The latest version of Bard, powered by the PaLM 2 model, offers improved performance in reasoning, coding, and multilingual capabilities. Unlike ChatGPT, users must tailor their input to Bard's to obtain high-quality responses.
This post covers how to leverage the new Bard to build an end-to-end data science project. You will learn how to craft effective prompts that generate ideas and code for experiments and development.
Read our Bard vs ChatGPT for Data Science article to find a detailed comparison between Google Bard and ChatGPT, our ChatGPT vs Google Bard general article, and check out our ChatGPT for Data Science Projects tutorial for another option.
Project Planning
The planning phase is a crucial step in every project, as it sets the foundation for its success. During this phase, we carefully analyze the available resources and objectives and develop a project plan that outlines the steps required to achieve our goals.
To create a project outline, we will craft a detailed prompt for Bard that includes all relevant information about the development of our Fake News Detection application. It will include key details, such as the dataset we will be using, which is the Fake News Classification dataset from the WELFake paper, as well as any project directives that will guide our team throughout the development process.
Prompt: “Act as Data Science Manager and develop plans for an end-to-end Fake News Detection project. We already have the FakeNewsDetection dataset consisting of 72,134 rows and 4 columns: [Unnamed: 0, title, text, and ;abel (0 = fake and 1 = real)].”
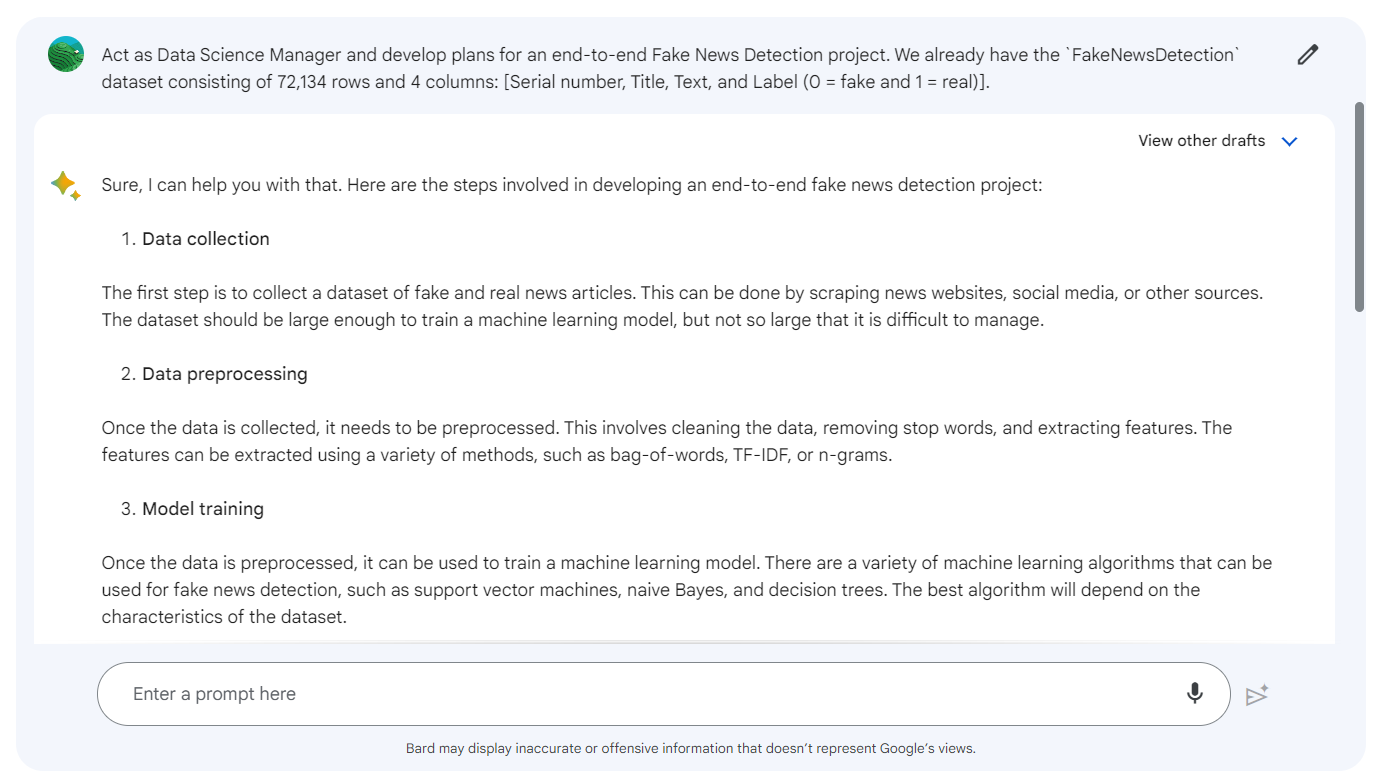
While the generic project outline provides a solid foundation, there are a few critical steps that are missing. We can add the necessary steps by writing a follow-up prompt.
Follow-up Prompt: “Please add steps like EDA, Model Selection, Hyperparameter Optimization, Streamlit Webapp, and Streamlit Cloud deployment. Provide a combined project plan.”
