Course
Understanding Machine Learning
2 hr
293.2K
Imagine you are developing a self-driving car. To make the car "see" and understand the road, it must learn to recognize objects like pedestrians, traffic signs, and other vehicles. For this to happen, the car’s machine learning system requires thousands—if not millions—of images from real-world driving scenarios.
But the car can't inherently understand what's in the images. It doesn't know that a red octagon is a stop sign or that a person is walking on the sidewalk. This is where data annotation comes in.
Data annotation is the process of labeling raw data to make it understandable and usable for machine learning models. We’ll explain it in more depth later, but keep this in mind.
Here’s what we will explore in this article:
Let’s get into it!
The best way to think of data annotation is to think of what it’s like to teach kids different animals. At first, you show them a picture of a dog and say, “This is a dog.” Then you show them a cat and say, “This is a cat.” Over time, by showing them labeled examples, the child learns to identify animals independently. Data annotation works similarly for machines.
Just as a child requires labeled examples (note: saying “This is a dog” is the labeling), machine learning models require data to be annotated to learn from it. Thus, Data annotation is the process of labeling or tagging data, such as images, text, or audio, so that machine learning algorithms can recognize and understand it.
The labels serve as examples that teach the system what patterns to look for. For instance, if you annotate thousands of images with "dog" or "cat" labels, the model will start recognizing the differences between the two.
Once it has learned from these examples, the model can then make predictions or classify new unlabeled data, just as the child eventually recognizes animals without your help.
Different types of data require specific annotation methods to prepare them for machine learning tasks. Depending on the nature of the data, there are unique approaches for labeling and tagging. Understanding these types helps determine the most effective way to train models for a variety of applications.
Let's explore the most common types of data annotation:
Image annotation involves labeling images so that machine learning models can identify and interpret objects within them. Different techniques are used in image annotation, depending on the level of detail required:

Bounding boxes. Source: Anolytics
This method involves drawing rectangles around objects in an image to help the model recognize their presence and location. Bounding boxes are commonly used to detect cars, pedestrians, or signs in self-driving technology.

Semantic segmentation. Source: Introduction to Semantic Image Segmentation
Here, each pixel in an image is labeled to assign specific regions to particular objects or categories, like identifying roads, buildings, or trees. This technique gives the model a more granular understanding of the scene.

Landmark annotation. Source: Anolytics
This technique involves marking specific points within an image, such as facial features or key points in body posture. It's used in applications like facial recognition and human pose estimation.
Text annotation is the process of labeling and tagging text data to make it understandable for natural language processing (NLP) models. It enables machines to comprehend, process, and analyze human language.
There are several common techniques used in text annotation:

Entity recognition. Source: Named Entity Recognition and Classification with Scikit-Learn
This involves identifying specific entities in text, such as names of people, places, or organizations. For example, in the sentence "Apple opened a new store in New York," the model would recognize "Apple" as a company and "New York" as a location.

Sentiment tagging. Source: Understanding the text annotation process for Customer Sentiment Analysis
This technique assigns emotions or opinions to pieces of text, labeling them as positive, negative, or neutral. It’s often used in customer reviews or social media monitoring to understand how users feel about a product or service.
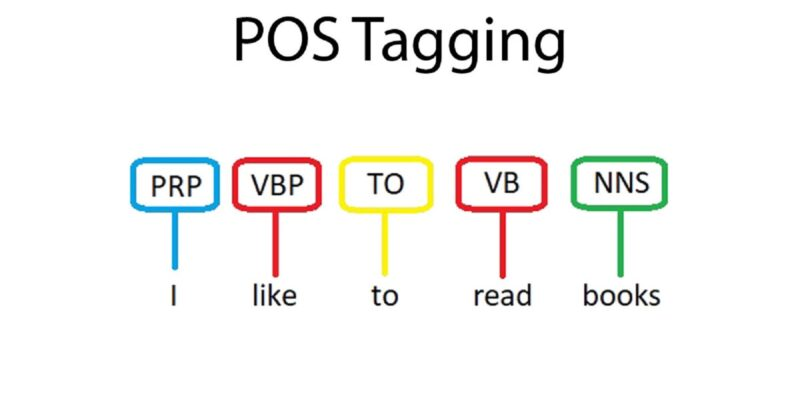
POS tagging. Source: POS tagging in NLP
This method labels each word in a sentence with its grammatical role (e.g., noun, verb, adjective), helping models understand language structure for tasks like translation or speech recognition.
Audio annotation involves labeling sound files to train models for speech recognition, music detection, or sound classification.
Some common audio annotation techniques include:
Converting spoken words in an audio file into written text is often used in speech-to-text applications.
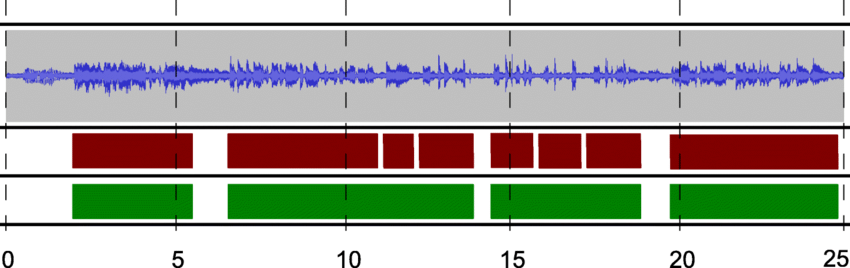
Speech segmentation. Source: ResearchGate
This involves dividing an audio file into different sections. For example, you may want to separate dialogue from background noise or identify individual speakers in a conversation.
