
Cours
Comprendre le Machine Learning
2 h
293.2K
Imaginez que vous développiez une voiture autonome. Pour que la voiture puisse « voir » et comprendre la route, elle doit apprendre à reconnaître des objets tels que les piétons, les panneaux de signalisation et les autres véhicules. Pour ce faire, lesystème d'apprentissage automatique de l'eurnécessite des milliers, voire des millions, d'images issues de situations de conduite réelles.
Cependant, la voiture ne peut pas comprendre intrinsèquement ce qui se trouve dans les images. Il ne sait pas qu'un octogone rouge est un panneau « Stop » ou qu'une personne marche sur le trottoir. C'est là que l'annotation de données entre en jeu.
L'annotation de données est le processus qui consiste à étiqueter des données brutes afin de les rendre compréhensibles et utilisables par les modèles d'apprentissage automatique. Nous vous fournirons plus de détails ultérieurement, mais veuillez garder cela à l'esprit.
Voici ce que nous allons examiner dans cet article :
Commençons sans plus attendre !
La meilleure façon d'appréhender l'annotation de données est de se représenter comment on enseigne aux enfants les différents animaux. Au début de l', vous leur montrez une image d'un chien et vous dites : « Ceci est un chien. » Ensuite, vous leur montrez un chat et vous dites : « Ceci est un chat. » Au fil du temps, en lui montrant des exemples étiquetés, l'enfant apprend à identifier les animaux de manière autonome. L'annotation des données fonctionne de manière similaire pour les machines.
Tout comme un enfant a besoin d'exemples étiquetés (remarque : dire « Ceci est un chien » correspond à l'étiquetage), les modèles d'apprentissage automatique ont besoin que les données soient annotées pour pouvoir en tirer des enseignements. Ainsi, l'annotation de données est le processus qui consiste à étiqueter ou à baliser des données, telles que des images, du texte ou des fichiers audio, afin que les algorithmes d'apprentissage automatique puissent les reconnaître et les comprendre.
Les étiquettes servent d'exemples qui enseignent au système les modèles à rechercher. Par exemple, si vous annotez des milliers d'images avec les étiquettes « chien » ou « chat », le modèle commencera à reconnaître les différences entre les deux.
Une fois qu'il a appris de ces exemples, le modèle peut alors faire des prédictions ou classer denouvelles données non étiquetées, tout comme l'enfant finit par reconnaître les animaux sans votre aide.
Différents types de données nécessitent des méthodes d'annotation spécifiques afin d'être préparées pour les tâches d'apprentissage automatique. En fonction de la nature des données, il existe des approches uniques pour l'étiquetage et le balisage. La compréhension de ces types permet de déterminer la méthode la plus efficace pour former des modèles destinés à diverses applications.
Explorons les types d'annotation de données les plus courants :
L'annotation d'images consiste à étiqueter des images afin que les modèles d'apprentissage automatique puissent identifier et interpréter les objets qu'elles contiennent. Différentes techniques sont utilisées pour l'annotation d'images, en fonction du niveau de détail requis :

Boîtes englobantes. s acides : Analytics
Cette méthode consiste à dessiner des rectangles autour des objets d'une image afin d'aider le modèle à reconnaître leur présence et leur emplacement. Les boîtes englobantes sont couramment utilisées pour détecter les véhicules, les piétons ou les panneaux dans le domaine de la technologie de conduite autonome.

Segmentation sémantique. Source : Introduction à la segmentation sémantique d'images
Ici, chaque pixel d'une image est étiqueté afin d'attribuer des zones spécifiques à des objets ou des catégories particuliers, comme l'identification des routes, des bâtiments ou des arbres. Cette technique permet au modèle d'avoir une compréhension plus fine de la scène.

Annotation de repère. s acides : Analytics
Cette technique consiste à marquer des points spécifiques dans une image, tels que les traits du visage ou les points clés de la posture corporelle. Il est utilisé dans des applications telles que la reconnaissance faciale et l'estimation de la posture humaine.
L'annotation de texte est le processus qui consiste à étiqueter et à baliser des données textuelles afin de les rendre compréhensibles pour les modèles de traitement du langage naturel (NLP). Il permet aux machines de comprendre, traiter et analyser le langage humain.
Il existe plusieurs techniques couramment utilisées pour l'annotation de texte :

Reconnaissance d'entités. Source :e : Reconnaissance et classification d'entités nommées avec Scikit-Learn
Il s'agit d'identifier des entités spécifiques dans un texte, telles que des noms de personnes, de lieux ou d'organisations. Par exemple, dans la phrase « Apple a ouvert un nouveau magasin à New York », le modèle reconnaîtrait « Apple » comme une entreprise et « New York » comme un lieu.

Étiquetage des sentiments. Source de l': Comprendre le processus d'annotation de texte pour l'analyse des sentiments des clients
Cette technique consiste à attribuer des émotions ou des opinions à des fragments de texte, en les qualifiant de positifs, négatifs ou neutres. Il est fréquemment utilisé dans les avis clients ou la surveillance des réseaux sociaux afin de comprendre l'opinion des utilisateurs sur un produit ou un service.
