
Programa
Fundamentos do Negócio de IA
12 h
Os modelos de raciocínio estão se tornando mais importantes e comuns, e podemos ver por quê. Se você observar o gráfico abaixo, verá que 37,2% dos usuários confiam no Claude para questões de codificação e matemática, de acordo com o Índice Econômico Antrópico. Isso me diz uma coisa: modelos de raciocínio sólidos podem trazer um valor comercial real, especialmente porque a adoção da IA em ambientes corporativos continua baixa.
Fonte: Índice econômico antrófico
Ao mesmo tempo, o Claude 3.7 não é apenas um modelo de raciocínio - é um híbrido. Podemos alternar entre o Modo de Pensamento (para tarefas de raciocínio estruturado) e um modo de bate-papo padrão para conversas gerais, redação e resumo.
O Claude 3.7 Sonnet é uma atualização muito maior do que o número da versão sugere. Os dados de benchmark confirmam que ele supera o desempenho do Claude 3.5 Sonnet em raciocínio, codificação e execução de tarefas no mundo real.
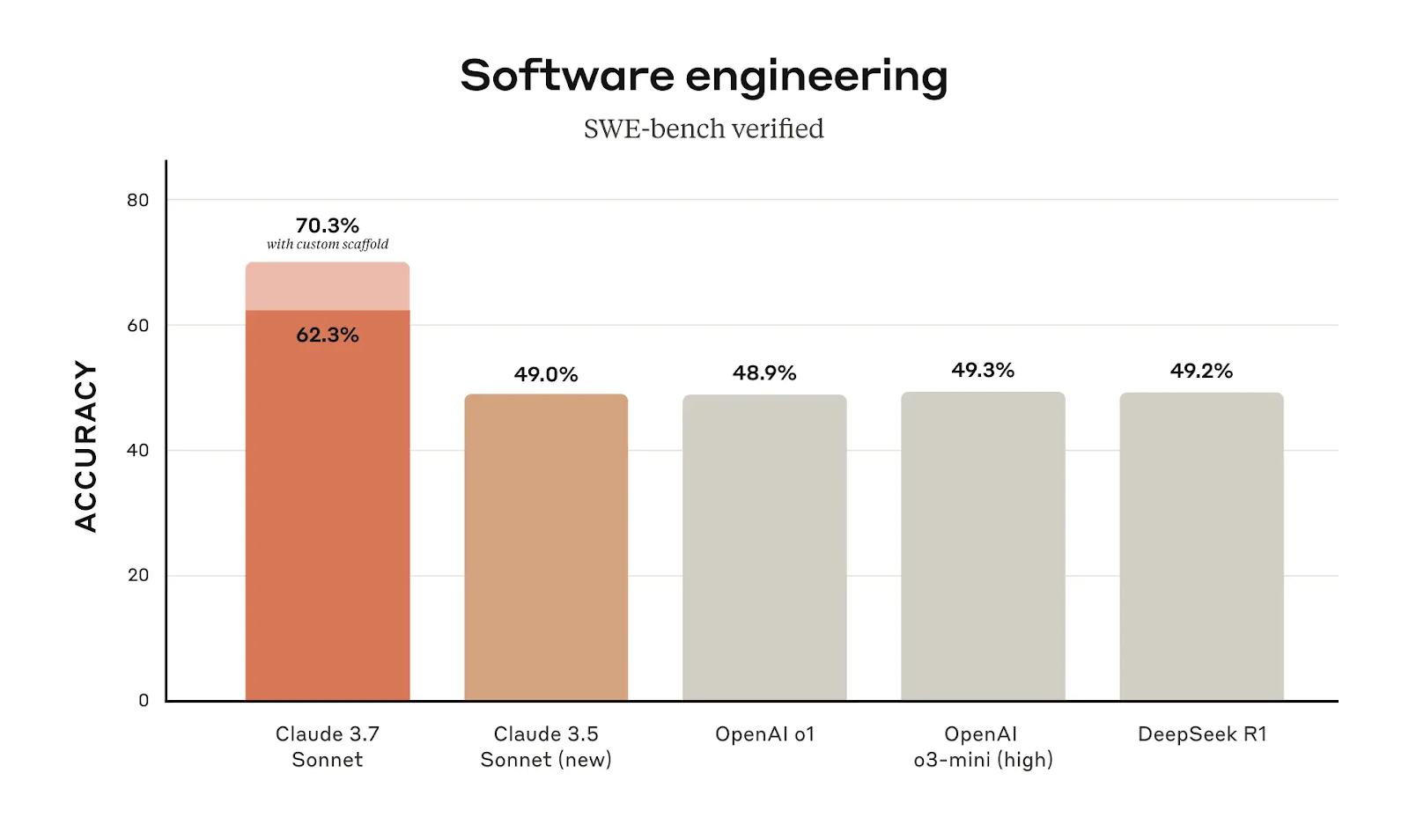
O Claude 3.7 Sonnet mostra uma clara vantagem em engenharia de software, com uma pontuação de precisão de 62,3% no SWE-bench Verified, um salto significativo em relação aos 49,0% do Claude 3.5 Sonnet. Ao usar um scaffold personalizado (um prompt estruturado ou contexto adicional que ajuda a orientar a resposta do modelo para uma solução mais precisa), essa precisão aumenta para 70,3%, tornando-o o modelo com melhor desempenho nessa categoria.
Fonte: Antrópico
