
Curso
Understanding Machine Learning
2 h
293.7K
Imagina que estás desarrollando un coche autónomo. Para que el coche «vea» y comprenda la carretera, debe aprender a reconocer objetos como peatones, señales de tráfico y otros vehículos. Para que esto sea posible, elsistema de machine learning de Carnecesita miles, si no millones, de imágenes de situaciones reales de conducción.
Pero el coche no puede entender por sí mismo lo que hay en las imágenes. No sabe que un octágono rojo es una señal de stop ni que una persona está caminando por la acera. Aquí es donde entra en juego la anotación de datos.
La anotación de datos es el proceso de etiquetar datos sin procesar para que sean comprensibles y utilizables para los modelos de machine learning. Lo explicaremos con más detalle más adelante, pero tenlo en cuenta.
Esto es lo que veremos en este artículo:
¡Empecemos!
La mejor manera de entender la anotación de datos es pensar en cómo se enseña a los niños los diferentes animales. Al principio,, les muestras una imagen de un perro y les dices: «Esto es un perro». Luego les muestras un gato y dices: «Esto es un gato». Con el tiempo, al mostrarles ejemplos etiquetados, el niño aprende a identificar los animales de forma independiente. La anotación de datos funciona de manera similar para las máquinas.
Al igual que un niño necesita ejemplos etiquetados (nota: decir «esto es un perro» es la etiqueta), los modelos de machine learning necesitan que los datos estén anotados para poder aprender de ellos. Por lo tanto, la anotación de datos es el proceso de etiquetar o marcar datos, como imágenes, texto o audio, para que los algoritmos de machine learning puedan reconocerlos y comprenderlos.
Las etiquetas sirven como ejemplos que enseñan al sistema qué patrones debe buscar. Por ejemplo, si anotan miles de imágenes con las etiquetas «perro» o «gato», el modelo comenzará a reconocer las diferencias entre ambos.
Una vez que ha aprendido de estos ejemplos, el modelo puede realizar predicciones o clasificar nuevos datos sin etiquetar, del mismo modo que el niño acaba reconociendo los animales sin tu ayuda.
Los diferentes tipos de datos requieren métodos de anotación específicos para prepararlos para tareas de machine learning. Dependiendo de la naturaleza de los datos, existen enfoques únicos para el etiquetado y el marcado. Comprender estos tipos ayuda a determinar la forma más eficaz de entrenar modelos para una variedad de aplicaciones.
Exploremos los tipos más comunes de anotación de datos:
La anotación de imágenes consiste en etiquetar imágenes para que los modelos de machine learning puedan identificar e interpretar los objetos que aparecen en ellas. En la anotación de imágenes se utilizan diferentes técnicas, dependiendo del nivel de detalle requerido:

Cuadros delimitadores. : Anolytics
Este método consiste en dibujar rectángulos alrededor de los objetos de una imagen para ayudar al modelo a reconocer su presencia y ubicación. Los cuadros delimitadores se utilizan habitualmente para detectar coches, peatones o señales en la tecnología de conducción autónoma.

Segmentación semántica. Fuente: Introducción a la segmentación semántica de imágenes
Aquí, cada píxel de una imagen se etiqueta para asignar regiones específicas a objetos o categorías concretos, como identificar carreteras, edificios o árboles. Esta técnica proporciona al modelo una comprensión más detallada de la escena.

Anotación de puntos de referencia. : Anolytics
Esta técnica consiste en marcar puntos específicos dentro de una imagen, como rasgos faciales o puntos clave de la postura corporal. Se utiliza en aplicaciones como el reconocimiento facial y la estimación de la postura humana.
La anotación de texto es el proceso de etiquetar y marcar datos de texto para que sean comprensibles para los modelos de procesamiento del lenguaje natural (NLP). Permite a las máquinas comprender, procesar y analizar el lenguaje humano.
Existen varias técnicas comunes que se utilizan en la anotación de textos:

Reconocimiento de entidades. Fuente: Reconocimiento y clasificación de entidades nombradas con Scikit-Learn
Esto implica identificar entidades específicas en un texto, como nombres de personas, lugares u organizaciones. Por ejemplo, en la frase «Apple abrió una nueva tienda en Nueva York», el modelo reconocería «Apple» como una empresa y «Nueva York» como una ubicación.

Etiquetado de sentimientos. Source: Comprensión del proceso de anotación de textos para el análisis del sentimiento del cliente
Esta técnica asigna emociones u opiniones a fragmentos de texto, etiquetándolos como positivos, negativos o neutros. Se utiliza a menudo en reseñas de clientes o en el seguimiento de redes sociales para comprender cómo se sienten los usuarios con respecto a un producto o servicio.
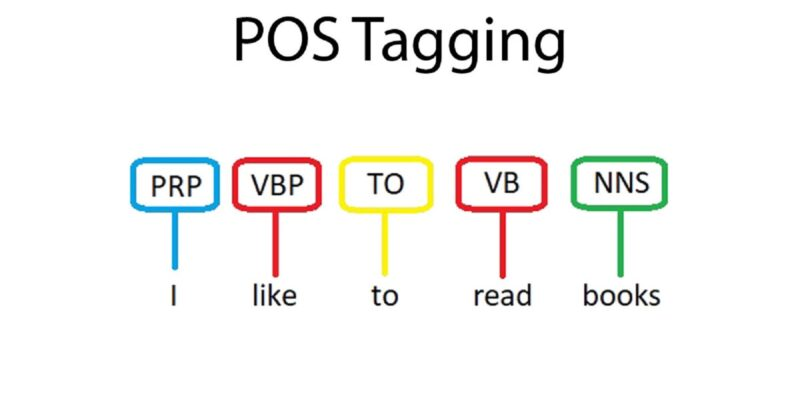
Etiquetado POS. Fuente: Etiquetado POS en PLN
Este método etiqueta cada palabra de una frase con su función gramatical (por ejemplo, sustantivo, verbo, adjetivo), lo que ayuda a los modelos a comprender la estructura del lenguaje para tareas como la traducción o el reconocimiento de voz.
La anotación de audio consiste en etiquetar archivos de sonido para entrenar modelos de reconocimiento de voz, detección de música o clasificación de sonidos.
Algunas técnicas comunes de anotación de audio incluyen:
La conversión de palabras habladas en un archivo de audio en texto escrito se utiliza a menudoen aplicaciones de voz a texto.
