
Curso
Aprendizado de máquina com modelos baseados em árvores em Python
5 h
116.5K
Recentemente, recebi uma mensagem de texto do meu banco:
"Nós bloqueamos o seu cartão. A transação de [valor] no [fornecedor] é sua?"
Felizmente, era apenas eu fazendo compras on-line em um horário não razoável, mas isso me fez pensar... como o banco sinaliza transações suspeitas entre todas as centenas de milhares que processa por dia?
A identificação de fraudes é um caso específico de um problema mais amplo em aprendizado de máquina (ML) chamado detecção de anomalias. Embora existam muitos métodos para resolver esse problema, neste blog, vamos nos concentrar em um dos mais populares: Florestas de isolamento.
Combater fraudes, defender redes, encontrar exceções e sinalizar equipamentos defeituosos podem parecer problemas diferentes. Entretanto, elas compartilham uma característica comum: não há rótulos ou definições claras do que constitui uma anomalia. Em muitos casos, as anomalias são raras e sutis, o que torna difícil identificá-las em meio a grandes quantidades de dados normais.
Uma maneira de desenvolver sistemas de detecção de anomalias é usar preditivo ML. Por exemplo, poderíamos coletar transações fraudulentas. Em seguida, usando recursos como valor da transação, hora, local e tipo de comerciante, podemos criar um modelo que diferencie essas transações das normais. O problema é que essa abordagem só nos permitirá detectar casos de fraude semelhantes aos que vimos no passado.
Os fraudadores frequentemente mudam suas estratégias e tentam novas formas de cometer fraudes. Muitas dessas estratégias serão completamente inesperadas. É por isso que os métodos não supervisionados são frequentemente usados para detectar anomalias. Eles funcionam comparando todas as transações e identificando aquelas que têm valores de recursos incomuns. É importante ressaltar que isso significa que não precisamos rotular nenhuma transação previamente.
A fraude não é o único comportamento que é difícil de classificar. Na produção, as máquinas podem falhar a qualquer momento de várias maneiras inesperadas. Em segurança cibernéticaos novos ataques são constantemente descobertos e corrigidos. Em medicinaNa medicina, problemas de saúde raros podem estar ocultos em meio a muitos resultados de exames. As aplicações são infinitas, portanto, vamos ver como funciona uma abordagem não supervisionada para detectar essas anomalias.
Se você não adivinhou pelo nome, florestas de isolamento são um método baseado em árvores. Eles são semelhantes aos Random Forests. No entanto, os componentes básicos são diferentes.
Um Random Forest usa árvores de decisão criadas com divisões baseadas na impureza de gini. Isso requer uma variável de destino, portanto, em vez disso, as florestas de isolamento usam árvores de isolamento. O método usa uma coleção dessas árvores para calcular as pontuações de anomalia de cada instância.
Vale a pena entender como esse bloco de construção básico funciona antes de calcularmos as pontuações de anomalia. Digamos que estejamos tentando detectar transações fraudulentas. Para simplificar, avaliaremos 1.000 transações (instâncias) e consideraremos duas variáveis de nosso conjunto de dados: o valor ( x1) e a hora do dia (x2) de uma transação.
Para criar uma árvore de isolamento, começamos com todas as instâncias ou uma amostra delas no nó raiz. Na Figura 1 abaixo, você pode ver que temos uma amostra de 256 instâncias (mais sobre esse número posteriormente).