Uma melhoria de quase 13% na precisão entre as versões do modelo não é apenas um pequeno refinamento. Isso sugere que o Claude 3.7 Sonnet foi otimizado para melhor compreensão e execução de tarefas relacionadas à programação. Para os usuários que dependem do Claude para engenharia de software, depuração ou automação, a atualização faz uma diferença tangível.
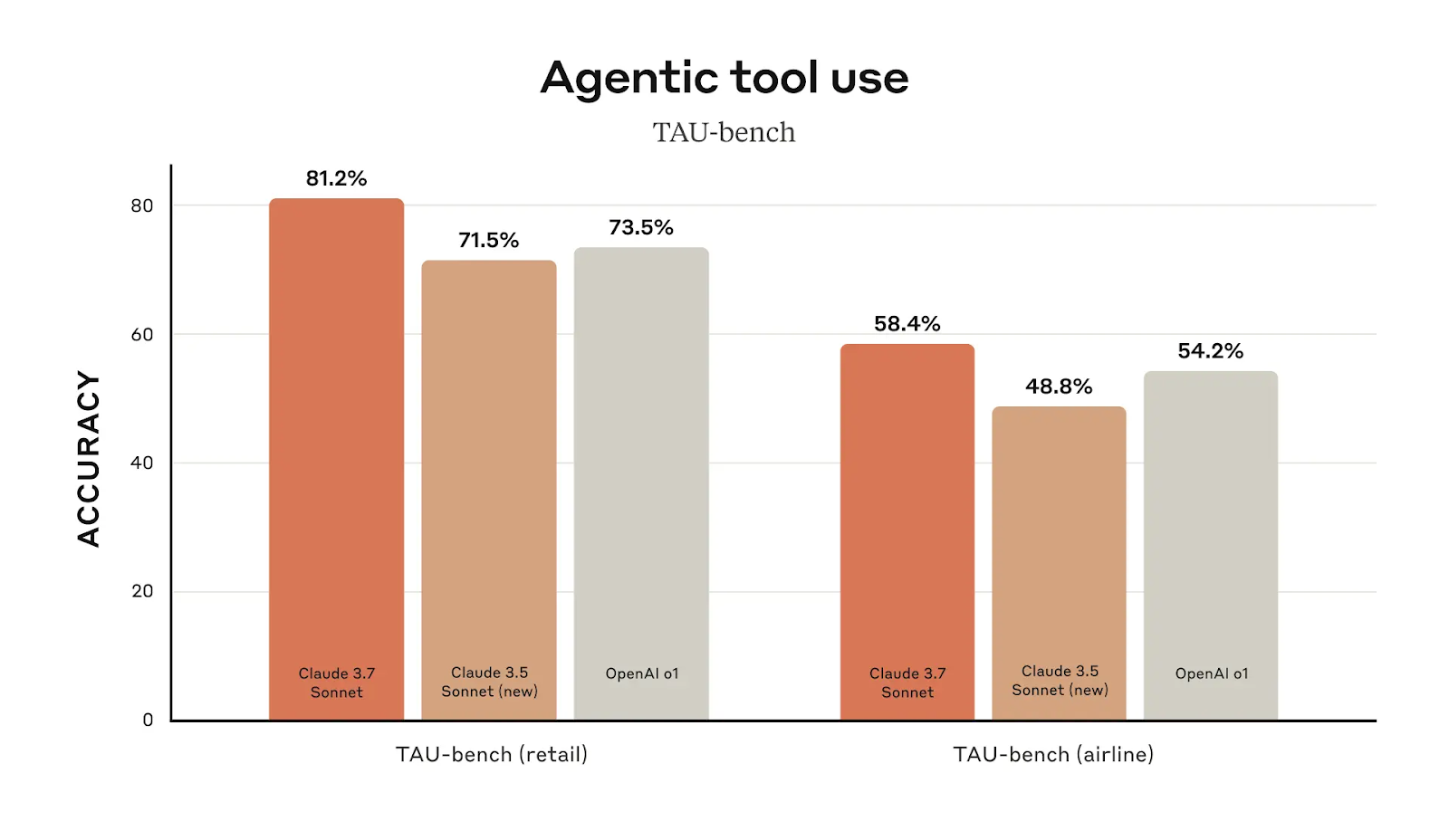
O desempenho no uso da ferramenta agêntica é outra área em que o Claude 3.7 Sonnet supera seu antecessor. Em tarefas relacionadas ao varejo, ele atinge 81,2% de precisão, acima dos 71,5% do Claude 3.5 Sonnet. Em tarefas relacionadas a companhias aéreas, a pontuação é de 58,4%, uma melhoria de quase dez pontos em relação à versão anterior.
Fonte: Antrópico
Em todos os benchmarks, os maiores ganhos vêm do modo de raciocínio estendido, que permite que o Claude 3.7 tenha um desempenho muito superior em tarefas de raciocínio complexas. Os usuários que dependem da IA para fluxos de trabalho estruturados, codificação ou solução de problemas verão uma clara diferença entre o Claude 3.5 e o Claude 3.7, especialmente ao usar o pensamento estendido.
Fonte: Antrópico
A maior parte desse progresso vem do pensamento estendido de Claude, portanto, vamos descobrir mais sobre isso.