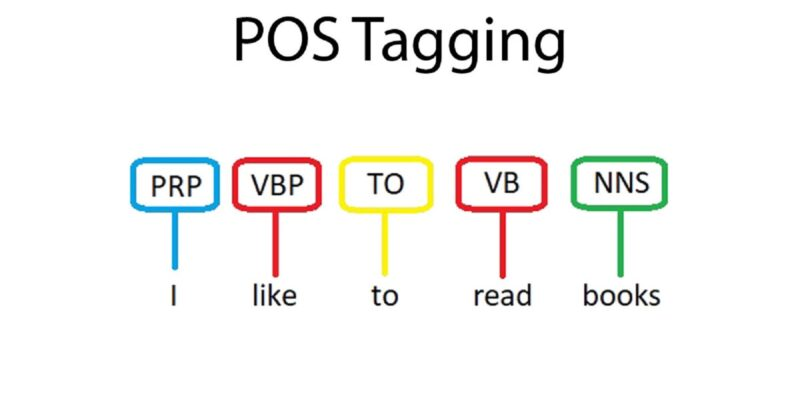
Étiquetage POS. Source :e : Étiquetage POS en TALN
Cette méthode attribue à chaque mot d'une phrase son rôle grammatical (par exemple, nom, verbe, adjectif), ce qui aide les modèles à comprendre la structure du langage pour des tâches telles que la traduction ou la reconnaissance vocale.
L'annotation audio consiste à étiqueter des fichiers audio afin de former des modèles à la reconnaissance vocale, à la détection musicale ou à la classification sonore.
Voici quelques techniques courantes d'annotation audio :
La conversion des mots prononcés dans un fichier audio en texte écrit est souvent utiliséedans les applications de reconnaissance vocale.
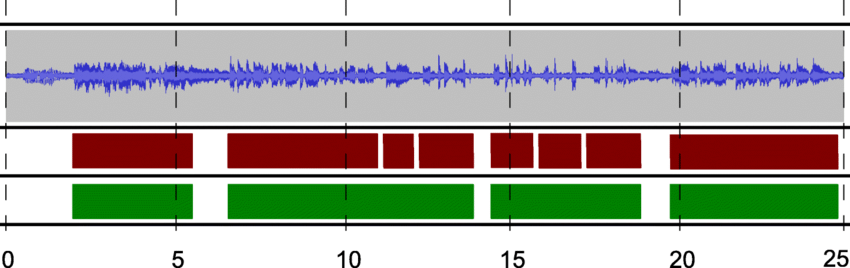
Segmentation de la parole. s acides : Recherche sur ResearchGate
Cela consiste à diviser un fichier audio en différentes sections. Par exemple, vous pouvez souhaiter séparer les dialogues du bruit de fond ou identifier chaque interlocuteur dans une conversation.
Étiquetage sonore. Ainsi,source : Étiquetage Freesound par VGGish avec KNN
Le marquage sonore consiste à étiqueter des sons spécifiques (par exemple, le bruit de la circulation, les cris d'animaux, etc.) dans un fichier audio.
L'annotation vidéo consiste à étiqueter et à baliser des objets ou des actions dans des images vidéo afin d'aider les modèles d'apprentissage automatique à interpréter les mouvements et les activités.
Les principales techniques d'annotation vidéo comprennent :
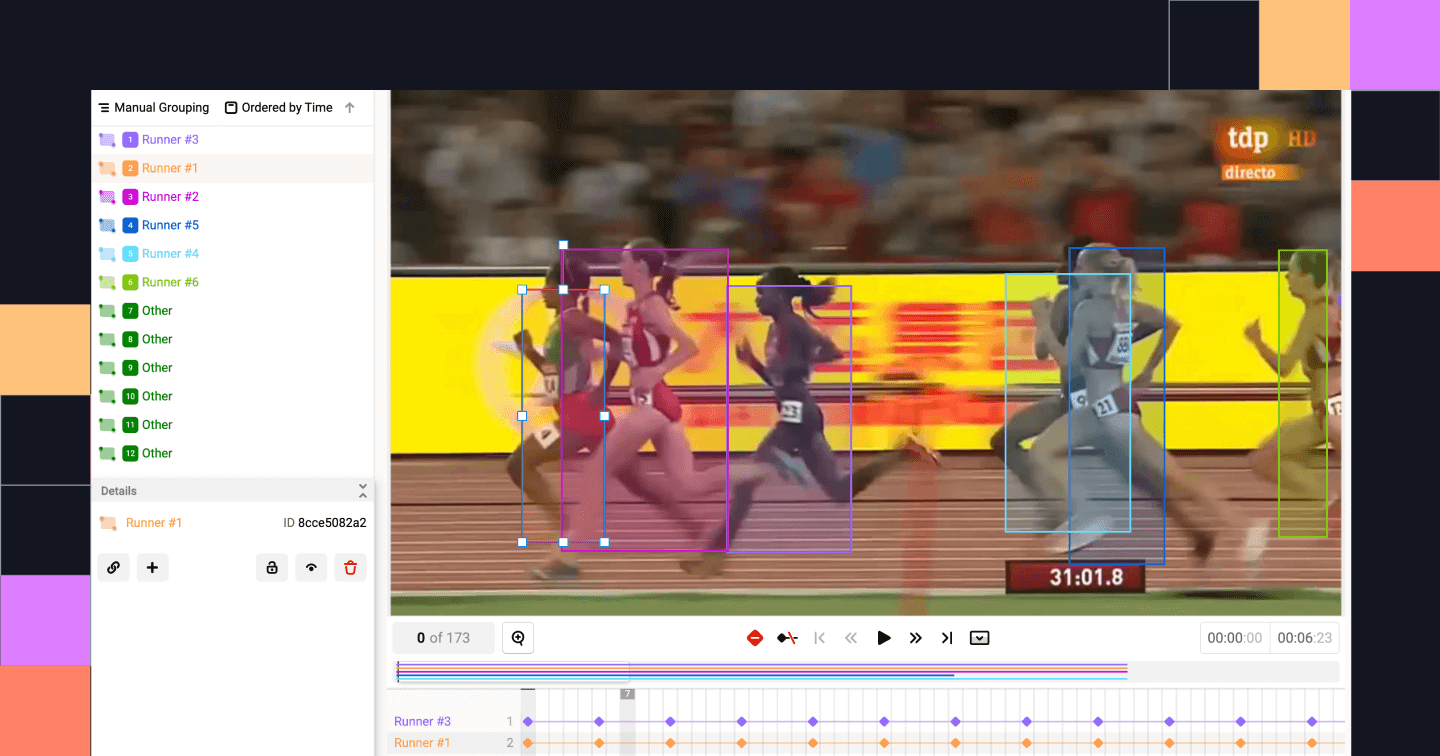
Suivi d'objets. Source: Studio d'étiquettes
Le suivi d'objets consiste à étiqueter en continu des objets sur plusieurs images afin de suivre leurs mouvements. Dans les scénarios de conduite autonome, par exemple, le suivi d'objets peut être utilisé pour suivre un véhicule dans un carrefour très fréquenté.
