
Curso
Introdução a LLMs em Python
3 h
33.7K
DeepSeek, uma startup chinesa de IA, revolucionou o setor global de IA, eliminando US$ 1 trilhão das bolsas de valores dos EUA e abalando gigantes da tecnologia como Nvidia e OpenAI. Ele emergiu rapidamente como líder em geração de texto, raciocínio, modelos de visão e geração de imagens. O DeepSeek lançou recentemente modelos de última geração, incluindo o Janus, um modelo multimodal capaz de compreender dados visuais e gerar imagens a partir de texto.
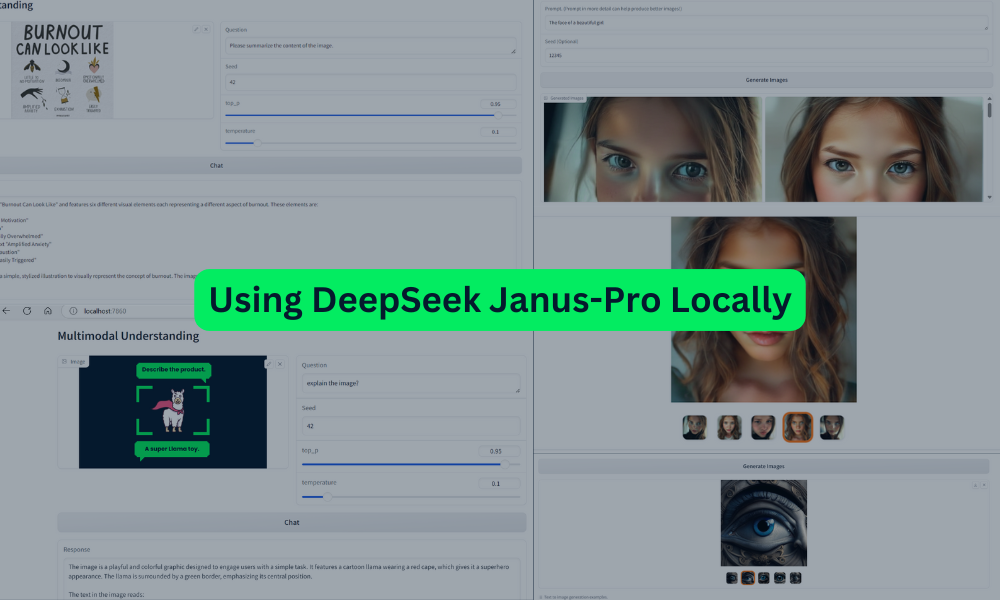
Imagem do autor
Neste tutorial, aprenderemos sobre a série Janus, configuraremos o projeto Janus, criaremos um contêiner do Docker para executar o modelo localmente e testaremos seus recursos com vários prompts de imagem e texto.
Saiba mais sobre os modelos do DeepSeek que estão revolucionando o setor global de IA:
O DeepSeek Janus-Series é uma nova linha de modelos multimodais projetados para unificar tarefas de geração e compreensão visual usando estruturas inovadoras. A série inclui o Janus, JanusFlow e o avançado Janus-Pro, cada um deles baseado na iteração anterior com melhorias notáveis em eficiência, desempenho e recursos multimodais.
O Janus é uma estrutura autorregressiva inovadora que separa a codificação visual em caminhos distintos para tarefas de compreensão e geração, usando uma arquitetura de transformação unificada. Essa abordagem resolve conflitos entre essas funções, aumentando a flexibilidade e a eficácia. O Janus se iguala ou supera os modelos específicos de tarefas, o que o torna um forte candidato para sistemas multimodais de última geração.
O JanusFlow combina modelagem de linguagem autorregressiva com fluxo retificado, uma técnica de modelagem generativa de última geração. Seu design minimalista permite o treinamento fácil em grandes estruturas de modelos de linguagem sem a necessidade de modificações complicadas. O JanusFlow demonstra desempenho superior em benchmarks quando comparado a abordagens especializadas e unificadas, ampliando efetivamente os limites da modelagem de linguagem visual.
O Janus-Pro aprimora os modelos anteriores introduzindo estratégias de treinamento otimizadas, conjuntos de dados de treinamento expandidos e escalonamento para tamanhos de modelos maiores. Esses avanços melhoram significativamente a compreensão multimodal e o acompanhamento de instruções de texto para imagem, além de garantir uma geração de texto para imagem mais estável.
Fonte: deepseek-ai/Janus
Leia Janus-Pro da DeepSeek: Recursos, comparação com o DALL-E 3 e muito mais para saber mais sobre a série Janus, como acessá-la e como ela se compara ao DALL-E 3 da OpenAI.
O Janus é um modelo relativamente novo e, atualmente, não há versões quantizadas ou aplicativos locais de IA disponíveis para uso fácil em laptops ou desktops.
No entanto, o repositório Janus no GitHub oferece um excelente aplicativo web do Gradio para que você possa experimentar. O desafio, no entanto, é que a demonstração muitas vezes não funciona devido a vários conflitos de pacotes.
Para superar esse problema, neste projeto, modificaremos o código original, criaremos nossa própria imagem do Docker e executaremos o contêiner localmente usando o aplicativo Docker Desktop.