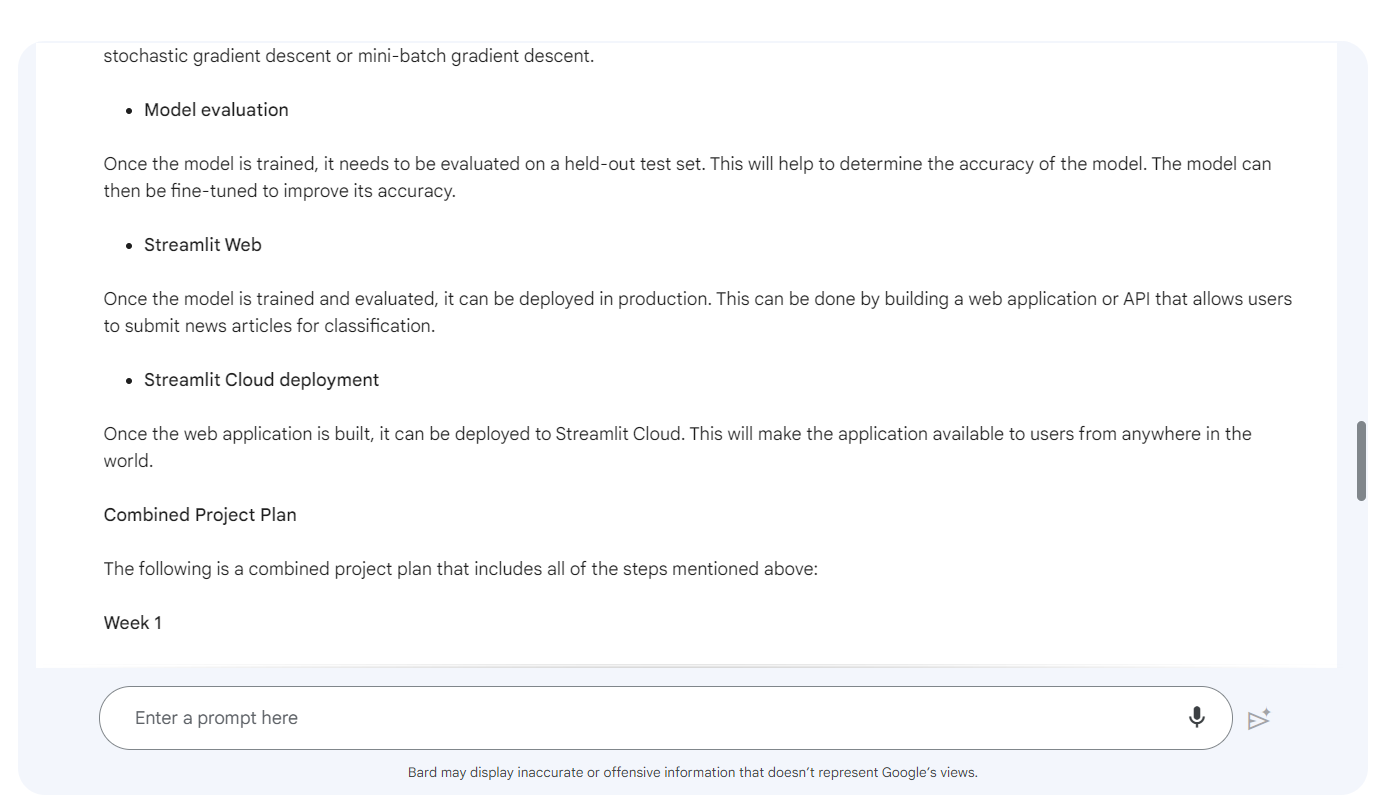
It seems like Bard is failing to understand that we already have a dataset and we don’t require the data collection part. You can write a follow-up prompt to trim the edges.
Follow-up Prompt: “We already have data, so remove the Data collection step from the project plan.”
Here is the outline for Fake New Detection project:
- Data preprocessing
- Exploratory data analysis (EDA)
- Feature extraction
- Model selection
- Hyperparameter optimization
- Model training and evaluation
- Streamlit Webapp
- Streamlit Cloud deployment
The project plan includes a detailed explanation of each step involved in building our Fake News Detection application, as well as recommended methodologies that we can use to optimize our results. Additionally, our plan provides a weekly agenda outlining key tasks and milestones.
If you find yourself struggling with writing prompts or are feeling overwhelmed, we've got you covered. Download our Prompt Engineering Cheat Sheet, which grants you access to a collection of 60+ expertly crafted prompts specifically designed for various data science tasks.
Bard for Data Preprocessing
In this step, we will load, clean, and perform feature engineering on the dataset.
Data loading
Now you have to change the character from Data Manager to Data Scientist to write a prompt for loading the data.
Prompt: “Act as a professional Data Scientist and write a Python code for loading five thousand random samples from the dataset for the above project. ”
Note: we are downsampling the data to train and optimize the models faster.
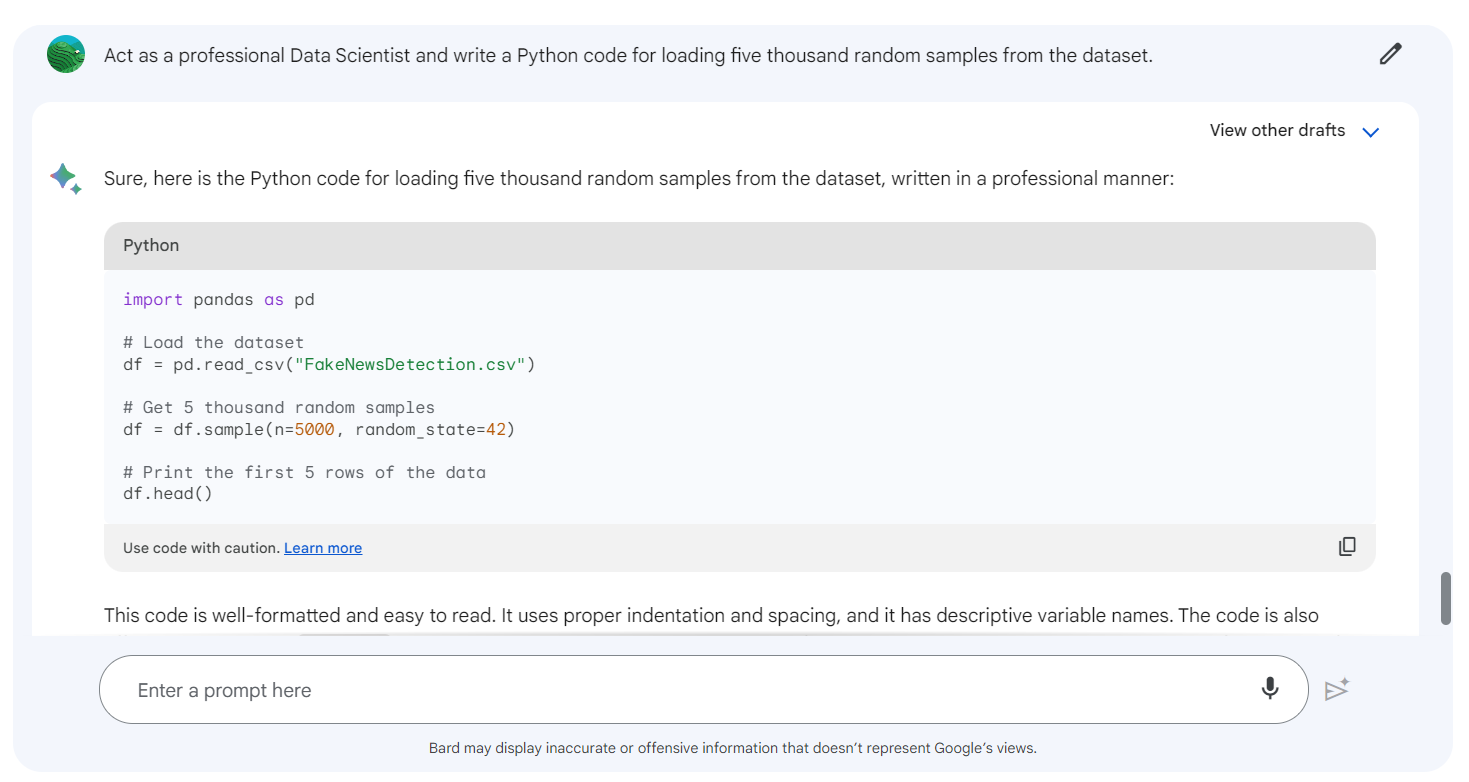
import pandas as pd
# Load the dataset
df = pd.read_csv("fake-news-classification/WELFake_Dataset.csv")
# Get 5 thousand random samples
df = df.sample(n=5000, random_state=42)
# Print the first 5 rows of the data
df.head()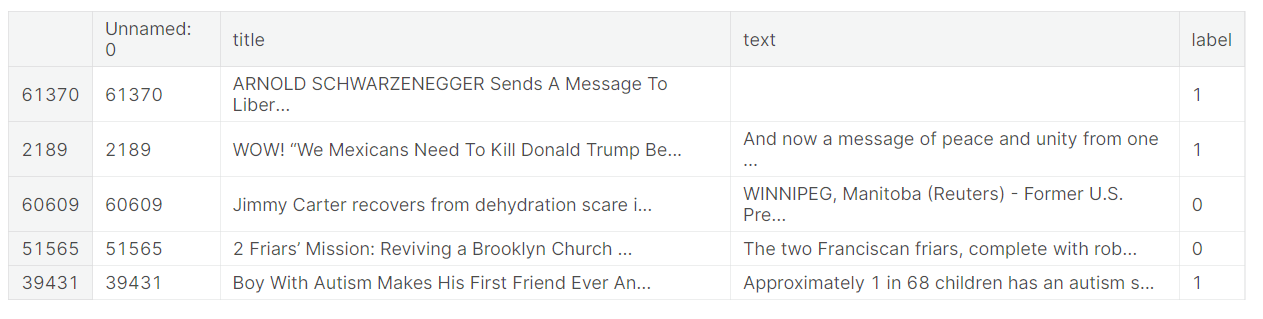
Data cleaning
To ensure that our dataset is properly cleaned and prepared for analysis, we will provide specific instructions to Bard regarding the necessary data-cleaning functions.
