
Kurs
R'de Doğrusal Regresyon için Çıkarım
4 sa
16K
Doğrusal regresyon, en basit makine öğrenimi tekniklerinden biridir. Bir veya daha fazla bağımsız değişkene dayanarak bağımlı değişkenin değerini tahmin etmeyi içerir.
Örneğin, doğrusal regresyon, ev fiyatlarını ev boyutuna göre ya da bir kişinin kilosunu boyuna göre tahmin etmek için uygulanabilir. Doğrusal regresyon modelleri öncelikle iki türe ayrılır: basit ve çoklu doğrusal regresyon.
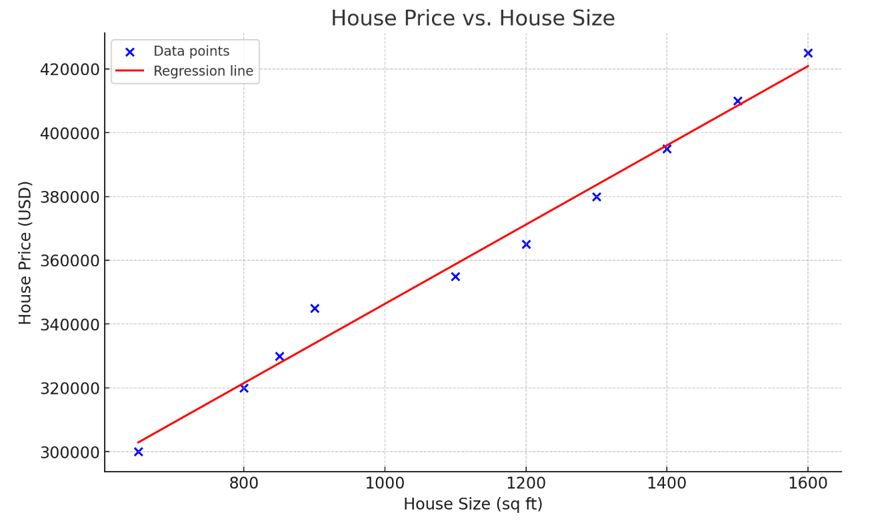
Görsel: OpenAI
Yukarıdaki grafik, ev boyutu (bağımsız değişken) ile ev fiyatı (bağımlı değişken) arasındaki ilişkiyi modelleyen basit doğrusal regresyonu temsil eder. Görselleştirmede gözlemlendiği gibi, ev büyüdükçe fiyat da artar.
Regresyon doğrusunun denklemi şöyledir:
y = mx + c + ⍷
Yukarıdaki formül tanıdık geliyorsa, muhtemelen okulda y = mx + c’nin bir doğru denklemi olduğunu öğrendiğiniz içindir. Bu denklemde:
⍷ artık terimini veya hata terimini temsil eder. Bu, gerçek değer ile regresyonun tahmin ettiği değer arasındaki farktır. Bu terim, bir regresyon doğrusunu tamamen deterministik bir doğrudan ayırır ve x ile y arasındaki ilişkinin kusursuz şekilde öngörülebilir olmamasına yol açar.
Konu hakkında daha kapsamlı bir rehber için, doğrusal regresyonun temel unsurlarını açıklayan makalemizi okuyun.
Excel’i doğrusal regresyon yapmak için etkili bir araç kılan bazı faktörler şunlardır:
2024 itibarıyla, Statista’nın bildirdiğine göre yalnızca Amerika Birleşik Devletleri’nde 731.000’den fazla şirket ve dünya çapında sayısız kurum Excel kullanmaktadır. Kuruluşların tüm seviyelerindeki yöneticiler veri yönetimi ve raporlama amacıyla Excel’den yararlanır.
Excel’de doğrusal regresyon gibi öngörücü modeller oluşturarak, şirketler raporlama ve öngörücü modelleme faaliyetlerini tek bir platformda toplayabilir. Bu da programlama ortamları ile Excel tabloları arasında sürekli geçiş yapmak yerine iş akışlarını sadeleştirmelerini sağlar.
Veri alanında yeniyseniz, işin içinde kodlama olduğu için bir öngörücü model kurma fikri göz korkutucu görünebilir. Excel bu süreci basitleştirir ve zaten aşina olduğunuz bir arabirimde çalışmanıza olanak tanır. Excel ile doğrusal regresyon modeli kurmak, sadece birkaç tıklamayla gerçekleştirilebilen basit bir sürece dönüşür.
Excel, farklı değişkenler arasındaki ilişkiyi daha iyi anlamak için grafiğe dökmenize olanak tanıyan güçlü görselleştirme yetenekleri sunar. Ayrıca, görselleştirmelerin PowerPoint sunumlarına kolayca gömülmesini sağlayarak paydaşlarla etkili iletişim için rapor oluşturmayı basitleştirir.
Bu eğitime başlamadan önce, bu GitHub deposunda bulunan veri setini indirin. Bu veri seti, OpenAI tarafından eğitim amaçlarıyla özel olarak oluşturulmuştur. Veri girişi, basit formüller uygulama ve çalışma sayfaları arasında gezinme gibi temel elektronik tablo işlemlerine hâkim olmak, bu eğitimi takip etme becerinizi artıracaktır.
Öncelikle Excel’de Veri Analizi ToolPak eklentisini etkinleştirmemiz gerekiyor. Bu, doğrusal regresyon için kullanacağımız aracın da yer aldığı çeşitli veri analizi araçları sunan bir Excel eklentisidir.
