Curso
Biomedical Image Analysis in Python
4 h
23.4K
O SAM2 é um modelo de base desenvolvido pela Meta para segmentação visual em imagens e vídeos. Ao contrário de seu antecessor, SAMque se concentrava principalmente em imagens estáticas, o SAM2 foi projetado para lidar também com as complexidades da segmentação de vídeo.
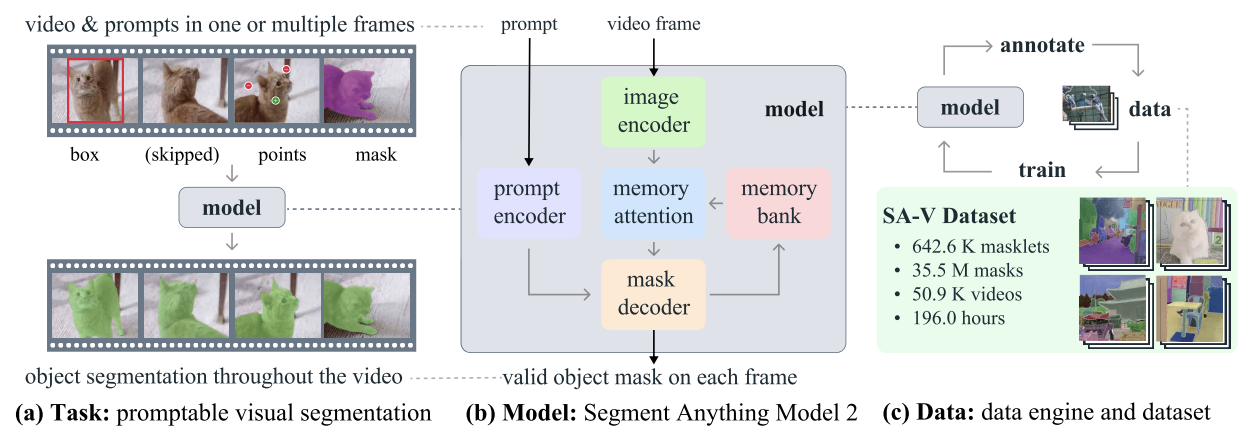
SAM2 - Tarefa, modelo e dados (Fonte: Ravi et al., 2024)
Ele emprega uma arquitetura de transformador com memória de streaming, permitindo o processamento de vídeo em tempo real. O treinamento do SAM 2 envolveu um conjunto de dados vasto e variado, com o novo conjunto de dados SA-V, que inclui mais de 600.000 anotações de máscara em 51.000 vídeos.
Seu mecanismo de dados, que permite a coleta interativa de dados e o aprimoramento do modelo, dá a ele a capacidade de segmentar tudo o que for possível. Esse mecanismo permite que o SAM 2 aprenda e se adapte continuamente, tornando-o mais eficiente no tratamento de dados novos e desafiadores. No entanto, para tarefas específicas de domínio ou objetos raros, o ajuste fino é essencial para obter o desempenho ideal.
No contexto do SAM 2, o ajuste fino é o processo de treinamento adicional do modelo SAM 2 pré-treinado em um conjunto de dados específico para melhorar seu desempenho em uma tarefa ou domínio específico. Embora o SAM 2 seja uma ferramenta avançada treinada em um conjunto de dados amplo e diversificado, sua natureza de uso geral nem sempre produz resultados ideais para tarefas especializadas ou raras.
Por exemplo, se você estiver trabalhando em um projeto de imagens médicas que exija a identificação de tipos específicos de tumores, o desempenho do modelo poderá ficar aquém do esperado devido ao seu treinamento generalizado.
O processo de ajuste fino
O ajuste fino do SAM 2 resolve essa limitação, permitindo que você adapte o modelo ao seu conjunto de dados específico. Esse processo melhora a a precisão do modelo e o torna mais eficaz para seu caso de uso exclusivo.
