
Kurs
Python ile Ağaç Tabanlı Modellerle Machine Learning
5 sa
117.2K
Yakın zamanda bankamdan bir mesaj aldım:
“Kartınıza bloke koyduk. [tutar] tutarındaki [iş yeri] işlemi size mi ait?”
Neyse ki sadece makul olmayan bir saatte çevrimiçi alışveriş yapan bendim. Ama aklıma takıldı… banka günde işlediği yüz binlerce işlem arasından şüpheli olanları nasıl işaretliyor?
Sahtekarlığı tespit etmek, makine öğrenimi (ML) alanında anomali tespiti denen daha geniş bir problemin özel bir örneğidir. Bu problemi çözmek için pek çok yöntem olsa da, bu blog yazısında en popüler yöntemlerden birine odaklanacağız: Isolation Forest.
Sahtekarlıkla mücadele, ağları savunma, aykırı değerleri bulma ve arızalı ekipmanı işaretleme farklı problemler gibi görünebilir. Ancak ortak bir özellikleri var—anomaliyi neyin oluşturduğuna dair net etiketler veya tanımlar yoktur. Çoğu durumda anomaliler nadir ve belirsizdir; çok miktardaki normal verinin arasında fark edilmeleri zordur.
Anomali tespit sistemleri geliştirmenin bir yolu öngörücü ML kullanmaktır. Örneğin, sahte işlemleri toplayabiliriz. Ardından, işlem tutarı, zamanı, konumu ve işyeri türü gibi özellikleri kullanarak bunları normal işlemlerden ayırt eden bir model kurabiliriz. Sorun şu ki bu yaklaşım, yalnızca geçmişte gördüklerimize benzeyen sahtekarlık vakalarını tespit etmemizi sağlar.
Dolandırıcılar sık sık stratejilerini değiştirir ve sahtekarlık yapmanın yeni yollarını dener. Bu stratejilerin birçoğu tamamen beklenmedik olacaktır. Bu nedenle gözetimsiz yöntemler sıklıkla anomalileri tespit etmek için kullanılır. Tüm işlemleri karşılaştırarak ve olağandışı özellik değerlerine sahip olanları belirleyerek çalışırlar. Önemli olan, önceden hiçbir işlemi etiketlememize gerek olmamasıdır.
Sınıflandırılması zor olan yalnızca sahtekarlık değildir. Üretimde makineler beklenmedik şekillerde her an arızalanabilir. Siber güvenlikte sürekli yeni saldırılar keşfedilip yamalanır. Tıpta, nadir sağlık sorunları çok sayıda test sonucu arasında gizlenebilir. Uygulamalar sınırsız; o halde bu anomalileri tespit etmeye yönelik gözetimsiz bir yaklaşımın nasıl çalıştığına bakalım.
İsminden tahmin ettiyseniz, Isolation Forest bir ağaç tabanlı yöntemdir. Random Forest’a benzerler. Ancak temel yapı taşları farklıdır.
Random Forest, gini safsızlığına dayalı bölünmeler kullanılarak oluşturulan karar ağaçlarını kullanır. Bu bir hedef değişken gerektirir; bunun yerine Isolation Forest, İzolasyon Ağaçlarını kullanır. Yöntem, her örnek için anomali puanlarını hesaplamak üzere bu ağaçlardan oluşan bir küme kullanır.
Anomali puanlarını hesaplamadan önce bu temel yapı taşının nasıl çalıştığını anlamaya değer. Diyelim ki sahte işlemleri tespit etmeye çalışıyoruz. Basit tutmak için 1000 işlemi (örnek) değerlendirip veri kümemizden iki değişkeni ele alacağız: tutar (x1) ve işlemin günün hangi saatinde yapıldığı (x2).
Bir İzolasyon Ağacı oluşturmak için kök düğümde tüm örneklerle veya bir örneklemle başlarız. Aşağıdaki Şekil 1’de 256 örnekten oluşan bir örneklemimiz olduğunu görebilirsiniz (bu sayı hakkında birazdan daha fazlası).