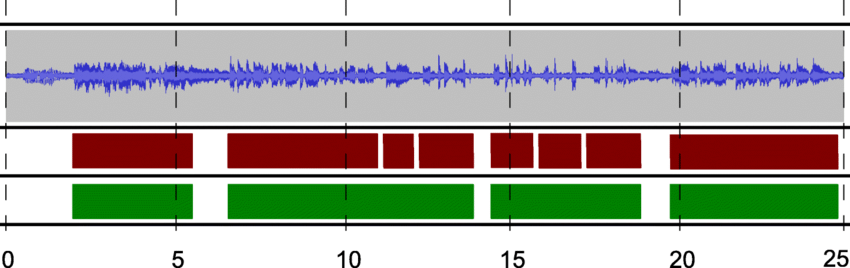
Segmentación del habla. : ResearchGate
Esto implica dividir un archivo de audio en diferentes secciones. Por ejemplo, es posible que quieras separar el diálogo del ruido de fondo o identificar a cada uno de los interlocutores en una conversación.
Etiquetado de sonido. Así queFuente: Etiquetado de Freesound por VGGish con KNN
El etiquetado de sonido consiste en etiquetar sonidos específicos (por ejemplo, ruido del tráfico, sonidos de animales, etc.) dentro de un archivo de audio.
La anotación de vídeo consiste en etiquetar y marcar objetos o acciones en fotogramas de vídeo para ayudar a los modelos de machine learning a interpretar el movimiento y las actividades.
Las técnicas clave de anotación de vídeos incluyen:
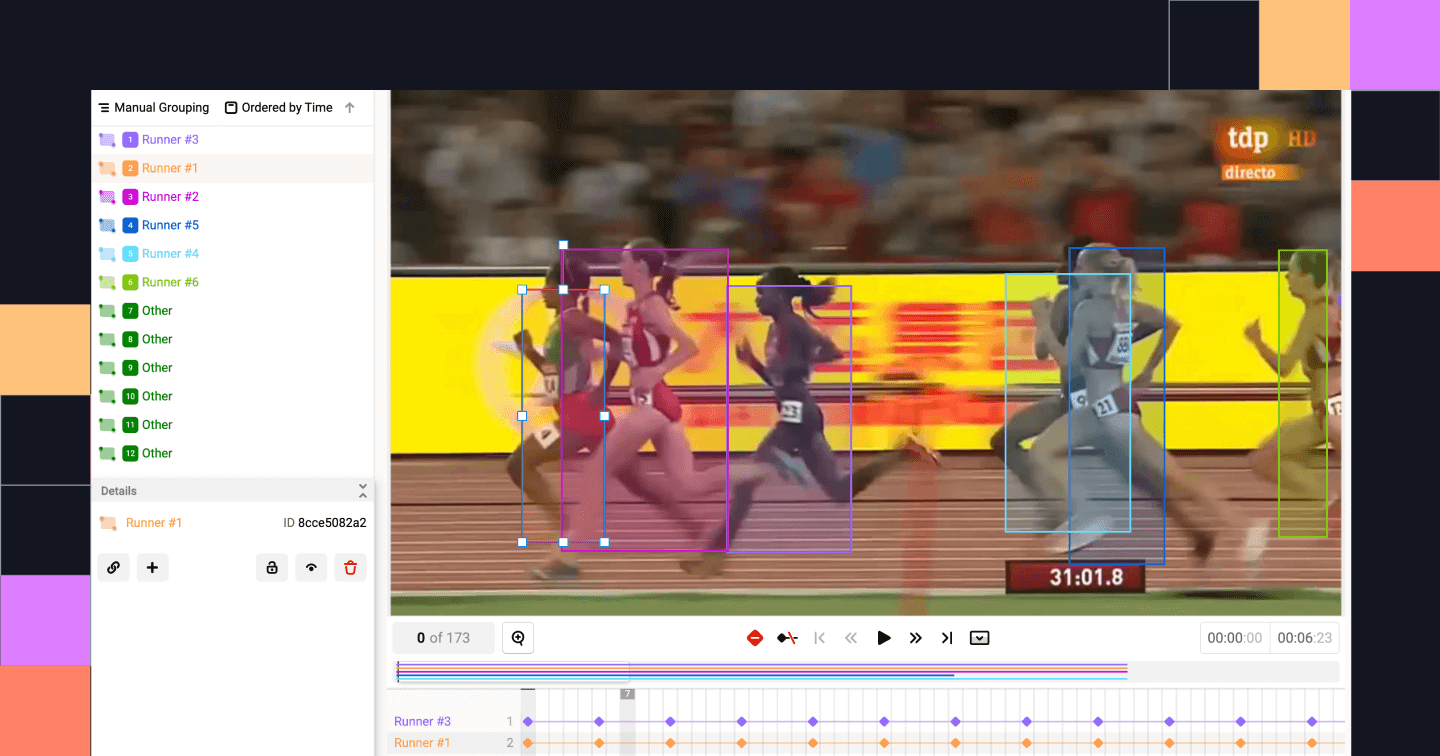
Seguimiento de objetos. Fuente: Estudio de etiquetas
El seguimiento de objetos consiste en etiquetar continuamente objetos en varios fotogramas para seguir su movimiento. En escenarios de conducción autónoma, por ejemplo, se puede utilizar el seguimiento de objetos para seguir a un vehículo a través de una intersección concurrida.
