
Corso
Inferenza per la regressione lineare in R
4 h
16K
La regressione lineare è una delle tecniche di machine learning più semplici. Consiste nel prevedere il valore di una variabile dipendente sulla base di una o più variabili indipendenti.
Per esempio, la regressione lineare può essere usata per prevedere il prezzo di una casa in base alla sua metratura o il peso di una persona in base alla sua altezza. I modelli di regressione lineare si suddividono principalmente in due categorie: regressione lineare semplice e multipla.
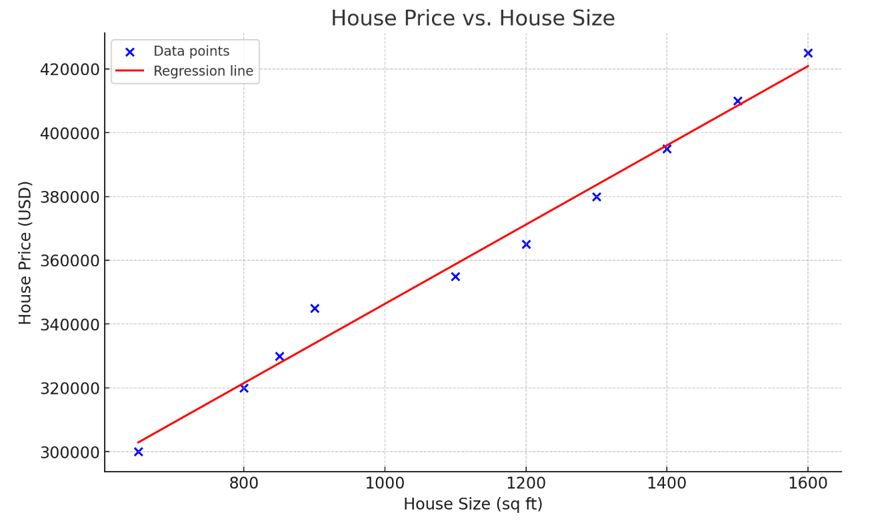
Immagine di OpenAI
Il grafico sopra rappresenta una regressione lineare semplice, che modella la relazione tra la dimensione della casa (variabile indipendente) e il prezzo della casa (variabile dipendente). Come si osserva nella visualizzazione, più grande è la casa, più alto è il prezzo.
L'equazione della retta di regressione è:
y = mx + c + ⍷
Se la formula ti sembra familiare, è perché probabilmente a scuola hai imparato che y = mx + c è l'equazione di una retta. In questa equazione:
⍷ rappresenta il residuo o termine d'errore. È la differenza tra il valore reale e il valore previsto dal modello di regressione. È ciò che distingue una retta di regressione da una retta perfettamente deterministica, rendendo la relazione tra x e y non perfettamente prevedibile.
Per una guida più approfondita sull'argomento, leggi il nostro articolo che spiega le basi della regressione lineare.
Ecco alcuni fattori che rendono Excel uno strumento efficace per eseguire la regressione lineare:
Nel 2024, Excel è utilizzato da oltre 731.000 aziende negli Stati Uniti e da molte altre nel mondo, secondo Statista. I dirigenti a tutti i livelli organizzativi usano Excel per la gestione dei dati e la reportistica.
Creando modelli predittivi come la regressione lineare in Excel, le aziende possono riunire in un'unica piattaforma sia la reportistica sia la modellazione predittiva. Questo consente di snellire i flussi di lavoro, evitando di dover passare continuamente da ambienti di programmazione ai fogli di calcolo Excel.
Se sei alle prime armi nel mondo dei dati, l'idea stessa di costruire un modello predittivo può intimorire per via del codice da scrivere. Excel semplifica il processo, permettendoti di lavorare in un'interfaccia che già conosci. Con Excel, costruire un modello di regressione lineare diventa un'operazione semplice, realizzabile in pochi clic.
Excel offre solide funzionalità di visualizzazione, permettendoti di rappresentare graficamente la relazione tra variabili per comprenderle meglio. Inoltre, semplifica la creazione di report, consentendo di incorporare facilmente le visualizzazioni nelle presentazioni PowerPoint per comunicare in modo efficace con gli stakeholder.
Prima di iniziare il tutorial, scarica il dataset disponibile in questo repository GitHub. Questo dataset è stato creato specificamente da OpenAI per scopi didattici. Avere dimestichezza con le operazioni di base sui fogli di calcolo, come inserire dati, applicare formule semplici e navigare tra i fogli, ti aiuterà a seguire meglio questo tutorial.