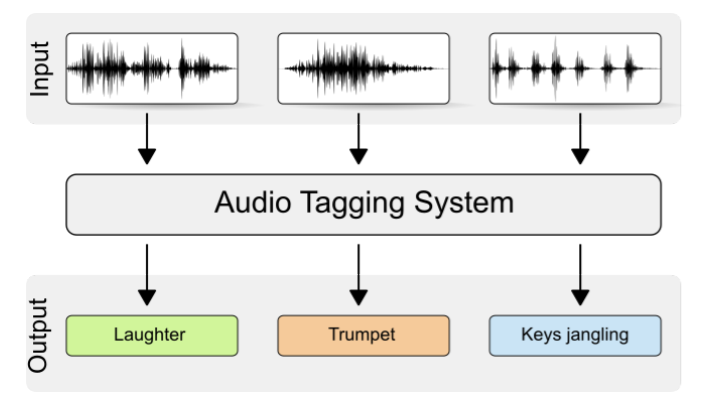
Sound tagging. Source: Freesound Tagging by VGGish with KNN
Sound tagging is when specific sounds (e.g., traffic noise, animal sounds, etc.) are labeled within an audio file.
Video annotation involves labeling and tagging objects or actions in video frames to help machine learning models interpret motion and activities.
Key video annotation techniques include:
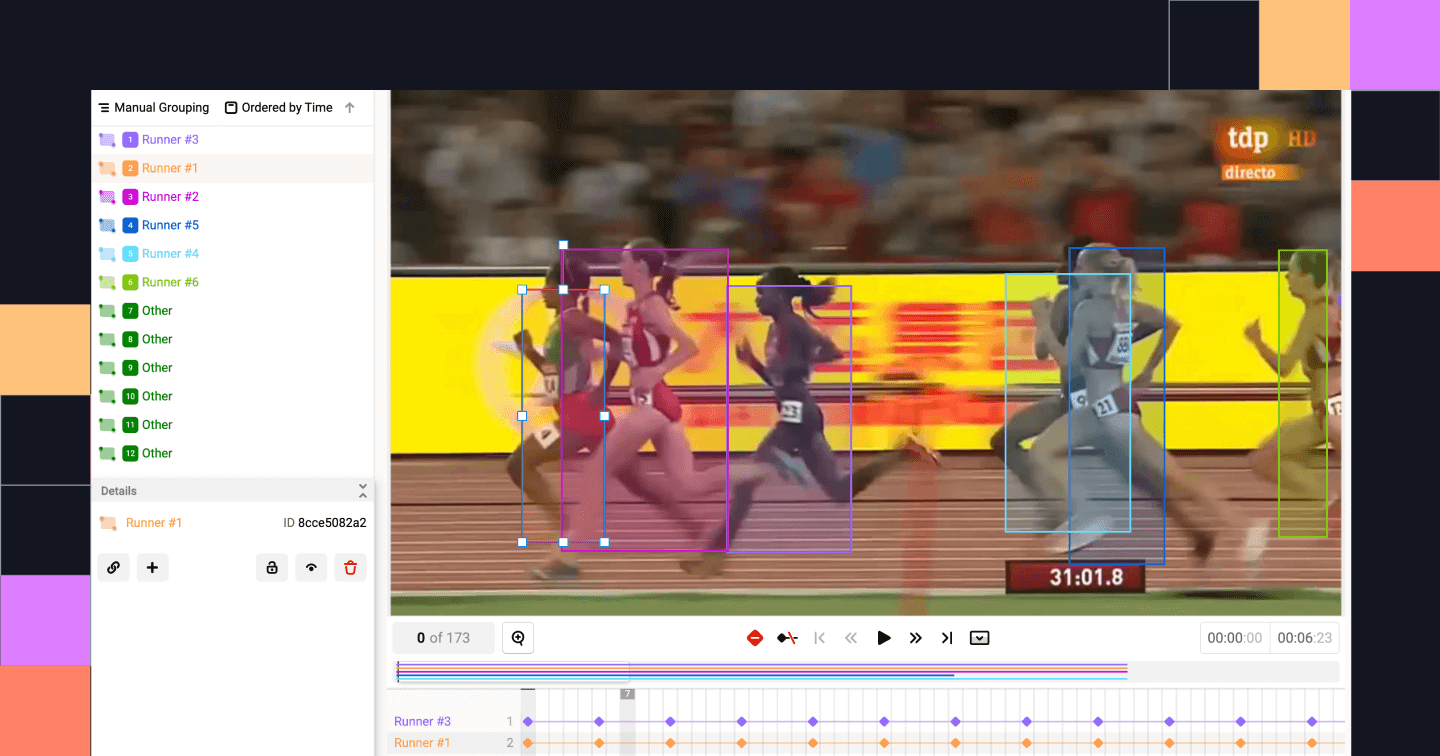
Object tracking. Source: Label Studio
Object tracking involves continuously labeling objects across multiple frames to track their movement. In autonomous driving scenarios, for example, one may use object tracking to follow a vehicle through a busy intersection.