Bunu yapmak için önce Excel dosyasını açın ve Dosya -> Seçenekler yolunu izleyin. Seçenekler iletişim kutusunda Eklentiler -> Excel Eklentilerini seçin ve Gite tıklayın:
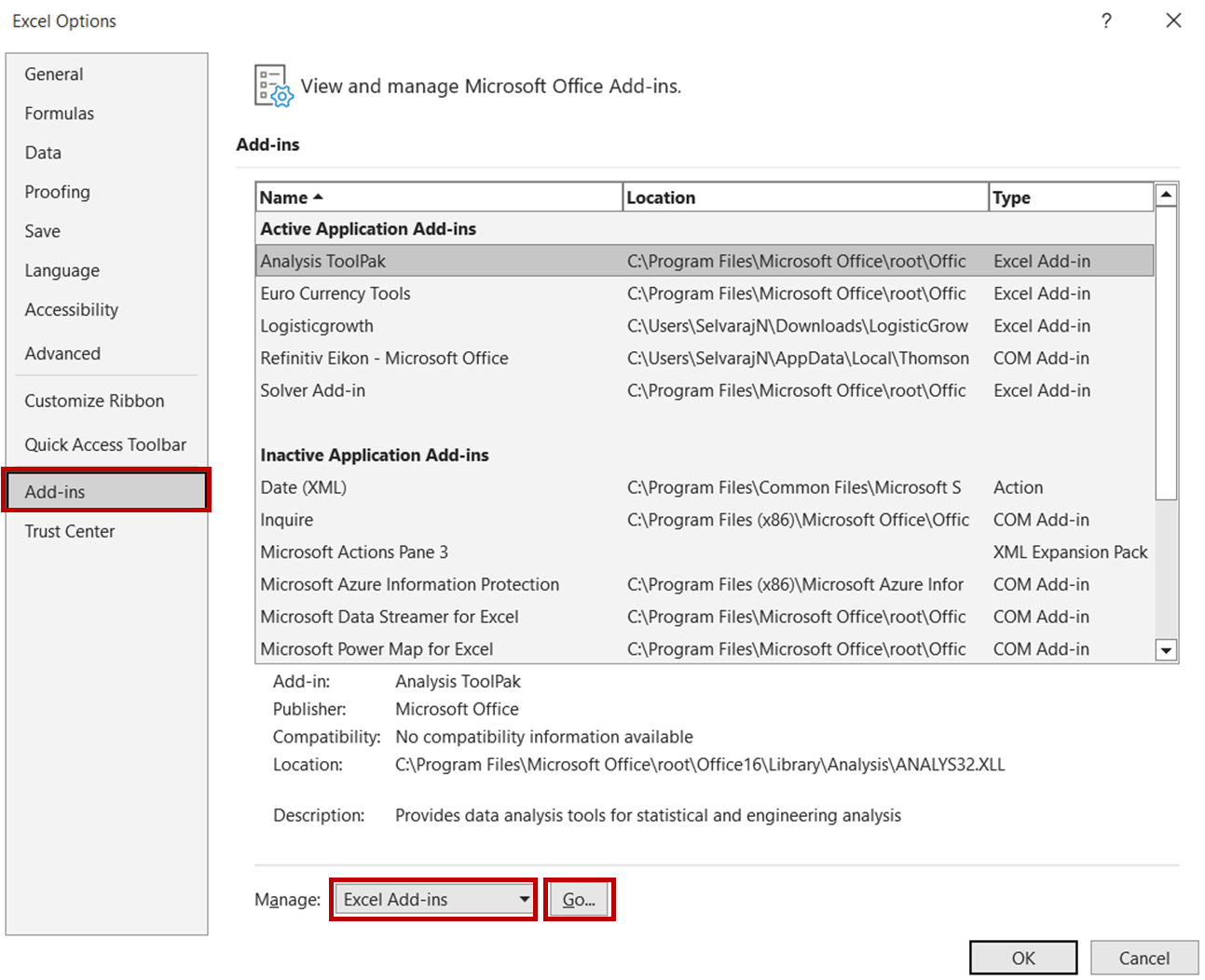
Eklentiler iletişim kutusunda Analysis ToolPak seçeneğini işaretleyin ve Tamama tıklayın.
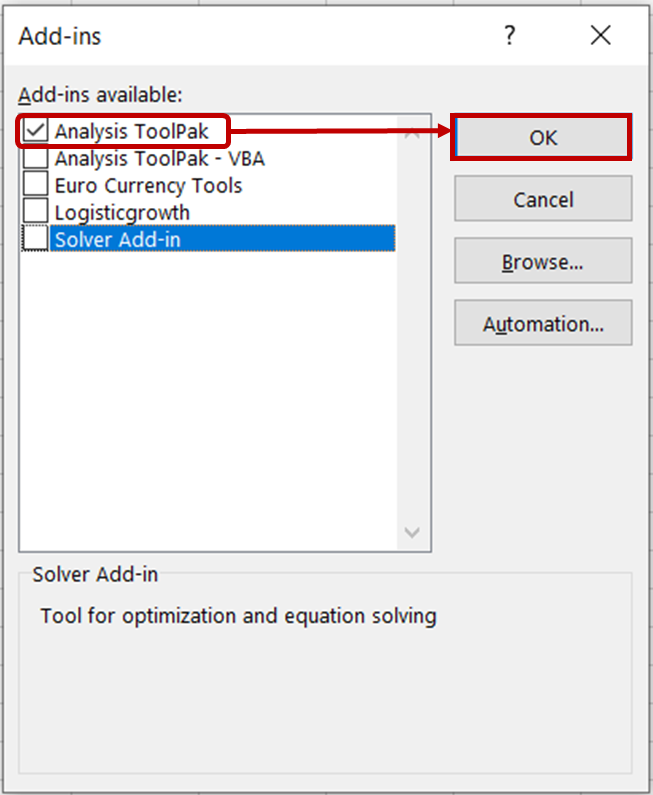
Artık Veri Analizi araçlarını Veri sekmesinde görmelisiniz.
Veri Analizi ToolPak’i etkinleştirdiğimize göre, veri seti üzerinde doğrusal regresyon uygulamaya geçebiliriz. Dondurma satışları veri setini açın ve Veri sekmesine gidin. Analiz grubunda Veri Analizine tıklayın.

Ardından, analiz araçları listesinden Regressionı seçin ve Tamam’a tıklayın.
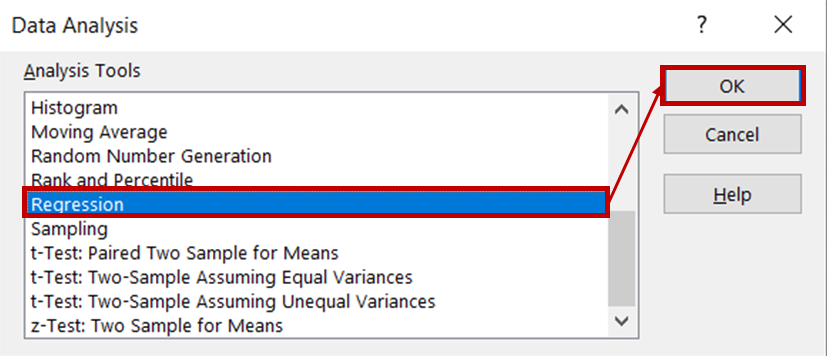
Regresyon iletişim kutusunda, Input Y Range için dondurma satış verilerini içeren sütunu seçin. Input X range için sıcaklık ve fiyat verilerini içeren sütunları seçin. Labels kutusunun işaretli olduğundan emin olun; bu, Excel’in başlıkları tanımasına ve kalan satırları sayısal veri olarak işlemesine yardımcı olur. Output options bölümünde, sonuçların yeni bir çalışma sayfasında görüntülenmesi için New Worksheet Ply seçeneğini işaretleyin.