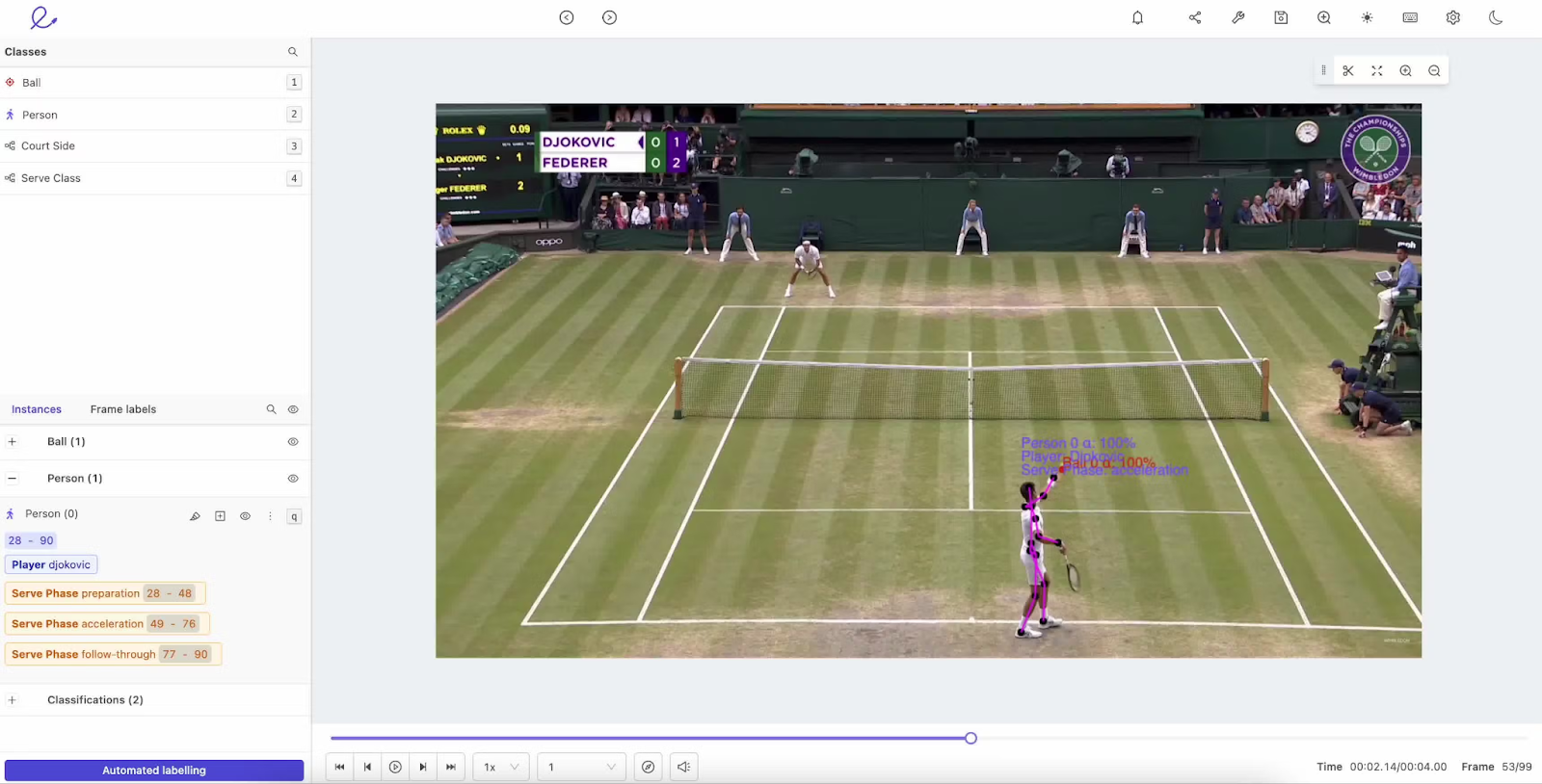
Etiquetado de actividades. Source: Encord
Es cuando se asignan etiquetas a acciones específicas, como alguien caminando, corriendo o sentándose en un vídeo. Esto ayuda a los modelos a comprender el comportamiento humano en aplicaciones como la supervisión de la seguridad o el análisis deportivo.
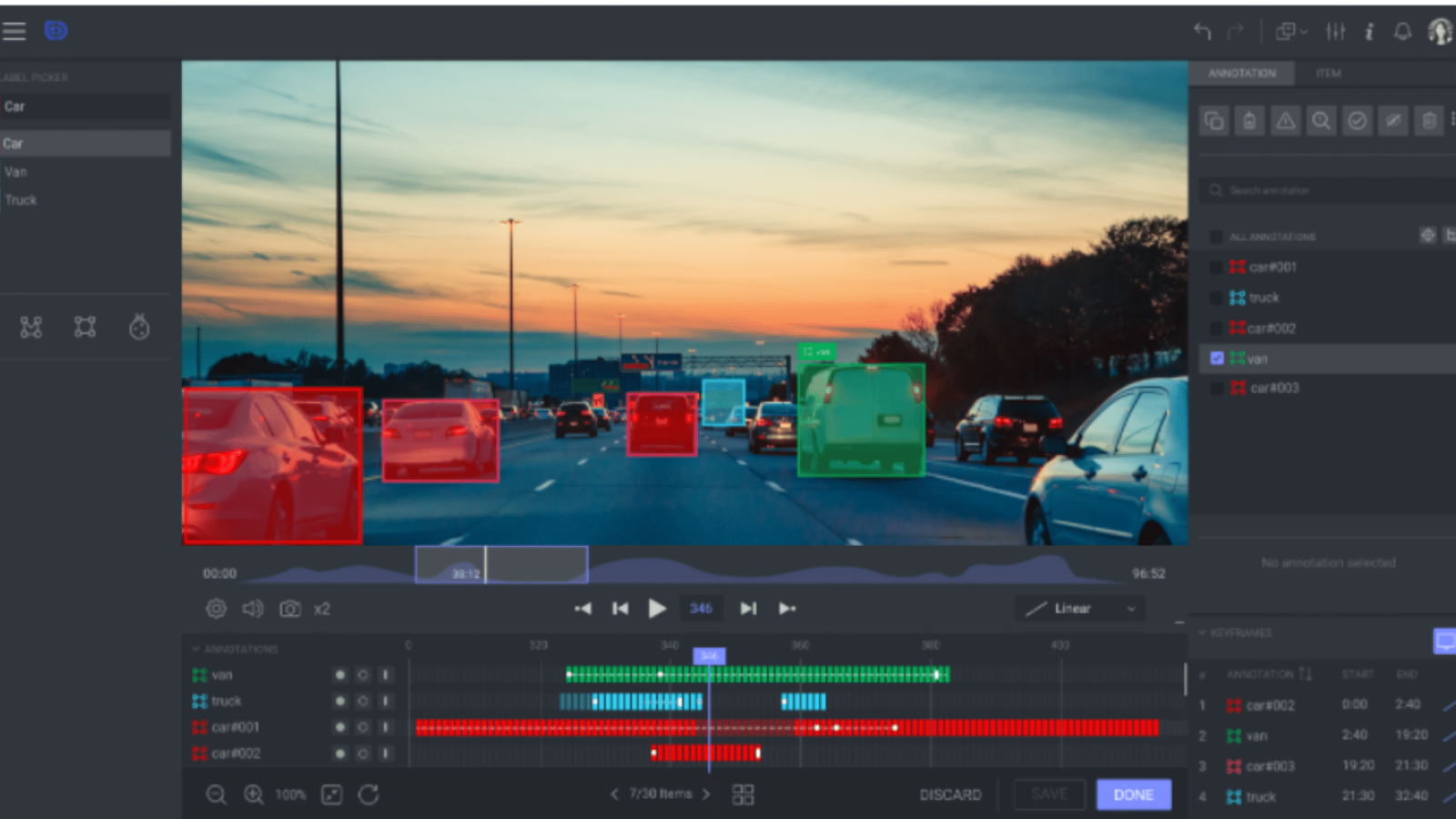
Anotación fotograma a fotograma. Source: dataloop
Cuando se etiqueta cada fotograma individual de un vídeo para capturar los detalles más minuciosos, se denomina detección fotograma a fotograma. Se utiliza a menudo para tareas que requieren una gran precisión, como el análisis de los movimientos corporales en fisioterapia.
