
Kurs
Machine Learning verstehen
2 Std.
293.4K
Stell dir vor, du entwickelst ein selbstfahrendes Auto. Damit das Auto die Straße „sehen“ und verstehen kann, muss es lernen, Sachen wie Fußgänger, Verkehrszeichen und andere Fahrzeuge zu erkennen. Damit das klappt,braucht das maschinelleLernsystem von carTausende, wenn nicht Millionen Bilder aus echten Fahrsituationen.
Aber das Auto kann nicht von selbst verstehen, was auf den Bildern zu sehen ist. Es weiß nicht, dass ein rotes Achteck ein Stoppschild ist oder dass jemand auf dem Gehweg läuft. Hier kommt die Datenannotation ins Spiel.
Datenannotation ist der Vorgang, bei dem Rohdaten beschriftet werden, damit sie für Modelle des maschinellen Lernens verständlich und nutzbar werden. Wir werden das später genauer erklären, aber behalte das bitte im Hinterkopf.
Das werden wir in diesem Artikel anschauen:
Lass uns loslegen!
Am besten kann man sich Datenannotation vorstellen, wenn man daran denkt, wie man Kindern verschiedene Tiere beibringt. Zuerst zeigst du ihnen auf ein Bild von einem Hund und sagst: „Das ist ein Hund.“ Dann zeigst du ihnen eine Katze und sagst: „Das ist eine Katze.“ Mit der Zeit lernt das Kind, Tiere selbstständig zu erkennen, indem man ihm beschriftete Beispiele zeigt. Datenannotation funktioniert bei Maschinen ähnlich.
Genauso wie ein Kind beschriftete Beispiele braucht (Anmerkung: „Das ist ein Hund“ ist die Beschriftung), brauchen Modelle für maschinelles Lernen Daten, die mit Anmerkungen versehen sind, um daraus lernen zu können. Also, Datenannotation ist das Beschriften oder Markieren von Daten wie Bildern, Texten oder Audiodateien, damit Algorithmen für maschinelles Lernen sie erkennen und verstehen können.
Die Labels zeigen dem System, welche Muster es suchen soll. Wenn du zum Beispiel Tausende von Bildern mit den Labels „Hund“ oder „Katze“ versiehst, lernt das Modell, die Unterschiede zwischen den beiden zu erkennen.
Sobald das Modell aus diesen Beispielen gelernt hat, kann es Vorhersagen treffen oder neue Daten ohne Beschriftungklassifizieren, so wie das Kind irgendwann Tiere ohne deine Hilfe erkennt.
Verschiedene Datentypen brauchen spezielle Annotationsmethoden, damit sie für Machine-Learning-Aufgaben vorbereitet werden können. Je nachdem, um was für Daten es geht, gibt's verschiedene Wege, sie zu kennzeichnen und zu taggen. Wenn man diese Typen versteht, kann man besser entscheiden, wie man Modelle für verschiedene Anwendungen am besten trainiert.
Schauen wir uns mal die gängigsten Arten von Datenannotationen an:
Bei der Bildbeschriftung werden Bilder so versehen, dass Modelle für maschinelles Lernen die Objekte darin erkennen und verstehen können. Je nachdem, wie detailliert die Bildbeschriftung sein soll, gibt's verschiedene Techniken:

Begrenzungsrahmen. Sauer-: Analytik
Bei dieser Methode werden Rechtecke um Objekte in einem Bild gezeichnet, damit das Modell sie besser erkennen und ihre Position bestimmen kann. Begrenzungsrahmen werden oft benutzt, um Autos, Fußgänger oder Schilder in der selbstfahrenden Technologie zu erkennen.

Semantische Segmentierung. Quelle: Einführung in die semantische Bildsegmentierung
Hier wird jedes Pixel in einem Bild markiert, um bestimmte Bereiche bestimmten Objekten oder Kategorien zuzuordnen, z. B. Straßen, Gebäude oder Bäume. Mit dieser Technik kann das Modell die Szene besser verstehen.

Anmerkung zu einem Orientierungspunkt. Sauer-: Analytik
Bei dieser Technik markiert man bestimmte Punkte in einem Bild, zum Beispiel Gesichtszüge oder wichtige Punkte der Körperhaltung. Es wird zum Beispiel für Gesichtserkennung und die Schätzung von Körperhaltungen verwendet.
Textannotation ist das Beschriften und Markieren von Textdaten, damit sie von Modellen für die natürliche Sprachverarbeitung (NLP) verstanden werden können . Es lässt Maschinen menschliche Sprache verstehen, verarbeiten und analysieren.
Es gibt ein paar gängige Techniken für Textanmerkungen:

Entitätserkennung. Quelle: Erkennung und Klassifizierung benannter Entitäten mit Scikit-Learn
Dabei werden bestimmte Sachen im Text rausgesucht, wie zum Beispiel Namen von Leuten, Orten oder Organisationen. In dem Satz „Apple hat einen neuen Laden in New York eröffnet“ würde das Modell „Apple“ als Firma und „New York“ als Ort erkennen.

Stimmungsmarkierung. Quelle: Den Prozess der Textannotation für die Analyse der Kundenstimmung verstehen
Diese Technik ordnet Emotionen oder Meinungen zu Textstellen zu und kennzeichnet sie als positiv, negativ oder neutral. Es wird oft in Kundenbewertungen oder beim Social-Media-Monitoring verwendet, um zu verstehen, wie Nutzer über ein Produkt oder eine Dienstleistung denken.
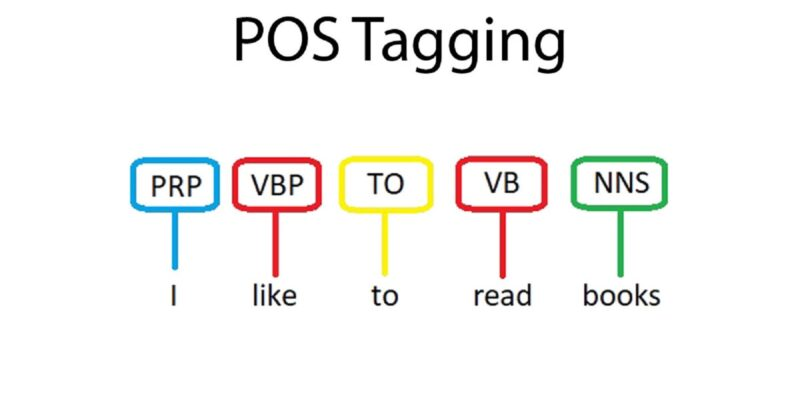
POS-Kennzeichnung. Quelle: POS-Tagging in der NLP
Diese Methode kennzeichnet jedes Wort in einem Satz mit seiner grammatikalischen Funktion (z. B. Substantiv, Verb, Adjektiv) und hilft Modellen dabei, die Sprachstruktur für Aufgaben wie Übersetzung oder Spracherkennung zu verstehen.
Bei Audio-Annotation werden Audiodateien beschriftet, um Modelle für Spracherkennung, Musikerkennung oder Geräuschklassifizierung zu trainieren.