Per prima cosa, dobbiamo abilitare il Data Analysis ToolPak in Excel. Si tratta di un componente aggiuntivo di Excel che fornisce vari strumenti di analisi dei dati, incluso quello che useremo per la regressione lineare.
Per farlo, apri il file Excel e vai su File -> Opzioni. Nella finestra Opzioni, seleziona Componenti aggiuntivi -> Componenti aggiuntivi di Excel e fai clic su Vai:
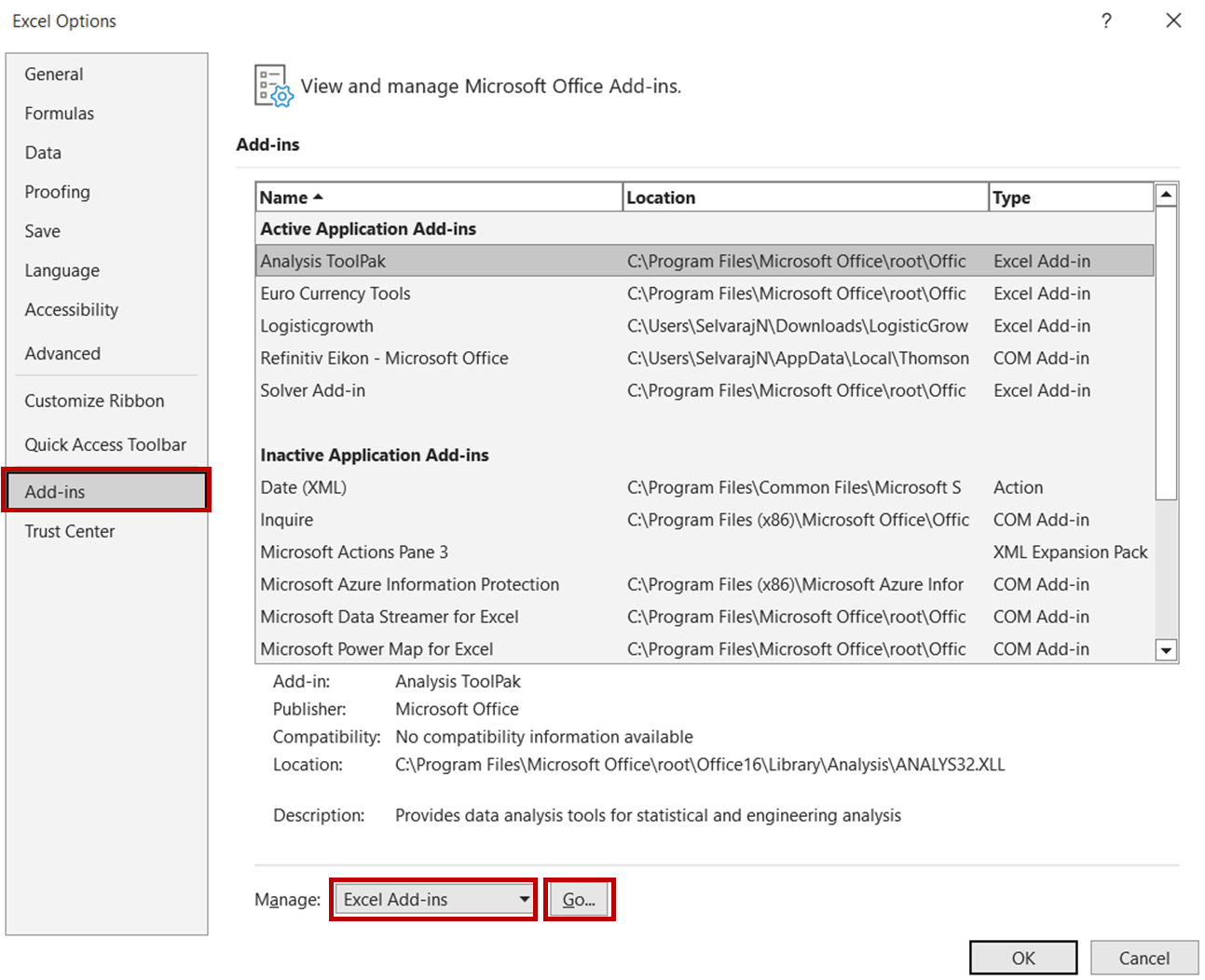
Nella finestra di dialogo Componenti aggiuntivi, seleziona l'opzione Analysis ToolPak e fai clic su OK.
