
Cursus
Inference for Linear Regression in R
4 Hr
16K
Lineaire regressie is een van de eenvoudigste machinelearningtechnieken. Het houdt in dat je de waarde van een afhankelijke variabele voorspelt op basis van een of meer onafhankelijke variabelen.
Zo kun je met lineaire regressie bijvoorbeeld huizenprijzen voorspellen op basis van de grootte van het huis, of het gewicht van een persoon op basis van hun lengte. Lineaire regressiemodellen worden grofweg ingedeeld in twee typen: enkelvoudige en meervoudige lineaire regressie.
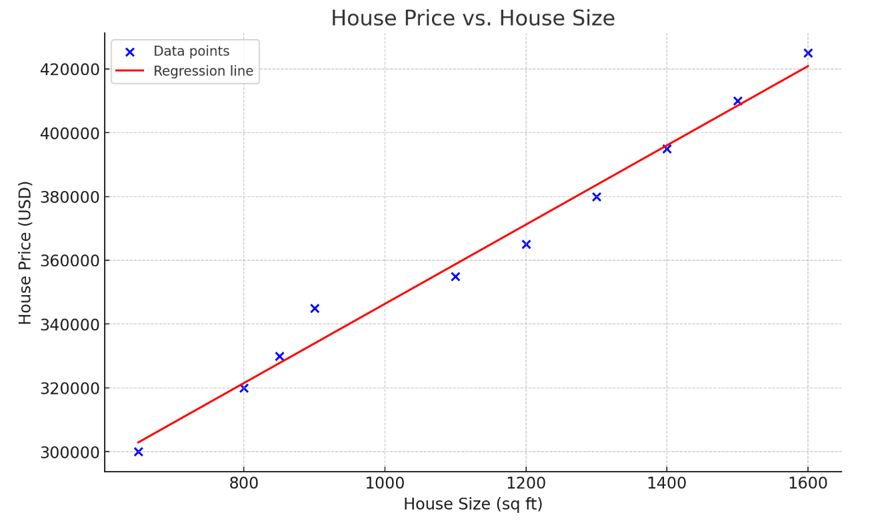
Afbeelding door OpenAI
De bovenstaande grafiek toont enkelvoudige lineaire regressie, waarbij de relatie wordt gemodelleerd tussen de grootte van een huis (onafhankelijke variabele) en de huizenprijs (afhankelijke variabele). Zoals in de visualisatie te zien is, geldt: hoe groter het huis, hoe hoger de prijs.
De vergelijking van de regressielijn is:
y = mx + c + ⍷
Als de bovenstaande formule je bekend voorkomt, komt dat doordat je op school waarschijnlijk hebt geleerd dat y = mx + c de vergelijking van een rechte lijn is. In deze vergelijking:
⍷ staat voor de residu- of foutterm. Dit is het verschil tussen de werkelijke waarde en de door het regressiemodel voorspelde waarde. Deze term onderscheidt een regressielijn van een puur deterministische rechte lijn, waardoor de relatie tussen x en y niet perfect voorspelbaar is.
Voor een uitgebreidere gids over dit onderwerp, lees ons artikel over de basis van lineaire regressie.
Hier zijn enkele factoren die van Excel een effectief hulpmiddel maken voor het uitvoeren van lineaire regressie:
Vanaf 2024 wordt Excel gebruikt door meer dan 731.000 bedrijven in de Verenigde Staten en nog veel meer wereldwijd, aldus Statista. Managers op alle organisatieniveaus gebruiken Excel voor databeheer en rapportage.
Door voorspellende modellen zoals lineaire regressie in Excel te bouwen, kunnen bedrijven hun rapportage- en voorspellingsactiviteiten op één platform bundelen. Zo kunnen organisaties hun workflows stroomlijnen in plaats van voortdurend te hoeven schakelen tussen programmeeromgevingen en Excel-spreadsheets.
Als je een beginner bent in de datawereld, kan het idee om een voorspellend model te bouwen intimiderend lijken vanwege de benodigde code. Excel vereenvoudigt dit proces, zodat je kunt werken in een omgeving die je al kent. Met Excel wordt het opzetten van een lineair regressiemodel een eenvoudig proces dat je in slechts een paar klikken kunt uitvoeren.
Excel biedt sterke visualisatiemogelijkheden, waarmee je de relatie tussen verschillende variabelen kunt grafisch weergeven om ze beter te begrijpen. Daarnaast vereenvoudigt het het maken van rapporten, zodat visualisaties eenvoudig kunnen worden opgenomen in PowerPoint-presentaties voor effectieve communicatie met stakeholders.
Voordat je met deze tutorial begint, download je de dataset in deze GitHub-repository. Deze dataset is speciaal door OpenAI gemaakt voor educatieve doeleinden. Basisvaardigheden met spreadsheets, zoals gegevens invoeren, eenvoudige formules toepassen en navigeren tussen werkbladen, helpen je om deze tutorial beter te volgen.
We moeten eerst de Data Analysis ToolPak in Excel inschakelen. Dit is een Excel-invoegtoepassing die verschillende analysetools biedt, waaronder de tool die we voor lineaire regressie gaan gebruiken.
