
Cours
Machine learning avec des modèles arborescents en Python
5 h
116.4K
J’ai récemment reçu un SMS de ma banque :
« Nous avons bloqué temporairement votre carte. La transaction de [montant] chez [commerçant] est-elle la vôtre ? »
Heureusement, ce n’était que moi, en train de faire du shopping en ligne à une heure indue. Mais cela m’a fait réfléchir… comment la banque repère-t-elle des opérations suspectes parmi les centaines de milliers qu’elle traite chaque jour ?
Identifier la fraude est un cas particulier d’un problème plus large en apprentissage automatique (ML) appelé détection d’anomalies. Parmi les nombreuses approches possibles, nous nous concentrerons ici sur l’une des plus utilisées : Isolation Forest.
Lutter contre la fraude, défendre des réseaux, repérer des valeurs aberrantes, signaler un équipement défectueux : ces problèmes paraissent très différents. Pourtant, ils ont un point commun : il n’existe pas de libellés clairs ni de définition précise de ce qu’est une anomalie. Dans bien des cas, les anomalies sont rares et subtiles, donc difficiles à identifier au milieu d’un grand volume de données normales.
Une façon de concevoir des systèmes de détection d’anomalies consiste à utiliser des méthodes prédictives en ML. Par exemple, nous pourrions collecter des transactions frauduleuses puis, à partir de variables comme le montant, l’heure, le lieu et le type de commerçant, construire un modèle distinguant ces opérations des transactions normales. Le problème, c’est que cette approche ne permettra de détecter que des fraudes similaires à celles déjà observées.
Les fraudeurs changent souvent de stratégie et testent de nouveaux modes opératoires, parfois totalement imprévus. C’est pourquoi les méthodes non supervisées sont souvent utilisées pour détecter des anomalies. Elles comparent l’ensemble des transactions et repèrent celles dont les variables présentent des valeurs atypiques. L’intérêt majeur : il n’est pas nécessaire d’annoter les transactions en amont.
La fraude n’est pas le seul comportement difficile à classifier. En production, des machines peuvent tomber en panne à tout moment, et de façon inattendue. En cybersécurité, de nouvelles attaques sont découvertes et corrigées en permanence. En médecine, des pathologies rares peuvent se cacher au milieu d’une multitude de résultats d’examens. Les applications sont innombrables, voyons donc comment fonctionne une approche non supervisée pour détecter ces anomalies.
Comme son nom l’indique, les Isolation Forests sont une méthode à base d’arbres, proches des Random Forests. Cependant, leurs briques de base diffèrent.
Une Random Forest utilise des arbres de décision construits avec des scissions fondées sur l’impureté de Gini. Cela requiert une variable cible. À la place, Isolation Forest recourt à des « arbres d’isolement ». L’algorithme agrège ces arbres pour calculer un score d’anomalie pour chaque instance.
Avant de calculer des scores, il vaut la peine de comprendre cette brique de base. Supposons que nous cherchions à détecter des transactions frauduleuses. Pour simplifier, évaluons 1 000 transactions (instances) et considérons deux variables : le montant (x1) et l’heure de la journée (x2) d’une transaction.
Pour créer un arbre d’isolement, on démarre avec toutes les instances (ou un échantillon) dans le nœud racine. Dans la figure 1 ci-dessous, nous utilisons un échantillon de 256 instances (nous reviendrons sur ce nombre).