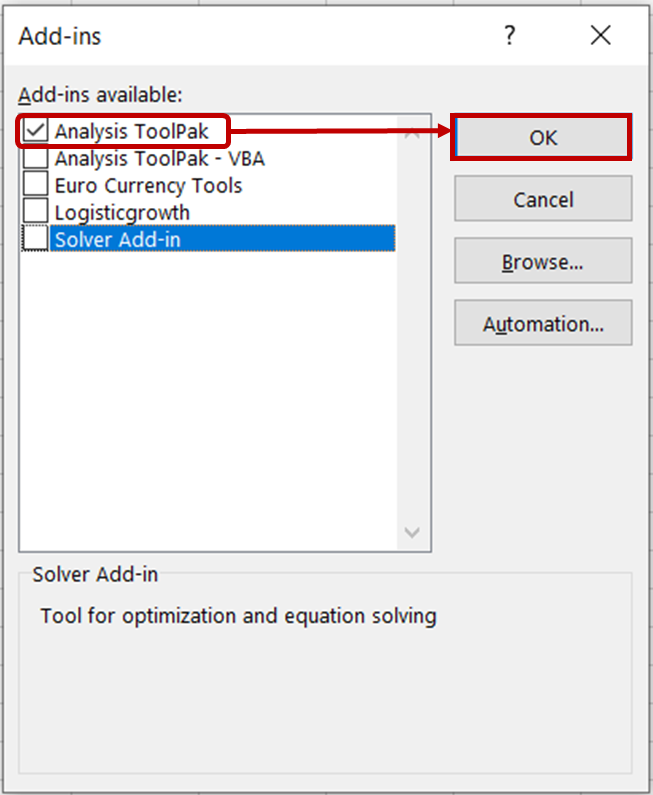
Ora dovresti vedere gli strumenti di Analisi dati nella scheda Dati.
Ora che abbiamo abilitato il Data Analysis ToolPak, possiamo procedere con l'esecuzione della regressione lineare sul dataset. Apri il dataset sulle vendite di gelati e vai alla scheda Dati. Nel gruppo Analisi, fai clic su Analisi dati.

Quindi, seleziona Regressione dall'elenco degli strumenti di analisi e fai clic su OK.
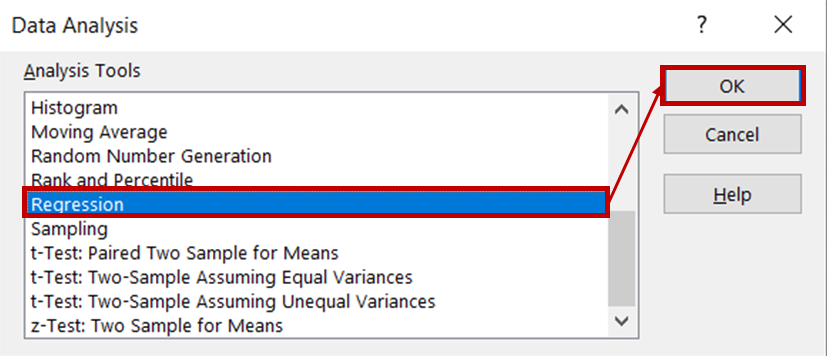
Nella finestra di dialogo della regressione, per Intervallo di input Y seleziona la colonna che contiene i dati delle vendite di gelati. Per Intervallo di input X seleziona le colonne che contengono i dati di temperatura e prezzo. Assicurati che la casella Etichette sia selezionata, così Excel riconoscerà le intestazioni e tratterà le righe rimanenti come dati numerici. Nella sezione Opzioni di output, seleziona Nuovo foglio di lavoro per visualizzare i risultati in un nuovo foglio.