Ein paar gängige Techniken für Audio-Anmerkungen sind:
Das Umwandeln von gesprochenen Wörtern in einer Audiodatei in geschriebenen Text wird oftin Sprach-zu-Text-Anwendungenverwendet.
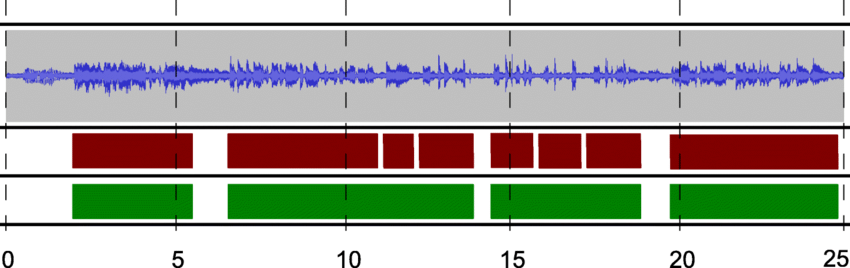
Segmentierung von Sprache. Sauer-: Forschungstor
Dabei wird eine Audiodatei in verschiedene Abschnitte aufgeteilt. Du möchtest vielleicht Dialoge von Hintergrundgeräuschen trennen oder einzelne Sprecher in einem Gespräch erkennen.
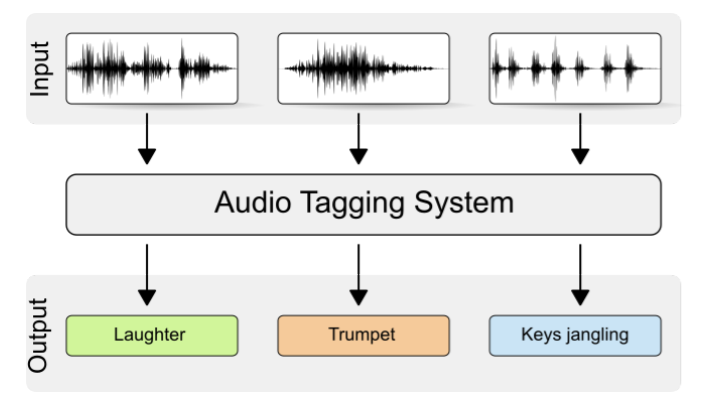
Sound-Tagging. Also,Quelle: Freesound-Tagging von VGGish mit KNN
Sound-Tagging ist, wenn bestimmte Geräusche (z. B. Verkehrslärm, Tiergeräusche usw.) in einer Audiodatei markiert werden.
Bei der Videoannotation werden Objekte oder Aktionen in Videobildern markiert und mit Tags versehen, damit Modelle für maschinelles Lernen Bewegungen und Aktivitäten besser verstehen können.
