Programa
Manipulação de dados Em Python
16 h
Com o aumento do volume, da variedade e da velocidade dos dados, o foco na criação de conjuntos de dados de qualidade e bem estruturados tornou-se mais importante do que nunca, pois eles influenciam diretamente a precisão dos insights e a eficácia das decisões em todos os setores.
Dados mal organizados ou com falhas podem levar a conclusões equivocadas, o que custa tempo, dinheiro e recursos. É nesse ponto queo data wrangling entra em cena como o processo essencial que garante que os dados brutos e não estruturados sejam transformados em um formato limpo e organizado, pronto para análise .
A organização dos dados envolve uma série de etapas para garantir que eles sejam precisos, confiáveis e adaptados para atender às necessidades específicas da análise em questão. Ao dominar a organização de dados, você pode liberar todo o potencial dos seus dados, transformando-os em insights acionáveis que conduzem a decisões informadas e, por fim, levam ao sucesso.
A manipulação de dados é o processo de transformação de dados brutos em um formato mais utilizável. Isso envolve a limpeza, a estruturação e o enriquecimento dos dados para que eles estejam prontos para análise.
Imagine que você acabou de receber um enorme conjunto de dados - ele é confuso, com valores ausentes, inconsistências e informações irrelevantes. A organização de dados é como um kit de ferramentas que ajuda você a arrumar esses dados, garantindo que eles sejam organizados e consistentes.
A organização de dados é importante para garantir que seus dados sejam de alta qualidade e bem estruturados, o que é crucial para uma análise de dados precisa. Dados limpos e estruturados servem como base para todas as etapas subsequentes do fluxo de trabalho de dados, quer você esteja criando um modelo de machine learning, gerando visualizações ou realizando análises estatísticas.
Dados de alta qualidade reduzem o risco de erros e vieses em sua análise, levando a insights mais confiáveis. Compreender a importância da organização dos dados é fundamental, pois ela afeta diretamente a validade das decisões tomadas com base nesses dados.
Dados mal manipulados podem levar a conclusões errôneas, o que pode ter consequências significativas em aplicativos do mundo real. Portanto, dominar a organização de dados é essencial para qualquer pessoa que queira tomar decisões orientadas por dados.
Há cinco etapas principais para a organização de dados:
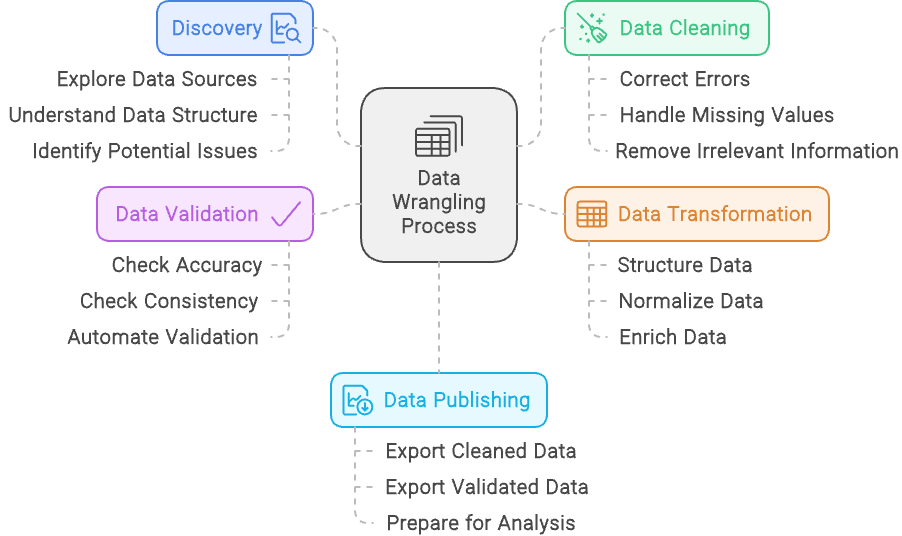
O processo de coleta de dados - criado com o Napkin.ai
Descrevemos as cinco etapas da coleta de dados, mas vamos analisar cada uma delas com mais detalhes:
A descoberta na organização de dados é como dar uma primeira olhada em um quebra-cabeça antes de você começar a juntar as peças. Isso envolve examinar o conjunto de dados para ter uma noção clara de com o que você está trabalhando, incluindo a compreensão dos tipos de dados, suas fontes e como eles estão estruturados.