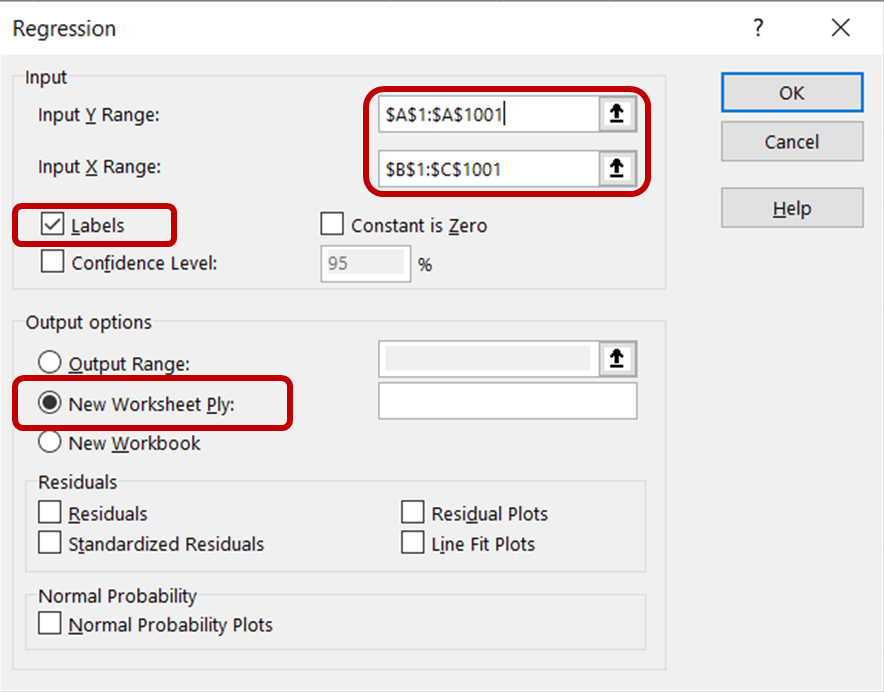
Quindi, fai clic su OK per eseguire l'analisi di regressione sul dataset.
Dopo aver eseguito la regressione, vedrai comparire automaticamente un nuovo foglio di lavoro nel file Excel, con una serie di tabelle di risultati come queste:
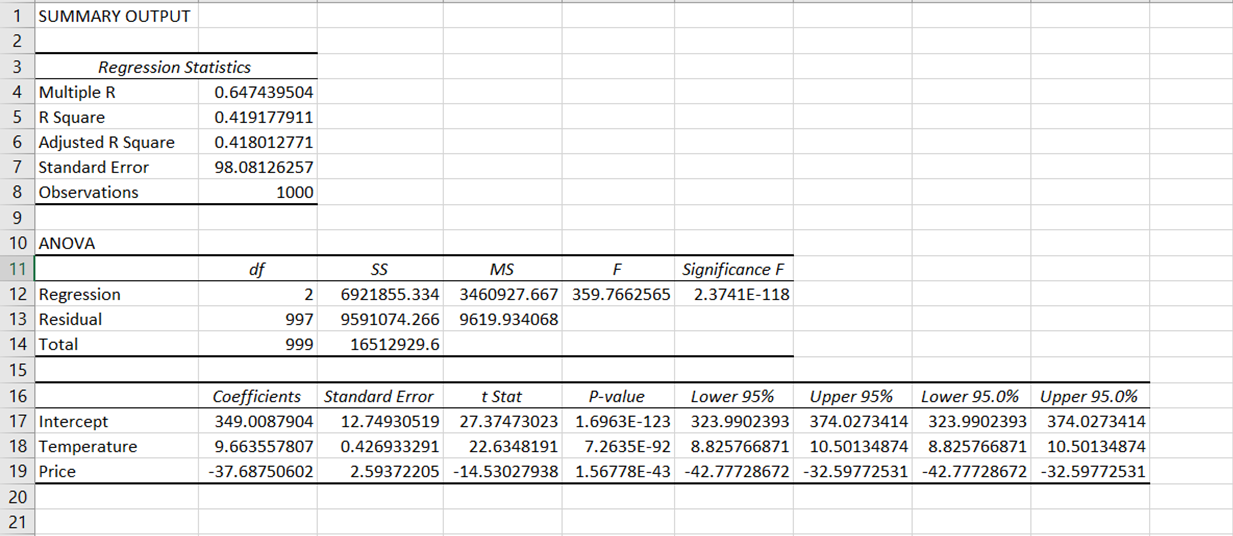
I risultati della regressione sono suddivisi in varie componenti: statistiche della regressione, ANOVA, coefficienti, errore standard, t Stat, p-value e intervallo di confidenza.
Esaminiamo ciascuna di queste componenti più nel dettaglio:
Excel riporta le seguenti statistiche riassuntive come risultato dell'analisi di regressione:
R multiplo
È un coefficiente di correlazione che misura l'intensità e la direzione della relazione lineare tra variabili. Varia da -1 a 1: valori vicini a -1 o 1 indicano una relazione forte, valori vicini a 0 suggeriscono assenza di correlazione.