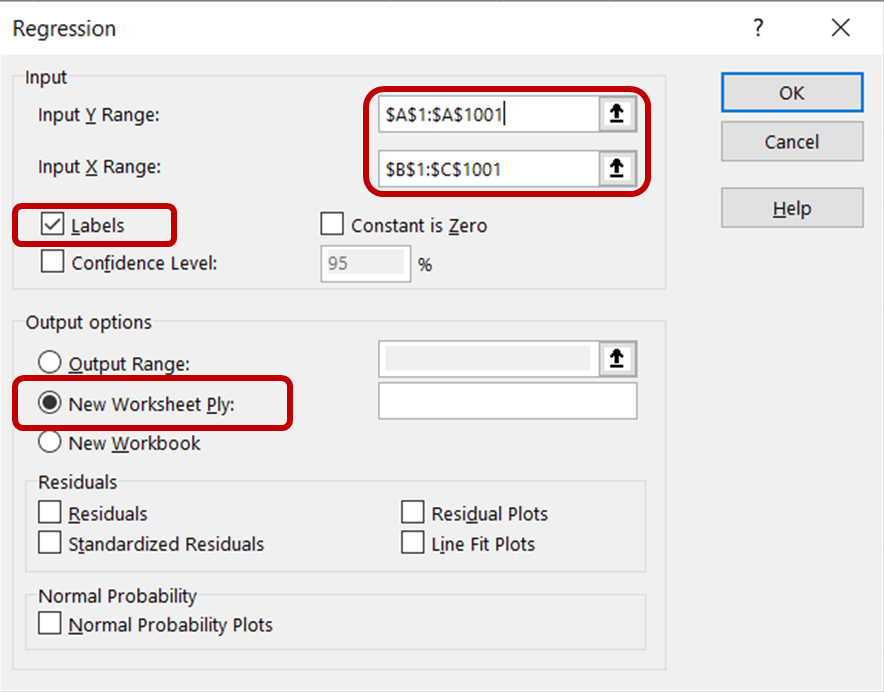
Ardından, veri seti üzerinde regresyon analizini çalıştırmak için Tamam’a tıklayın.
Regresyonu gerçekleştirdikten sonra, Excel dosyasında otomatik olarak yeni bir çalışma sayfası belirdiğini ve aşağıdakine benzer bir dizi sonuç tablosu içerdiğini görmelisiniz:
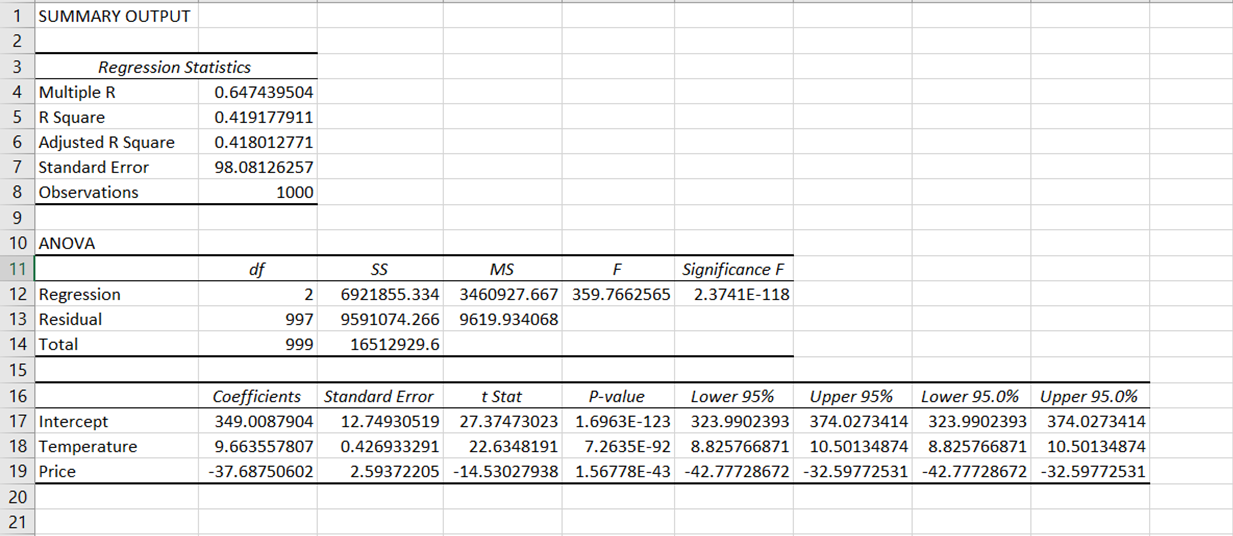
Regresyon çıktısının sonuçları; regresyon istatistikleri, ANOVA, katsayılar, standart hata, t istatistiği, p-değeri ve güven aralığı gibi çeşitli bileşenlere ayrılmıştır.
Şimdi bu bileşenlerin her birini daha ayrıntılı inceleyelim:
Excel, regresyon analizi sonucunda aşağıdaki özet istatistikleri raporlar:
Multiple R
Bu, değişkenler arasındaki doğrusal ilişkinin yönünü ve gücünü ölçen bir korelasyon katsayısıdır. -1 ile 1 arasında değişir; -1 veya 1’e yakın değerler güçlü bir ilişkiyi, 0’a yakın değerler ise korelasyon olmadığını gösterir.
Analizimizde korelasyon katsayısı yaklaşık 0,65 olup, bağımlı değişkenimiz (dondurma satışları) ile bağımsız değişkenlerimiz (fiyat ve sıcaklık) arasında orta düzeyde pozitif bir korelasyon olduğunu gösterir.
