
Programa
Engenheiro de dados associado em SQL
30 h
A engenharia de dados é altamente técnica, então não é surpresa que a maior parte do seu processo de entrevista envolva perguntas e exercícios técnicos. Nesta seção, vamos falar sobre diferentes tipos de perguntas e respostas técnicas, com foco em perguntas para iniciantes, Python, SQL, baseadas em projetos e de gerenciamento.
As entrevistas para engenheiros juniores focam em ferramentas, Python e consultas SQL. Também podem incluir perguntas sobre gerenciamento de banco de dados e processos ETL, incluindo desafios de codificação e testes para fazer em casa.
Quando as empresas contratam recém-formados, elas querem ter certeza de que você consegue lidar com os dados e sistemas delas de forma eficaz.
Existem três esquemas principais de modelagem de dados: estrela, floco de neve (Snowflake) e galáxia.
Exemplo de esquema em estrela. Imagem de guru99
Exemplo de esquema Snowflake. Imagem de guru99
Exemplo de esquema Galaxy. Imagem de guru99
Ao responder a essa pergunta, fale sobre as ferramentas ETL que você domina e explique por que escolheu ferramentas específicas para determinados projetos. Discuta os prós e contras de cada ferramenta e como elas se encaixam no seu fluxo de trabalho. Ferramentas populares de código aberto incluem:
Se você precisa atualizar seus conhecimentos sobre ETL, considere fazer o curso Introdução à Engenharia de Dados.
A orquestração de dados é um processo automático pra acessar dados brutos de várias fontes, fazer limpeza, transformação e modelagem de dados, e usar isso pra tarefas analíticas. Isso garante que os dados fluam bem entre os diferentes sistemas e etapas do processamento.
Ferramentas populares para orquestração de dados incluem:
A engenharia analítica envolve transformar dados processados, aplicar modelos estatísticos e visualizá-los por meio de relatórios e painéis.
Ferramentas populares para engenharia analítica incluem:
Essas ferramentas ajudam a acessar, transformar e visualizar dados para obter insights significativos e apoiar os processos de tomada de decisão.
O OLAP (Processamento Analítico Online) analisa dados históricos e dá suporte a consultas complexas. É otimizado para cargas de trabalho com muitas leituras e costuma ser usado em warehouse para tarefas de inteligência empresarial. O OLTP ( Processamento de Transações Online) foi feito pra cuidar de dados transacionais em tempo real. É otimizado para cargas de trabalho com muitas gravações e é usado em bancos de dados operacionais para as operações diárias dos negócios.
A principal diferença está no objetivo deles: O OLAP ajuda na tomada de decisões, enquanto o OLTP dá suporte às operações do dia a dia.
Se você ainda tiver dúvidas, recomendo ler a postagem do blog OLTP vs OLAP.
Python é a linguagem mais popular em engenharia de dados por causa da sua versatilidade e do rico ecossistema de bibliotecas disponíveis para processamento, análise e automação de dados. Aqui estão algumas perguntas relacionadas ao Python que você pode encontrar em uma entrevista de engenharia de dados.
As bibliotecas de processamento de dados mais populares em Python incluem:
Cada uma dessas bibliotecas tem prós e contras, e a escolha depende dos requisitos específicos dos dados e da escala das tarefas de processamento de dados.