Da mesma forma que você pode classificar peças de quebra-cabeça por cor ou forma de borda, a descoberta ajuda a categorizar e reconhecer padrões nos dados, preparando o terreno para o trabalho futuro.
Mas a descoberta também tem a ver com a identificação de possíveis problemas, como peças faltando ou cores incompatíveis em um quebra-cabeça.
Durante essa etapa, você identifica quaisquer problemas nos dados, como inconsistências, valores ausentes ou padrões inesperados. Ao descobrir esses desafios logo no início, você pode planejar como lidar com eles nas etapas subsequentes da organização dos dados, garantindo um caminho mais suave para um conjunto de dados limpo e utilizável.
Limpeza de dados envolve o refinamento do seu conjunto de dados para garantir que ele seja preciso e confiável.
Esse processo inclui a abordagem de problemas como a correção de erros, o tratamento de valores ausentes e a correção de inconsistências. Por exemplo, se o seu conjunto de dados contiver entradas duplicadas para o mesmo indivíduo ou transação, a limpeza de dados envolveria a remoção dessas duplicatas para evitar distorcer os resultados.
Além disso, se você descobrir que algumas entradas estão mal formatadas, como números de telefone com formatos variados, você deve padronizá-las para um formato consistente. O objetivo é melhorar a qualidade e a integridade gerais dos dados, preparando-os para uma análise precisa e significativa.
Transformação de dados É o processo de modificar e aprimorar o conjunto de dados para que ele se alinhe melhor aos requisitos da sua análise. Essa etapa envolve a estruturação dos dados, como reformulá-los para que se ajustem ao formato desejado ou combinar várias fontes em uma estrutura coesa.
A normalização dos dados é outro aspecto importante, o que significa ajustar os valores a uma escala ou formato comum, como converter todos os valores monetários em uma única moeda ou padronizar as unidades de medida.
Além disso, a transformação de dados inclui o enriquecimento do conjunto de dados com a adição de novas variáveis ou a integração de fontes de dados externas para fornecer mais contexto ou percepções. Por exemplo, você pode calcular novas métricas com base nos dados existentes ou anexar informações adicionais de outros bancos de dados para fornecer um quadro mais completo.
O objetivo da transformação de dados é preparar os dados de forma a melhorar sua usabilidade e relevância para uma análise aprofundada.
Validação de dados envolve garantir a precisão e a confiabilidade do seu conjunto de dados por meio de verificações sistemáticas e processos automatizados. Essa etapa é fundamental para confirmar se os dados estão corretos e consistentes.
Durante a validação de dados, você realiza várias verificações para identificar discrepâncias, como a comparação de dados com benchmarks conhecidos ou a validação com regras e restrições predefinidas. Os processos automatizados podem incluir a execução de scripts que sinalizam anomalias ou inconsistências, garantindo que os dados sigam os formatos e intervalos esperados.
O objetivo da validação de dados é detectar quaisquer problemas antes que os dados sejam usados para análise, evitando que os erros afetem os resultados. Ao verificar rigorosamente a precisão e a confiabilidade dos dados, você garante que os insights extraídos dos dados sejam baseados em informações confiáveis.
A publicação de dados é a etapa final do processo de organização de dados, em que os dados limpos e estruturados são disponibilizados para análise e tomada de decisões. Essa etapa envolve a preparação dos dados para divulgação, geralmente por meio da criação de painéis, relatórios ou visualizações interativas que os tornem acessíveis e compreensíveis para as partes interessadas.