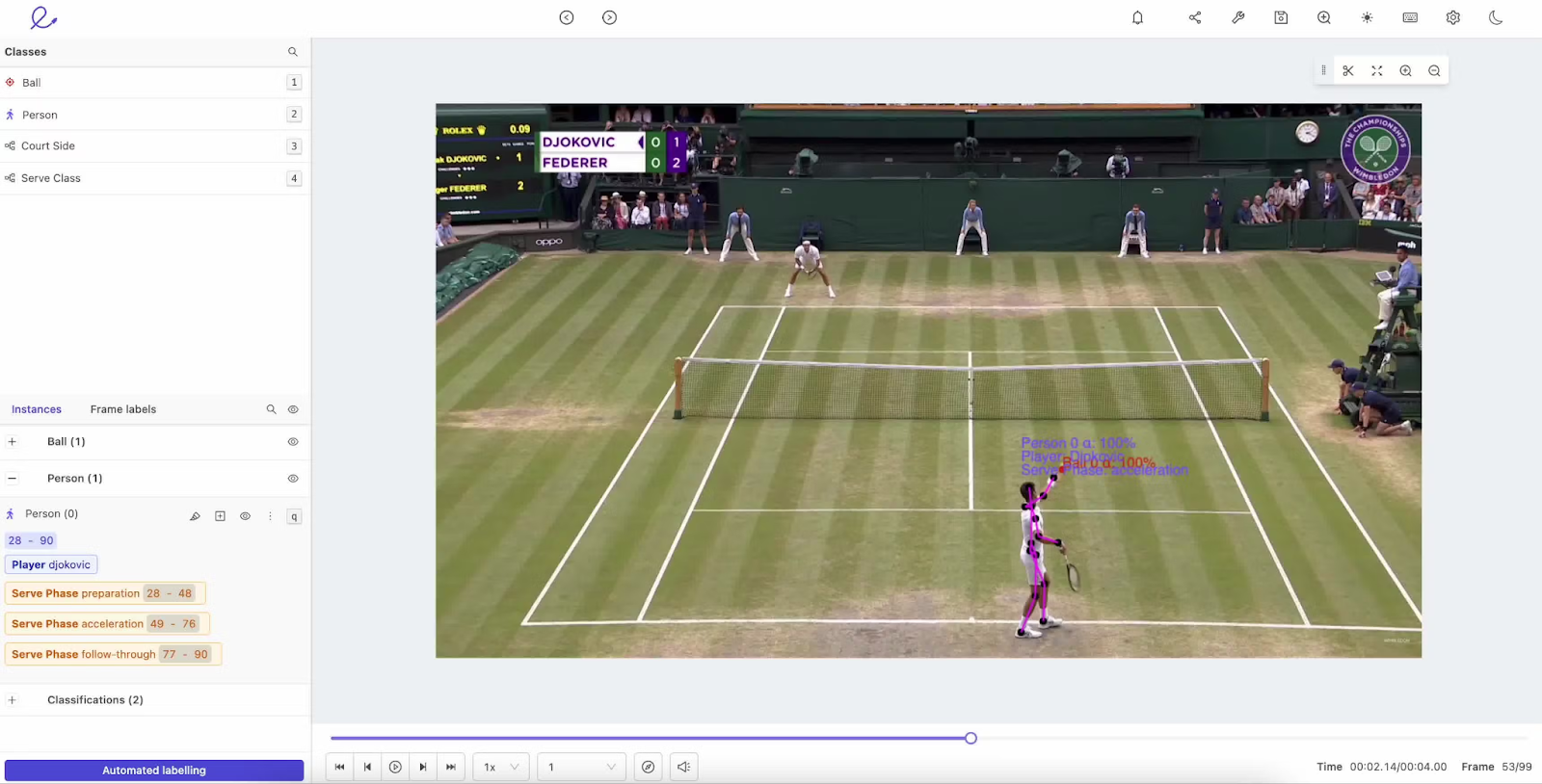
Étiquetage des activités. Source de l': Encord
Il s'agit de l'attribution d'étiquettes à des actions spécifiques, telles que marcher, courir ou s'asseoir dans une vidéo. Cela aide les modèles à comprendre le comportement humain dans des applications telles que la surveillance de la sécurité ou l'analyse sportive.
