
Corso
Machine Learning con modelli ad alberi in Python
5 h
117.2K
Di recente ho ricevuto un messaggio dalla mia banca:
“Abbiamo bloccato temporaneamente la tua carta. La transazione di [importo] presso [esercente] è tua?”
Per fortuna ero solo io a fare shopping online a un'ora improbabile, ma questo mi ha fatto pensare… come fa la banca a segnalare le transazioni sospette tra le centinaia di migliaia che elabora ogni giorno?
Individuare le frodi è un caso specifico di un problema più ampio nel machine learning (ML) chiamato rilevamento delle anomalie. Sebbene esistano molti metodi per risolvere questo problema, in questo blog ci concentreremo su uno dei più popolari: Isolation Forest.
Combattere le frodi, difendere le reti, trovare outlier e segnalare apparecchiature difettose possono sembrare problemi diversi. Tuttavia, condividono una caratteristica comune: non ci sono etichette chiare o definizioni precise di cosa costituisce un'anomalia. In molti casi, le anomalie sono rare e sottili, il che le rende difficili da identificare tra enormi quantità di dati normali.
Un modo per sviluppare sistemi di rilevamento delle anomalie è usare metodi predittivi di ML. Per esempio, potremmo raccogliere transazioni fraudolente. Poi, usando caratteristiche come importo, ora, luogo e tipo di esercente, possiamo costruire un modello che le distingua dalle transazioni normali. Il problema è che questo approccio ci permetterà di rilevare solo casi di frode simili a quelli già visti in passato.
I truffatori spesso cambiano strategia e tentano nuove modalità di frode. Molte di queste saranno del tutto inaspettate. Ecco perché spesso si usano metodi non supervisionati per rilevare anomalie. Funzionano confrontando tutte le transazioni e identificando quelle con valori delle caratteristiche insoliti. Importante: questo significa che non dobbiamo etichettare preventivamente alcuna transazione.
La frode non è l'unico comportamento difficile da classificare. Nella manifattura, le macchine possono guastarsi in qualsiasi momento e in modi inaspettati. In cybersecurity, nuovi attacchi vengono costantemente scoperti e corretti. In medicina, problemi di salute rari possono nascondersi tra molti risultati di test. Le applicazioni sono infinite, quindi vediamo come funziona un approccio non supervisionato per rilevare queste anomalie.
Come suggerisce il nome, le Isolation Forest sono un metodo basato su alberi. Sono simili alle Random Forest, ma i mattoni di base sono diversi.
Una Random Forest usa alberi decisionali creati con split basati sull'impurità di Gini. Questo richiede una variabile target, quindi le Isolation Forest usano invece Isolation Tree. Il metodo usa una collezione di questi alberi per calcolare un punteggio di anomalia per ciascuna istanza.
Vale la pena capire come funziona questo blocco di base prima di calcolare i punteggi di anomalia. Diciamo che stiamo cercando di rilevare transazioni fraudolente. Per semplicità, valuteremo 1000 transazioni (istanze) e considereremo due variabili del nostro dataset: l'importo (x1) e l'ora del giorno (x2) di una transazione.
Per creare un'Isolation Tree, partiamo da tutte o da un campione di istanze nel nodo radice. In Figura 1 sotto, puoi vedere che abbiamo un campione di 256 istanze (più avanti parleremo di questo numero).