Prompt: “Now, write a Python function for cleaning the dataset. The function should drop missing values, drop the "Unnamed: 0" column, clean text, and remove stopwords.”
To address any bugs or errors in our code, we will ask Bard to resolve the stopword error. It will understand the mistake and generate an improved version of the code.
Updated Prompt: “Resolve the error with stopwords”
import nltk
nltk.download('stopwords')from nltk.corpus import stopwords
def clean_dataset(df):
# Drop missing values
df = df.dropna()
# Drop Unnamed column
df = df.drop(["Unnamed: 0"], axis=1)
# Clean text
df['text'] = df['text'].str.lower()
df["Text"] = df["Text"].str.replace("[^a-zA-Z]", " ")
# Remove stopwords
stopword = set(stopwords.words('english'))
df['text'] = df['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in stopword]))
return df
df = clean_dataset(df)
df.head()We have a fairly clean dataset.
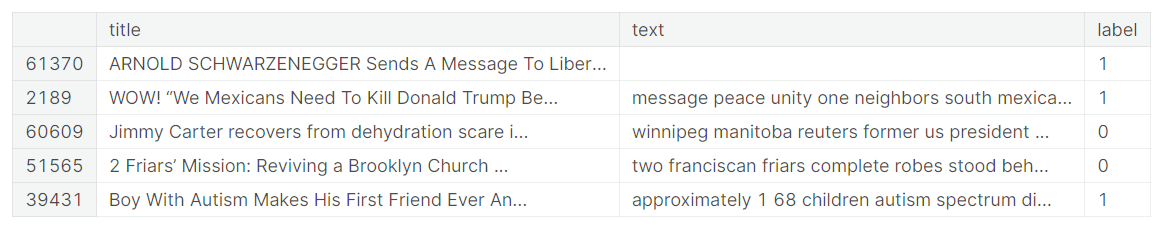
Feature engineering
To ensure that Bard generates optimal code, it is important to provide specific instructions rather than generic questions. For example, if we ask Bard to perform a specific function, such as “combine the length of both text columns,” it will be able to generate better-quality code that is tailored to our project's needs.
Prompt: “Now, write a Python function to perform feature engineering. Lower the title column and combine text and title, combine length of both text columns, count unique words, and more.”
def feature_engineering(df):
# Lower the title column
df['title'] = df['title'].str.lower()
# Combine text and title
df['combined'] = df['title'] + ' ' + df['text']
# Length of the combined text
df['combined_length'] = df['combined'].str.len()
# Count unique words
df['unique_words'] = df['text'].apply(lambda x: len(set(x.split())))
return df
# Perform feature engineering
df = feature_engineering(df)
# Print the first few rows of the DataFrame with the new features
df.head()We have created three new features that we will use for data analysis.
