
Corso
Introduzione a SQL Server
4 h
171.2K
La funzione LAG() è una funzione finestra di SQL che ti consente di creare una nuova colonna che accede a una riga precedente a partire da un’altra colonna. Il nome deriva dal fatto che ogni riga della nuova colonna "ritarda" per recuperare un valore da una riga precedente dell’altra colonna specificata.
Vediamo la sintassi di base in azione. Supponiamo di avere una semplice tabella a due colonne con i prezzi giornalieri di un titolo, simile a questa:
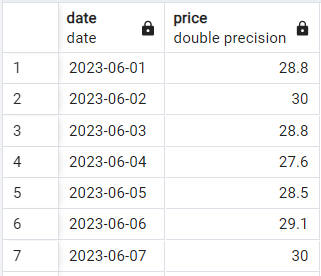
Dati di esempio dei prezzi azionari. Immagine dell’autore.
Possiamo usare la seguente query per creare una nuova colonna che, in ogni riga, ottiene il prezzo del giorno precedente:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before
FROM stock_price;E otterremmo il seguente risultato:
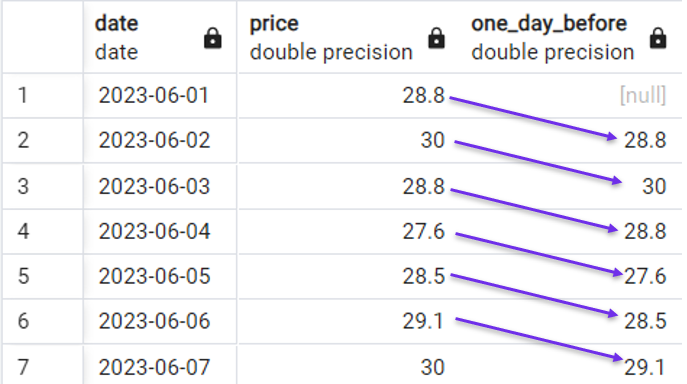
Esempio rapido di utilizzo di LAG(). Immagine dell’autore.
Nota che abbiamo introdotto un valore [null] perché per la prima riga non esiste il valore del giorno precedente.
La funzione LAG() si scrive all’interno della clausola SELECT. Nella sua forma più semplice, può essere scritta così:
LAG(column1) OVER(ORDER BY column2)Ecco la stessa funzione LAG() applicata in una query autonoma:
SELECT
column1,
column2,
LAG(column1) OVER (ORDER BY column2) AS previous_value
FROM
table_name;Come vedi, la sintassi di base è composta da diverse parti. Analizziamole insieme:
OVER() è una parola chiave obbligatoria per ogni funzione finestra. La clausola definisce il frame su cui verrà eseguita la funzione finestra. Nell’esempio sopra, la funzione finestra verrà eseguita sull’ordinamento di column2.ORDER BY non è obbligatorio, ma è altamente consigliato con la funzione LAG(); di solito la funzione non ha senso senza.LAG(). È possibile usare più di una colonna come base per l’ordinamento.Potresti chiederti cosa renda così utile la funzione LAG(). La risposta è che la nuova colonna ritardata può essere usata per confrontare valori di due righe diverse.
Per questo la funzione LAG() è comunemente usata con dati di serie temporali. Per esempio, nel nostro dataset di prova, possiamo calcolare facilmente la variazione giornaliera del prezzo con la seguente query:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change
FROM stock_price; 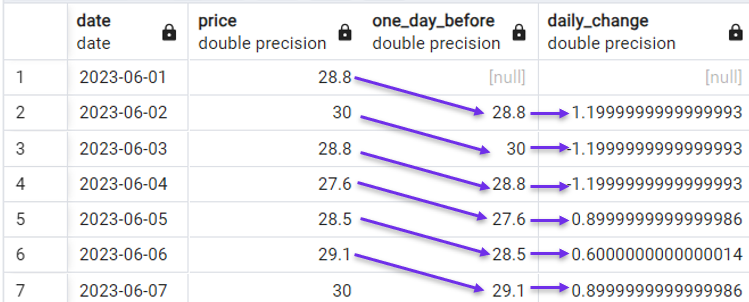
Calcolo della variazione giornaliera con LAG(). Immagine dell’autore.
Possiamo anche passare a un calcolo più sofisticato e considerare invece le variazioni percentuali giornaliere.