Durante a publicação de dados, você pode configurar pipelines de dados ou interfaces que permitam aos usuários consultar e interagir com os dados, garantindo que eles sejam entregues em um formato que atenda às suas necessidades.
O objetivo é fornecer percepções claras e acionáveis a partir dos dados, permitindo a tomada de decisões informadas e facilitando a comunicação das descobertas em toda a organização. Ao publicar os dados de forma eficaz, você garante que o trabalho árduo de organização dos dados se traduza em resultados significativos e práticos.
Os termos data wrangling e data cleaning são frequentemente usados de forma intercambiável, mas se referem a diferentes aspectos do processo de preparação de dados. Embora ambos sejam essenciais para preparar os dados para análise, eles têm finalidades distintas e envolvem tarefas diferentes. Entender a diferença entre eles ajuda a esclarecer suas funções e garante que cada aspecto da preparação de dados seja tratado de forma eficaz.
Preparação de dados é um processo abrangente que envolve a transformação de dados brutos em um formato adequado para análise. Ele abrange vários estágios, incluindo a aquisição dos dados, sua estruturação, limpeza e validação. O objetivo da organização de dados é preparar os dados de diversas fontes para que possam ser analisados e usados com eficiência para gerar insights. Esse processo garante que os dados estejam organizados, precisos e prontos para uma análise detalhada.
Limpeza de dados, por outro lado, é um subconjunto específico da organização de dados. Ele se concentra exclusivamente na melhoria da qualidade dos dados, abordando e corrigindo erros e inconsistências. Isso inclui tarefas como a remoção de registros duplicados, a correção de erros de digitação, o tratamento de valores ausentes e a padronização de formatos de dados. Embora a limpeza de dados seja uma parte crucial da organização de dados, ela é apenas uma etapa do processo mais amplo.
Simplificando, a preparação de dados é a estrutura geral que prepara os dados para análise, incluindo várias etapas para lidar com diversos aspectos da preparação de dados. A limpeza de dados é um componente integral dessa estrutura, dedicado especificamente a aprimorar a precisão e a consistência dos dados.
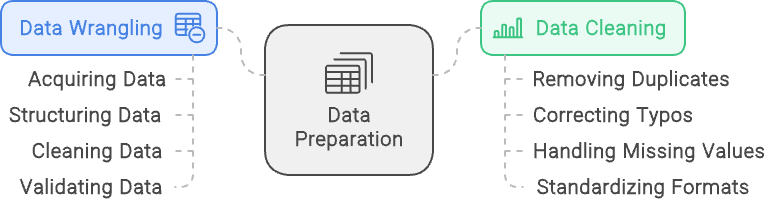
Limpeza de dados vs. organização de dados: O Data Wrangling se concentra na estruturação e validação de dados, enquanto o Data Cleaning se concentra em garantir que dados limpos e de qualidade estejam disponíveis. Imagem criada com napkin.ai
Há muitas maneiras de lidar com os dados, seja por meio do uso de ferramentas fundamentais baseadas em GUI, como Excel ou Alteryx, seja por meio de codificação com linguagens como R e Python. Vamos explorar algumas opções aqui.
Para tarefas simples de organização de dados, planilhas como Microsoft Excel e o Google Sheets costumam ser as melhores opções para você. Essas ferramentas são altamente acessíveis e oferecem uma interface familiar, o que as torna ideais para tarefas como classificação, filtragem e limpeza básica de dados. As planilhas são particularmente úteis para conjuntos de dados menores ou para aqueles que estão apenas começando a aprender a lidar com dados.
Com funções e fórmulas incorporadas, eles permitem que os usuários realizem cálculos e manipulem dados rapidamente, sem a necessidade de conhecimento técnico aprofundado.
Para manipulação de dados e automação mais complexas, linguagens de programação como Python e R são amplamente usadas. Python, com suas bibliotecas poderosas, como PandasNumPy e OpenRefine, é excelente para lidar com grandes conjuntos de dados e realizar transformações complexas de dados.