Open hiervoor eerst het Excel-bestand en ga naar Bestand -> Opties. Selecteer in het dialoogvenster Opties Invoegtoepassingen -> Excel-invoegtoepassingen en klik op Starten:
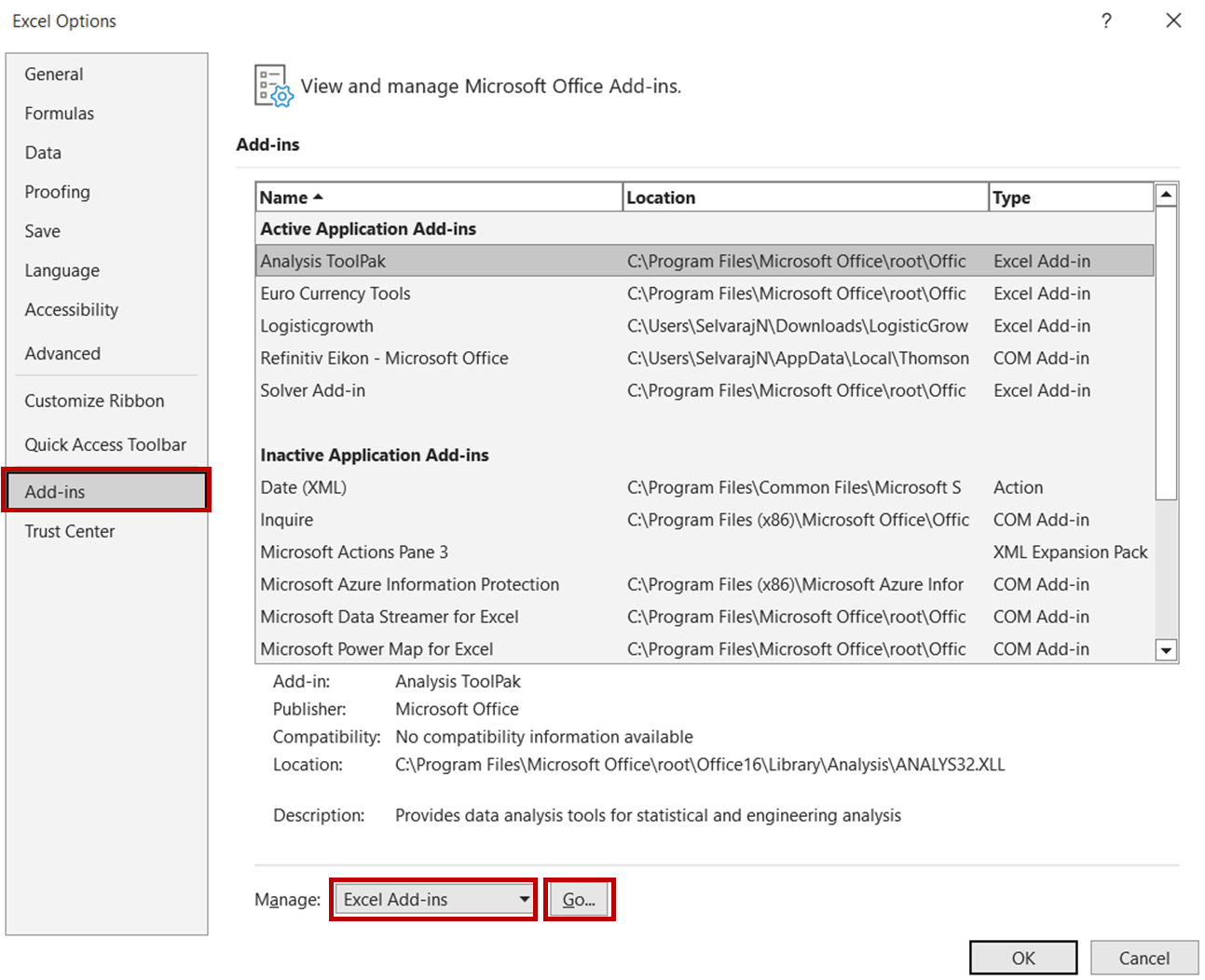
Vink in het dialoogvenster Invoegtoepassingen de optie Analysis ToolPak aan en klik op OK.
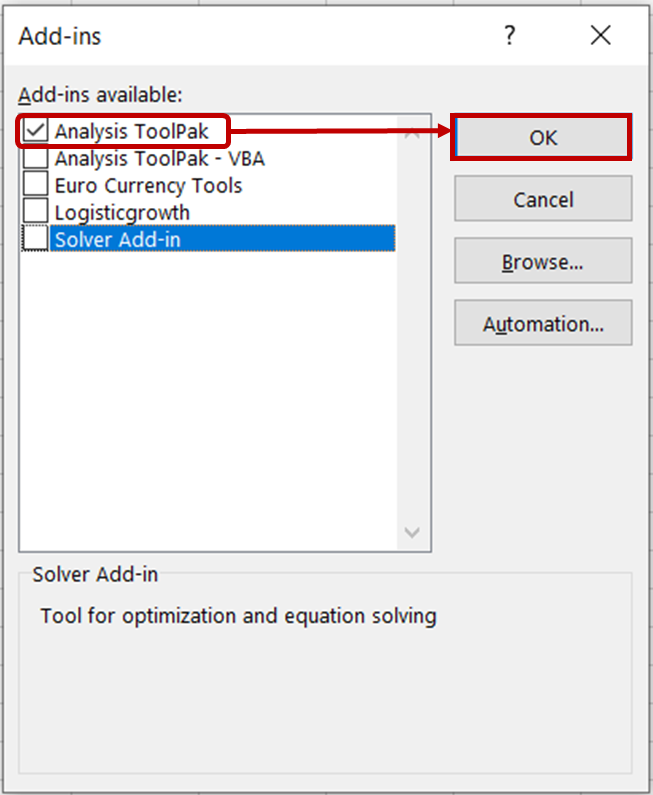
Je zou nu in het tabblad Gegevens de tools Gegevensanalyse moeten zien.
Nu we de Data Analysis ToolPak hebben ingeschakeld, kunnen we lineaire regressie uitvoeren op de dataset. Open de ijsverkoop-dataset en ga naar het tabblad Gegevens. Klik in de groep Analyse op Gegevensanalyse.

Selecteer vervolgens Regressie in de lijst met analysetools en klik op OK.
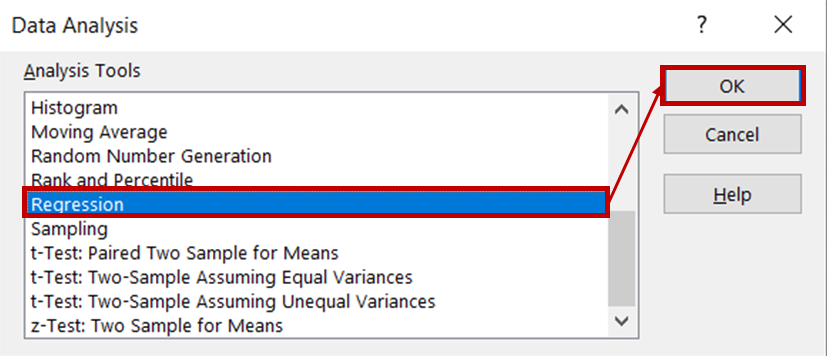
Selecteer in het regressiedialoogvenster bij Invoerbereik Y de kolom met gegevens over ijsverkoop. Selecteer bij Invoerbereik X de kolommen met temperatuur- en prijsgegevens. Zorg dat het vakje Labels is aangevinkt, zodat Excel de kopteksten herkent en de resterende rijen als numerieke gegevens behandelt. Selecteer in het gedeelte Uitvoeropties Nieuw werkblad om de resultaten in een nieuw werkblad te laten weergeven.