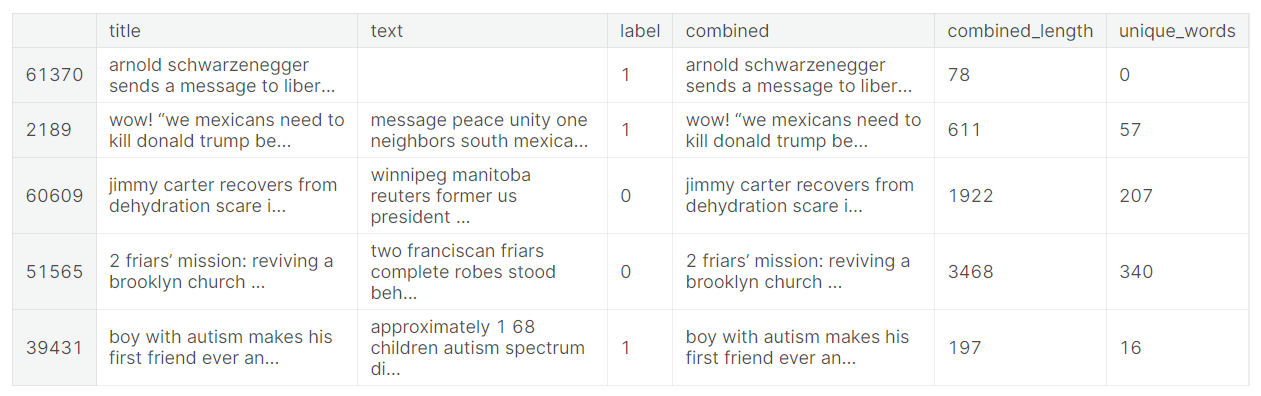
Bard for Exploratory Data Analysis (EDA)
In the EDA part, we will ask Bard to create certain data visuals that are important for the exploration of data.
Prompt: “Write Python code to perform Exploratory Data Analysis (EDA) on the above project. Include a histogram to combine the length of fake vs real, label distribution, and word cloud.”
We will write a follow-up prompt to add bin edges.
Follow-up Prompt: “Update the EDA code with `np.linspace` to create bin edges from 0 to 200 with 40 bin width.”
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
bins = np.linspace(0, 200, 40)
# Histogram of the length of fake vs real news articles
plt.hist(df['combined_length'].where(df['label'] == 1),bins, alpha=0.5, label='Real')
plt.hist(df['combined_length'].where(df['label'] == 0),bins, alpha=0.5, label='Fake')
plt.xlabel('Combined Text Length')
plt.ylabel('Number of Articles')
plt.legend()
plt.show()It seems like fake news has a longer text length than real news.
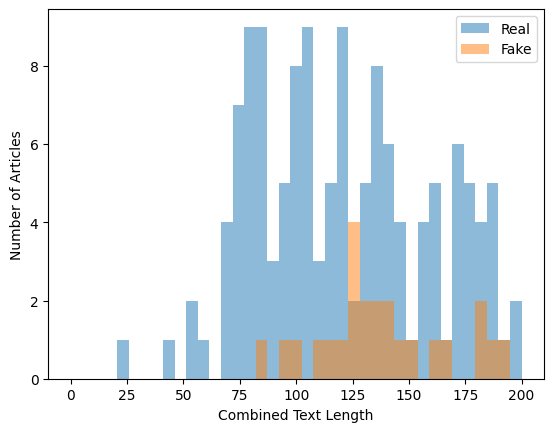
# Label distribution
plt.pie(df['label'].value_counts(), labels=['Fake', 'Real'], autopct='%1.1f%%')
plt.show()The label distribution is fairly equal, and we don’t have to perform class balancing.
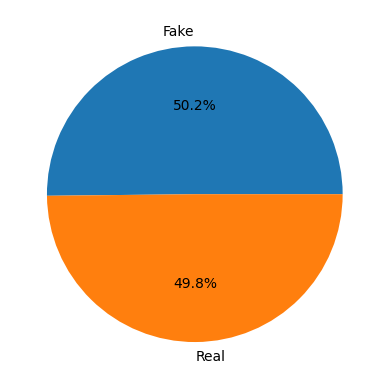
from wordcloud import WordCloud
wc = WordCloud(max_words=100, background_color='white')
wc.generate(' '.join(df[df['label'] == 0]['combined']))
plt.imshow(wc)
plt.axis('off')
plt.title('Word cloud of fake news articles')
plt.show()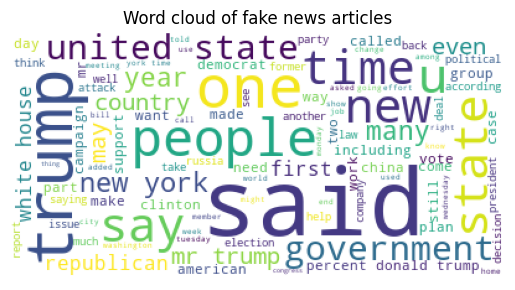
wc = WordCloud(max_words=100, background_color='white')
wc.generate(' '.join(df[df['label'] == 1]['combined']))
plt.imshow(wc)
plt.axis('off')
plt.title('Word cloud of real news articles')
plt.show()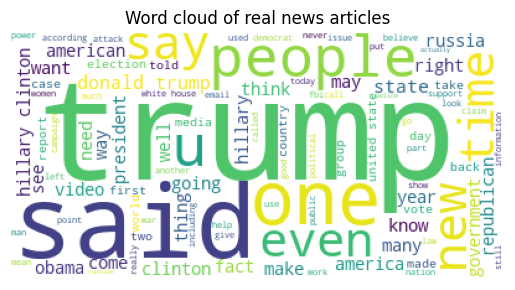
The real news has more prominent words like “trump” and “said” compared to fake news.
Feature Extraction with Bard
In this part, we will write a prompt to convert a “text” column into vectors and split the dataset into train and test datasets.
Prompt: “Convert the text column into vectors and split the dataset into training and testing datasets.”
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
# Convert the text column into vectors
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(df['text'])
# Split the dataset into training and testing datasets
X_train, X_test, y_train, y_test = train_test_split(X, df['label'], test_size=0.25)Bard for Model Selection
With the necessary background information provided, you can now ask straightforward questions.
Prompt: “Perform model selection.”
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Train the models
models = [LogisticRegression(), SVC(), DecisionTreeClassifier(), RandomForestClassifier()]
for model in models:
model.fit(X_train, y_train)
# Evaluate the models
predictions = []
for model in models:
predictions.append(model.predict(X_test))
# Calculate the accuracy of the models
accuracies = []
for predictions in predictions:
accuracies.append(accuracy_score(y_test, predictions))
# Print the accuracy of the models
print("Accuracy of LogisticRegression:", accuracies[0])
print("Accuracy of SVC:", accuracies[1])
print("Accuracy of DecisionTreeClassifier:", accuracies[2])
print("Accuracy of RandomForestClassifier:", accuracies[3])Accuracy of LogisticRegression: 0.9024979854955681
Accuracy of SVC: 0.91941982272361
Accuracy of DecisionTreeClassifier: 0.8767123287671232
Accuracy of RandomForestClassifier: 0.8863819500402901
Based on our analysis, it appears that all of the models we tested have performed relatively well. However, the Support Vector Classifier (SVC) model achieved the highest accuracy score among the tested models.
Hyperparameter Tuning with Bard
We have asked Bard to write a hyperparameter tuning code that saves the optimal model and vector object for deployment.
Prompt: ”Write a Python code for Hyperparameter optimization of SVC. Also, save the best model and vectorizer using Joblib.”
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score,f1_score, classification_report, confusion_matrix
import joblib
# Create a RandomForestClassifier model
svm = SVC()
# Create the hyperparameter grid
param_grid = {'C': [1, 10, 100], 'gamma': [0.01, 0.1, 1]}
# Create the GridSearchCV object
grid = GridSearchCV(SVC(), param_grid, cv=5)