Quando ativado, o modo de raciocínio estendido aumenta o número de etapas de raciocínio que o Claude executa antes de finalizar uma resposta. Os desenvolvedores podem ajustar esse processo definindo um orçamento de raciocínio, que define quantos tokens o modelo pode usar ao resolver um problema. Conforme mostrado no gráfico de desempenho do AIME 2024 abaixo, a precisão melhora à medida que mais tokens são alocados, seguindo uma tendência logarítmica.
Fonte: Antrópico
Essa abordagem reflete o esforço cognitivo humano: para tarefas simples, respostas rápidas são suficientes, mas para tarefas complexas, uma análise mais profunda leva a melhores resultados. Agora, o Claude pode decidir quando fazer uma pausa, reavaliar e refinar seu raciocínio, em vez de optar por respostas imediatas.
Um dos aspectos mais interessantes do modo de pensamento estendido é que o processo de raciocínio do Claude é visível para o usuário. No entanto, esse recurso apresenta alguns desafios. Embora forneça informações sobre o raciocínio da IA, o processo de pensamento exibido pode nem sempre estar perfeitamente alinhado com a forma como o modelo realmente toma decisões. O "problema da fidelidade" - se os pensamentos relatados por uma IA representam com precisão sua mecânica interna - ainda é uma questão de pesquisa em aberto.
Claude 3.7 A capacidade do Sonnet de se envolver em raciocínio iterativo de longo prazo é testada em avaliações como OSWorld e jogabilidade do Pokémon Red. No Pokémon Red, por exemplo, o Claude 3.7 Sonnet alcança uma progressão muito maior no jogo do que as versões anteriores, passando por vários marcos, enquanto os modelos anteriores ficam presos no início do jogo.