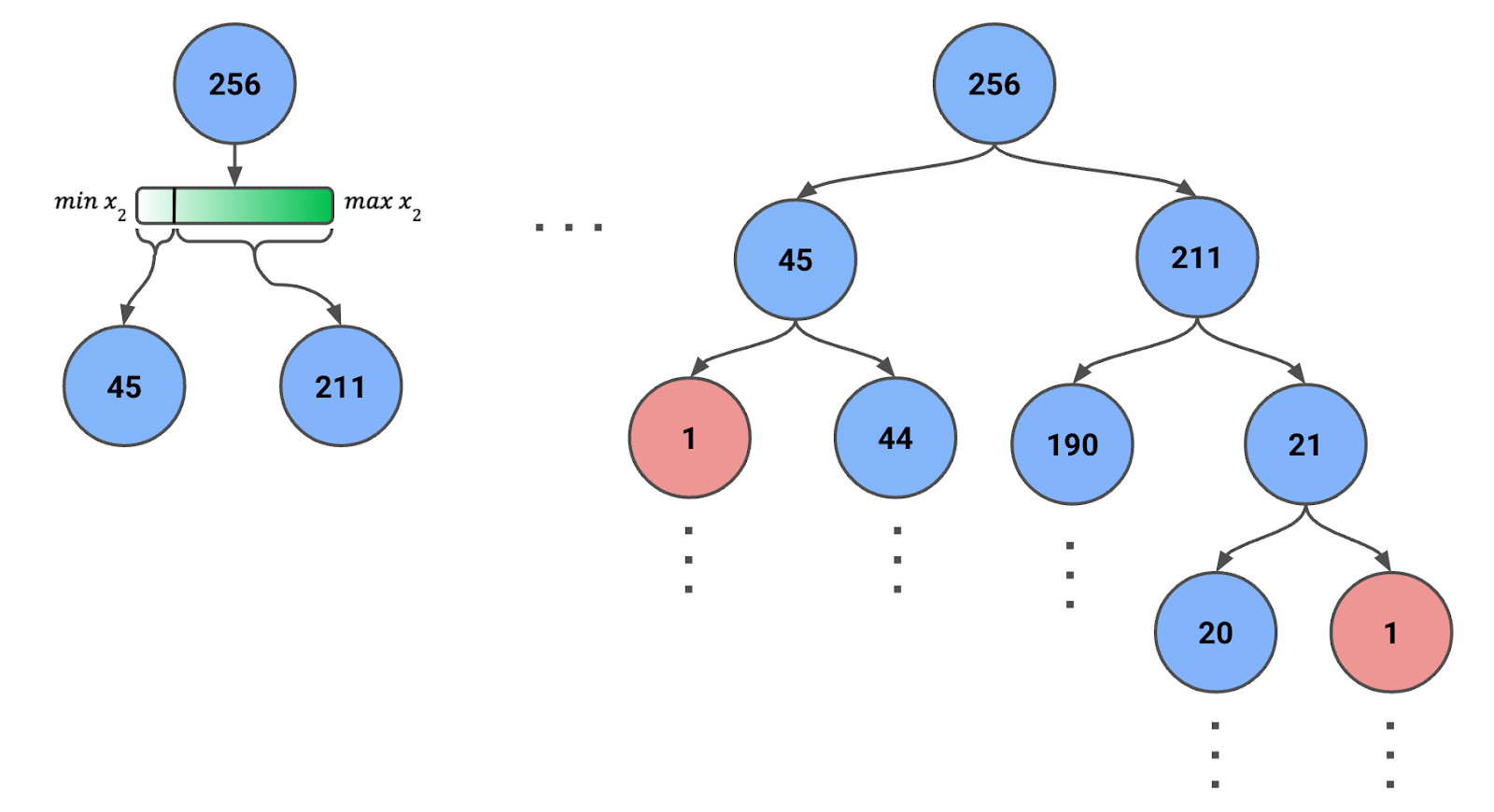
Figure 1 : arbre d’isolement créé par divisions aléatoires récursives. Le nombre d’instances par nœud est indiqué.
Nous procédons ainsi :
Notez que l’intervalle de la variable évolue à chaque étape : on utilise les valeurs min et max de la variable pour les instances du nœud. Cet ajustement dynamique garantit des coupures pertinentes et évite d’obtenir des nœuds vides.
La figure 2 donne l’intuition de l’isolement des valeurs aberrantes. Les instances A, B, et C paraissent différentes des autres transactions.
