
Curso
Entendendo Machine Learning
2 h
293.2K
Imagina que você está desenvolvendo um carro autônomo. Para que o carro “veja” e entenda a estrada, ele precisa aprender a reconhecer coisas como pedestres, sinais de trânsito e outros veículos. Pra isso rolar, osistema de machine learning do carprecisa de milhares, se não milhões, de imagens de situações reais de direção.
Mas o carro não consegue entender o que está nas imagens. Ele não sabe que um octógono vermelho é um sinal de pare ou que uma pessoa está andando na calçada. É aí que entra a anotação de dados.
A anotação de dados é o processo de rotular dados brutos para torná-los compreensíveis e utilizáveis para modelos de machine learning. Vamos explicar isso com mais detalhes depois, mas fica de olho nisso.
Aqui está o que vamos ver neste artigo:
Vamos lá!
A melhor maneira de pensar em anotação de dados é imaginar como é ensinar crianças sobre diferentes animais. Primeiro,, você mostra uma foto de um cachorro e diz: “Isso é um cachorro”. Depois, mostra um gato e diz: “Isso é um gato”. Com o tempo, mostrando exemplos com rótulos, a criança aprende a identificar os animais sozinha. A anotação de dados funciona de maneira parecida para as máquinas.
Assim como uma criança precisa de exemplos rotulados (lembre-se: dizer “Isso é um cachorro” é a rotulagem), os modelos de machine learning precisam que os dados sejam anotados para aprender com eles. Então, a anotação de dados é o processo de rotular ou marcar dados, como imagens, texto ou áudio, para que os algoritmos de machine learning possam reconhecê-los e entendê-los.
As etiquetas são tipo exemplos que ensinam ao sistema quais padrões procurar. Por exemplo, se você marcar milhares de imagens com as etiquetas “cachorro” ou “gato”, o modelo vai começar a perceber as diferenças entre os dois.
Depois de aprender com esses exemplos, o modelo pode fazer previsões ou classificar novos dados sem rótulos, assim como a criança acaba reconhecendo os animais sem a sua ajuda.
Diferentes tipos de dados precisam de métodos de anotação específicos pra serem preparados pra tarefas de machine learning. Dependendo do tipo de dados, tem maneiras diferentes de rotular e marcar. Entender esses tipos ajuda a descobrir a melhor maneira de treinar modelos para várias aplicações.
Vamos ver os tipos mais comuns de anotação de dados:
A anotação de imagens envolve rotular imagens para que os modelos de machine learning possam identificar e interpretar objetos dentro delas. Diferentes técnicas são usadas na anotação de imagens, dependendo do nível de detalhe necessário:

Caixas delimitadoras. : Anolytics
Esse método envolve desenhar retângulos ao redor dos objetos em uma imagem para ajudar o modelo a reconhecer a presença e a localização deles. As caixas delimitadoras são muito usadas pra detectar carros, pedestres ou sinais na tecnologia de direção autônoma.

Segmentação semântica. Fonte: Introdução à segmentação semântica de imagens
Aqui, cada pixel de uma imagem é rotulado para atribuir regiões específicas a objetos ou categorias específicas, como identificar estradas, edifícios ou árvores. Essa técnica dá ao modelo uma compreensão mais detalhada da cena.

Anotação de ponto de referência. : Anolytics
Essa técnica envolve marcar pontos específicos dentro de uma imagem, como características faciais ou pontos-chave na postura corporal. É usado em aplicações como reconhecimento facial e estimativa da postura humana.
A anotação de texto é o processo de rotular e marcar dados de texto para torná-los compreensíveis para modelos de processamento de linguagem natural (NLP). Isso faz com que as máquinas entendam, processem e analisem a linguagem humana.
Tem várias técnicas comuns usadas na anotação de texto:

Reconhecimento de entidades. Fonte: Reconhecimento e classificação de entidades nomeadas com Scikit-Learn
Isso envolve identificar coisas específicas no texto, tipo nomes de pessoas, lugares ou organizações. Por exemplo, na frase “A Apple abriu uma nova loja em Nova York”, o modelo reconheceria “Apple” como uma empresa e “Nova York” como um lugar.

Marcação de sentimentos. SouFonte: Entendendo o processo de anotação de texto para análise do sentimento do cliente
Essa técnica atribui emoções ou opiniões a trechos de texto, classificando-os como positivos, negativos ou neutros. É muito usado em avaliações de clientes ou monitoramento de redes sociais pra entender como os usuários se sentem em relação a um produto ou serviço.
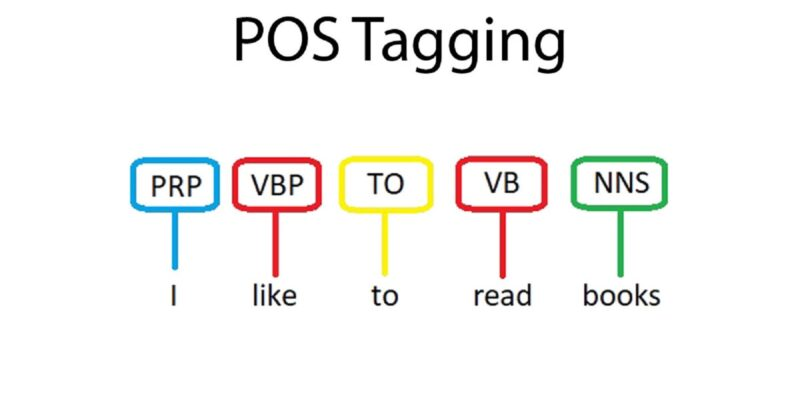
Etiquetagem POS. Fonte: Marcação POS em PLN
Esse método coloca uma etiqueta em cada palavra de uma frase com sua função gramatical (por exemplo, substantivo, verbo, adjetivo), ajudando os modelos a entender a estrutura da linguagem para tarefas como tradução ou reconhecimento de fala.
A anotação de áudio é quando a gente coloca rótulos em arquivos de som pra treinar modelos pra reconhecimento de fala, detecção de música ou classificação de sons.
Algumas técnicas comuns de anotação de áudio são:
Converter palavras faladas em um arquivo de áudio em texto escrito é algo que a gente vê bastanteem aplicativos de conversão de voz em texto.