Wichtige Techniken für Videoanmerkungen sind:
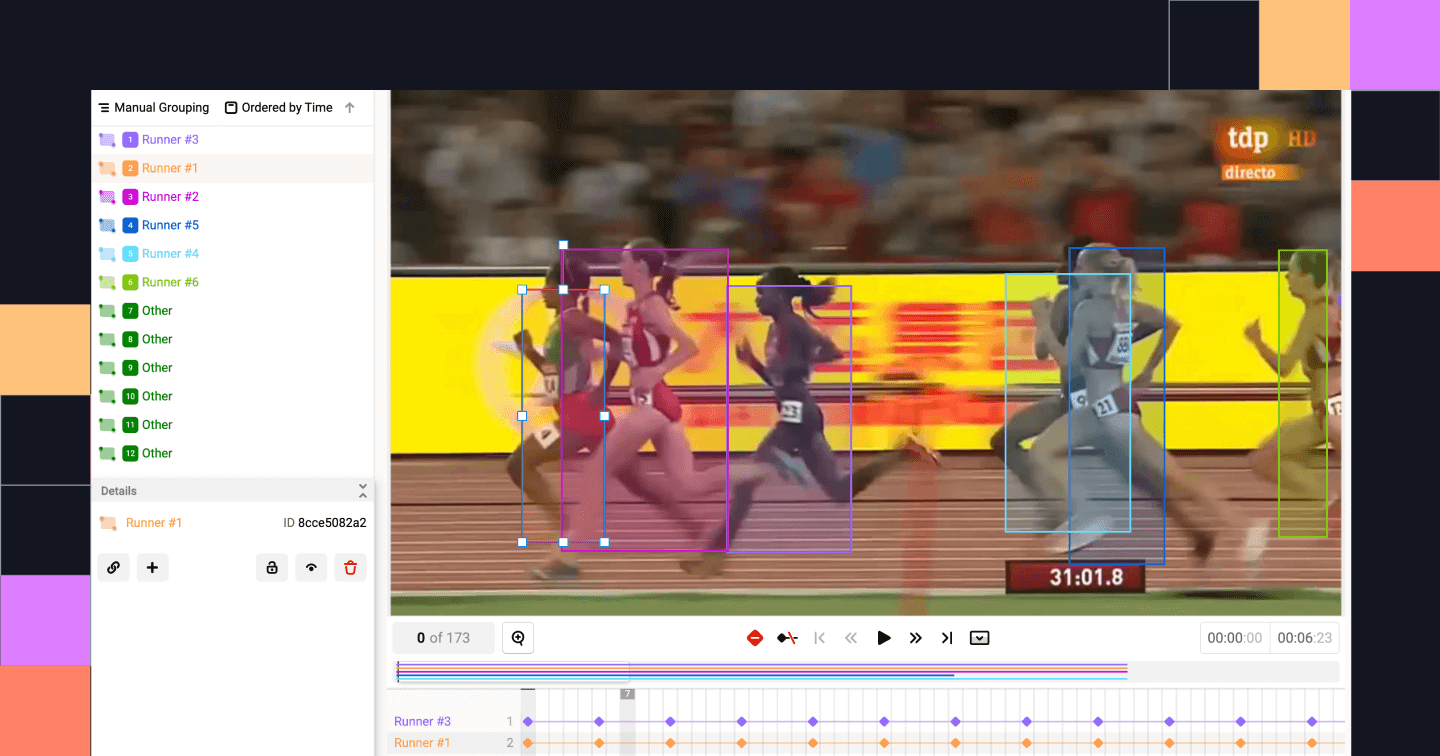
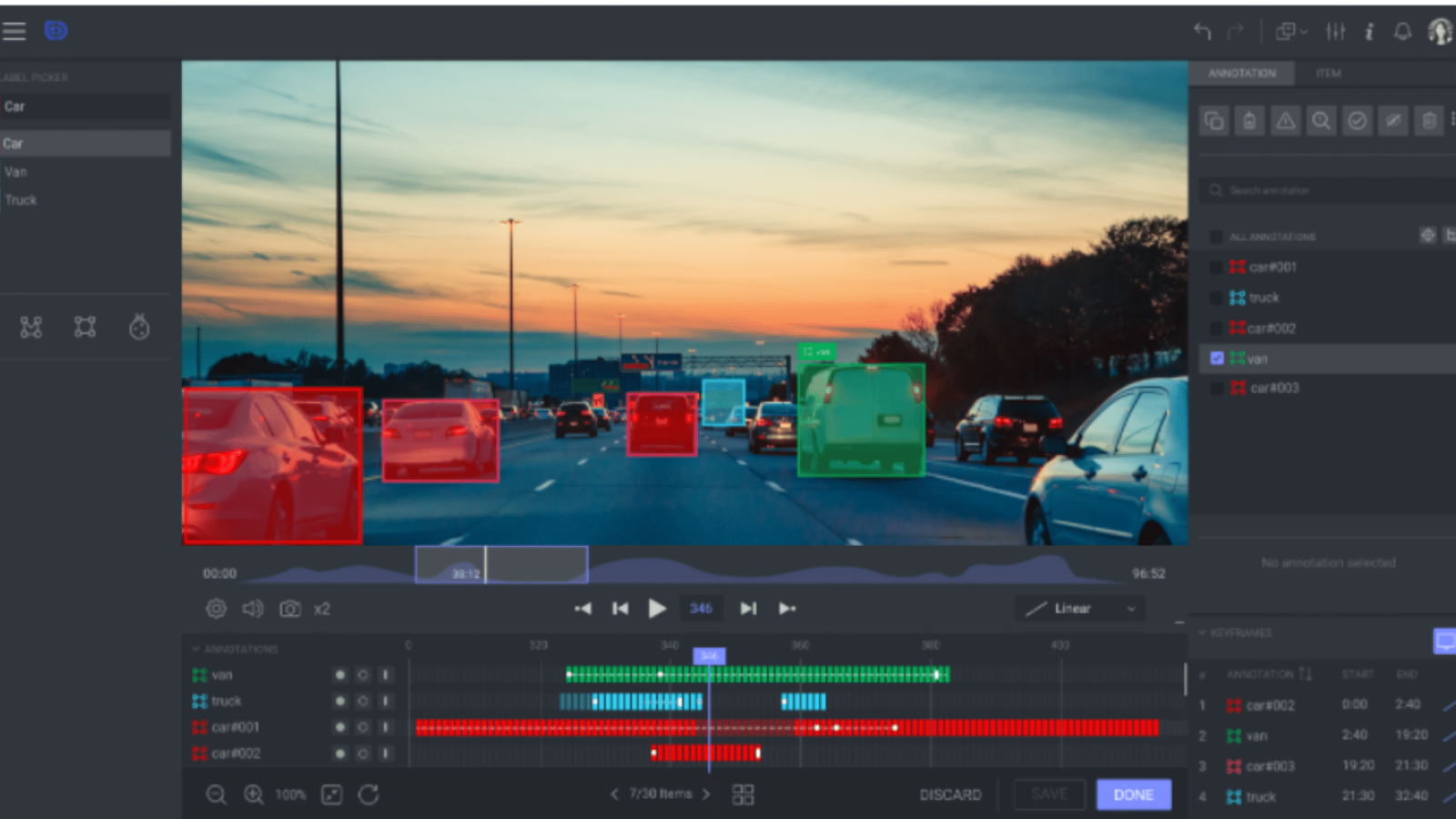
Objektverfolgung. Quelle: Label Studio
Beim Objekt-Tracking werden Objekte über mehrere Frames hinweg ständig markiert, um ihre Bewegung zu verfolgen. In Szenarien mit autonomem Fahren kann man zum Beispiel die Objektverfolgung nutzen, um ein Auto durch eine belebte Kreuzung zu verfolgen.
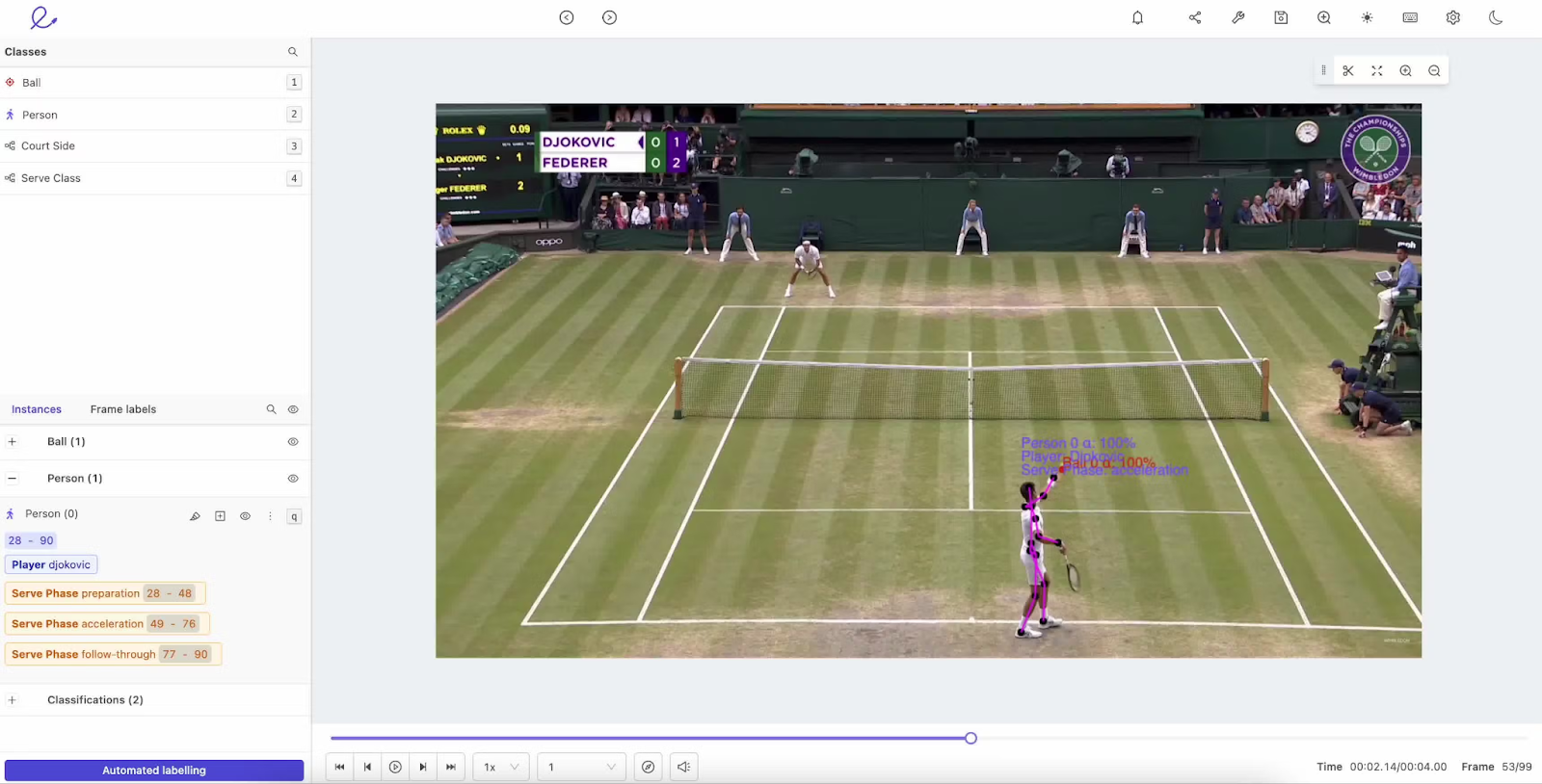
Aktivitätsbeschriftung. Quelle: Encord
Hier werden bestimmten Aktionen, wie z. B. jemandem, der in einem Video geht, rennt oder sich hinsetzt, Labels zugewiesen. Das hilft Modellen, menschliches Verhalten in Anwendungen wie Sicherheitsüberwachung oder Sportanalysen besser zu verstehen.