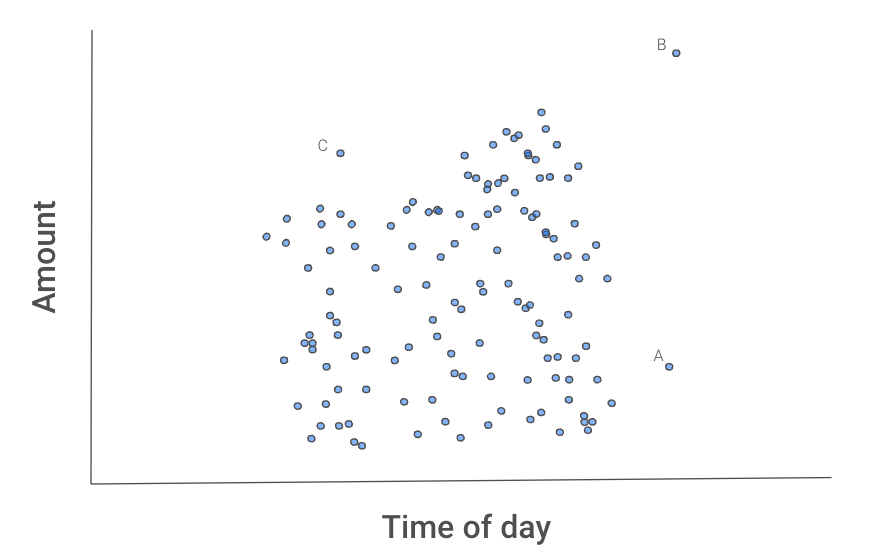
Figure 2 : nuage de points des transactions
B sera probablement isolée en premier, car une seule coupure sur l’une ou l’autre variable suffit à la séparer du reste.
A nécessiterait une seule coupure sur x2.
C pourrait prendre plus de temps, car il faudrait l’isoler en combinant les deux variables : C a un montant et une heure séparément « normaux », mais pas un montant normal pour cette heure-là.
Nous pourrions avoir de la chance et isoler l’une de ces instances du premier coup, mais le plus probable est qu’il faille quelques essais. L’essentiel est qu’en moyenne, B demandera moins de coupures que A, A moins que C, et que ces trois points nécessiteront moins de coupures que le reste. Mais comment capter ce comportement moyen ?
Le nombre de coupures nécessaires pour isoler une anomalie détermine la longueur du chemin jusqu’à la feuille de l’instance. Lorsqu’une forêt d’arbres d’isolement produit systématiquement des chemins plus courts pour certains échantillons, ceux-ci sont probablement des anomalies. On capte ce comportement moyen en agrégeant les longueurs de chemin sur tous les arbres : c’est le score d’anomalie.
Pour calculer un score d’anomalie pour une instance x, définissons d’abord quelques valeurs :
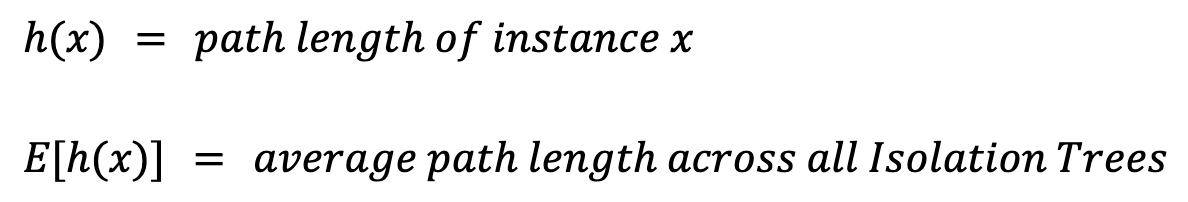
La longueur de chemin, h(x), est le nombre d’arêtes (coupures) à parcourir pour atteindre la feuille de l’instance. Prendre simplement la moyenne E[h(x)] pose problème : les arbres plus grands, avec davantage d’instances, ont des chemins plus longs, y compris pour les anomalies. Pour en tenir compte, il faut une normalisation basée sur la taille de l’échantillon n :
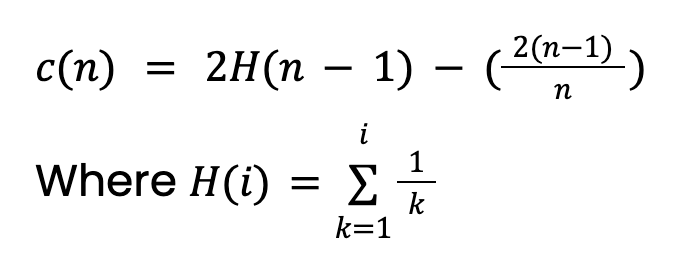
Cette valeur provient de la théorie des arbres de recherche binaires (BST). Elle donne la longueur moyenne d’un parcours infructueux dans un BST. Comme les arbres d’isolement ont une structure équivalente, on prend c(n) comme longueur de chemin attendue pour une instance (anormale ou non). À noter : cette valeur doit être ajustée si l’on fixe une profondeur maximale de l’arbre.
