
Kurs
Maschinelles Lernen mit baumbasierten Modellen in Python
5 Std.
116.4K
Kürzlich bekam ich eine SMS von meiner Bank:
“Wir haben deine Karte vorübergehend gesperrt. Ist die Transaktion über [Betrag] bei [Händler] von dir?”
Zum Glück war es nur mein eigener Online-Einkauf zu einer fragwürdigen Uhrzeit. Trotzdem fragte ich mich: Wie markiert die Bank unter Hunderttausenden täglicher Vorgänge ausgerechnet die verdächtigen?
Betrugserkennung ist ein Spezialfall eines größeren Problems im Maschinellen Lernen (ML) namens Anomalieerkennung. Es gibt viele Methoden, dieses Problem zu lösen. In diesem Blog schauen wir uns eine der populärsten näher an: Isolation Forests.
Betrug bekämpfen, Netzwerke schützen, Ausreißer finden oder defekte Geräte markieren — all das wirkt zunächst verschieden. Gemeinsam ist diesen Fällen jedoch, dass es keine klaren Labels oder Definitionen dafür gibt, was eine Anomalie ist. Oft sind Anomalien selten und subtil — schwer zu erkennen in der Masse normaler Daten.
Ein Weg zur Anomalieerkennung ist prädiktives ML. Man könnte beispielsweise bekannte Betrugsfälle sammeln und mit Merkmalen wie Betrag, Uhrzeit, Ort und Händlertyp ein Modell bauen, das diese von normalen Transaktionen unterscheidet. Das Problem: Damit finden wir nur Betrug, der früheren Fällen ähnelt.
Betrüger passen ihre Taktiken an und probieren Neues. Vieles davon ist völlig unerwartet. Darum kommen häufig unüberwachte Methoden zum Einsatz. Sie vergleichen alle Transaktionen und identifizieren solche mit ungewohnten Merkmalswerten. Der Clou: Wir müssen vorher nichts labeln.
Nicht nur Betrug lässt sich schwer klassifizieren. In der Fertigung können Maschinen jederzeit auf unerwartete Weise ausfallen. In der Cybersicherheit tauchen stetig neue Angriffe auf und werden wieder gepatcht. In der Medizin können seltene Krankheitsbilder in vielen Testergebnissen untergehen. Die Anwendungsfälle sind endlos — schauen wir uns also an, wie ein unüberwachter Ansatz diese Anomalien erkennt.
Wie der Name vermuten lässt, sind Isolation Forests eine baum-basierte Methode. Sie sind mit Random Forests verwandt, basieren aber auf anderen Bausteinen.
Ein Random Forest nutzt Entscheidungsbäume mit Splits basierend auf Gini-Impurität. Dafür braucht man eine Zielvariable. Isolation Forests setzen stattdessen Isolation Trees ein. Ein Ensemble solcher Bäume liefert dann für jede Instanz einen Anomaliescore.
Bevor wir Anomaliescores berechnen, lohnt sich ein Blick auf diesen Grundbaustein. Nehmen wir an, wir wollen betrügerische Transaktionen erkennen. Zur Vereinfachung betrachten wir 1.000 Transaktionen (Instanzen) und zwei Variablen: den Betrag (x1) und die Tageszeit (x2).
Ein Isolation Tree startet mit allen oder einem Sample der Instanzen in der Wurzel. In Abbildung 1 siehst du ein Sample von 256 Instanzen (warum 256, gleich mehr).