Rcom pacotes como dplyr e tidyré outra opção forte, particularmente favorecida nas comunidades estatísticas e acadêmicas por seus recursos robustos de análise de dados. Ambas as linguagens oferecem um alto grau de flexibilidade, permitindo que os usuários criem scripts de fluxos de trabalho personalizados e automatizem tarefas repetitivas, o que as torna ideais para profissionais de dados que trabalham com necessidades mais sofisticadas de manipulação de dados.

Nossa Folha de referência sobre como lidar com dados em Pandas pode ajudar você a dominar muitos dos conceitos básicos
As ferramentas de software dedicadas são projetadas especificamente para agilizar o processo de organização de dados, oferecendo recursos avançados que simplificam tarefas complexas de dados. Essas ferramentas são ideais para usuários que precisam de soluções eficientes, porém acessíveis, para limpar, estruturar e preparar dados para análise sem a necessidade de codificação extensiva.
Alteryx é uma ferramenta líder nessa categoria, conhecida por sua interface intuitiva de arrastar e soltar que permite aos usuários limpar, combinar e transformar facilmente dados de várias fontes. Ele vem equipado com uma variedade de ferramentas integradas para manipulação de dados, o que facilita a execução de tarefas como filtragem, união e agregação de dados.
O Alteryx Designer Cloud , baseado na nuvem , aprimora ainda mais esses recursos, fornecendo uma plataforma escalonável e colaborativa para a organização de dados. Essa solução permite que as equipes trabalhem juntas em tempo real, lidando com grandes conjuntos de dados e fluxos de trabalho complexos de forma eficiente em diferentes ambientes. Independentemente de ser usado no local ou na nuvem, o Alteryx garante que os dados sejam preparados com precisão e estejam prontos para uma análise criteriosa.
Para projetos de dados abrangentes que exigem soluções de ponta a ponta, plataformas integradas como o KNIME, Apache NiFie Microsoft Power BI são usadas com frequência. Essas plataformas não apenas suportam a organização de dados, mas também fornecem ferramentas para integração, análise e visualização de dados em um único ambiente.
O KNIME, por exemplo, é conhecido por sua interface modular, baseada em nós, que permite aos usuários criar fluxos de trabalho complexos visualmente. O Apache NiFi é excelente no gerenciamento e na automação de fluxos de dados entre sistemas, enquanto o Power BI combina a preparação de dados com recursos avançados de visualização. Essas plataformas são ideais para projetos em que os dados precisam ser preparados, analisados e compartilhados sem problemas, oferecendo uma abordagem holística para a tomada de decisões orientada por dados.
Há muitas opções quando se trata de manipulação de dados com Python. Os dois principais pacotes utilizados são Pandas e NumPy. Esses dois pacotes têm ferramentas poderosas que permitem que os usuários executem facilmente as principais técnicas de organização de dados em seus conjuntos de dados.
Como grande parte do processamento de dados ocorre em Python, dominar esses pacotes será essencial para qualquer profissional de dados. Embora existam muitas técnicas, algumas coisas importantes que você deve saber são como realizar a limpeza de dados de alto nível (eliminando nulos, por exemplo), mesclando conjuntos de dados e lidando com valores ausentes.
Há muitas ocasiões em que os dados precisam ser limpos em Python antes de serem utilizados. Isso pode envolver coisas como a remoção de espaços em branco nas cadeias de caracteres, a eliminação de valores nulos ou a correção de tipos de dados, para citar alguns exemplos.
Cada conjunto de dados é diferente e terá suas próprias necessidades, portanto, explore seu conjunto de dados para entender se é necessária uma limpeza adicional. Praticar várias técnicas e habilidades de codificação é uma ótima maneira de aprender todas as maneiras diferentes de limpar dados em Python. limpar dados em Python.