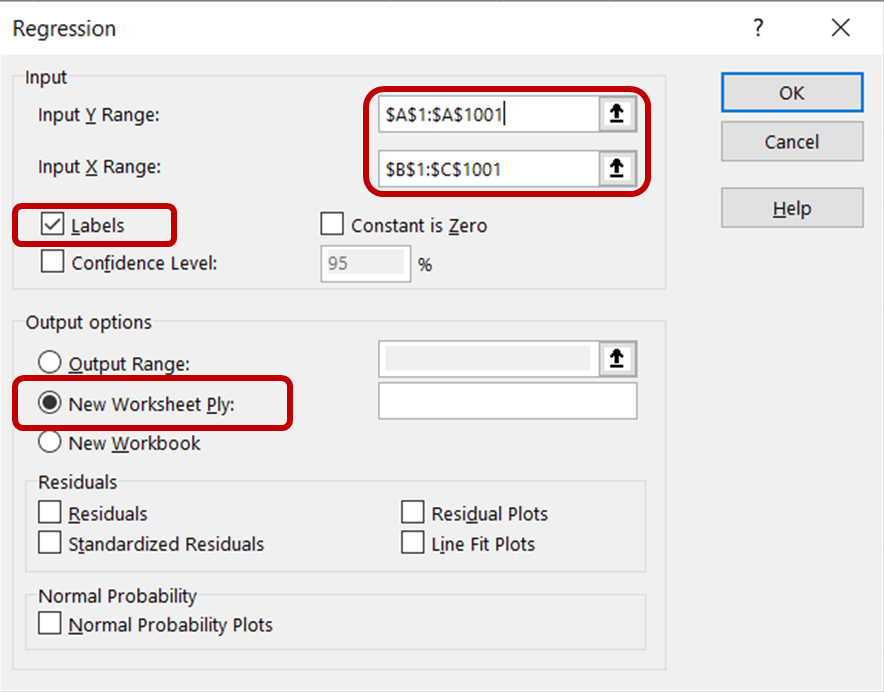
Klik vervolgens op OK om de regressieanalyse op de dataset uit te voeren.
Na het uitvoeren van de regressie verschijnt er automatisch een nieuw werkblad in het Excel-bestand met een reeks resultaattabellen die er ongeveer zo uitzien:
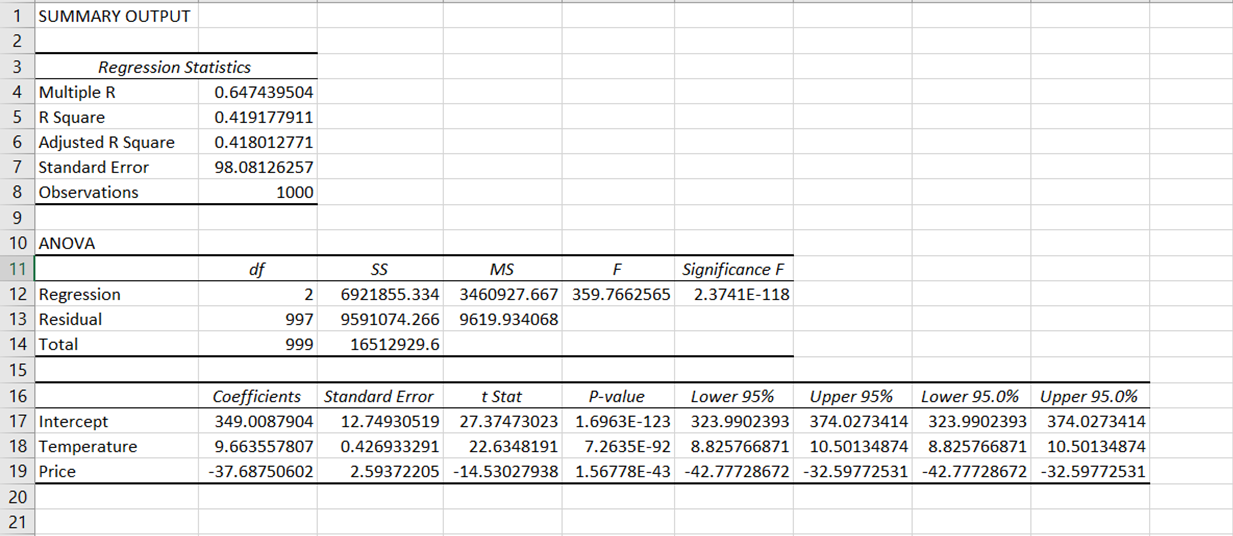
De resultaten van de regressie-uitvoer zijn opgesplitst in verschillende onderdelen: regressiestatistieken, ANOVA, coëfficiënten, standaardfout, t Stat, p-waarde en betrouwbaarheidsinterval.
Laten we elk van deze onderdelen nader bekijken:
Excel rapporteert de volgende samenvattende statistieken als resultaat van de regressieanalyse:
Multiple R
Dit is een correlatiecoëfficiënt die de sterkte en richting van een lineaire relatie tussen variabelen meet. De waarde ligt tussen -1 en 1, waarbij waarden dicht bij -1 of 1 op een sterke relatie duiden en waarden rond 0 op geen correlatie.
In onze analyse is de correlatiecoëfficiënt ongeveer 0,65, wat wijst op een matige positieve correlatie tussen onze afhankelijke variabele (ijsverkoop) en de onafhankelijke variabelen (prijs en temperatuur).
R Square
R2 is een statistische maat die aangeeft hoe goed de data past bij het regressiemodel. Het is het kwadraat van de correlatiecoëfficiënt, Multiple R, en vertegenwoordigt het aandeel van de variantie in de afhankelijke variabele dat kan worden verklaard door de onafhankelijke variabelen.
R2 ligt tussen 0 en 1, waarbij waarden dichter bij 1 op een betere modelpassing duiden. Onze R2 is ongeveer 0,419, wat betekent dat circa 41,9% van de variantie in ijsverkoop door het model kan worden verklaard.
Aangepaste R Square
Dit is de R-kwadraatwaarde gecorrigeerd voor het aantal voorspellers in het model. Het is doorgaans een betere maat bij het vergelijken van modellen met een verschillend aantal voorspellers. In ons geval is de aangepaste R2 0,418. Dit is zeer vergelijkbaar met onze R2, wat suggereert dat de onafhankelijke variabelen die we hebben opgenomen (temperatuur en prijs) relevant zijn voor het model en geen grote straf hebben geïntroduceerd.
Standaardfout
De standaardfout meet de gemiddelde afstand waarmee de geobserveerde waarden van de regressielijn afwijken. Een kleinere standaardfout is beter, omdat dit betekent dat de regressielijn beter op de data past.
In ons geval is de standaardfout ongeveer 98,05, wat aangeeft dat de werkelijke ijsverkoopwaarden ongeveer 98,05 eenheden afwijken van de voorspelde waarden.