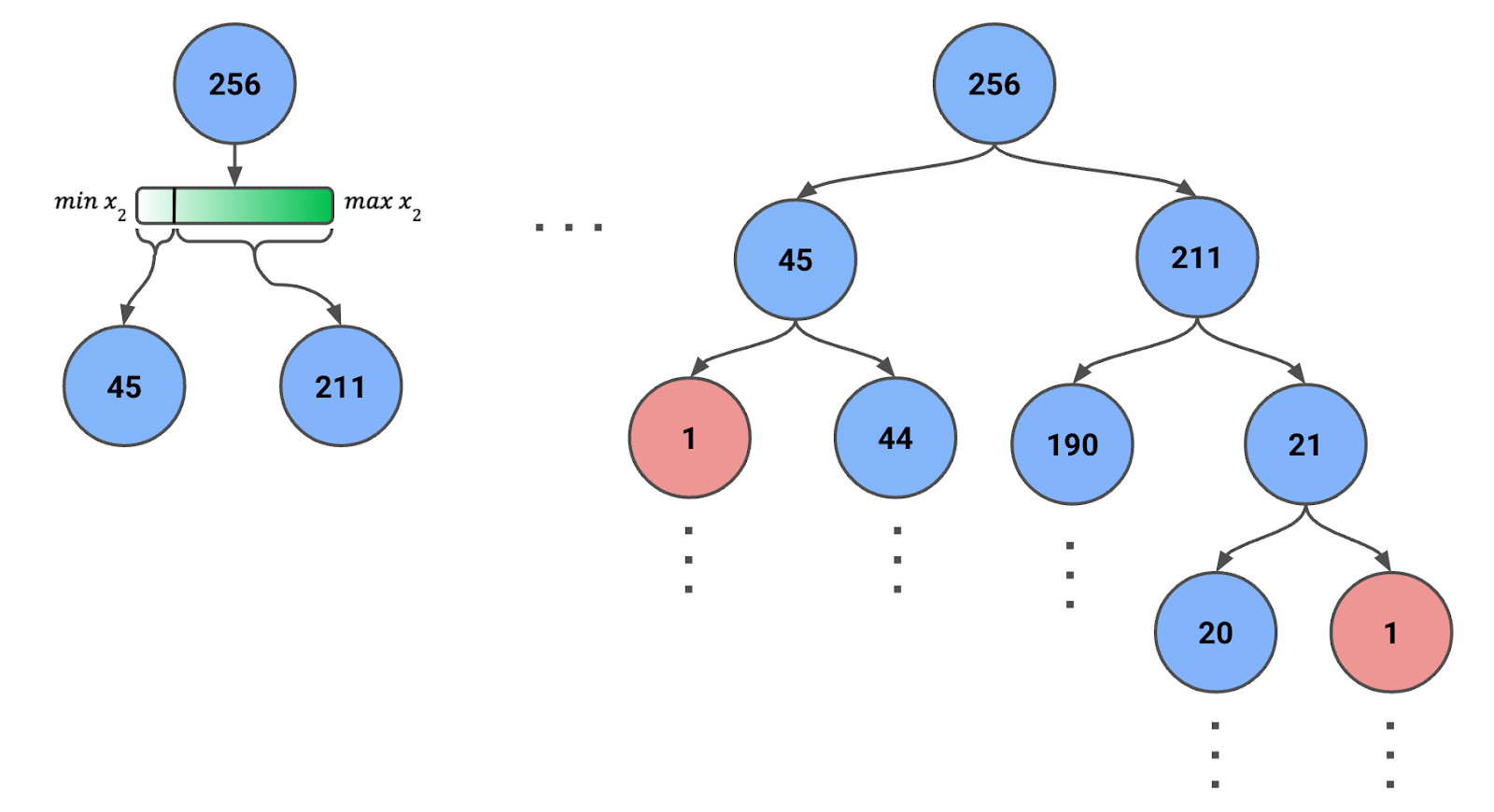
Abbildung 1: Isolation Tree mit rekursiven Zufallssplits. Die Instanzanzahl je Knoten ist angegeben.
Dann gehen wir so vor:
Beachte, dass sich der Wertebereich eines Features bei jedem Schritt ändert. Wir verwenden jeweils das Minimum und Maximum des Features innerhalb der Instanzen des aktuellen Knotens. Diese dynamische Anpassung sorgt für sinnvolle Splits und verhindert leere Knoten.
Abbildung 2 vermittelt ein Gefühl dafür, warum dieser Prozess Ausreißer isoliert. Die Instanzen A, B, und C unterscheiden sich vom Rest.