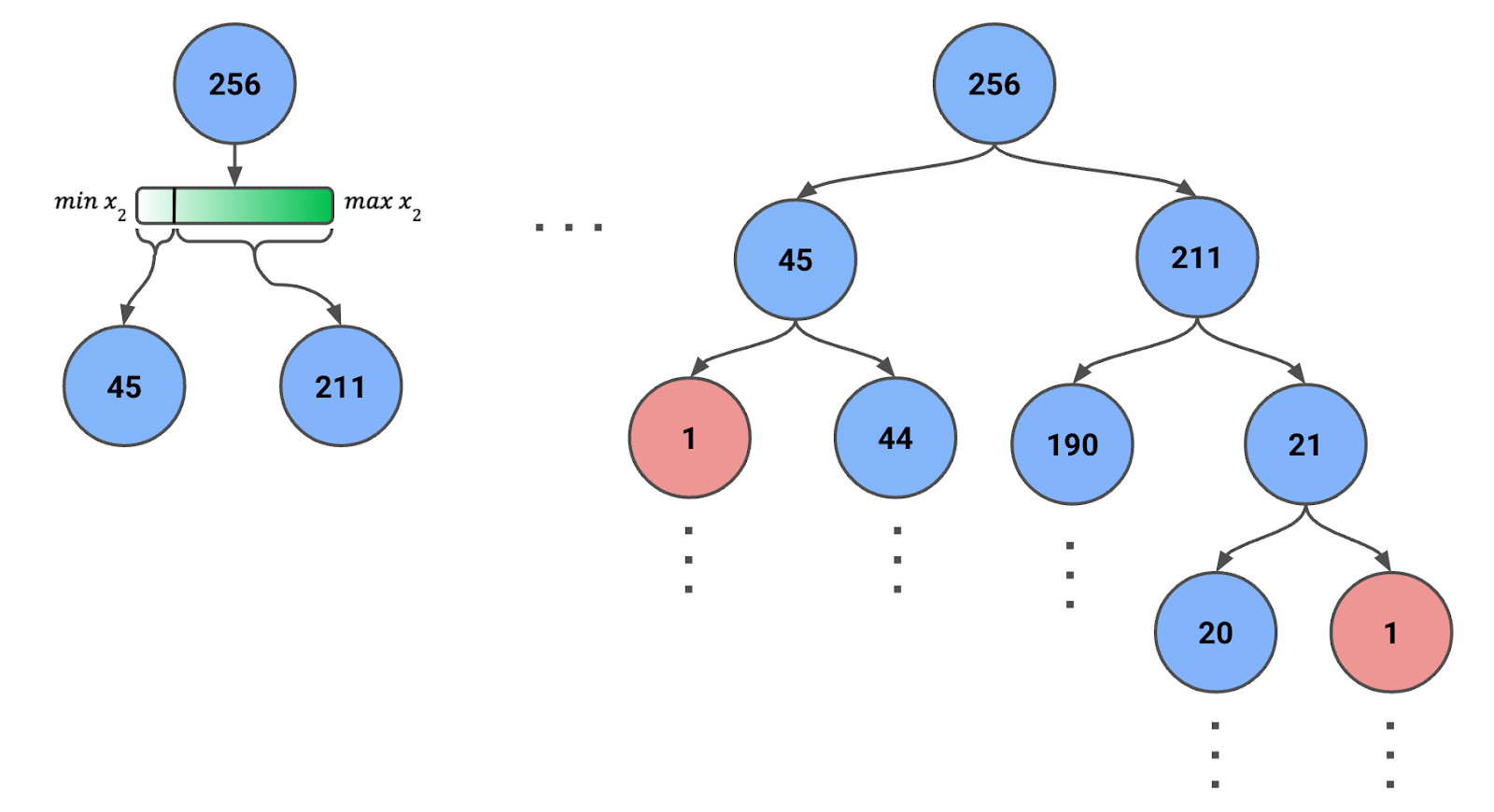
Figura 1: Isolation Tree creata usando split casuali ricorsivi. È indicato il numero di istanze in ciascun nodo.
Poi:
Nota che l'intervallo della caratteristica cambia a ogni passo. Cioè, usiamo i valori minimo e massimo della caratteristica per le istanze del nodo. Questo adattamento dinamico garantisce split significativi ed evita nodi con zero istanze.
La Figura 2 qui sotto ci dà un'intuizione del perché questo processo isola gli outlier. Le istanze A, B, e C sembrano diverse dalle altre transazioni.
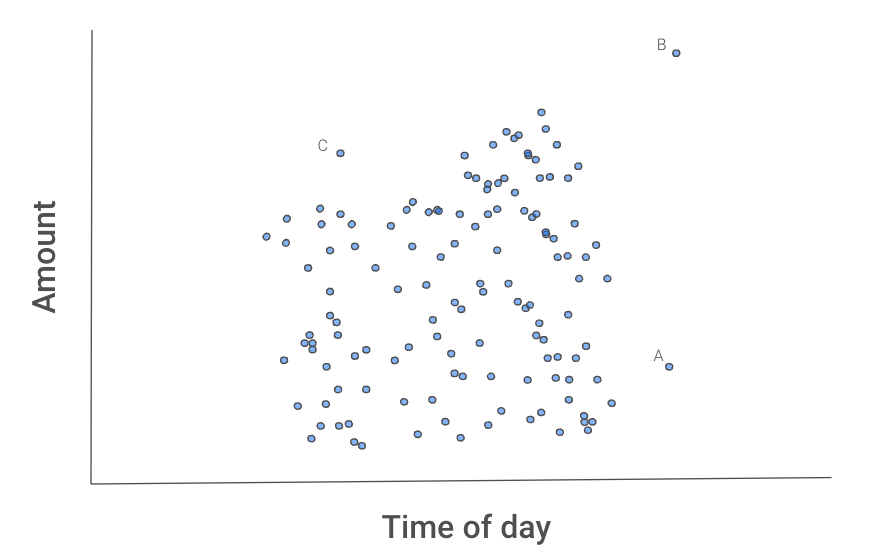
Figura 2: Scatter plot delle transazioni
B probabilmente verrà isolata per prima perché può essere separata dalle altre transazioni con uno split di una qualsiasi delle due caratteristiche.
A richiederebbe uno split su x2.
C potrebbe richiedere più tempo perché andrebbe isolata usando entrambe le caratteristiche. Cioè, C ha sia un importo sia un'orario normali, ma non un importo normale per quell'ora del giorno.
Potremmo essere fortunati e isolare una di queste istanze al primo tentativo. Più probabilmente, serviranno alcuni tentativi. Il punto importante è che, in media, B richiederà meno split di A, A meno di C, e tutti e tre i punti richiederanno meno split rispetto alle altre transazioni. Ma come catturiamo questo comportamento medio?
Il numero di split necessari per isolare un'anomalia determina la lunghezza del percorso fino alla foglia dell'istanza. Quando una foresta di Isolation Tree produce costantemente percorsi più corti per determinati campioni, quei campioni sono probabilmente anomalie. Catturiamo questo comportamento medio aggregando le lunghezze dei percorsi su tutti gli alberi, un processo noto come calcolo del punteggio di anomalia.
Per calcolare un punteggio di anomalia per un'istanza x, dobbiamo prima definire alcuni valori:
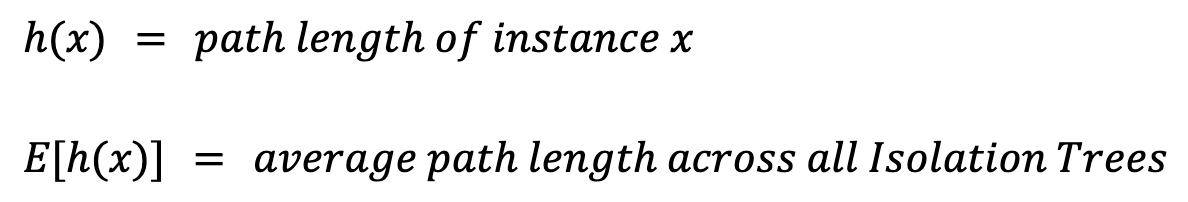
La lunghezza del percorso, h(x), è il numero di archi (split) da attraversare per raggiungere la foglia dell'istanza. Semplicemente farne la media, E[h(x)], porta a problemi. Infatti, alberi più grandi con più istanze tendono ad avere percorsi più lunghi, anche per le anomalie. Per tenerne conto, serve un valore di normalizzazione basato sulla dimensione del campione n:
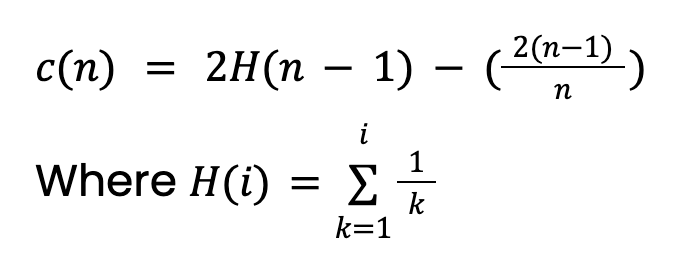
Questo valore deriva dalla teoria dei Binary Search Tree (BST). Fornisce la lunghezza del percorso media delle ricerche non riuscite nei BST. Poiché gli Isolation Tree hanno una struttura equivalente ai BST, prendiamo c(n) come la lunghezza di percorso attesa per un'istanza (anomala o meno). Nota che questo valore dovrà essere adattato se impostiamo una profondità massima dell'albero.
Infine, possiamo calcolare il nostro punteggio di anomalia s(x,n):
 Il punteggio varia tra 0 e 1 e, nell'interpretarlo, dovremmo considerare tre scenari:
Il punteggio varia tra 0 e 1 e, nell'interpretarlo, dovremmo considerare tre scenari:
In altre parole, quando la lunghezza di percorso media di un'istanza è più corta della lunghezza di percorso media attesa, il punteggio di anomalia sarà più vicino a 1. Tuttavia, come vedremo implementando il metodo, il pacchetto Scikit-learn apporta ulteriori aggiustamenti al punteggio.
Affrontiamo l'implementazione passo dopo passo a partire dagli import.
Abbiamo i pacchetti Python standard per la gestione dei dati e la visualizzazione (righe 2-5). Usiamo anche l'implementazione Scikit-learn di Isolation Forest (riga 7) e l'ultimo pacchetto serve per importare il nostro dataset (riga 8).
# Imports
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import IsolationForest
from ucimlrepo import fetch_ucirepoCarichiamo i dati direttamente dal repository UCI di machine learning. Usiamo il dataset Air Quality (CC BY 4.0), che contiene 9.358 istanze di misurazioni della qualità dell'aria da un sensore in una città italiana. In questo contesto, un'anomalia può essere considerata una lettura del sensore che indica livelli di inquinamento insolitamente alti.
# Fetch dataset from UCI repository
air_quality = fetch_ucirepo(id=360)Facciamo un po' di pulizia dei dati prima di applicare il modello. Iniziamo selezionando tutte le caratteristiche dal dataset (riga 2) e poi selezioniamo un sottoinsieme di 4 caratteristiche (riga 5). Sono tutte misure di diversi ossidi metallici nell'aria (cioè inquinanti). Quindi eliminiamo le righe con valori mancanti (righe 8-9). Alla fine abbiamo 6.941 istanze e qui sotto puoi vedere un'anteprima del set di caratteristiche.
# Convert to DataFrame
data = air_quality.data.features
# Select features
features = data[['CO(GT)', 'C6H6(GT)', 'NOx(GT)', 'NO2(GT)']]
# Drop rows with missing values (-200)
features = features.replace(-200, np.nan)
features = features.dropna()
print(features.shape)
features.head()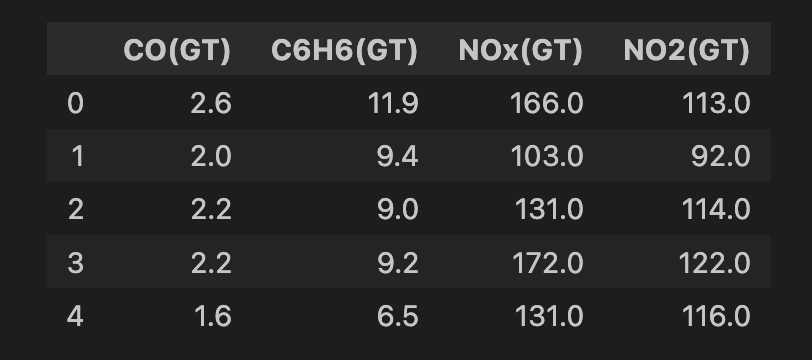
L'ultima cosa da fare è definire i parametri usati per addestrare l'Isolation Forest. In questo caso useremo i tre valori seguenti:
n_estimators è il numero di Isolation Tree usati nell'insieme. Un valore di 100 è usato nell'articolo su Isolation Forest. Con gli esperimenti, i ricercatori hanno visto che produce buoni risultati su una varietà di dataset. contamination è la percentuale di punti dati che ci aspettiamo siano anomalie. sample_size è il numero di istanze usate per addestrare ciascun Isolation Tree. Un valore di 256 è comunemente usato perché ci permette di evitare un criterio di arresto per dimensione massima dell'albero. Questo perché possiamo aspettarci dimensioni massime ragionevoli pari a log(256) = 8.Il valore di contamination non ha una giustificazione solida come gli altri. Potrebbe derivare dall'esperienza. Supponiamo che nell'analisi precedente abbiamo trovato che l'1% delle letture indica alti livelli di inquinamento. Potrebbe anche dipendere da vincoli di risorse. Per esempio, analizzando transazioni fraudolente potresti avere tempo solo per approfondire il 5% di tutte le transazioni. Quando visualizzeremo i punteggi di anomalia, vedremo come vengono aggiustati usando questo valore di contamination.
# Parameters
n_estimators = 100 # Number of trees
contamination = 0.01 # Expected proportion of anomalies
sample_size = 256 # Number of samples used to train each treeInfine possiamo addestrare l'Isolation Forest. Se conosci Sklearn, allora questo processo ti sembrerà familiare. Inizializziamo il modello usando i parametri discussi sopra (righe 2-5). Poi addestriamo il modello sul nostro set di caratteristiche (riga 6).
# Train Isolation Forest
iso_forest = IsolationForest(n_estimators=n_estimators,
contamination=contamination,
max_samples=sample_size,
random_state=42)
iso_forest.fit(features)Il modello addestrato ha due funzioni utili:
decision_function calcola il punteggio di anomalia in modo simile a quanto discusso nella sezione teorica. predict fornisce un'etichetta binaria basata sul valore di contamination. Nel nostro caso, l'1% delle istanze con i peggiori punteggi di anomalia riceverà il valore -1. Le altre istanze ricevono il valore 1.Aggiungiamo l'output di queste funzioni al nostro dataset (righe 2-4). Quando contiamo i valori di anomalia (riga 6) vediamo che 70 istanze sono etichettate come anomalie.
# Calculate anomaly scores and classify anomalies
data = data.loc[features.index].copy()
data['anomaly_score'] = iso_forest.decision_function(features)
data['anomaly'] = iso_forest.predict(features)
data['anomaly'].value_counts()Possiamo andare oltre e visualizzare tutti i punteggi di anomalia. Lo facciamo con il codice seguente:
# Visualization of the results
plt.figure(figsize=(10, 5))
# Plot normal instances
normal = data[data['anomaly'] == 1]
plt.scatter(normal.index, normal['anomaly_score'], label='Normal')
# Plot anomalies
anomalies = data[data['anomaly'] == -1]
plt.scatter(anomalies.index, anomalies['anomaly_score'], label='Anomaly')
plt.xlabel("Instance")
plt.ylabel("Anomaly Score")
plt.legend()
plt.show()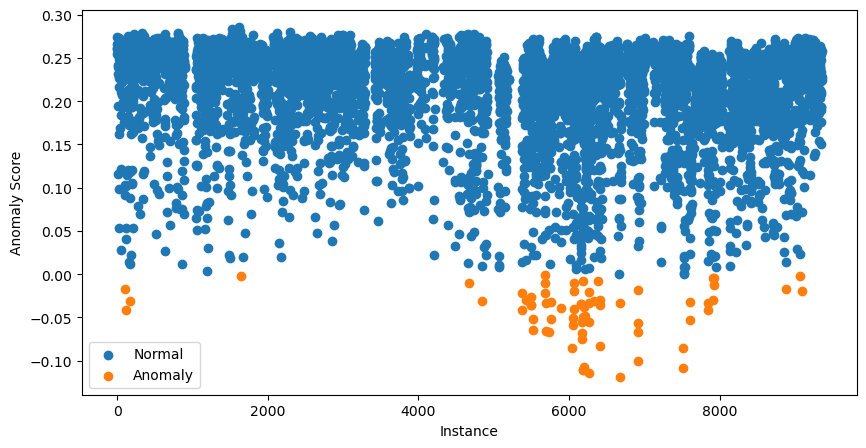
Le 70 istanze con i punteggi di anomalia più bassi sono indicate in arancione. Queste sono le nostre potenziali anomalie e il prossimo passo è indagarle ulteriormente.
A questo punto potresti essere un po' confuso. Non avevamo detto che punteggi vicini a 1 indicano potenziali anomalie?
I punteggi che vedi nello scatter plot sopra sono stati aggiustati. Per farlo, il pacchetto calcola prima un offset. Si tratta del percentile del punteggio di anomalia basato sul valore di contamination. Nel nostro caso, l'offset sarà il 99º percentile. I punteggi finali sono poi dati da offset - score. In questo modo tutti i punteggi sotto 0 suggeriscono potenziali anomalie.
Usando lo scatter plot sopra, possiamo identificare potenziali anomalie. Tuttavia, questo non ci dice perché siano state classificate come anomalie. Per capirlo dovremo fare un'analisi ulteriore.
Per esempio, nel codice seguente creiamo uno scatter plot di tutte le istanze tracciando il loro valore CO(GT) rispetto al valore NO2(GT). Coloriamo anche i punti in base al fatto che siano stati classificati come anomalie.
# Visualization of the results
plt.figure(figsize=(5, 5))
# Plot non-anomalies then anomalies
plt.scatter(normal['CO(GT)'], normal['NO2(GT)'], label='Normal')
plt.scatter(anomalies['CO(GT)'], anomalies['NO2(GT)'], label='Anomaly')
plt.xlabel("CO(GT)")
plt.ylabel("NO2(GT)")
plt.legend()
plt.show()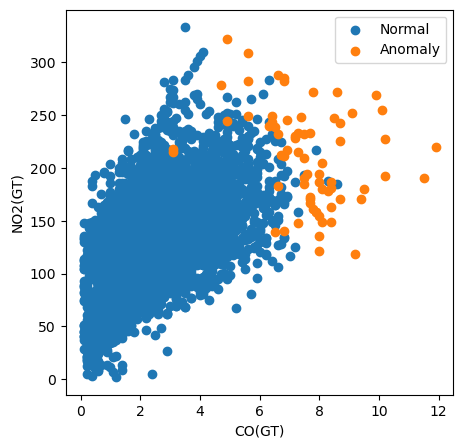
Da questo grafico possiamo vedere che la misura dell'inquinante CO(GT) è particolarmente importante. Nota che molte anomalie hanno per questa caratteristica un valore superiore a 6. Tuttavia, questo non spiega tutte le anomalie. Alcune hanno valori alti per entrambe le caratteristiche e altre non sembrano anomale in base a nessuna delle caratteristiche in questo grafico. Questo suggerisce che anche altri inquinanti hanno contribuito alla classificazione.
Questo ci porta ai principali vantaggi delle Isolation Forest rispetto ad altri metodi di rilevamento delle anomalie. Il primo è che possono gestire dati ad alta dimensionalità. Come abbiamo visto, le istanze possono essere segnalate come anomalie usando tutte le caratteristiche, e il metodo funziona bene anche con molte più di quattro caratteristiche. Un altro vantaggio chiave è che possono trovare anomalie di vario tipo.
Per confronto, un metodo semplice è lo z-score. Usando singole caratteristiche, classificherà le anomalie in base a quanto i valori si discostano dalla loro media. Tuttavia, questo è solo un tipo di anomalia. Questo approccio inoltre presume che le caratteristiche abbiano una distribuzione normale e richiede di valutare gli z-score per ogni caratteristica del dataset.
Con le Isolation Forest non facciamo assunzioni sulla distribuzione delle caratteristiche. Il risultato è che possiamo trovare istanze anomale per ragioni diverse dall'essere lontane dalla media. Come abbiamo visto, possiamo anche fare classificazioni usando tutte le caratteristiche simultaneamente. Questo può semplificare drasticamente l'analisi, soprattutto con dataset di grandi dimensioni.
Altre considerazioni: l'Isolation Forest ha una complessità temporale lineare ed è non supervisionata. Questo la rende un metodo ideale per rilevare anomalie senza conoscenze pregresse in grandi dataset. È spesso il caso nelle applicazioni reali come il rilevamento delle frodi, dove nuovi tipi di frode emergono continuamente in mezzo a un mare di transazioni normali.
Una limitazione evidente di Isolation Forest è che potrebbe non funzionare bene con dataset piccoli. Questo ha a che fare con il processo casuale con cui vengono creati gli Isolation Tree. C'è sempre la possibilità che istanze normali abbiano percorsi brevi o, al contrario, che anomalie abbiano percorsi più lunghi. Con dataset piccoli, questo è più probabile. In altre parole, perché le Isolation Forest funzionino, serve abbastanza dato per mediare la casualità.
Un'altra limitazione, come abbiamo visto, è che Isolation Forest può solo identificare potenziali anomalie. Non ci dice nulla sul perché certe istanze siano anomalie. Per farlo, serve un'analisi ulteriore. Ora, il vantaggio di identificare anomalie complesse si trasforma in una sfida. In definitiva, può richiedere molto lavoro e conoscenza del dominio per spiegare pienamente un'anomalia.
Abbiamo esplorato Isolation Forest, uno strumento potente per il rilevamento delle anomalie in vari domini. Abbiamo visto come il suo approccio unico—isolare le anomalie tramite partizionamento casuale—offra vantaggi rispetto ai metodi tradizionali: gestione di dati ad alta dimensionalità, identificazione di pattern di anomalia complessi e scalabilità.
L'esempio pratico con Python e Scikit-learn ha mostrato la semplicità d'uso.
Sebbene Isolation Forest identifichi efficacemente potenziali anomalie senza conoscenze pregresse, presenta anche limitazioni, in particolare con dataset piccoli e per l'incapacità di spiegare perché specifiche istanze siano considerate anomalie.
I migliori corsi di Machine Learning!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