Aqui estão os principais benefícios do ajuste fino do SAM 2:
Para começar a fazer o ajuste fino do SAM 2, você precisará ter os seguintes pré-requisitos:
Software e outros requisitos:
A qualidade do seu conjunto de dados é crucial para o ajuste fino do modelo SAM 2. Imagens ou vídeos anotados de alta qualidade com máscaras de segmentação precisas são essenciais para que você obtenha o desempenho ideal. Anotações precisas permitem que o modelo aprenda os recursos corretos, levando a uma melhor precisão de segmentação e robustez em aplicativos do mundo real.
A primeira etapa envolve a aquisição do conjunto de dados, que forma a espinha dorsal do processo de treinamento. Obtivemos nossos dados do Kaggleuma plataforma confiável que fornece uma gama diversificada de conjuntos de dados. Usando a API do Kaggle, baixamos os dados no formato necessário, garantindo que as imagens e as máscaras de segmentação correspondentes estivessem prontamente disponíveis para processamento posterior.
Depois de fazer o download dos conjuntos de dados, executamos as seguintes etapas:
Como o modelo SAM2 requer entradas em formatos específicos, convertemos os dados da seguinte forma:
As imagens e máscaras processadas são então organizadas nas respectivas pastas para facilitar o acesso durante o processo de ajuste fino. Além disso, os caminhos para essas imagens e máscaras são gravados em um arquivo CSV (train.csv ) para facilitar o carregamento de dados durante o treinamento.
A etapa final envolveu a validação do conjunto de dados para garantir sua precisão:
Aqui você encontra está um bloco de notas rápido para mostrar a você o código para a criação do conjunto de dados. Você pode seguir esse caminho de criação de dados ou usar diretamente qualquer conjunto de dados disponível on-line no mesmo formato que o mencionado nos pré-requisitos.
O Segment Anything Model 2 contém vários componentes, mas o truque aqui para um ajuste fino mais rápido é treinar apenas componentes leves, como o decodificador de máscara e o codificador de prompt, em vez de todo o modelo. As etapas para o ajuste fino desse modelo são as seguintes:
Para iniciar o processo de ajuste fino, precisamos instalar a biblioteca SAM-2, que é essencial para o Segment Anything Model (SAM2). Esse modelo foi projetado para lidar com várias tarefas de segmentação de forma eficaz. A instalação envolve a clonagem do repositório SAM-2 do GitHub e a instalação das dependências necessárias.
!git clone https://github.com/facebookresearch/segment-anything-2
%cd /content/segment-anything-2
!pip install -q -e .Esse trecho de código garante que a biblioteca SAM2 esteja corretamente instalada e pronta para ser usada em nosso fluxo de trabalho de ajuste fino.
Depois que a biblioteca SAM-2 estiver instalada, a próxima etapa é adquirir o conjunto de dados que usaremos para o ajuste fino. Usamos um conjunto de dados disponível no Kaggle, especificamente um conjunto de dados de segmentação de TC de tórax que contém imagens e máscaras de pulmões, coração e traqueia.
O conjunto de dados contém:
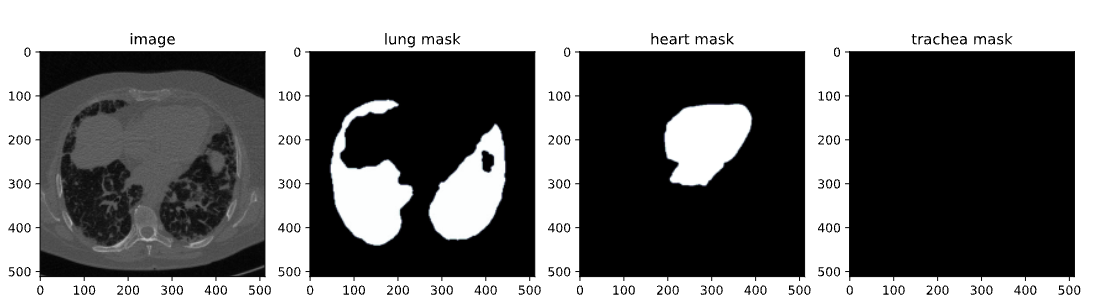
Imagem do conjunto de dados de tomografia computadorizada
Neste blog, usaremos apenas imagens e máscaras de pulmões para segmentação. A API do Kaggle permite que você baixe conjuntos de dados diretamente para o nosso ambiente. Começamos fazendo o upload do arquivo kaggle.json do Kaggle para acessar qualquer conjunto de dados com facilidade.