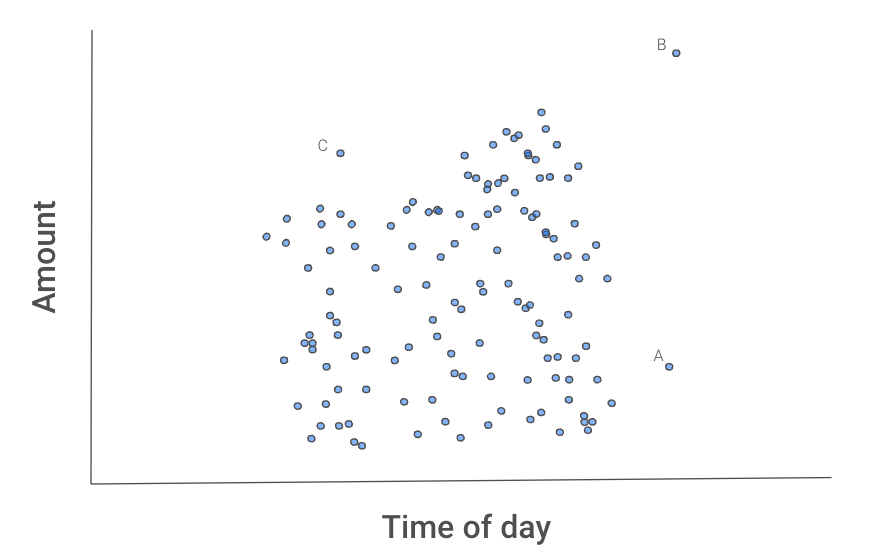
Abbildung 2: Streudiagramm der Transaktionen
B wird sich vermutlich als erstes isolieren lassen, denn hier reicht ein Split in einem der beiden Features.
A ließe sich mit einem Split in x2 trennen.
Bei C dauert es länger, da beide Features genutzt werden müssen: C hat sowohl einen normalen Betrag als auch eine normale Uhrzeit, aber keinen normalen Betrag für genau diese Uhrzeit.
Vielleicht haben wir Glück und isolieren eine Instanz direkt beim ersten Versuch — meist braucht es mehrere. Wichtig ist: Im Schnitt braucht B weniger Splits als A, A weniger als C, und alle drei benötigen weniger Splits als normale Transaktionen. Aber wie fassen wir dieses Durchschnittsverhalten zusammen?
Die Anzahl der Splits bis zur Isolation einer Anomalie bestimmt die Pfadlänge bis zum Blattknoten der Instanz. Ergibt ein Wald aus Isolation Trees für bestimmte Stichproben konsistent kürzere Pfade, sind diese Stichproben wahrscheinlich Anomalien. Dieses Verhalten erfassen wir, indem wir die Pfadlängen über alle Bäume aggregieren — das ist der Anomaliescore.
Um für eine Instanz x den Score zu berechnen, definieren wir zunächst ein paar Werte:
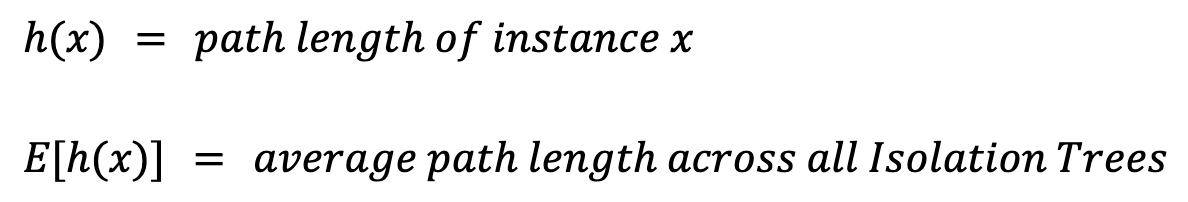
Die Pfadlänge h(x) ist die Anzahl der Kanten (Splits) bis zum Blatt der Instanz. Ein einfaches Mittel E[h(x)] bereitet Probleme, weil größere Bäume mit mehr Instanzen tendenziell längere Pfade haben — auch bei Anomalien. Daher benötigen wir eine Normalisierung in Abhängigkeit der Samplegröße n:
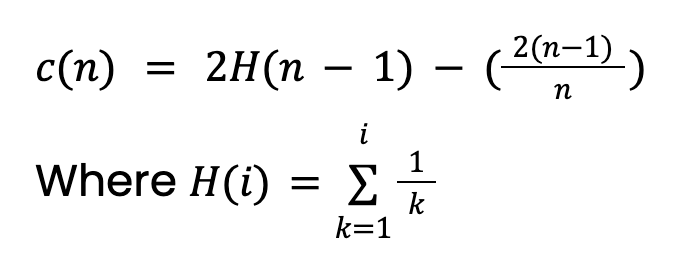
Dieser Wert stammt aus der Theorie der Binary Search Trees (BST). Er gibt die durchschnittliche Pfadlänge erfolgloser Suchen in BST an. Da Isolation Trees strukturell ähnlich sind, nehmen wir c(n) als erwartete Pfadlänge für eine Instanz (ob Anomalie oder nicht). Hinweis: Setzen wir eine maximale Baumtiefe, muss der Wert angepasst werden.
Damit können wir den Anomaliescore s(x,n) berechnen:
 Der Score liegt zwischen 0 und 1. Bei der Interpretation helfen drei Fälle:
Der Score liegt zwischen 0 und 1. Bei der Interpretation helfen drei Fälle:
Heißt: Ist die durchschnittliche Pfadlänge kürzer als erwartet, nähert sich der Score 1. In der Praxis nimmt das Scikit-learn-Paket jedoch noch Anpassungen am Score vor.
Gehen wir die Implementierung Schritt für Schritt durch und beginnen mit den Imports.
Wir verwenden Standard-Python-Pakete für Datenverarbeitung und Visualisierung (Zeilen 2–5). Außerdem die Scikit-learn-Implementierung von Isolation Forest (Zeile 7) und zuletzt ein Paket zum Laden unseres Datensatzes (Zeile 8).
# Imports
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import IsolationForest
from ucimlrepo import fetch_ucirepoWir laden die Daten direkt aus dem UCI Machine Learning Repository. Wir nutzen den Datensatz Air Quality (CC BY 4.0) mit 9.358 Messwerten zur Luftqualität eines Sensors in einer italienischen Stadt. Hier kann eine Anomalie als Sensormessung mit außergewöhnlich hoher Verschmutzung gelten.
# Fetch dataset from UCI repository
air_quality = fetch_ucirepo(id=360)Vor dem Modelltraining bereinigen wir die Daten. Zuerst wählen wir alle Features aus dem Datensatz (Zeile 2) und anschließend eine Teilmenge aus vier Features (Zeile 5). Das sind Messungen verschiedener Metalloxid-Schadstoffe in der Luft. Danach entfernen wir Zeilen mit fehlenden Werten (Zeilen 8–9). Am Ende bleiben 6.941 Instanzen übrig — unten siehst du einen Ausschnitt der Features.
# Convert to DataFrame
data = air_quality.data.features
# Select features
features = data[['CO(GT)', 'C6H6(GT)', 'NOx(GT)', 'NO2(GT)']]
# Drop rows with missing values (-200)
features = features.replace(-200, np.nan)
features = features.dropna()
print(features.shape)
features.head()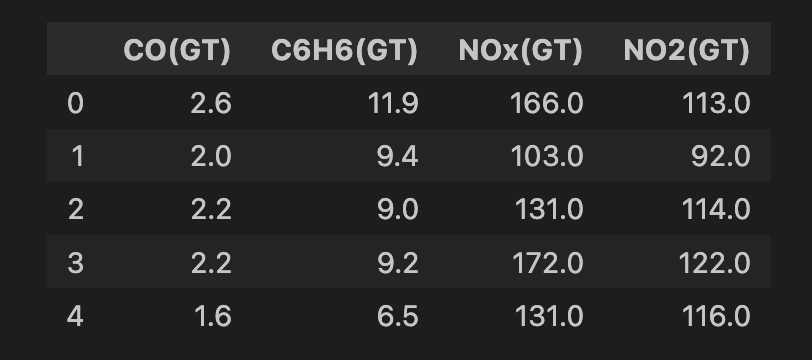
Zum Schluss definieren wir die Parameter für das Training des Isolation Forest. Wir verwenden diese drei Werte:
n_estimators gibt die Anzahl der Isolation Trees im Ensemble an. Ein Wert von 100 wurde im Isolation-Forest-Paper verwendet und lieferte in Tests über viele Datensätze gute Ergebnisse. contamination ist der erwartete Anteil an Anomalien in den Daten. sample_size ist die Zahl der Instanzen pro Isolation Tree. 256 ist ein gängiger Wert, da man so meist ohne maximale Baumtiefe auskommt. Erwartbar sind maximale Tiefen um log(256) = 8.Der Kontaminationswert ist weniger eindeutig begründbar. Er kann aus Erfahrung stammen — etwa wenn frühere Analysen zeigen, dass 1% der Messungen hohe Verschmutzung anzeigen. Oder aus Kapazitätsgründen: In der Betrugserkennung kannst du z. B. nur 5% aller Fälle näher prüfen. Bei der Visualisierung siehst du, wie der Wert die Scores beeinflusst.