El método utilizado para anotar los datos puede variar en función de varios factores, tales como:
En otras palabras, algunas tareas requieren la precisión de los anotadores humanos, mientras que otras pueden beneficiarse de la automatización para ahorrar tiempo y ampliar el proceso. A continuación, exploraremos los distintos enfoques para que puedas comprender mejor en qué situaciones se debe utilizar cada uno.
La anotación manual es cuando anotadores humanos etiquetan los datos a mano. En este enfoque, los anotadores capacitados revisan cuidadosamente cada dato y aplican las etiquetas o etiquetas necesarias.
La mayor ventaja de la anotación manual es la precisión. Dado que los seres humanos pueden comprender el contexto, los matices y los patrones complejos mejor que las máquinas, pueden garantizar que los datos se etiqueten con precisión. Este nivel de precisión es especialmente importante para proyectos que requieren anotaciones detalladas y de alta calidad, como el etiquetado de imágenes médicas o tareas complejas de lenguaje natural.
Sin embargo, la anotación manual también plantea retos importantes:
A pesar de estos retos, la anotación manual sigue siendo esencial para proyectos en los que la precisión es fundamental, aunque las empresas suelen buscar formas de equilibrar la calidad con la eficiencia en términos de tiempo y costes.
La anotación semiautomatizada combina la experiencia humana con la asistencia del machine learning. En este enfoque, un modelo de machine learning ayuda a los anotadores humanos preetiquetando los datos u ofreciendo sugerencias. A continuación, los anotadores humanos revisan y perfeccionan las etiquetas para garantizar su precisión.
La ventaja de la anotación semiautomatizada es que agiliza el proceso sin perder precisión. La máquina puede realizar tareas repetitivas o sencillas, lo que permite a los anotadores humanos centrarse en datos más complejos o ambiguos. Este enfoque es ideal para proyectos grandes en los que la anotación manual completa sería demasiado lenta o costosa, ya que logra un equilibrio entre la eficiencia en el tiempo y el control de calidad.
Sin embargo, se enfrenta a ciertos retos:
La anotación semiautomatizada funciona mejor para proyectos que necesitan equilibrar la calidad y la velocidad, en los que los datos son lo suficientemente complejos como para beneficiarse de la revisión humana, pero lo suficientemente grandes como para requerir la ayuda de una máquina.
La anotación automatizada utiliza algoritmos de machine learning para etiquetar datos sin intervención humana. En este enfoque, los modelos preentrenados o las herramientas basadas en IA anotan automáticamente grandes conjuntos de datos. Esto hace que el proceso sea más rápido y escalable que los métodos manuales o semiautomatizados.
La principal ventaja de la anotación automatizada es su eficiencia. Puede procesar grandes cantidades de datos en una fracción del tiempo que le llevaría a un anotador humano. Como resultado, la anotación automatizada es una solución ideal para proyectos con grandes conjuntos de datos, como etiquetar millones de imágenes para un modelo de visión artificial o transcribir grandes volúmenes de audio para el reconocimiento de voz.
Pero las desventajas de depender de las máquinas son las siguientes:
La anotación automatizada es más adecuada para proyectos que requieren rapidez y escalabilidad, pero en los que se acepta un cierto margen de error o en los que se puede recurrir posteriormente a la revisión humana para perfeccionar los resultados.
El crowdsourcing consiste en distribuir tareas de etiquetado de datos a un gran número de colaboradores mediante plataformascomo Amazon Mechanical Turk o Appen. Este método permite a las empresas anotar grandes conjuntos de datos de forma rápida y rentable, gracias a un grupo global de trabajadores.
Una de las principales ventajas del crowdsourcing es la escalabilidad. La distribución de tareas entre muchos colaboradores permite a las empresas gestionar grandes volúmenes de datos de forma eficiente. Por ejemplo, un proyecto que requiere miles de imágenes etiquetadas o transcripciones se puede completar en días, en lugar de semanas o meses.
Las desventajas de este enfoque son las siguientes:
El crowdsourcing es ideal para proyectos a gran escala que requieren anotaciones rápidas y rentables. Sin embargo, mantener resultados de alta calidad requiere una supervisión y una gestión de tareas rigurosas.
Existe una amplia gama de herramientas disponibles para la anotación de datos. Estas herramientas van desde plataformas de código abierto hasta soluciones comerciales integrales, cada una de ellas diseñada para satisfacer las diferentes necesidades de los proyectos.
Por ejemplo, las herramientas de código abierto suelen ser personalizables y de uso gratuito. Esto los hace ideales para proyectos más pequeños o equipos con experiencia técnica. Por otro lado, las opciones comerciales ofrecen funciones más avanzadas, como automatización, herramientas de colaboración y control de calidad, lo que las hace más adecuadas para proyectos a gran escala o empresas que buscan un flujo de trabajo optimizado.