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change,
((price - LAG(price) OVER(ORDER BY date))*100 /
(LAG(price) OVER(ORDER BY date))) AS daily_perc_change
FROM stock_price; 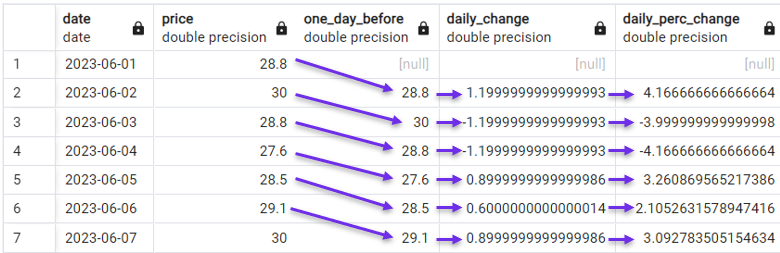
Calcolo della variazione percentuale giornaliera con LAG(). Immagine dell’autore.
Ora che abbiamo capito l’uso di base di LAG(), alziamo gradualmente il livello e vediamo cos’altro possiamo fare.
Passiamo a un altro dataset di esempio che registra i ricavi mensili di tre aziende immaginarie: Welsh LLC, Jones Group e Green-Keebler, dall’inizio del 2022 a metà 2024. Ecco com’è strutturato il dato:
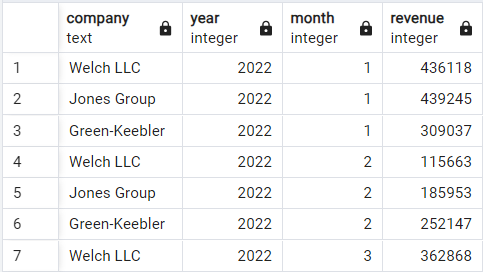
Dataset demo dei ricavi. Immagine dell’autore.
Nel nuovo dataset, la colonna ritardata dovrebbe essere ordinata in base a due colonne: year e month. Come detto, questo si fa passando entrambe le colonne alla clausola ORDER BY.
Nella query seguente creiamo una colonna ritardata e una colonna di differenza dei ricavi mese su mese (MoM), ordinate in base sia a year che a month. Filtriamo anche la query con una clausola WHERE per concentrarci per ora su un’unica azienda.
SELECT *,
LAG(revenue) OVER(ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(ORDER BY year, month) AS mom_difference
FROM revenues
WHERE company = 'Welch LLC'; 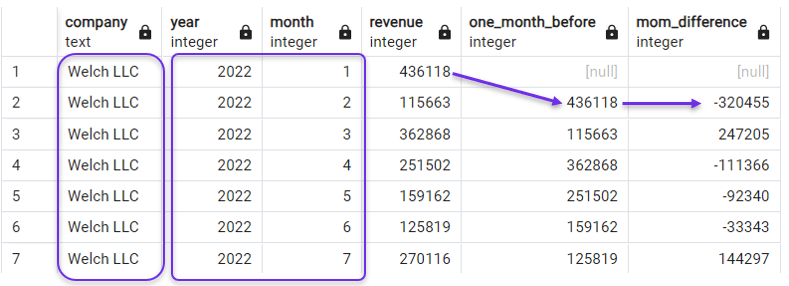
Ordinamento per anno e mese per LAG(). Immagine dell’autore.
Supponiamo di voler calcolare le stesse due colonne per le tre aziende del dataset. Se le calcoliamo come abbiamo fatto finora con LAG(), la colonna ritardata scorrerebbe su tutte e tre le aziende e la colonna della differenza mescolerebbe i ricavi di tutte, cosa che non vogliamo.
Vogliamo invece ottenere il ricavo del mese precedente e calcolare la differenza MoM per ciascuna azienda separatamente, poi ricominciare per l’azienda successiva.
Per farlo, introduciamo una nuova clausola nella sintassi di LAG(): PARTITION BY, che può essere aggiunta alla sintassi di base come segue:
LAG(column1) OVER(PARTITION BY column3 ORDER BY column2)Nel nostro esempio, la colonna per la partizione è company. Quindi modificheremo la query precedente aggiungendo PARTITION BY ed eliminando l’istruzione WHERE.
SELECT *,
LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS mom_difference
FROM revenues;Nel risultato vedremmo che le colonne ritardata e MoM ora scorrono sui ricavi mensili della prima azienda soltanto, poi ricominciano per la successiva. Lo si vede nello screenshot qui sotto, che mostra gli ultimi mesi di Green-Keebler e i primi di Jones Group.
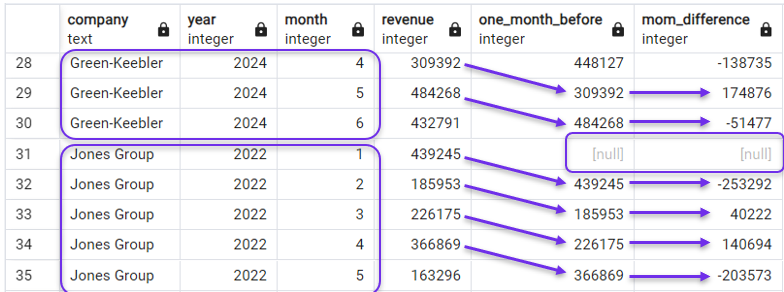
Uso di PARTITION BY con LAG(). Immagine dell’autore.
E se non avessimo bisogno del valore dalla riga precedente, ma da sei o dodici righe sopra? In altre parole, se dovessimo calcolare la differenza anno su anno (YoY) invece della MoM?
In questo caso, aggiungeremmo un nuovo parametro alla sintassi di LAG(). Questo parametro è chiamato offset e specifica quante righe sopra l’attuale vogliamo che LAG() recuperi il valore. La sua posizione nella sintassi è la seguente:
LAG(column1, offset) OVER(PARTITION BY column3 ORDER BY column2)Per impostazione predefinita, e come l’abbiamo usata finora, il valore dell’offset è uguale a uno. Tuttavia, specificando esplicitamente l’offset nell’espressione LAG(), possiamo cambiare questo parametro di default.
Tornando al nostro esempio, per ottenere la variazione YoY dei ricavi dobbiamo prendere il ricavo dello stesso mese dell’anno precedente. Possiamo farlo con la seguente query, in cui specifichiamo 12 come offset:
SELECT *,
LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;E il risultato sarebbe:
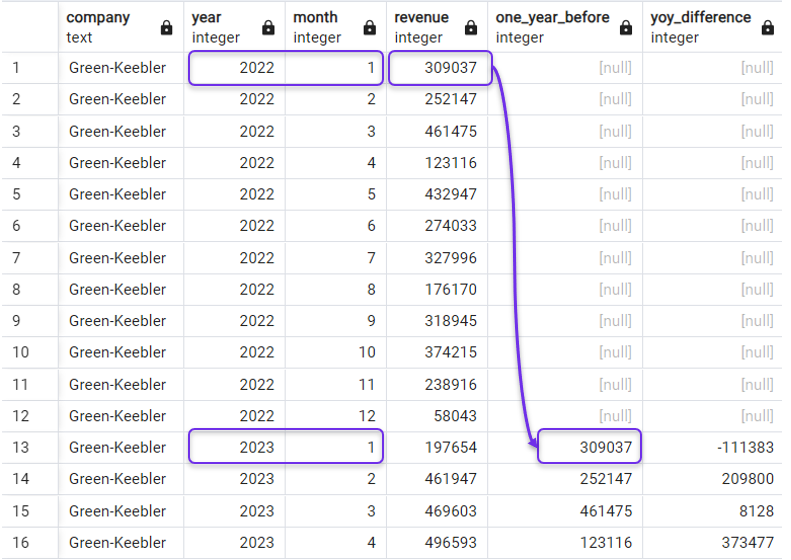
Differenza anno su anno con LAG(). Immagine dell’autore.
Avrai notato che la funzione LAG() restituisce NULL nelle righe in cui i periodi precedenti non sono disponibili, come nelle righe dell’anno 2022 nella query precedente.
Questo è il comportamento predefinito di LAG(), ma può essere modificato specificando esplicitamente un nuovo parametro chiamato "default". Questo parametro può assumere qualsiasi valore numerico intero o float. Nella sintassi della funzione, il parametro è posizionato così:
LAG(column1, offset, default) OVER(PARTITION BY column3 ORDER BY column2)Un caso d’uso comune del parametro "default" è quando i valori di una serie temporale partono effettivamente da zero.
Nel nostro esempio, possiamo assumere che le tre aziende siano state fondate a gennaio 2022 (la data più precoce del dataset) e quindi considerare pari a zero i ricavi precedenti alla fondazione. In questo modo calcoleremo più accuratamente la variazione dei ricavi, dato che qualsiasi ricavo ottenuto nei primi mesi risulterebbe una variazione positiva.
Nella query specificheremo zero come parametro "default" in entrambe le espressioni LAG() come segue:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;E il risultato produrrà zeri nella colonna ritardata e il ricavo netto a partire da zero nella colonna della variazione YoY:
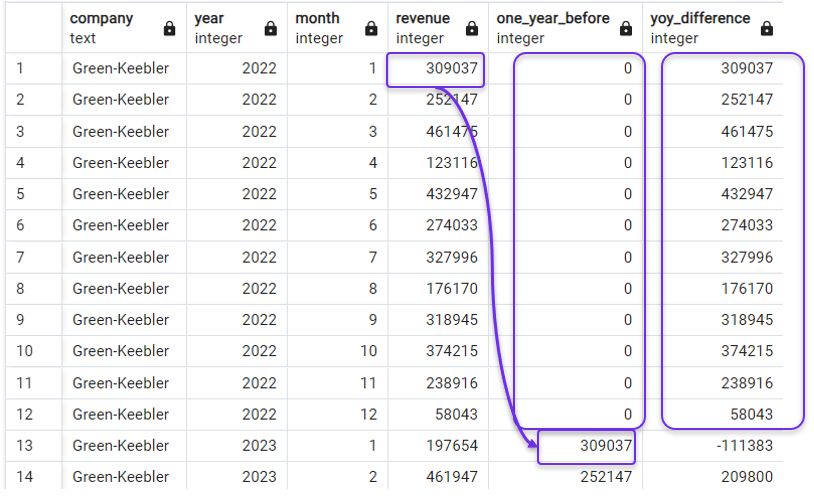
Sostituire i NULL con zeri in LAG(). Immagine dell’autore.
Nota che, per poter specificare esplicitamente un valore per il parametro "default", diventa obbligatorio specificare esplicitamente anche un valore per l’offset, dato che il primo numero fornito dopo il nome della colonna all’interno di LAG() verrà comunque interpretato come offset.
Se hai bisogno di cambiare il "default" ma non l’offset, imposta l’offset a uno e si comporterà come al solito.
È utile sapere che l’ordinamento a cui si affida la funzione LAG() non deve coincidere con l’ordinamento della vista risultante. Puoi sempre cambiarlo usando normalmente la clausola ORDER BY nella query.
Nel nostro esempio, possiamo riordinare il risultato per mostrare lo stesso mese dello stesso anno per le tre aziende prima di passare al mese successivo, ordinando la query per anno e mese nella clausola ORDER BY esterna:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues
ORDER BY year, month;E otterremo ciò che ci serve:
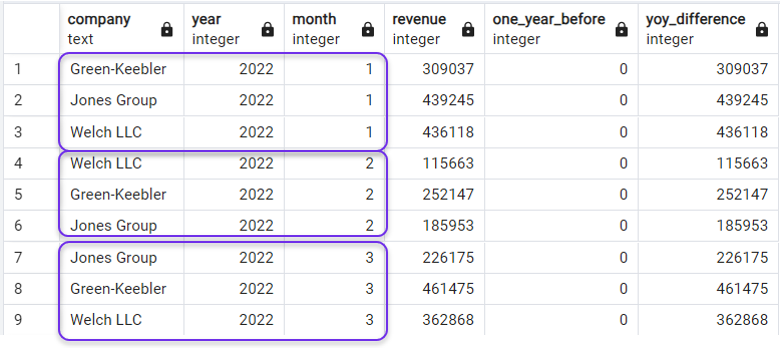
Ordinare la query dopo LAG(). Immagine dell’autore.
Vediamo i problemi più comuni, nel caso ti serva aiuto per il troubleshooting.
ORDER BY nell’istruzione LAG() può portare a risultati sbagliati. Anche se l’ordinamento originale della tabella sorgente è adatto alla funzione, non farci mai affidamento, perché può cambiare nel tempo.ORDER BY nell’istruzione LAG() e assicurati di ordinare per la colonna corretta.LAG() errato per mancato uso della clausola PARTITION BY o per uso sulla colonna sbagliata.LAG().NULL nell’output di LAG() quando sarebbe più opportuno un altro valore, non dichiarando il parametro "default".LAG() in più di una colonna, devi comunque scrivere l’intera istruzione LAG() nella seconda colonna, non il suo alias. Usare l’alias della prima colonna LAG() genererà un errore.LAG() all’interno del SELECT.LAG(), come tutte le funzioni finestra, può essere costosa computazionalmente con dataset grandi. Ignorare l’indicizzazione delle colonne usate nelle clausole PARTITION BY e ORDER BY può portare a scarse prestazioni.PARTITION BY e ORDER BY siano indicizzate, se possibile, per migliorare le prestazioni delle query.LAG() e le altre funzioni finestra possono diventare confuse e poco leggibili, soprattutto quando se ne usano più di una.LAG() e altre funzioni finestra, aggiungi commenti e documenta cosa cerca di ottenere la query. Aiuta gli altri e te stesso a capire scopo e logica dell’uso di LAG() quando la query verrà rivista.In questo tutorial abbiamo visto cos’è la funzione LAG() e come possa essere uno strumento potente per eseguire analisi di serie temporali. Inoltre, abbiamo esplorato i suoi argomenti e le clausole correlate. La prossima volta che lavori con dati temporali, o comunque sequenziali, in SQL, valuta l’uso di LAG() e ciò che ti permette di fare. In altri contesti, LAG() è utile per trovare autocorrelazioni, lisciare i dati o verificare intervalli irregolari come parte della pulizia dei dati.
Se ti incuriosisce ciò che può fare una singola funzione finestra, puoi scoprire l’intera famiglia e far crescere le tue abilità di analisi in SQL con il nostro corso interattivo PostgreSQL Summary Stats and Window Functions. E se ti è piaciuto questo articolo, probabilmente apprezzerai seguire l’Associate Data Analyst in SQL Career Track e ottenere alla fine la SQL Associate Certification!
Impara SQL con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