Para obter o kaggle.json, acesse a guia Settings (Configurações) no seu perfil de usuário e selecione Create New Token (Criar novo token). Isso acionará o download do Kaggle. json, um arquivo que contém suas credenciais de API.
# get dataset from Kaggle
from google.colab import files
files.upload() # This will prompt you to upload the kaggle.json file
!mkdir -p ~/.kaggle
!mv kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle datasets download -d polomarco/chest-ct-segmentationDescompacte os dados:
!unzip chest-ct-segmentation.zip -d chest-ct-segmentationCom o conjunto de dados pronto, vamos iniciar o processo de ajuste fino. Como mencionei anteriormente, o segredo aqui é fazer o ajuste fino apenas dos componentes leves do SAM2, como o decodificador de máscara e o codificador de prompt, em vez de todo o modelo. Essa abordagem é mais eficiente e requer menos recursos.
Para o processo de ajuste fino, precisamos começar com pesos pré-treinados do modelo SAM2. Esses pesos, chamados de "pontos de controle", são o ponto de partida para treinamento adicional. Os pontos de verificação foram treinados em uma ampla variedade de imagens e, ao ajustá-los em nosso conjunto de dados específico, podemos obter melhor desempenho em nossas tarefas de destino.
!wget -O sam2_hiera_tiny.pt "https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_tiny.pt"
!wget -O sam2_hiera_small.pt "https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_small.pt"
!wget -O sam2_hiera_base_plus.pt "https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_base_plus.pt"
!wget -O sam2_hiera_large.pt "https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_large.pt"Nessa etapa, baixamos vários pontos de verificação do SAM-2 que correspondem a diferentes tamanhos de modelo (por exemplo, minúsculo, pequeno, base_plus, grande). A escolha do ponto de verificação pode ser ajustada com base nos recursos computacionais disponíveis e na tarefa específica em questão.
Com o download do conjunto de dados, a próxima etapa é prepará-lo para o treinamento. Isso envolve a divisão do conjunto de dados em conjuntos de treinamento e teste e a criação de estruturas de dados que podem ser inseridas no modelo SAM 2 durante o ajuste fino.
%cd /content/segment-anything-2
import os
import pandas as pd
import cv2
import torch
import torch.nn.utils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
from sklearn.model_selection import train_test_split
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
# Path to the chest-ct-segmentation dataset folder
data_dir = "/content/segment-anything-2/chest-ct-segmentation"
images_dir = os.path.join(data_dir, "images/images")
masks_dir = os.path.join(data_dir, "masks/masks")
# Load the train.csv file
train_df = pd.read_csv(os.path.join(data_dir, "train.csv"))
# Split the data into two halves: one for training and one for testing
train_df, test_df = train_test_split(train_df, test_size=0.2, random_state=42)
# Prepare the training data list
train_data = []
for index, row in train_df.iterrows():
image_name = row['ImageId']
mask_name = row['MaskId']
# Append image and corresponding mask paths
train_data.append({
"image": os.path.join(images_dir, image_name),
"annotation": os.path.join(masks_dir, mask_name)
})
# Prepare the testing data list (if needed for inference or evaluation later)
test_data = []
for index, row in test_df.iterrows():
image_name = row['ImageId']
mask_name = row['MaskId']
# Append image and corresponding mask paths
test_data.append({
"image": os.path.join(images_dir, image_name),
"annotation": os.path.join(masks_dir, mask_name)
})
Dividimos o conjunto de dados em um conjunto de treinamento (80%) e um conjunto de teste (20%) para garantir que possamos avaliar o desempenho do modelo após o treinamento. Os dados de treinamento serão usados para ajustar o modelo SAM 2, enquanto os dados de teste serão usados para inferência e avaliação.
Depois de dividir o conjunto de dados em conjuntos de treinamento e teste, a próxima etapa envolve a criação de máscaras binárias, a seleção de pontos-chave dentro dessas máscaras e a visualização desses elementos para garantir que os dados sejam processados corretamente.