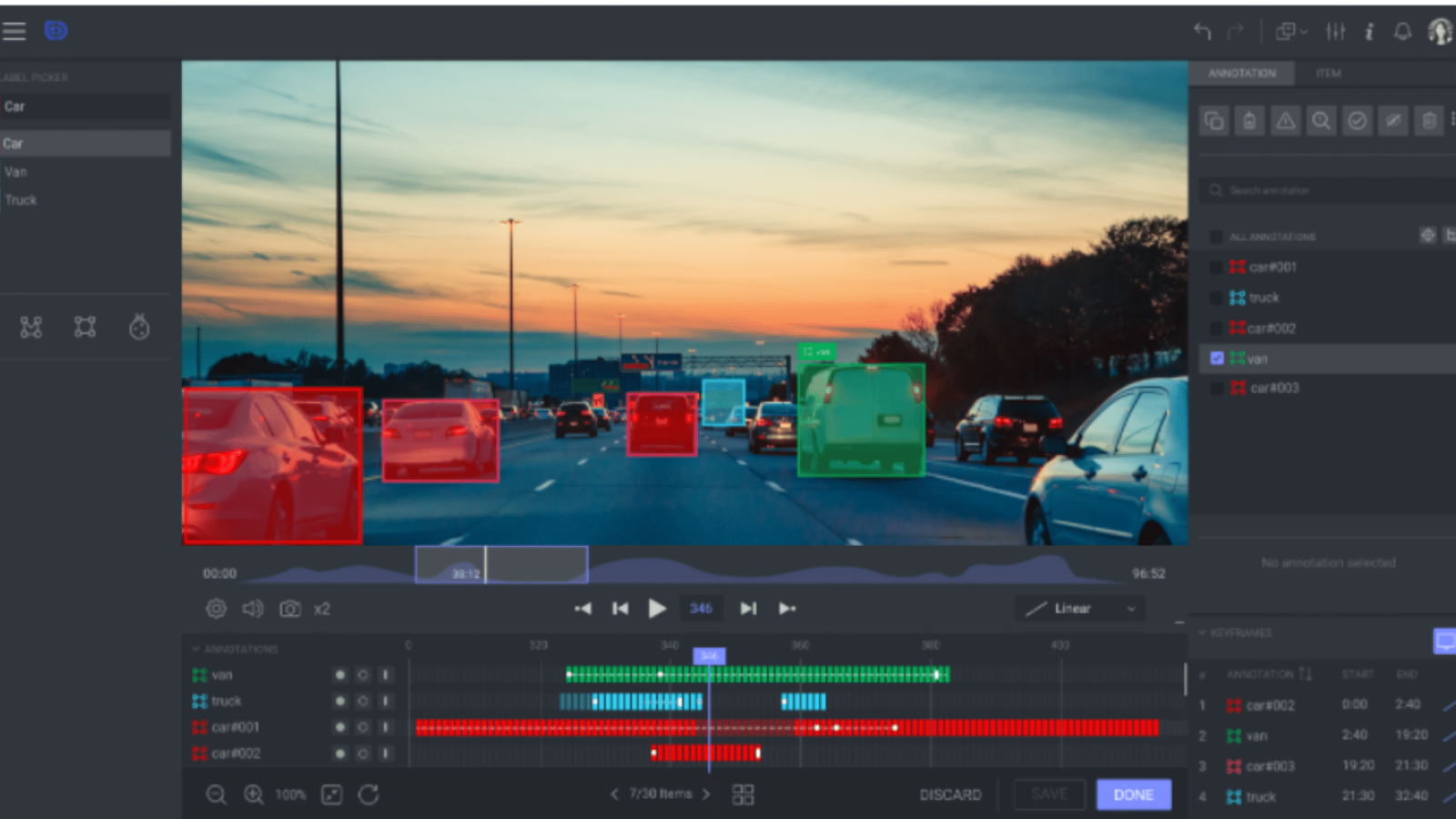
Annotation image par image. Source de l': dataloop
Lorsque chaque image d'une vidéo est étiquetée afin de capturer les moindres détails, on parle de détection image par image. Ceci est souvent utilisé pour des tâches qui nécessitent une grande précision, telles que l'analyse des mouvements du corps en physiothérapie.
La méthode utilisée pour annoter les données peut varier en fonction de plusieurs facteurs, tels que :
En d'autres termes, certaines tâches nécessitent la précision des annotateurs humains, tandis que d'autres peuvent bénéficier de l'automatisation pour gagner du temps et adapter le processus. Ci-dessous, nous examinerons les différentes approches afin de vous permettre de mieux comprendre dans quelles situations chacune d'entre elles doit être utilisée.
L'annotation manuelle consiste à faire appel à des annotateurs humains pour étiqueter les données à la main. Dans cette approche, des annotateurs qualifiés examinent attentivement chaque donnée et y appliquent les étiquettes ou balises nécessaires.
Le principal avantage de l'annotation manuelle réside dans sa précision. Étant donné que les êtres humains sont mieux à même que les machines de comprendre le contexte, les nuances et les schémas complexes, ils peuvent garantir que les données sont étiquetées avec précision. Ce niveau de précision est particulièrement important pour les projets qui nécessitent des annotations détaillées et de haute qualité, tels que l'étiquetage d'images médicales ou les tâches complexes en langage naturel.
Cependant, l'annotation manuelle présente également des défis importants :
Malgré ces défis, l'annotation manuelle reste essentielle pour les projets où la précision est cruciale, même si les entreprises recherchent souvent des moyens d'équilibrer la qualité, le temps et l'efficacité des coûts.
L'annotation semi-automatisée combine l'expertise humaine et l'assistance de l'apprentissage automatique. Dans cette approche, un modèle d'apprentissage automatique assiste les annotateurs humains en pré-étiquetant les données ou en proposant des suggestions. Les annotateurs humains examinent ensuite les étiquettes et les affinent afin d'en garantir l'exactitude.
L'avantage de l'annotation semi-automatisée réside dans le fait qu'elle accélère le processus tout en conservant un haut niveau de précision. La machine est capable d'effectuer des tâches répétitives ou simples, ce qui permet aux annotateurs humains de se concentrer sur des données plus complexes ou ambiguës. Cette approche est particulièrement adaptée aux projets de grande envergure pour lesquels une annotation manuelle complète serait trop lente ou trop coûteuse, car elle offre un équilibre entre efficacité et contrôle qualité.