A extração de dados da web em Python geralmente envolve as seguintes etapas:
1. Acesse a página da web usando a biblioteca requests:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')2. Extraia tabelas e informações usando o BeautifulSoup:
tables = soup.find_all('table')3. Converta para um formato estruturado usando pandas:
import pandas as pd
data = []
for table in tables:
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append(cols)
df = pd.DataFrame(data)4. Limpe os dados usando pandas e NumPy:
df.dropna(inplace=True) # Drop missing values5. Salve os dados como um arquivo CSV:
df.to_csv('scraped_data.csv', index=False)Em alguns casos, pandas.read_html pode facilitar o processo:
df_list = pd.read_html('http://example.com')
df = df_list[0] # Assuming the table of interest is the first onePara lidar com grandes conjuntos de dados que não cabem na memória, é preciso usar ferramentas e técnicas feitas para computação fora do núcleo:
import dask.dataframe as dd
df = dd.read_csv('large_dataset.csv')from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('data_processing').getOrCreate()
df = spark.read.csv('large_dataset.csv', header=True, inferSchema=True)import pandas as pd
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
process(chunk) # Replace with your processing functionPara garantir que o código Python seja eficiente e otimizado para desempenho, considere as seguintes práticas:
cProfile, line_profiler ou memory_profiler para identificar gargalos no seu código.import cProfile
cProfile.run('your_function()')numpy ou pandas para operações vetorizadas em vez de loops.import numpy as np
data = np.array([1, 2, 3, 4, 5])
result = data * 2 # Vectorized operationdata_dict = {'key1': 'value1', 'key2': 'value2'} # Faster lookups compared to listsfrom multiprocessing import Pool
def process_data(data_chunk):
# Your processing logic here
return processed_chunk
with Pool(processes=4) as pool:
results = pool.map(process_data, data_chunks)from functools import lru_cache
@lru_cache(maxsize=None)
def expensive_computation(x):
# Perform expensive computation
return resultA integridade e a qualidade dos dados são importantes para uma engenharia de dados confiável. As melhores práticas incluem:
def validate_data(df):
assert df['age'].min() >= 0, "Age cannot be negative"
assert df['salary'].dtype == 'float64', "Salary should be a float"
# Additional checks...pandas para limpar e pré-processar dados, lidando com valores ausentes, removendo duplicatas e corrigindo erros. df.dropna(inplace=True) # Drop missing values
df.drop_duplicates(inplace=True) # Remove duplicatespytest.import pytest
def test_clean_data():
raw_data = pd.DataFrame({'age': [25, -3], 'salary': ['50k', '60k']})
clean_data = clean_data_function(raw_data)
assert clean_data['age'].min() >= 0
assert clean_data['salary'].dtype == 'float64' from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.email_operator import EmailOperator
# Define your DAG and tasks...Lidar com dados ausentes é uma tarefa comum na engenharia de dados. As abordagens incluem:
df.dropna(inplace=True) df['column'].fillna(df['column'].mean(), inplace=True) df['column_missing'] = df['column'].isnull().astype(int) from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)Pra lidar com os limites de taxa da API, tem estratégias como:
Exemplo usando a biblioteca Python time e o módulo requests:
import time
import requests
def fetch_data_with_rate_limit(url):
for attempt in range(5): # Retry up to 5 times
response = requests.get(url)
if response.status_code == 429: # Too many requests
time.sleep(2 ** attempt) # Exponential backoff
else:
return response.json()
raise Exception("Rate limit exceeded")Python é, sem dúvida, uma das linguagens mais importantes na engenharia de dados. Você pode aprimorar suas habilidades fazendo nosso programa de Engenheiro de Dados em Python, que tem um currículo completo pra te dar conceitos modernos de engenharia de dados, linguagens de programação, ferramentas e estruturas.
A etapa de codificação SQL é uma parte importante do processo de contratação de engenheiros de dados. Praticar vários scripts simples e complexos pode te ajudar a se preparar. Os entrevistadores podem pedir pra você escrever consultas pra análise de dados, expressões de tabela comum, classificação, adicionar subtotais e funções temporárias.
Os CTEs são usados para simplificar junções complexas e executar subconsultas. Elas ajudam a tornar as consultas SQL mais legíveis e fáceis de manter. Aqui está um exemplo de uma CTE que mostra todos os alunos com especialização em Ciências e nota A:
SELECT *
FROM class
WHERE id IN (
SELECT DISTINCT id
FROM students
WHERE grade = "A"
AND major = "Science"
);Usando um CTE, a consulta fica assim:
WITH temp AS (
SELECT id
FROM students
WHERE grade = "A"
AND major = "Science"
)
SELECT *
FROM class
WHERE id IN (SELECT id FROM temp);Os CTEs podem ser usados para problemas mais complexos e vários CTEs podem ser encadeados.
Os engenheiros de dados geralmente classificam os valores com base em parâmetros como vendas e lucro. A função ` RANK() ` é usada para classificar dados com base em uma coluna específica:
SELECT
id,
sales,
RANK() OVER (ORDER BY sales DESC) AS rank
FROM bill;Como alternativa, você pode usar DENSE_RANK(), que não pula as classificações seguintes se os valores forem iguais.