Waarnemingen
Dit verwijst naar het totale aantal datapunten (rijen) dat in de dataset is geanalyseerd, exclusief eventuele kopteksten.
ANOVA staat voor Analysis of Variance. Het is een statistische techniek die informatie geeft over de mate van variatie binnen een regressiemodel via:
Vrijheidsgraden (df)
Dit staat voor het aantal waarden in de uiteindelijke berekening dat vrij kan variëren. In de context van ANOVA verwijst “Regressie”-df naar het aantal onafhankelijke variabelen in het model, namelijk 2. “Residueel”-df wordt berekend door het aantal onafhankelijke variabelen en 1 af te trekken van het totale aantal waarnemingen. In ons geval is dit 997.
Som van kwadraten (SS)
Dit kwantificeert variatie. “Regressie-SS” meet de variatie in de afhankelijke variabele die door het model kan worden verklaard. “Residuele SS” vertegenwoordigt de onverklaarde variatie.
Gemiddelde kwadraatsom (MS)
Dit wordt verkregen door de som van kwadraten (SS) te delen door de vrijheidsgraden (df).
F-statistiek (F)
Deze statistiek bepaalt de algehele significantie van het model. Een hogere F-waarde geeft aan dat het model beter bij de data past.
Significance F
Dit is de p-waarde die hoort bij de F-statistiek. Een zeer kleine p-waarde (kleiner dan 0,05) duidt erop dat je model beter bij de data past dan een model zonder onafhankelijke variabelen. In ons geval is de Significance F-waarde lager dan 0,05, wat aangeeft dat het model goed bij de data past.
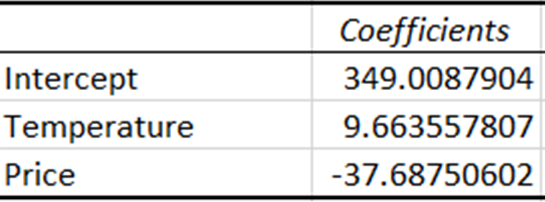
Coëfficiënten vertegenwoordigen de geschatte verandering in de afhankelijke variabele bij een verandering van één eenheid in de onafhankelijke variabele.
De coëfficiënt voor temperatuur geeft aan dat bij elke toename van één eenheid in temperatuur de verkoop met circa 9,66 eenheden toeneemt. Omgekeerd geeft de coëfficiënt voor prijs aan dat de verkoop met ongeveer 37,69 eenheden afneemt bij een toename van één eenheid in prijs.
De standaardfout meet de gemiddelde afstand tussen de geobserveerde waarden en de regressielijn. Een lagere standaardfout wijst op een beter model.
De t-statistiek is de coëfficiënt gedeeld door de standaardfout ervan. Een grotere t-statistiek geeft aan dat de coëfficiënt verschilt van nul, wat impliceert dat deze een grotere impact heeft op de afhankelijke variabele.
P-waarden vertellen ons de kans om een t-statistiek te observeren die net zo extreem is als de geobserveerde, onder de aanname dat de nulhypothese waar is (d.w.z. dat de coëfficiënt voor een onafhankelijke variabele 0 is).
Simpel gezegd: hoe groter de t-statistiek en hoe kleiner de p-waarde, des te sterker het bewijs tegen de nulhypothese, wat ondersteunt dat de onafhankelijke variabelen (prijs en temperatuur) een statistisch significant effect hebben op de afhankelijke variabele (ijsverkoop).
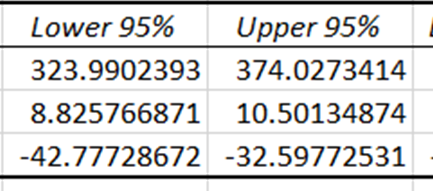
Betrouwbaarheidsintervallen geven de onder- en bovengrenzen waarbinnen de werkelijke coëfficiënten van de onafhankelijke variabelen naar verwachting vallen, met een betrouwbaarheid van 95%. Omdat de betrouwbaarheidsintervallen voor prijs en temperatuur verschillen van nul, hebben deze coëfficiënten een statistisch significant effect bij het voorspellen van ijsverkoop.
Het visualiseren van de relatie tussen twee variabelen kan je begrip van de dataset sterk verbeteren. Hoewel de Analysis ToolPak van Excel gedetailleerde samenvattende statistieken biedt, kan een grafische weergave in één oogopslag de sterkte en richting van een relatie tussen variabelen tonen.
Een spreidingsdiagram met een trendlijn is een effectieve manier om deze relatie te visualiseren en kan in minder dan vijf minuten worden gemaakt. Met deze visualisatie zie je in één oogopslag hoe de ene variabele de andere beïnvloedt.