# Parameters
n_estimators = 100 # Number of trees
contamination = 0.01 # Expected proportion of anomalies
sample_size = 256 # Number of samples used to train each treeJetzt trainieren wir das Modell. Wenn dir Sklearn vertraut ist, kommt dir der Ablauf bekannt vor: Wir initialisieren mit den obigen Parametern (Zeilen 2–5) und fitten auf dem Featureset (Zeile 6).
# Train Isolation Forest
iso_forest = IsolationForest(n_estimators=n_estimators,
contamination=contamination,
max_samples=sample_size,
random_state=42)
iso_forest.fit(features)Das trainierte Modell bietet zwei nützliche Funktionen:
decision_function berechnet den Anomaliescore ähnlich wie in der Theorie beschrieben. predict liefert ein binäres Label basierend auf dem Kontaminationswert. In unserem Fall erhalten die 1% der Instanzen mit den schlechtesten Scores den Wert -1, alle anderen 1.Wir fügen die Ausgaben unserem Dataset hinzu (Zeilen 2–4). Die Zählung der Anomalielabels (Zeile 6) zeigt: 70 Instanzen sind als Anomalien markiert.
# Calculate anomaly scores and classify anomalies
data = data.loc[features.index].copy()
data['anomaly_score'] = iso_forest.decision_function(features)
data['anomaly'] = iso_forest.predict(features)
data['anomaly'].value_counts()Anschließend visualisieren wir alle Scores mit folgendem Code:
# Visualization of the results
plt.figure(figsize=(10, 5))
# Plot normal instances
normal = data[data['anomaly'] == 1]
plt.scatter(normal.index, normal['anomaly_score'], label='Normal')
# Plot anomalies
anomalies = data[data['anomaly'] == -1]
plt.scatter(anomalies.index, anomalies['anomaly_score'], label='Anomaly')
plt.xlabel("Instance")
plt.ylabel("Anomaly Score")
plt.legend()
plt.show()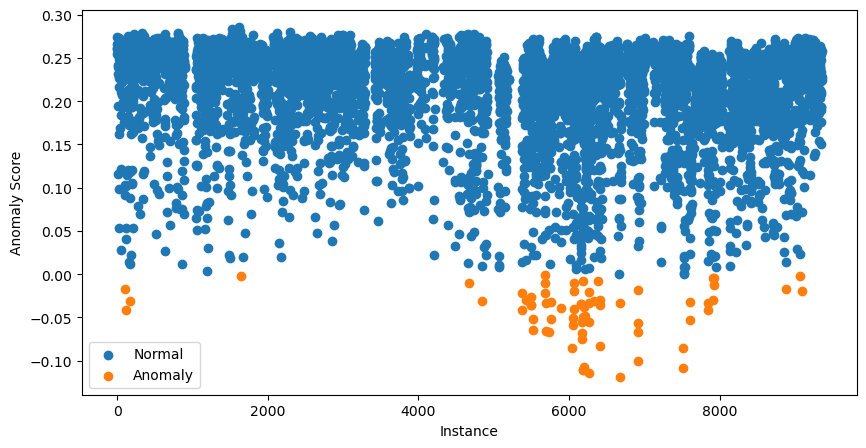
Die 70 Instanzen mit den niedrigsten Scores sind orange markiert. Das sind unsere potenziellen Anomalien — der nächste Schritt ist die Detailanalyse.
An dieser Stelle könnte Verwirrung entstehen: Sagten wir nicht, dass Werte nahe 1 auf Anomalien hindeuten?
Die in der Grafik gezeigten Scores sind angepasst. Dafür berechnet das Paket zunächst ein Offset: den Score-Prozentrang basierend auf der Kontamination. Bei uns also das 0,99-Perzentil. Die finalen Scores sind dann Offset - Score. So deuten alle Werte unter 0 auf potenzielle Anomalien hin.
Mit dem obigen Plot identifizieren wir potenzielle Anomalien, wissen aber noch nicht, warum sie so klassifiziert wurden. Dafür benötigen wir weitere Analysen.
Im folgenden Beispiel plotten wir alle Instanzen über CO(GT) vs. NO2(GT) und färben nach Klassifikation.