# Fit the GridSearchCV object to the training data
grid.fit(X_train, y_train)
# Print the best parameters
print(grid.best_params_){'C': 10, 'gamma': 0.1}# Predict the labels of the testing data using the best model
y_pred = grid.predict(X_test)
# Calculate the accuracy of the best model
accuracy = accuracy_score(y_test, y_pred)
# Print the accuracy of the best model
print("Accuracy of the best model:", accuracy)The accuracy has improved slightly.
Accuracy of the best model: 0.9298952457695407The saved mode and vector will be used for running the inference.
# Save the best model
joblib.dump(grid.best_estimator_, 'best_model.pkl')
# Save the TfidfVectorizer
joblib.dump(vectorizer, 'tfidf_vectorizer.pkl')Model Evaluation with Bard
Accuracy is not enough for the classification model. We have to test it on the f1-score, recall, precision, and confusion matrix.
Prompt: ”Write a Python code for model evaluation. Include classification report, confusion matrix, and f1 score.”
print(classification_report(y_test, y_pred))According to the report, our model is quite stable on the test dataset.
precision recall f1-score support
0 0.94 0.92 0.93 620
1 0.92 0.94 0.93 621
accuracy 0.93 1241
macro avg 0.93 0.93 0.93 1241
weighted avg 0.93 0.93 0.93 1241# Plot the confusion matrix
print(confusion_matrix(y_test, y_pred))[[572 65]
[ 37 567]]# Calculate the F1 score
f1_score = f1_score(y_test, y_pred, average='weighted')
# Print the F1 score
print("F1 score:", f1_score)F1 score: 0.9298892365447746Using Bard for a Streamlit Webapp
After satisfying the result, we will develop an app that will convert the input text into the vector, pass it through a model, and display the result.
Before that, we have to create a GitHub repository.
