2) en kiezen daarna een subset van 4 features (regel 5). Dit zijn metingen van verschillende metaaloxide-chemische stoffen in de lucht (dus vervuilende stoffen). Vervolgens verwijderen we rijen met missende waarden (regels 8-9). Uiteindelijk houden we 6.941 instanties over en hieronder zie je een snapshot van de featureset.
# Convert to DataFrame
data = air_quality.data.features
# Select features
features = data[['CO(GT)', 'C6H6(GT)', 'NOx(GT)', 'NO2(GT)']]
# Drop rows with missing values (-200)
features = features.replace(-200, np.nan)
features = features.dropna()
print(features.shape)
features.head()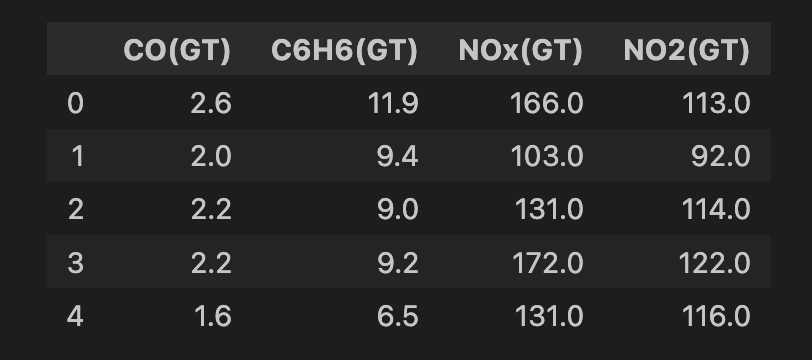
Als laatste definiëren we de parameters voor het trainen van het Isolation Forest. In dit geval gebruiken we de drie waarden hieronder:
n_estimators is het aantal Isolation Trees in het ensemble. Een waarde van 100 wordt gebruikt in het Isolation Forest-paper. Door experimenten zagen de onderzoekers dat dit goede resultaten gaf op verschillende datasets. contamination is het percentage datapunten waarvan we verwachten dat het anomalieën zijn. sample_size is het aantal instanties dat wordt gebruikt om elke Isolation Tree te trainen. Een waarde van 256 is gangbaar, omdat we dan geen maximale boomgrootte als stopcriterium hoeven te gebruiken. We kunnen immers redelijke maximale boomdieptes verwachten van log(256) = 8.De contaminatiewaarde heeft geen harde onderbouwing zoals de andere waarden. Ze kan komen uit eerdere ervaring. Stel dat we in een eerdere analyse 1% van de metingen als hoge vervuiling zagen. Ze kan ook voortkomen uit resourcebeperkingen. Bijv. bij het analyseren van frauduleuze transacties heb je misschien alleen tijd om 5% van alle transacties nader te bekijken. Bij het visualiseren van de anomaliescores zien we hoe ze met deze contaminatiewaarde worden aangepast.
# Parameters
n_estimators = 100 # Number of trees
contamination = 0.01 # Expected proportion of anomalies
sample_size = 256 # Number of samples used to train each treeNu kunnen we het Isolation Forest trainen. Als je Sklearn kent, ziet dit proces er bekend uit. We initialiseren het model met de bovenstaande parameters (regels 2-5). Daarna trainen we het model op onze featureset (regel 6).
# Train Isolation Forest
iso_forest = IsolationForest(n_estimators=n_estimators,
contamination=contamination,
max_samples=sample_size,
random_state=42)
iso_forest.fit(features)Het getrainde model heeft twee handige functies:
decision_function berekent de anomaliescore op een vergelijkbare manier als in de theoriekant besproken. predict geeft een binaire label op basis van de contaminatiewaarde. In ons geval krijgen de 1% instanties met de slechtste anomaliescores de waarde -1. De overige instanties krijgen 1.We voegen de output van deze functies toe aan onze dataset (regels 2-4). Als we de anomaliewaarden tellen (regel 6), zien we dat 70 instanties als anomalie zijn gelabeld.