R Square
R2, verilerin regresyon modeline ne kadar iyi uyduğunu söyleyen istatistiksel bir ölçüdür. Korelasyon katsayısının, yani Multiple R’nin karesidir ve bağımlı değişkendeki varyansın ne kadarının bağımsız değişkenler tarafından açıklandığını temsil eder.
R2 0 ile 1 arasında değişir; 1’e yakın değerler daha iyi bir model uyumunu işaret eder. Bizim R2 değerimiz yaklaşık 0,419’dur; bu da dondurma satışlarındaki varyansın yaklaşık %41,9’unun model tarafından açıklandığı anlamına gelir.
Adjusted R Square
Bu, modeldeki yordayıcı sayısına göre ayarlanmış R-kare değeridir. Farklı sayıda yordayıcı içeren modeller karşılaştırılırken genellikle daha iyi bir ölçüdür. Bizim durumda ayarlanmış R2 0,418’dir. Bu değer R2 ile çok benzerdir ve dahil ettiğimiz bağımsız değişkenlerin (sıcaklık ve fiyat) modele uygun olduğunu, büyük bir ceza getirmediğini gösterir.
Standard Error
Standart hata, gözlenen değerlerin regresyon doğrusundan ortalama uzaklığını ölçer. Daha küçük bir standart hata daha iyidir; çünkü regresyon doğrusunun verilere daha yakın uyduğunu gösterir.
Bizim durumda standart hata yaklaşık 98,05 olup, gerçek dondurma satış değerlerinin tahmin edilenlerden ortalama 98,05 birim saptığını gösterir.
Observations
Bu, başlıklar hariç veri setinde analiz edilen toplam veri noktası (satır) sayısını ifade eder.
ANOVA, Varyans Analizi anlamına gelir. Bir regresyon modelindeki değişkenlik düzeyi hakkında şu unsurlar aracılığıyla bilgi veren istatistiksel bir tekniktir:
Serbestlik Derecesi (df)
Nihai hesaplamada değişebilen değerlerin sayısını temsil eder. ANOVA bağlamında, “Regression” df, modeldeki bağımsız değişken sayısını ifade eder; bu da 2’dir. “Residual” df, toplam gözlem sayısından bağımsız değişken sayısı ve 1 çıkarılarak hesaplanır. Bizim durumda bu değer 997’dir.
Kareler Toplamı (SS)
Bu, değişkenliği niceler. “Regression SS”, model tarafından açıklanabilen bağımlı değişkendeki değişkenliği ölçer. “Residual SS” ise açıklanamayan değişkenliği temsil eder.
Ortalama Kare (MS)
Kareler Toplamı’nın (SS) Serbestlik Derecesi’ne (df) bölünmesiyle elde edilir.
F-istatistiği (F)
Modelin genel anlamlılığını belirleyen istatistiktir. Daha yüksek bir F değeri, modelin verilere daha iyi uyduğunu gösterir.
Significance F
Bu, F-istatistiği ile ilişkili p-değeridir. Çok küçük bir p-değeri (0,05’ten az), modelinizin bağımsız değişken içermeyen bir modele kıyasla verilere daha iyi uyduğunu gösterir. Bizim durumda Significance F değeri 0,05’ten küçüktür; bu da modelin verilere iyi uyduğunu gösterir.
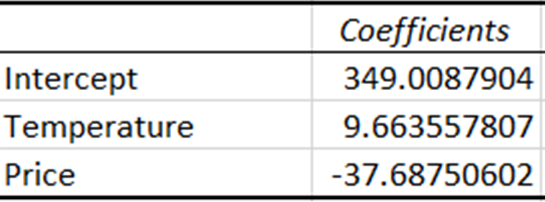
Katsayılar, bağımsız değişkende bir birimlik değişim olduğunda bağımlı değişkende beklenen değişim miktarını temsil eder.
Sıcaklık katsayısı, sıcaklıktaki her bir birim artışla satışların yaklaşık 9,66 birim arttığını gösterir. Buna karşılık, fiyat katsayısı, fiyatta bir birimlik artışla satışların yaklaşık 37,69 birim azaldığını gösterir.
Standart hata, gözlenen değerler ile regresyon doğrusu arasındaki ortalama mesafeyi ölçer. Daha düşük standart hata, daha iyi bir model anlamına gelir.
t-istatistiği, katsayının kendi standart hatasına bölünmesiyle elde edilir. Daha büyük bir t-istatistiği, katsayının sıfırdan farklı olduğunu ve dolayısıyla bağımlı değişken üzerinde daha büyük bir etkisi olduğunu ima eder.
P-değerleri, sıfır hipotezinin doğru olduğu varsayımı altında (yani bir bağımsız değişkenin katsayısının 0 olduğu durumda) gözlemlenen kadar uç bir t-istatistiğini gözlemleme olasılığını söyler.
Basitçe ifade etmek gerekirse, t-istatistiği ne kadar büyük ve p-değeri ne kadar küçükse, sıfır hipotezine karşı kanıt o kadar güçlüdür; bu da bağımsız değişkenlerin (fiyat ve sıcaklık) bağımlı değişken (dondurma satışları) üzerinde istatistiksel olarak anlamlı bir etkisi olduğu sonucunu destekler.
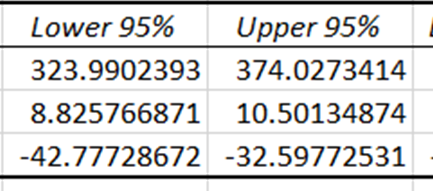
Güven aralıkları, %95 güven düzeyinde, bağımsız değişkenlerin gerçek katsayılarının düşmesinin beklendiği alt ve üst sınırları sağlar. Fiyat ve sıcaklık için güven aralıkları sıfırdan farklı olduğundan, bu katsayılar dondurma satışlarını tahmin etmede istatistiksel olarak anlamlı bir etkiye sahiptir.
İki değişken arasındaki ilişkiyi görselleştirmek, veri setini anlamanızı büyük ölçüde geliştirebilir. Excel’in Analysis ToolPak’i ayrıntılı özet istatistikler sunsa da, grafiksel bir gösterim değişkenler arasındaki ilişkinin yönünü ve gücünü anında gösterebilir.