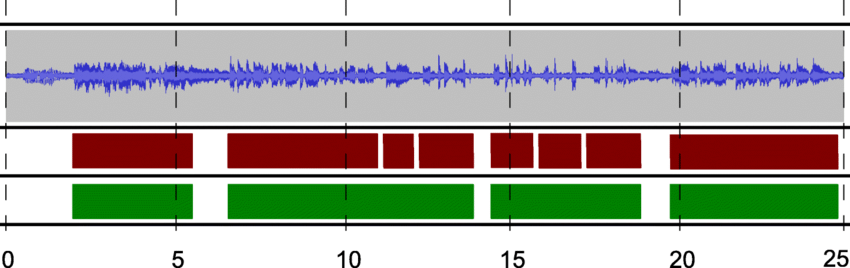
Segmentação da fala. : ResearchGate
Isso é dividir um arquivo de áudio em várias partes. Por exemplo, você pode querer separar o diálogo do barulho de fundo ou identificar quem está falando em uma conversa.
Marcação de sons. Então,fonte: Marcação Freesound por VGGish com KNN
A marcação de sons é quando sons específicos (por exemplo, barulho de trânsito, sons de animais, etc.) são rotulados dentro de um arquivo de áudio.
A anotação de vídeo envolve rotular e marcar objetos ou ações em quadros de vídeo para ajudar os modelos de machine learning a entender movimentos e atividades.
As principais técnicas de anotação de vídeo incluem:
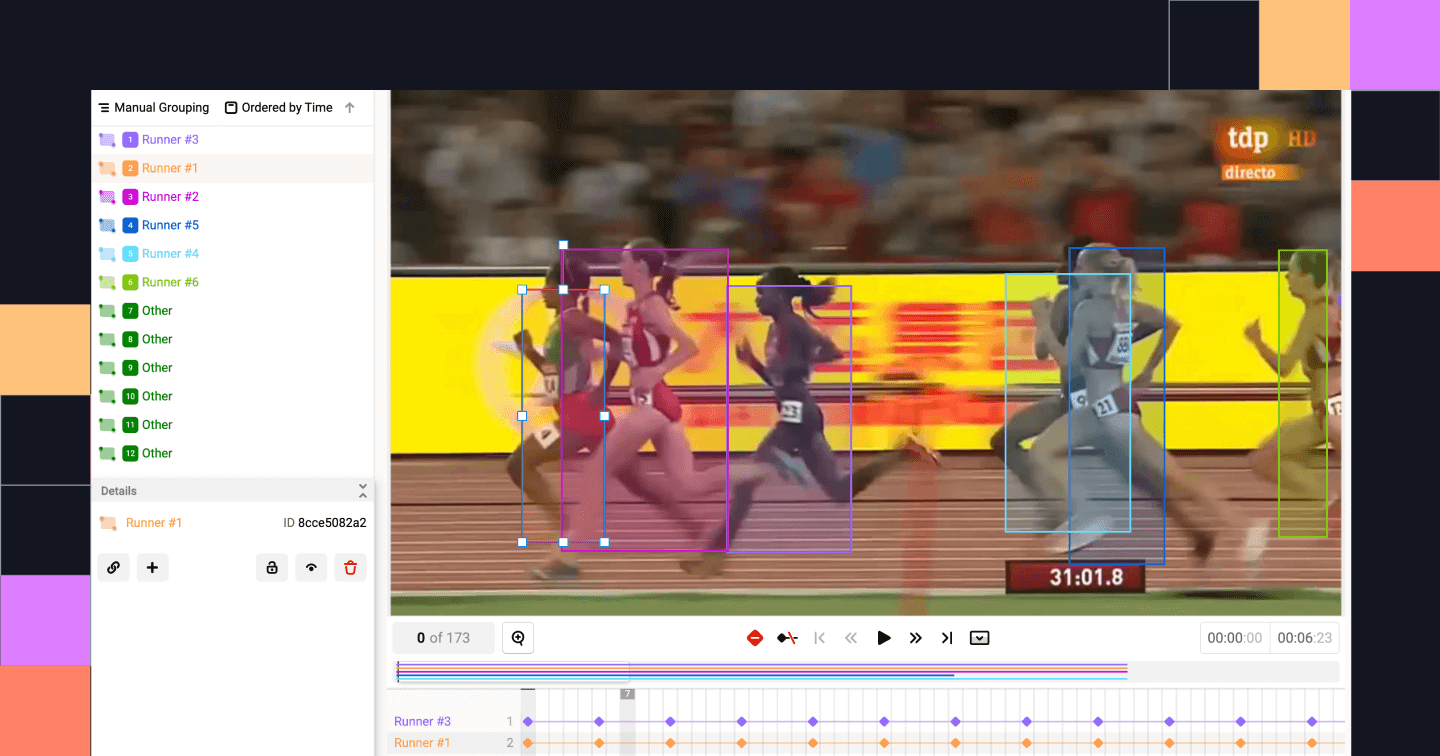
Rastreamento de objetos. Fonte: Estúdio de etiquetas
O rastreamento de objetos envolve rotular objetos de forma contínua em vários quadros para acompanhar seus movimentos. Em cenários de direção autônoma, por exemplo, dá pra usar o rastreamento de objetos pra acompanhar um veículo em um cruzamento movimentado.