Cependant, il est confronté à certains défis :
L'annotation semi-automatisée est particulièrement adaptée aux projets qui doivent trouver un équilibre entre qualité et rapidité, où les données sont suffisamment complexes pour bénéficier d'une révision humaine, mais suffisamment volumineuses pour nécessiter l'aide d'une machine.
L'annotation automatisée utilise des algorithmes d'apprentissage automatique pour étiqueter les données sans intervention humaine. Dans cette approche, des modèles pré-entraînés ou des outils basés sur l'IA annotent automatiquement de grands ensembles de données. Cela rend le processus plus rapide et plus évolutif que les méthodes manuelles ou semi-automatisées.
Le principal avantage de l'annotation automatisée réside dans son efficacité. Il est capable de traiter d'énormes quantités de données en une fraction du temps qu'il faudrait à un annotateur humain. Par conséquent, l'annotation automatisée est une solution idéale pour les projets impliquant d'énormes ensembles de données, comme le balisage de millions d'images pour un modèle de vision par ordinateur ou la transcription de grands volumes audio pour la reconnaissance vocale.
Cependant, le recours aux machines présente les inconvénients suivants :
L'annotation automatisée est particulièrement adaptée aux projets qui exigent rapidité et évolutivité, mais pour lesquels une certaine marge d'erreur est acceptable ou lorsque les résultats peuvent être affinés ultérieurement par une révision humaine.
Le crowdsourcing consiste à distribuer des tâches de libellé de données à un grand nombre de contributeurs à l'aide de plateformestelles qu'Amazon Mechanical Turk ou Appen. Cette méthode permet aux entreprises d'annoter rapidement et à moindre coût de grands ensembles de données en faisant appel à un vivier mondial de travailleurs.
L'un des principaux avantages du crowdsourcing réside dans son évolutivité. La répartition des tâches entre plusieurs contributeurs permet aux entreprises de traiter efficacement de grands volumes de données. Par exemple, un projet nécessitant des milliers d'images étiquetées ou de transcriptions peut être réalisé en quelques jours plutôt qu'en plusieurs semaines ou mois.
Les inconvénients de cette approche sont les suivants :
Le crowdsourcing est idéal pour les projets à grande échelle qui nécessitent une annotation rapide et rentable. Cependant, le maintien de résultats de haute qualité nécessite une surveillance et une gestion des tâches rigoureuses.
Il existe une large gamme d'outils disponibles pour l'annotation des données. Ces outils vont des plateformes open source aux solutions commerciales complètes, chacune étant conçue pour répondre aux besoins spécifiques de différents projets.
Par exemple, les outils open source sont souvent personnalisables et gratuits. Cela les rend particulièrement adaptés aux projets de petite envergure ou aux équipes disposant d'une expertise technique. D'autre part, les options commerciales offrent des fonctionnalités plus avancées, notamment l'automatisation, des outils de collaboration et le contrôle qualité, ce qui les rend plus adaptées aux projets à grande échelle ou aux entreprises à la recherche d'un flux de travail rationalisé.
Dans cette section, nous examinerons certains des outils les plus populaires disponibles pour l'annotation de données et la manière dont ils peuvent vous aider avec différents types de données :
Source:e : Documents Labelbox
Labelbox est une plateforme commerciale de grande envergure, conçue pour optimiser le processus d'annotation des données, en mettant l'accent sur la collaboration et le contrôle qualité. Elle a été fondée en 2018 par Manu Sharma, Brian Rieger et Peter Welinder, dont la mission est «d'r à créer les meilleurs produits adaptés à l'intelligence artificielle».
La plateforme Labelbox offre une interface intuitive où les équipes peuvent collaborer pour annoter des données, suivre les progrès et maintenir des normes d'annotation élevées. Elle prend également en charge divers types de données (images, vidéos, texte, etc.), ce qui rend la plateforme extrêmement polyvalente pour différents projets d'apprentissage automatique.
L'une de ses principales caractéristiques réside dans ses mécanismes de contrôle qualité intégrés, qui permettent aux équipes de vérifier et d'approuver les annotations, garantissant ainsi des résultats cohérents et précis.
Labelbox est idéal pour les organisations qui souhaitent intensifier leurs efforts d'annotation grâce à des fonctionnalités intégrées de gestion de projet et d'automatisation.
Source de l': Page Wikipédia consacrée au CVAT
CVAT est un outil open source de l' spécialement conçu pour annoter des ensembles de données d'images et de vidéos. Développé par Intel, CVAT est hautement personnalisable et offre une large gamme de techniques d'annotation (par exemple, des cadres, des polygones et des annotations de points clés). Sa flexibilité le rend adapté à des projets allant de la détection d'objets à la reconnaissance faciale.
Étant donné qu'il s'agit d'un logiciel libre, CVAT est gratuit et peut être adapté aux besoins spécifiques de chaque projet. Cela en fait un choix populaire auprès des chercheurs et des petites équipes qui ont besoin d'outils d'annotation puissants sans avoir à investir dans des logiciels commerciaux.