Trend çizgili bir saçılım grafiği oluşturmak, bu ilişkiyi görselleştirmenin etkili bir yoludur ve beş dakikadan kısa sürede yapılabilir. Bu görselleştirme tekniği, bir değişkenin diğerini nasıl etkilediğini bir bakışta görmenizi sağlar.
“Dondurma Satışları” ile “Sıcaklık” arasındaki ilişkiyi şu şekilde görselleştirebilirsiniz:
Önce “Dondurma Satışları” ve “Sıcaklık” değişkenlerini içeren hücreleri vurgulayın. Ardından “Ekle” sekmesine gidin ve “Saçılım” grafik simgesine tıklayın:
Şuna benzeyen sade bir saçılım grafiği göreceksiniz:
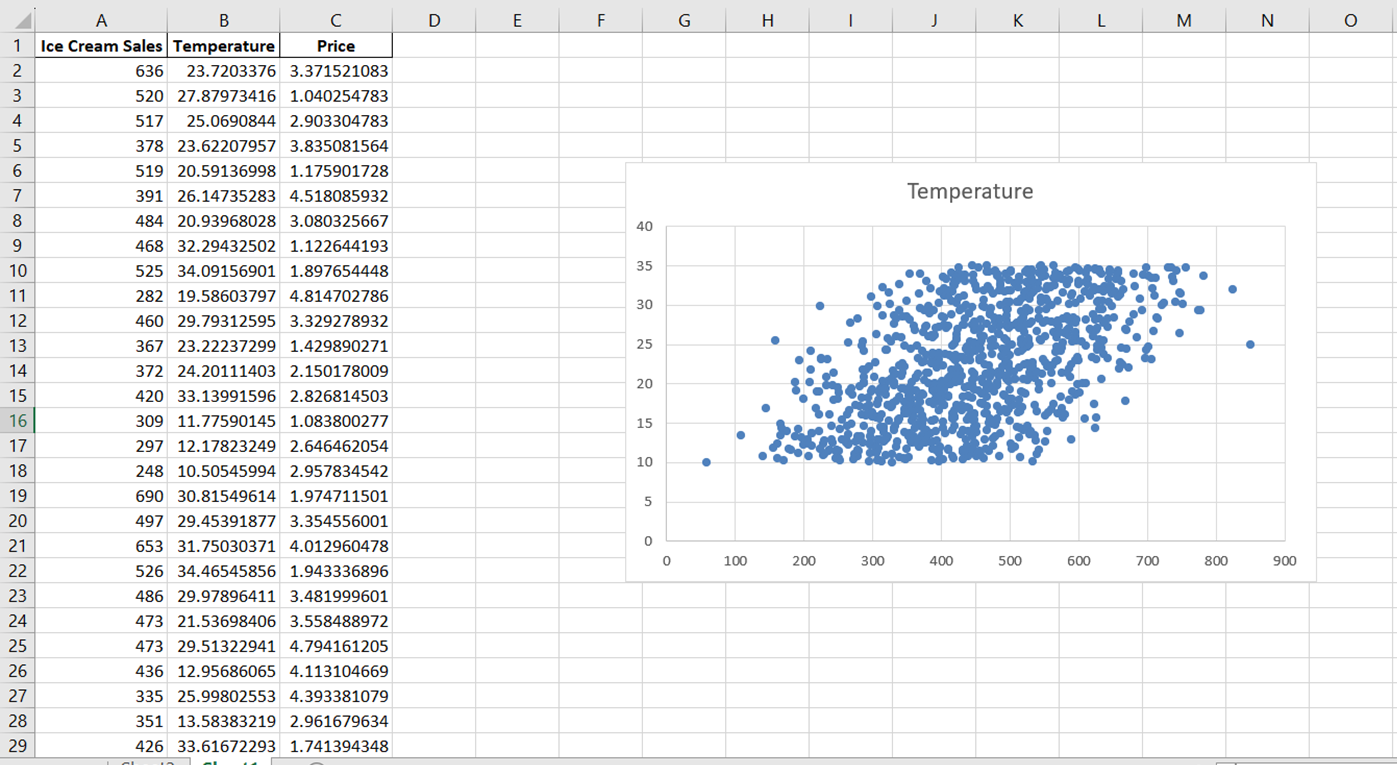
Şimdi, görselleştirdiğimiz ilişkiyi doğru şekilde tanımlamak için grafiği yeniden adlandıralım. Grafiğin başlığına tıklayın ve “Dondurma satışları ile sıcaklık arasındaki ilişki” olarak değiştirin.