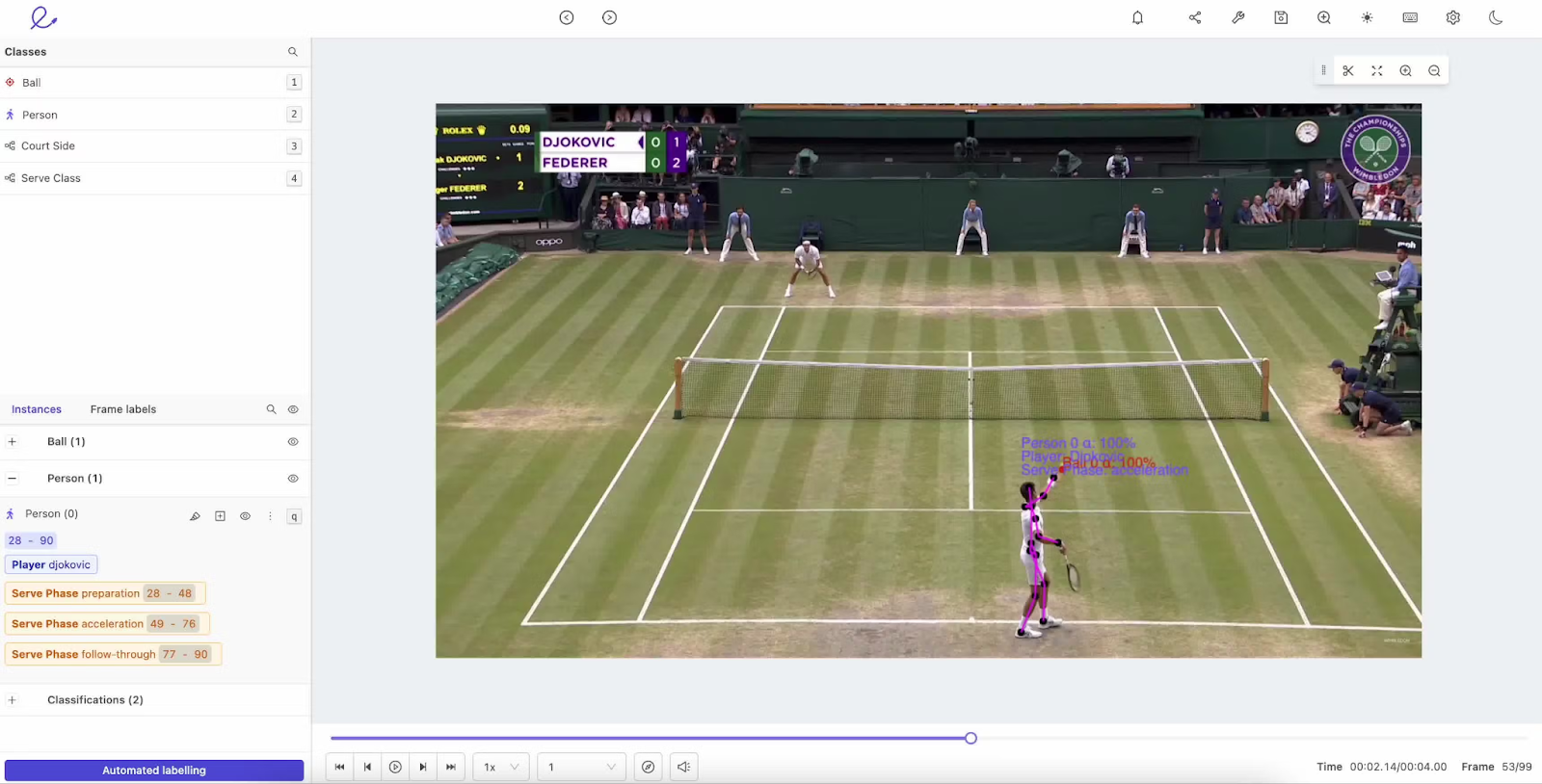
Rotulagem de atividades. SouFonte: Encord
É quando rótulos são atribuídos a ações específicas, como alguém andando, correndo ou sentando em um vídeo. Isso ajuda os modelos a entender o comportamento humano em aplicações como monitoramento de segurança ou análise esportiva.
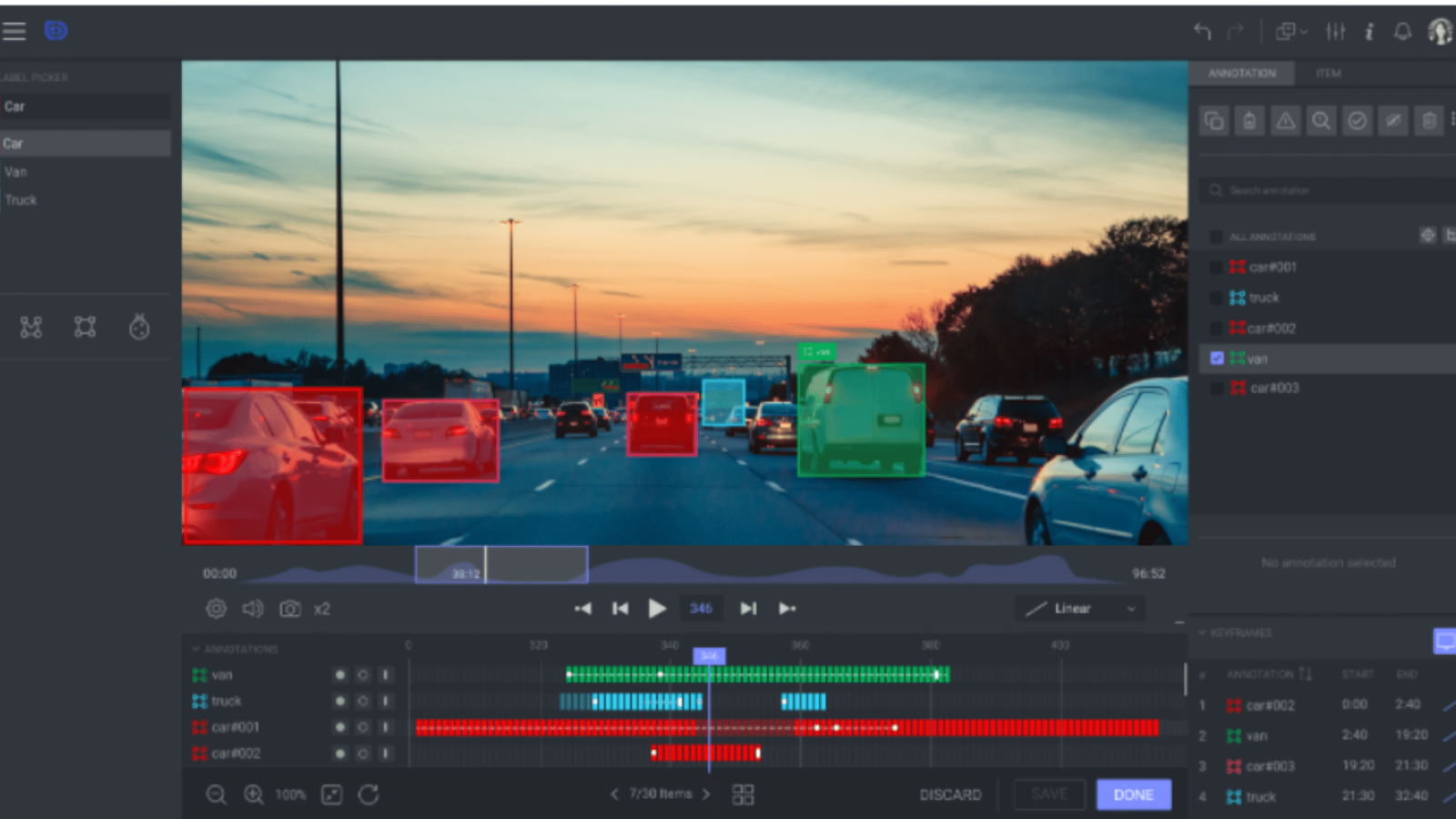
Anotação quadro a quadro. SouFonte: dataloop
Quando cada quadro de um vídeo é rotulado para capturar detalhes minuciosos, isso é chamado de detecção quadro a quadro. Isso é muito usado pra tarefas que precisam de muita precisão, tipo analisar os movimentos do corpo na fisioterapia.