Zo visualiseer je de relatie tussen “Ice Cream Sales” en “Temperature”:
Markeer eerst de cellen met de variabelen “Ice Cream Sales” en “Temperature”. Ga vervolgens naar het tabblad “Invoegen” en klik op het pictogram “Spreiding”:
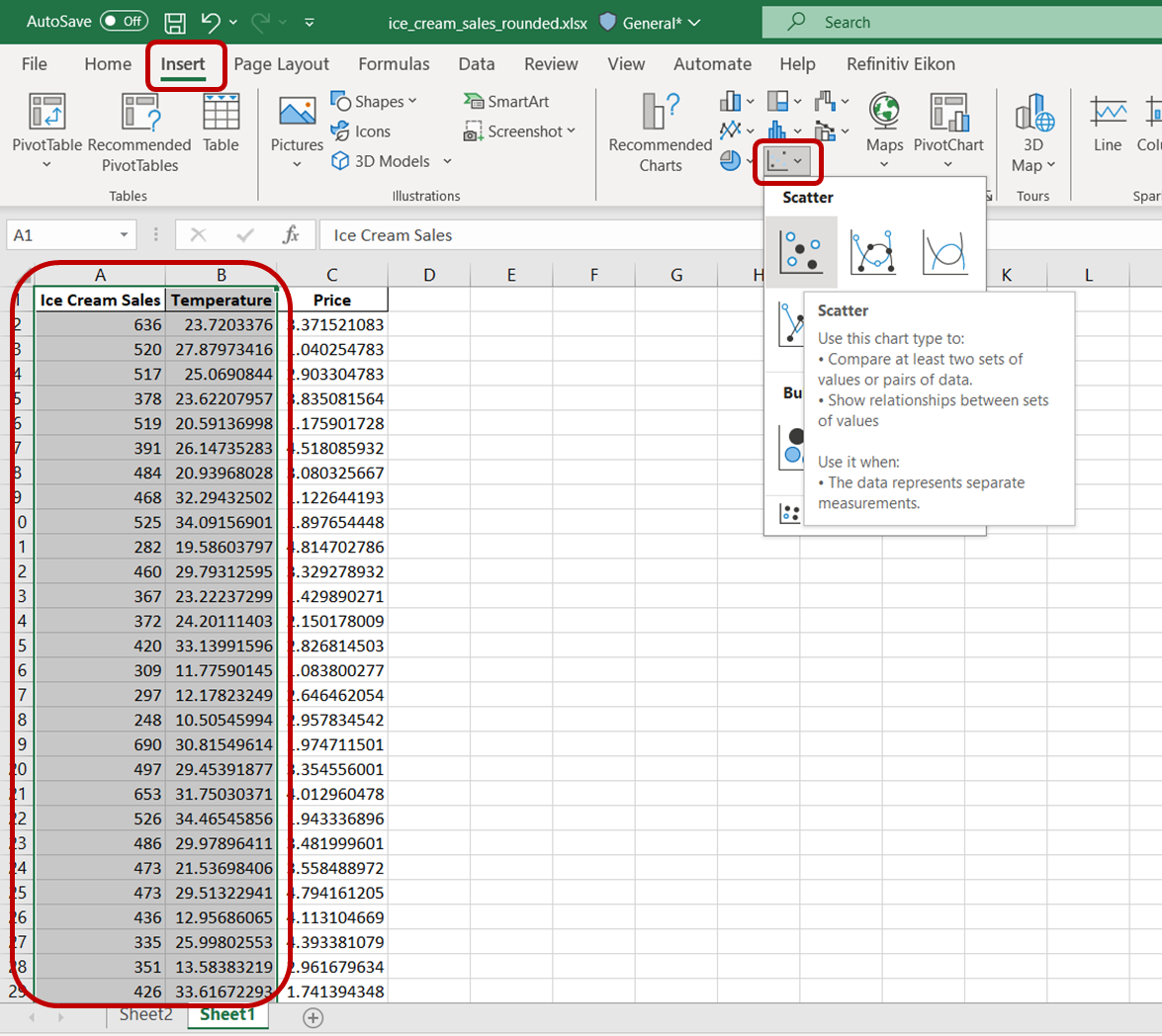
Je ziet een eenvoudig spreidingsdiagram dat er zo uitziet:
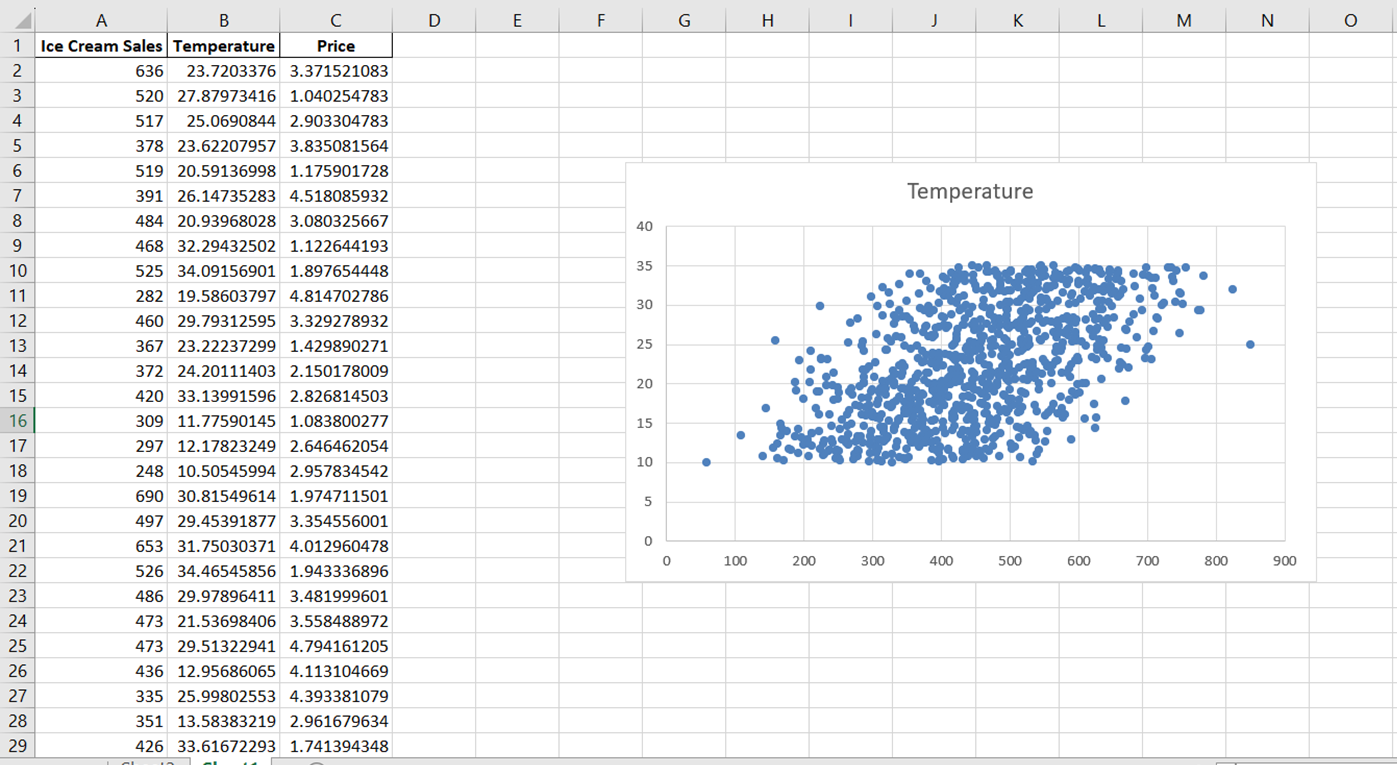
Laten we nu de grafiektitel aanpassen zodat deze de relatie die we visualiseren goed beschrijft. Klik simpelweg op de grafiektitel en verander deze in “Relatie tussen ijsverkoop en temperatuur.”
Om vervolgens het label van de x-as te wijzigen, ga je naar “Grafiekontwerp.” Selecteer in de vervolgkeuzelijst “Grafiekelement toevoegen” “Astitels” -> “Primair horizontaal”:
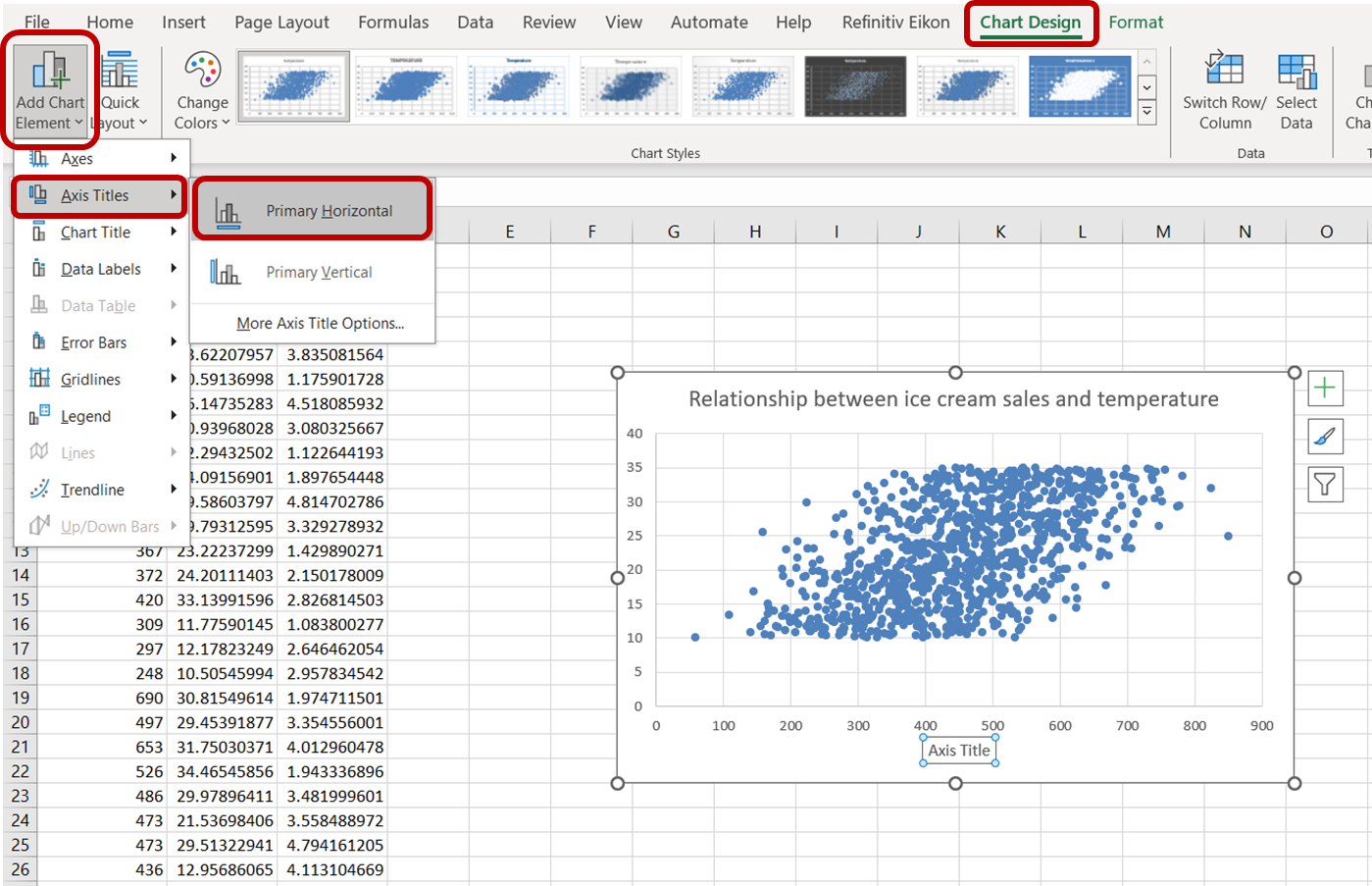
Klik op de standaard astitel die verschijnt en typ “Ice Cream Sales” om de as correct te labelen. Doe hetzelfde voor de y-as door “Primair verticaal” te selecteren en de astitel te vervangen door “Temperature:”
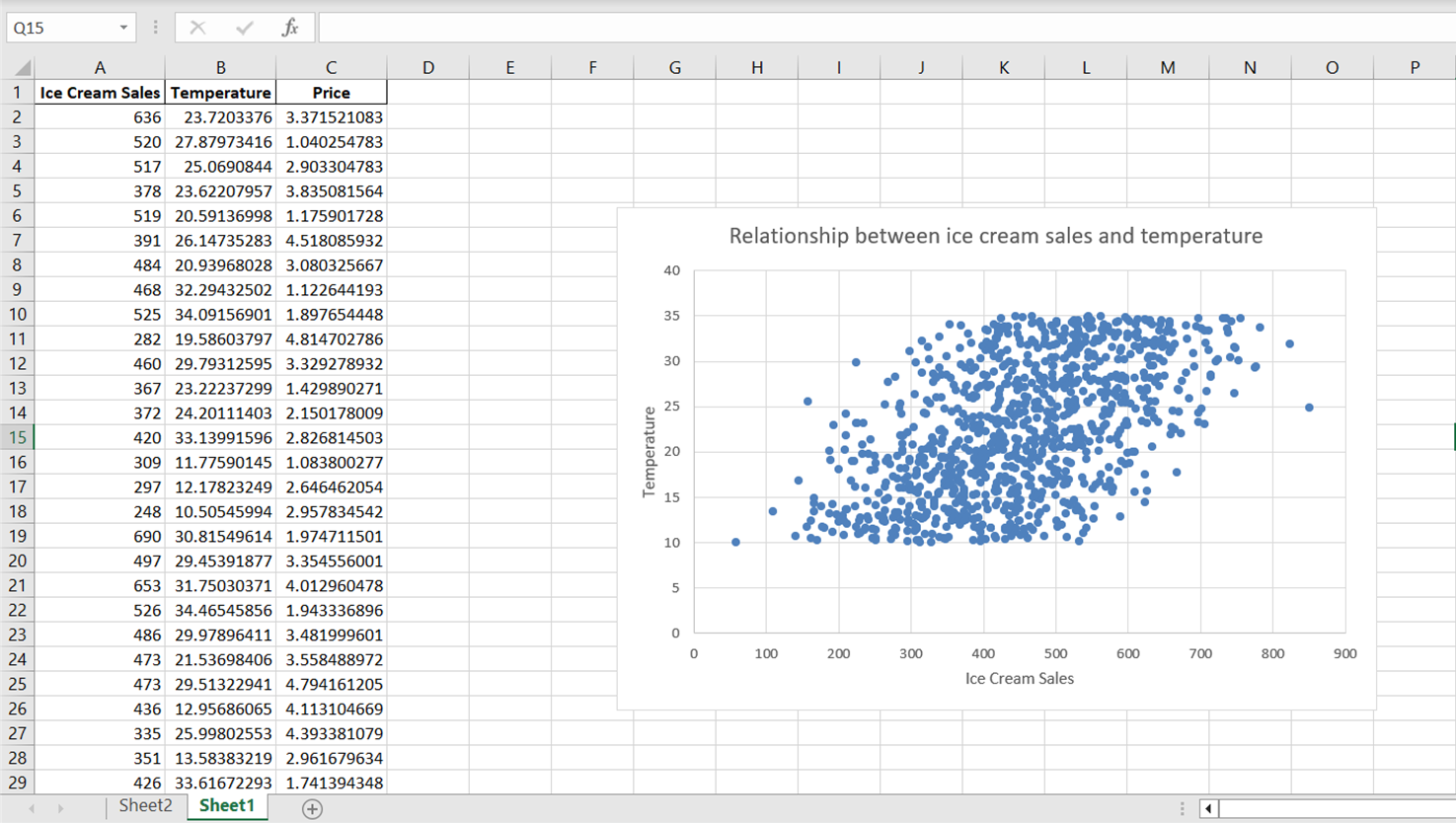
Merk op dat het spreidingsdiagram weliswaar een algemene richting in de relatie tussen temperatuur en ijsverkoop laat zien, maar dat de datapunten vrij verspreid lijken. Om deze relatie beter samen te vatten, inclusief de algehele richting en helling, voegen we een trendlijn of lijn van beste fit toe.