Ardından, x-ekseni etiketini değiştirmek için “Grafik Tasarımı”na gidin. “Grafik Öğesi Ekle” açılır menüsünde “Eksen Başlıkları” -> “Birincil Yatay”ı seçin:
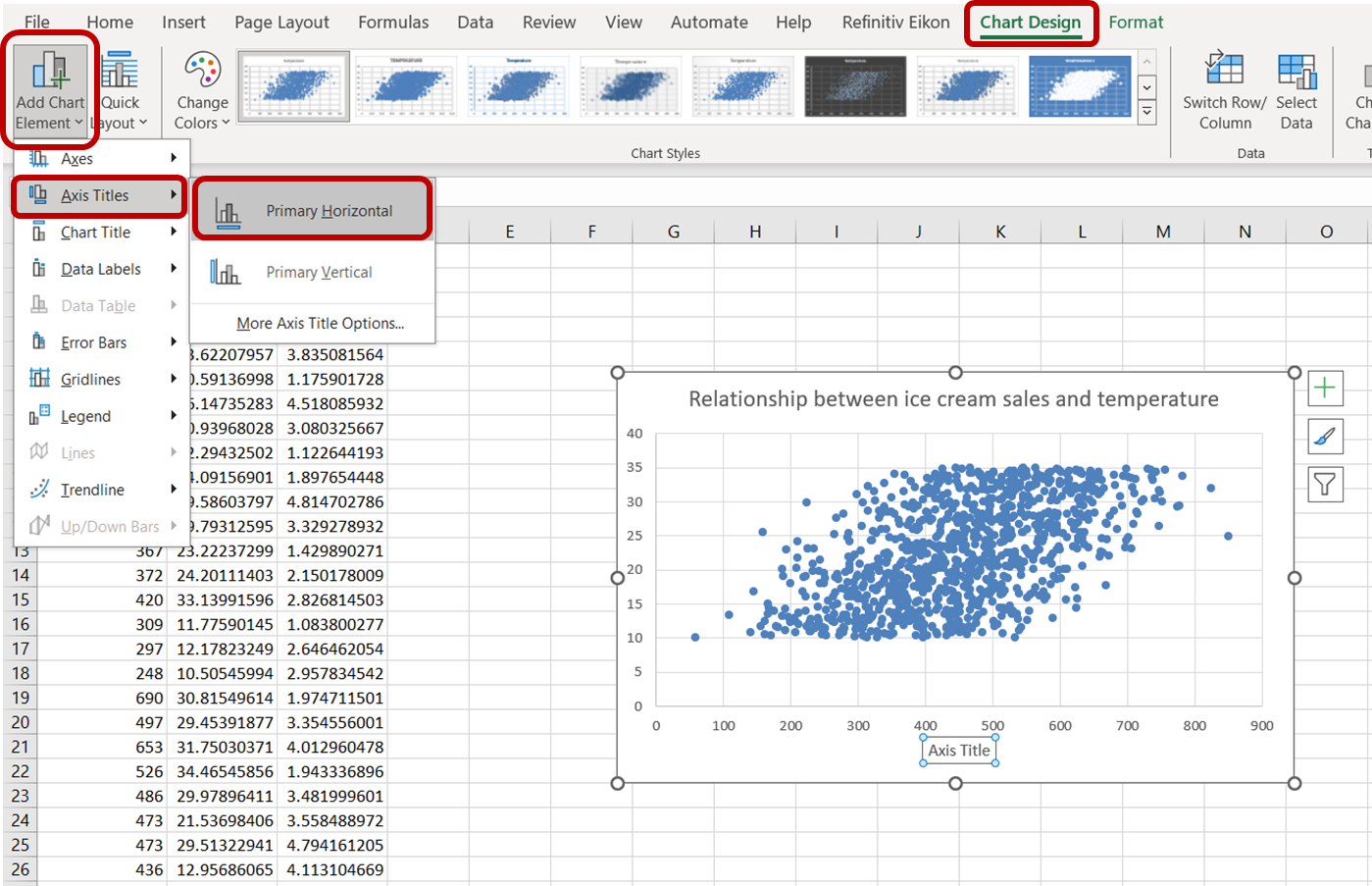
Görünen varsayılan eksen başlığına tıklayın ve ekseni doğru etiketlemek için “Dondurma Satışları” yazın. Y-ekseni için de “Birincil Dikey”i seçip eksen başlığını “Sıcaklık” ile değiştirerek aynı işlemi yapın:
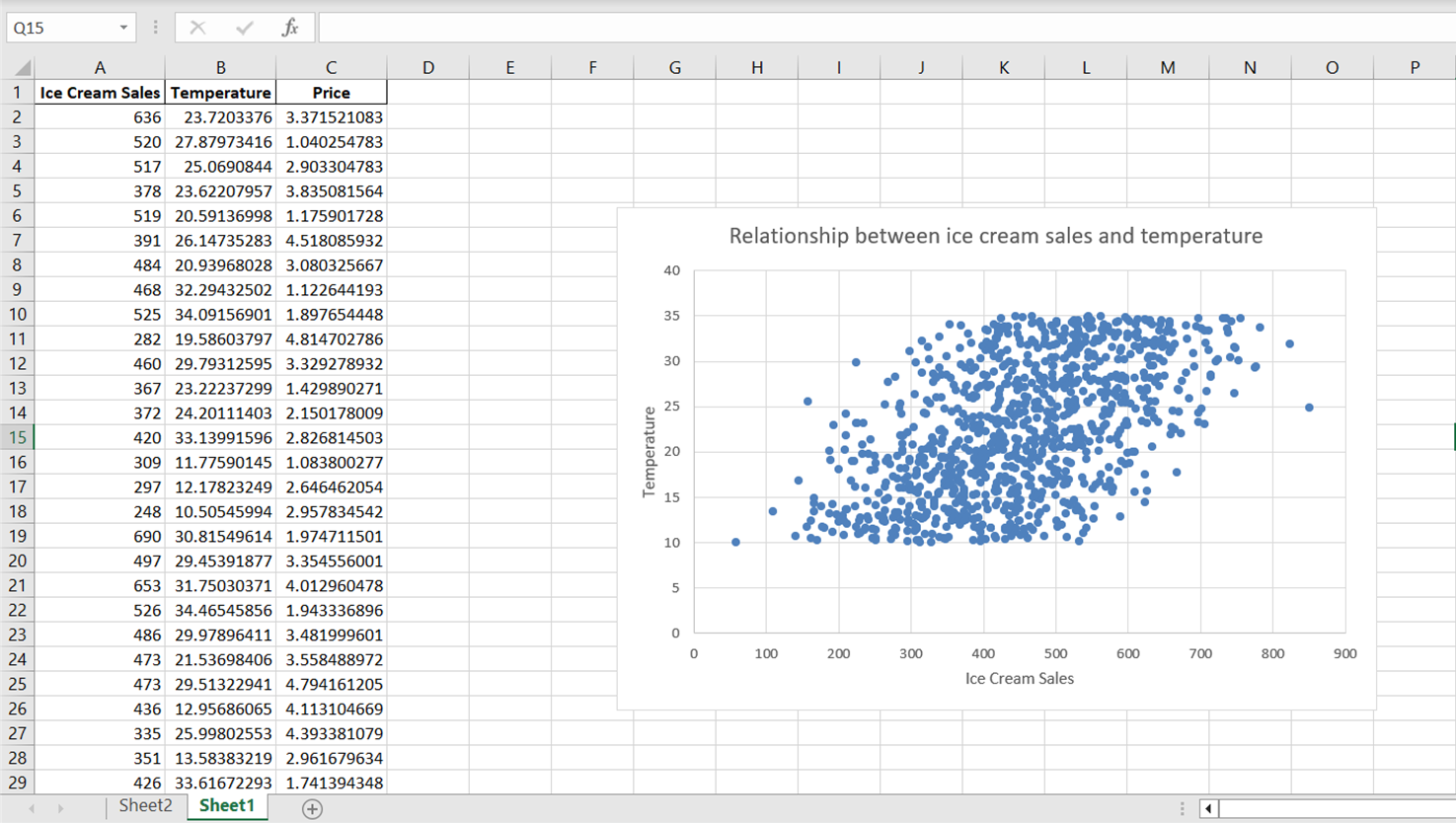
Saçılım grafiği, sıcaklık ile dondurma satışları arasındaki ilişkinin genel yönünü ortaya koysa da, veri noktalarının geniş bir alana yayıldığını fark edeceksiniz. Bu ilişkiyi, genel yönü ve eğimi de dahil olmak üzere daha iyi özetlemek için bir trend çizgisi ya da en iyi uyum doğrusunu ekleyelim.