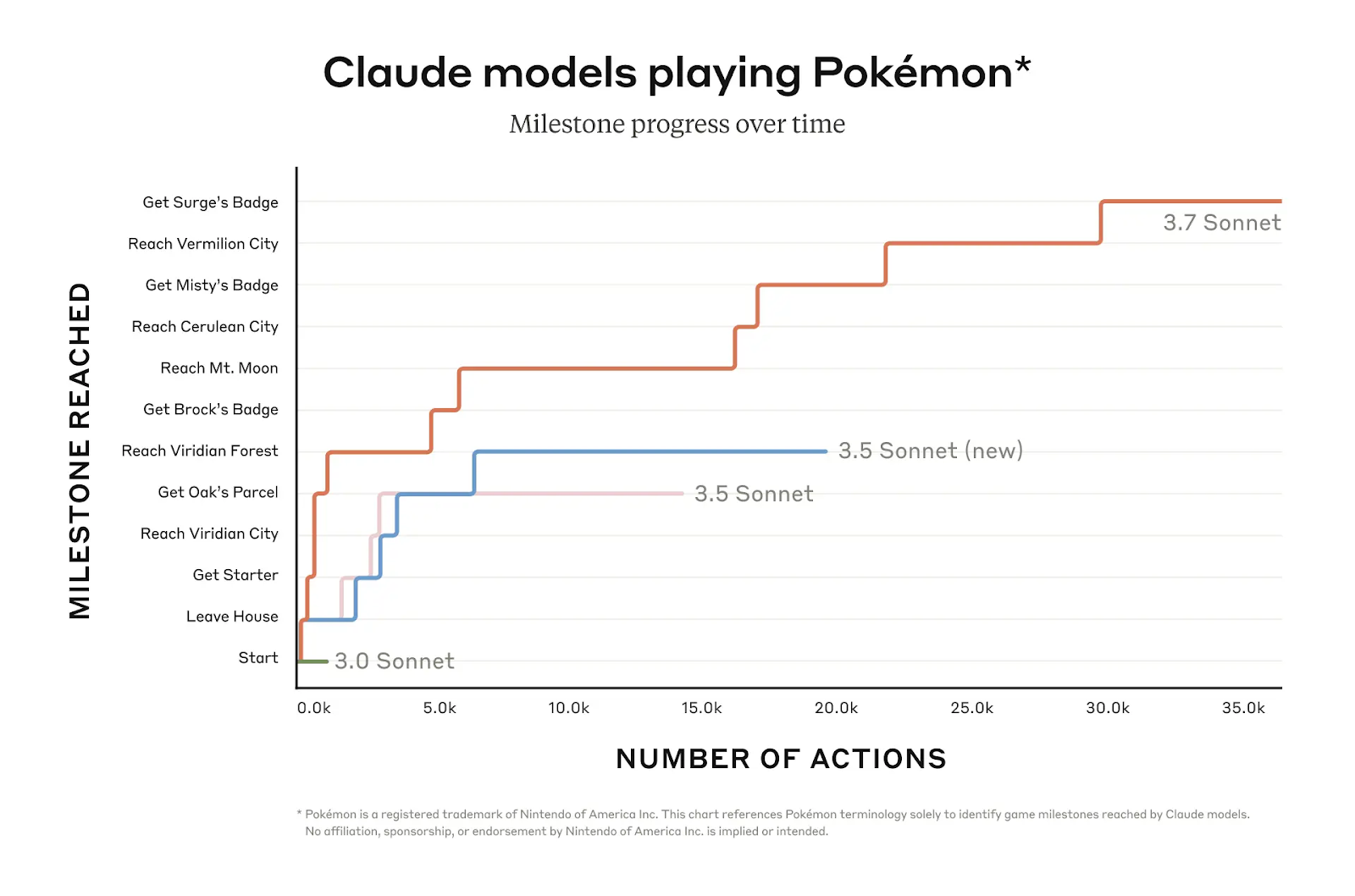
Fonte: Antrópico
Já vimos o desempenho do Claude 3.7 Sonnet em relação à sua versão anterior, mas como ele se compara ao o3-mini da OpenAI, ao DeepSeek-R1 ou ao Grok 3?