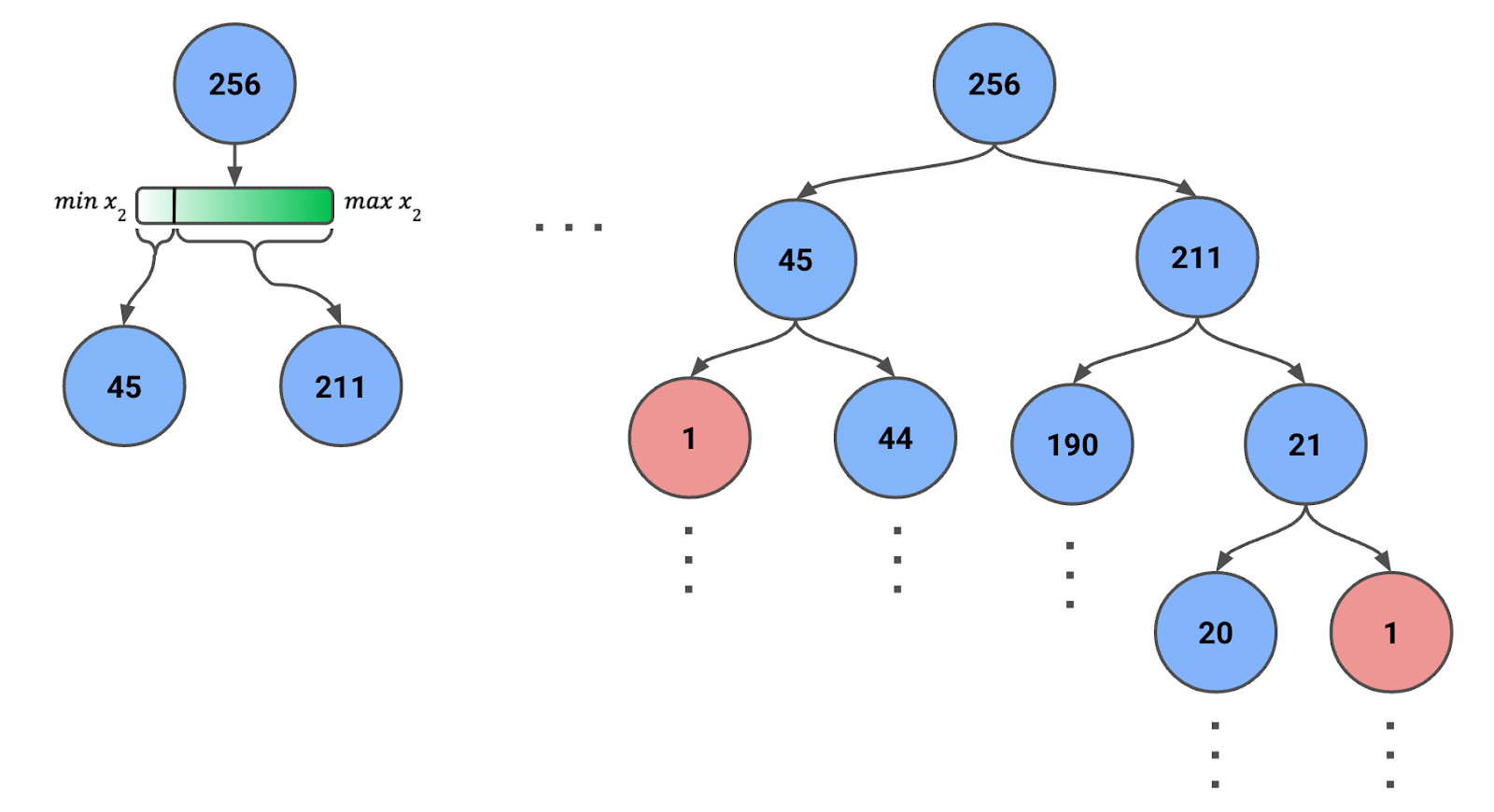
Figura 1: Árvore de isolamento criada usando divisões aleatórias recursivas. O número de instâncias em cada nó é fornecido.
Então, nós:
Observe em que o alcance do recurso mudará a cada etapa. Ou seja, usamos os valores mínimo e máximo do recurso para as instâncias do nó. Esse ajuste dinâmico garante que as divisões sejam significativas e que os nós não terminem com zero instâncias.
A Figura 2 abaixo nos dá uma ideia de por que esse processo isola os outliers. As instâncias A, B e C parecem diferentes das outras transações.
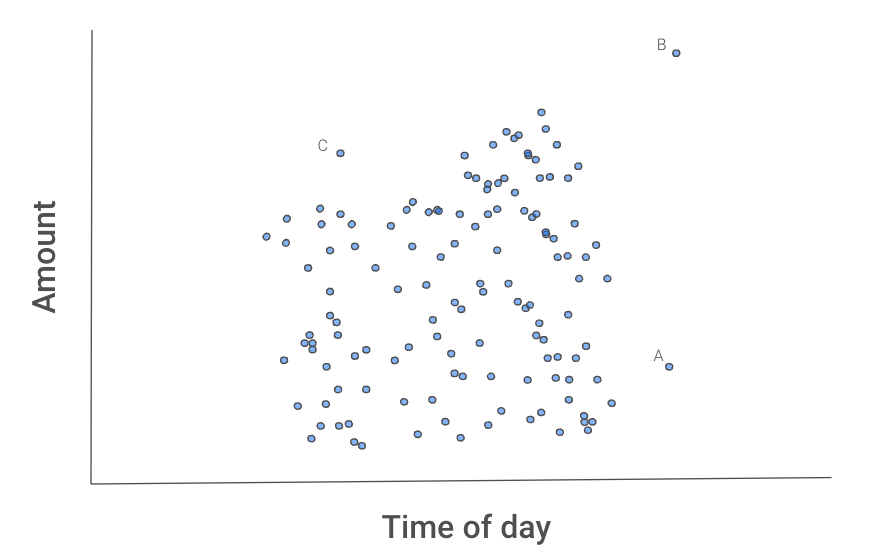
Figura 2: Gráfico de dispersão de transações
B provavelmente será isolado primeiro, pois pode ser separado das outras transações usando uma divisão de qualquer recurso.