Bu grafiğe bir trend çizgisi eklemek için, bu saçılım grafiğindeki herhangi bir veri noktasına tıklayın. Bu işlem, grafikteki tüm veri noktalarını seçecektir. Ardından, seçili veri noktalarına sağ tıklayın. Açılan menüden “Trend Çizgisi Ekle”yi seçin:
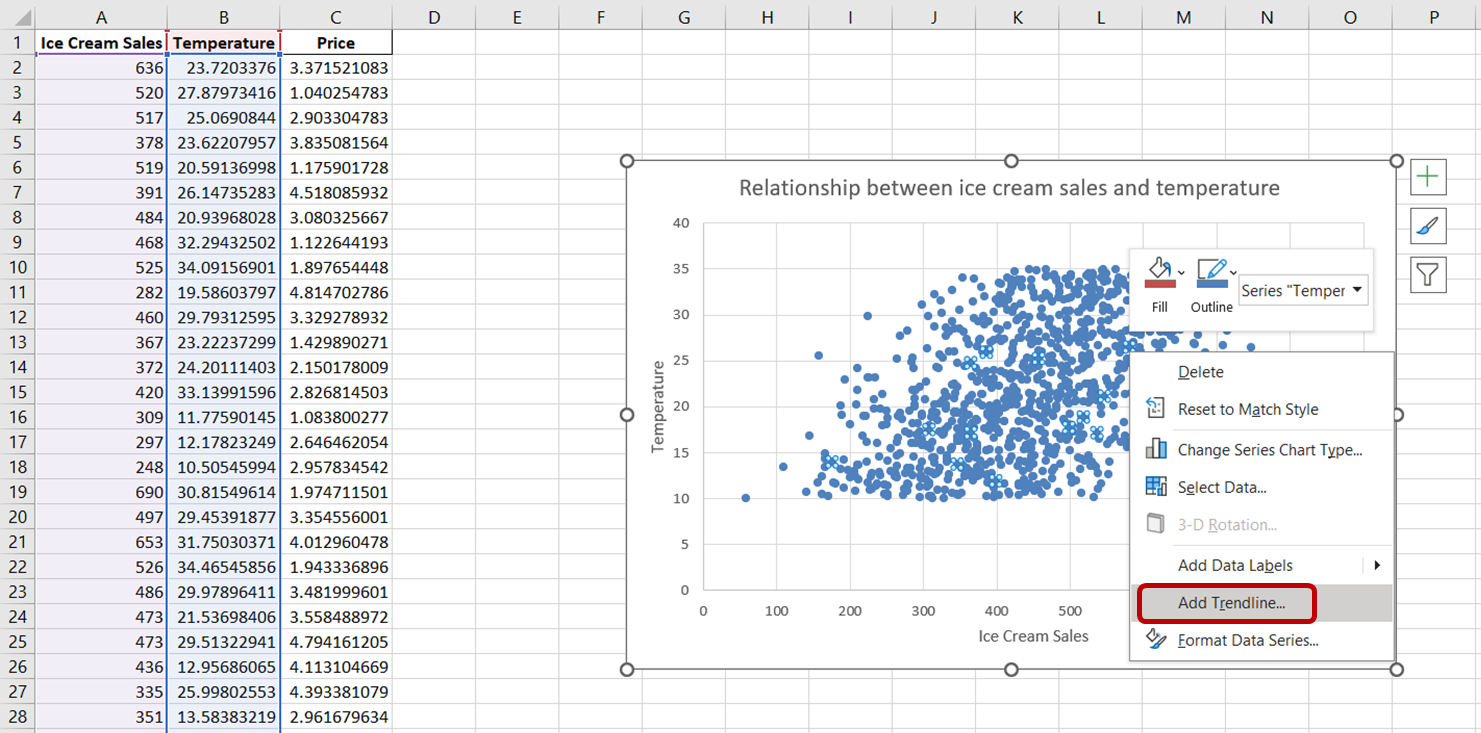
Grafikte, değişkenler arasındaki ilişkinin genel yönünü gösteren kesik bir çizgi belirmelidir:
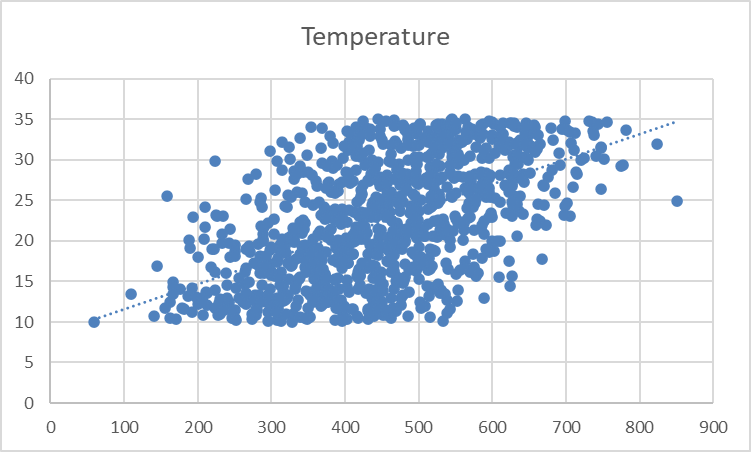
Trend çizgisi soluk ve belli belirsiz görünüyor. Görünürlüğü artırmak için biçimlendirmesini ayarlayalım.