Enfin, nous pouvons calculer le score d’anomalie s(x,n) :
 Le score varie entre 0 et 1. Pour l’interpréter, considérons trois cas :
Le score varie entre 0 et 1. Pour l’interpréter, considérons trois cas :
Autrement dit, quand la longueur de chemin moyenne d’une instance est inférieure à la longueur moyenne attendue, le score tend vers 1. Cependant, comme nous le verrons à l’implémentation, le package Scikit-learn effectue des ajustements supplémentaires du score.
Passons à l’implémentation pas à pas, en commençant par les imports.
Nous utilisons les packages Python standards pour la manipulation de données et la visualisation (lignes 2 à 5). Nous recourons aussi à l’implémentation Scikit-learn d’Isolation Forest (ligne 7) et le dernier package sert à importer notre jeu de données (ligne 8).
# Imports
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import IsolationForest
from ucimlrepo import fetch_ucirepoNous chargeons les données directement depuis le UCI Machine Learning Repository. Nous utilisons le jeu de données Air Quality (CC BY 4.0), qui contient 9 358 mesures de qualité de l’air issues d’un capteur dans une ville italienne. Dans ce contexte, une anomalie peut être une lecture du capteur indiquant un niveau de pollution anormalement élevé.
# Fetch dataset from UCI repository
air_quality = fetch_ucirepo(id=360)Nous effectuons un nettoyage avant d’appliquer le modèle. Nous commençons par sélectionner toutes les variables du jeu de données (ligne 2), puis un sous-ensemble de 4 variables (ligne 5), qui mesurent des oxydes métalliques présents dans l’air (donc des polluants). Nous supprimons ensuite les lignes avec des valeurs manquantes (lignes 8–9). Au final, nous conservons 6 941 instances ; un aperçu des variables est présenté ci-dessous.
# Convert to DataFrame
data = air_quality.data.features
# Select features
features = data[['CO(GT)', 'C6H6(GT)', 'NOx(GT)', 'NO2(GT)']]
# Drop rows with missing values (-200)
features = features.replace(-200, np.nan)
features = features.dropna()
print(features.shape)
features.head()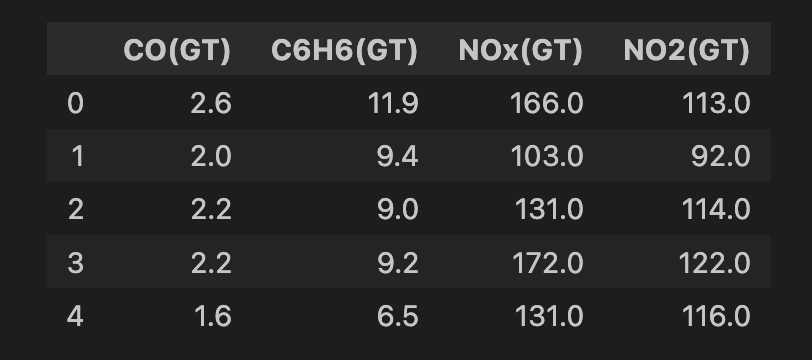
Dernière étape : définir les paramètres d’entraînement d’Isolation Forest. Nous utiliserons les trois valeurs ci-dessous :
n_estimators : nombre d’arbres d’isolement dans l’ensemble. La valeur 100 est utilisée dans l’article fondateur d’Isolation Forest ; les auteurs ont observé de bonnes performances sur divers jeux de données.contamination : pourcentage de points que l’on s’attend à voir anormaux. sample_size : nombre d’instances utilisées pour entraîner chaque arbre d’isolement. La valeur 256 est fréquente, car elle évite d’imposer une profondeur maximale : on peut s’attendre à une profondeur raisonnable de log(256) = 8.La valeur de contamination n’a pas de justification aussi solide que les autres. Elle peut provenir de l’expérience : par exemple, une analyse précédente pourrait avoir montré que 1 % des relevés indiquent une forte pollution. Elle peut aussi dépendre de contraintes opérationnelles : en détection de fraude, vous n’avez peut-être le temps d’enquêter que sur 5 % des transactions. Nous verrons, lors de la visualisation, comment les scores d’anomalie sont ajustés avec cette valeur.