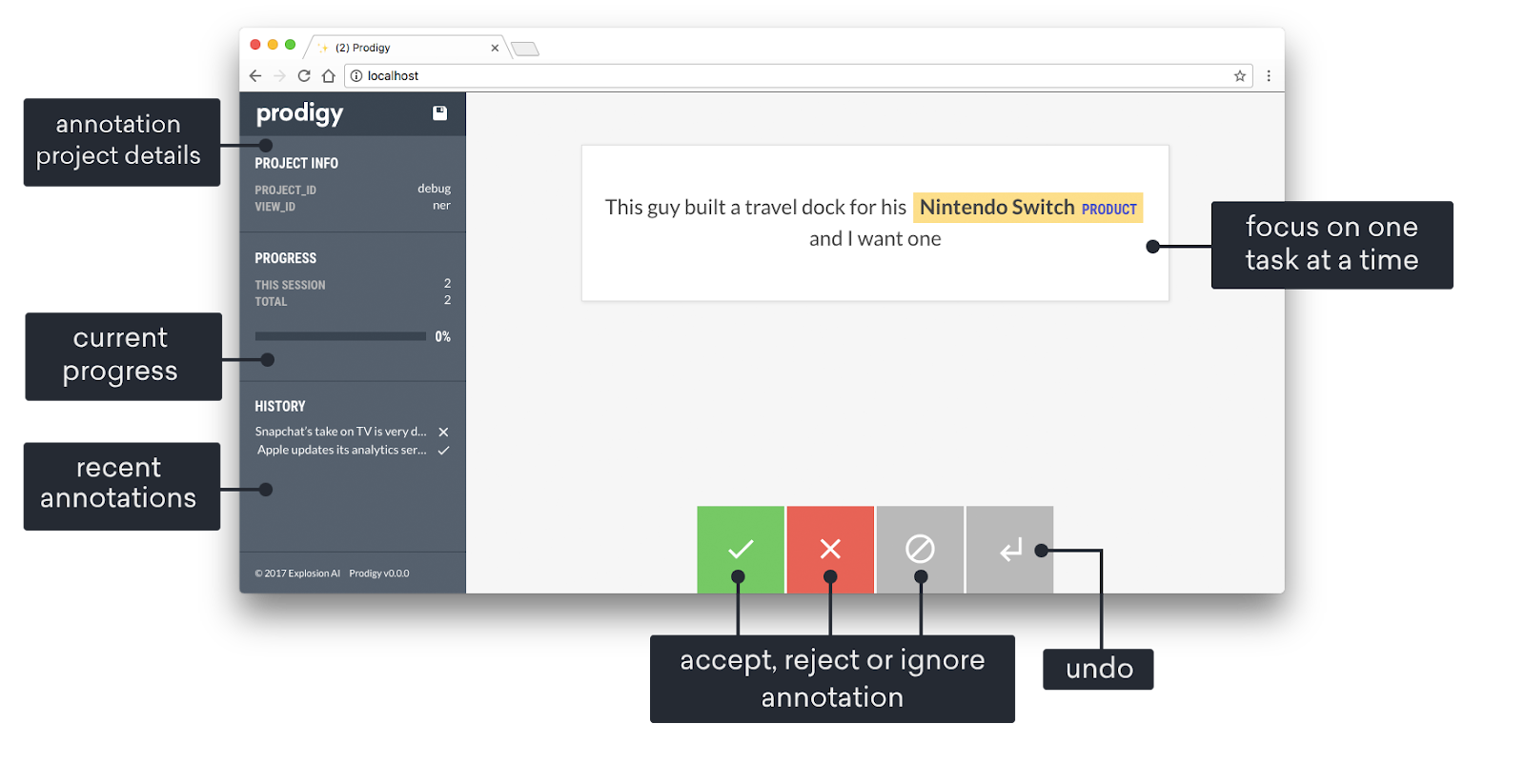
Source de l': Documents Prodigy
Prodigy est un outil d'annotation avancé et basé sur l', développé par Explosion AI, qui utilise l'apprentissage actif pour améliorer l'efficacité, en particulier dans les tâches de traitement du langage naturel (NLP). Avec Prodigy, un modèle d'apprentissage automatique assiste les annotateurs en suggérant des étiquettes basées sur leurs prédictions, qui sont ensuite confirmées ou corrigées par des réviseurs humains.
Cette approche interactive accélère le processus d'annotation tout en garantissant la qualité des données étiquetées. Bien qu'il s'agisse d'un outil commercial, Prodigy est hautement personnalisable ; par exemple, il permet aux utilisateurs de créer leurs propres flux de travail d'annotation. Ces facteurs rendent Prodigy particulièrement adapté aux équipes travaillant sur des projets de TALN spécialisés tels que l'analyse des sentiments, la reconnaissance d'entités ou la classification de textes.
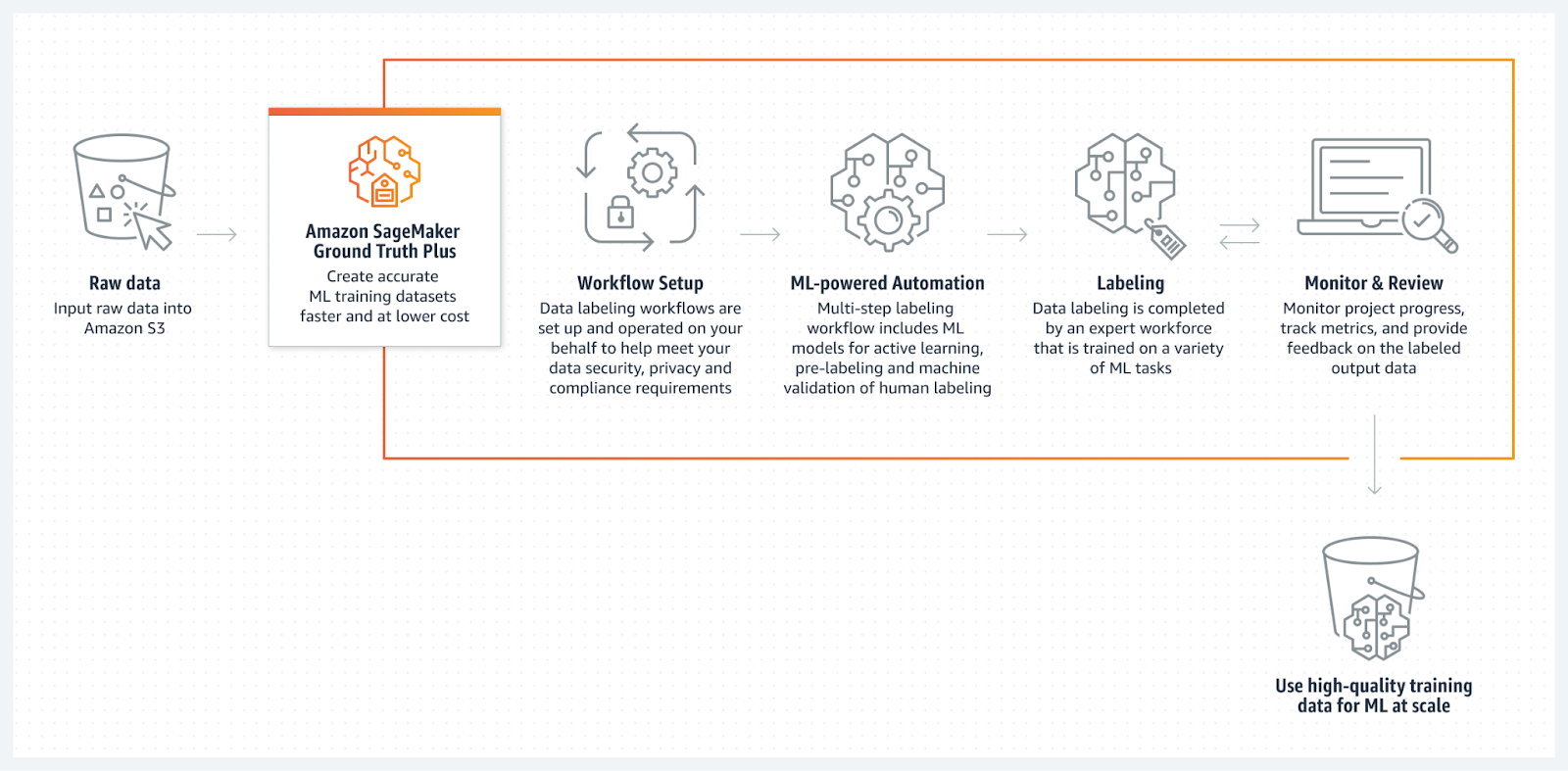
Source : Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth est un service de labellisation de données entièrement géré et conforme aux normes de l'industrie, qui s'intègre parfaitement à AWS. Il fournit des outils d'annotation manuelle et automatisée des données qui permettent aux utilisateurs d'étiqueter les données rapidement et avec précision.
SageMaker Ground Truth utilise l'apprentissage automatique pour assister les annotateurs humains en pré-étiquetant les données, ce qui accélère le processus et réduit les coûts. Ce service constitue également une option extrêmement polyvalente pour différentes tâches d'apprentissage automatique, car il prend en charge un large éventail de types de données, notamment les images, le texte et les vidéos.
De plus, il est évolutif, ce qui en fait une option solide pour les entreprises qui ont besoin de capacités d'annotation à grande échelle au sein de l'écosystème AWS.
Une annotation efficace des données est essentielle à la réussite des modèles d'apprentissage automatique, car la qualité des données étiquetées a un impact direct sur la précision des prédictions et des classifications. Le respect des meilleures pratiques peut contribuer à garantir l'efficacité et la fiabilité du processus d'annotation.
Dans cette section, nous examinerons les pratiques essentielles qui peuvent améliorer la qualité et la cohérence de l'annotation des données tout en relevant les défis auxquels on peut être confronté lors du processus d'étiquetage.
L'une des étapes les plus importantes du processus d'annotation des données consiste à créer des directives claires et bien définies. Ces directives doivent préciser exactement comment les données doivent être étiquetées et quels critères les annotateurs doivent respecter pour garantir la cohérence.
Des directives claires contribuent à :
Il est particulièrement important de disposer de règles standardisées pour les données complexes ou subjectives, telles que les images ou les textes pouvant donner lieu à plusieurs interprétations.
La qualité est essentielle pour garantir l'exactitude et la fiabilité des données annotées. Par conséquent, les données annotées doivent être examinées périodiquement afin de s'assurer qu'elles répondent aux normes requises. Ce processus peut être mené à bien par le biais d'audits aléatoires, en faisant appel à plusieurs annotateurs pour les mêmes tâches (afin de comparer les résultats) ou en recoupant les annotations, selon le projet.
L'essentiel est qu'il est essentiel de mettre en œuvreun processus d'assurance qualité robuste pour vous aider à détecter rapidement les erreurs, réduire les biais dans vos données et garantir que les données étiquetées sont adaptées à la formation de modèles d'apprentissage automatique performants.
L'apprentissage actif est une technique d'apprentissage automatique qui permet à un algorithme de sélectionner les échantillons de données les plus informatifs pour l'étiquetage, ce qui améliore les performances du modèle. Cette technique peut considérablement améliorer l'efficacité du processus d'annotation. Il permet aux annotateurs de concentrer leur temps et leur énergie sur les points de données les plus complexes et les plus précieux, tandis que l'algorithme d'apprentissage automatique suggère le reste.
Cette approche réduit le temps consacré à l'étiquetage des échantillons simples ou répétitifs et accélère le processus d'annotation global. Ainsi, cela augmente les chances que le modèle d'apprentissage automatique utilisé pour faire des prédictions soit entraîné sur les exemples les plus critiques.
Afin de garantir la précision du processus d'annotation, les annotateurs doivent recevoir une formation adéquate. La formation aide les annotateurs à comprendre les exigences spécifiques de la tâche et à appliquer correctement les directives d'annotation.
Des annotateurs bien formés sont plus susceptibles de produire des données étiquetées de haute qualité, ce qui améliore en fin de compte les performances des modèles d'apprentissage automatique qu'ils soutiennent. Des sessions de formation régulières et des boucles de rétroaction peuvent également contribuer à affiner les compétences des annotateurs au fil du temps, améliorant ainsi davantage le processus d'annotation des données.