Assim como no Python, você pode criar funções em SQL para deixar suas consultas mais elegantes e evitar declarações case repetitivas. Aqui está um exemplo de uma função temporária get_gender:
CREATE TEMPORARY FUNCTION get_gender(type VARCHAR) RETURNS VARCHAR AS (
CASE
WHEN type = "M" THEN "male"
WHEN type = "F" THEN "female"
ELSE "n/a"
END
);
SELECT
name,
get_gender(type) AS gender
FROM class;Essa abordagem deixa seu código SQL mais limpo e fácil de manter.
Pode adicionar subtotais usando as funções GROUP BY e ROLLUP(). Aqui vai um exemplo:
SELECT
department,
product,
SUM(sales) AS total_sales
FROM sales_data
GROUP BY ROLLUP(department, product);Essa consulta vai te dar um subtotal para cada departamento e um total geral no final.
Lidar com dados ausentes é essencial para manter a integridade dos dados. Abordagens comuns incluem:
COALESCE(): Essa função mostra o primeiro valor que não é nulo na lista.SELECT id, COALESCE(salary, 0) AS salary FROM employees;CASE `: Para lidar com valores ausentes de forma condicional. SELECT id,
CASE
WHEN salary IS NULL THEN 0
ELSE salary
END AS salary
FROM employees;A agregação de dados envolve o uso de funções agregadas como SUM(), AVG(), COUNT(), MIN() e MAX(). Aqui vai um exemplo:
SELECT department,
SUM(salary) AS total_salary,
AVG(salary) AS average_salary,
COUNT(*) AS employee_count
FROM employees
GROUP BY department;Para otimizar consultas SQL, você pode:
SELECT * ” especificando apenas as colunas necessárias.EXPLAIN ANALYZE
SELECT customer_id, COUNT(order_id)
FROM orders
GROUP BY customer_id;Resolver exercícios de codificação SQL é a melhor maneira de praticar e revisar conceitos esquecidos. Você pode avaliar suas habilidades em SQL fazendo o teste de Análise de Dados em SQL do DataCamp (você vai precisar de uma conta para acessar essa avaliação).
Depois das rodadas gerais de entrevistas, você geralmente passa para uma etapa técnica que inclui desafios de programação, resolução de problemas, desenho de sistemas de banco de dados em um quadro branco, uma prova para fazer em casa e perguntas analíticas.
Essa etapa pode ser bem intensa, então conhecer algumas das perguntas e respostas mais comuns em entrevistas de engenharia de dados pode te ajudar a se sair bem na entrevista.
Essa resposta deve surgir naturalmente se você já trabalhou em um projeto de engenharia de dados como estudante ou profissional. Dito isso, se preparar com antecedência é sempre útil. Veja como organizar sua resposta:
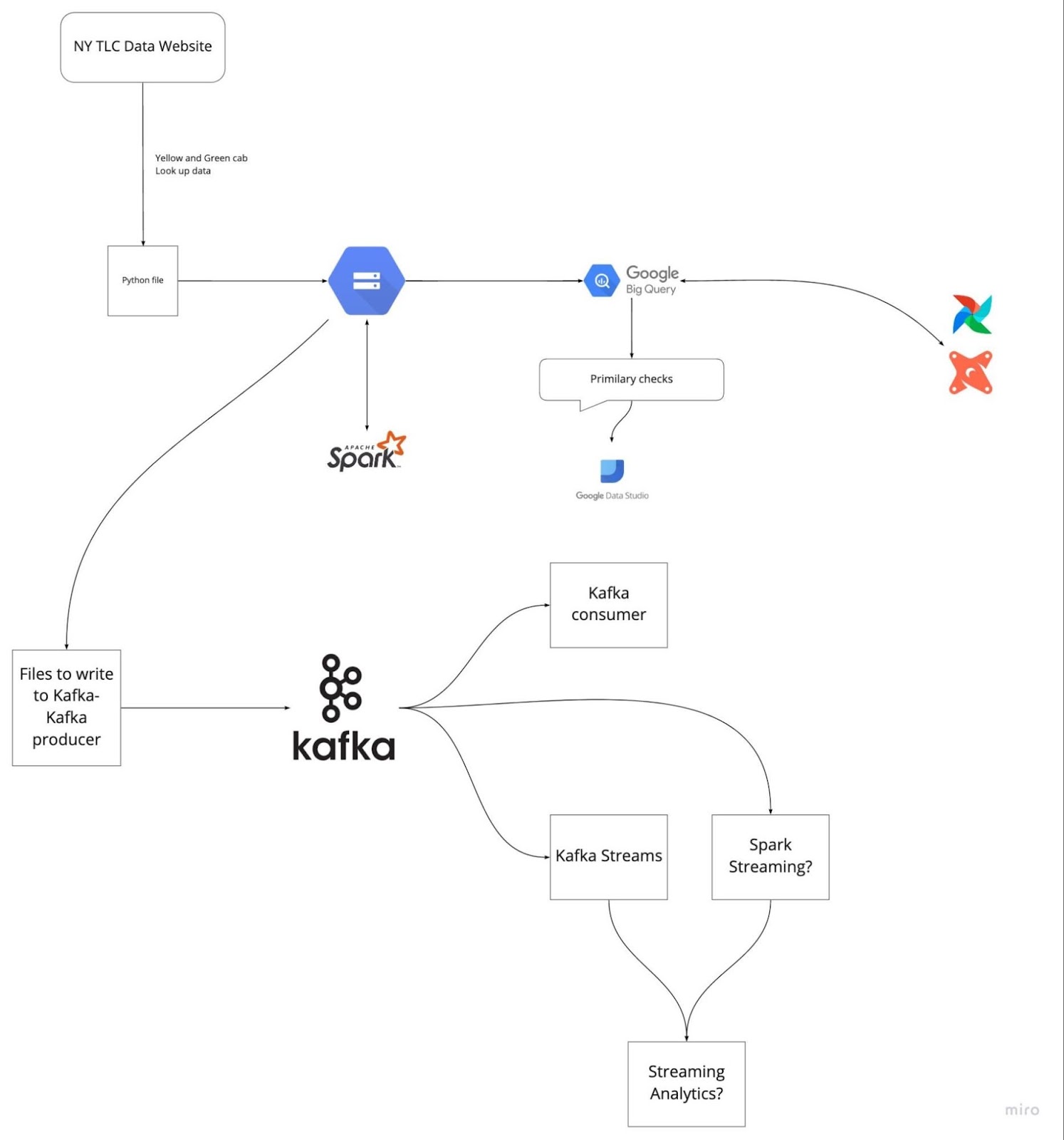
Image from DataTalksClub/data-engineering-zoomcamp
Se você se preparar antes, dando uma olhada nos últimos cinco projetos em que trabalhou, vai conseguir evitar aquele frio na barriga durante a entrevista. Entenda o problema e as soluções que você implementou. Pratique explicar cada etapa de forma clara e direta.
Para cargos de gerente de engenharia, as perguntas geralmente são sobre tomada de decisões, entendimento do negócio, organização e manutenção de conjuntos de dados, conformidade e políticas de segurança.
Um data warehouse fornece dados históricos para tarefas de análise de dados e tomada de decisões. Ele suporta processamento analítico de alto volume, como Processamento Analítico Online (OLAP). Os data warehouses são feitos pra lidar com consultas complexas que acessam várias linhas e são otimizados pra operações que exigem muita leitura. Eles suportam alguns usuários simultâneos e são projetados para recuperar grandes volumes de dados de forma rápida e eficiente.
Os sistemas operacionais de gerenciamento de banco de dados (OLTP) cuidam de conjuntos de dados dinâmicos em tempo real. Eles suportam o processamento de transações de alto volume para milhares de clientes simultâneos, tornando-os adequados para operações diárias. Os dados geralmente consistem em informações atuais e atualizadas sobre transações e operações comerciais. Os sistemas OLTP são otimizados para operações com muitas gravações e processamento rápido de consultas.
A gestão de desastres é responsabilidade de um gerente de engenharia de dados. Um plano de recuperação de desastres garante que os sistemas de dados possam ser restaurados e continuar funcionando em caso de um ataque cibernético, falha de hardware, desastre natural ou outros eventos catastróficos. Os pontos importantes são:
Como gerente de engenharia de dados, tomar decisões envolve equilibrar considerações técnicas com objetivos de negócios. Algumas abordagens incluem:
Cumprir as regras de proteção de dados envolve várias práticas, tipo:
Ao discutir um projeto desafiador, você pode se concentrar nos seguintes aspectos:
Avaliar e implementar novas tecnologias de dados envolve:
Uma maneira eficaz de priorizar tarefas é com base no impacto delas nos objetivos de negócios e na urgência. Você pode usar estruturas como a Matriz de Eisenhower para categorizar tarefas em quatro quadrantes: urgentes e importantes, importantes, mas não urgentes, urgentes, mas não importantes, e nenhuma das duas coisas. Além disso, converse com as pessoas envolvidas para combinar as prioridades e garantir que a equipe se concentre nas atividades mais importantes.
Nesta seção, vamos ver as perguntas mais frequentes em entrevistas de engenharia de dados feitas por gerentes do Facebook, Amazon e Google para vagas nessa área.
Um cluster Kafka é composto por vários brokers que distribuem dados por várias instâncias. Essa arquitetura oferece escalabilidade e tolerância a falhas sem tempo de inatividade. Se o cluster principal parar de funcionar, outros clusters Kafka podem oferecer os mesmos serviços, garantindo alta disponibilidade.
A arquitetura do cluster Kafka inclui Tópicos, Corretores, ZooKeeper, Produtores e Consumidores. Ele lida com fluxos de dados de forma eficiente para aplicações de big data, permitindo a criação de aplicações robustas baseadas em dados.
O Apache Airflow permite que você gerencie e programe pipelines para fluxos de trabalho analíticos, gerenciamento de warehouse e transformação e modelagem de dados. Ele oferece:
Pra saber se um endereço IP tá certo, dá pra dividir a sequência de caracteres em “.” e fazer várias verificações pra validar cada parte. Aqui está uma função Python para fazer isso:
def is_valid(ip):
ip = ip.split(".")
for i in ip:
if len(i) > 3 or int(i) < 0 or int(i) > 255:
return False
if len(i) > 1 and int(i) == 0:
return False
if len(i) > 1 and int(i) != 0 and i[0] == '0':
return False
return True
A = "255.255.11.135"
B = "255.050.11.5345"
print(is_valid(A)) # True
print(is_valid(B)) # FalseO Hadoop funciona principalmente em três modos:
DISTINCT Para lidar com duplicatas no SQL, você pode usar a palavra-chave `DUPLICATE` ou excluir linhas duplicadas usando ` ROWID ` com a função ` MAX ` ou ` MIN `. Aqui estão alguns exemplos:
Usando DISTINCT:
SELECT DISTINCT Name, ADDRESS
FROM CUSTOMERS
ORDER BY Name;Apagando duplicatas usando o ROWID:
DELETE FROM Employee
WHERE ROWID NOT IN (
SELECT MAX(ROWID)
FROM Employee
GROUP BY Name, ADDRESS
);Esse desafio comum de codificação pode ser resolvido usando uma abordagem matemática:
def search_missing_number(list_num):
n = len(list_num)
# Check if the first or last number is missing
if list_num[0] != 1:
return 1
if list_num[-1] != n + 1:
return n + 1
# Calculate the sum of the first n+1 natural numbers
total = (n + 1) * (n + 2) // 2
# Calculate the sum of all elements in the list
sum_of_L = sum(list_num)
# Return the difference, which is the missing number
return total - sum_of_L
# Validation
num_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13]
print("The missing number is", search_missing_number(num_list)) # The missing number is 12Antes de ir para uma entrevista, você deve revisar todos os conceitos e termos padrão usados em engenharia de dados. Aqui estão algumas das áreas mais importantes em que você deve se concentrar:
Preparar-se para uma entrevista de engenharia de dados pode ser desafiador, mas com os recursos certos e prática, você pode se destacar e conseguir o emprego dos seus sonhos. Para melhorar ainda mais suas habilidades e conhecimentos, confira estes recursos valiosos:
Aproveite esses cursos para fortalecer sua base e se manter à frente na sua carreira em engenharia de dados. Boa sorte nas entrevistas!
Aprenda mais sobre engenharia de dados com esses cursos!
Programa
Programa
Curso
blog
Tim Lu
9 min
blog
Javier Canales Luna
15 min
blog
Nisha Arya Ahmed
15 min
blog
Javier Canales Luna
15 min
blog
Srujana Maddula
15 min
blog
Javier Canales Luna
15 min