# Parameters
n_estimators = 100 # Number of trees
contamination = 0.01 # Expected proportion of anomalies
sample_size = 256 # Number of samples used to train each treeNous pouvons maintenant entraîner Isolation Forest. Si vous connaissez Sklearn, la procédure vous sera familière : initialisation du modèle avec les paramètres ci-dessus (lignes 2–5), puis apprentissage sur notre jeu de variables (ligne 6).
# Train Isolation Forest
iso_forest = IsolationForest(n_estimators=n_estimators,
contamination=contamination,
max_samples=sample_size,
random_state=42)
iso_forest.fit(features)Le modèle entraîné propose deux fonctions utiles :
decision_function calcule un score d’anomalie de manière similaire à la partie théorique. predict fournit un label binaire basé sur la contamination. Dans notre cas, le 1 % des instances avec les pires scores reçoivent la valeur -1 ; les autres, 1.Nous ajoutons la sortie de ces fonctions au jeu de données (lignes 2–4). En comptant les valeurs d’anomalie (ligne 6), on observe que 70 instances sont étiquetées comme anomalies.
# Calculate anomaly scores and classify anomalies
data = data.loc[features.index].copy()
data['anomaly_score'] = iso_forest.decision_function(features)
data['anomaly'] = iso_forest.predict(features)
data['anomaly'].value_counts()Allons plus loin et visualisons l’ensemble des scores d’anomalie avec le code ci-dessous :
# Visualization of the results
plt.figure(figsize=(10, 5))
# Plot normal instances
normal = data[data['anomaly'] == 1]
plt.scatter(normal.index, normal['anomaly_score'], label='Normal')
# Plot anomalies
anomalies = data[data['anomaly'] == -1]
plt.scatter(anomalies.index, anomalies['anomaly_score'], label='Anomaly')
plt.xlabel("Instance")
plt.ylabel("Anomaly Score")
plt.legend()
plt.show()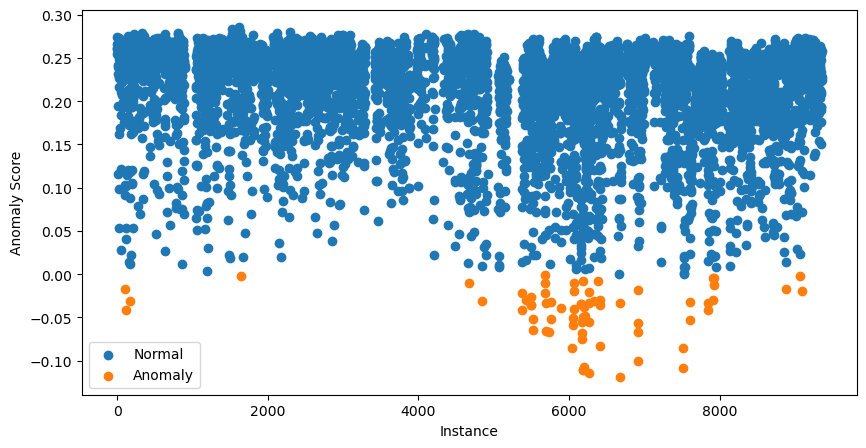
Les 70 instances aux scores les plus faibles apparaissent en orange. Ce sont nos anomalies potentielles ; étape suivante : les investiguer.
À ce stade, un doute : n’a-t-on pas dit que des scores proches de 1 indiquaient des anomalies potentielles ?
Les scores du nuage de points ci-dessus ont été ajustés. Pour cela, le package calcule d’abord un offset : le percentile du score d’anomalie basé sur la contamination. Dans notre cas, il s’agit du 99e percentile. Les scores finaux sont alors offset - score. Ainsi, tout score inférieur à 0 suggère une anomalie potentielle.
Le nuage de points précédent permet d’identifier des anomalies potentielles, sans expliquer pourquoi elles ont été classées comme telles. Pour le comprendre, il faut poursuivre l’analyse.
Par exemple, dans le code ci-dessous, nous traçons toutes les instances selon leur valeur CO(GT) et leur valeur NO2(GT), en colorant les points selon leur classification.
# Visualization of the results
plt.figure(figsize=(5, 5))
# Plot non-anomalies then anomalies
plt.scatter(normal['CO(GT)'], normal['NO2(GT)'], label='Normal')
plt.scatter(anomalies['CO(GT)'], anomalies['NO2(GT)'], label='Anomaly')
plt.xlabel("CO(GT)")
plt.ylabel("NO2(GT)")
plt.legend()
plt.show()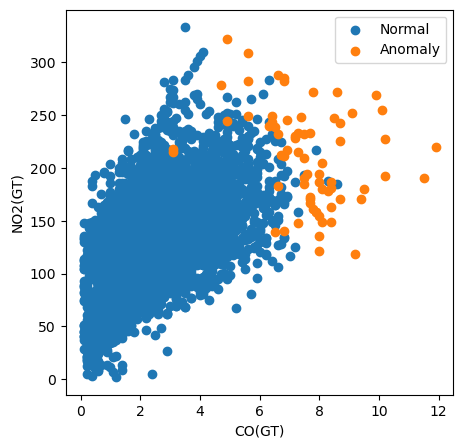
On observe que la mesure du polluant CO(GT) joue un rôle clé : nombre d’anomalies ont une valeur supérieure à 6 pour cette variable. Cela n’explique toutefois pas toutes les anomalies : certaines ont des valeurs élevées pour les deux variables, d’autres ne paraissent pas anormales selon ce graphique. D’autres polluants ont donc probablement contribué à la classification.
Cela nous amène aux principaux atouts d’Isolation Forest face à d’autres méthodes de détection d’anomalies. D’abord, elle gère bien les données à forte dimension. Comme nous l’avons vu, une instance peut être signalée anormale en mobilisant l’ensemble des variables, et la méthode reste efficace au-delà de quatre variables. Autre avantage clé : elle détecte différents types d’anomalies.
À titre de comparaison, une méthode simple est le z-score : sur chaque variable, on classe comme anomalies les valeurs trop éloignées de la moyenne. Mais il ne s’agit que d’un type d’anomalie. Cette approche suppose en outre une distribution normale et exige d’examiner les z-scores pour chaque variable.
Avec Isolation Forest, aucune hypothèse n’est faite sur la distribution des variables. Résultat : on peut identifier des instances anormales pour d’autres raisons qu’un simple éloignement de la moyenne, et classifier en mobilisant toutes les variables simultanément. Cela simplifie fortement l’analyse, surtout sur de grands jeux de données.
Autres points à noter : Isolation Forest a une complexité temporelle linéaire et elle est non supervisée. C’est donc une méthode idéale pour détecter des anomalies sans connaissance préalable dans de grands volumes de données — situation fréquente en détection de fraude, où de nouveaux schémas émergent en continu parmi une masse de transactions normales.
Une limite notable d’Isolation Forest est sa performance moindre sur de petits jeux de données, en raison du caractère aléatoire de la construction des arbres. Il existe toujours un risque que des instances normales aient des chemins courts, ou inversement que des anomalies aient des chemins plus longs. Avec peu de données, ce risque augmente. Autrement dit, Isolation Forest nécessite suffisamment de données pour « moyenner » l’aléa.
Autre limite, comme nous l’avons vu : Isolation Forest identifie des anomalies potentielles, sans expliquer pourquoi. Pour cela, des analyses complémentaires sont requises. L’avantage de détecter des anomalies complexes devient alors un défi : expliquer pleinement une anomalie peut demander beaucoup de travail et de connaissance métier.
Nous avons exploré Isolation Forest, un outil puissant de détection d’anomalies dans de multiples domaines. Son approche singulière — isoler les anomalies par partitionnements aléatoires — présente des avantages face aux méthodes classiques : gestion de la haute dimension, identification de schémas d’anomalies complexes et passage à l’échelle.
L’exemple pratique avec Python et Scikit-learn a montré sa simplicité d’usage.
Si Isolation Forest identifie efficacement des anomalies potentielles sans connaissance préalable, elle a aussi des limites, notamment sur de petits jeux de données et son incapacité à expliquer pourquoi des instances sont jugées anormales.
Les meilleurs cours de machine learning !
Cours
Cours
Cours
Tutoriel
Aditya Sharma
Tutoriel
Sejal Jaiswal
Tutoriel
Sejal Jaiswal
Tutoriel
Javier Canales Luna
Tutoriel
Laiba Siddiqui
Tutoriel
Moez Ali