# Visualization of the results
plt.figure(figsize=(5, 5))
# Plot non-anomalies then anomalies
plt.scatter(normal['CO(GT)'], normal['NO2(GT)'], label='Normal')
plt.scatter(anomalies['CO(GT)'], anomalies['NO2(GT)'], label='Anomaly')
plt.xlabel("CO(GT)")
plt.ylabel("NO2(GT)")
plt.legend()
plt.show()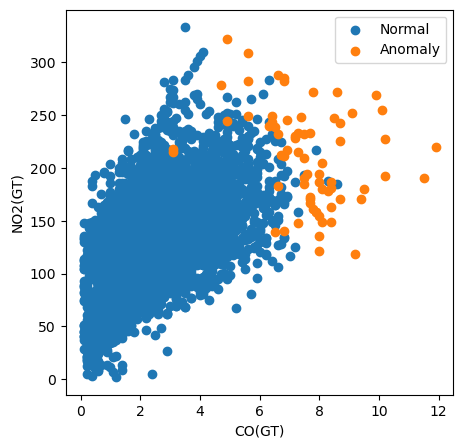
Hier wird deutlich, dass CO(GT) besonders wichtig ist: Viele Anomalien haben für dieses Feature Werte über 6. Das erklärt aber nicht alle Fälle. Einige haben hohe Werte in beiden Features, andere wirken hier nicht auffällig — offenbar tragen auch weitere Schadstoffe zur Klassifikation bei.
Daraus ergeben sich zentrale Vorteile gegenüber anderen Methoden. Erstens kann Isolation Forest hochdimensionale Daten gut verarbeiten. Wie gesehen, können alle Features gemeinsam zur Einstufung beitragen — und das auch bei weit mehr als vier Merkmalen. Zweitens erkennt die Methode unterschiedliche Arten von Anomalien.
Zum Vergleich: Ein einfacher Ansatz ist der z-Score. Pro Feature klassifiziert er Anomalien danach, wie weit ein Wert vom Mittel entfernt ist. Das deckt aber nur eine Anomalieform ab, setzt Normalverteilung voraus und erfordert die Prüfung aller Features separat.
Isolation Forest macht keine Annahmen zur Verteilung. So finden wir Instanzen, die aus anderen Gründen auffällig sind als nur „weit weg vom Mittel“. Zudem erfolgt die Klassifikation simultan über alle Features. Das vereinfacht Analysen deutlich — besonders bei großen Datensätzen.
Weitere Pluspunkte: Isolation Forest hat lineare Zeitkomplexität und arbeitet unüberwacht. Ideal also, um ohne Vorwissen in großen Daten Anomalien zu entdecken — wie etwa bei der Betrugserkennung, wo neue Betrugsarten laufend inmitten vieler normaler Transaktionen auftauchen.
Eine erkennbare Schwäche zeigt sich bei kleinen Datensätzen. Aufgrund der zufälligen Split-Erzeugung können normale Instanzen kurze Pfade haben oder Anomalien längere. Bei wenig Daten fällt das stärker ins Gewicht. Isolation Forest braucht also genug Daten, um die Zufälligkeit „auszumitteln“.
Außerdem identifiziert Isolation Forest, wie gesehen, nur potenzielle Anomalien — nicht das Warum. Für Erklärungen ist Zusatzanalyse nötig. Gerade die Fähigkeit, komplexe Anomalien zu finden, macht die Erklärung herausfordernd. Oft braucht es viel Arbeit und Domänenwissen, um eine Anomalie vollständig zu erklären.
Wir haben Isolation Forest als leistungsfähiges Werkzeug zur Anomalieerkennung in verschiedenen Domänen erkundet. Der Ansatz — Anomalien durch zufällige Partitionierung zu isolieren — bringt klare Vorteile gegenüber klassischen Methoden: Er meistert hochdimensionale Daten, erkennt komplexe Muster und skaliert gut.
Das Praxisbeispiel mit Python und Scikit-learn zeigte zugleich die einfache Anwendung.
Isolation Forest identifiziert effektiv potenzielle Anomalien ohne Vorwissen, hat aber Grenzen — insbesondere bei kleinen Datensätzen und weil es keine Gründe für die Einstufung liefert.
Top-Kurse zu Machine Learning!
Kurs
Kurs
Kurs
Tutorial
Matt Crabtree
Tutorial
Aditya Sharma
Tutorial
Mark Pedigo
Tutorial
Allan Ouko
Tutorial
Laiba Siddiqui
Tutorial
Adel Nehme