1. Leitura e redimensionamento de imagens: O processo começa com a seleção aleatória de uma imagem e sua máscara correspondente do conjunto de dados. A imagem é convertida do formato BGR para o formato RGB, que é o formato de cor padrão para a maioria dos modelos de aprendizagem profunda. A anotação correspondente (máscara) é lida no modo de escala de cinza. Em seguida, tanto a imagem quanto a máscara de anotação são redimensionadas para uma dimensão máxima de 1024 pixels, mantendo a proporção para garantir que os dados se ajustem aos requisitos de entrada do modelo e reduzam a carga computacional.
def read_batch(data, visualize_data=False):
# Select a random entry
ent = data[np.random.randint(len(data))]
# Get full paths
Img = cv2.imread(ent["image"])[..., ::-1] # Convert BGR to RGB
ann_map = cv2.imread(ent["annotation"], cv2.IMREAD_GRAYSCALE) # Read annotation as grayscale
if Img is None or ann_map is None:
print(f"Error: Could not read image or mask from path {ent['image']} or {ent['annotation']}")
return None, None, None, 0
# Resize image and mask
r = np.min([1024 / Img.shape[1], 1024 / Img.shape[0]]) # Scaling factor
Img = cv2.resize(Img, (int(Img.shape[1] * r), int(Img.shape[0] * r)))
ann_map = cv2.resize(ann_map, (int(ann_map.shape[1] * r), int(ann_map.shape[0] * r)), interpolation=cv2.INTER_NEAREST)
2. Binarização de máscaras de segmentação: A máscara de anotação multiclasse (que pode ter várias classes de objetos rotuladas com valores de pixel diferentes) é convertida em uma máscara binária. Essa máscara destaca todas as regiões de interesse na imagem, simplificando a tarefa de segmentação para um problema de classificação binária: objeto vs. plano de fundo. A máscara binária é então erodida usando um kernel 5x5.
A erosão reduz ligeiramente o tamanho da máscara, o que ajuda a evitar efeitos de limite ao selecionar pontos. Isso garante que os pontos selecionados estejam bem no interior do objeto, e não perto das bordas, que podem ser ruidosas ou ambíguas.
Os pontos-chave são selecionados dentro da máscara erodida. Esses pontos funcionam como avisos durante o processo de ajuste fino, orientando o modelo sobre onde concentrar sua atenção. Os pontos são selecionados aleatoriamente no interior dos objetos para garantir que sejam representativos e não sejam influenciados por limites ruidosos.
### Continuation of read_batch() ###
# Initialize a single binary mask
binary_mask = np.zeros_like(ann_map, dtype=np.uint8)
points = []
# Get binary masks and combine them into a single mask
inds = np.unique(ann_map)[1:] # Skip the background (index 0)
for ind in inds:
mask = (ann_map == ind).astype(np.uint8) # Create binary mask for each unique index
binary_mask = np.maximum(binary_mask, mask) # Combine with the existing binary mask
# Erode the combined binary mask to avoid boundary points
eroded_mask = cv2.erode(binary_mask, np.ones((5, 5), np.uint8), iterations=1)
# Get all coordinates inside the eroded mask and choose a random point
coords = np.argwhere(eroded_mask > 0)
if len(coords) > 0:
for _ in inds: # Select as many points as there are unique labels
yx = np.array(coords[np.random.randint(len(coords))])
points.append([yx[1], yx[0]])
points = np.array(points)
3. Visualização: Essa etapa é fundamental para verificar se as etapas de pré-processamento de dados foram executadas corretamente. Ao inspecionar visualmente os pontos na máscara binarizada, você pode garantir que o modelo receberá a entrada apropriada durante o treinamento. Por fim, a máscara binária é remodelada e formatada corretamente (com dimensões adequadas para a entrada do modelo), e os pontos também são remodelados para uso posterior no processo de treinamento. A função retorna a imagem processada, a máscara binária, os pontos selecionados e o número de máscaras encontradas.