Analisando os benchmarks atualizados, o Claude 3.7 Sonnet se posicionou como um dos modelos de melhor desempenho, especialmente em tarefas de raciocínio pesado, codificação e uso de ferramentas agênticas.
No raciocínio em nível de pós-graduação (GPQA Diamond), o Claude 3.7 Sonnet pontua 68,0% no modo padrão e 84,8% no modo de pensamento estendido, o que o torna um dos modelos mais fortes nessa categoria. Ele supera o o1 da OpenAI (78,0%) e o DeepSeek-R1 (71,5%) em uma quantidade significativa e o Grok 3 Beta (84,6%) por apenas uma pequena margem.
|
Benchmark |
Claude 3.7 Soneto (padrão) |
Claude 3.7 Soneto (Pensamento estendido) |
OpenAI o1 |
OpenAI o3-mini (alto) |
DeepSeek R1 |
Grok 3 Beta |
|
GPQA Diamond (raciocínio em nível de graduação) |
68.0% |
84.8% |
78.0% |
79.7% |
71.5% |
84.6% |
|
AIME 2024 (competição de matemática do ensino médio) |
23.3% |
80.0% |
83.3% |
87.3% |
79.8% |
93.3% |
|
Resolução de problemas matemáticos (MATH 500) |
82.2% |
96.2% |
96.4% |
97.9% |
97.3% |
- |
O benchmark AIME 2024, que testa problemas de competição de matemática do ensino médio, mostra uma tendência semelhante. O Claude 3.7 Sonnet dá um grande salto em relação às versões anteriores, com 80,0% de pontuação com o pensamento estendido ativado. Embora supere o DeepSeek-R1 (79,8%) por uma pequena margem, ele ainda fica atrás do o3-mini da OpenAI (87,3%) e do Grok 3 Beta (93,3%).
Na resolução de problemas de matemática (MATH 500), o Claude 3.7 Sonnet atinge 96,2%, ficando muito próximo do o3-mini da OpenAI (97,9%) e do DeepSeek R1 (97,3%).
Claude 3.7 O Sonnet obtém seus maiores ganhos em benchmarks de codificação. No SWE-bench Verified (que avalia modelos de IA em tarefas de engenharia de software), o Claude 3.7 Sonnet obteve 62,3% de pontuação, aumentando para 70,3% com um scaffold personalizado. Isso o coloca muito à frente do o1 (48,9%) e do o3-mini (49,3%) da OpenAI, bem como do DeepSeek R1 (49,2%), que foi projetado com a codificação em mente. Isso confirma que o Claude 3.7 é agora um dos melhores models de IA para tarefas relacionadas à programação.
|
Benchmark |
Claude 3.7 Soneto (padrão) |
Claude 3.7 Soneto (andaime personalizado) |
OpenAI o1 |
OpenAI o3-mini (alto) |
DeepSeek R1 |
|
SWE-bench Verificado (Codificação) |
62.3% |
70.3% |
48.9% |
49.3% |
49.2% |
|
TAU-bench Retail (uso de ferramentas) |
81.2% |
- |
73.5% |
- |
- |
|
TAU-bench Airline (uso de ferramentas) |
58.4% |
- |
54.2% |
- |
- |
Além da codificação, o Claude 3.7 Sonnet é líder no uso de ferramentas agênticas, o que o torna uma excelente opção para automação e execução de fluxo de trabalho. No TAU-bench (que testa a capacidade da IA de interagir com ferramentas externas em ambientes estruturados), o Claude 3.7 obteve uma pontuação de 81,2% em tarefas relacionadas ao varejo, superando o OpenAI o1 (73,5%). Em tarefas relacionadas a companhias aéreas, o Claude 3.7 atinge 58,4%, superando novamente o OpenAI o1 (54,2%).
Isso sugere que o Claude 3.7 é adequado para aplicativos de negócios e fluxos de trabalho estruturados, o que o torna uma boa opção para usuários corporativos que desejam integrar a IA em seus processos operacionais e de tomada de decisões.