Anmerkung zu jedem einzelnen Bild. Quelle:Quelle: dataloop
Wenn jedes einzelne Bild eines Videos mit kleinen Details versehen wird, nennt man das Frame-für-Frame-Erkennung. Das wird oft für Aufgaben gebraucht, die echt präzise sein müssen, wie zum Beispiel die Analyse von Körperbewegungen in der Physiotherapie.
Die Methode, mit der Daten kommentiert werden, kann von verschiedenen Faktoren abhängen, zum Beispiel:
Mit anderen Worten: Manche Aufgaben brauchen die Genauigkeit von menschlichen Annotatoren, während andere von Automatisierung profitieren, um Zeit zu sparen und den Prozess zu skalieren. Im Folgenden schauen wir uns die verschiedenen Ansätze genauer an, damit du besser verstehst, wann du welche verwenden solltest.
Bei der manuellen Annotation beschriften Leute die Daten von Hand. Bei diesem Ansatz schauen geschulte Annotatoren sich jedes einzelne Datenelement genau an und versehen es mit den richtigen Labels oder Tags.
Der größte Vorteil der manuellen Annotation ist die Genauigkeit. Da Menschen Kontext, Nuancen und komplexe Muster besser verstehen als Maschinen, können sie dafür sorgen, dass die Daten richtig gekennzeichnet werden. Diese Genauigkeit ist besonders wichtig für Projekte, die hochwertige, detaillierte Anmerkungen brauchen, wie zum Beispiel die Beschriftung medizinischer Bilder oder komplexe Aufgaben in natürlicher Sprache.
Manuelle Annotation bringt aber auch einige Herausforderungen mit sich:
Trotz dieser Herausforderungen ist die manuelle Annotation immer noch super wichtig für Projekte, bei denen es auf Genauigkeit ankommt, auch wenn Unternehmen oft nach Möglichkeiten suchen, Qualität mit Zeit und Kosten in Einklang zu bringen.
Die halbautomatische Annotation verbindet menschliches Fachwissen mit maschineller Lernhilfe. Bei diesem Ansatz hilft ein maschinelles Lernmodell den menschlichen Annotatoren, indem es die Daten vorab beschriftet oder Vorschläge macht. Anschließend überprüfen und verfeinern menschliche Annotatoren die Beschriftungen, um die Genauigkeit sicherzustellen.
Der Vorteil der halbautomatischen Annotation ist, dass sie den Prozess beschleunigt und trotzdem eine hohe Genauigkeit gewährleistet. Die Maschine kann sich um die immer gleichen oder einfachen Aufgaben kümmern, sodass die menschlichen Annotatoren sich auf die komplizierteren oder unklaren Daten konzentrieren können. Dieser Ansatz ist super für große Projekte, bei denen eine komplette manuelle Annotation zu langsam oder zu teuer wäre, weil er einen guten Mittelweg zwischen Zeiteffizienz und Qualitätskontrolle findet.
Allerdings gibt's da ein paar Herausforderungen:
Halbautomatische Annotation eignet sich am besten für Projekte, bei denen Qualität und Geschwindigkeit wichtig sind, die Daten komplex genug sind, um von einer Überprüfung durch Menschen zu profitieren, aber auch so umfangreich, dass maschinelle Unterstützung nötig ist.
Bei der automatisierten Annotation werden Daten mithilfe von Algorithmen für maschinelles Lernen ohne menschliches Zutun beschriftet. Bei diesem Ansatz werden große Datensätze automatisch mit vorab trainierten Modellen oder KI-gesteuerten Tools kommentiert. Dadurch wird der Prozess schneller und besser skalierbar als mit manuellen oder halbautomatischen Methoden.
Der größte Vorteil der automatisierten Annotation ist, dass sie echt effizient ist. Es kann riesige Datenmengen in einem Bruchteil der Zeit verarbeiten, die ein menschlicher Annotator dafür brauchen würde. Deshalb ist automatisierte Annotation super für Projekte mit riesigen Datensätzen, wie zum Beispiel das Taggen von Millionen von Bildern für ein Computervisionsmodell oder das Transkribieren von vielen Audioaufnahmen für die Spracherkennung.
Aber es gibt auch Nachteile, wenn man sich auf Maschinen verlässt:
Automatisierte Annotation ist super für Projekte, bei denen es auf Schnelligkeit und Skalierbarkeit ankommt, aber ein gewisser Fehleranteil okay ist oder die Ergebnisse später von Menschen überprüft werden können.
Beim Crowdsourcing werden Aufgaben zur Datenbeschriftung über Plattformenwie Amazon Mechanical Turk oder Appenan viele Leute verteilt. Mit dieser Methode können Firmen große Datensätze schnell und günstig mit Anmerkungen versehen, indem sie auf einen weltweiten Pool von Mitarbeitern zugreifen.
Einer der größten Vorteile von Crowdsourcing ist, dass man es gut skalieren kann. Durch die Verteilung von Aufgaben an viele Leute können Firmen große Datenmengen effizient bearbeiten. Ein Projekt, das zum Beispiel Tausende von beschrifteten Bildern oder Transkriptionen braucht, kann in wenigen Tagen statt in Wochen oder Monaten erledigt werden.
Die Nachteile dieses Ansatzes sind:
Crowdsourcing ist super für große Projekte, bei denen man schnell und günstig Anmerkungen machen muss. Um aber immer gute Ergebnisse zu liefern, muss man die Arbeit gut im Blick behalten und die Aufgaben gut organisieren.
Für die Datenannotation gibt's jede Menge Tools. Diese Tools reichen von Open-Source-Plattformen bis hin zu umfassenden kommerziellen Lösungen, die alle auf unterschiedliche Projektanforderungen zugeschnitten sind.
Zum Beispiel sind Open-Source-Tools oft anpassbar und kostenlos. Das macht sie super für kleinere Projekte oder Teams mit technischem Know-how. Auf der anderen Seite bieten kommerzielle Optionen mehr Funktionen, wie Automatisierung, Tools für die Zusammenarbeit und Qualitätskontrolle, was sie besser für große Projekte oder Unternehmen macht, die einen optimierten Arbeitsablauf wollen.