### Continuation of read_batch() ###
if visualize_data:
# Plotting the images and points
plt.figure(figsize=(15, 5))
# Original Image
plt.subplot(1, 3, 1)
plt.title('Original Image')
plt.imshow(img)
plt.axis('off')
# Segmentation Mask (binary_mask)
plt.subplot(1, 3, 2)
plt.title('Binarized Mask')
plt.imshow(binary_mask, cmap='gray')
plt.axis('off')
# Mask with Points in Different Colors
plt.subplot(1, 3, 3)
plt.title('Binarized Mask with Points')
plt.imshow(binary_mask, cmap='gray')
# Plot points in different colors
colors = list(mcolors.TABLEAU_COLORS.values())
for i, point in enumerate(points):
plt.scatter(point[0], point[1], c=colors[i % len(colors)], s=100, label=f'Point {i+1}') # Corrected to plot y, x order
# plt.legend()
plt.axis('off')
plt.tight_layout()
plt.show()
binary_mask = np.expand_dims(binary_mask, axis=-1) # Now shape is (1024, 1024, 1)
binary_mask = binary_mask.transpose((2, 0, 1))
points = np.expand_dims(points, axis=1)
# Return the image, binarized mask, points, and number of masks
return img, binary_mask, points, len(inds)
# Visualize the data
Img1, masks1, points1, num_masks = read_batch(train_data, visualize_data=True)
O código acima retorna a figura a seguir, que contém a imagem original do conjunto de dados junto com a máscara binarizada e a máscara binarizada com pontos.

Imagem original, máscara binarizada e máscara binarizada com pontos para o conjunto de dados.
O ajuste fino do modelo SAM2 envolve várias etapas, inclusive o carregamento do modelo, a configuração do otimizador e do agendador e a atualização iterativa dos pesos do modelo com base nos dados de treinamento.
Carregue os pontos de controle do modelo:
sam2_checkpoint = "sam2_hiera_small.pt" # @param ["sam2_hiera_tiny.pt", "sam2_hiera_small.pt", "sam2_hiera_base_plus.pt", "sam2_hiera_large.pt"]
model_cfg = "sam2_hiera_s.yaml" # @param ["sam2_hiera_t.yaml", "sam2_hiera_s.yaml", "sam2_hiera_b+.yaml", "sam2_hiera_l.yaml"]
sam2_model = build_sam2(model_cfg, sam2_checkpoint, device="cuda")
predictor = SAM2ImagePredictor(sam2_model)
Começamos criando o modelo SAM2 usando os pontos de verificação pré-treinados. Em seguida, o modelo é agrupado em uma classe de previsão, o que simplifica o processo de definição de imagens, prompts de codificação e máscaras de decodificação.
Configuramos vários hiperparâmetros para garantir que o modelo aprenda de forma eficaz, como a taxa de aprendizado, o decaimento do peso e as etapas de acumulação do gradiente. Esses hiperparâmetros controlam o processo de aprendizagem, inclusive a velocidade com que o modelo atualiza seus pesos e como ele evita o ajuste excessivo. Você pode brincar com eles.
# Train mask decoder.
predictor.model.sam_mask_decoder.train(True)
# Train prompt encoder.
predictor.model.sam_prompt_encoder.train(True)
# Configure optimizer.
optimizer=torch.optim.AdamW(params=predictor.model.parameters(),lr=0.0001,weight_decay=1e-4) #1e-5, weight_decay = 4e-5
# Mix precision.
scaler = torch.cuda.amp.GradScaler()
# No. of steps to train the model.
NO_OF_STEPS = 3000 # @param
# Fine-tuned model name.
FINE_TUNED_MODEL_NAME = "fine_tuned_sam2"
O otimizador é responsável por atualizar os pesos do modelo, enquanto o programador ajusta a taxa de aprendizagem durante o treinamento para melhorar a convergência. Ao fazer o ajuste fino desses parâmetros, podemos obter melhor precisão de segmentação.
O processo de ajuste fino real é iterativo, no qual, em cada etapa, um lote de imagens e máscaras apenas para pulmões é passado pelo modelo, e a perda é calculada e usada para atualizar os pesos do modelo.