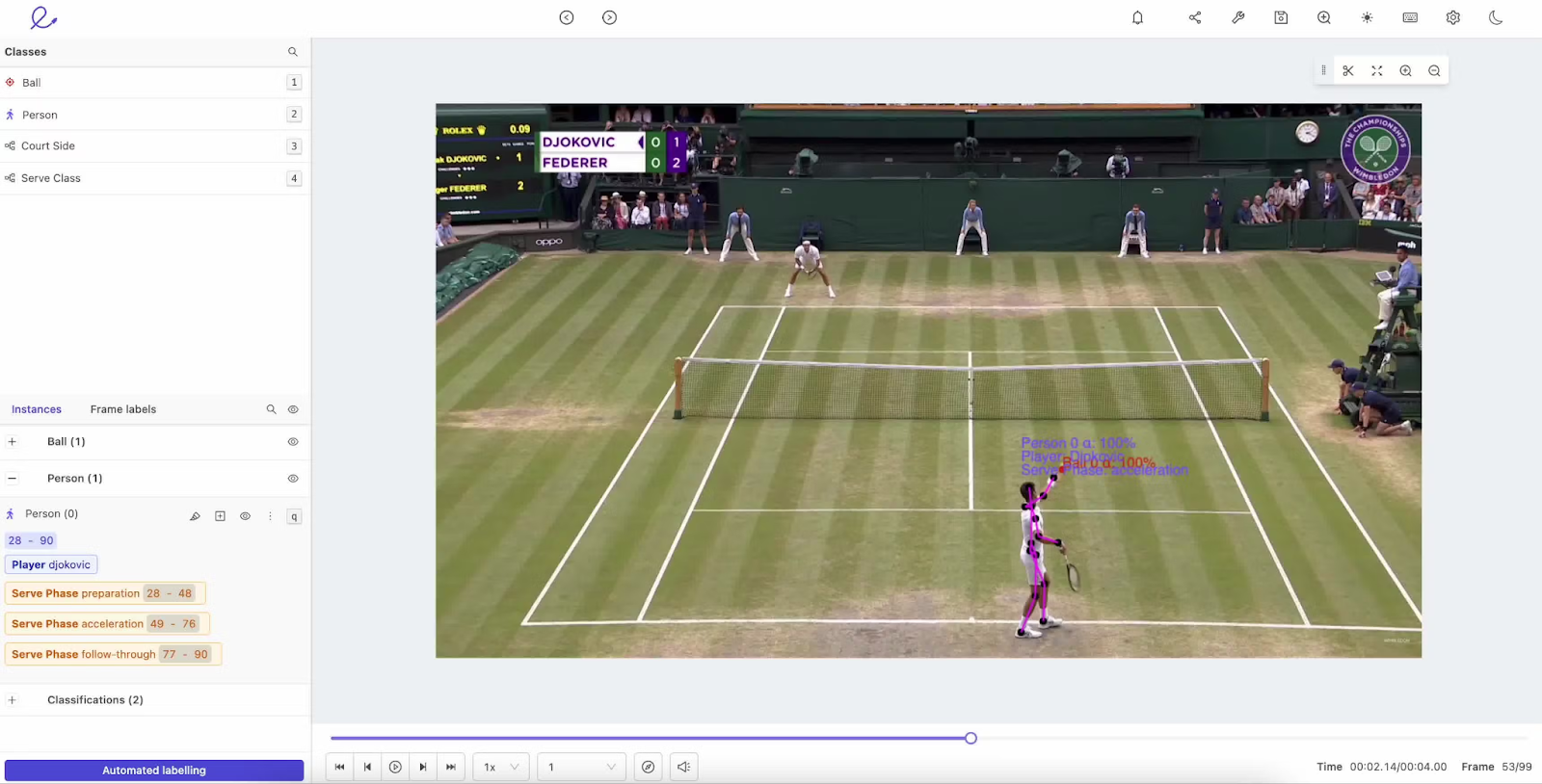
Activity labeling. Source: Encord
This is when labels are assigned to specific actions, like someone walking, running, or sitting down in a video. This helps models understand human behavior in applications like security monitoring or sports analytics.