Nella nostra analisi, il coefficiente di correlazione è circa 0,65, indicando una correlazione positiva moderata tra la variabile dipendente (vendite di gelati) e le variabili indipendenti (prezzo e temperatura).
R quadro
R2 è una misura statistica che indica quanto bene i dati si adattano al modello di regressione. È il quadrato del coefficiente di correlazione, R multiplo, e rappresenta la quota di varianza della variabile dipendente spiegata dalle variabili indipendenti.
R2 varia da 0 a 1, con valori più vicini a 1 che suggeriscono un modello meglio adattato. Il nostro R2 è circa 0,419, il che significa che circa il 41,9% della varianza nelle vendite di gelati è spiegata dal modello.
R quadro corretto
È il valore di R quadro aggiustato per il numero di predittori nel modello. In genere è una misura migliore quando si confrontano modelli con numeri diversi di predittori. Nel nostro caso, l'R2 corretto è 0,418. È molto simile al nostro R2, suggerendo che le variabili indipendenti incluse (temperatura e prezzo) sono pertinenti al modello e non hanno introdotto una grande penalizzazione.
Errore standard
L'errore standard misura la distanza media tra i valori osservati e la retta di regressione. Un errore standard più piccolo è preferibile, perché significa che la retta di regressione si adatta meglio ai dati.
Nel nostro caso, l'errore standard è circa 98,05, indicando che i valori reali delle vendite di gelati si discostano da quelli previsti di circa 98,05 unità.
Osservazioni
Si riferisce al numero totale di punti dati (righe) analizzati nel dataset, escluse le intestazioni.
ANOVA sta per Analisi della varianza. È una tecnica statistica che fornisce informazioni sul livello di variabilità all'interno di un modello di regressione attraverso:
Gradi di libertà (df)
Rappresentano il numero di valori nella stima finale che sono liberi di variare. Nel contesto dell'ANOVA, i df di “Regressione” si riferiscono al numero di variabili indipendenti nel modello, che è 2. I df “Residuo” si calcolano sottraendo dal numero totale di osservazioni il numero di variabili indipendenti e 1. Nel nostro caso, è 997.
Somma dei quadrati (SS)
Quantifica la variazione. La “SS di regressione” misura la variazione nella variabile dipendente spiegata dal modello. La “SS residua” rappresenta la variazione non spiegata.
Media dei quadrati (MS)
Si ottiene dividendo la Somma dei quadrati (SS) per i Gradi di libertà (df).
Statistica F (F)
Questa statistica determina la significatività complessiva del modello. Un valore F più alto indica che il modello si adatta meglio ai dati.
Significatività F
È il p-value associato alla statistica F. Un p-value molto piccolo (inferiore a 0,05) indica che il tuo modello si adatta ai dati meglio di un modello senza variabili indipendenti. Nel nostro caso, il valore di Significatività F è inferiore a 0,05, indicando che il modello si adatta bene ai dati.
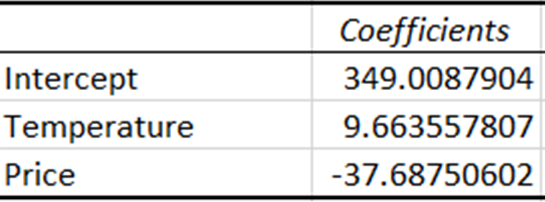
I coefficienti rappresentano la variazione stimata della variabile dipendente per una variazione unitaria della variabile indipendente.
Il coefficiente della temperatura indica che, per ogni aumento di un'unità della temperatura, le vendite aumentano di circa 9,66 unità. Al contrario, il coefficiente del prezzo indica che le vendite diminuiscono di circa 37,69 unità per un aumento di un'unità del prezzo.
L'errore standard misura la distanza media tra i valori osservati e la retta di regressione. Un errore standard più basso indica un modello migliore.
La statistica t è il coefficiente diviso per il suo errore standard. Un valore t più grande indica che il coefficiente è diverso da zero, implicando un impatto maggiore sulla variabile dipendente.
I p-value indicano la probabilità di osservare una statistica t estrema quanto quella osservata, assumendo che l'ipotesi nulla sia vera (cioè che il coefficiente per una variabile indipendente sia 0).
In termini semplici, maggiore è la statistica t e minore è il p-value, maggiori sono le evidenze contro l'ipotesi nulla, a supporto della conclusione che le variabili indipendenti (prezzo e temperatura) hanno un impatto statisticamente significativo sulla variabile dipendente (vendite di gelati).
