
Courses
Machine Learning với mô hình dựa trên cây trong Python
5 giờ
117.2K
Gần đây tôi nhận được một tin nhắn từ ngân hàng:
“Chúng tôi đã tạm khóa thẻ của bạn. Giao dịch [số tiền] tại [nhà cung cấp] có phải của bạn không?”
May mắn là đó chỉ là tôi mua sắm online vào một giờ giấc không hợp lý, nhưng điều đó khiến tôi tự hỏi… làm sao ngân hàng gắn cờ các giao dịch đáng ngờ giữa hàng trăm nghìn giao dịch họ xử lý mỗi ngày?
Nhận diện gian lận là một trường hợp cụ thể của một vấn đề rộng hơn trong máy học (ML) gọi là phát hiện bất thường. Dù có nhiều phương pháp để giải quyết vấn đề này, trong bài viết này, chúng ta sẽ tập trung vào một trong những cách phổ biến nhất: Isolation Forests.
Chống gian lận, bảo vệ mạng, tìm điểm ngoại lai và gắn cờ thiết bị lỗi có thể trông như những vấn đề khác nhau. Tuy nhiên, chúng có một đặc điểm chung — không có nhãn hay định nghĩa rõ ràng về điều gì cấu thành một bất thường. Nhiều trường hợp, bất thường hiếm và tinh vi, khiến chúng khó bị phát hiện giữa một lượng lớn dữ liệu bình thường.
Một cách để xây dựng hệ thống phát hiện bất thường là dùng ML dự đoán . Ví dụ, ta có thể thu thập các giao dịch gian lận. Sau đó, dùng các đặc trưng như số tiền, thời gian, địa điểm và loại nhà bán, ta xây dựng một mô hình phân biệt chúng với giao dịch bình thường. Vấn đề là cách tiếp cận này chỉ cho phép phát hiện các vụ gian lận tương tự những gì ta đã thấy trước đây.
Kẻ gian thường thay đổi chiến lược và thử những cách mới để thực hiện gian lận. Nhiều chiến lược sẽ hoàn toàn bất ngờ. Đây là lý do tại sao các phương pháp không giám sát thường được dùng để phát hiện bất thường. Chúng hoạt động bằng cách so sánh tất cả giao dịch và xác định các giao dịch có giá trị đặc trưng bất thường. Quan trọng là ta không cần gán nhãn trước cho bất kỳ giao dịch nào.
Gian lận không phải hành vi duy nhất khó phân loại. Trong sản xuất, máy móc có thể hỏng bất cứ lúc nào theo nhiều cách không ngờ. Trong an ninh mạng, các kiểu tấn công mới liên tục được phát hiện và vá. Trong y học, các vấn đề sức khỏe hiếm gặp có thể ẩn giữa nhiều kết quả xét nghiệm. Ứng dụng là vô tận, vậy hãy xem một cách tiếp cận không giám sát để phát hiện các bất thường này hoạt động thế nào.
Nếu bạn chưa đoán ra từ tên gọi, Isolation Forests là một phương pháp dựa trên cây. Chúng giống với Random Forest, nhưng các khối xây dựng cơ bản thì khác.
Random Forest dùng cây quyết định với các phép chia dựa trên độ hỗn tạp Gini. Điều này cần biến mục tiêu, vì vậy Isolation Forest dùng Isolation Tree. Phương pháp sử dụng một tập hợp các cây này để tính điểm bất thường cho từng quan sát.
Đáng để hiểu cách khối xây dựng cơ bản này hoạt động trước khi tính điểm bất thường. Giả sử ta đang cố phát hiện giao dịch gian lận. Để đơn giản, ta đánh giá 1000 giao dịch (quan sát) và xét hai biến từ tập dữ liệu: số tiền (x1) và thời điểm trong ngày (x2) của giao dịch.
Để tạo một Isolation Tree, ta bắt đầu với tất cả hoặc một mẫu các quan sát trong nút gốc. Trong Hình 1 bên dưới, bạn có thể thấy ta có một mẫu gồm 256 quan sát (sẽ nói thêm về con số này sau).