Om een trendlijn aan deze grafiek toe te voegen, klik je op een willekeurig datapunt in dit spreidingsdiagram. Hiermee selecteer je alle datapunten in de grafiek. Klik vervolgens met de rechtermuisknop op de geselecteerde datapunten. Kies in het menu dat verschijnt “Trendlijn toevoegen:”
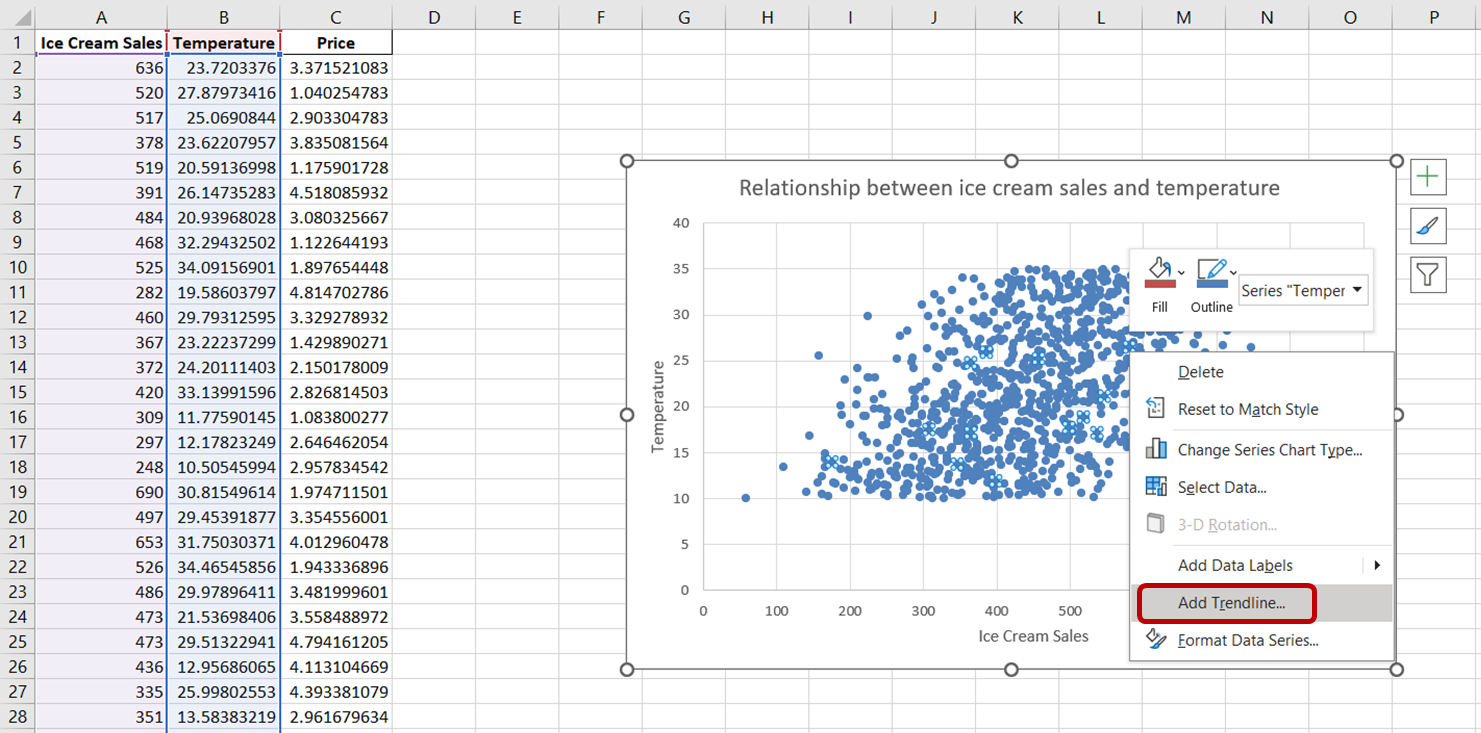
Je zou een stippellijn in de grafiek moeten zien verschijnen, die de algemene richting van de relatie tussen de variabelen laat zien:
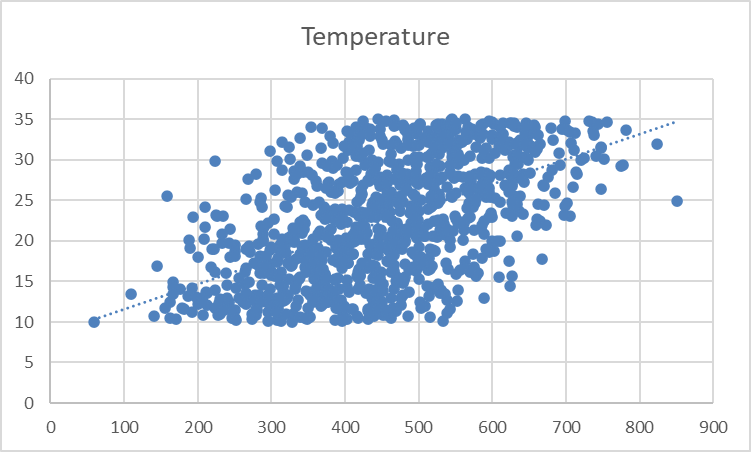
De trendlijn is nogal licht en subtiel. Laten we de opmaak aanpassen voor betere zichtbaarheid.