O Claude 3.7 Sonnet está disponível por meio de vários canais, incluindo a interface da Web do Anthropic, a integração do Claude em vários aplicativos e o acesso à API para desenvolvedores. Embora o modelo seja uma atualização significativa, sua disponibilidade vem com algumas limitações - especialmente se você quiser usar o Modo Pensamento, que atualmente está bloqueado em um nível pago.
Para usuários em geral, o Claude 3.7 Sonnet pode ser acessado pelo site oficial do Anthropic (claude.ai) e do aplicativo Claude. Ele está disponível no nível gratuito, mas com restrições:
Para ativar o Thinking Mode, você precisa clicar em Estendido no menu suspenso do modelo:
Os desenvolvedores podem integrar o Claude 3.7 Sonnet em seus aplicativos usando a API do Anthropic, que pode ser acessada pelo portal do desenvolvedor do Anthropic. A API oferece suporte a um modelo de preço pago conforme o uso, com base no uso do token.
Aqui você encontra uma visão geral das ofertas de API do Anthropic:
|
Recurso |
Claude 3.7 Soneto |
Claude 3.5 Soneto |
Claude 3.5 Haiku |
Claude 3 Opus |
Claude 3 Haiku |
|
Descrição |
Nosso modelo mais inteligente |
Nosso modelo mais inteligente anterior |
Nosso modelo mais rápido |
Modelo avançado para tarefas complexas |
O modelo mais rápido e compacto para uma capacidade de resposta quase instantânea |
|
Pontos fortes |
O mais alto nível de inteligência e capacidade com pensamento estendido alternável |
Alto nível de inteligência e capacidade |
Inteligência em alta velocidade |
Inteligência, fluência e compreensão de alto nível |
Desempenho direcionado rápido e preciso |
|
Multilíngue |
Sim |
Sim |
Sim |
Sim |
Sim |
|
Visão |
Sim |
Sim |
Sim |
Sim |
Sim |
|
Sim |
Não |
Não |
Não |
Não |
|
|
Nome do modelo da API |
claude-3-7-sonnet-20250219 |
Versão atualizada: claude-3-5-sonnet-20241022 Versão anterior: claude-3-5-sonnet-20240620 |
claude-3-5-haiku-20241022 |
claude-3-opus-20240229 |
claude-3-haiku-20240307 |
|
Latência comparativa |
Rápido |
Rápido |
Mais rápido |
Moderadamente rápido |
Mais rápido |
|
Janela de contexto |
200K |
200K |
200K |
200K |
200K |
|
Saída máxima |
Normal: 8192 tokens Pensamento estendido: 64.000 tokens |
8192 tokens |
8192 tokens |
4096 tokens |
4096 tokens |
|
Custo (entrada/saída por MTok) |
$3.00 / $15.00 |
$3.00 / $15.00 |
$0.80 / $4.00 |
$15.00 / $75.00 |
$0.25 / $1.25 |
|
Corte de dados de treinamento |
Outubro de 2024 |
Abril de 2024 |
Julho de 2024 |
Agosto de 2023 |
Agosto de 2023 |
Fonte: Antrópico
Certifique-se de sempre verificar os preços mais recentes da API.
A Anthropic acaba de fazer sua maior mudança nos últimos tempos com o Claude 3.7 Sonnet, um modelo que finalmente a leva para o espaço da IA de raciocínio. Com base nos benchmarks, podemos ver que ele é um concorrente legítimo do o3-mini, do DeepSeek-R1 e do Grok 3 da OpenAI, com forte desempenho em codificação, resolução de problemas estruturados e uso de ferramentas agênticas.
A capacidade de alternar entre os modos generalista e de raciocínio o torna mais versátil, mas o fato de o Thinking Mode ser pago parece um passo em falso, especialmente com alternativas gratuitas disponíveis. Ainda assim, o Claude 3.7 é um grande avanço.
Aprenda IA com estes cursos!
Programa
Programa
Curso
blog
Abid Ali Awan
9 min
blog
Stanislav Karzhev
9 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan