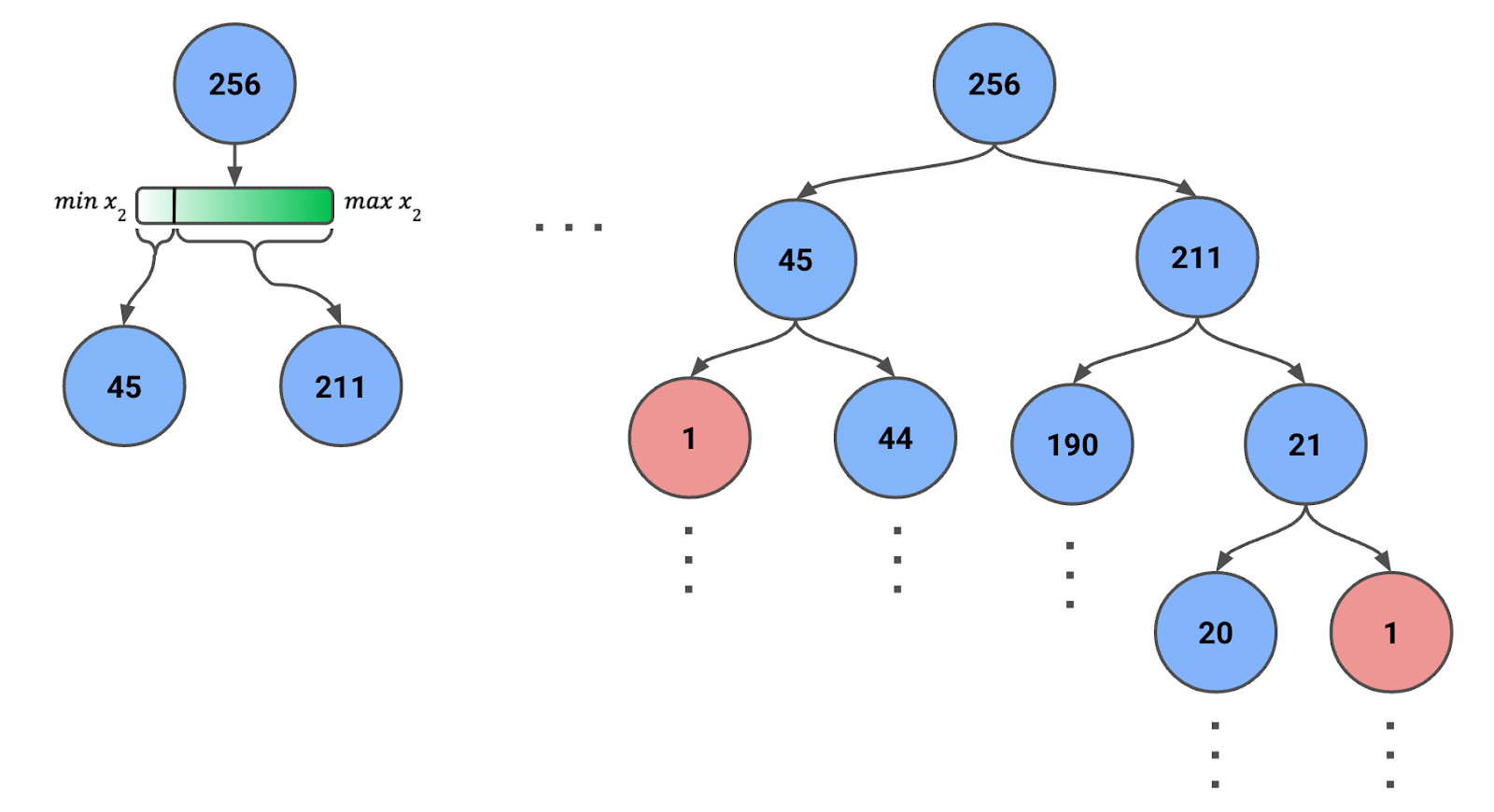
Şekil 1: Özyinelemeli rastgele bölünmelerle oluşturulan İzolasyon Ağacı. Her düğümdeki örnek sayısı verilmiştir.
Ardından şunları yaparız:
Not edin ki özellik aralığı her adımda değişecektir. Yani, düğümdeki örneklerin özelliklerinin minimum ve maksimum değerlerini kullanırız. Bu dinamik ayarlama, bölünmelerin anlamlı olmasını ve düğümlerin sıfır örnekle sonuçlanmamasını sağlar.
Şekil 2 aşağıda, bu sürecin aykırı değerleri neden izole ettiğine dair bir sezgi verir. A, B, ve C örnekleri diğer işlemlerden farklı görünüyor.
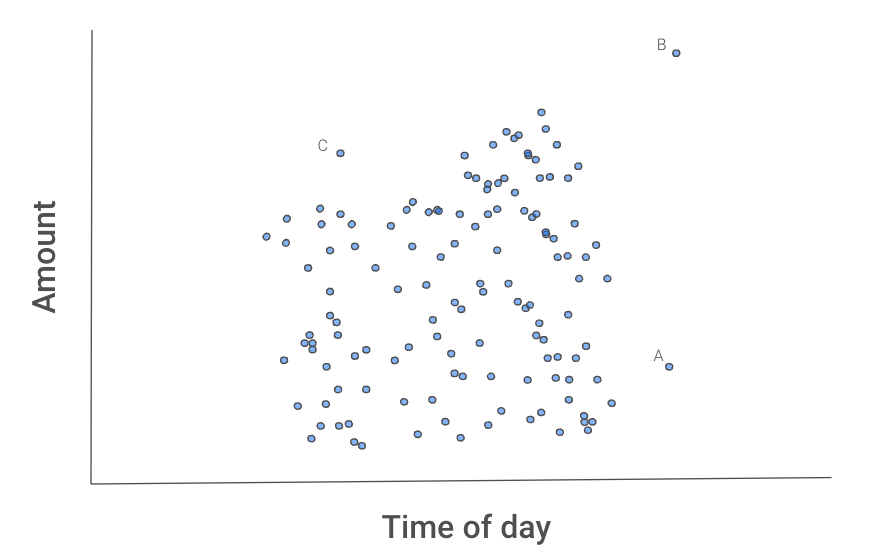
Şekil 2: İşlemlerin saçılım grafiği
B büyük olasılıkla ilk izole edilen olacaktır; çünkü herhangi bir özellikten tek bir bölünmeyle diğer işlemlerden ayrılabilir.
A için x2’den bir bölünme yeterli olurdu.
C daha uzun sürebilir; çünkü her iki özelliği kullanarak izole etmeniz gerekir. Yani C’nin hem tutarı hem zamanı normaldir; ancak günün o saati için tutarı normal değildir.
Şanslı olabilir ve bu örneklerden birini ilk denemede izole edebiliriz. Büyük olasılıkla birkaç deneme gerekecek. Önemli nokta, ortalama olarak, B’nin A’dan, A’nın da C’den daha az bölünme gerektireceği ve bu üç noktanın diğer işlemlerden daha az bölünme gerektireceği olacaktır. Peki bu ortalama davranışı nasıl yakalarız?
Bir anomalinin izole edilmesi için gereken bölünme sayısı, örneğin yaprak düğümüne olan yol uzunluğunu belirler. Bir İzolasyon Ağaçları ormanı belirli örnekler için tutarlı şekilde daha kısa yol uzunlukları veriyorsa, bu örnekler büyük olasılıkla anomalidir. Bu ortalama davranışı, tüm ağaçlar boyunca yol uzunluklarını bir araya getirerek yakalarız; buna anomali puanının hesaplanması denir.
Bir x örneği için anomali puanı hesaplamak üzere önce birkaç değeri tanımlamamız gerekir:
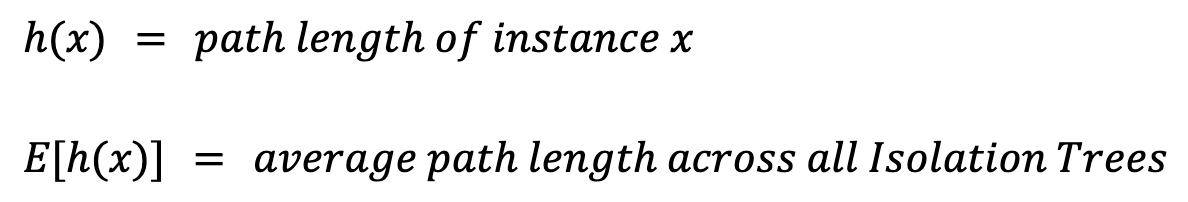
Yol uzunluğu, h(x), örneğin yaprak düğümüne ulaşmak için geçilmesi gereken kenarların (bölünmelerin) sayısıdır. Basitçe ortalamasını, E[h(x)], almak sorun yaratır. Çünkü daha fazla örneğe sahip daha büyük ağaçlar daha büyük yol uzunluklarına meyillidir. Bu, anomaliler için bile geçerlidir. Bunu dikkate almak için örneklem büyüklüğüne dayalı bir normalleştirme değerine ihtiyacımız var, n:
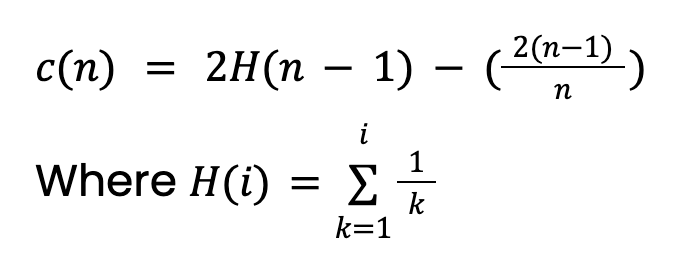
Bu değer İkili Arama Ağaçları (BST) teorisinden gelir. BST’lerde başarısız aramaların ortalama yol uzunluğunu verir. İzolasyon Ağaçlarının BST’lerle eşdeğer bir yapısı olduğundan, c(n) değerini bir örnek için beklenen yol uzunluğu (anomalik olsun olmasın) olarak alırız. Bu değerin, ağaç için azami bir derinlik belirlersek ayarlanması gerektiğini unutmayın.
Son olarak anomali puanımızı hesaplayabiliriz s(x,n):
 Puan 0 ile 1 arasında değişir ve yorumlarken üç senaryoyu dikkate almalıyız:
Puan 0 ile 1 arasında değişir ve yorumlarken üç senaryoyu dikkate almalıyız:
Başka bir deyişle, bir örneğin ortalama yol uzunluğu beklenen ortalama yol uzunluğundan kısaysa anomali puanı 1’e yaklaşır. Ancak yöntemi uygularken göreceğimiz gibi, Scikit-learn paketi puana ek ayarlamalar yapar.
Uygulamaya adım adım yaklaşalım ve içe aktarmalarla başlayalım.
Veri işleme ve görselleştirme için standart Python paketlerimiz var (satır 2-5). Ayrıca Isolation Forest’ın Scikit-learn uygulamasını (satır 7) ve veri setimizi içe aktarmak için kullanılan bir paketi (satır 8) kullanıyoruz.
# Imports
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import IsolationForest
from ucimlrepo import fetch_ucirepoVerilerimizi doğrudan UCI makine öğrenimi deposundan yüklüyoruz. Air Quality veri setini (CC BY 4.0) kullanıyoruz; bu set, İtalya’daki bir şehirdeki bir sensörden alınan 9.358 hava kalitesi ölçümünü içerir. Bu veri seti bağlamında, anomali, olağandışı derecede yüksek kirlilik seviyelerini gösteren sensör okuması olarak kabul edilebilir.
# Fetch dataset from UCI repository
air_quality = fetch_ucirepo(id=360)Modeli uygulamadan önce biraz veri temizleme yapıyoruz. Önce veri setindeki tüm özellikleri seçiyoruz (satır 2) ve ardından 4 özelliğin bir alt kümesini seçiyoruz (satır 5). Bunların hepsi havadaki farklı metal oksit kimyasallarının (yani kirleticilerin) ölçümleridir. Daha sonra eksik değer içeren satırları kaldırıyoruz (satır 8-9). Sonunda 6.941 örneğimiz kalıyor; aşağıda özellik kümesinin bir anlık görüntüsünü görebilirsiniz.
# Convert to DataFrame
data = air_quality.data.features
# Select features
features = data[['CO(GT)', 'C6H6(GT)', 'NOx(GT)', 'NO2(GT)']]
# Drop rows with missing values (-200)
features = features.replace(-200, np.nan)
features = features.dropna()
print(features.shape)
features.head()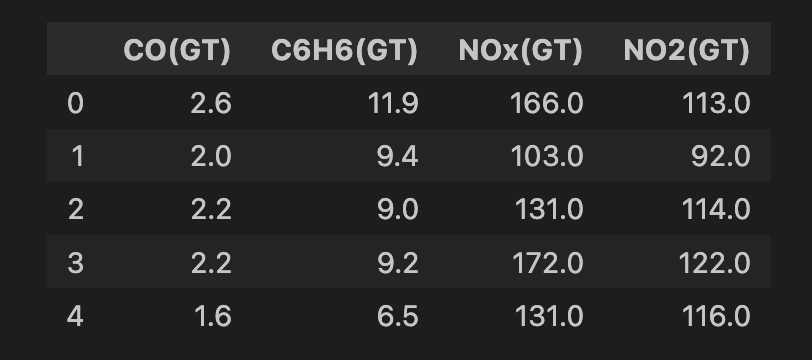
Yapılacak son şey, Isolation Forest’ı eğitmek için kullanılan parametreleri tanımlamaktır. Bu durumda aşağıdaki üç değeri kullanacağız:
n_estimators, toplulukta kullanılan İzolasyon Ağacı sayısıdır. Isolation Forest makalesinde 100 değeri kullanılmıştır. Araştırmacılar denemeler yoluyla bunun çeşitli veri setlerinde iyi sonuçlar verdiğini bulmuştur. contamination, verilerin beklenen anomali oranıdır. sample_size, her İzolasyon Ağacını eğitmek için kullanılan örnek sayısıdır. 256 değeri yaygın olarak kullanılır; çünkü azami ağaç boyutu durdurma ölçütüne ihtiyaç duymamızı önler. Bunun nedeni, makul azami ağaç boyutlarının log(256) = 8 olmasının beklenebilmesidir.Contamination değeri, diğerleri gibi sağlam bir gerekçeye sahip değildir. Önceki deneyimden gelebilir. Diyelim ki önceki analizde okumaların %1’inin yüksek kirlilik seviyelerine işaret ettiğini bulduk. Kaynak kısıtlarından da kaynaklanabilir. Örneğin, sahte işlemleri analiz ederken tüm işlemlerin yalnızca %5’ini daha ileri analiz etmeye yetecek zamanınız olabilir. Anomali puanlarını görselleştirdiğimizde, bu contamination değeri kullanılarak nasıl ayarlandıklarını göreceğiz.
# Parameters
n_estimators = 100 # Number of trees
contamination = 0.01 # Expected proportion of anomalies
sample_size = 256 # Number of samples used to train each treeSon olarak Isolation Forest’ı eğitebiliriz. Sklearn’e aşinaysanız bu süreç tanıdık gelmelidir. Modeli yukarıda tartışılan parametrelerle başlatıyoruz (satır 2-5). Ardından modeli özellik kümemiz üzerinde eğitiyoruz (satır 6).
# Train Isolation Forest
iso_forest = IsolationForest(n_estimators=n_estimators,
contamination=contamination,
max_samples=sample_size,
random_state=42)
iso_forest.fit(features)Eğitilmiş modelin iki kullanışlı fonksiyonu vardır:
decision_function, anomali puanını teori bölümünde tartıştığımıza benzer bir şekilde hesaplar. predict contamination değerlerine göre ikili bir etiket sağlar. Bizim durumumuzda, en kötü anomali puanına sahip örneklerin %1’ine -1 değeri verilecek. Diğer örneklere 1 verilir.Bu fonksiyonların çıktısını veri setimize ekliyoruz (satır 2-4). Anomali değerlerini saydığımızda (satır 6) 70 örneğin anomali olarak etiketlendiğini görüyoruz.