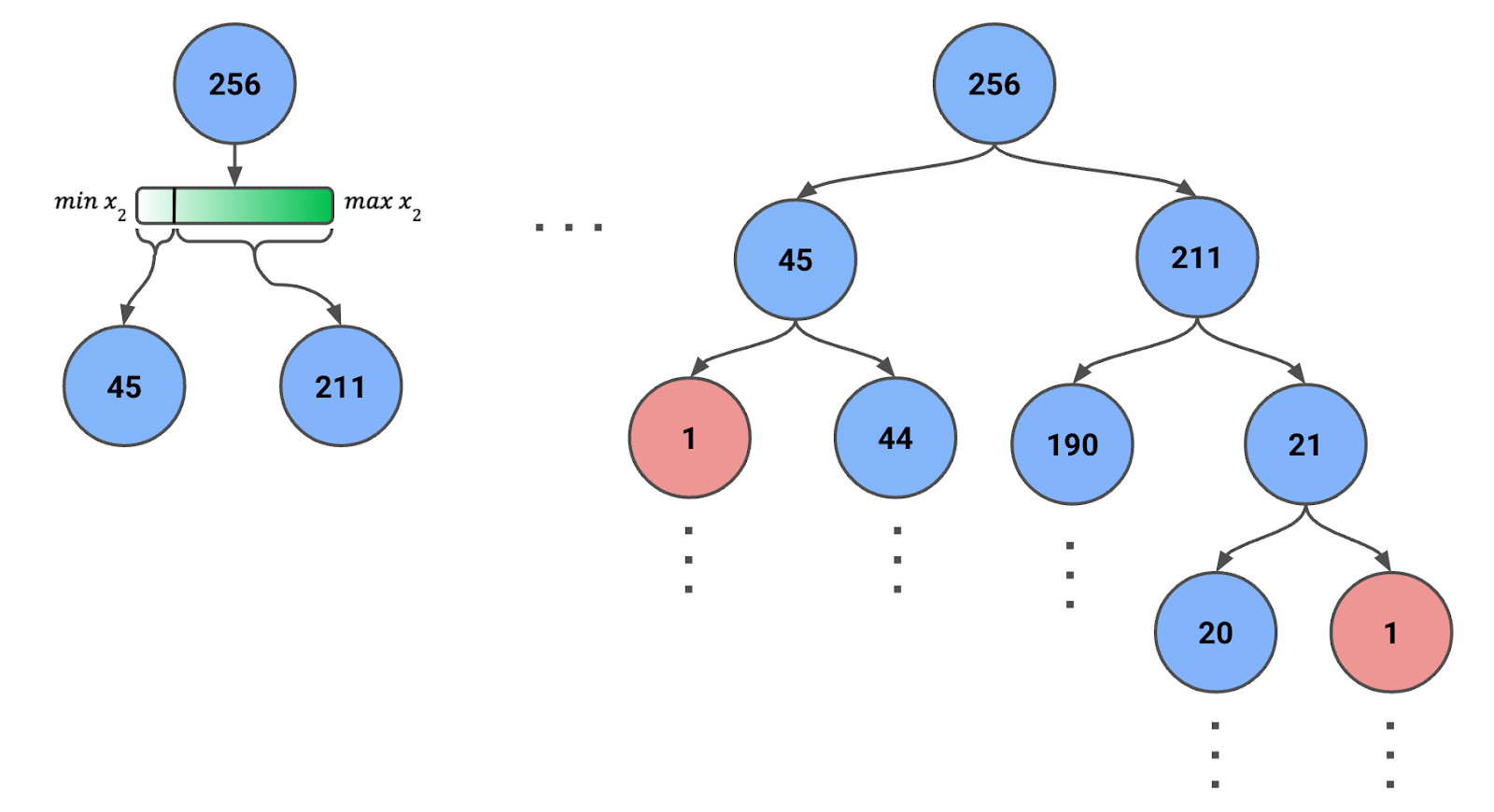
Hình 1: Isolation Tree được tạo bằng các phép chia ngẫu nhiên đệ quy. Số lượng quan sát trong mỗi nút được hiển thị.
Sau đó, ta:
Lưu ý rằng phạm vi của đặc trưng sẽ thay đổi ở mỗi bước. Tức là, ta dùng giá trị nhỏ nhất và lớn nhất của đặc trưng đối với các quan sát trong nút. Sự điều chỉnh động này đảm bảo các phép chia có ý nghĩa và các nút không rơi vào tình trạng không có quan sát nào.