A receberia uma divisão de x2.
C pode demorar mais, pois você precisaria isolá-lo usando os dois recursos. Ou seja, C tem uma quantidade e um horário normais, mas não uma quantidade normal para aquele horário do dia.
Talvez tenhamos sorte e isolemos uma dessas instâncias na primeira tentativa. Provavelmente, você precisará de algumas tentativas. O ponto importante é que, em média,, B levará menos divisões do que A, A menos divisões do que C, e todos os três pontos levarão menos divisões do que as outras transações. Mas como podemos capturar esse comportamento médio?
O número de divisões necessárias para isolar uma anomalia determina o comprimento do caminho até o nó folha da instância. Quando uma floresta de árvores de isolamento produz consistentemente comprimentos de caminho mais curtos para amostras específicas, é provável que essas amostras sejam anomalias. Capturamos esse comportamento médio agregando os comprimentos de caminho em todas as árvores, um processo conhecido como cálculo de uma pontuação de anomalia.
Para calcular uma pontuação de anomalia para uma instância xprecisamos primeiro definir alguns valores:
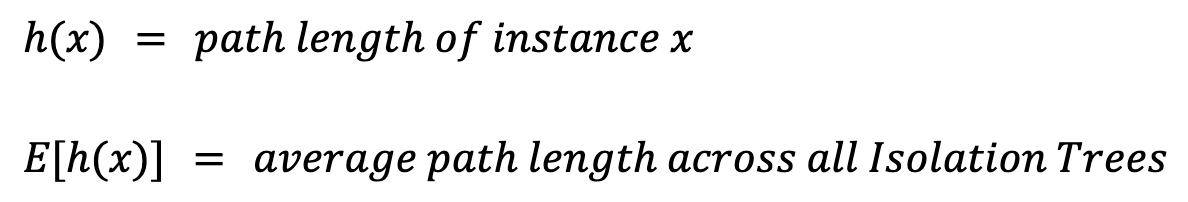
O comprimento do caminho, h(x), é o número de bordas (divisões) que devem ser percorridas para alcançar o nó folha da instância. Se você simplesmente tirar a média, E[h(x)], terá problemas. Isso ocorre porque árvores maiores, com mais instâncias, tendem a ter comprimentos de caminho maiores. Isso é verdadeiro até mesmo para anomalias. Para levar isso em conta, precisamos de um valor de normalização com base no tamanho da amostra n:
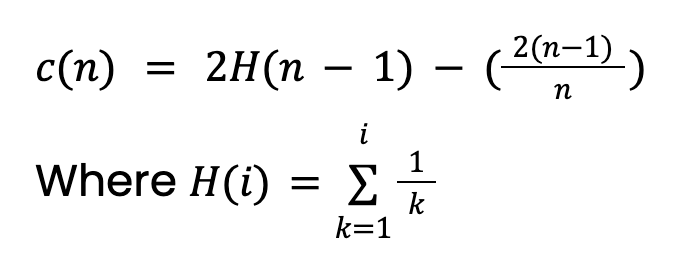
Esse valor vem da teoria de Árvores de pesquisa binária (BST). Ele fornece o comprimento médio do caminho de buscas malsucedidas no BST. Como as árvores de isolamento têm uma estrutura equivalente às BSTs, consideramos c(n) como o comprimento do caminho esperado para uma instância (com anomalia ou não). Observe que esse valor precisará ser ajustado se definirmos uma profundidade máxima para a árvore.
Por fim, podemos calcular nossa pontuação de anomalia s(x,n):
 A pontuação varia entre 0 e 1 e, ao interpretá-la, devemos considerar três cenários:
A pontuação varia entre 0 e 1 e, ao interpretá-la, devemos considerar três cenários:
Em outras palavras, quando o comprimento médio do caminho de uma instância for menor do que o comprimento médio esperado do caminho, a pontuação da anomalia será mais próxima de 1. No entanto, como veremos ao implementar o método, o Scikit-learn faz outros ajustes na pontuação.
Vamos abordar a implementação passo a passo e começar com as importações.
Temos pacotes Python padrão para manipulação e visualização de dados (linhas 2-5). Também estamos usando a implementação do Scikit-learn do Isolation Forest (linha 7) e o pacote final é usado para importar nosso conjunto de dados (linha 8).
# Imports
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import IsolationForest
from ucimlrepo import fetch_ucirepoCarregamos nossos dados diretamente do repositório de aprendizado de máquina da UCI. Estamos usando o Qualidade do ar (CC BY 4.0), que contém 9.358 instâncias de medições da qualidade do ar de um sensor em uma cidade italiana. No contexto desse conjunto de dados, uma anomalia pode ser considerada uma leitura de sensor que indica níveis excepcionalmente altos de poluição.
# Fetch dataset from UCI repository
air_quality = fetch_ucirepo(id=360)Fazemos uma limpeza dos dados antes de aplicar o modelo. Começamos selecionando todos os recursos do conjunto de dados (linha 2) e, em seguida, selecionamos um subconjunto de 4 recursos (linha 5). Todas essas são medidas de diferentes produtos químicos de óxido de metal no ar (ou seja, poluentes). Em seguida, eliminamos todas as linhas que têm valores ausentes (linhas 8-9). No final, temos 6.941 instâncias e você pode ver um instantâneo do conjunto de recursos abaixo.
# Convert to DataFrame
data = air_quality.data.features
# Select features
features = data[['CO(GT)', 'C6H6(GT)', 'NOx(GT)', 'NO2(GT)']]
# Drop rows with missing values (-200)
features = features.replace(-200, np.nan)
features = features.dropna()
print(features.shape)
features.head()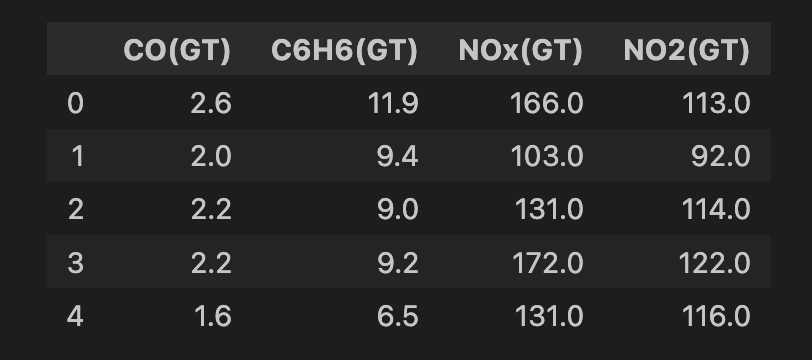
A última coisa a fazer é definir os parâmetros usados para treinar o Isolation Forest. Nesse caso, usaremos os três valores abaixo:
n_estimators é o número de árvores de isolamento usadas no conjunto. Um valor de 100 é usado no documento Isolation Forest. Por meio de experimentos, os pesquisadores descobriram que isso produzia bons resultados em uma variedade de conjuntos de dados. contamination é a porcentagem de pontos de dados que esperamos que sejam anomalias. sample_size é o número de instâncias usadas para treinar cada árvore de isolamento. Um valor de 256 é comumente usado, pois nos permite evitar o uso de um critério de parada de tamanho máximo de árvore. Isso ocorre porque podemos esperar tamanhos máximos de árvore razoáveis de log(256) = 8.O valor de contaminação não tem uma justificativa sólida como os outros valores. Isso pode vir de experiências anteriores. Suponha que, na análise anterior, tenhamos encontrado 1% das leituras que indicam altos níveis de poluição. Isso também pode ocorrer devido a restrições de recursos. Por exemplo, ao analisar transações fraudulentas, você pode ter tempo suficiente para analisar apenas 5% de todas as transações. Quando visualizarmos as pontuações de anomalia, veremos como elas são ajustadas usando esse valor de contaminação.
# Parameters
n_estimators = 100 # Number of trees
contamination = 0.01 # Expected proportion of anomalies
sample_size = 256 # Number of samples used to train each treePor fim, podemos treinar o Isolation Forest. Se você conhece o Sklearn, esse processo deve parecer familiar. Inicializamos o modelo usando os parâmetros discutidos acima (linhas 2-5). Em seguida, treinamos o modelo em nosso conjunto de recursos (linha 6).