En esta sección, exploraremos algunas de las herramientas más populares disponibles para la anotación de datos y cómo pueden ayudar con diferentes tipos de datos:
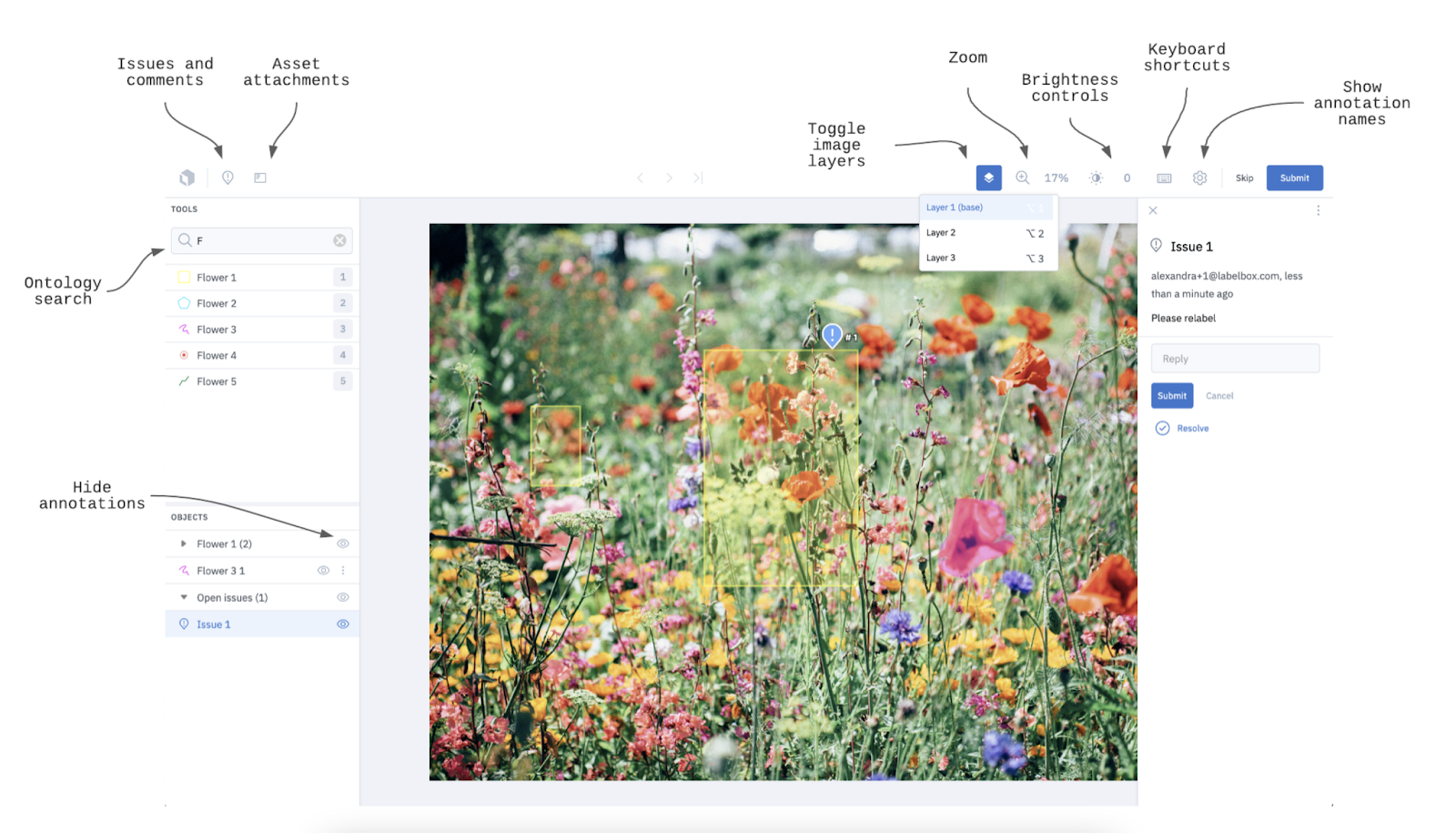
Fuente: Documentos de Labelbox
Labelbox es una plataforma comercial de anotación de datos ( ) ampliamente utilizada, diseñada para optimizar el proceso de anotación de datos, centrándose en la colaboración y el control de calidad. Fue fundada en 2018 por Manu Sharma, Brian Rieger y Peter Welinder, cuya misión es«: crear los mejores productos para alinearse con la inteligencia artificial».
La plataforma Labelbox ofrece una interfaz intuitiva en la que los equipos pueden colaborar para anotar datos, realizar un seguimiento del progreso y mantener altos estándares de anotación. También admite una gran variedad de tipos de datos (por ejemplo, imágenes, vídeo y texto), lo que hace que la plataforma sea extremadamente versátil para diferentes proyectos de machine learning.
Una de sus características principales son los mecanismos de control de calidad integrados, que permiten a los equipos revisar y aprobar las anotaciones, lo que garantiza resultados coherentes y precisos.
Labelbox es ideal para organizaciones que buscan ampliar sus esfuerzos de anotación con funciones integradas de gestión de proyectos y automatización.
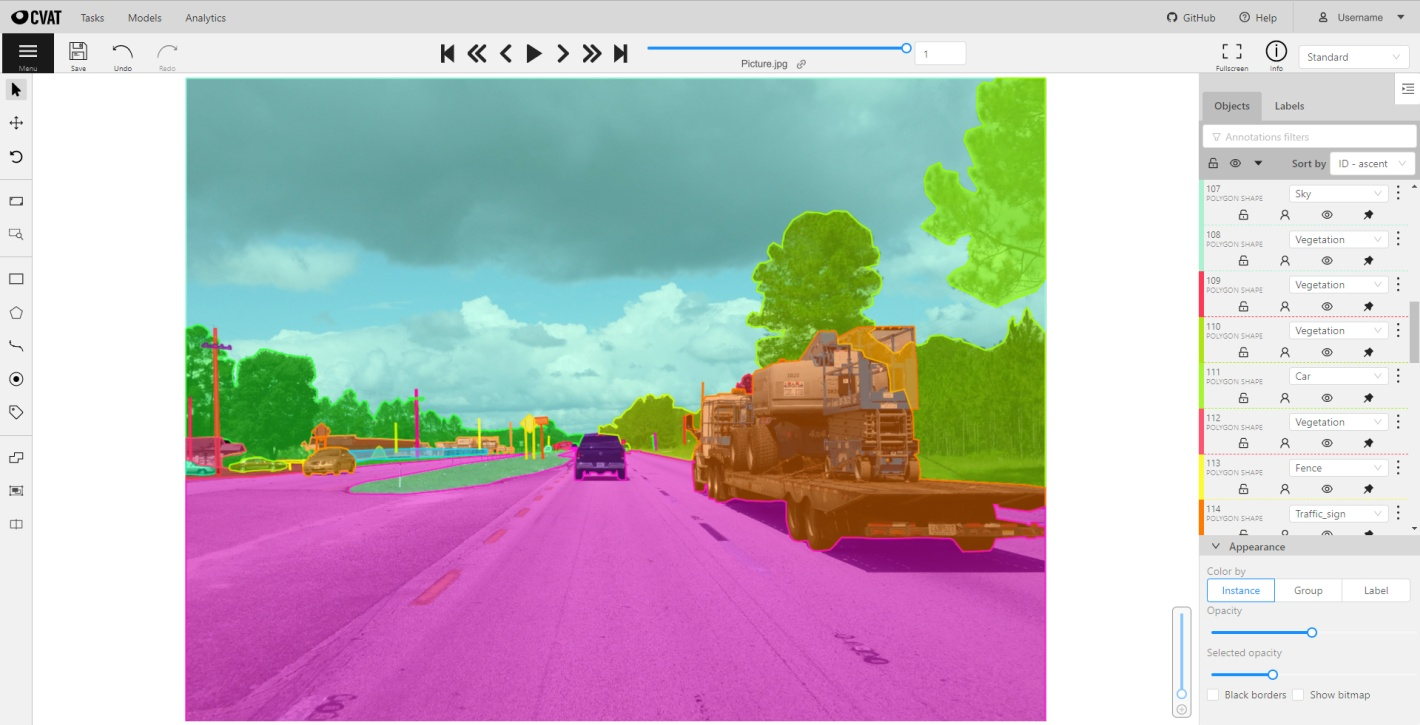
Source: Página de CVAT en Wikipedia
CVAT es una herramienta de código abierto de CVAT ( ) diseñada específicamente para anotar conjuntos de datos de imágenes y vídeos. Desarrollado por Intel, CVAT es altamente personalizable y ofrece una amplia gama de técnicas de anotación (por ejemplo, cuadros delimitadores, polígonos y anotaciones de puntos clave). Su flexibilidad lo hace adecuado para proyectos que van desde la detección de objetos hasta el reconocimiento facial.