# Calculate anomaly scores and classify anomalies
data = data.loc[features.index].copy()
data['anomaly_score'] = iso_forest.decision_function(features)
data['anomaly'] = iso_forest.predict(features)
data['anomaly'].value_counts()We kunnen nog een stap verder gaan en alle anomaliescores visualiseren. Dat doen we met onderstaande code:
# Visualization of the results
plt.figure(figsize=(10, 5))
# Plot normal instances
normal = data[data['anomaly'] == 1]
plt.scatter(normal.index, normal['anomaly_score'], label='Normal')
# Plot anomalies
anomalies = data[data['anomaly'] == -1]
plt.scatter(anomalies.index, anomalies['anomaly_score'], label='Anomaly')
plt.xlabel("Instance")
plt.ylabel("Anomaly Score")
plt.legend()
plt.show()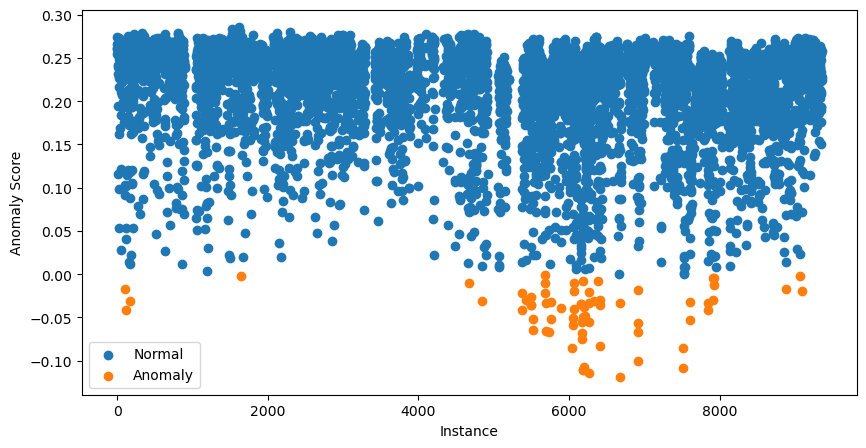
De 70 instanties met de laagste anomaliescores zijn oranje weergegeven. Dit zijn onze potentiële anomalieën; de volgende stap is om ze verder te onderzoeken.
Op dit punt denk je misschien: zeiden we niet dat scores dicht bij 1 op potentiële anomalieën wijzen?
De scores in het bovenstaande spreidingsdiagram zijn aangepast. Het pakket berekent eerst een offset: de percentielwaarde van de anomaliescore op basis van de contaminatiewaarde. In ons geval is de offset het 0,99-percentiel. De uiteindelijke scores zijn dan offset - score. Hierdoor duiden alle scores onder 0 op potentiële anomalieën.
Met het spreidingsdiagram hierboven kunnen we potentiële anomalieën aanwijzen. Maar daarmee weten we nog niet waarom ze als anomalie zijn geclassificeerd. Daarvoor is vervolgonderzoek nodig.
In de onderstaande code maken we bijvoorbeeld een spreidingsdiagram van alle instanties door hun CO(GT)-waarde uit te zetten tegen hun NO2(GT)-waarde. We kleuren de punten ook op basis van de classificatie als anomalie.