Hình 2 bên dưới cho ta trực giác về lý do quy trình này cô lập các điểm ngoại lai. Các quan sát A, B, và C có vẻ khác biệt so với các giao dịch còn lại.
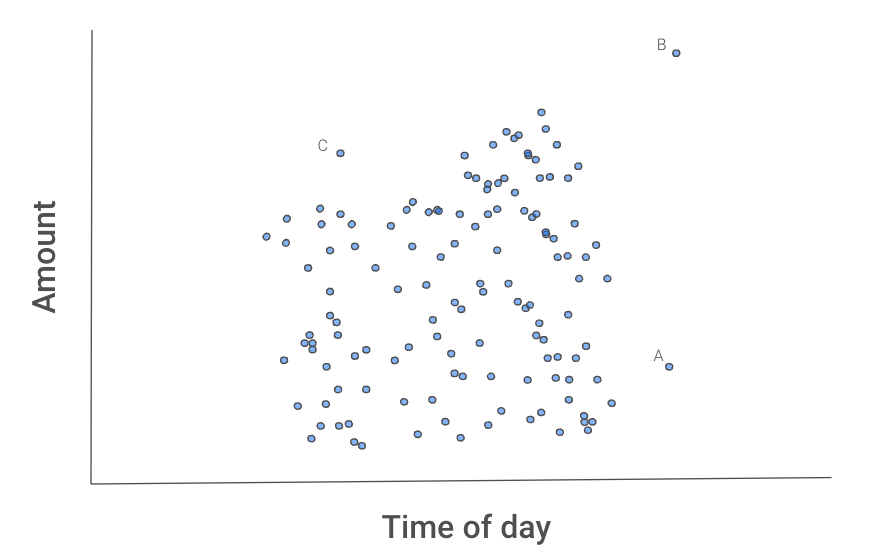
Hình 2: Biểu đồ phân tán các giao dịch
B nhiều khả năng sẽ được cô lập đầu tiên vì có thể tách khỏi các giao dịch khác chỉ bằng một phép chia theo một trong hai đặc trưng.
A sẽ cần một phép chia theo x2.
C có thể mất nhiều thời gian hơn vì cần cô lập nó bằng cả hai đặc trưng. Tức là, C có cả số tiền và thời gian đều bình thường nhưng không bình thường so với khoảng thời gian đó trong ngày.
Ta có thể may mắn cô lập một trong các quan sát này ngay lần đầu. Khả năng cao là sẽ cần vài lần thử. Điểm quan trọng là, trung bình, B sẽ cần ít phép chia hơn A, A ít hơn C, và cả ba điểm sẽ cần ít phép chia hơn các giao dịch còn lại. Nhưng làm sao ta nắm bắt được hành vi trung bình này?
Số phép chia cần để cô lập một bất thường quyết định độ dài đường đi đến nút lá của quan sát đó. Khi một rừng Isolation Tree liên tục cho độ dài đường đi ngắn hơn đối với các mẫu cụ thể, các mẫu đó có khả năng là bất thường. Ta nắm bắt hành vi trung bình này bằng cách tổng hợp độ dài đường đi qua tất cả các cây, quá trình này được gọi là tính điểm bất thường.
Để tính điểm bất thường cho một quan sát x, trước tiên ta cần định nghĩa vài giá trị:
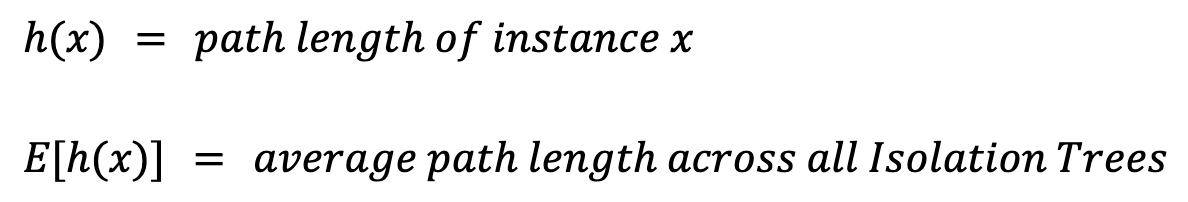
Độ dài đường đi, h(x), là số cạnh (phép chia) cần đi qua để đến nút lá của quan sát. Chỉ đơn giản lấy trung bình, E[h(x)], sẽ gây ra vấn đề. Bởi vì cây lớn hơn với nhiều quan sát hơn có xu hướng có độ dài đường đi lớn hơn, ngay cả với bất thường. Để tính đến điều này, ta cần một giá trị chuẩn hóa dựa trên kích thước mẫu n:
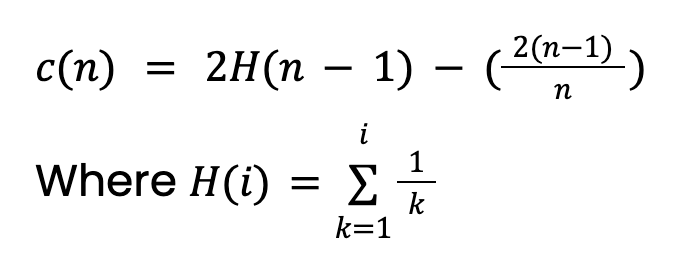
Giá trị này đến từ lý thuyết về Cây Tìm kiếm Nhị phân (BST). Nó cho độ dài đường đi trung bình của các lần tìm kiếm không thành công trong BST. Vì Isolation Tree có cấu trúc tương đương BST, ta lấy c(n) làm độ dài đường đi kỳ vọng cho một quan sát (dù có phải bất thường hay không). Lưu ý giá trị này cần được điều chỉnh nếu ta đặt độ sâu tối đa cho cây.
Cuối cùng, ta có thể tính điểm bất thường s(x,n):
 Điểm nằm trong khoảng từ 0 đến 1, và khi diễn giải, ta nên cân nhắc ba kịch bản:
Điểm nằm trong khoảng từ 0 đến 1, và khi diễn giải, ta nên cân nhắc ba kịch bản:
Nói cách khác, khi độ dài đường đi trung bình của một quan sát ngắn hơn độ dài đường đi trung bình kỳ vọng, điểm bất thường sẽ gần 1 hơn. Tuy nhiên, như ta sẽ thấy khi triển khai phương pháp, gói Scikit-learn có điều chỉnh thêm đối với điểm số.
Hãy tiếp cận phần triển khai từng bước và bắt đầu với các import.
Ta dùng các gói Python tiêu chuẩn để xử lý dữ liệu và trực quan hóa (dòng 2–5). Ta cũng dùng bản triển khai Isolation Forest trong Scikit-learn (dòng 7) và gói cuối để nhập tập dữ liệu (dòng 8).
# Imports
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import IsolationForest
from ucimlrepo import fetch_ucirepoTa tải dữ liệu trực tiếp từ kho lưu trữ máy học UCI. Ta dùng tập dữ liệu Air Quality (CC BY 4.0), chứa 9.358 quan sát về đo chất lượng không khí từ một cảm biến ở một thành phố của Ý. Trong bối cảnh này, một bất thường có thể là một lần đọc cảm biến cho thấy mức độ ô nhiễm bất thường cao.
# Fetch dataset from UCI repository
air_quality = fetch_ucirepo(id=360)Ta làm sạch dữ liệu trước khi áp dụng mô hình. Bắt đầu bằng cách chọn tất cả đặc trưng từ tập dữ liệu (dòng 2) rồi chọn một tập con gồm 4 đặc trưng (dòng 5). Đây đều là các phép đo các hóa chất oxit kim loại trong không khí (tức chất ô nhiễm). Sau đó loại bỏ các hàng có giá trị thiếu (dòng 8–9). Cuối cùng, ta còn 6.941 quan sát và bạn có thể xem ảnh chụp nhanh bộ đặc trưng bên dưới.
# Convert to DataFrame
data = air_quality.data.features
# Select features
features = data[['CO(GT)', 'C6H6(GT)', 'NOx(GT)', 'NO2(GT)']]
# Drop rows with missing values (-200)
features = features.replace(-200, np.nan)
features = features.dropna()
print(features.shape)
features.head()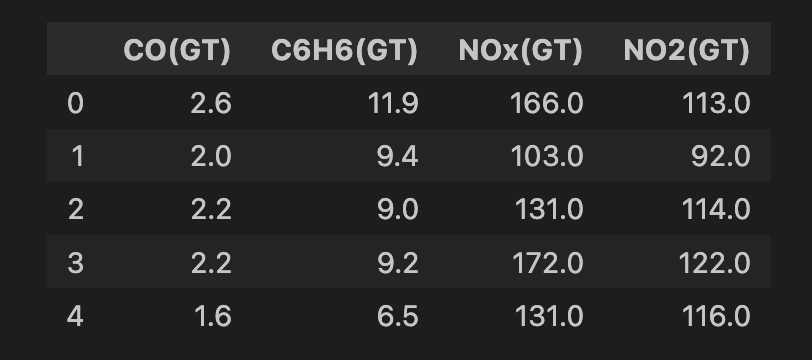
Cuối cùng là định nghĩa các tham số dùng để huấn luyện Isolation Forest. Ở đây, ta dùng ba giá trị dưới đây:
n_estimators là số lượng Isolation Tree dùng trong mô hình tổ hợp. Giá trị 100 được dùng trong bài báo Isolation Forest. Qua thực nghiệm, các nhà nghiên cứu thấy giá trị này cho kết quả tốt trên nhiều tập dữ liệu. contamination là tỷ lệ phần trăm điểm dữ liệu ta kỳ vọng là bất thường. sample_size là số quan sát dùng để huấn luyện mỗi Isolation Tree. Giá trị 256 thường được dùng vì giúp ta tránh phải đặt tiêu chí dừng theo kích thước cây tối đa. Bởi ta có thể kỳ vọng kích thước cây tối đa hợp lý là log(256) = 8.Giá trị contamination không có cơ sở vững như các giá trị còn lại. Nó có thể đến từ kinh nghiệm trước đó. Giả sử trong phân tích trước, ta thấy 1% lần đọc cho thấy mức ô nhiễm cao. Nó cũng có thể đến từ ràng buộc nguồn lực. Ví dụ, khi phân tích giao dịch gian lận, bạn chỉ có đủ thời gian để phân tích sâu 5% tổng số giao dịch. Khi trực quan hóa điểm bất thường, ta sẽ thấy chúng được điều chỉnh theo giá trị contamination này.
# Parameters
n_estimators = 100 # Number of trees
contamination = 0.01 # Expected proportion of anomalies
sample_size = 256 # Number of samples used to train each treeCuối cùng, ta có thể huấn luyện Isolation Forest. Nếu bạn quen với Sklearn, quy trình này sẽ quen thuộc. Ta khởi tạo mô hình với các tham số đã bàn ở trên (dòng 2–5). Sau đó huấn luyện mô hình trên bộ đặc trưng (dòng 6).
# Train Isolation Forest
iso_forest = IsolationForest(n_estimators=n_estimators,
contamination=contamination,
max_samples=sample_size,
random_state=42)
iso_forest.fit(features)Mô hình đã huấn luyện có hai hàm hữu ích:
decision_function sẽ tính điểm bất thường theo cách tương tự phần lý thuyết đã thảo luận. predict sẽ trả về nhãn nhị phân dựa trên giá trị contamination. Trong trường hợp của ta, 1% quan sát có điểm bất thường tệ nhất sẽ nhận giá trị -1. Các quan sát còn lại nhận giá trị 1.Ta thêm đầu ra của các hàm này vào tập dữ liệu (dòng 2–4). Khi đếm các giá trị bất thường (dòng 6) ta thấy 70 quan sát được gán nhãn bất thường.
# Calculate anomaly scores and classify anomalies
data = data.loc[features.index].copy()
data['anomaly_score'] = iso_forest.decision_function(features)
data['anomaly'] = iso_forest.predict(features)
data['anomaly'].value_counts()Ta có thể đi xa hơn và trực quan hóa tất cả điểm bất thường. Thực hiện bằng đoạn mã dưới đây:
# Visualization of the results
plt.figure(figsize=(10, 5))
# Plot normal instances
normal = data[data['anomaly'] == 1]
plt.scatter(normal.index, normal['anomaly_score'], label='Normal')
# Plot anomalies
anomalies = data[data['anomaly'] == -1]
plt.scatter(anomalies.index, anomalies['anomaly_score'], label='Anomaly')
plt.xlabel("Instance")
plt.ylabel("Anomaly Score")
plt.legend()
plt.show()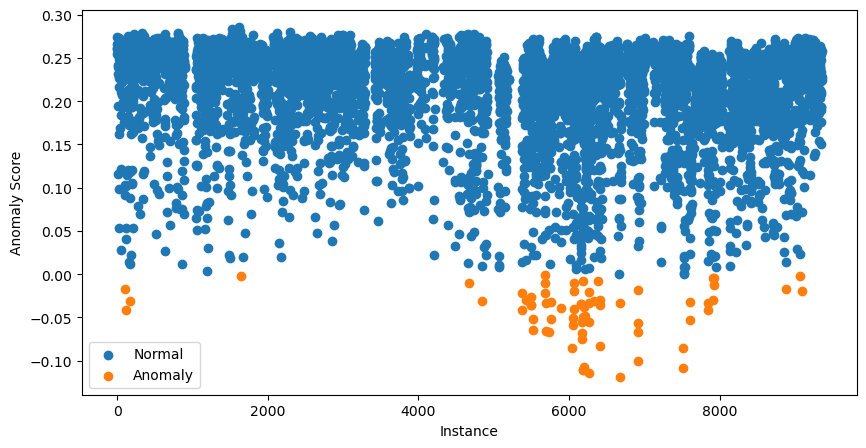
70 quan sát có điểm bất thường thấp nhất được hiển thị màu cam. Đây là các bất thường tiềm năng và bước tiếp theo là điều tra sâu hơn.
Lúc này bạn có thể hơi bối rối. Chẳng phải ta nói điểm gần 1 cho thấy bất thường tiềm năng sao?
Các điểm bạn thấy trong biểu đồ phân tán trên đã được điều chỉnh. Để làm điều này, gói trước tiên tính một độ lệch (offset). Đây là phân vị của điểm bất thường dựa trên giá trị contamination. Trong trường hợp của ta, độ lệch sẽ là phân vị 0,99. Điểm cuối cùng sau đó được tính bằng offset - score. Làm vậy có nghĩa là tất cả điểm nhỏ hơn 0 gợi ý bất thường tiềm năng.
Dùng biểu đồ phân tán trên, ta có thể nhận diện các bất thường tiềm năng. Tuy nhiên, điều này không cho ta biết vì sao chúng được phân loại là bất thường. Để làm vậy, ta cần phân tích sâu hơn.
Ví dụ, trong đoạn mã dưới đây ta tạo một biểu đồ phân tán của tất cả quan sát bằng cách vẽ giá trị CO(GT) so với giá trị NO2(GT). Ta cũng tô màu các điểm dựa trên việc chúng có được phân loại là bất thường hay không.
# Visualization of the results
plt.figure(figsize=(5, 5))
# Plot non-anomalies then anomalies
plt.scatter(normal['CO(GT)'], normal['NO2(GT)'], label='Normal')
plt.scatter(anomalies['CO(GT)'], anomalies['NO2(GT)'], label='Anomaly')
plt.xlabel("CO(GT)")
plt.ylabel("NO2(GT)")
plt.legend()
plt.show()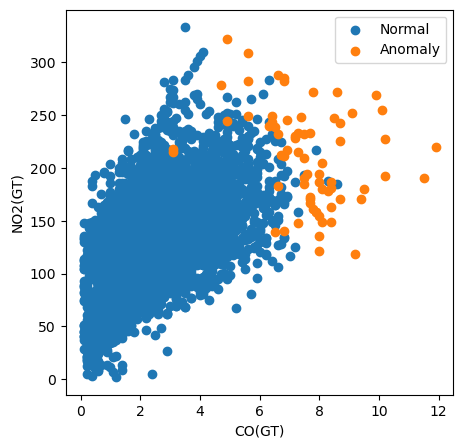
Dựa vào biểu đồ này, ta thấy phép đo chất ô nhiễm CO(GT) đặc biệt quan trọng. Lưu ý rằng nhiều bất thường có giá trị lớn hơn 6 đối với đặc trưng này. Tuy nhiên, điều này không giải thích tất cả bất thường. Một số có giá trị cao ở cả hai đặc trưng và một số không có vẻ là bất thường bởi bất kỳ đặc trưng nào trong biểu đồ này. Điều này gợi ý rằng các chất ô nhiễm khác cũng góp phần vào phân loại.