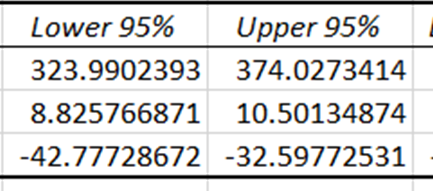
Gli intervalli di confidenza forniscono i limiti inferiore e superiore entro cui ci si aspetta che rientrino i veri coefficienti delle variabili indipendenti, con un livello di confidenza del 95%. Poiché gli intervalli di confidenza per prezzo e temperatura sono diversi da zero, questi coefficienti hanno un impatto statisticamente significativo nella previsione delle vendite di gelati.
Visualizzare la relazione tra due variabili può migliorare notevolmente la comprensione del dataset. Sebbene l'Analysis ToolPak di Excel offra statistiche riassuntive dettagliate, una rappresentazione grafica può mostrarti immediatamente l'intensità e la direzione della relazione tra variabili.
Creare uno scatter plot con una linea di tendenza è un modo efficace per visualizzare questa relazione, e si può fare in meno di cinque minuti. Questa tecnica di visualizzazione ti consente di vedere a colpo d'occhio come una variabile influisce sull'altra.
Ecco come visualizzare la relazione tra “Vendite di gelati” e “Temperatura”:
Per prima cosa, evidenzia le celle contenenti le variabili “Vendite di gelati” e “Temperatura”. Poi, vai alla scheda “Inserisci” e fai clic sull'icona del grafico “Dispersione”:
Vedrai un semplice scatter plot che appare così:
Rinominiamo ora il grafico per descrivere accuratamente la relazione che stiamo visualizzando. Fai semplicemente clic sul titolo del grafico e cambialo in “Relazione tra vendite di gelati e temperatura.”
Successivamente, per modificare l'etichetta dell'asse x, vai su “Progettazione grafico”. Nel menu a discesa “Aggiungi elemento grafico”, seleziona “Titoli degli assi” -> “Orizzontale principale”:
Fai clic sul titolo predefinito dell'asse che compare e digita “Vendite di gelati” per etichettare correttamente l'asse. Fai lo stesso per l'asse y selezionando “Verticale principale” e sostituendo il titolo dell'asse con “Temperatura:”
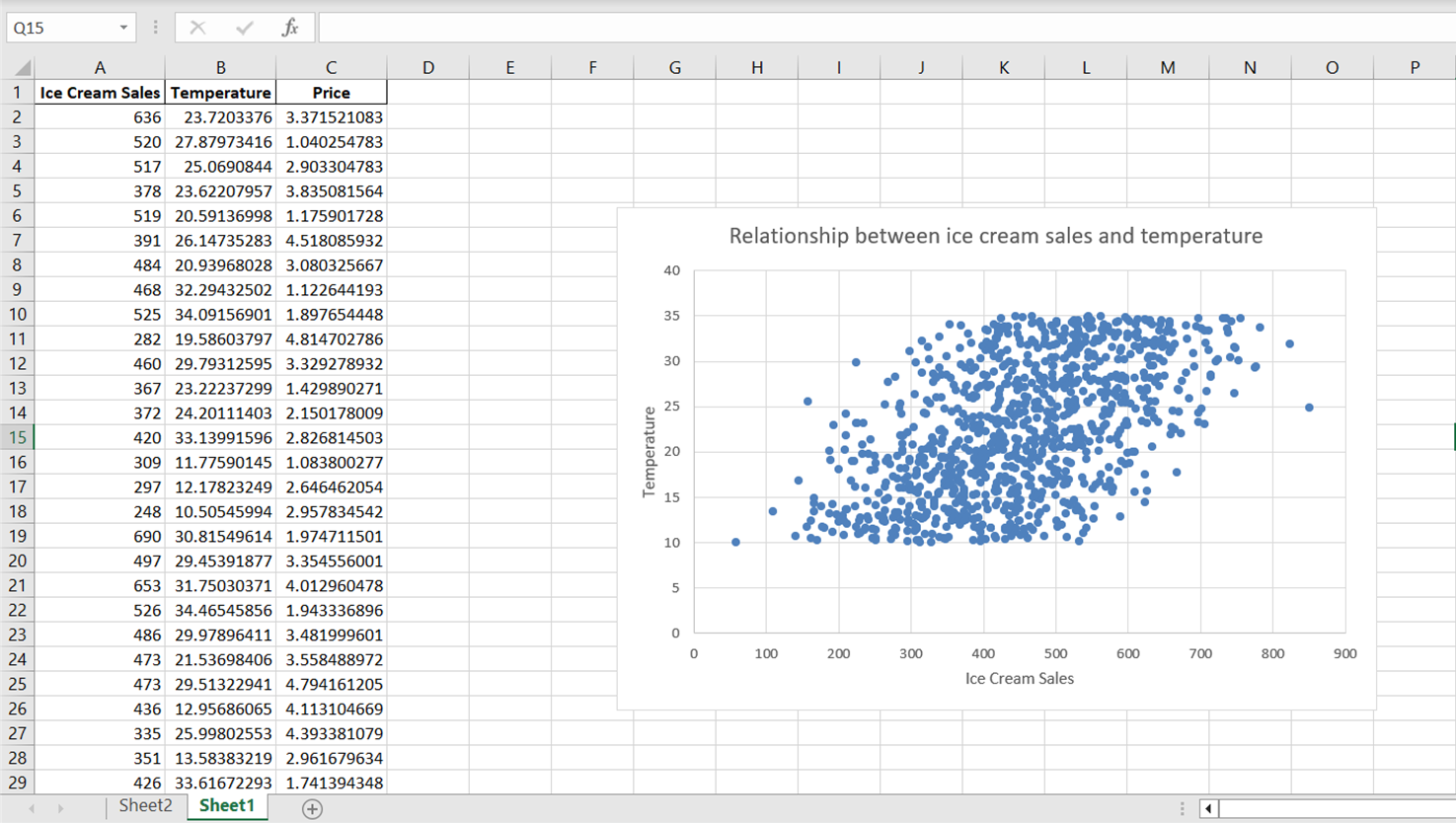
Nota che, sebbene lo scatter plot riveli una direzione generale nella relazione tra temperatura e vendite di gelati, i punti dati appaiono piuttosto dispersi. Per riassumere meglio questa relazione, inclusa la sua direzione complessiva e la pendenza, aggiungiamo una linea di tendenza o linea di miglior adattamento.
Per aggiungere una linea di tendenza a questo grafico, fai semplicemente clic su un qualsiasi punto dati nello scatter plot. Questa azione selezionerà tutti i punti dati nel grafico. Quindi, fai clic con il tasto destro sui punti dati selezionati. Nel menu che appare, scegli “Aggiungi linea di tendenza”:
Dovresti vedere apparire una linea tratteggiata sul grafico, che illustra la direzione generale della relazione tra le variabili:
La linea di tendenza appare tenue e poco evidente. Modifichiamone la formattazione per migliorarne la visibilità.
Per prima cosa, fai clic sulla linea di tendenza per selezionarla. A destra della finestra di Excel apparirà il riquadro “Formato linea di tendenza”. In questo riquadro, seleziona l'opzione “Riempimento e linea”. Poi, aumenta lo spessore della linea di tendenza a 3 pt e cambia il colore in rosso:
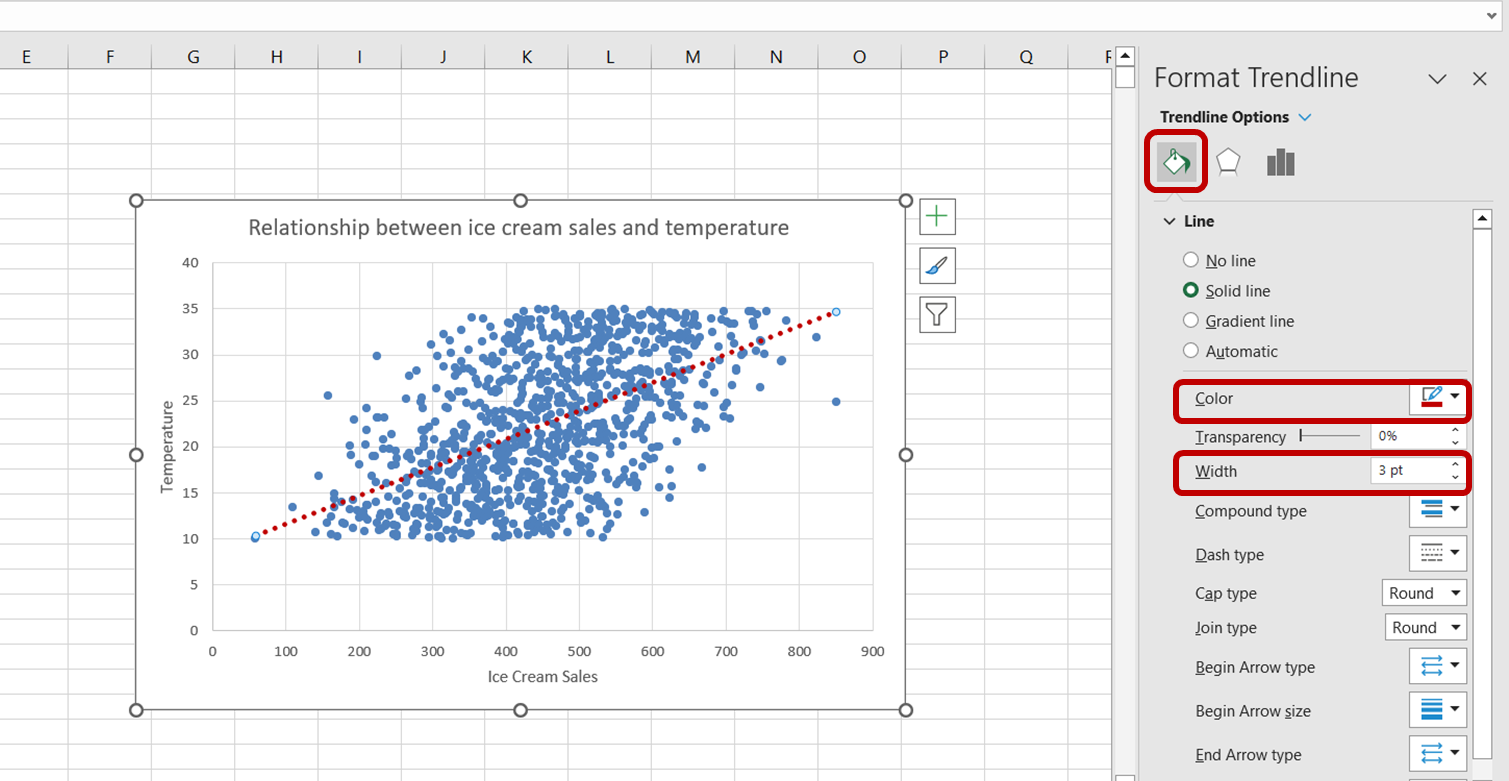
Abbiamo ora creato con successo una visualizzazione per comprendere meglio la relazione tra vendite di gelati e temperatura.
Guardando il grafico qui sopra, possiamo dire che esiste una relazione positiva tra temperatura e vendite di gelati. All'aumentare della temperatura, sembra che aumentino anche le vendite di gelati, indicando che la temperatura è un predittore significativo delle vendite di gelati.
Nota che questa osservazione è simile a quanto abbiamo ricavato dai risultati dell'analisi di regressione nella sezione precedente.
Ora hai acquisito una solida comprensione di come eseguire una regressione lineare in Excel, interpretare varie misure statistiche per valutare l'adattamento di un modello e visualizzare l'analisi di regressione usando scatter plot e linee di tendenza.
Ma il percorso non finisce qui.
Che ci creda o no, abbiamo appena scalfito la superficie della modellazione predittiva, e c'è molto altro da imparare. Ecco alcuni possibili passi successivi per approfondire la tua comprensione dell'argomento.
Metti in pratica i concetti che hai imparato in questo articolo per non dimenticarli. Ad esempio, prendi il dataset usato in questo tutorial e crea uno scatter plot per illustrare la relazione tra vendite di gelati e prezzi.
Puoi spingerti oltre imparando come visualizzare l'equazione di regressione sulla linea di tendenza.
Come abbiamo visto all'inizio dell'articolo, l'ampio utilizzo di Excel in numerose organizzazioni lo rende molto richiesto. Avere una solida padronanza di Excel può aumentare significativamente le tue possibilità di impiego in vari settori grazie alla sua diffusione.
Se hai incontrato difficoltà nel seguire questo tutorial o se non ti senti ancora a tuo agio con le formule di Excel, valuta di iscriverti al nostro percorso di apprendimento Excel Fundamentals. Questo corso ti introdurrà a varie tecniche di visualizzazione dei dati, tabelle pivot e funzioni logiche come COUNTIFs e IF annidati, spianando la strada alla padronanza di Excel.
Inizia oggi il tuo percorso nella regressione!
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