In diesem Abschnitt schauen wir uns ein paar der beliebtesten Tools für die Datenannotation an und wie sie bei verschiedenen Datentypen helfen können:
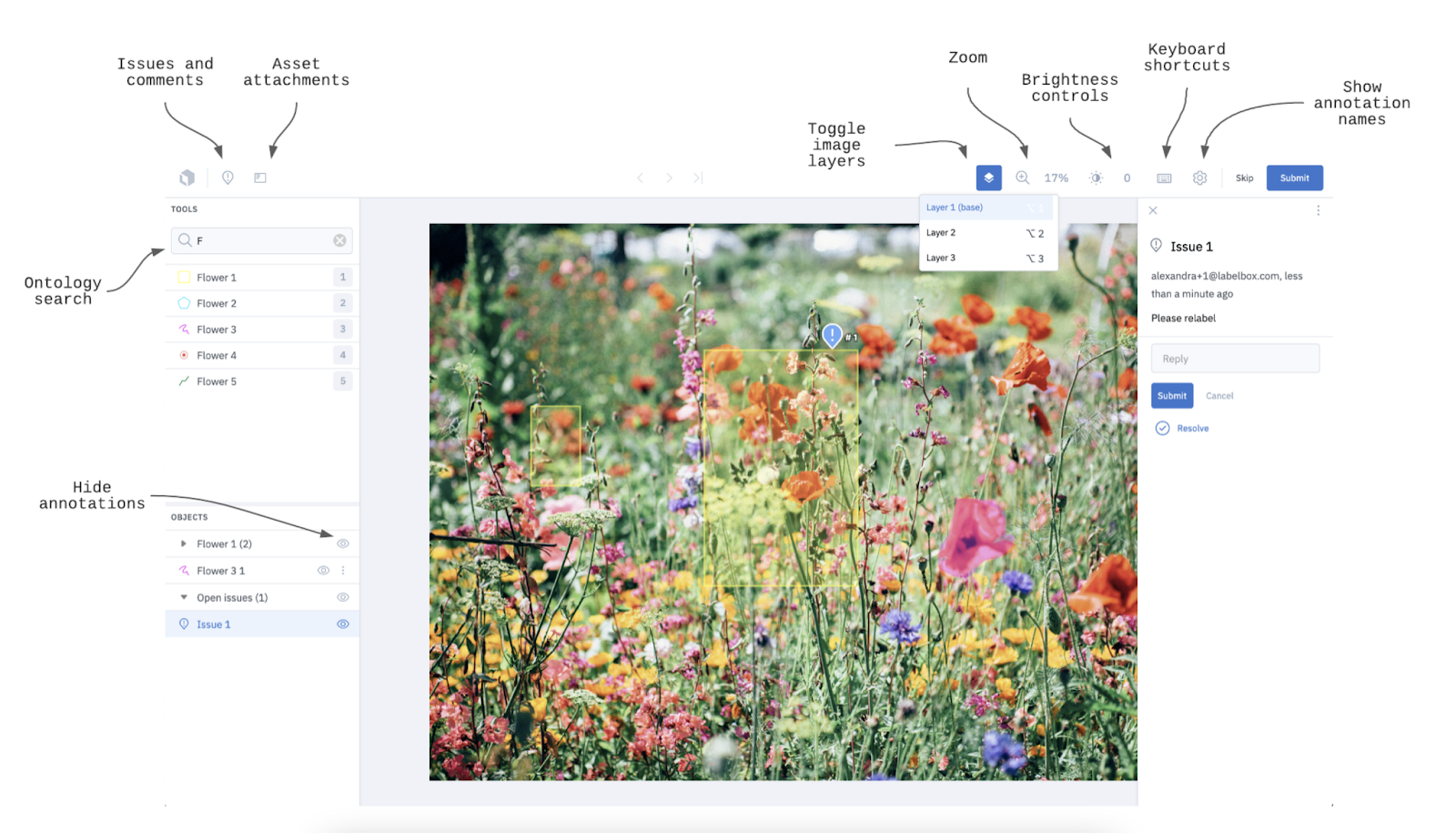
Quelle: Labelbox-Dokumente
Labelbox ist eine weit verbreitete kommerzielle Plattform für die Datenannotation ( ), die den Prozess der Datenannotation optimiert und dabei den Fokus auf Zusammenarbeit und Qualitätskontrolle legt. Das Unternehmen wurde 2018 von Manu Sharma, Brian Rieger und Peter Welinder gegründet. Ihr Ziel ist es,„, die besten Produkte für künstliche Intelligenz zu entwickeln“.
Die Labelbox-Plattform bietet eine intuitive Oberfläche, auf der Teams zusammenarbeiten können, um Daten zu kommentieren, den Fortschritt zu verfolgen und hohe Annotationsstandards einzuhalten. Außerdem kann es viele verschiedene Datentypen (z. B. Bilder, Videos und Text) verarbeiten, was die Plattform super vielseitig für verschiedene Machine-Learning-Projekte macht.
Eines der besten Features sind die eingebauten Qualitätskontrollen, mit denen Teams Anmerkungen checken und genehmigen können – so bleiben die Ergebnisse immer konsistent und genau.
Labelbox ist perfekt für Unternehmen, die ihre Annotationsarbeit mit integrierten Projektmanagement- und Automatisierungsfunktionen ausbauen wollen.
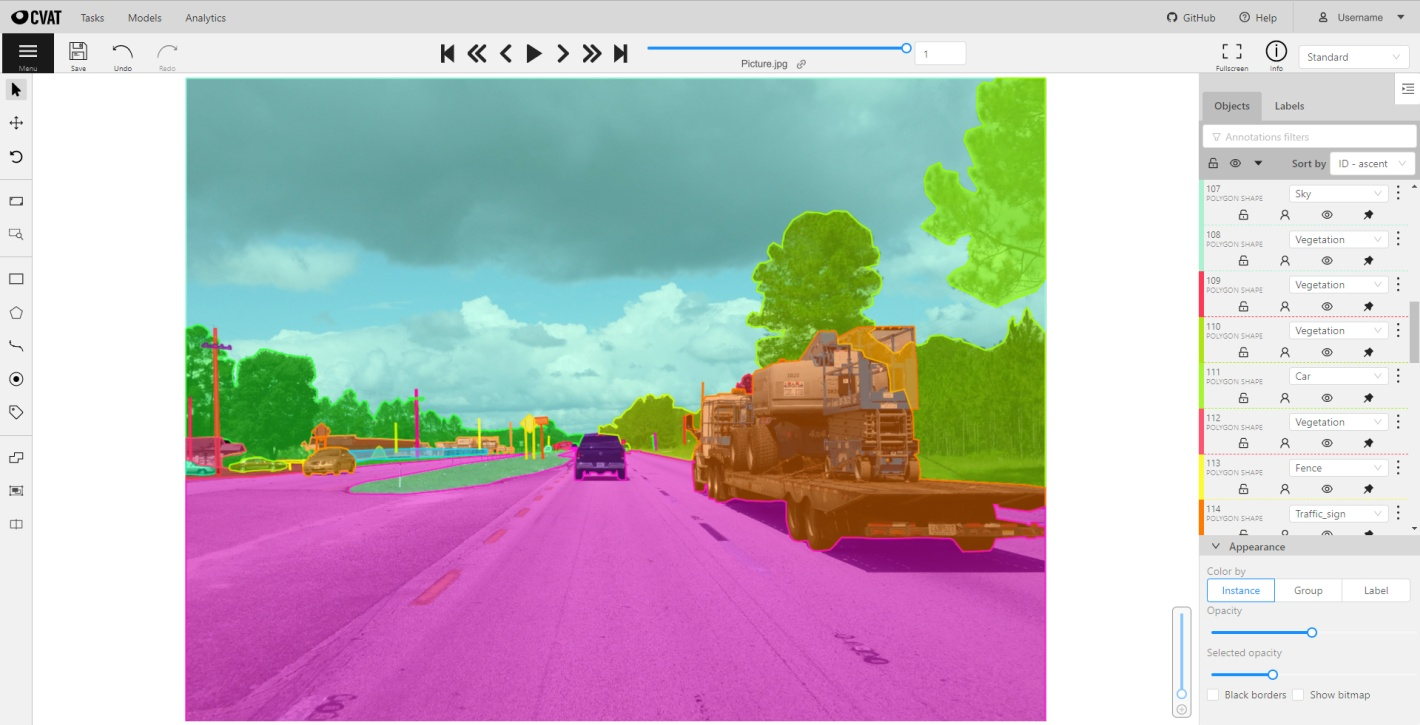
Quelle: CVAT-Seite auf Wikipedia
CVAT ist ein Open-Source-Tool namens „ ”, das speziell dafür gemacht ist, Bild- und Videodatensätze mit Anmerkungen zu versehen. CVAT wurde von Intel entwickelt, lässt sich super anpassen und bietet viele verschiedene Anmerkungstechniken (z. B. Begrenzungsrahmen, Polygone und Anmerkungen zu wichtigen Punkten). Dank seiner Flexibilität eignet es sich für Projekte von der Objekterkennung bis hin zur Gesichtserkennung.
Da CVAT Open Source ist, kannst du es kostenlos nutzen und an die speziellen Anforderungen deines Projekts anpassen. Das macht es zu einer beliebten Wahl für Forscher und kleinere Teams, die leistungsstarke Annotationswerkzeuge brauchen, ohne viel Geld für kommerzielle Software ausgeben zu wollen.
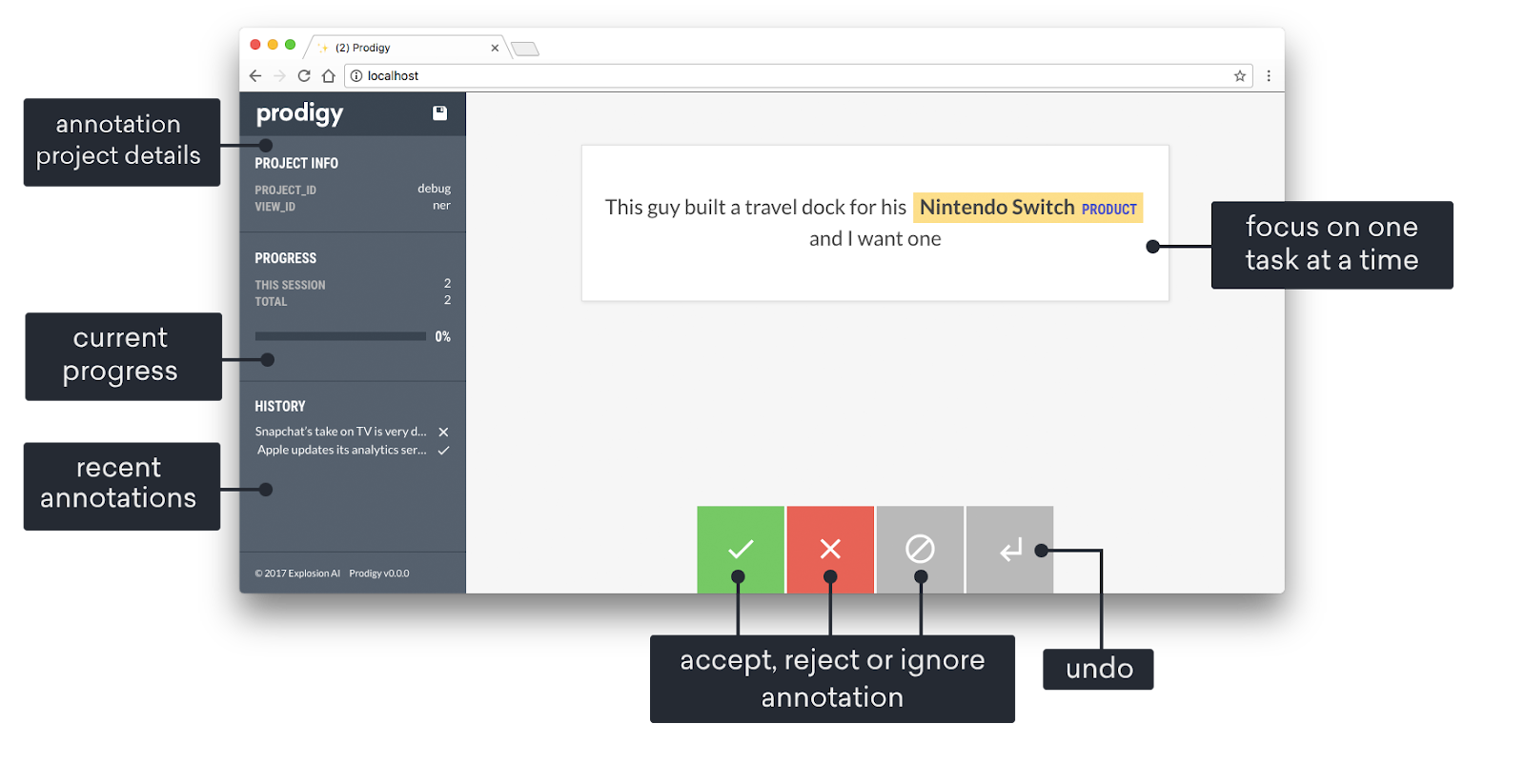
Quelle: Prodigy-Dokumente
Prodigy ist ein fortschrittliches Annotationstool von Explosion AI, das mit aktivem Lernen die Effizienz vor allem bei Aufgaben der natürlichen Sprachverarbeitung (NLP) verbessert. Bei Prodigy hilft ein maschinelles Lernmodell den Annotatoren, indem es auf Basis seiner Vorhersagen Labels vorschlägt, die dann von menschlichen Prüfern bestätigt oder korrigiert werden.
Dieser interaktive Ansatz macht das Annotieren schneller und sorgt gleichzeitig dafür, dass die beschrifteten Daten echt gut sind. Obwohl Prodigy ein kommerzielles Tool ist, lässt es sich super anpassen. Zum Beispiel können Nutzer ihre eigenen Anmerkungs-Workflows erstellen. Diese Faktoren machen Prodigy super für Teams, die an speziellen NLP-Projekten wie Sentimentanalyse, Entitätserkennung oder Textklassifizierung arbeiten.