O jeito de anotar os dados pode mudar dependendo de várias coisas, tipo:
Em outras palavras, algumas tarefas precisam da precisão de anotadores humanos, enquanto outras podem aproveitar a automação pra economizar tempo e ampliar o processo. A seguir, vamos ver as várias abordagens pra você entender melhor em que situação cada uma deve ser usada.
A anotação manual é quando anotadores humanos rotulam os dados manualmente. Nessa abordagem, anotadores treinados analisam cada dado com cuidado e colocam os rótulos ou tags necessários.
A maior vantagem da anotação manual é a precisão. Como a gente consegue entender melhor o contexto, as nuances e os padrões complexos do que as máquinas, dá pra garantir que os dados sejam rotulados com precisão. Esse nível de precisão é super importante pra projetos que precisam de anotações detalhadas e de alta qualidade, tipo rotular imagens médicas ou tarefas complexas de linguagem natural.
Mas, a anotação manual também tem uns desafios bem grandes:
Mesmo com esses desafios, a anotação manual continua sendo essencial para projetos em que a precisão é fundamental, mesmo que as empresas muitas vezes procurem maneiras de equilibrar qualidade com tempo e eficiência de custos.
A anotação semi-automatizada junta a experiência humana com a ajuda do machine learning. Nessa abordagem, um modelo de machine learning ajuda os anotadores humanos pré-rotulando os dados ou oferecendo sugestões. Depois, os anotadores humanos revisam e ajustam os rótulos pra garantir que tudo esteja certo.
A vantagem da anotação semi-automatizada é que ela agiliza o processo, mantendo um alto nível de precisão. A máquina consegue lidar com tarefas repetitivas ou simples, o que deixa os anotadores humanos mais livres pra se concentrar em pontos de dados mais complexos ou confusos. Essa abordagem é ideal para projetos grandes, onde a anotação manual completa seria muito lenta ou cara, porque ela consegue um equilíbrio entre eficiência de tempo e controle de qualidade.
Mas tem alguns desafios:
A anotação semi-automatizada funciona melhor para projetos que precisam equilibrar qualidade e velocidade, onde os dados são complexos o suficiente para se beneficiar da revisão humana, mas grandes o suficiente para precisar de ajuda de uma máquina.
A anotação automatizada usa algoritmos de machine learning para rotular dados sem a intervenção humana. Nessa abordagem, modelos pré-treinados ou ferramentas baseadas em IA anotam automaticamente grandes conjuntos de dados. Isso torna o processo mais rápido e escalável do que os métodos manuais ou semi-automatizados.
A principal vantagem da anotação automática é a eficiência. Ele consegue processar um monte de dados em uma fração do tempo que um anotador humano levaria. Por isso, a anotação automática é uma solução ideal pra projetos com muitos dados, tipo marcar milhões de imagens pra um modelo de visão computacional ou transcrever um monte de áudio pra reconhecimento de voz.
Mas as desvantagens de depender de máquinas são as seguintes:
A anotação automática é mais indicada para projetos que precisam de rapidez e escalabilidade, mas onde uma certa margem de erro é aceitável ou quando a revisão humana pode ser usada depois para refinar os resultados.
O crowdsourcing é quando a gente distribui tarefas de rotulagem de dados pra um monte de gente usando plataformascomo Amazon Mechanical Turk ou Appen. Esse método permite que as empresas anotem grandes conjuntos de dados de forma rápida e econômica, usando um grupo global de trabalhadores.
Uma das principais vantagens do crowdsourcing é a escalabilidade. Distribuir tarefas para várias pessoas ajuda as empresas a lidar com grandes quantidades de dados de um jeito eficiente. Por exemplo, um projeto que precisa de milhares de imagens ou transcrições pode ser feito em dias, em vez de semanas ou meses.
As desvantagens dessa abordagem são as seguintes:
O crowdsourcing é perfeito pra projetos grandes que precisam de anotações rápidas e baratas. Mas, pra manter resultados de alta qualidade, é preciso ter um bom controle e gerenciamento das tarefas.
Tem várias ferramentas disponíveis pra anotação de dados. Essas ferramentas vão desde plataformas de código aberto até soluções comerciais completas, cada uma feita para atender às necessidades de diferentes projetos.
Por exemplo, as ferramentas de código aberto geralmente são personalizáveis e de uso gratuito. Isso faz com que sejam ideais para projetos menores ou equipes com experiência técnica. Por outro lado, as opções comerciais oferecem recursos mais avançados, como automação, ferramentas de colaboração e controle de qualidade, o que as torna mais adequadas para projetos de grande escala ou empresas que querem um fluxo de trabalho mais eficiente.
Nesta seção, vamos ver algumas das ferramentas mais populares disponíveis para anotação de dados e como elas podem ajudar com diferentes tipos de dados:
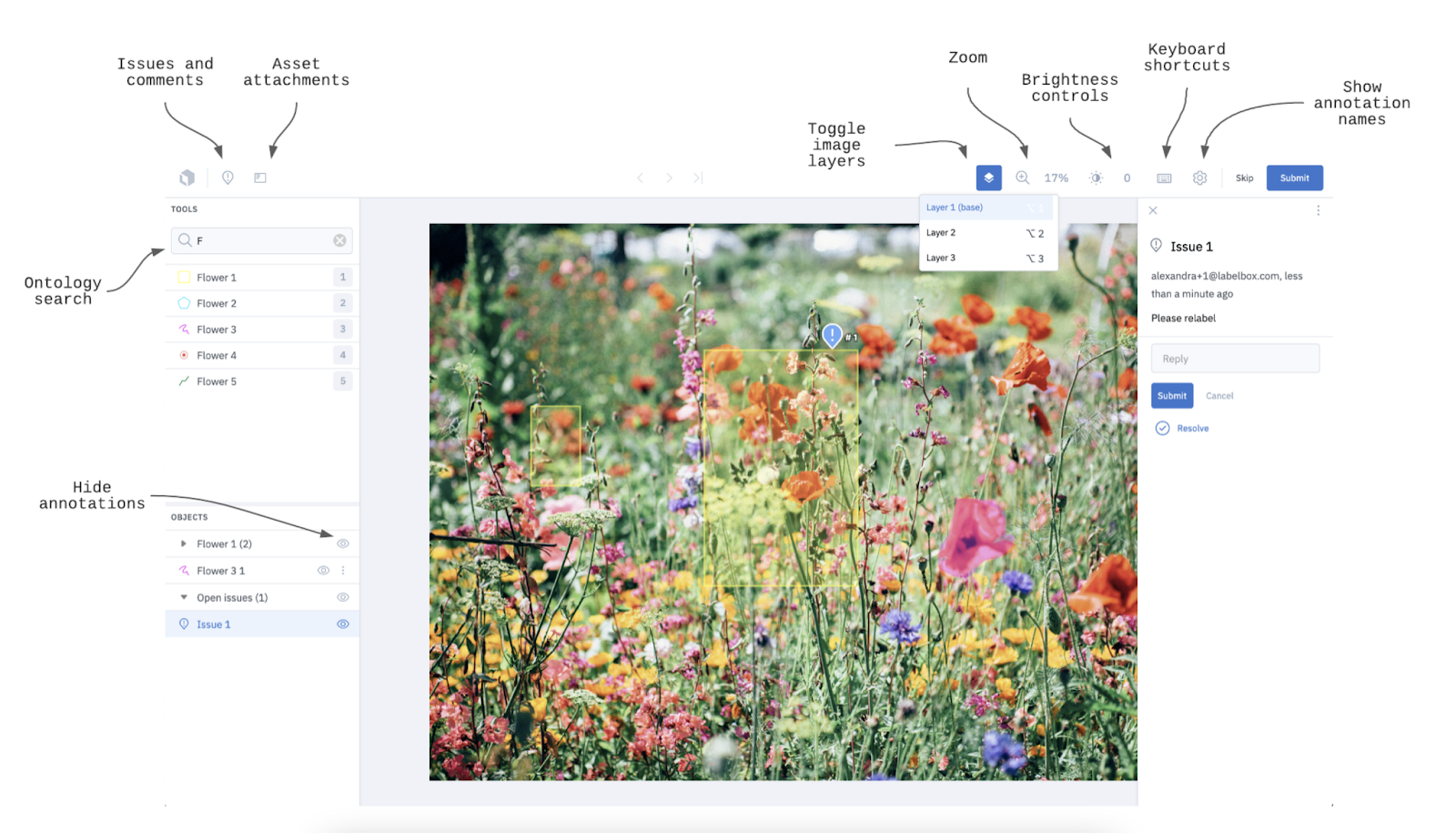
Fonte: Documentos do Labelbox
Labelbox é uma plataforma comercial super usada ( ) que foi criada pra simplificar o processo de anotação de dados, com foco na colaboração e no controle de qualidade. Foi criada em 2018 por Manu Sharma, Brian Rieger e Peter Welinder, cuja missão é“, criar os melhores produtos para se alinhar com a inteligência artificial”.
A plataforma Labelbox tem uma interface super intuitiva onde as equipes podem trabalhar juntas para anotar dados, acompanhar o progresso e manter altos padrões de anotação. Ele também suporta vários tipos de dados (por exemplo, imagens, vídeo e texto), o que torna a plataforma super versátil para diferentes projetos de machine learning.
Uma das principais coisas legais é que ele já vem com mecanismos de controle de qualidade, que permitem que as equipes revisem e aprovem as anotações — isso garante resultados consistentes e precisos.
O Labelbox é perfeito pra quem quer dar um upgrade nas suas anotações com gerenciamento de projetos e automação integrados.
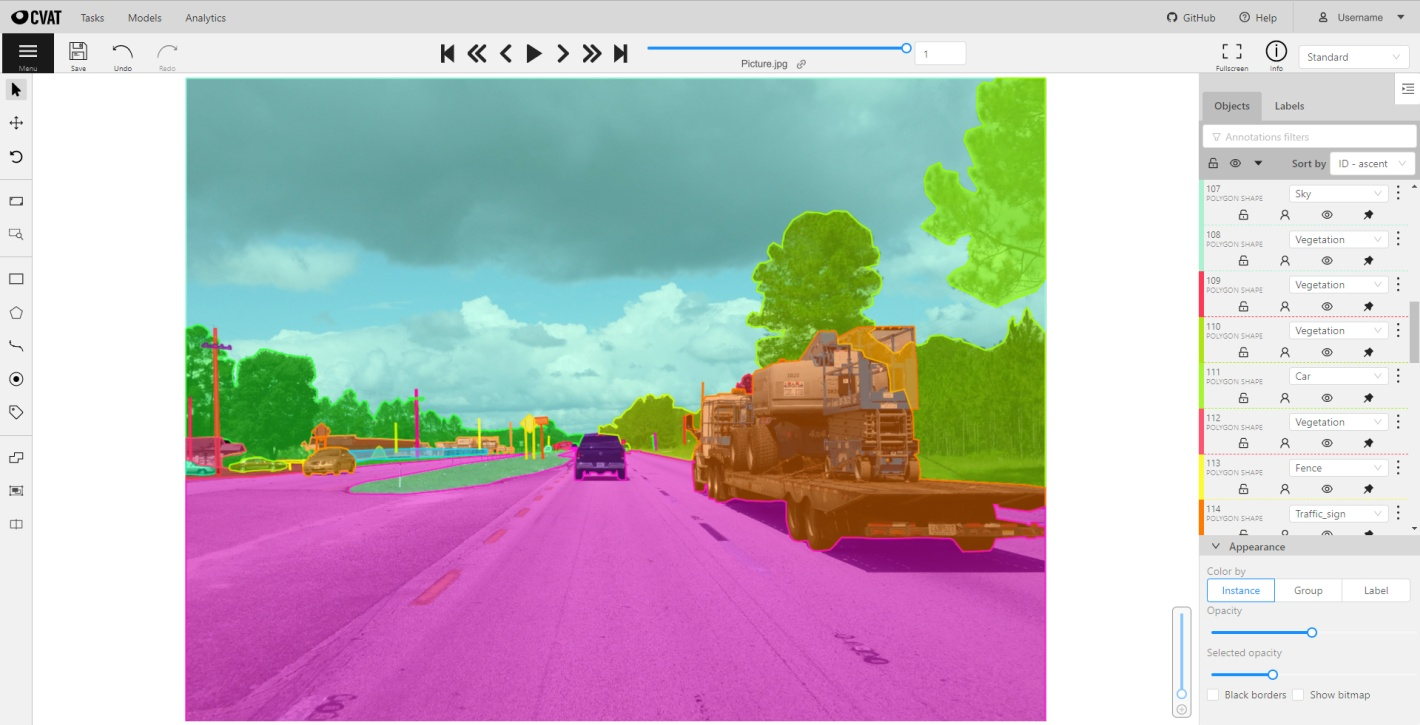
SouFonte: Página da CVAT na Wikipedia
CVAT é uma ferramenta de código aberto ( ) feita especialmente para anotar conjuntos de dados de imagens e vídeos. Desenvolvido pela Intel, o CVAT é super personalizável e tem várias técnicas de anotação (por exemplo, caixas delimitadoras, polígonos e anotações de pontos-chave). A flexibilidade dele faz com que seja ideal para projetos que vão desde a detecção de objetos até o reconhecimento facial.