Quando se trata de limpar as cadeias de caracteres, um dos muitos problemas é o espaço em branco de arrastamento/condução. Isso pode causar problemas ao tentar analisar cadeias de caracteres com base no comprimento, no local ou na correspondência. A melhor maneira de lidar com algo assim é usar o método str.strip() em uma série.
# Example utilizes a pandas series
# If working with a dataframe, call the series using df[col] syntax
s = pd.Series(['1. Ant. ', '2. Bee!\n', '3. Cat?\t', np.nan, 10, True])
# It is important to include the .str or else the method will not work
s.str.strip()Eliminar valores nulos no Pandas é fácil. Discutiremos como preencher valores nulos mais adiante neste artigo. Você pode simplesmente usar o método dropna(). Há parâmetros opcionais nesse método que permitem que você escolha as condições exatas que eliminarão uma linha/coluna, mas o comportamento padrão é eliminar qualquer linha com valores nulos
# For any dataframe
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
"toy": [np.nan, 'Batmobile', 'Bullwhip'],
"born": [pd.NaT, pd.Timestamp("1940-04-25"), pd.NaT]}
df.dropna()O método .astype() permite que os usuários alterem o tipo de dados de uma série, mas a correção dos tipos de dados é um pouco mais complicada, pois você precisa garantir que todos os valores da série do Pandas correspondam a esse tipo de dados.
Por exemplo, converter uma série que é um objeto em um número inteiro significa que você sabe que cada valor é um número inteiro. Se houver um único valor que não seja um número inteiro, você receberá um erro no método. Você pode optar por forçá-lo tornando nulos os valores inválidos, mas pode valer mais a pena investigar enquanto determinados valores não estiverem sendo convertidos.
Ao mesclar DataFrames no Pandas, você se assemelha à junção no SQL. O comportamento padrão de um Pandas merge() é executar uma união interna. No entanto, ele se unirá a nulos, portanto, tenha cuidado. A execução de uma mesclagem exige que você utilize uma chave específica. Você pode unir várias colunas ou até mesmo o índice.
# Create two dataframes
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],
'value': [1, 2, 3, 5]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
'value': [5, 6, 7, 8]})
# merge the df1 DataFrame to the df2 DataFrame using the columns key and rkey as keys
df1.merge(df2, left_on='lkey', right_on='rkey')O código acima mesclará os dois DataFrames com base nas chaves correspondentes em suas respectivas colunas lkey e rkey. Os valores não correspondentes serão descartados e você ficará apenas com os valores correspondentes. No entanto, você pode alterar o comportamento da mesclagem e escolher uma mesclagem esquerda/direita/externa também. Essa é uma ferramenta poderosa que permite que os cientistas de dados reúnam diferentes conjuntos de dados de várias fontes de dados.
Quando se trata de valores ausentes, a metodologia exata pode variar de acordo com o caso comercial. Quando falamos de valores ausentes, devemos considerar por que o valor está ausente. Se o valor estiver faltando devido a erros técnicos, talvez devêssemos nos concentrar em corrigir o erro técnico antes de analisar nossos dados e ver se não é possível recuperar os dados históricos.
Às vezes, podemos usar o restante dos dados e simplesmente ignorar o valor ausente. Se os dados históricos forem importantes e irrecuperáveis, devemos preencher os dados ausentes. Vamos discutir como você pode preencher as informações que faltam.
O principal método de preenchimento de dados é usar o método fillna() do Pandas. Para valores de cadeia de caracteres, esse método pode ser usado para preencher esses nulos, por exemplo: df.fillna(value=’missing’), o que pode ser suficiente! A vantagem desse método é que você pode ser criativo. Combinando o método Pandas fillna() com uma variedade de métodos NumPy, como mean(), median() e funções lambda, podemos preencher matematicamente os valores ausentes.
Como alternativa, existem até mesmo métodos do Pandas, como interpolate(), que podem preencher algoritmicamente as lacunas se os dados forem ordenados (por exemplo, com base no tempo). O objetivo é preencher os dados com a maior precisão possível para que eles reflitam os dados reais.