Clone the repository and save all the essential components of the application. This step not only ensures their safekeeping but also enables effective versioning of both the app and the model.
git clone https://github.com/kingabzpro/Fake-News-DataCamp-Project.gitWrite a generic prompt to develop an app for predicting if the news is real or fake.
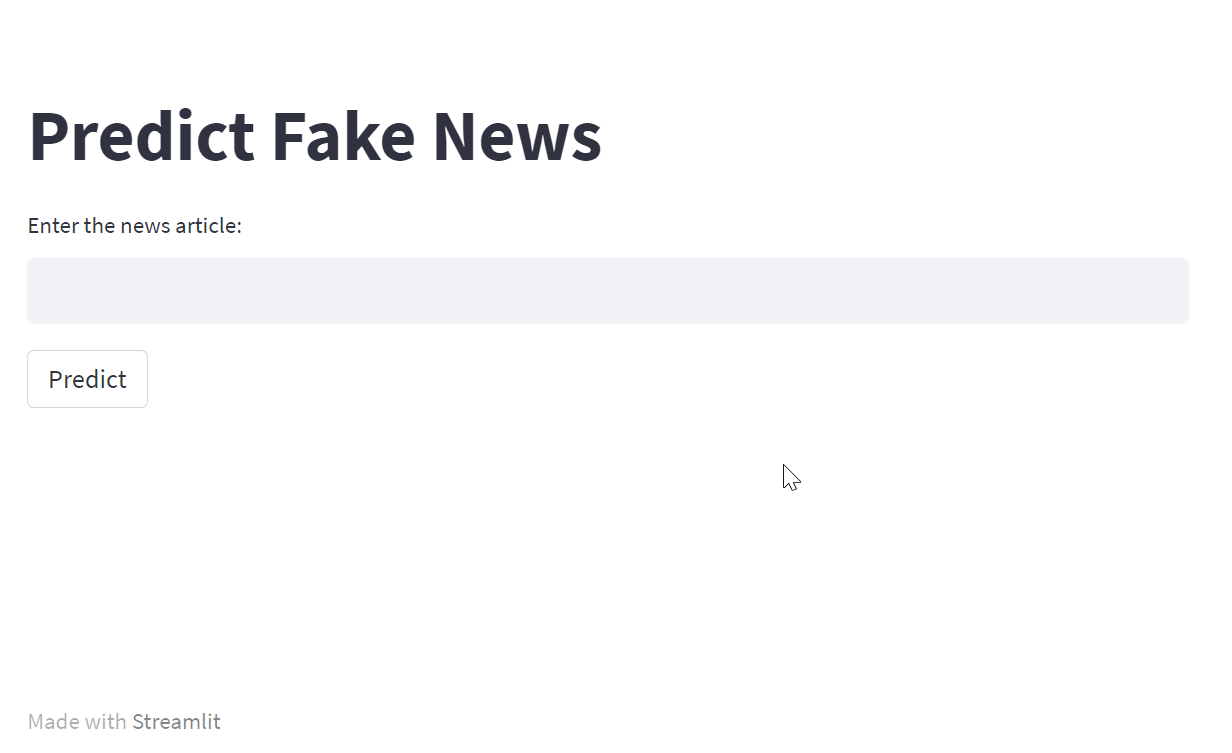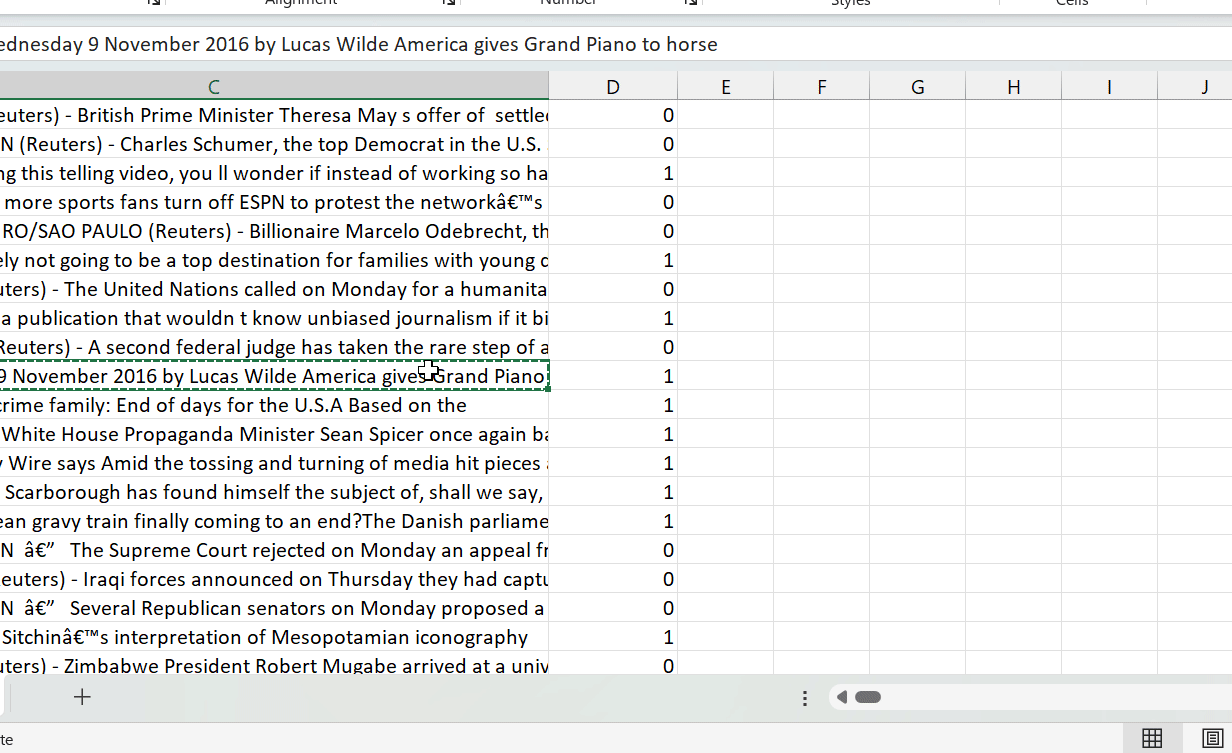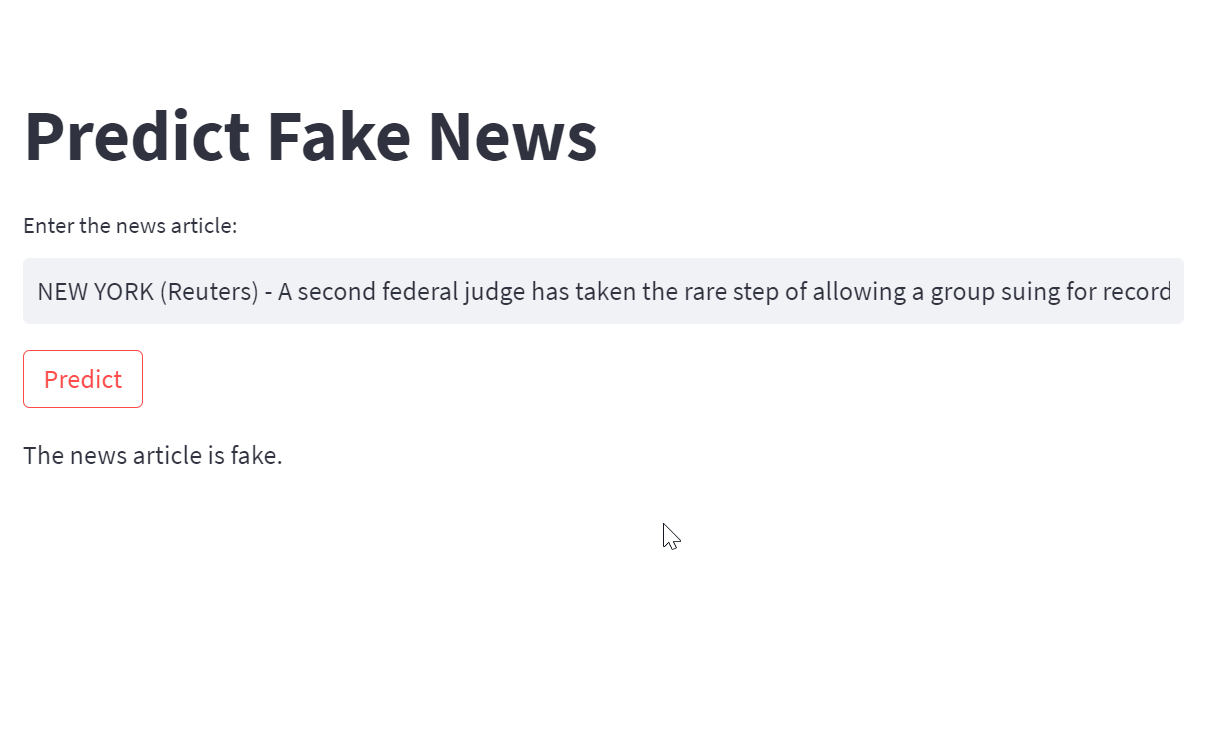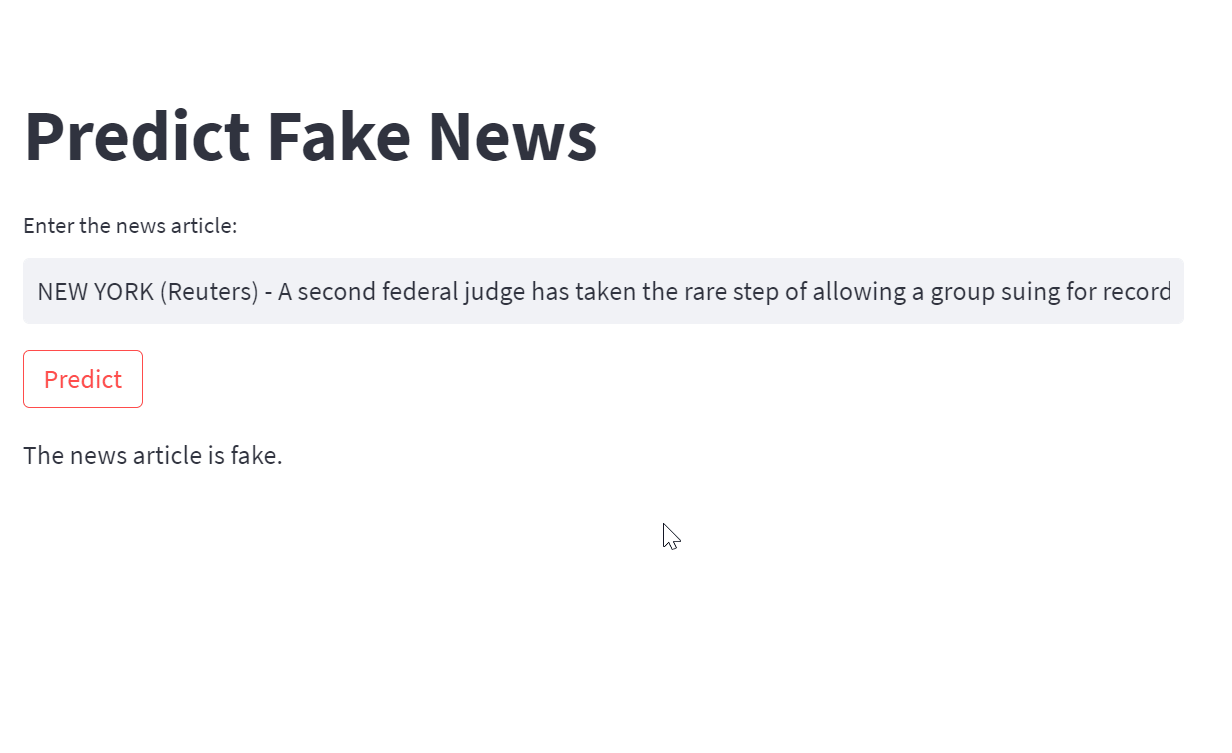
Prompt: “Write a separate Python file for creating a web app using Streamlit to predict if the News is (0 = fake or 1 = real). Just include Streamlit app part.”
Next, let's create an app.py file and transfer the code from Bard into this file. Once done, you can run the application using the command streamlit run app.py.
Note: make sure you have all the required Python packages to run the Streamlit app.
It looks like the Bard failed to load the vectorizer. We can write a follow-up prompt to fix this issue.
Follow-up Prompt: “Add loading Vectorizer and Model in the app file using joblib.”
The app is not working properly, so we must add a run button to fix that issue.
Follow-up Prompt: “Also, add a button to run the inference.”
import streamlit as st
import joblib
# Load the vectorizer
vectorizer = joblib.load("tfidf_vectorizer.pkl")
# Load the model
model = joblib.load("best_model.pkl")
# Create a title
st.title("Predict Fake News")
# Input text
text = st.text_input("Enter the news article:")
# Button to run inference
if st.button("Predict"):
# Convert the text to a vector
vector = vectorizer.transform([text])
# Predict the label
label = model.predict(vector)[0]
# Display the label
if label == 0:
st.write("The news article is fake.")