Al ser de código abierto, CVAT es gratuito y se puede adaptar a las necesidades específicas de cada proyecto. Esto lo convierte en una opción popular entre investigadores y equipos pequeños que necesitan potentes herramientas de anotación sin el coste que supone el software comercial.
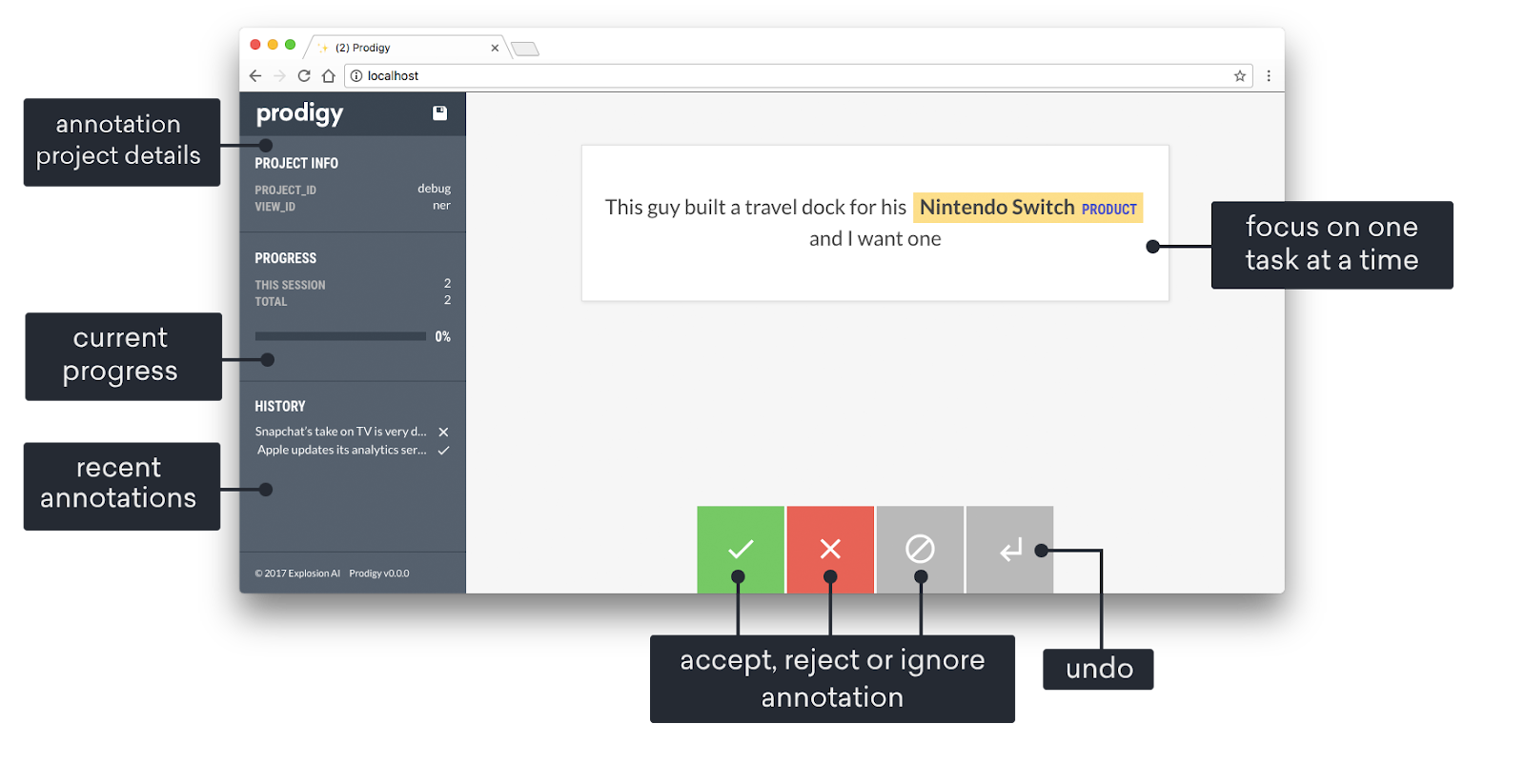
Source: Documentos Prodigy
Prodigy es una herramienta de anotación avanzaida desarrollada por Explosion AI que utiliza el aprendizaje activo para mejorar la eficiencia, especialmente en tareas de procesamiento del lenguaje natural (NLP). Con Prodigy, un modelo de machine learning ayuda a los anotadores sugiriendo etiquetas basadas en sus predicciones, que luego son confirmadas o corregidas por revisores humanos.
Este enfoque interactivo agiliza el proceso de anotación y garantiza al mismo tiempo la alta calidad de los datos etiquetados. A pesar de ser una herramienta comercial, Prodigy es altamente personalizable; por ejemplo, permite a los usuarios crear sus propios flujos de trabajo de anotación. Estos factores hacen que Prodigy sea muy adecuado para equipos que trabajan en proyectos especializados de PLN, como el análisis de sentimientos, el reconocimiento de entidades o la clasificación de textos.