Realizar a manipulação de dados em SQL pode ser uma maneira eficaz de processar seus dados, especialmente se o banco de dados SQL estiver na nuvem. Isso limita a quantidade de dados processados pelo seu computador local e a quantidade de dados que saem/entram nas redes.
O foco principal da organização de dados em SQL é limitar o escopo dos dados que fluem pelos nossos pipelines por meio da extração, transformação e carregamento adequados dos dados. Algumas maneiras de gerenciar isso são filtrar dados, unir-se a tabelas de referência e realizar agregações.
A principal maneira de filtrar tabelas no SQL é usando a cláusula WHERE. Ele é bastante simples de usar, mas pode ser extraordinariamente poderoso. As condições podem ser simples declarações de igualdade, procurar cadeias de caracteres semelhantes ou até mesmo utilizar outras subconsultas. Você também pode combinar várias cláusulas where usando os comandos AND e OR!
A filtragem com base em casos simples, como a busca de um valor específico de uma coluna, pode ter a seguinte aparência:
SELECT *
FROM sample_table
WHERE sample_col = 23O uso de instruções mais complexas, como LIKE ou IN, pode proporcionar flexibilidade às cláusulas WHERE. Por exemplo, a consulta a seguir procura pessoas cujo nome começa com J graças ao curinga % e também cujo sobrenome é IN na lista fornecida.
SELECT *
FROM sample_table
WHERE name LIKE ‘J%’ /* looks for people whose name starts with J */
AND last_name IN (‘Smith’, ‘Rockefeller’, ‘Williams’) /* Looks for people whose last name is in this list */Por fim, algo como usar outras subconsultas pode dar flexibilidade à filtragem. Você pode se basear nos resultados de outra tabela. Um exemplo comum é encontrar uma lista de IDs de clientes após uma data específica.
SELECT *
FROM sample_table
WHERE customer_id IN (SELECT id FROM reference_table WHERE date >= ‘2024-01-01’)O uso de uma combinação dessas técnicas garante que as entradas de dados sejam exatamente o que você está procurando e que os tamanhos dos conjuntos de dados possam ser minimizados. Um uso extra poderoso dos filtros é a remoção de duplicatas em seu conjunto de dados e a limpeza dessa forma. Algumas técnicas mais avançadas a serem implementadas são os filtros HAVING para agregações e as declarações QUALIFY com funções de janela.
A realização de uniões de tabelas nos permite coletar informações extras que podemos precisar para nossos conjuntos de dados. O SQL tem uma variedade de junções, como INNER, OUTER, LEFT, e RIGHT. Com as uniões INNER e OUTER, determinamos quais dados são mantidos. As uniões INNER mantêm os dados somente se houver uma correspondência em ambos os lados, enquanto OUTER mantém os dados que também não são correspondidos, dependendo do lado a partir do qual estamos unindo (esquerdo ou direito).
A união LEFT mantém os dados no lado esquerdo da união e a união RIGHT mantém os dados no lado direito da união. Você combina as uniões LEFT e RIGHT com as uniões INNER e OUTER, bem como a união especial FULL OUTER JOIN, que simplesmente une todos os dados de ambas as tabelas.
Um exemplo de associação pode ser:
SELECT *
FROM a
LEFT OUTER JOIN
b
WHERE a.id = b.idNa declaração acima, você tem a tabela a à esquerda, pois é a primeira, e a tabela b à direita, pois é a segunda. O site LEFT OUTER JOIN diz: junte os dados da tabela a e da tabela b onde a.id = b.id, mas se não houver correspondência, mantenha todos os dados da tabela a. As uniões são ferramentas poderosas para trazer dados extras que podem ser necessários para sua entrada de dados.