else:
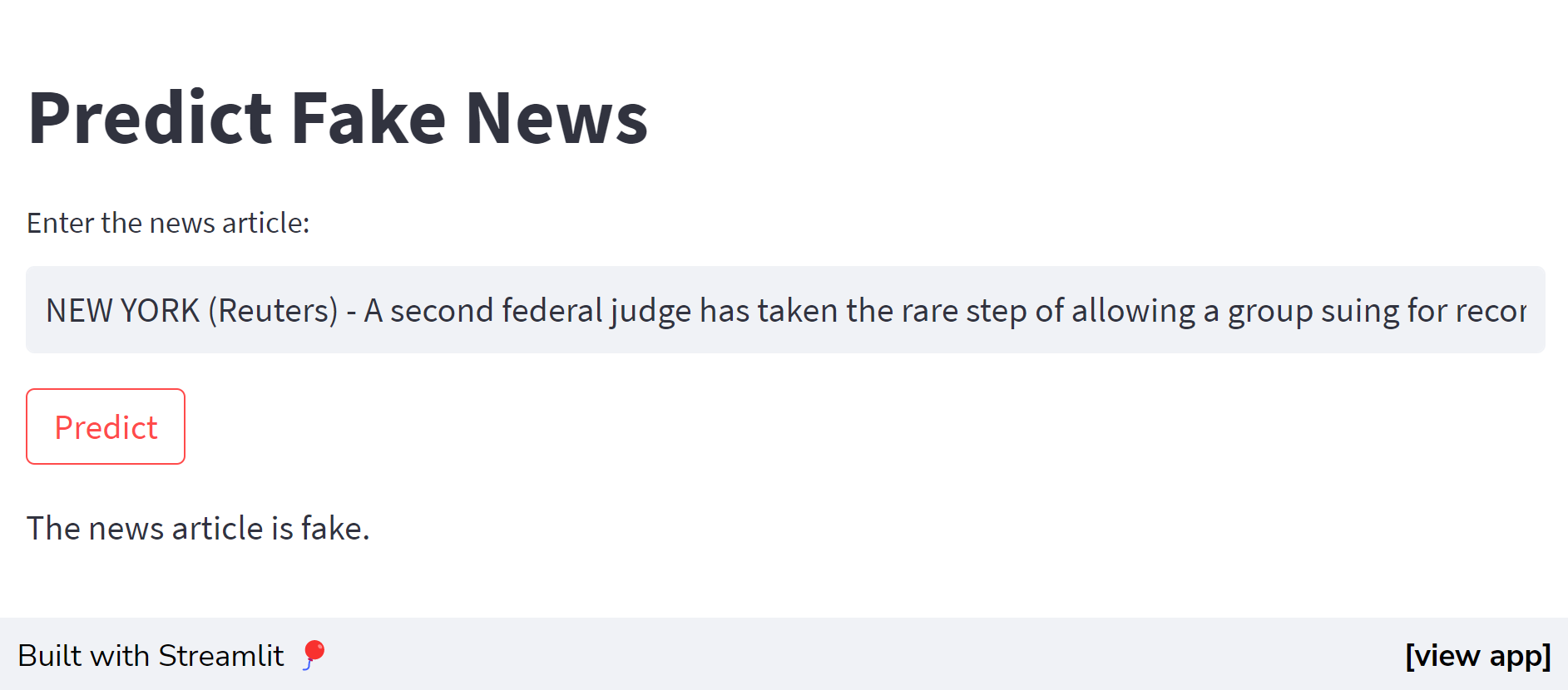
st.write("The news article is real.")We have successfully built a Streamlit app that accepts text input and provides predictions on the authenticity of news articles.
Using Bard for Streamlit Cloud Deployment
To deploy the app to the cloud, we have to ask Bard for help. It turns out we just need to push our code to the GitHub repository and connect it with the Streamlit server.
Prompt: “Help me deploy an app on Streamlit Community Cloud.”
1. Create a requirements.txt file and add all of the required Python packages like “scikit-learn.”
2. Add the files using Git, commit, and push to the external server. Make sure you have added model, vector, app.py, and requirements.txt.
3. Go to share.streamlit.io, click on “New app,” select GitHub repository, and add the required information about the application.
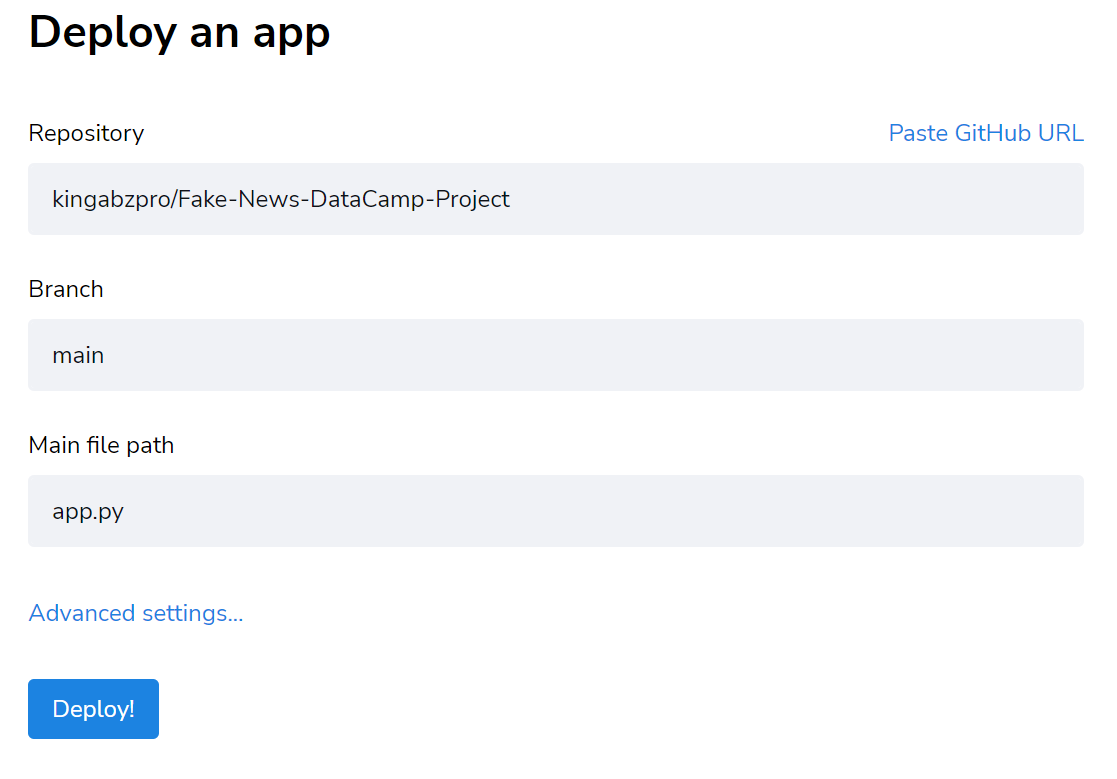
That’s it. Our app is deployed and available for the public at Streamlit (fake-news-detector.streamlit.app).
Conclusion
AI tools such as ChatGPT, Bard, and Claude empower us to excel in our daily data science tasks. Leveraging the capabilities of these tools, we enhance our efficiency and proficiency, enabling us to tackle complex data challenges with ease.
In this post, we explored the power of the new version of Bard for developing comprehensive end-to-end data science projects. You can also check out our guide on Using ChatGPT For Data Science Projects or take a comprehensive ChatGPT course: Introduction to ChatGPT, and discover best practices for writing prompts.