Önce trend çizgisine tıklayarak onu seçin. Excel pencerenizin sağ tarafında “Trend Çizgisini Biçimlendir” görev bölmesi görünecektir. Bu görev bölmesinde “Dolgu & Çizgi” seçeneğini seçin. Ardından trend çizgisinin kalınlığını 3 pt’ye artırın ve rengini kırmızıya değiştirin:
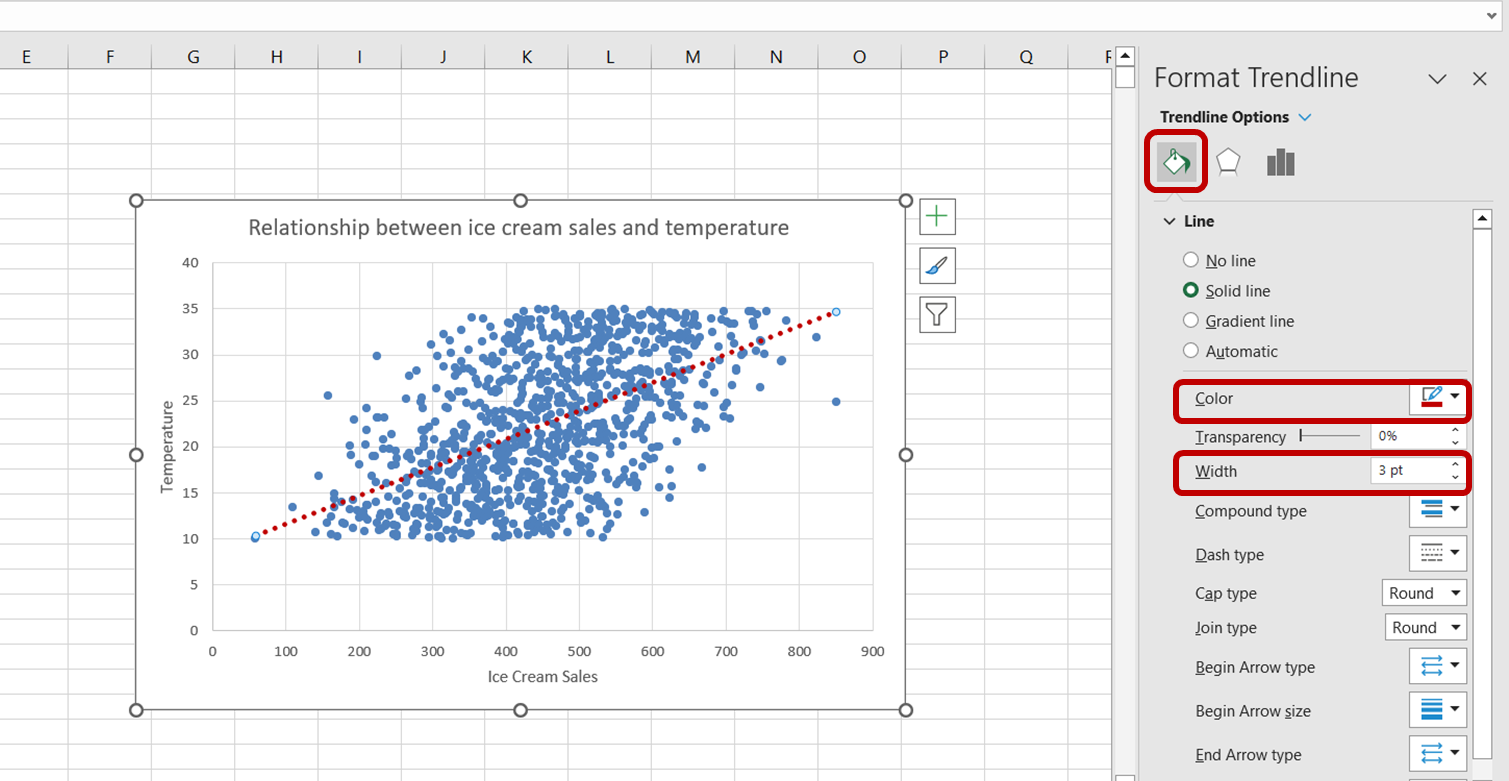
Artık dondurma satışları ile sıcaklık arasındaki ilişkiyi daha iyi anlamak için başarılı bir görselleştirme oluşturduk.
Yukarıdaki grafiğe bakarak, sıcaklık ile dondurma satışları arasında pozitif bir ilişki olduğunu söyleyebiliriz. Sıcaklık arttıkça dondurma satışları da artıyor gibi görünmektedir; bu da sıcaklığın dondurma satışlarının önemli bir yordayıcısı olduğunu gösterir.
Bu gözlemin, bir önceki bölümdeki regresyon analizi sonuçlarından çıkardığımız sonuçla benzer olduğuna dikkat edin.
Artık Excel’de doğrusal regresyonu nasıl uygulayacağınızı, bir modelin uyumunu değerlendirmek için çeşitli istatistiksel ölçüleri nasıl yorumlayacağınızı ve saçılım grafikleri ile trend çizgileri kullanarak regresyon analizini nasıl görselleştireceğinizi sağlam bir şekilde kavradınız.
Ancak yolculuk burada bitmiyor.
İnanın ya da inanmayın, öngörücü modellemenin yalnızca yüzeyine değindik ve öğrenilecek çok daha fazla şey var. Konuya ilişkin anlayışınızı derinleştirmek için bazı olası sonraki adımlar şunlardır.
Bu makalede öğrendiğiniz kavramları unutmamak için pratik yapın. Örneğin, bu eğitimde kullanılan veri setini alın ve dondurma satışları ile fiyatlar arasındaki ilişkiyi göstermek için bir saçılım grafiği oluşturun.
Bunu bir adım daha ileri götürerek, regresyon denklemini trend çizgisi üzerinde nasıl görüntüleyeceğinizi de öğrenebilirsiniz.
Bu makalenin başında da belirttiğimiz gibi, Excel’in sayısız kurumda yaygın kullanımı onu yüksek talep gören bir araç haline getiriyor. Excel’i iyi derecede bilmek, geniş ölçekte kullanılmasından dolayı farklı sektörlerde istihdam şansınızı önemli ölçüde artırabilir.
Bu eğitimi takip ederken zorlandıysanız veya Excel’in formülleriyle henüz rahat değilseniz, Excel Temelleri öğrenim yolumuza kaydolmayı düşünebilirsiniz. Bu kurs, çeşitli veri görselleştirme tekniklerini, pivot tabloları ve COUNTIFs ile İç İçe IF’ler gibi mantıksal işlevleri tanıtarak Excel ustalığına giden yolu açacaktır.
Regresyon Yolculuğunuza Bugün Başlayın!
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