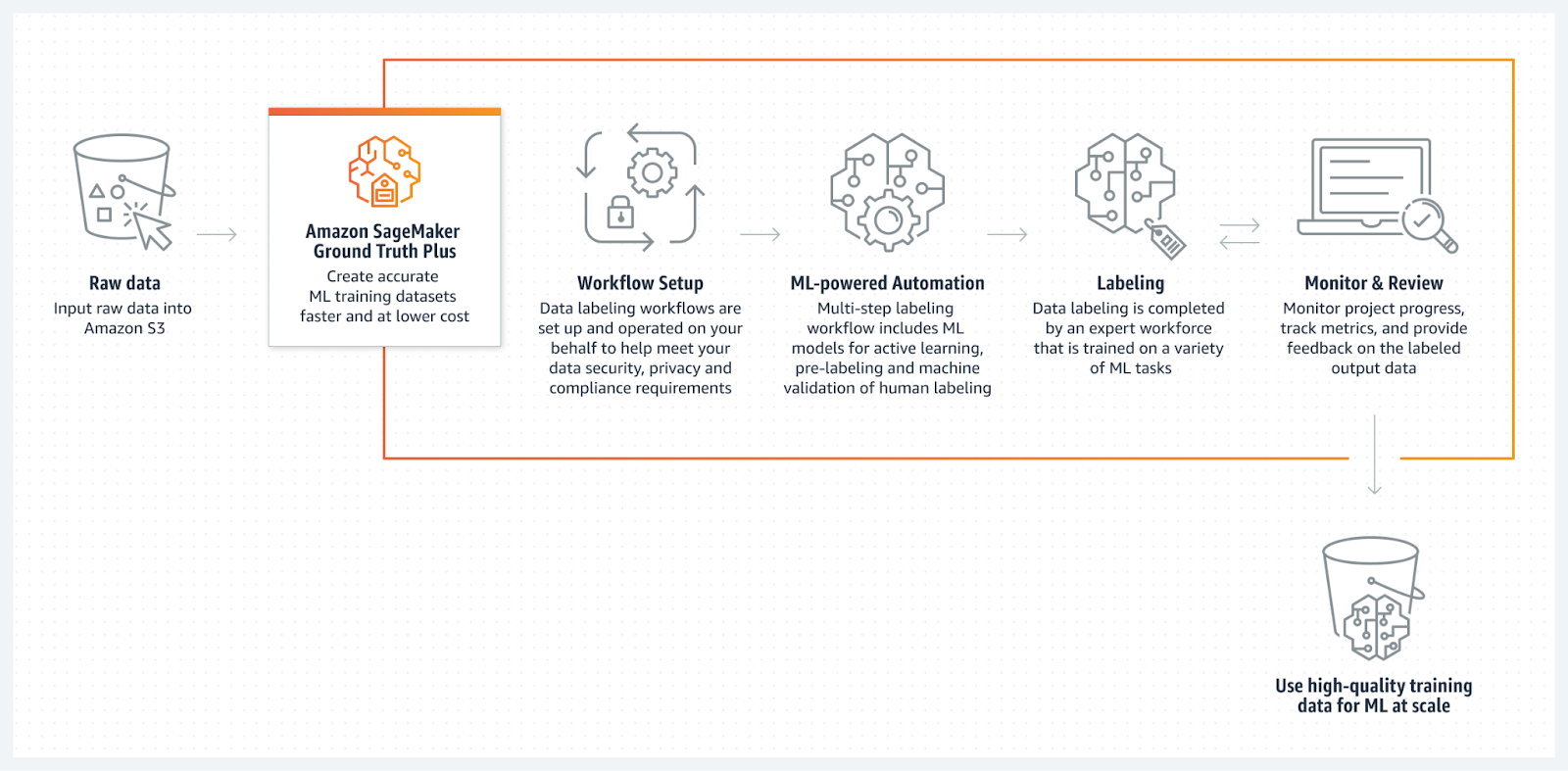
Fuente: Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth es un servicio de etiquetado de datos totalmente gestionado y basado en la nube que se integra a la perfección con AWS. Proporciona herramientas para la anotación manual y automatizada de datos que permiten a los usuarios etiquetar los datos de forma rápida y precisa.
SageMaker Ground Truth utiliza machine learning para ayudar a los anotadores humanos mediante el preetiquetado de datos, lo que acelera el proceso y reduce los costes. El servicio también es una opción extremadamente versátil para diferentes tareas de machine learning, ya que admite una amplia variedad de tipos de datos, incluyendo imágenes, texto y vídeos.
Además, está diseñado para ser escalable, lo que lo convierte en una opción sólida para las empresas que necesitan capacidades de anotación a gran escala dentro del ecosistema de AWS.
La anotación eficaz de datos es fundamental para el éxito de los modelos de machine learning, ya que la calidad de los datos etiquetados influye directamente en la precisión de las predicciones y clasificaciones. Seguir las mejores prácticas puede ayudar a garantizar que el proceso de anotación sea eficiente y fiable.
En esta sección, exploraremos prácticas esenciales que pueden mejorar la calidad y la coherencia de la anotación de datos, al tiempo que abordamos los retos que pueden surgir durante el proceso de etiquetado.
Uno de los pasos más importantes en el proceso de anotación de datos es crear directrices claras y bien definidas. Estas directrices deben especificar exactamente cómo deben etiquetarse los datos y qué criterios deben seguir los anotadores para garantizar la coherencia.
Unas directrices claras ayudan a:
Contar con normas estandarizadas es especialmente importante en el caso de datos complejos o subjetivos, como imágenes o textos con múltiples interpretaciones posibles.
La calidad es necesaria para mantener la precisión y fiabilidad de los datos anotados. Por lo tanto, los datos anotados deben revisarse periódicamente para garantizar que cumplen con los estándares requeridos. Este proceso puede llevarse a cabo mediante auditorías aleatorias, utilizando varios anotadores para las mismas tareas (para comparar resultados) o cotejando las anotaciones, en función del proyecto.
La idea principal es que es fundamental implementarun proceso de control de calidad sólido que te ayude a detectar errores de forma temprana, reducir el sesgo en tus datos y garantizar que los datos etiquetados sean adecuados para entrenar modelos de machine learning de alto rendimiento.