Uma última ferramenta que poderíamos utilizar no SQL para a organização de dados é a cláusula GROUP BY para realizar agregações. Isso simplifica os dados e nos permite pré-processá-los um pouco antes de enviá-los ao longo do pipeline. A agregação é uma ferramenta poderosa para calcular estatísticas resumidas. Aqui está um exemplo em que estamos analisando o total de vendas por ID de cliente..:
SELECT
Customer_ID,
SUM(sales)
FROM sample_table
GROUP BY Customer_IDHá várias funções de agregação, como SUM, MEAN, MAX e MIN, que nos permitem entender nossos dados de forma rápida e fácil. Aproveitar as vantagens das agregações simplifica a entrada de dados nos pipelines.
Esta seção abordará alguns exemplos práticos e casos de uso de técnicas de organização de dados. As principais metas em que nos concentraremos são: padronização de dados, fusão de fontes de dados e processamento de texto.
É importante padronizar os dados nas mesmas unidades. Se você estiver trabalhando com dados que medem a mesma coisa em unidades diferentes ou com diferença de moeda, isso poderá causar problemas na análise.
Abordaremos um exemplo simples de conversão de diferentes moedas para dólares americanos no SQL. Primeiro, vamos supor que você tenha duas tabelas. A Tabela 1 é uma tabela sales que contém vendas de produtos para várias regiões e a Tabela 2 é uma tabela currency_exchange que contém a taxa de câmbio para várias regiões em vários dias. Um exemplo dessa conversão pode ser o seguinte:
SELECT
a.sale_id,
a.region,
CASE WHEN region <> ‘US’
THEN a.sale_price * b.exchange_rate
ELSE a.sale_price
END AS sale_price
FROM sales AS a
LEFT OUTER JOIN
currency_exchange AS b
WHERE a.region = b.regionIsso pega o sale_id e o region da tabela sales e faz a junção com a tabela de referência currency_exchange na região para que você possa obter a taxa de câmbio. Muitas vezes, pode haver uma data envolvida para que você possa obter a taxa de câmbio do dia.
Uma parte importante da organização de dados é o processamento de dados para nossos modelos de machine learning. Recentemente, muitos modelos têm se concentrado no processamento de linguagem natural e um precursor disso é a análise de sentimentos por meio de dados de texto.
Uma etapa essencial para isso é a preparação do texto por meio da normalização e da remoção da pontuação. Como a pontuação e a capitalização podem não fornecer um contexto importante para um modelo de machine learning, geralmente é melhor normalizar.
Para fazer isso, utilizaremos os pacotes básicos do Python e o pacote re. Veja abaixo um exemplo de remoção de pontuação, normalização de texto para remover letras maiúsculas e corte de espaço vazio.
# import regex
import re
# input string
test_string = " Python 3.0, released in 2008, was a major revision of the language that is not completely backward compatible and much Python 2 code does not run unmodified on Python 3. With Python 2's end-of-life, only Python 3.6.x[30] and later are supported, with older versions still supporting e.g. Windows 7 (and old installers not restricted to 64-bit Windows)."
# remove whitespaces
no_space_string = test_string.strip()
# convert to lower case
lower_string = no_space_string .lower()
# remove numbers
no_number_string = re.sub(r'\d+','',lower_string)
print(no_number_string)O trecho de código acima fornece uma excelente base para a remoção de espaços em branco, a conversão de caracteres em letras minúsculas e a remoção de números/dados não alfabéticos.
A organização de dados é um componente essencial da preparação de nossos dados para modelos e análises de machine learning. Há uma infinidade de ferramentas em Python, como os pacotes pandas e numpy, juntamente com uma variedade de métodos SQL, como as cláusulas WHERE e GROUP BY, que nos permitem preparar nossos dados.
O domínio dessas técnicas é fundamental para que qualquer aspirante a profissional de dados tenha sucesso na profissão. Se você quiser se aprofundar nos tópicos de organização de dados, considere os seguintes recursos:
Principais cursos da DataCamp
Programa
Curso
Curso
blog
Matt Crabtree
10 min
blog
Matt Crabtree
15 min
blog
Matt Crabtree
9 min
blog
Javier Canales Luna
14 min
Tutorial
Kurtis Pykes