# Initialize scheduler
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=500, gamma=0.2) # 500 , 250, gamma = 0.1
accumulation_steps = 4 # Number of steps to accumulate gradients before updating
for step in range(1, NO_OF_STEPS + 1):
with torch.cuda.amp.autocast():
image, mask, input_point, num_masks = read_batch(train_data, visualize_data=False)
if image is None or mask is None or num_masks == 0:
continue
input_label = np.ones((num_masks, 1))
if not isinstance(input_point, np.ndarray) or not isinstance(input_label, np.ndarray):
continue
if input_point.size == 0 or input_label.size == 0:
continue
predictor.set_image(image)
mask_input, unnorm_coords, labels, unnorm_box = predictor._prep_prompts(input_point, input_label, box=None, mask_logits=None, normalize_coords=True)
if unnorm_coords is None or labels is None or unnorm_coords.shape[0] == 0 or labels.shape[0] == 0:
continue
sparse_embeddings, dense_embeddings = predictor.model.sam_prompt_encoder(
points=(unnorm_coords, labels), boxes=None, masks=None,
)
batched_mode = unnorm_coords.shape[0] > 1
high_res_features = [feat_level[-1].unsqueeze(0) for feat_level in predictor._features["high_res_feats"]]
low_res_masks, prd_scores, _, _ = predictor.model.sam_mask_decoder(
image_embeddings=predictor._features["image_embed"][-1].unsqueeze(0),
image_pe=predictor.model.sam_prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=True,
repeat_image=batched_mode,
high_res_features=high_res_features,
)
prd_masks = predictor._transforms.postprocess_masks(low_res_masks, predictor._orig_hw[-1])
gt_mask = torch.tensor(mask.astype(np.float32)).cuda()
prd_mask = torch.sigmoid(prd_masks[:, 0])
seg_loss = (-gt_mask * torch.log(prd_mask + 0.000001) - (1 - gt_mask) * torch.log((1 - prd_mask) + 0.00001)).mean()
inter = (gt_mask * (prd_mask > 0.5)).sum(1).sum(1)
iou = inter / (gt_mask.sum(1).sum(1) + (prd_mask > 0.5).sum(1).sum(1) - inter)
score_loss = torch.abs(prd_scores[:, 0] - iou).mean()
loss = seg_loss + score_loss * 0.05
# Apply gradient accumulation
loss = loss / accumulation_steps
scaler.scale(loss).backward()
# Clip gradients
torch.nn.utils.clip_grad_norm_(predictor.model.parameters(), max_norm=1.0)
if step % accumulation_steps == 0:
scaler.step(optimizer)
scaler.update()
predictor.model.zero_grad()
# Update scheduler
scheduler.step()
if step % 500 == 0:
FINE_TUNED_MODEL = FINE_TUNED_MODEL_NAME + "_" + str(step) + ".torch"
torch.save(predictor.model.state_dict(), FINE_TUNED_MODEL)
if step == 1:
mean_iou = 0
mean_iou = mean_iou * 0.99 + 0.01 * np.mean(iou.cpu().detach().numpy())
if step % 100 == 0:
print("Step " + str(step) + ":\t", "Accuracy (IoU) = ", mean_iou)
Durante cada iteração, o modelo processa um lote de imagens, calcula as máscaras de segmentação e as compara com a verdade terrestre para calcular a perda. Essa perda é então usada para ajustar os pesos do modelo, melhorando gradualmente o desempenho do modelo. Após o treinamento de cerca de 3.000 épocas, obtivemos uma precisão (IoU - Intersection over Union) de cerca de 72%.
