
Courses
Giới thiệu về SQL Server
4 giờ
171.2K
Hàm LAG() là một trong các hàm cửa sổ của SQL, cho phép bạn tạo một cột mới truy cập giá trị của hàng trước đó từ một cột khác. Tên gọi của nó xuất phát từ việc mỗi hàng trong cột mới bạn tạo sẽ “trễ” lại để lấy giá trị từ hàng đứng trước trong cột mà bạn chỉ định.
Hãy xem cú pháp cơ bản hoạt động ra sao. Giả sử chúng ta có một bảng hai cột đơn giản với giá cổ phiếu theo ngày như sau:
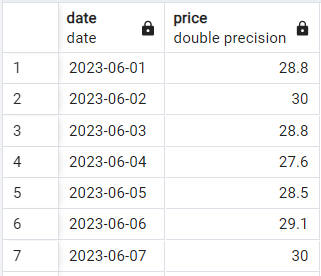
Dữ liệu giá cổ phiếu mẫu. Ảnh: Tác giả.
Ta có thể dùng truy vấn sau để tạo một cột mới lấy giá của ngày liền trước ở mỗi hàng:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before
FROM stock_price;Và đây là kết quả:
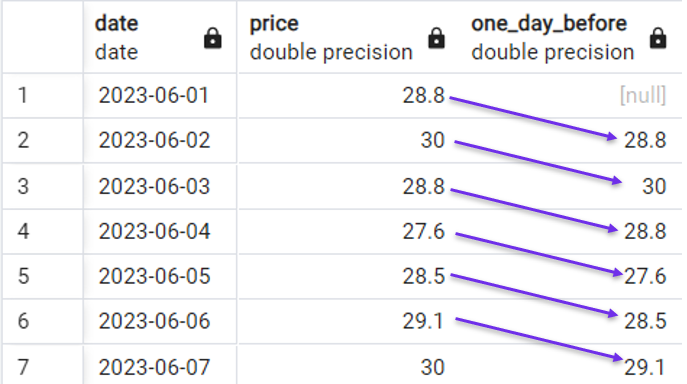
Ví dụ nhanh về cách dùng LAG(). Ảnh: Tác giả.
Lưu ý chúng ta có một giá trị [null] do không có giá trị của ngày trước đó cho hàng đầu tiên.
Hàm LAG() được viết trong mệnh đề SELECT. Ở dạng cơ bản nhất, hàm có thể được viết như sau:
LAG(column1) OVER(ORDER BY column2)Dưới đây là cùng hàm LAG() áp dụng trong một truy vấn độc lập:
SELECT
column1,
column2,
LAG(column1) OVER (ORDER BY column2) AS previous_value
FROM
table_name;Như bạn thấy, cú pháp cơ bản gồm vài phần. Hãy cùng phân tích:
OVER() là từ khóa bắt buộc với mọi hàm cửa sổ. Mệnh đề này xác định phạm vi mà hàm cửa sổ sẽ chạy. Trong ví dụ trên, hàm cửa sổ chạy trên column2 sau khi sắp xếp.ORDER BY không bắt buộc nhưng rất nên dùng với hàm LAG(); thường thì hàm sẽ thiếu ý nghĩa nếu không có nó. LAG() sẽ theo. Có thể dùng nhiều cột làm cơ sở sắp xếp.Bạn có thể thắc mắc điều gì khiến hàm LAG() hữu ích. Câu trả lời là cột “trễ” mới có thể dùng để so sánh giá trị giữa hai hàng khác nhau.
Đó là lý do hàm LAG() thường dùng với dữ liệu chuỗi thời gian. Ví dụ, trong tập dữ liệu minh họa của chúng ta, có thể dễ dàng tính mức thay đổi giá cổ phiếu theo ngày bằng truy vấn sau:
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change
FROM stock_price; 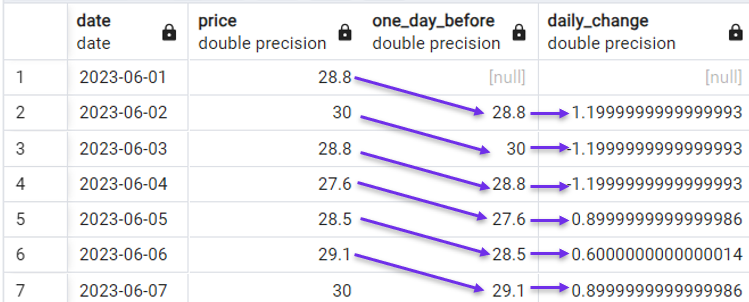
Tính thay đổi theo ngày với LAG(). Ảnh: Tác giả.
Chúng ta cũng có thể tiến tới phép tính tinh vi hơn, xem xét thay đổi phần trăm theo ngày.
SELECT date,
price,
LAG(price) OVER(ORDER BY date) AS one_day_before,
price - LAG(price) OVER(ORDER BY date) AS daily_change,
((price - LAG(price) OVER(ORDER BY date))*100 /
(LAG(price) OVER(ORDER BY date))) AS daily_perc_change
FROM stock_price; 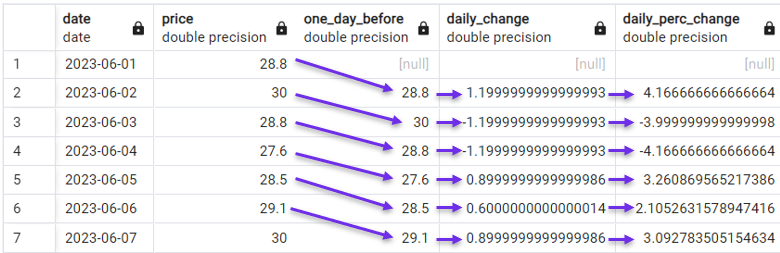
Tính thay đổi phần trăm theo ngày với LAG(). Ảnh: Tác giả.
Giờ khi đã hiểu cách dùng cơ bản của LAG(), hãy nâng dần độ phức tạp và xem còn có thể làm gì với nó.
Tại đây chúng ta chuyển sang một tập dữ liệu minh họa khác ghi nhận doanh thu theo tháng của ba công ty giả định: Welsh LLC, Jones Group và Green-Keebler, từ đầu 2022 đến giữa 2024. Cấu trúc dữ liệu như sau:
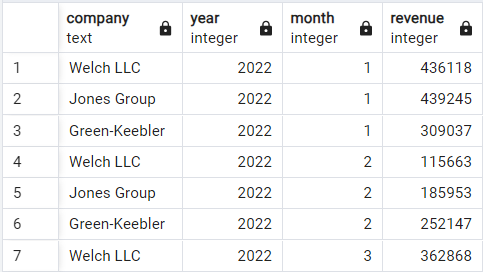
Tập dữ liệu doanh thu minh họa. Ảnh: Tác giả.
Trong tập dữ liệu mới, cột “trễ” cần được sắp xếp dựa trên hai cột: year và month. Như đã đề cập, có thể làm điều này bằng cách đưa cả hai cột vào mệnh đề ORDER BY.
Trong truy vấn sau, chúng ta tạo một cột “trễ” và một cột chênh lệch doanh thu theo tháng (MoM), được sắp xếp theo cả year và month. Chúng ta cũng lọc truy vấn bằng mệnh đề WHERE để tạm thời tập trung vào một công ty.
SELECT *,
LAG(revenue) OVER(ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(ORDER BY year, month) AS mom_difference
FROM revenues
WHERE company = 'Welch LLC'; 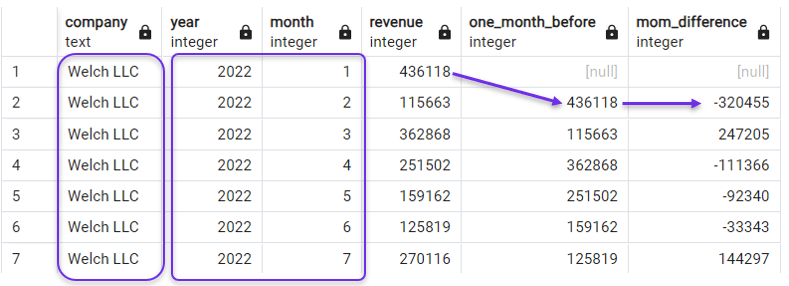
Sắp xếp theo năm và tháng cho LAG(). Ảnh: Tác giả.
Giả sử chúng ta muốn tính hai cột tương tự cho cả ba công ty trong tập dữ liệu. Nếu tính như cách đã làm với LAG() tới giờ, cột “trễ” sẽ chạy xuyên ba công ty, và cột chênh lệch sẽ trộn lẫn doanh thu của tất cả, điều này không đúng mục đích.
Điều chúng ta muốn là lấy doanh thu tháng trước và tính chênh lệch MoM cho từng công ty riêng rẽ, rồi bắt đầu lại cho công ty kế tiếp.
Để làm vậy, ta thêm mệnh đề mới vào cú pháp LAG(): PARTITION BY, có thể chèn vào cú pháp cơ bản như sau:
LAG(column1) OVER(PARTITION BY column3 ORDER BY column2)Trong ví dụ này, cột cần phân vùng là company. Vì vậy, ta sẽ sửa truy vấn trước bằng cách thêm PARTITION BY và bỏ mệnh đề WHERE.
SELECT *,
LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS one_month_before,
revenue - LAG(revenue) OVER(PARTITION BY company ORDER BY year, month) AS mom_difference
FROM revenues;Kết quả cho thấy các cột “trễ” và MoM giờ đây chạy qua doanh thu theo tháng của từng công ty riêng lẻ, rồi bắt đầu lại cho công ty tiếp theo. Ta có thể thấy điều này trong ảnh chụp dưới đây, hiển thị các tháng cuối của Green-Keebler và các tháng đầu của Jones Group.
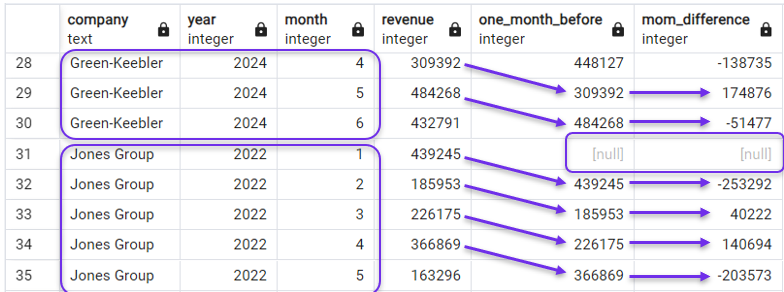
Dùng PARTITION BY với LAG(). Ảnh: Tác giả.
Điều gì xảy ra nếu chúng ta không cần lấy giá trị từ hàng liền trước mà là từ sáu hoặc mười hai hàng phía trên? Nói cách khác, nếu cần tính chênh lệch theo năm (YoY) thay vì theo tháng (MoM)?
Khi đó, ta thêm một tham số mới vào cú pháp LAG(). Tham số này gọi là offset, xác định số hàng phía trên hiện tại mà LAG() sẽ lấy giá trị. Vị trí của nó trong cú pháp như sau:
LAG(column1, offset) OVER(PARTITION BY column3 ORDER BY column2)Theo mặc định, và như cách ta đã dùng đến giờ, giá trị offset bằng một. Tuy nhiên, bằng cách chỉ định rõ offset trong biểu thức LAG(), chúng ta có thể thay đổi tham số mặc định này.
Quay lại ví dụ, để lấy thay đổi doanh thu YoY, ta cần doanh thu của cùng tháng ở năm trước. Có thể làm như sau, với 12 là offset:
SELECT *,
LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;Và kết quả sẽ là:
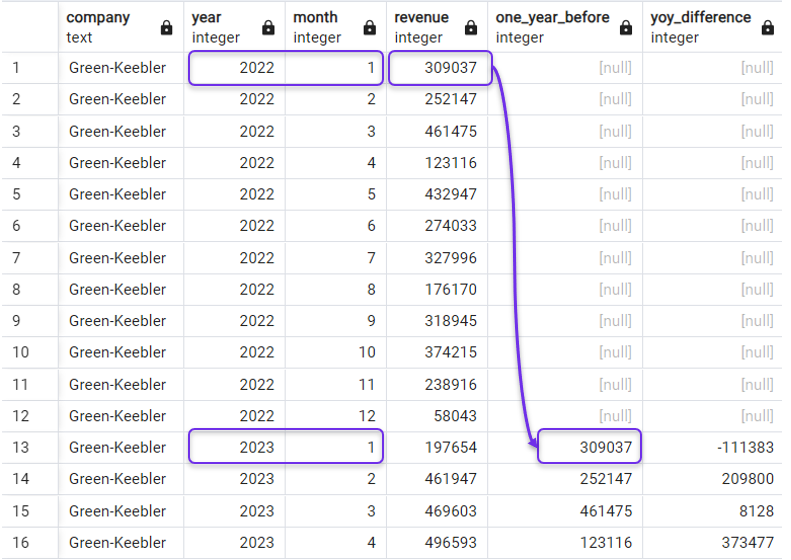
Chênh lệch theo năm với LAG(). Ảnh: Tác giả.
Bạn có thể nhận thấy hàm LAG() trả về NULL ở các hàng không có dữ liệu kỳ trước, như các hàng năm 2022 trong truy vấn vừa rồi.
Đây là hành vi mặc định của LAG(), nhưng có thể thay đổi bằng cách chỉ định rõ tham số mới gọi là “default”. Tham số này có thể nhận bất kỳ giá trị số nguyên hoặc số thực nào. Trong cú pháp hàm, tham số nằm như sau:
LAG(column1, offset, default) OVER(PARTITION BY column3 ORDER BY column2)Tình huống phổ biến của tham số “default” là khi các giá trị thực tế bắt đầu từ 0 trong dữ liệu chuỗi thời gian.
Trong ví dụ của chúng ta, có thể giả định ba công ty được thành lập vào tháng 1/2022 (mốc sớm nhất trong tập dữ liệu), do đó có thể coi doanh thu trước thời điểm thành lập là 0. Cách này giúp tính thay đổi doanh thu chính xác hơn, vì bất kỳ doanh thu nào trong những tháng đầu đều là thay đổi dương.
Trong truy vấn, chúng ta sẽ đặt 0 làm tham số “default” trong cả hai biểu thức LAG() như sau:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues;Và kết quả sẽ đưa về số 0 trong cột “trễ”, cũng như doanh thu thuần từ 0 trong cột thay đổi doanh thu YoY:
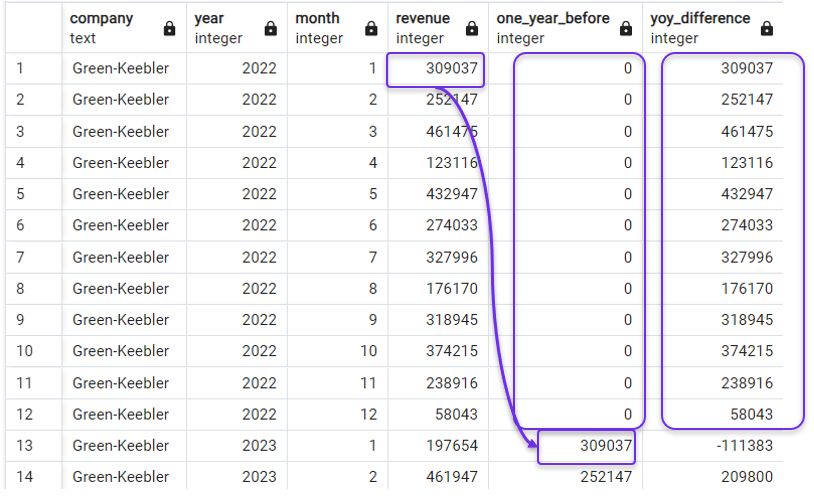
Thay NULL bằng 0 trong LAG(). Ảnh: Tác giả.
Lưu ý rằng để có thể chỉ định rõ giá trị cho tham số “default”, bạn bắt buộc cũng phải chỉ định rõ giá trị cho offset, vì số đầu tiên sau tên cột trong hàm LAG() sẽ được hiểu là offset.
Nếu bạn cần thay đổi “default” nhưng không muốn đổi offset, hãy đặt offset là 1, khi đó nó sẽ hoạt động như bình thường.
Điều hữu ích cần biết là thứ tự mà hàm LAG() dựa vào không nhất thiết phải trùng với thứ tự của kết quả hiển thị. Bạn luôn có thể thay đổi thứ tự đó bằng cách dùng mệnh đề ORDER BY như thông thường trong truy vấn.
Trong ví dụ, ta có thể sắp xếp lại kết quả để hiển thị cùng một tháng của cùng một năm cho cả ba công ty trước khi chuyển sang tháng kế tiếp, bằng cách sắp xếp theo year và month trong mệnh đề ORDER BY bên ngoài:
SELECT *,
LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS one_year_before,
revenue - LAG(revenue, 12, 0) OVER(PARTITION BY company ORDER BY year, month) AS yoy_difference
FROM revenues
ORDER BY year, month;Và chúng ta sẽ có đúng điều mình cần:
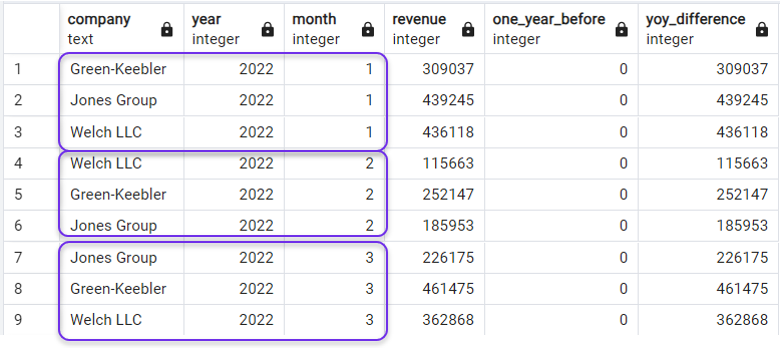
Sắp xếp truy vấn sau khi dùng LAG(). Ảnh: Tác giả.
Hãy xem các vấn đề phổ biến để bạn dễ khắc phục khi cần.
ORDER BY trong câu lệnh LAG() có thể dẫn đến kết quả sai. Dù thứ tự ban đầu của bảng nguồn có thể phù hợp, đừng bao giờ phụ thuộc vào thứ tự đó vì nó có thể thay đổi theo thời gian.ORDER BY trong câu lệnh LAG(), và đảm bảo bạn sắp xếp theo đúng cột.LAG() sai do bỏ qua mệnh đề PARTITION BY hoặc dùng với cột không phù hợp. LAG() của bạn chạy trên đó.NULL trong đầu ra của LAG() khi một giá trị khác phù hợp hơn, do không khai báo tham số “default”.LAG() ở nhiều cột, bạn vẫn phải viết đầy đủ câu lệnh LAG() ở cột thứ hai, không dùng bí danh. Dùng bí danh của cột LAG() đầu tiên sẽ gây lỗi.LAG() trong mệnh đề SELECT.LAG(), như các hàm cửa sổ khác, có thể tốn tài nguyên tính toán với tập dữ liệu lớn. Vì vậy, bỏ qua việc lập chỉ mục cho các cột dùng trong PARTITION BY và ORDER BY có thể dẫn đến hiệu suất kém.PARTITION BY và ORDER BY được lập chỉ mục nếu có thể để cải thiện hiệu năng truy vấn.LAG() và các hàm cửa sổ khác có thể trở nên rối rắm, khó đọc hoặc hiểu, nhất là khi dùng nhiều hàm.LAG() và các hàm cửa sổ khác, hãy thêm chú thích và mô tả mục tiêu của truy vấn. Điều này giúp người khác và chính bạn hiểu mục đích và logic đằng sau việc dùng LAG() khi xem lại truy vấn.Trong hướng dẫn này, chúng ta đã xem hàm LAG() là gì và vì sao nó có thể là công cụ mạnh để thực hiện phân tích chuỗi thời gian. Ngoài ra, chúng ta cũng tìm hiểu các tham số và mệnh đề liên quan. Lần tới khi làm việc với dữ liệu liên quan đến thời gian, hoặc bất kỳ dữ liệu có thứ tự nào trong SQL, hãy cân nhắc sử dụng LAG() và những gì nó cho phép bạn thực hiện. Ở các ngữ cảnh khác, LAG() hữu ích để tìm tự tương quan, làm mượt dữ liệu, hoặc kiểm tra khoảng thời gian bất thường trong quá trình làm sạch dữ liệu.
Nếu bạn hứng thú với những gì một hàm cửa sổ có thể làm, hãy tìm hiểu cả “gia đình” này và nâng tầm kỹ năng phân tích SQL của bạn với khóa học tương tác PostgreSQL Summary Stats and Window Functions toàn diện. Và nếu bạn thích bài viết này, có lẽ bạn cũng sẽ thích theo học lộ trình nghề nghiệp Associate Data Analyst in SQL và nhận chứng chỉ SQL Associate vào cuối khóa!
Học SQL với DataCamp
Courses
Courses
Courses