Por ser de código aberto, o CVAT é grátis e pode ser personalizado para atender às necessidades específicas do seu projeto. Isso faz dele uma escolha popular entre pesquisadores e equipes menores que precisam de ferramentas de anotação poderosas sem o custo de um software comercial.
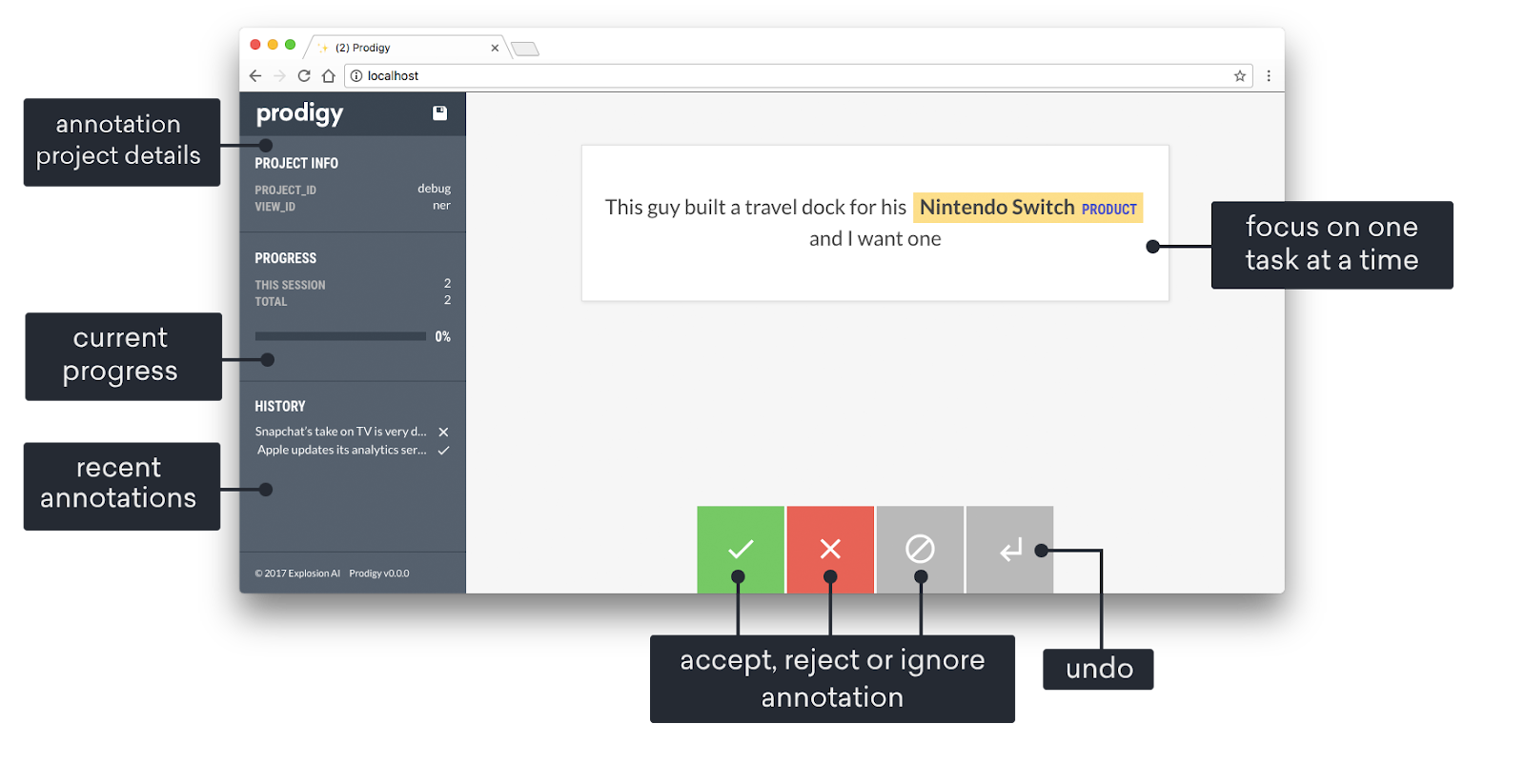
SouFonte: Documentos Prodigy
Prodigy é uma ferramenta de anotação avançada eida, desenvolvida pela Explosion AI, que usa aprendizado ativo para melhorar a eficiência, principalmente em tarefas de processamento de linguagem natural (NLP). Com o Prodigy, um modelo de machine learning ajuda os anotadores sugerindo rótulos com base nas suas previsões, que depois são confirmados ou corrigidos por revisores humanos.
Essa abordagem interativa agiliza o processo de anotação e, ao mesmo tempo, garante que os dados rotulados sejam de alta qualidade. Mesmo sendo uma ferramenta comercial, o Prodigy é super personalizável; por exemplo, dá para criar seus próprios fluxos de trabalho de anotação. Esses fatores fazem do Prodigy uma ótima escolha para equipes que trabalham em projetos de PNL especializados, como análise de sentimentos, reconhecimento de entidades ou classificação de textos.