O modelo pode então ser usado para inferência, onde ele prevê máscaras de segmentação em imagens novas e não vistas. Comece com asfunções auxiliares read_images e get_points para obter a imagem de inferência e sua máscara junto com os pontos-chave.
def read_image(image_path, mask_path): # read and resize image and mask
img = cv2.imread(image_path)[..., ::-1] # Convert BGR to RGB
mask = cv2.imread(mask_path, 0)
r = np.min([1024 / img.shape[1], 1024 / img.shape[0]])
img = cv2.resize(img, (int(img.shape[1] * r), int(img.shape[0] * r)))
mask = cv2.resize(mask, (int(mask.shape[1] * r), int(mask.shape[0] * r)), interpolation=cv2.INTER_NEAREST)
return img, mask
def get_points(mask, num_points): # Sample points inside the input mask
points = []
coords = np.argwhere(mask > 0)
for i in range(num_points):
yx = np.array(coords[np.random.randint(len(coords))])
points.append([[yx[1], yx[0]]])
return np.array(points)Em seguida, carregue as imagens de amostra que você deseja para inferência, juntamente com os pesos recém-ajustados, e execute a inferência definindo torch.no_grad().
# Randomly select a test image from the test_data
selected_entry = random.choice(test_data)
image_path = selected_entry['image']
mask_path = selected_entry['annotation']
# Load the selected image and mask
image, mask = read_image(image_path, mask_path)
# Generate random points for the input
num_samples = 30 # Number of points per segment to sample
input_points = get_points(mask, num_samples)
# Load the fine-tuned model
FINE_TUNED_MODEL_WEIGHTS = "fine_tuned_sam2_1000.torch"
sam2_model = build_sam2(model_cfg, sam2_checkpoint, device="cuda")
# Build net and load weights
predictor = SAM2ImagePredictor(sam2_model)
predictor.model.load_state_dict(torch.load(FINE_TUNED_MODEL_WEIGHTS))
# Perform inference and predict masks
with torch.no_grad():
predictor.set_image(image)
masks, scores, logits = predictor.predict(
point_coords=input_points,
point_labels=np.ones([input_points.shape[0], 1])
)
# Process the predicted masks and sort by scores
np_masks = np.array(masks[:, 0])
np_scores = scores[:, 0]
sorted_masks = np_masks[np.argsort(np_scores)][::-1]
# Initialize segmentation map and occupancy mask
seg_map = np.zeros_like(sorted_masks[0], dtype=np.uint8)
occupancy_mask = np.zeros_like(sorted_masks[0], dtype=bool)
# Combine masks to create the final segmentation map
for i in range(sorted_masks.shape[0]):
mask = sorted_masks[i]
if (mask * occupancy_mask).sum() / mask.sum() > 0.15:
continue
mask_bool = mask.astype(bool)
mask_bool[occupancy_mask] = False # Set overlapping areas to False in the mask
seg_map[mask_bool] = i + 1 # Use boolean mask to index seg_map
occupancy_mask[mask_bool] = True # Update occupancy_mask
# Visualization: Show the original image, mask, and final segmentation side by side
plt.figure(figsize=(18, 6))
plt.subplot(1, 3, 1)
plt.title('Test Image')
plt.imshow(image)
plt.axis('off')
plt.subplot(1, 3, 2)
plt.title('Original Mask')
plt.imshow(mask, cmap='gray')
plt.axis('off')
plt.subplot(1, 3, 3)
plt.title('Final Segmentation')
plt.imshow(seg_map, cmap='jet')
plt.axis('off')
plt.tight_layout()
plt.show()Nessa etapa, usamos o modelo ajustado para gerar máscaras de segmentação para imagens de teste. Em seguida, as máscaras previstas são visualizadas juntamente com as imagens originais e as máscaras da verdade básica para avaliar o desempenho do modelo.

Imagem de segmentação final nos dados de teste
O ajuste fino do SAM2 oferece uma maneira prática de aprimorar seus recursos para tarefas específicas. Independentemente de você estar trabalhando com imagens médicas, veículos autônomos ou edição de vídeo, o ajuste fino permite que você use o SAM2 para atender às suas necessidades específicas. Seguindo este guia, você pode adaptar o SAM2 aos seus projetos e obter resultados de segmentação de última geração.
Para casos de uso mais avançados, considere o ajuste fino de componentes adicionais do SAM2, como o codificador de imagem. Embora isso exija mais recursos, oferece maior flexibilidade e melhorias de desempenho.
Aprenda IA com estes cursos!
Curso
Curso
Curso
blog
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan

