
Cursus
Introductie tot SQL Server
4 Hr
171.2K
De LAG()-functie is een van SQL’s window-functies waarmee je een nieuwe kolom kunt maken die een vorige rij uit een andere kolom ophaalt. De naam komt van het feit dat elke rij in de nieuwe kolom “achterloopt” om een waarde uit een voorgaande rij in de opgegeven kolom op te halen.
Laten we de basis-syntaxis bekijken. Stel, we hebben een eenvoudige tabel met twee kolommen met dagelijkse aandelenkoersen die er zo uitziet:
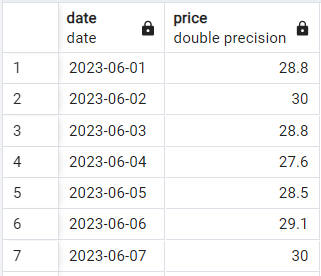
Voorbeeld van aandelenkoersgegevens. Afbeelding door de auteur.
We kunnen de volgende query gebruiken om een nieuwe kolom te maken die in elke rij de prijs van de vorige dag ophaalt met de volgende query:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before
FROM stock_price;En dan krijgen we het volgende resultaat:
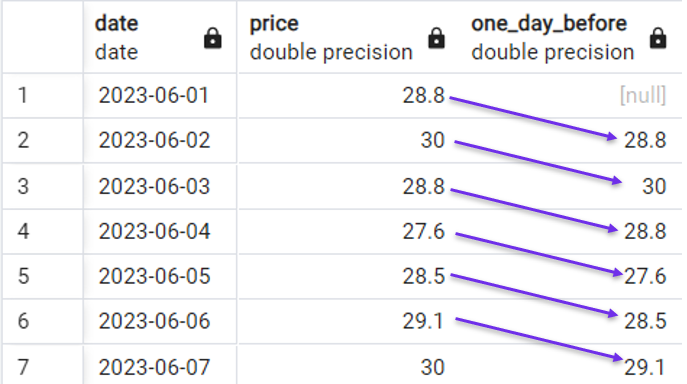
Snel voorbeeld van LAG()-gebruik. Afbeelding door de auteur.
Let op dat we één [null]-waarde hebben gekregen, omdat er voor de eerste rij geen waarde van de vorige dag is.
De LAG()-functie schrijf je in de SELECT-clausule. In de meest eenvoudige vorm ziet de functie er als volgt uit:
LAG(column1) OVER(ORDER BY column2)Hier is dezelfde LAG()-functie toegepast in een losse query:
SELECT
column1,
column2,
LAG(column1) OVER (ORDER BY column2) AS previous_value
FROM
table_name;Zoals je ziet, bestaat de basis-syntaxis uit meerdere onderdelen. Laten we die samen doornemen:
OVER() is verplicht bij elke window-functie. De clausule definieert het frame waarover de window-functie draait. In het bovenstaande voorbeeld draait de window-functie over de geordende column2.ORDER BY is niet verplicht, maar wordt sterk aangeraden bij de LAG()-functie; meestal heeft de functie zonder ORDER BY weinig zin. LAG()-functie volgt. Je kunt meer dan één kolom gebruiken als sorteerbasis.Je vraagt je misschien af wat er zo bijzonder is aan de LAG()-functie. Het antwoord is dat de nieuwe “laggende” kolom kan worden gebruikt om waarden uit twee verschillende rijen te vergelijken.
Daarom wordt de LAG()-functie vaak gebruikt met tijdreeksdata. In onze demo-dataset kunnen we bijvoorbeeld eenvoudig de dagelijkse verandering in aandelenkoers berekenen met de volgende query:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change
FROM stock_price; 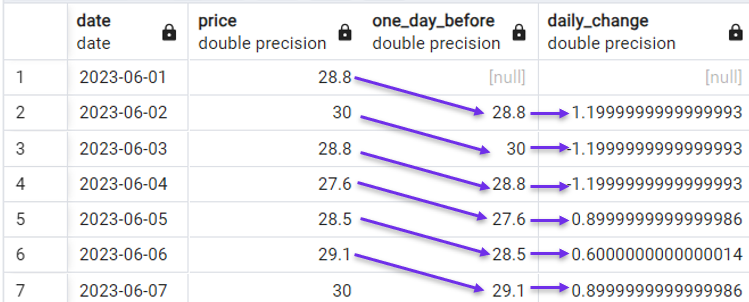
Dagelijkse verandering berekenen met LAG(). Afbeelding door de auteur.
We kunnen ook een stap verder gaan en in plaats daarvan dagelijkse procentuele veranderingen berekenen.
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change,
((price - LAG(price) OVER(ORDER BY date))*100 /
(LAG(price) OVER(ORDER BY date))) AS daily_perc_change
FROM stock_price; 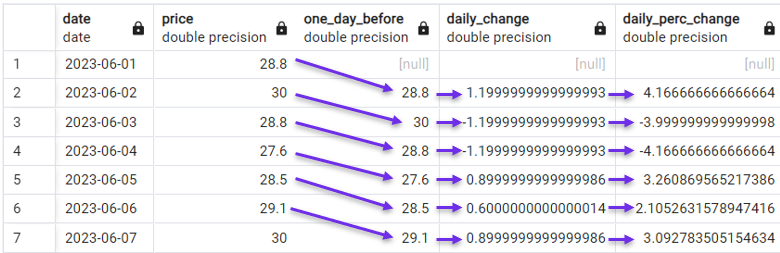
Dagelijkse procentuele verandering berekenen met LAG(). Afbeelding door de auteur.
Nu we het basisgebruik van de LAG()-functie begrijpen, gaan we stap voor stap verder en kijken we wat we er nog meer mee kunnen doen.
Hier schakelen we over naar een andere demo-dataset met maandelijkse omzet voor drie fictieve bedrijven: Welsh LLC, Jones Group en Green-Keebler, van begin 2022 tot halverwege 2024. Zo is de data opgebouwd:
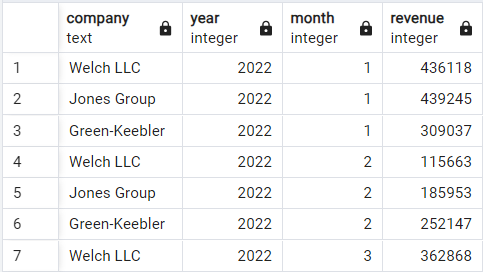
Demo-omzetdataset. Afbeelding door de auteur.
In onze nieuwe dataset moet de lag-kolom worden geordend op basis van twee kolommen: year en month. Zoals eerder genoemd, kan dit door beide kolommen aan de ORDER BY-clausule mee te geven.
In de volgende query maken we een lag-kolom en een maand-op-maand (MoM) omzetverschilkolom, geordend op zowel year als month. Ook filteren we onze query met een WHERE-clausule om ons voorlopig op één bedrijf te richten.
SELECT *,
LAG(revenue) OVER(ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(ORDER BY year, month) AS mom_difference
FROM revenues
WHERE company = 'Welch LLC'; 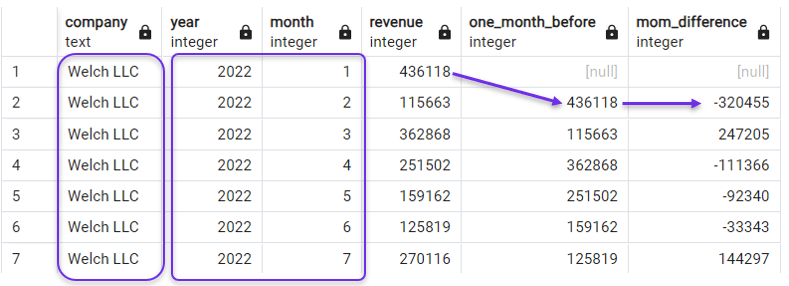
Sorteren op jaar en maand voor LAG(). Afbeelding door de auteur.
Stel dat we dezelfde twee kolommen willen berekenen voor de drie bedrijven in onze dataset. Als we dat op dezelfde manier doen als tot nu toe met LAG(), dan zou de lag-kolom over de drie bedrijven heen lopen en zou de verschilkolom de omzetten van alle bedrijven door elkaar halen, en dat willen we niet.
Wat we wél willen, is de omzet van de vorige maand ophalen en het MoM-verschil per bedrijf afzonderlijk berekenen, en vervolgens opnieuw beginnen bij het volgende bedrijf.
Om dit te doen, voegen we een nieuwe clausule toe aan onze LAG()-syntaxis: PARTITION BY. Die kan aan de basis-syntaxis worden toegevoegd als volgt:
LAG(column1) OVER(PARTITION BY column3 ORDER BY column2)De kolom waarop we in ons voorbeeld moeten partitioneren is company. We passen onze vorige query dus aan door de PARTITION BY-clausule toe te voegen en de WHERE-clausule weg te halen.
SELECT *,
LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS mom_difference
FROM revenues;In het resultaat zien we dat de lag- en MoM-kolommen nu alleen over de maandelijkse omzetten van het eerste bedrijf lopen, en daarna opnieuw beginnen bij het volgende. Dat zie je in de onderstaande screenshot, die de laatste maanden van Green-Keebler en de eerste maanden van Jones Group toont.
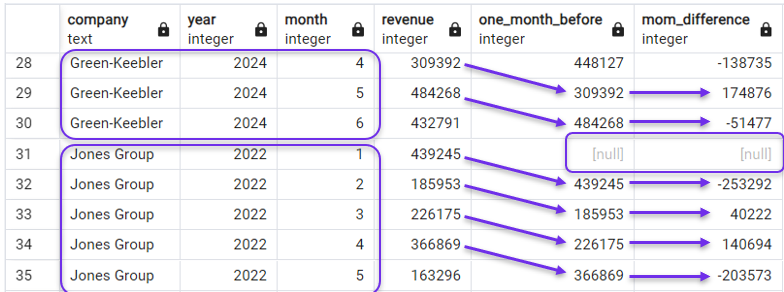
PARTITION BY gebruiken met LAG(). Afbeelding door de auteur.
Wat als we de waarde niet uit de vorige rij nodig hebben, maar uit zes of twaalf rijen erboven? Met andere woorden: wat als we het jaar-op-jaar- (YoY) verschil willen berekenen in plaats van MoM?
Dan voegen we een nieuwe parameter toe aan de LAG()-syntaxis: de offset. Die bepaalt hoeveel rijen boven de huidige rij de LAG()-functie de waarde moet ophalen. De positie in de syntaxis is hieronder te zien:
LAG(column1, offset) OVER(PARTITION BY column3 ORDER BY column2)Standaard, en zoals we de functie tot nu toe hebben gebruikt, is de offset gelijk aan één. Door de offset expliciet in de LAG()-expressie op te geven, kun je deze standaardwaarde wijzigen.
Terug naar ons voorbeeld: om de YoY-omzetverandering te krijgen, moeten we de omzet van dezelfde maand in het vorige jaar ophalen. Dat kan met de volgende query, waarin we 12 als offset opgeven:
SELECT *,
LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;En het resultaat zou zijn:
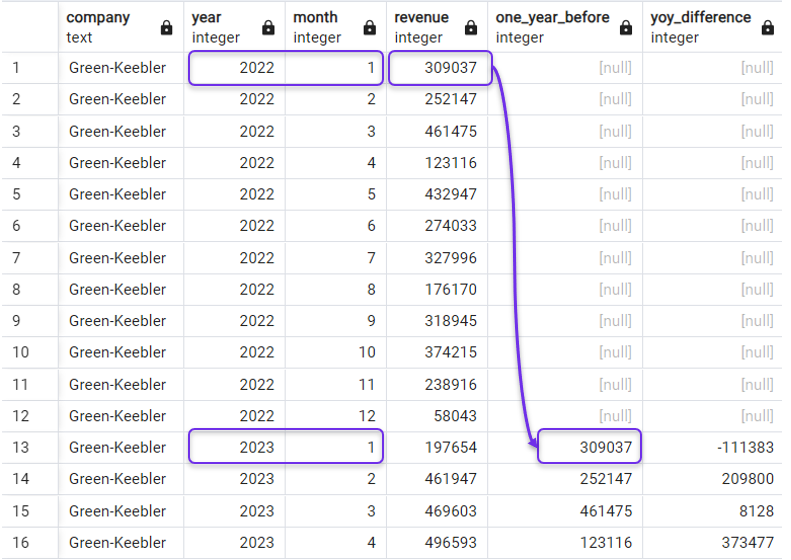
Jaar-op-jaar-verschil met LAG(). Afbeelding door de auteur.
Je hebt misschien gemerkt dat de LAG()-functie NULL retourneert in rijen waar eerdere perioden niet beschikbaar zijn, zoals in de rijen van het jaar 2022 in onze vorige query.
Dit is het standaardgedrag van de LAG()-functie, maar je kunt het aanpassen door expliciet een nieuwe parameter op te geven, “default”. Deze parameter kan elke gehele of decimale numerieke waarde zijn. In de syntaxis staat de parameter als volgt gepositioneerd:
LAG(column1, offset, default) OVER(PARTITION BY column3 ORDER BY column2)Een veelvoorkomend gebruik van de “default”-parameter is wanneer de waarden in de tijdreeks feitelijk bij nul beginnen.
In ons voorbeeld kunnen we aannemen dat de drie bedrijven in januari 2022 zijn opgericht (de vroegste datum in onze dataset), en daarom kunnen we de omzet vóór de oprichting als nul beschouwen. Zo berekenen we de omzetverandering nauwkeuriger, omdat elke omzet in de eerste maanden dan een positieve verandering is.
In onze query zetten we nul als “default”-parameter in beide LAG()-expressies, als volgt:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;En het resultaat geeft nullen in de lag-kolom, en het netto verschil vanaf nul in de YoY-verschilkolom:
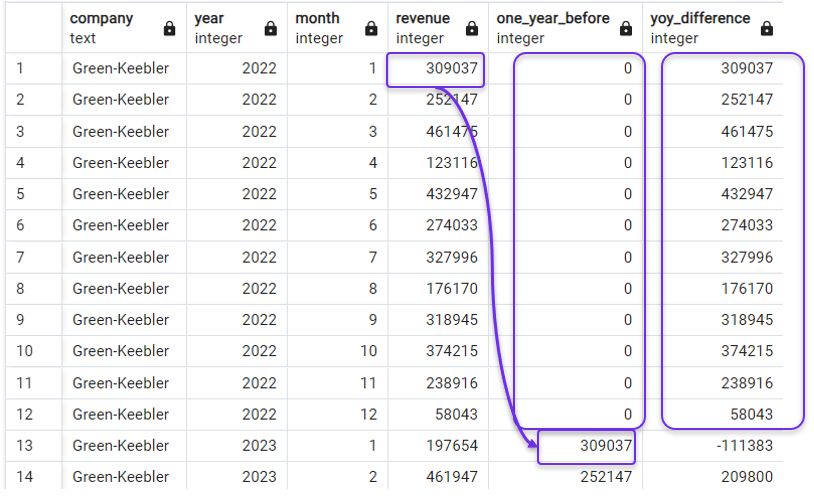
NULL-waarden vervangen door nullen in LAG(). Afbeelding door de auteur.
Let op: als je expliciet een waarde voor de “default”-parameter wilt opgeven, moet je ook expliciet een waarde voor de offset opgeven, omdat het eerste getal na de kolomnaam in de LAG()-functie sowieso als offset wordt gezien.
Als je de “default” wilt aanpassen maar niet de offset, zet de offset-parameter dan op één; dan gedraagt die zich zoals normaal.
Het is handig om te weten dat de volgorde waarop de LAG()-functie afhankelijk is, niet dezelfde hoeft te zijn als de volgorde van het resulterende overzicht. Je kunt die volgorde altijd wijzigen door gewoon de ORDER BY-clausule in je query te gebruiken.
In ons voorbeeld kunnen we het resultaat herschikken zodat we eerst dezelfde maand van hetzelfde jaar voor de drie bedrijven tonen voordat we naar de volgende maand gaan, door in de buitenste ORDER BY-clausule op jaar en maand te sorteren:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues
ORDER BY year, month;En dan krijgen we wat we nodig hebben:
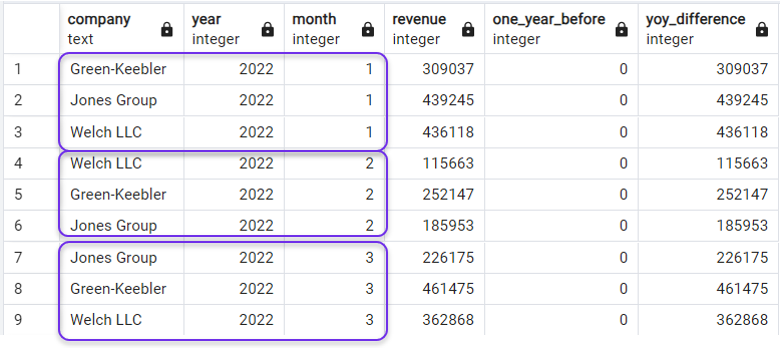
De query sorteren na LAG(). Afbeelding door de auteur.
Laten we naar veelvoorkomende problemen kijken, voor het geval je hulp nodig hebt bij het troubleshooten.
ORDER BY-clausule in de LAG()-instructie kan tot onjuiste resultaten leiden. Zelfs als de oorspronkelijke volgorde van de brontabel geschikt lijkt, vertrouw daar nooit op, want die kan in de tijd veranderen.ORDER BY-clausule in de LAG()-instructie en zorg dat je op de juiste kolom sorteert.LAG()-frame doordat je de PARTITION BY-clausule over het hoofd ziet of deze met de verkeerde kolom gebruikt. LAG()-functie loopt.NULL-waarden in de output van LAG() laten staan wanneer een andere waarde passender is, doordat je de “default”-parameter niet opgeeft.LAG()-instructie in meer dan één kolom gebruikt, moet je in de tweede kolom toch de volledige LAG()-instructie schrijven, niet de alias. De alias van de eerste LAG()-kolom gebruiken levert een fout op.LAG()-instructies altijd volledig uit binnen de SELECT-clausule.LAG()-functie, net als alle window-functies, kan rekenintensief zijn bij grote datasets. Het niet indexeren van de kolommen die in PARTITION BY en ORDER BY worden gebruikt, kan daarom tot slechte prestaties leiden.PARTITION BY en ORDER BY worden gebruikt, waar mogelijk zijn geïndexeerd om de query-prestaties te verbeteren.LAG() en andere window-functies rommelig en lastig te lezen of te begrijpen worden, vooral als er meerdere functies worden gebruikt.LAG() en andere window-functies gebruikt. Dit helpt anderen en jezelf om het doel en de logica achter het gebruik van LAG() te begrijpen wanneer de query later wordt bekeken.In deze tutorial hebben we gezien wat de LAG()-functie is en hoe die een krachtig hulpmiddel kan zijn voor tijdreeksanalyses. Daarnaast hebben we de argumenten en bijbehorende clausules verkend. De volgende keer dat je met tijdgerelateerde of anderszins geordende data in SQL werkt, overweeg dan de LAG()-functie en wat die je laat doen. In andere contexten helpt LAG() bij het vinden van autocorrelaties, het gladstrijken van data of het controleren op onregelmatige intervallen als onderdeel van datacleaning.
Ben je benieuwd wat één window-functie kan doen? Leer dan meer over de hele familie en til je analysekills in SQL naar een hoger niveau met onze interactieve cursus PostgreSQL Summary Stats and Window Functions. En als je dit artikel interessant vond, dan vind je waarschijnlijk ook de Associate Data Analyst in SQL Career Track leuk en kun je aan het eind de SQL Associate Certification behalen!
Leer SQL met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