# Train Isolation Forest
iso_forest = IsolationForest(n_estimators=n_estimators,
contamination=contamination,
max_samples=sample_size,
random_state=42)
iso_forest.fit(features)O modelo treinado tem duas funções úteis:
decision_function calculará a pontuação de anomalia de modo semelhante ao que discutimos na seção de teoria. predict fornecerá um rótulo binário com base nos valores de contaminação. No nosso caso, o 1% de instâncias com as piores pontuações de anomalia receberá um valor de -1. As outras instâncias recebem um valor de 1.Adicionamos o resultado dessas funções ao nosso conjunto de dados (linhas 2-4). Quando contamos os valores de anomalia (linha 6), vemos que 70 das instâncias são rotuladas como anomalias.
# Calculate anomaly scores and classify anomalies
data = data.loc[features.index].copy()
data['anomaly_score'] = iso_forest.decision_function(features)
data['anomaly'] = iso_forest.predict(features)
data['anomaly'].value_counts()Podemos ir além e visualizar todas as pontuações de anomalias. Fazemos isso usando o código abaixo:
# Visualization of the results
plt.figure(figsize=(10, 5))
# Plot normal instances
normal = data[data['anomaly'] == 1]
plt.scatter(normal.index, normal['anomaly_score'], label='Normal')
# Plot anomalies
anomalies = data[data['anomaly'] == -1]
plt.scatter(anomalies.index, anomalies['anomaly_score'], label='Anomaly')
plt.xlabel("Instance")
plt.ylabel("Anomaly Score")
plt.legend()
plt.show()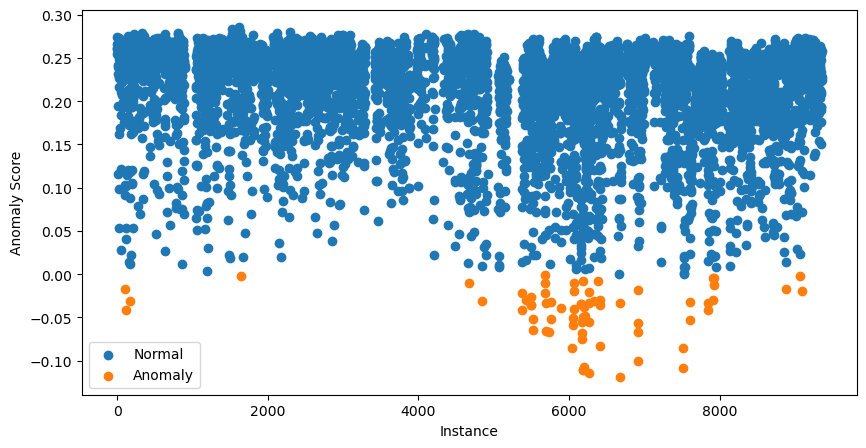
As 70 instâncias com as pontuações de anomalia mais baixas são apresentadas em laranja. Essas são nossas possíveis anomalias e a próxima etapa é investigá-las mais a fundo.
A essa altura, você pode estar um pouco confuso. Não dissemos que pontuações próximas a 1 indicam possíveis anomalias?
As pontuações que você vê no gráfico de dispersão acima foram ajustadas. Para fazer isso, o pacote primeiro calcula umdeslocamento . Esse é o percentil da pontuação de anomalia com base no valor de contaminação. No nosso caso, o deslocamento será o percentil 0,99. As pontuações finais são dadas por offset - score. Isso significa que todas as pontuações abaixo de 0 sugerem possíveis anomalias.
Usando o gráfico de dispersão acima, podemos identificar possíveis anomalias. No entanto, isso não nos diz por que elas foram classificadas como anomalias. Para isso, precisaremos fazer uma análise mais aprofundada.
Por exemplo, no código abaixo, criamos um gráfico de dispersão de todas as instâncias plotando seu valor de CO(GT) versus seu valor de NO2(GT). Também colorimos os pontos com base no fato de eles terem sido classificados como anomalias.