Bien que l'annotation des données soit essentielle à l'entraînement de modèles d'apprentissage automatique précis, ce processus comporte son lot de défis. Dans cette section, nous aborderons certains des défis les plus courants liés à l'annotation de données.
L'annotation manuelle des données est souvent une tâche fastidieuse. L'annotation de toutes les instances nécessite un investissement considérable en temps et en ressources financières, en particulier lorsque le jeu de données est volumineux. Plus les données sont complexes (telles que des vidéos ou des images complexes), plus le processus d'annotation est long. Il est nécessaire de recruter des annotateurs qualifiés, ce qui augmente les coûts.
Pour surmonter ce défi, les organisations peuvent utiliser des outils d'annotation semi-automatisés, dans lesquels des modèles d'apprentissage automatique suggèrent des étiquettes qui sont ensuite vérifiées par des humains. Cela accélère le processus sans compromettre la précision.
L'apprentissage actif peut également contribuer à concentrer les efforts humains sur les données les plus informatives, ce qui réduit la quantité totale de données à étiqueter manuellement. De plus, l'utilisation de plateformes de crowdsourcing telles qu'Amazon Mechanical Turk permet à plusieurs contributeurs de travailler simultanément, ce qui rend l'annotation à grande échelle plus abordable et plus efficace.
Un autre défi majeur consiste à gérer la subjectivité et les préjugés dans le processus d'annotation. Différents annotateurs peuvent interpréter les mêmes données de différentes manières. Ceci est extrêmement courant pour des tâches telles que l'étiquetage des émotions dans un texte ou l'identification d'objets dans des images complexes. Le problème est que la subjectivité peut introduire un biais dans les données étiquetées, ce qui peut entraîner des prédictions biaisées du modèle.
Afin de réduire la subjectivité et les biais, les organisations doivent établir des directives claires et détaillées en matière d'annotation afin de garantir que tous les annotateurs suivent les mêmes critères. Une autre solution consiste à utiliser plusieurs annotateurs pour les mêmes données, ce qui permet de procéder à des vérifications croisées et aide à identifier et à corriger les annotations biaisées ou incohérentes.
Les annotations qui révèlent des informations d'identification peuvent enfreindre les réglementations en matière de confidentialité qui protègent les données personnelles. Ce défi est particulièrement important lors de l'externalisation des tâches d'annotation ou de l'utilisation de plateformes de crowdsourcing, où de nombreux contributeurs ont accès aux données.
Des solutions telles que l'anonymisation (suppression des informations personnelles identifiables) et l'utilisation de plateformes sécurisées et cryptées pour l'annotation peuvent contribuer à atténuer ces risques.
Dans cette section, nous explorerons les applications concrètes de l'annotation de données. Commençons sans plus attendre !
Dans le domaine des véhicules autonomes, l'annotation des données est essentielle pour enseigner à l'IA à naviguer en toute sécurité dans le monde réel. Les véhicules autonomes s'appuient sur des données annotées pour identifier les objets.
Par exemple, les annotateurs étiquettent des images ou des images vidéo en dessinant des cadres autour des voitures ou en marquant les limites de la route pour la détection des voies. Ces annotations aident l'IA à apprendre à reconnaître et à réagir à divers scénarios routiers, tels que s'arrêter pour laisser passer des piétons ou rester dans la bonne voie.
Les modèles d'IA ont besoin d'images médicales étiquetées pour apprendre à détecter les anomalies. Par exemple, des annotateurs qualifiés pourraient délimiter des zones spécifiques sur des images afin de marquer les régions présentant des signes précurseurs d'un cancer. Cela permet à l'IA de détecter rapidement et précisément le cancer plus tôt que les méthodes traditionnelles, ce qui améliore les résultats pour les patients et réduit la charge de travail des professionnels de santé.
Pour les chatbots destinés au service client, l'annotation de texte est essentielle pour enseigner à l'IA comment comprendre le langage humain.
Par exemple, les annotateurs peuvent étiqueter du texte afin d'aider les chatbots à reconnaître l'intention de l'utilisateur. Les chatbots analyseraient ensuite les interactions étiquetées afin d'apprendre à fournir les réponses appropriées. Cela permet aux organisations d'offrir une assistance plus rapide et plus précise, et d'améliorer l'expérience client.
Dans l'analyse des sentiments, une notation de texte et d's est utilisée pour évaluer ce que les clients pensent de certaines choses (par exemple, la marque, les produits ou les événements). Le processus consiste à demander à des annotateurs de classer des expressions ou des phrases comme positives, négatives ou neutres, puis de transmettre ces données à l'IA afin qu'elle apprenne à identifier le sentiment sous-jacent. Une entreprise peut ensuite déployer cette solution pour surveiller la manière dont les clients accueillent le lancement d'un nouveau produit.
L'annotation de données est le processus qui consiste à étiqueter des données afin de les rendre reconnaissables et utilisables par les modèles d'apprentissage automatique. Il s'agit d'une étape cruciale dans le développement de systèmes d'IA capables d'interpréter et de répondre avec précision aux données du monde réel. Pourquoi ? En effet, la qualité et la précision des données annotées ont un impact direct sur les performances et l'efficacité des modèles d'IA.
En définitive, l'annotation des données sert de base à la création de systèmes d'IA intelligents et fiables, capables de stimuler l'innovation dans divers secteurs. Cela en fait un élément indispensable du développement de l'apprentissage automatique.
Pour approfondir vosconnaissances, veuillez consulter les ressources suivantes :
Veuillez découvrir l'apprentissage automatique et l'intelligence artificielle grâce à ces cours.
Cours
Cours
Cours