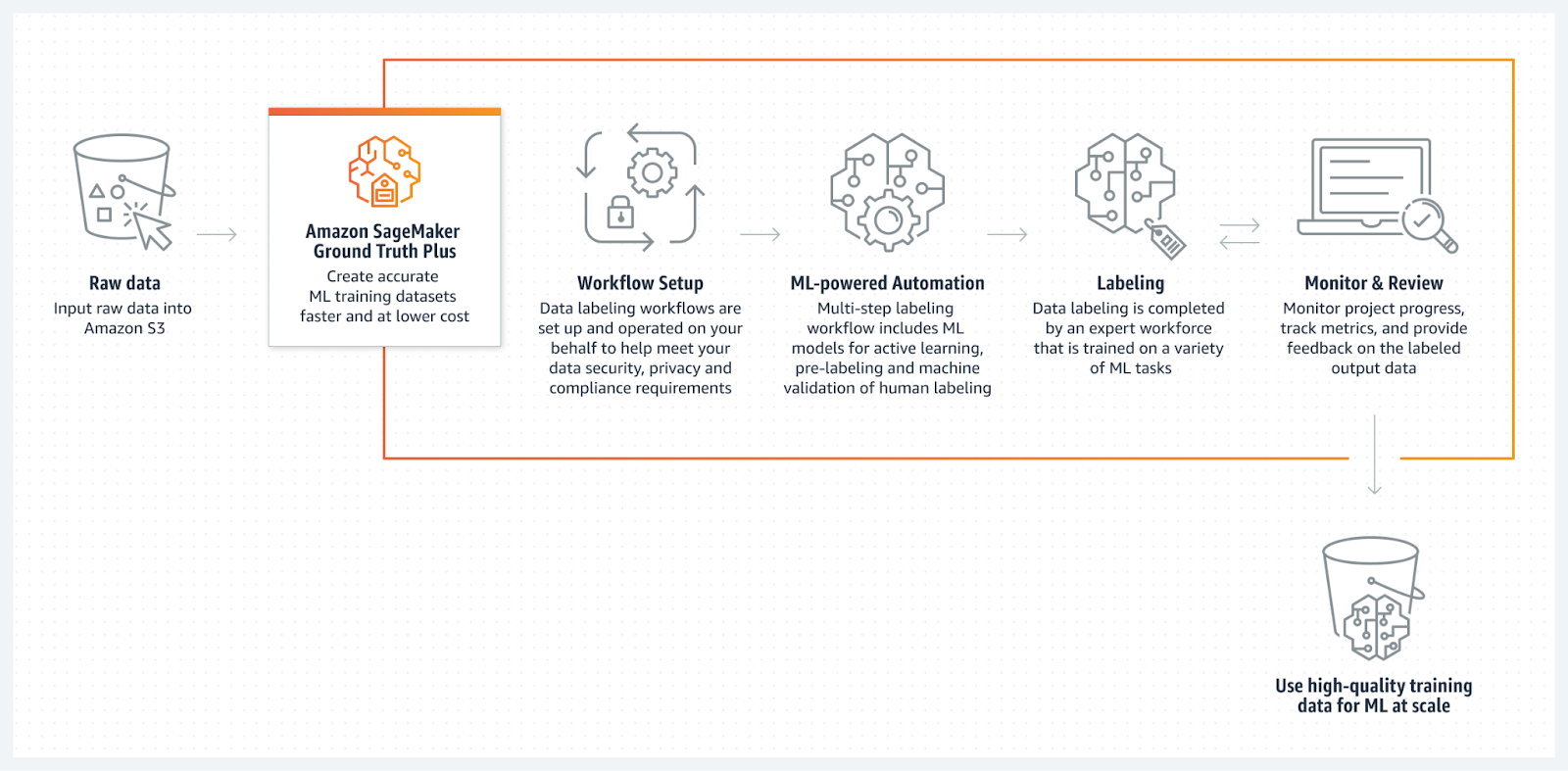
Fonte: Amazon SageMaker Ground Truth
O Amazon SageMaker Ground Truth é um serviço completo de rotulagem de dados ( ) totalmente gerenciado que se integra perfeitamente à AWS. Ele oferece ferramentas para anotação manual e automática de dados, que permitem aos usuários rotular dados de forma rápida e precisa.
O SageMaker Ground Truth usa machine learning para ajudar os anotadores humanos, pré-rotulando os dados, o que acelera o processo e reduz os custos. O serviço também é uma opção super versátil para diferentes tarefas de machine learning, já que dá suporte a vários tipos de dados, como imagens, texto e vídeos.
Além disso, ele foi feito pra ser escalável, o que significa que é uma ótima opção pra empresas que precisam de recursos de anotação em grande escala dentro do ecossistema da AWS.
A anotação eficaz dos dados é fundamental para o sucesso dos modelos de machine learning, já que a qualidade dos dados rotulados afeta diretamente a precisão das previsões e classificações. Seguir as melhores práticas pode ajudar a garantir que o processo de anotação seja eficiente e confiável.
Nesta seção, vamos ver práticas essenciais que podem melhorar a qualidade e a consistência da anotação de dados, além de resolver os desafios que podem aparecer no processo de rotulagem.
Uma das etapas mais importantes no processo de anotação de dados é criar diretrizes claras e bem definidas. Essas diretrizes devem dizer exatamente como os dados devem ser rotulados e quais critérios os anotadores devem seguir para garantir a consistência.
Ter diretrizes claras ajuda a:
Ter regras padronizadas é super importante pra dados complexos ou subjetivos, tipo imagens ou textos que podem ser interpretados de várias maneiras.
A qualidade é essencial pra manter a precisão e a confiabilidade dos dados anotados. Então, os dados anotados precisam ser revisados de vez em quando pra garantir que estão dentro dos padrões exigidos. Esse processo pode ser feito com auditorias aleatórias, usando vários anotadores para as mesmas tarefas (para comparar resultados) ou verificando as anotações entre si, dependendo do projeto.
O ponto principal é que é super importante implementarum processo robusto de garantia de qualidade para ajudar a detectar erros logo no início, reduzir o viés nos dados e garantir que os dados rotulados sejam adequados para treinar modelos de machine learning de alto desempenho.
A aprendizagem ativa é uma técnica de machine learning que permite que um algoritmo escolha as amostras de dados mais informativas para rotular, o que melhora o desempenho do modelo. Essa técnica pode melhorar bastante a eficiência do processo de anotação. Isso permite que os anotadores concentrem seu tempo e energia nos pontos de dados mais desafiadores e valiosos, enquanto o algoritmo de machine learning sugere o resto.
Essa abordagem reduz o tempo gasto na rotulagem de amostras fáceis ou repetitivas e acelera o processo geral de anotação. Assim, aumenta a chance de o modelo de machine learning usado para fazer previsões ser treinado com os exemplos mais críticos.
Para garantir que o processo de anotação seja feito direitinho, os anotadores devem receber um treinamento legal. O treinamento ajuda os anotadores a entender os requisitos específicos da tarefa e como aplicar as diretrizes de anotação da maneira certa.
Anotadores bem treinados têm mais chances de produzir dados rotulados de alta qualidade, o que acaba melhorando o desempenho dos modelos de machine learning que eles estão apoiando. Sessões de treinamento regulares e ciclos de feedback também podem ajudar a refinar as habilidades dos anotadores ao longo do tempo, aprimorando ainda mais o processo de anotação de dados.
Embora a anotação de dados seja essencial para treinar modelos precisos de machine learning, o processo tem seus próprios desafios. Nesta seção, vamos falar sobre alguns dos desafios mais comuns na anotação de dados.
A anotação manual de dados costuma ser bem trabalhosa. É preciso bastante tempo e dinheiro pra anotar todas as instâncias, principalmente quando o conjunto de dados é grande. Quanto mais complexos os dados (como vídeos ou imagens complicadas), mais demorado fica o processo de anotação. É preciso contratar anotadores qualificados, o que aumenta os custos.
Para superar esse desafio, as organizações podem usar ferramentas de anotação semi-automatizadas, nas quais modelos de machine learning sugerem rótulos e os humanos os verificam. Isso agiliza o processo sem perder a precisão.
A aprendizagem ativa também pode ajudar, concentrando o esforço humano nos dados mais informativos, o que reduz a quantidade total de dados a serem rotulados manualmente. Além disso, usar plataformas de crowdsourcing como o Amazon Mechanical Turk permite que várias pessoas trabalhem ao mesmo tempo, o que significa que anotações em grande escala podem ser mais baratas e eficientes.
Outro desafio importante é lidar com a subjetividade e o viés no processo de anotação. Diferentes anotadores podem interpretar os mesmos dados de maneiras diferentes. Isso é super comum em tarefas como rotular emoções em textos ou identificar objetos em imagens complexas. O problema é que a subjetividade pode trazer um viés pros dados rotulados, o que pode acabar levando a previsões erradas do modelo.
Para reduzir a subjetividade e o viés, as organizações devem criar diretrizes de anotação claras e detalhadas que garantam que todos os anotadores sigam os mesmos critérios. Outra solução é usar vários anotadores para os mesmos dados, o que permite a verificação cruzada e ajuda a identificar e corrigir anotações tendenciosas ou inconsistentes.
Anotações que mostram informações que podem identificar alguém podem violar as regras de privacidade que protegem os dados pessoais. Esse desafio é ainda mais importante quando a gente terceiriza tarefas de anotação ou usa plataformas de crowdsourcing, onde várias pessoas têm acesso aos dados.
Soluções como a anonimização (tirar informações pessoais) e usar plataformas seguras e criptografadas para anotações podem ajudar a diminuir esses riscos.
Nesta seção, vamos ver como a anotação de dados funciona na vida real. Vamos lá!
Nos veículos autônomos, a anotação de dados é a base para ensinar a IA a navegar com segurança no mundo real. Os carros autônomos dependem de dados anotados para identificar objetos.
Por exemplo, os anotadores rotulam imagens ou quadros de vídeo desenhando caixas delimitadoras em torno dos carros ou marcando os limites da estrada para detectar as faixas. Essas anotações ajudam a IA a aprender como reconhecer e reagir a várias situações na estrada, como parar para pedestres ou ficar na faixa certa.
Os modelos de IA precisam de imagens médicas rotuladas para aprender a detectar anormalidades. Por exemplo, anotadores experientes podem marcar áreas específicas nas imagens pra indicar regiões que mostram sinais precoces de câncer. Isso permite que a IA detecte o câncer de forma rápida e precisa, mais cedo do que os métodos tradicionais, o que melhora os resultados dos pacientes e reduz a carga de trabalho dos profissionais da área médica.
Para chatbots de atendimento ao cliente, a anotação de texto é essencial para ensinar a IA a entender a linguagem humana.
Por exemplo, os anotadores podem rotular o texto para ajudar os chatbots a entender o que o usuário quer. Os chatbots analisariam as interações rotuladas para aprender como dar as respostas certas. Isso permite que as empresas ofereçam uma ajuda mais rápida e precisa e melhorem a experiência do cliente.
Na análise de sentimentos, usa-se uma notação de texto e eo para avaliar como os clientes se sentem em relação a certas coisas (por exemplo, a marca, os produtos ou eventos). Funciona assim: os anotadores marcam frases ou expressões como positivas, negativas ou neutras, e depois esses dados são passados para a IA para aprender o sentimento por trás disso. Uma empresa pode usar isso pra acompanhar como os clientes estão recebendo o lançamento de um novo produto.
A anotação de dados é o processo de rotular dados para torná-los reconhecíveis e utilizáveis para modelos de machine learning. É um passo super importante no desenvolvimento de sistemas de IA que conseguem entender e responder com precisão aos dados do mundo real. Por quê? Porque a qualidade e a precisão dos dados anotados têm um impacto direto no desempenho e na eficácia dos modelos de IA.
No fim das contas, a anotação de dados é a base pra construir sistemas de IA inteligentes e confiáveis que podem impulsionar a inovação em vários setores. Isso faz dele uma parte essencial do desenvolvimento do machine learning.
Para continuar aprendendo, dá uma olhada nesses recursos:
Aprenda mais sobre machine learning e IA com esses cursos!
Curso
Curso
Curso
blog
Austin Chia
blog
Abid Ali Awan
5 min
blog
Matt Crabtree
15 min
Tutorial
Zoumana Keita