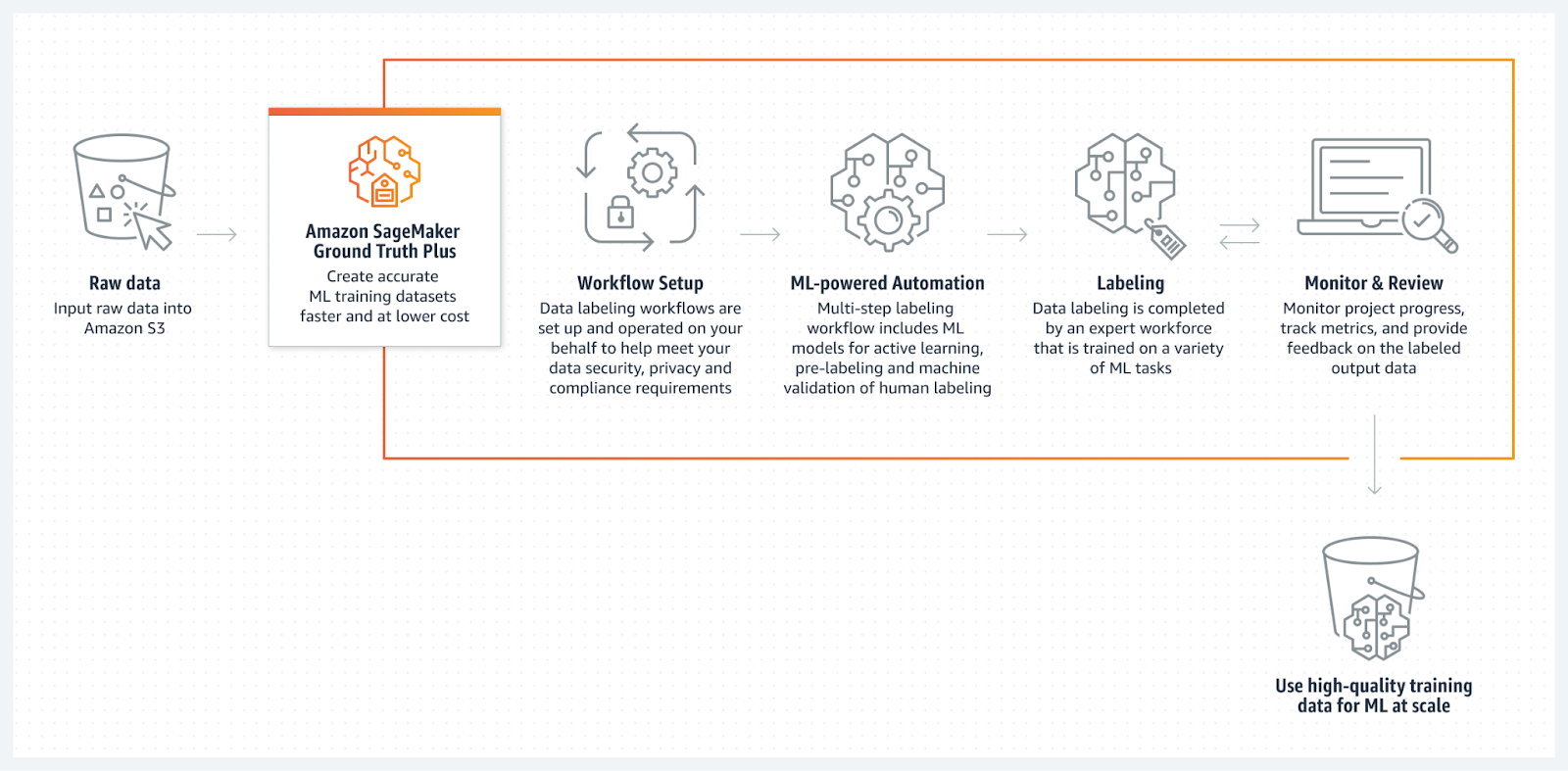
Quelle: Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth ist ein voll verwalteter Datenkennzeichnungsdienst mit dem „ “, der sich nahtlos in AWS einbinden lässt. Es bietet Tools für die manuelle und automatisierte Datenannotation, mit denen Benutzer Daten schnell und genau kennzeichnen können.
SageMaker Ground Truth nutzt maschinelles Lernen, um menschliche Annotatoren zu unterstützen, indem Daten vorab gekennzeichnet werden. Das beschleunigt den Prozess und senkt die Kosten. Der Service ist auch super flexibel für verschiedene Machine-Learning-Aufgaben, weil er viele verschiedene Datentypen wie Bilder, Texte und Videos unterstützt.
Außerdem ist es skalierbar, was es zu einer guten Wahl für Unternehmen macht, die umfangreiche Annotationsfunktionen innerhalb des AWS-Ökosystems brauchen.
Effektive Datenannotation ist super wichtig für den Erfolg von Machine-Learning-Modellen, weil die Qualität der beschrifteten Daten direkt Einfluss auf die Genauigkeit von Vorhersagen und Klassifizierungen hat. Wenn du dich an die bewährten Methoden hältst, kannst du sicherstellen, dass der Annotationsprozess effizient und zuverlässig läuft.
In diesem Abschnitt schauen wir uns wichtige Vorgehensweisen an, die die Qualität und Konsistenz der Datenannotation verbessern und gleichzeitig Probleme lösen können, die beim Beschriften auftreten können.
Einer der wichtigsten Schritte beim Datenannotationsprozess ist die Erstellung klarer, gut definierter Richtlinien. Diese Richtlinien sollten genau festlegen, wie Daten gekennzeichnet werden müssen und welche Kriterien die Annotatoren für die Einheitlichkeit beachten sollten.
Klare Richtlinien helfen dabei:
Standardisierte Regeln sind besonders wichtig für komplexe oder subjektive Daten, wie Bilder oder Texte, die man auf verschiedene Arten verstehen kann.
Qualität ist wichtig, um die Genauigkeit und Zuverlässigkeit von kommentierten Daten zu halten. Deshalb müssen die kommentierten Daten regelmäßig überprüft werden, um sicherzustellen, dass sie den geforderten Standards entsprechen. Dieser Prozess kann durch stichprobenartige Audits, den Einsatz mehrerer Annotatoren für dieselben Aufgaben (zum Vergleich der Ergebnisse) oder durch Gegenprüfung der Annotationen durchgeführt werden, je nach Projekt.
Das Wichtigste ist, dass dueinen soliden Qualitätssicherungsprozess einrichtest , damit du Fehler früh erkennen, Verzerrungen in deinen Daten reduzieren und sicherstellen kannst, dass die beschrifteten Daten für das Training leistungsstarker Machine-Learning-Modelle geeignet sind.
Aktives Lernen ist eine Technik des maschinellen Lernens, bei der ein Algorithmus die informativsten Datenproben für die Beschriftung auswählt, was die Leistung des Modells verbessert. Diese Technik kann die Effizienz des Annotationsprozesses deutlich verbessern. So können Annotatoren ihre Zeit und Energie auf die schwierigsten und wertvollsten Datenpunkte konzentrieren, während der Algorithmus für maschinelles Lernen den Rest vorschlägt.
So sparst du Zeit beim Beschriften von einfachen oder sich wiederholenden Proben und der ganze Annotationsprozess geht schneller. So steigt die Wahrscheinlichkeit, dass das Machine-Learning-Modell, das für Vorhersagen genutzt wird, mit den wichtigsten Beispielen trainiert wird.
Damit die Annotation richtig gemacht wird, sollten die Leute, die das machen, gut geschult sein. Durch Schulungen lernen die Annotatoren, was bei der Aufgabe wichtig ist und wie sie die Annotationsrichtlinien richtig anwenden.
Gut geschulte Annotatoren liefern eher hochwertige beschriftete Daten, was letztendlich die Leistung der von ihnen unterstützten Machine-Learning-Modelle verbessert. Regelmäßige Schulungen und Feedback-Runden können auch dabei helfen, die Fähigkeiten der Annotatoren mit der Zeit zu verbessern und so den Datenannotationsprozess weiter zu optimieren.
Datenannotation ist zwar super wichtig, um genaue Machine-Learning-Modelle zu trainieren, aber der Prozess hat auch seine Tücken. In diesem Abschnitt schauen wir uns ein paar der häufigsten Probleme bei der Datenannotation an.
Manuelles Annotieren von Daten -ist oft ziemlich aufwendig. Es braucht echt viel Zeit und Geld, um alle Fälle zu kommentieren, vor allem wenn der Datensatz groß ist. Je komplizierter die Daten sind (wie Videos oder komplizierte Bilder), desto mehr Zeit braucht man für die Beschriftung. Es müssen erfahrene Annotatoren eingestellt werden, was die Kosten erhöht.
Um das Problem zu lösen, können Unternehmen halbautomatische Annotationstools nutzen, bei denen KI-Modelle Labels vorschlagen und Menschen diese dann checken. Das macht den Prozess schneller, ohne dass die Genauigkeit leidet.
Aktives Lernen kann auch helfen, indem es die Arbeit auf die Daten konzentriert, die am meisten bringen, was die Menge der Daten reduziert, die manuell gekennzeichnet werden müssen. Außerdem können mit Crowdsourcing-Plattformen wie Amazon Mechanical Turk mehrere Leute gleichzeitig arbeiten, was bedeutet, dass große Annotationsprojekte günstiger und effizienter werden.
Eine weitere wichtige Herausforderung ist der Umgang mit Subjektivität und Voreingenommenheit beim Annotationsprozess. Verschiedene Annotatoren können dieselben Daten unterschiedlich interpretieren. Das ist echt häufig bei Aufgaben wie dem Beschriften von Emotionen in Texten oder dem Erkennen von Objekten in komplizierten Bildern. Das Problem dabei ist, dass Subjektivität zu Verzerrungen in den beschrifteten Daten führen kann, was wiederum zu verzerrten Modellvorhersagen führen kann.
Um Subjektivität und Voreingenommenheit zu vermeiden, sollten Unternehmen klare und detaillierte Anweisungen für Anmerkungen erstellen, damit alle, die Anmerkungen machen, die gleichen Kriterien befolgen. Eine andere Möglichkeit ist, mehrere Annotatoren für die gleichen Daten zu nehmen. So kann man die Arbeit gegenprüfen und voreingenommene oder widersprüchliche Annotationen leichter erkennen und korrigieren.
Kommentare, die persönliche Infos preisgeben, können gegen Datenschutzbestimmungen verstoßen, die persönliche Daten schützen. Diese Herausforderung ist besonders wichtig, wenn man Annotationsaufgaben auslagert oder Crowdsourcing-Plattformen nutzt, wo viele Leute Zugriff auf die Daten haben.
Lösungen wie Anonymisierung (das Entfernen von personenbezogenen Daten) und die Verwendung sicherer, verschlüsselter Plattformen für Anmerkungen können dabei helfen, diese Risiken zu verringern.
In diesem Abschnitt schauen wir uns mal an, wie Datenannotation in der Praxis eingesetzt werden kann. Lass uns loslegen!
Bei selbstfahrenden Autos ist die Datenannotation echt wichtig, damit die KI lernt, wie man sicher durch die reale Welt navigiert. Selbstfahrende Autos brauchen Daten mit Anmerkungen, um Sachen zu erkennen.
Zum Beispiel beschriften Leute, die Anmerkungen machen, Bilder oder Videobilder, indem sie Rahmen um Autos zeichnen oder Straßenränder markieren, um die Fahrspur zu erkennen. Diese Anmerkungen helfen der KI dabei, verschiedene Verkehrssituationen zu erkennen und richtig zu reagieren, z. B. für Fußgänger anzuhalten oder in der richtigen Spur zu bleiben.
KI-Modelle brauchen beschriftete medizinische Bilder, um zu lernen, wie man Anomalien erkennt. Zum Beispiel könnten erfahrene Annotatoren bestimmte Bereiche auf Bildern markieren, um Stellen zu kennzeichnen, die erste Anzeichen von Krebs zeigen. Dadurch kann KI Krebs schneller und genauer erkennen als mit herkömmlichen Methoden, was die Behandlungsergebnisse für Patienten verbessert und die Arbeitsbelastung für medizinisches Fachpersonal verringert.
Für Chatbots im Kundenservice ist das Kommentieren von Texten echt wichtig, damit die KI menschliche Sprache kapiert.
Zum Beispiel können Leute, die Anmerkungen machen, Text markieren, damit Chatbots besser verstehen, was die Nutzer wollen. Die Chatbots würden dann die gekennzeichneten Interaktionen analysieren, um zu lernen, wie sie die richtigen Antworten geben können. So können Unternehmen schneller und besser helfen und das Kundenerlebnis verbessern.
Bei der Sentimentanalyse wird eine Text- und Ausdrucksnotation verwendet, um zu messen, wie Kunden über bestimmte Dinge denken (z. B. die Marke, Produkte oder Events). Das geht so: Die Leute, die die Texte bearbeiten, markieren Phrasen oder Sätze als positiv, negativ oder neutral. Diese Infos werden dann an die KI weitergeleitet, die daraus die Stimmung lernt. Ein Unternehmen kann das dann nutzen, um zu checken, wie die Kunden auf eine neue Produkteinführung reagieren.
Datenannotation ist der Vorgang, bei dem Daten beschriftet werden, damit sie für Machine-Learning-Modelle erkennbar und nutzbar sind. Das ist ein wichtiger Schritt bei der Entwicklung von KI-Systemen, die Daten aus der echten Welt richtig verstehen und darauf reagieren können. Warum? Weil die Qualität und Genauigkeit der kommentierten Daten direkt die Leistung und Effektivität von KI-Modellen beeinflussen.
Letztendlich sind Datenannotationen die Basis für intelligente, zuverlässige KI-Systeme, die Innovationen in verschiedenen Branchen vorantreiben können. Das macht es zu einem unverzichtbaren Bestandteil der Entwicklung im Bereich maschinelles Lernen.
Wenn du weiterlernen willst, check mal diese Ressourcen aus:
Lerne in diesen Kursen mehr über maschinelles Lernen und KI!
Kurs
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