El aprendizaje activo es una técnica de machine learning que permite a un algoritmo seleccionar las muestras de datos más informativas para su etiquetado, lo que mejora el rendimiento del modelo. Esta técnica puede mejorar significativamente la eficiencia del proceso de anotación. Permite a los anotadores centrar su tiempo y energía en los puntos de datos más difíciles y valiosos, mientras que el algoritmo de machine learning sugiere el resto.
Este enfoque reduce el tiempo dedicado al etiquetado de muestras fáciles o repetitivas y acelera el proceso de anotación en general. De este modo, aumenta la probabilidad de que el modelo de machine learning utilizado para realizar predicciones se entrene con los ejemplos más críticos.
Para garantizar que el proceso de anotación se lleve a cabo con precisión, los anotadores deben recibir una formación adecuada. La formación ayuda a los anotadores a comprender los requisitos específicos de la tarea y cómo aplicar correctamente las directrices de anotación.
Los anotadores bien formados son más propensos a producir datos etiquetados de alta calidad, lo que en última instancia mejora el rendimiento de los modelos de machine learning que están apoyando. Las sesiones de formación periódicas y los bucles de retroalimentación también pueden ayudar a perfeccionar las habilidades de los anotadores con el tiempo, mejorando aún más el proceso de anotación de datos.
Aunque la anotación de datos es esencial para entrenar modelos de machine learning precisos, el proceso conlleva una serie de retos. En esta sección, analizaremos algunos de los retos más comunes en la anotación de datos.
La anotación manual de datos suele requerir mucho trabajo. Se necesita una cantidad considerable de tiempo y recursos financieros para anotar todas las instancias, especialmente cuando el conjunto de datos es grande. Cuanto más complejos sean los datos (como vídeos o imágenes intrincadas), más tiempo llevará el proceso de anotación. Es necesario contratar a anotadores cualificados, lo que aumenta los costes.
Para superar este reto, las organizaciones pueden utilizar herramientas de anotación semiautomatizadas, en las que los modelos de machine learning sugieren etiquetas y los humanos las verifican. Esto acelera el proceso sin sacrificar la precisión.
El aprendizaje activo también puede ayudar al centrar el esfuerzo humano en los datos más informativos, lo que reduce la cantidad total de datos que deben etiquetarse manualmente. Además, el uso de plataformas de crowdsourcing como Amazon Mechanical Turk permite que varios colaboradores trabajen simultáneamente, lo que significa que la anotación a gran escala puede ser más asequible y eficiente.
Otro reto clave es lidiar con la subjetividad y el sesgo en el proceso de anotación. Diferentes anotadores pueden interpretar los mismos datos de maneras diferentes. Esto es muy habitual en tareas como etiquetar emociones en textos o identificar objetos en imágenes complejas. El problema es que la subjetividad puede introducir sesgos en los datos etiquetados, lo que a su vez puede dar lugar a predicciones sesgadas del modelo.
Para reducir la subjetividad y los sesgos, las organizaciones deben crear directrices de anotación claras y detalladas que garanticen que todos los anotadores sigan los mismos criterios. Otra solución es utilizar varios anotadores para los mismos datos, lo que permite realizar comprobaciones cruzadas y ayuda a identificar y corregir anotaciones sesgadas o incoherentes.
Las anotaciones que revelan información identificativa pueden infringir las normativas de privacidad que protegen los datos personales. Este reto es especialmente importante cuando se externalizan tareas de anotación o se utilizan plataformas de crowdsourcing, en las que muchos colaboradores tienen acceso a los datos.
Soluciones como la anonimización (eliminación de información de identificación personal) y el uso de plataformas seguras y encriptadas para las anotaciones pueden ayudar a mitigar estos riesgos.
En esta sección, exploraremos las aplicaciones reales de la anotación de datos. ¡Empecemos!
En los vehículos autónomos, la anotación de datos es la base para enseñar a la IA a navegar con seguridad por el mundo real. Los coches autónomos dependen de datos anotados para identificar objetos.
Por ejemplo, los anotadores etiquetan imágenes o fotogramas de vídeo dibujando cuadros delimitadores alrededor de los coches o marcando los límites de la carretera para detectar los carriles. Estas anotaciones ayudan a la IA a aprender a reconocer y reaccionar ante diversas situaciones en la carretera, como detenerse ante peatones o permanecer en el carril correcto.
Los modelos de IA necesitan imágenes médicas etiquetadas para aprender a detectar anomalías. Por ejemplo, anotadores expertos delinearían áreas específicas en imágenes para marcar regiones que muestran signos tempranos de cáncer. Esto permite a la IA detectar el cáncer de forma rápida y precisa antes que los métodos tradicionales, lo que mejora los resultados de los pacientes y reduce la carga de trabajo de los profesionales médicos.
En el caso de los chatbots de atención al cliente, las anotaciones de texto son fundamentales para enseñar a la IA a comprender el lenguaje humano.
Por ejemplo, los anotadores pueden etiquetar texto para ayudar a los chatbots a reconocer la intención del usuario. A continuación, los chatbots analizarían las interacciones etiquetadas para aprender a proporcionar las respuestas adecuadas. Esto permite a las organizaciones ofrecer una asistencia más rápida y precisa, y mejorar la experiencia del cliente.
En el análisis de sentimientos, se utiliza una notación textual ee para evaluar cómo se sienten los clientes respecto a determinadas cosas (por ejemplo, la marca, los productos o los eventos). El funcionamiento es el siguiente: los anotadores etiquetan frases u oraciones como positivas, negativas o neutras, y luego estos datos se transmiten a la IA para que aprenda el sentimiento subyacente. A continuación, una empresa puede implementar esto para supervisar cómo están recibiendo los clientes el lanzamiento de un nuevo producto.
La anotación de datos es el proceso de etiquetar datos para que sean reconocibles y utilizables por los modelos de machine learning. Es un paso fundamental en el desarrollo de sistemas de IA capaces de interpretar y responder con precisión a datos del mundo real. ¿Por qué? Porque la calidad y la precisión de los datos anotados influyen directamente en el rendimiento y la eficacia de los modelos de IA.
En última instancia, la anotación de datos sirve como base para crear sistemas de IA inteligentes y fiables que pueden impulsar la innovación en diversos sectores. Esto lo convierte en una parte indispensable del desarrollo del machine learning.
Para continuar tuaprendizaje, consulta los siguientes recursos:
¡Aprende más sobre machine learning e IA con estos cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
6 min
blog
Austin Chia
blog
Javier Canales Luna
10 min
blog
Zoumana Keita
14 min
Tutorial
Zoumana Keita