Điều này dẫn ta đến các ưu điểm chính của Isolation Forest so với các phương pháp phát hiện bất thường khác. Đầu tiên là chúng có thể xử lý dữ liệu nhiều chiều. Như đã thấy, quan sát có thể bị gắn cờ là bất thường dựa trên tất cả đặc trưng, và phương pháp hoạt động tốt với nhiều hơn bốn đặc trưng rất nhiều. Một ưu điểm quan trọng khác là chúng có thể tìm bất thường thuộc nhiều kiểu khác nhau.
Để so sánh, một phương pháp phát hiện bất thường đơn giản là z-score. Dùng từng đặc trưng riêng lẻ, cách này sẽ phân loại bất thường dựa trên khoảng cách giá trị đặc trưng so với trung bình của nó. Tuy nhiên, đây chỉ là một kiểu bất thường. Cách này cũng giả định các đặc trưng có phân phối chuẩn và yêu cầu ta đánh giá z-score cho mọi đặc trưng trong tập dữ liệu.
Với Isolation Forest, ta không đưa ra giả định về phân phối của đặc trưng. Kết quả là ta có thể tìm các quan sát là bất thường vì những lý do khác ngoài việc cách xa trung bình. Như đã thấy, ta cũng có thể phân loại đồng thời bằng tất cả đặc trưng. Điều này có thể đơn giản hóa đáng kể phân tích, đặc biệt với các tập dữ liệu lớn.
Các cân nhắc khác là Isolation Forest có độ phức tạp thời gian tuyến tính và là phương pháp không giám sát. Điều này khiến nó trở thành một phương pháp lý tưởng để phát hiện bất thường mà không cần kiến thức trước trong các tập dữ liệu lớn. Điều này thường xảy ra trong các ứng dụng thực tế như phát hiện gian lận, nơi các loại gian lận mới liên tục xuất hiện giữa một biển giao dịch bình thường.
Một hạn chế đáng chú ý của Isolation Forest là có thể không hoạt động tốt với các tập dữ liệu nhỏ. Điều này liên quan đến quá trình ngẫu nhiên khi tạo các Isolation Tree. Luôn có khả năng các quan sát bình thường có đường đi ngắn, hoặc ngược lại, các bất thường có đường đi dài hơn. Với tập dữ liệu nhỏ, điều này có khả năng xảy ra cao hơn. Nói cách khác, để Isolation Forest hoạt động, ta cần đủ dữ liệu để trung bình hóa tính ngẫu nhiên.
Một hạn chế khác, như ta đã thấy, là Isolation Forest chỉ có thể nhận diện các bất thường tiềm năng. Nó không cho ta biết vì sao các quan sát nhất định là bất thường. Để làm điều đó, ta cần phân tích sâu hơn. Lúc này, ưu điểm trong việc nhận diện bất thường phức tạp lại trở thành thách thức. Cuối cùng, có thể cần rất nhiều công sức và kiến thức miền để giải thích đầy đủ một bất thường.
Chúng ta đã khám phá Isolation Forest, một công cụ mạnh mẽ để phát hiện bất thường trong nhiều lĩnh vực. Ta đã thấy cách tiếp cận độc đáo của nó — cô lập bất thường thông qua phân hoạch ngẫu nhiên — mang lại lợi thế so với các phương pháp truyền thống: xử lý dữ liệu nhiều chiều, nhận diện các mẫu bất thường phức tạp và đảm bảo khả năng mở rộng.
Ví dụ thực hành bằng Python và Scikit-learn cho thấy sự dễ dùng.
Mặc dù Isolation Forest có thể hiệu quả trong việc nhận diện các bất thường tiềm năng mà không cần kiến thức trước, nó cũng có hạn chế, đặc biệt khi làm việc với tập dữ liệu nhỏ và việc không thể giải thích vì sao các quan sát cụ thể bị coi là bất thường.
Các khóa học Machine Learning hàng đầu!
Courses
Courses
Courses