Klik eerst op de trendlijn om deze te selecteren. Het taakvenster “Trendlijn opmaken” verschijnt aan de rechterkant van je Excel-venster. Selecteer in dit taakvenster de optie “Opvulling & Lijn”. Verhoog vervolgens de lijndikte naar 3 pt en verander de kleur in rood:
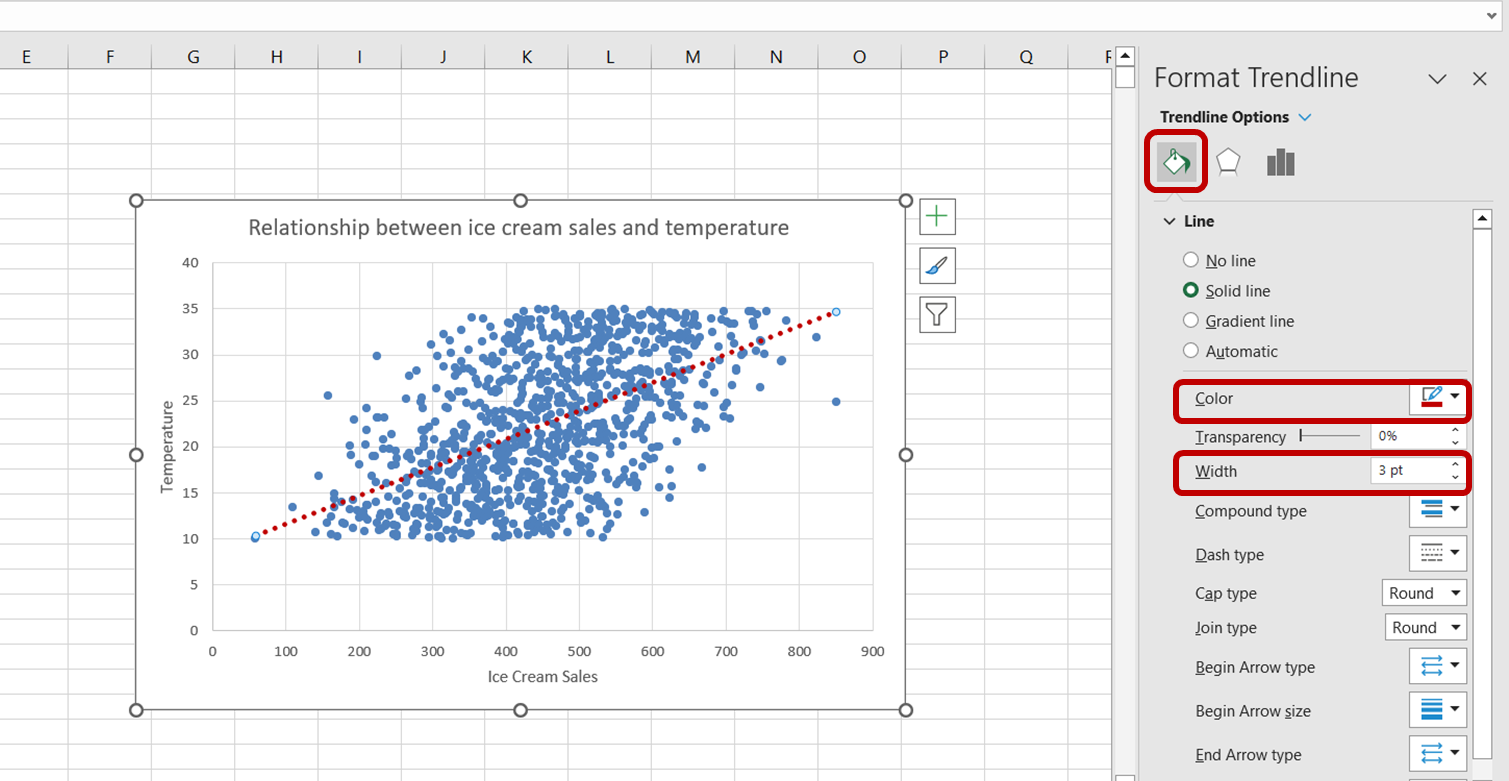
We hebben nu met succes een visualisatie gemaakt om de relatie tussen ijsverkoop en temperatuur beter te begrijpen.
Alleen al door naar de bovenstaande grafiek te kijken, kunnen we zien dat er een positieve relatie is tussen temperatuur en ijsverkoop. Naarmate de temperatuur stijgt, lijkt de ijsverkoop ook toe te nemen, wat aangeeft dat temperatuur een belangrijke voorspeller is van ijsverkoop.
Merk op dat deze observatie overeenkomt met de conclusie uit de resultaten van de regressieanalyse in de vorige sectie.
Je hebt nu een goed begrip gekregen van hoe je lineaire regressie in Excel uitvoert, hoe je verschillende statistische maten interpreteert om de passing van een model te beoordelen, en hoe je regressieanalyse visualiseert met spreidingsdiagrammen en trendlijnen.
Maar hier stopt de reis niet.
Geloof het of niet, we hebben nog maar aan de oppervlakte gekrabd van voorspellend modelleren, en er valt nog veel meer te leren. Hier zijn enkele mogelijke volgende stappen om je begrip van het onderwerp te verdiepen.
Oefen de concepten die je in dit artikel hebt geleerd, zodat je ze niet vergeet. Neem bijvoorbeeld de dataset die in deze tutorial is gebruikt en maak een spreidingsdiagram om de relatie tussen ijsverkoop en prijzen te illustreren.
Je kunt nog een stap verder gaan door te leren hoe je de regressievergelijking op de trendlijn weergeeft.
Zoals we eerder in dit artikel hebben vastgesteld, is Excel door het brede gebruik in tal van organisaties sterk in trek. Een goede beheersing van Excel kan je kansen op werk in verschillende sectoren aanzienlijk vergroten door de brede toepasbaarheid.
Als je moeite had met het volgen van deze tutorial of als je nog niet comfortabel bent met Excel-formules, overweeg dan om je in te schrijven voor onze leerlijn Excel Fundamentals. Deze cursus introduceert je tot verschillende datavisualisatietechnieken, draaitabellen en logische functies zoals COUNTIFs en geneste IF's, en helpt je op weg naar Excel-expert.
Begin vandaag nog met je regressiereis!
Cursus
Cursus
blog
Adel Nehme
15 min