# Calculate anomaly scores and classify anomalies
data = data.loc[features.index].copy()
data['anomaly_score'] = iso_forest.decision_function(features)
data['anomaly'] = iso_forest.predict(features)
data['anomaly'].value_counts()Daha ileri gidip tüm anomali puanlarını görselleştirebiliriz. Bunu aşağıdaki kodla yapıyoruz:
# Visualization of the results
plt.figure(figsize=(10, 5))
# Plot normal instances
normal = data[data['anomaly'] == 1]
plt.scatter(normal.index, normal['anomaly_score'], label='Normal')
# Plot anomalies
anomalies = data[data['anomaly'] == -1]
plt.scatter(anomalies.index, anomalies['anomaly_score'], label='Anomaly')
plt.xlabel("Instance")
plt.ylabel("Anomaly Score")
plt.legend()
plt.show()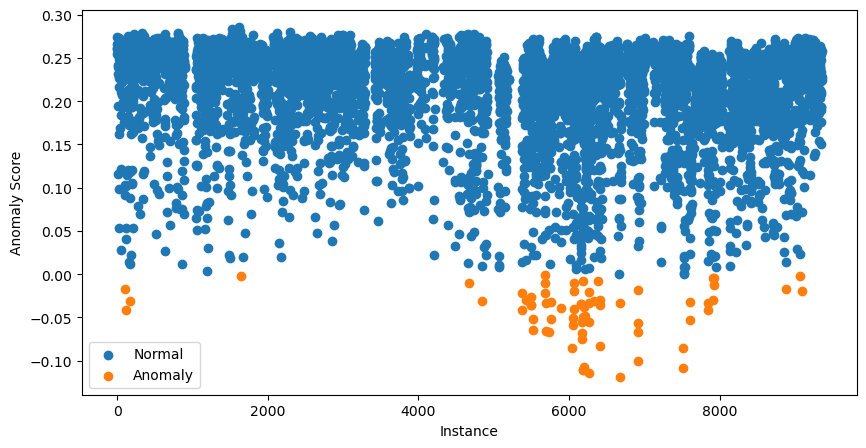
En düşük anomali puanına sahip 70 örnek turuncu renkle gösterilmiştir. Bunlar potansiyel anomalilerimizdir; bir sonraki adım bunları daha ayrıntılı incelemektir.
Bu noktada biraz kafanız karışmış olabilir. Puanların 1’e yakın olması potansiyel anomalilere işaret etmiyor muydu?
Yukarıdaki saçılım grafiğinde gördüğünüz puanlar ayarlanmıştır. Bunu yapmak için paket önce bir ofset hesaplar. Bu, contamination değerine göre anomali puanı yüzdelik dilimidir. Bizim durumumuzda ofset %0,99 yüzdelik dilim olacaktır. Son puanlar şu şekilde verilir: ofset - puan. Bunu yapmak, 0’ın altındaki tüm puanların potansiyel anomalilere işaret etmesi anlamına gelir.
Yukarıdaki saçılım grafiğini kullanarak potansiyel anomalileri belirleyebiliriz. Ancak bu, bunların neden anomali olarak sınıflandırıldığını söylemez. Bunu yapmak için daha ileri analiz gerekecektir.
Örneğin, aşağıdaki kodda tüm örneklerin CO(GT) değerlerini NO2(GT) değerlerine karşı çizerek bir saçılım grafiği oluşturuyoruz. Noktaları ayrıca anomali olarak sınıflandırılıp sınıflandırılmadıklarına göre renklendiriyoruz.
# Visualization of the results
plt.figure(figsize=(5, 5))
# Plot non-anomalies then anomalies
plt.scatter(normal['CO(GT)'], normal['NO2(GT)'], label='Normal')
plt.scatter(anomalies['CO(GT)'], anomalies['NO2(GT)'], label='Anomaly')
plt.xlabel("CO(GT)")
plt.ylabel("NO2(GT)")
plt.legend()
plt.show()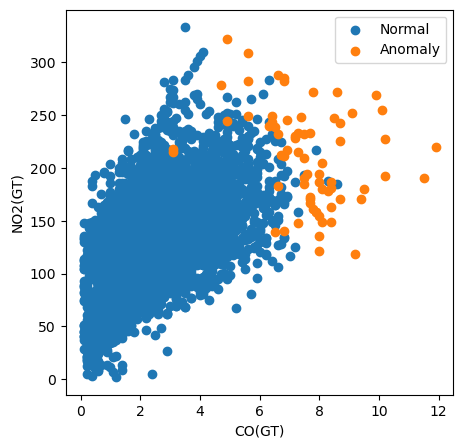
Bu grafiği kullanarak CO(GT) kirletici ölçümünün özellikle önemli olduğunu görebiliriz. Anomalilerin birçoğunun bu özellik için 6’dan büyük değere sahip olduğunu fark edin. Ancak bu, tüm anomalileri açıklamaz. Bazılarının her iki özellik için de yüksek değerleri vardır; bazıları ise bu grafikteki özelliklerin hiçbirine göre anomali gibi görünmemektedir. Bu da diğer kirleticilerin de sınıflandırmaya katkıda bulunduğunu düşündürür.