# Visualization of the results
plt.figure(figsize=(5, 5))
# Plot non-anomalies then anomalies
plt.scatter(normal['CO(GT)'], normal['NO2(GT)'], label='Normal')
plt.scatter(anomalies['CO(GT)'], anomalies['NO2(GT)'], label='Anomaly')
plt.xlabel("CO(GT)")
plt.ylabel("NO2(GT)")
plt.legend()
plt.show()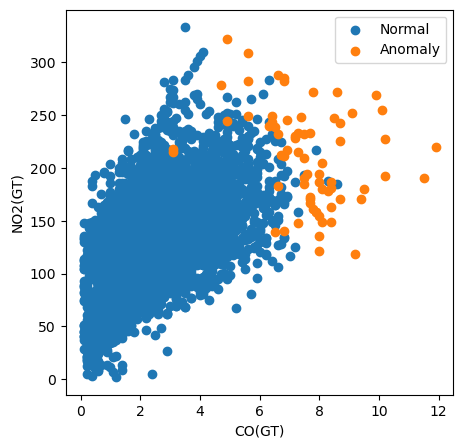
Met deze visualisatie zien we dat de CO(GT)-meting bijzonder belangrijk is. Veel anomalieën hebben voor deze feature een waarde boven 6. Dit verklaart echter niet alle anomalieën. Sommige hebben hoge waarden voor beide features en andere lijken in deze plot niet door een van de features anomalisch te zijn. Dit suggereert dat ook andere vervuilende stoffen aan de classificatie hebben bijgedragen.
Dit brengt ons bij de belangrijkste voordelen van Isolation Forests ten opzichte van andere methoden voor anomaliedetectie. Ten eerste kunnen ze omgaan met hoog-dimensionale data. Zoals we zagen, kunnen instanties als anomalie worden aangemerkt op basis van alle features, en de methode werkt ook goed met veel meer dan vier features. Een ander belangrijk voordeel is dat ze verschillende typen anomalieën kunnen vinden.
Ter vergelijking: een eenvoudige methode is de z-score. Die classificeert per feature anomalieën op basis van de afstand van de featurewaarde tot het gemiddelde. Maar dat is maar één type anomalie. Deze benadering veronderstelt ook dat features normaal verdeeld zijn en vereist dat we voor elke feature de z-scores beoordelen.
Bij Isolation Forests maken we geen aanname over de verdeling van een feature. Daardoor kunnen we instanties vinden die om andere redenen dan afstand tot het gemiddelde anomalisch zijn. Zoals we zagen, kunnen we bovendien tegelijk alle features gebruiken. Dat kan onze analyse sterk vereenvoudigen, zeker bij grote datasets.
Andere overwegingen zijn dat Isolation Forest een lineaire tijdcomplexiteit heeft en unsupervised is. Dat maakt het ideaal om zonder voorkennis anomalieën te detecteren in grote datasets. Dat is vaak het geval in toepassingen als fraudedetectie, waar voortdurend nieuwe fraudevormen ontstaan tussen een zee van normale transacties.
Een belangrijke beperking van Isolation Forest is dat het mogelijk minder goed presteert bij kleine datasets. Dit heeft te maken met het willekeurige proces waarmee de Isolation Trees worden gemaakt. Er is altijd een kans dat normale instanties korte paden hebben of dat anomalieën juist lange paden hebben. Bij kleine datasets is die kans groter. Met andere woorden: Isolation Forests hebben voldoende data nodig om de willekeur gemiddeld te compenseren.
Een andere beperking, zoals we zagen, is dat Isolation Forest alleen potentiële anomalieën kan identificeren. Het vertelt ons niets over het waarom. Daarvoor is extra analyse nodig. Het voordeel van complexe anomalieën herkennen, wordt zo een uitdaging. Uiteindelijk kan het veel werk en domeinkennis kosten om een anomalie volledig te verklaren.
We hebben Isolation Forest verkend, een krachtig hulpmiddel voor anomaliedetectie in uiteenlopende domeinen. We zagen hoe de unieke aanpak—anomalieën isoleren via willekeurige partitionering—voordelen biedt boven traditionele methoden: omgaan met hoog-dimensionale data, complexe anomaliepatronen herkennen en schaalbaarheid.
Het praktische voorbeeld met Python en Scikit-learn liet zien hoe eenvoudig het in gebruik is.
Hoewel Isolation Forest effectief potentiële anomalieën kan vinden zonder voorkennis, zijn er ook beperkingen, met name bij kleinere datasets en het onvermogen om uit te leggen waarom specifieke instanties als anomalie gelden.
Topcursussen Machine Learning!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