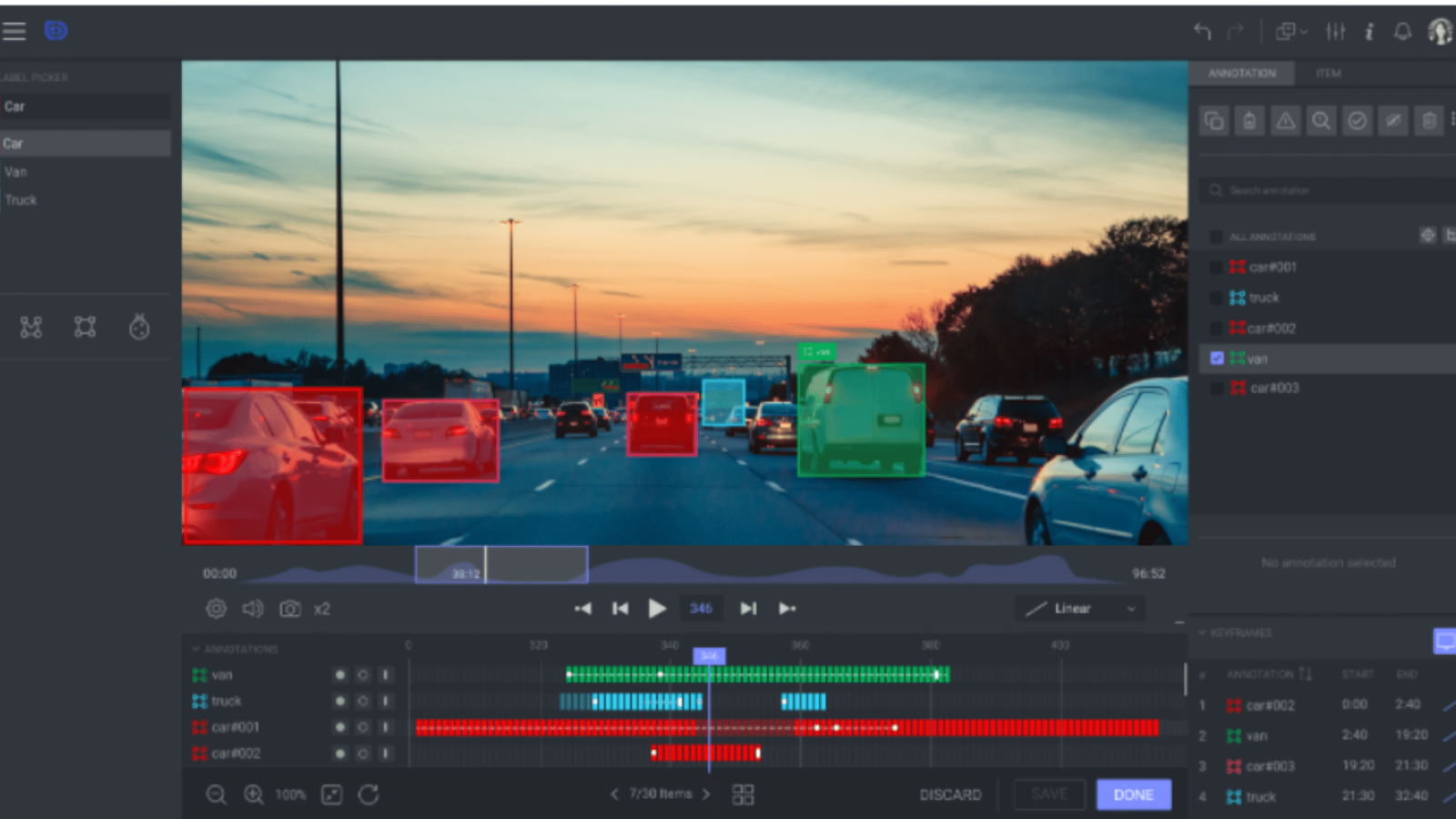
Frame-by-frame annotation. Source: dataloop
When each individual frame of a video is labeled to capture minute details, it’s called frame-by-frame detection. This is often used for tasks that require high precision, such as analyzing body movements in physical therapy.
The method used to annotate data can vary depending on several factors, such as:
In other words, some tasks require the accuracy of human annotators, while others can benefit from automation to save time and scale the process. Below, we'll explore the various approaches to give you a better insight into what situation each should be used in.
Manual annotation is when human annotators label data by hand. In this approach, trained annotators carefully review each piece of data and apply the necessary labels or tags.
The biggest advantage of manual annotation is accuracy. Since humans can understand context, nuance, and complex patterns better than machines, they can ensure the data is labeled precisely. This level of accuracy is especially important for projects that require high-quality, detailed annotations, such as medical image labeling or complex natural language tasks.
However, manual annotation also comes with significant challenges:
Despite these challenges, manual annotation remains essential for projects where precision is critical, even though businesses often look for ways to balance quality with time and cost efficiency.
Semi-automated annotation combines human expertise with machine learning assistance. In this approach, a machine learning model helps human annotators by pre-labeling the data or offering suggestions. The human annotators then review and refine the labels to ensure accuracy.
The benefit of semi-automated annotation is that it speeds up the process while still retaining a high level of accuracy. The machine can handle repetitive or simple tasks, which allows the human annotators to focus on more complex or ambiguous data points. This approach is ideal for large projects where full manual annotation would be too slow or expensive because it strikes a balance between time efficiency and quality control.
However, it faces certain challenges:
Semi-automated annotation works best for projects that need to balance quality with speed, where the data is complex enough to benefit from human review but large enough to require machine assistance.
Automated annotation uses machine learning algorithms to label data without human involvement. In this approach, pre-trained models or AI-driven tools automatically annotate large datasets. This makes the process faster and more scalable than manual or semi-automated methods.
The main advantage of automated annotation is its efficiency. It can process vast amounts of data in a fraction of the time it would take a human annotator. As a result, automated annotation is an ideal solution for projects with huge datasets, like tagging millions of images for a computer vision model or transcribing large volumes of audio for speech recognition.
But the drawbacks of relying on machines are as follows:
Automated annotation is best suited for projects that require speed and scalability but where a certain margin of error is acceptable or when human review can be used later to refine the results.
Crowdsourcing involves distributing data labeling tasks to a large number of contributors using platforms like Amazon Mechanical Turk or Appen. This method enables businesses to quickly and cost-effectively annotate large datasets by tapping into a global pool of workers.
One of the main advantages of crowdsourcing is scalability. Distributing tasks to many contributors enables companies to handle large volumes of data efficiently. For instance, a project requiring thousands of labeled images or transcriptions can be completed in days rather than weeks or months.
The downsides of this approach are as follows:
Crowdsourcing is ideal for large-scale projects that require fast and cost-effective annotation. However, maintaining high-quality results requires strong oversight and task management.
There are a wide range of tools available for data annotation. These tools range from open-source platforms to comprehensive commercial solutions that are each designed to meet different project needs.
For example, open-source tools are often customizable and free to use. This makes them them ideal for smaller projects or teams with technical expertise. On the other hand, commercial options provide more advanced features, including automation, collaboration tools, and quality control, which makes them better suited for large-scale projects or enterprises looking for a streamlined workflow.
In this section, we'll explore some of the most popular tools available for data annotation and how they can help with different types of data:
Source: Labelbox Docs
Labelbox is a widely used commercial platform designed to streamline the data annotation process, focusing on collaboration and quality control. It was founded in 2018 by Manu Sharma, Brian Rieger, and Peter Welinder, whose mission is “to build the best products to align with artificial intelligence.”
The Labelbox platform provides an intuitive interface where teams can collaborate to annotate data, track progress, and maintain high annotation standards. It also supports a variety of data types (e.g., images, video, and text), which makes the platform extremely versatile for different machine learning projects.
One of its key features is its built-in quality control mechanisms, which enable teams to review and approve annotations—this ensures consistent and accurate results.
Labelbox is ideal for organizations looking to scale up their annotation efforts with integrated project management and automation features.
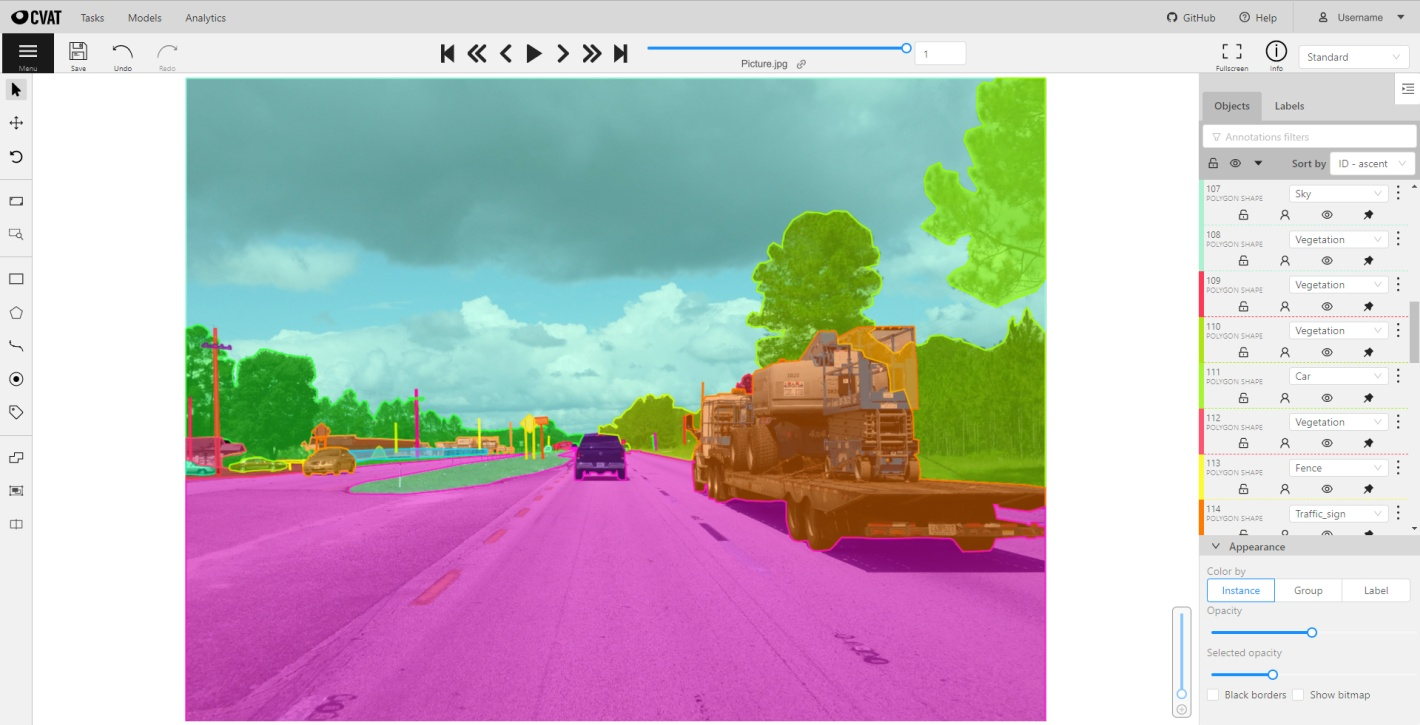
Source: CVAT Wikipedia page
CVAT is an open-source tool specifically designed to annotate image and video datasets. Developed by Intel, CVAT is highly customizable and offers a wide range of annotation techniques (e.g., bounding boxes, polygons, and keypoint annotations). Its flexibility makes it suitable for projects ranging from object detection to facial recognition.
Because it’s open-source, CVAT is free to use and can be tailored to meet specific project needs. This makes it a popular choice for researchers and smaller teams that need powerful annotation tools without the cost of commercial software.
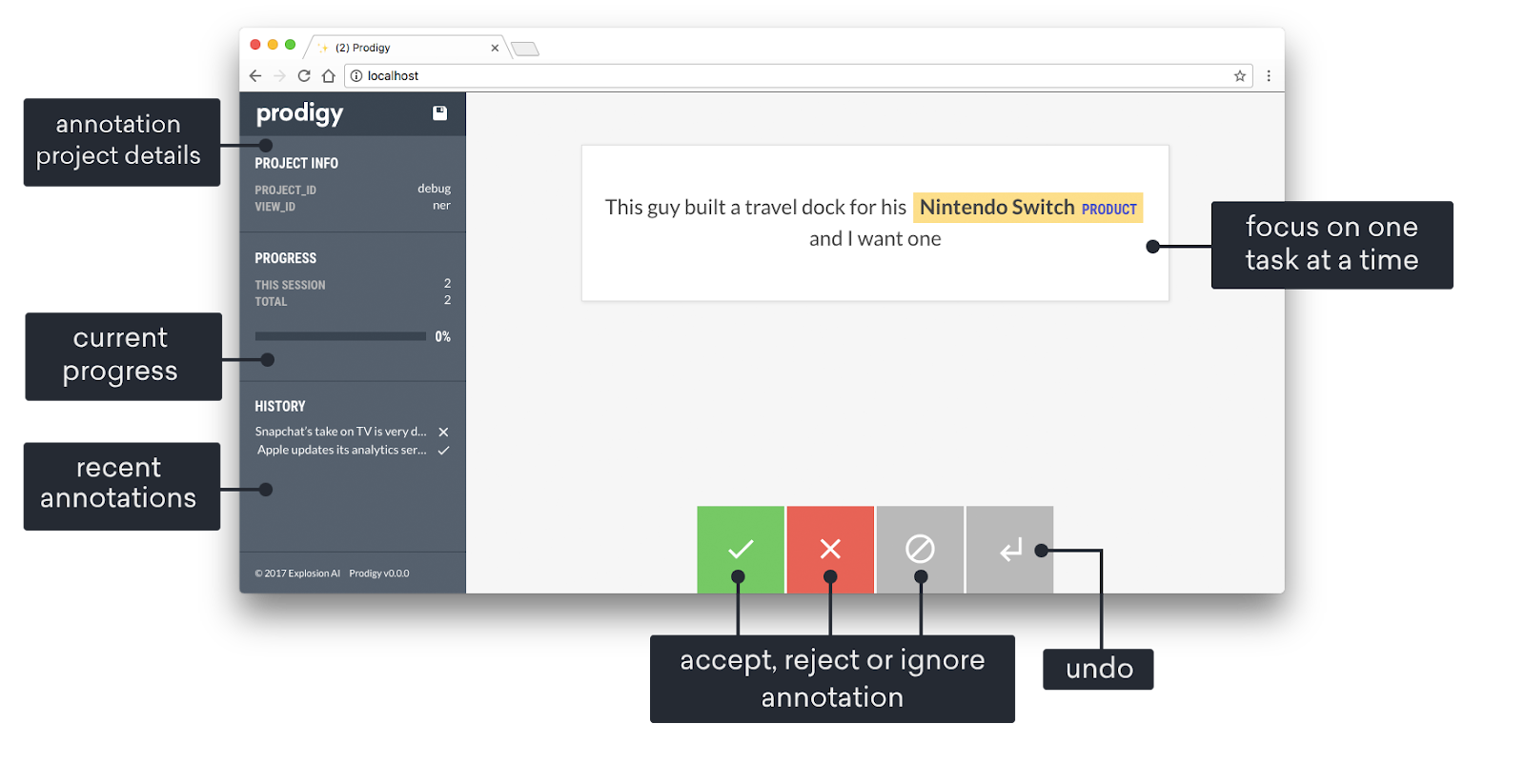
Source: Prodigy Docs
Prodigy is an advanced annotation tool developed by Explosion AI that uses active learning to improve efficiency, particularly in natural language processing (NLP) tasks. With Prodigy, a machine learning model assists annotators by suggesting labels based on their predictions, which are then confirmed or corrected by human reviewers.
This interactive approach speeds up the annotation process while simultaneously ensuring the labeled data is of high quality. Despite being a commercial tool, Prodigy is highly customizable; for example, it allows users to create their own annotation workflows. These factors make Prodigy highly suitable for teams working on specialized NLP projects like sentiment analysis, entity recognition, or text classification.
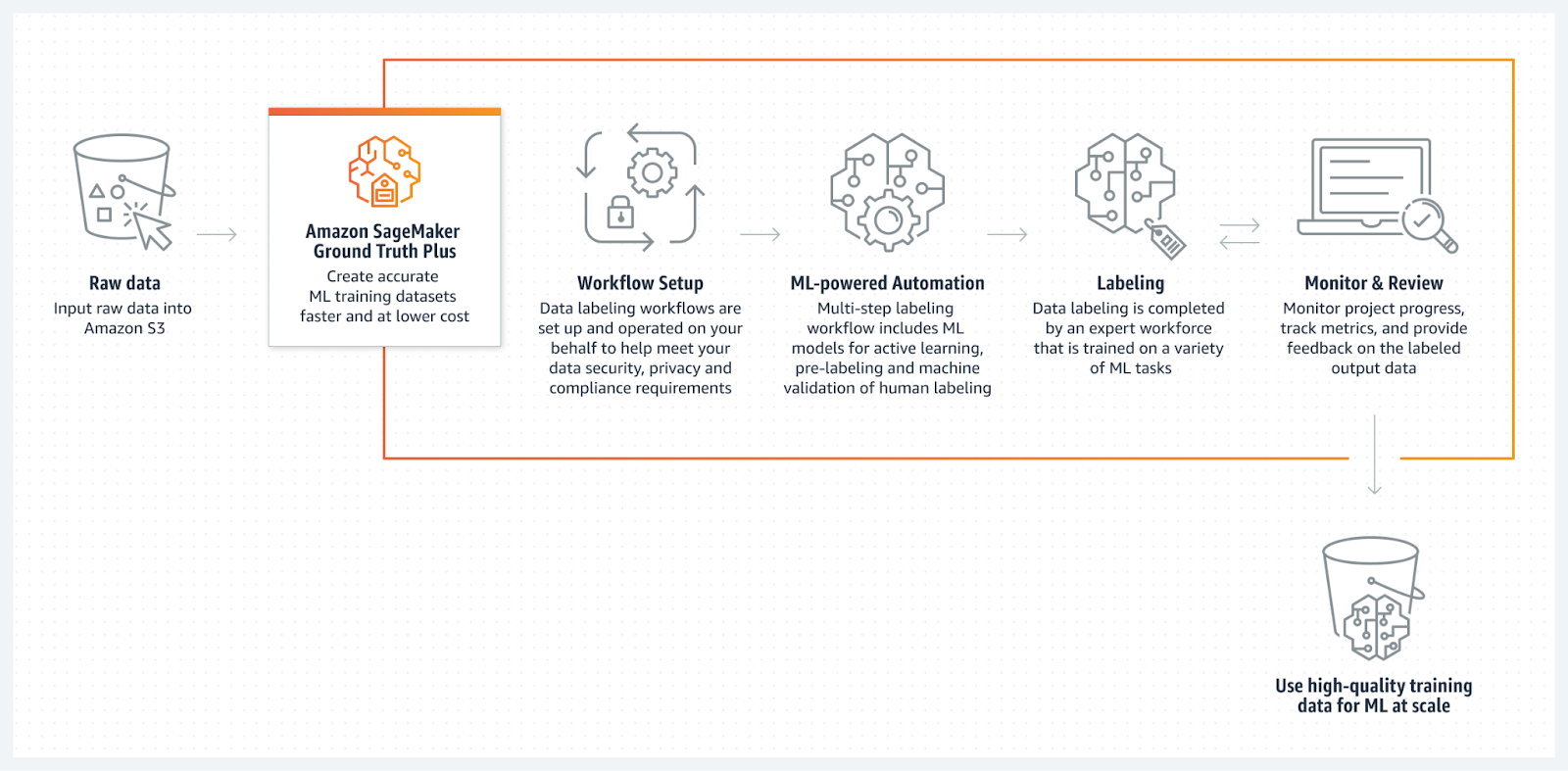
Source: Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth is a fully managed data labeling service that integrates seamlessly with AWS. It provides tools for manual and automated data annotation that allow users to label data quickly and accurately.
SageMaker Ground Truth uses machine learning to assist human annotators by pre-labeling data, which speeds up the process and reduces costs. The service is also an extremely versatile option for different machine learning tasks as it supports a wide variety of data types, including images, text, and videos.
Additionally, it’s built to scale, which means it’s a strong option for enterprises that require large-scale annotation capabilities within the AWS ecosystem.
Effective data annotation is critical to the success of machine learning models, as the quality of labeled data directly impacts the accuracy of predictions and classifications. Following best practices can help ensure that the annotation process is both efficient and reliable.
In this section, we’ll explore essential practices that can enhance the quality and consistency of data annotation while also addressing challenges one may face in the labeling process.
One of the most important steps in the data annotation process is creating clear, well-defined guidelines. These guidelines should specify exactly how data should be labeled and what criteria annotators should follow for consistency.
Clear guidelines help to:
Having standardized rules in place is particularly crucial for complex or subjective data, such as images or text with multiple possible interpretations.
Quality is necessary to maintain the accuracy and reliability of annotated data. Thus, annotated data must be periodically reviewed to ensure it meets the required standards. This process may be conducted through random audits, using multiple annotators for the same tasks (to compare results), or cross-checking annotations, depending on the project.
The main gist is that it is vital to implement a robust quality assurance process to help you catch errors early, reduce bias in your data, and ensure the labeled data is suitable for training high-performing machine learning models.
Active learning is a machine learning technique that allows an algorithm to select the most informative data samples for labeling, which improves the model's performance. This technique can significantly improve the efficiency of the annotation process. It allows annotators to focus their time and energy on the most challenging and valuable data points, while the machine learning algorithm suggests the rest.
This approach reduces the time spent on labeling easy or repetitive samples, and accelerates the overall annotation process. Thus, it increases the odds the machine learning model being used to make predictions is trained on the most critical examples.
To ensure that the annotation process is carried out accurately, annotators should receive proper training. Training helps annotators understand the specific requirements of the task and how to apply the annotation guidelines correctly.
Well-trained annotators are more likely to produce high-quality labeled data, which ultimately improves the performance of the machine learning models they are supporting. Regular training sessions and feedback loops can also help refine annotator skills over time, further enhancing the data annotation process.
While data annotation is essential for training accurate machine learning models, the process comes with its own set of challenges. In this section, we will discuss some of the most common challenges in data annotation.
Manual data annotation is often labor-intensive. A significant amount of time and financial resources is required to annotate all instances, especially when the dataset is large. The more complex the data (such as video or intricate images), the more time-consuming the annotation process becomes. Skilled annotators must be hired, which increases the costs.
To overcome this challenge, organizations can use semi-automated annotation tools, where machine learning models suggest labels and humans verify them. This speeds up the process without sacrificing accuracy.
Active learning can also help by focusing human effort on the most informative data, which reduces the total amount of data to be manually labeled. Additionally, using crowdsourcing platforms like Amazon Mechanical Turk allows multiple contributors to work simultaneously, which means large-scale annotation can be more affordable and efficient.
Another key challenge is dealing with subjectivity and bias in the annotation process. Different annotators may interpret the same data in varying ways. This is extremely common for tasks like labeling emotions in text or identifying objects in complex images. The problem with this is that subjectivity can introduce bias into the labeled data, which in turn can lead to biased model predictions.
To reduce subjectivity and bias, organizations should create clear, detailed annotation guidelines that ensure all annotators follow the same criteria. Another solution is to use multiple annotators for the same data, which allows cross-checking and helps identify and correct biased or inconsistent annotations.
Annotations that reveal identifying information can violate privacy regulations that protect personal data. This challenge is particularly significant when outsourcing annotation tasks or using crowdsourcing platforms, where many contributors have access to the data.
Solutions such as anonymization (removing personally identifiable information) and using secure, encrypted platforms for annotation can help mitigate these risks.
In this section, we'll explore the real-world applications of data annotation. Let’s get into it!
In autonomous vehicles, data annotation is the foundation for teaching AI to safely navigate the real world. Self-driving cars rely on annotated data to identify objects.
For example, annotators label images or video frames by drawing bounding boxes around cars or marking road boundaries for lane detection. These annotations help the AI learn how to recognize and react to various road scenarios, such as stopping for pedestrians or staying in the correct lane.
AI models require labeled medical images to learn how to detect abnormalities. For example, skilled annotators would outline specific areas on images to mark regions that show early signs of cancer. This enables AI to quickly and accurately detect cancer earlier than traditional methods, which improves patient outcomes and reduces the workload for medical professionals.
For customer service chatbots, text annotation is critical for teaching AI how to understand human language.
For example, annotators may label text to help chatbots recognize user intent. The chatbots would then analyze the labeled interactions to help them learn how to provide the appropriate responses. This enables organizations to offer quicker and more accurate assistance and improve the customer experience.
In sentiment analysis, text annotation is used to gauge how customers feel about certain things (e.g., the brand, products, or events). The way this works is that annotators would tag phrases or sentences as positive, negative, or neutral, and then this data is passed to AI to learn the underlying sentiment. A company may then deploy this to monitor how customers are receiving a new product launch.
Data annotation is the process of labeling data to make it recognizable and usable for machine learning models. It is a critical step in developing AI systems that can accurately interpret and respond to real-world data. Why? Because the quality and accuracy of annotated data directly impact the performance and effectiveness of AI models.
Ultimately, data annotation serves as the foundation for building intelligent, reliable AI systems that can drive innovation across various industries. This makes it an indispensable part of machine learning development.
To continue your learning, check out the following resources:
Learn more about machine learning and AI with these courses!
Course
Course
Course
blog
Abid Ali Awan
6 min
blog
Javier Canales Luna
10 min
blog
Alena Guzharina
6 min
blog
Javeria Rahim
7 min
blog
Austin Chia
Tutorial
Kurtis Pykes