Bu bizi, Isolation Forest’ın diğer anomali tespit yöntemlerine göre başlıca avantajlarına getirir. İlki, yüksek boyutlu veriyi işleyebilmeleridir. Yukarıda gördüğümüz gibi, örnekler tüm özellikler kullanılarak anomali olarak işaretlenebilir ve yöntem dörtten çok daha fazla özellikle de iyi çalışabilir. Bir diğer önemli avantaj, çeşitli türlerde anomalileri bulabilmeleridir.
Karşılaştırma için, basit bir anomali tespit yöntemi z-skordur. Tek tek özellikleri kullanarak, özellik değerlerinin ortalamadan ne kadar uzak olduğuna göre anomalileri sınıflandırır. Ancak bu yalnızca bir tür anomalidir. Bu yaklaşım ayrıca özelliklerin normal dağılıma sahip olduğunu varsayar ve veri setimizdeki her özellik için z-skorlarını değerlendirmemizi gerektirir.
Isolation Forest ile bir özelliğin dağılımı hakkında hiçbir varsayımda bulunmayız. Sonuç olarak, ortalamadan uzak olmaktan başka nedenlerle anomalik olan örnekleri bulabiliriz. Gördüğümüz gibi, aynı anda tüm özellikleri kullanarak da sınıflandırma yapabiliriz. Bu, özellikle büyük veri setlerinde analizimizi büyük ölçüde basitleştirebilir.
Diğer hususlar arasında Isolation Forest’ın doğrusal zaman karmaşıklığına sahip olması ve gözetimsiz olması yer alır. Bu, ön bilgi olmadan büyük veri setlerinde anomalileri tespit etmek için ideal bir yöntem yapar. Bu durum, yeni tür sahtekarlıkların normal işlemler arasında sürekli ortaya çıktığı sahtekarlık tespiti gibi gerçek dünya uygulamalarında sıklıkla görülür.
Isolation Forest’ın dikkate değer bir sınırlaması, küçük veri setlerinde iyi performans göstermeyebilmesidir. Bu, İzolasyon Ağaçlarının oluşturulmasındaki rastgele süreçle ilgilidir. Normal örneklerin kısa yollara sahip olması ya da tersine, anomalilerin daha uzun yollara sahip olması her zaman olasıdır. Küçük veri setlerinde bunun gerçekleşmesi daha olasıdır. Başka bir deyişle, Isolation Forest’ın işe yaraması için rastgeleliği ortalamak adına yeterli veriye ihtiyacımız vardır.
Gördüğümüz bir diğer sınırlama ise Isolation Forest’ın yalnızca potansiyel anomalileri belirleyebilmesidir. Bize belirli örneklerin neden anomali olduğunu söylemez. Bunu yapmak için daha ileri analiz gerekir. Şimdi, karmaşık anomalileri belirleme avantajı bir zorluk olarak karşımıza çıkar. Sonuçta bir anomaliyi tam olarak açıklamak çok fazla çalışma ve alan bilgisi gerektirebilir.
Farklı alanlarda anomali tespiti için güçlü bir araç olan Isolation Forest’ı inceledik. Anomalileri rastgele bölümlere ayırarak izole etme yaklaşımının; yüksek boyutlu veriyi işleme, karmaşık anomali örüntülerini belirleme ve ölçeklenebilirliği sağlama gibi geleneksel yöntemlere göre avantajlar sunduğunu gördük.
Python ve Scikit-learn kullanılarak yapılan pratik örnek, kullanım kolaylığını gösterdi.
Isolation Forest, ön bilgi olmaksızın potansiyel anomalileri etkili bir şekilde belirleyebilse de, özellikle daha küçük veri setleriyle çalışırken ve belirli örneklerin neden anomali sayıldığını açıklayamaması bakımından sınırlamaları vardır.
En İyi Makine Öğrenimi Kursları!
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