# Visualization of the results
plt.figure(figsize=(5, 5))
# Plot non-anomalies then anomalies
plt.scatter(normal['CO(GT)'], normal['NO2(GT)'], label='Normal')
plt.scatter(anomalies['CO(GT)'], anomalies['NO2(GT)'], label='Anomaly')
plt.xlabel("CO(GT)")
plt.ylabel("NO2(GT)")
plt.legend()
plt.show()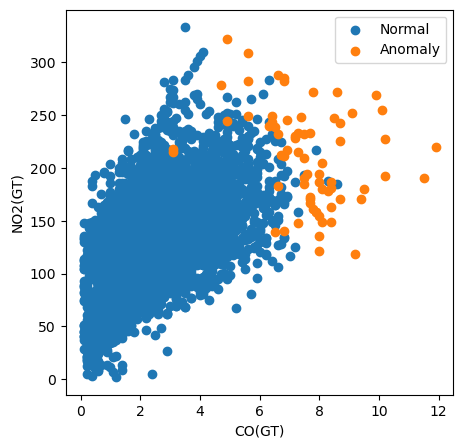
Usando esse gráfico, podemos ver que a medição do poluente CO(GT) é particularmente importante. Observe que muitas das anomalias têm um valor maior que 6 para esse recurso. No entanto, isso não explica todas as anomalias. Alguns têm valores altos para ambos os recursos e outros não parecem ser anomalias devido a nenhum dos recursos nesse gráfico. Isso sugere que outros poluentes também contribuíram para a classificação.
Isso nos leva às principais vantagens do Isolation Forests em relação a outros métodos de detecção de anomalias. A primeira é que eles podem lidar com dados de alta dimensão. Como vimos acima, as instâncias podem ser sinalizadas como anomalias usando todos os recursos, e o método pode funcionar bem com muito mais do que quatro recursos. Outra vantagem importante é que eles podem encontrar anomalias de vários tipos.
Para fins de comparação, um método simples de detecção de anomalias é o z-score. Usando recursos individuais, isso classificará as anomalias com base na distância entre os valores dos recursos e sua média. No entanto, esse é apenas um tipo de anomalia. Essa abordagem também pressupõe que os recursos têm uma distribuição normal e exige que avaliemos os escores z de cada recurso em nosso conjunto de dados.
Com o Isolation Forests, não fazemos nenhuma suposição sobre a distribuição de um recurso. O resultado é que podemos encontrar instâncias que são anomalias por outros motivos além de estarem longe da média. Como vimos, também podemos fazer classificações usando todos os recursos simultaneamente. Isso pode simplificar drasticamente nossa análise, especialmente com grandes conjuntos de dados.
Outras considerações são que o Isolation Forest tem uma complexidade de tempo linear complexidade de tempo e não é supervisionado. Isso o torna um método ideal para detectar anomalias sem conhecimento prévio em grandes conjuntos de dados. Esse é frequentemente o caso em aplicativos do mundo real, como detecção de fraudesem que novos tipos de fraude surgem continuamente em meio a um mar de transações normais.
Uma limitação notável do Isolation Forest é que ele pode não ter um desempenho tão bom com conjuntos de dados pequenos. Isso tem a ver com o processo aleatório no qual as árvores de isolamento são criadas. Sempre há uma chance de que as instâncias normais tenham caminhos curtos ou, ao contrário, que as anomalias tenham caminhos mais longos. Com conjuntos de dados pequenos, é mais provável que isso aconteça. Em outras palavras, para que as Isolation Forests funcionem, precisamos de dados suficientes para calcular a média da aleatoriedade.
Outra limitação, como vimos, é que o Isolation Forest só pode identificar possíveis anomalias. Isso não nos diz nada sobre por que certas instâncias são anômalas. Para isso, precisamos fazer uma análise mais aprofundada. Agora, a vantagem de identificar anomalias complexas representará um desafio. Por fim, pode ser necessário muito trabalho e conhecimento do domínio para explicar completamente uma anomalia.
Exploramos o Isolation Forest, uma ferramenta poderosa para a detecção de anomalias em vários domínios. Vimos como sua abordagem exclusiva - isolar anomalias por meio de particionamento aleatório - oferece vantagens sobre os métodos tradicionais: lidar com dados de alta dimensão, identificar padrões complexos de anomalias e garantir a escalabilidade.
O exemplo prático usando Python e Scikit-learn demonstrou a facilidade de uso.
Embora o Isolation Forest possa identificar com eficácia possíveis anomalias sem conhecimento prévio, ele também tem limitações, principalmente ao lidar com conjuntos de dados menores e sua incapacidade de explicar por que instâncias específicas são consideradas anomalias.
Os melhores cursos de aprendizado de máquina!
Curso
Curso
Curso
Tutorial
Kevin Babitz
Tutorial
Abid Ali Awan
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali
Tutorial
DataCamp Team
Tutorial
Moez Ali