Para começar, baixe e instale a versão mais recente do Docker Desktop no site oficial do Docker.
Observação para usuários do Windows:
Se estiver usando o Windows, você também precisará instalar o Windows Subsystem for Linux (WSL). Abra o terminal e execute o seguinte comando para instalar o WSL:
wsl --installEm seguida, clone o repositório Janus do GitHub e navegue até o diretório do projeto:
git clone https://github.com/deepseek-ai/Janus.git
cd JanusNavegue até a pasta de demonstração e abra o arquivo app_januspro.py no editor de código de sua preferência. Faça as seguintes alterações:
deepseek-ai/Janus-Pro-7B por deepseek-ai/Janus-Pro-1B.Isso carregará a versão mais leve do modelo, que tem apenas 4,1 GB de tamanho, o que a torna mais adequada para uso local.
demo.queue para o seguinte:demo.queue(concurrency_count=1, max_size=10).launch(
server_name="0.0.0.0", server_port=7860
)
Essa alteração garante a compatibilidade com o URL e a porta do Docker.
Para colocar o aplicativo em um contêiner, crie um Dockerfile no diretório raiz do projeto. Use o seguinte conteúdo para Dockerfile:
# Use the PyTorch base image
FROM pytorch/pytorch:latest
# Set the working directory inside the container
WORKDIR /app
# Copy the current directory into the container
COPY . /app
# Install necessary Python packages
RUN pip install -e .[gradio]
# Set the entrypoint for the container to launch your Gradio app
CMD ["python", "demo/app_januspro.py"]O Dockerfile irá:
Quando o Dockerfile estiver pronto, criaremos a imagem do Docker e executaremos o contêiner.
Você pode fazer o curso Introdução ao Docker para que você saiba mais sobre os conceitos básicos de criação e implantação de uma imagem do Docker.
Digite o seguinte comando no terminal para criar a imagem do Docker. Esse comando usará a imagem Dockerfile localizada na pasta raiz e atribuirá o nome janus à imagem:
docker build -t janus . Você levará de 10 a 15 minutos, dependendo da velocidade da Internet, para criar a imagem do zero.
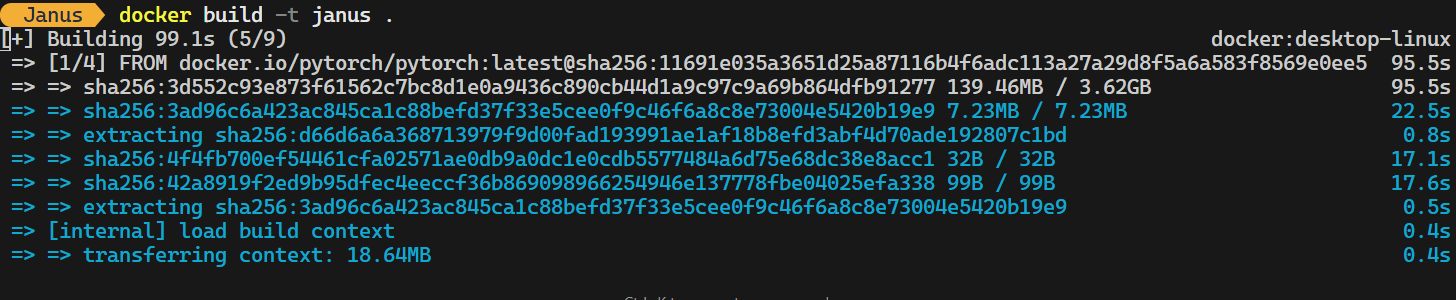
O comando a seguir inicia um contêiner Docker para o aplicativo Janus. Ele permite o suporte a GPU, mapeia a porta 7860 para acessar o aplicativo Gradio e garante o armazenamento persistente dos arquivos de modelo do Hugging Face.
docker run -it -p 7860:7860 -d -v huggingface:/root/.cache/huggingface -w /app --gpus all --name janus janus:latestSe você abrir o aplicativo Docker Desktop e navegar até a guia "Containers", verá que o contêiner janus está em execução. No entanto, ele ainda não está pronto para ser usado.
Para verificar o progresso, clique no contêiner janus e, em seguida, vá para a guia "Logs". Aqui, você notará que o contêiner está baixando o arquivo de modelo do Hugging Face Hub.
Quando o download do modelo for bem-sucedido, os registros exibirão uma mensagem indicando que o aplicativo está em execução.

Em seguida, você pode acessar o aplicativo visitando o seguinte URL no navegador: http://localhost:7860/.
Se você estiver com problemas, verifique a versão atualizada do projeto Janus em kingabzpro/Janus: Janus-Series.
O aplicativo web tem uma interface limpa e tudo parece estar funcionando sem problemas. Nesta seção, testaremos os recursos de compreensão multimodal e de geração de texto para imagem do Janus Pro.
Para avaliar a compreensão multimodal do modelo, primeiro carregamos uma imagem do tutorial do DataCamp e pedimos ao modelo que a explique. Os resultados são impressionantes - mesmo com o modelo 1B menor, a resposta é altamente precisa e detalhada.
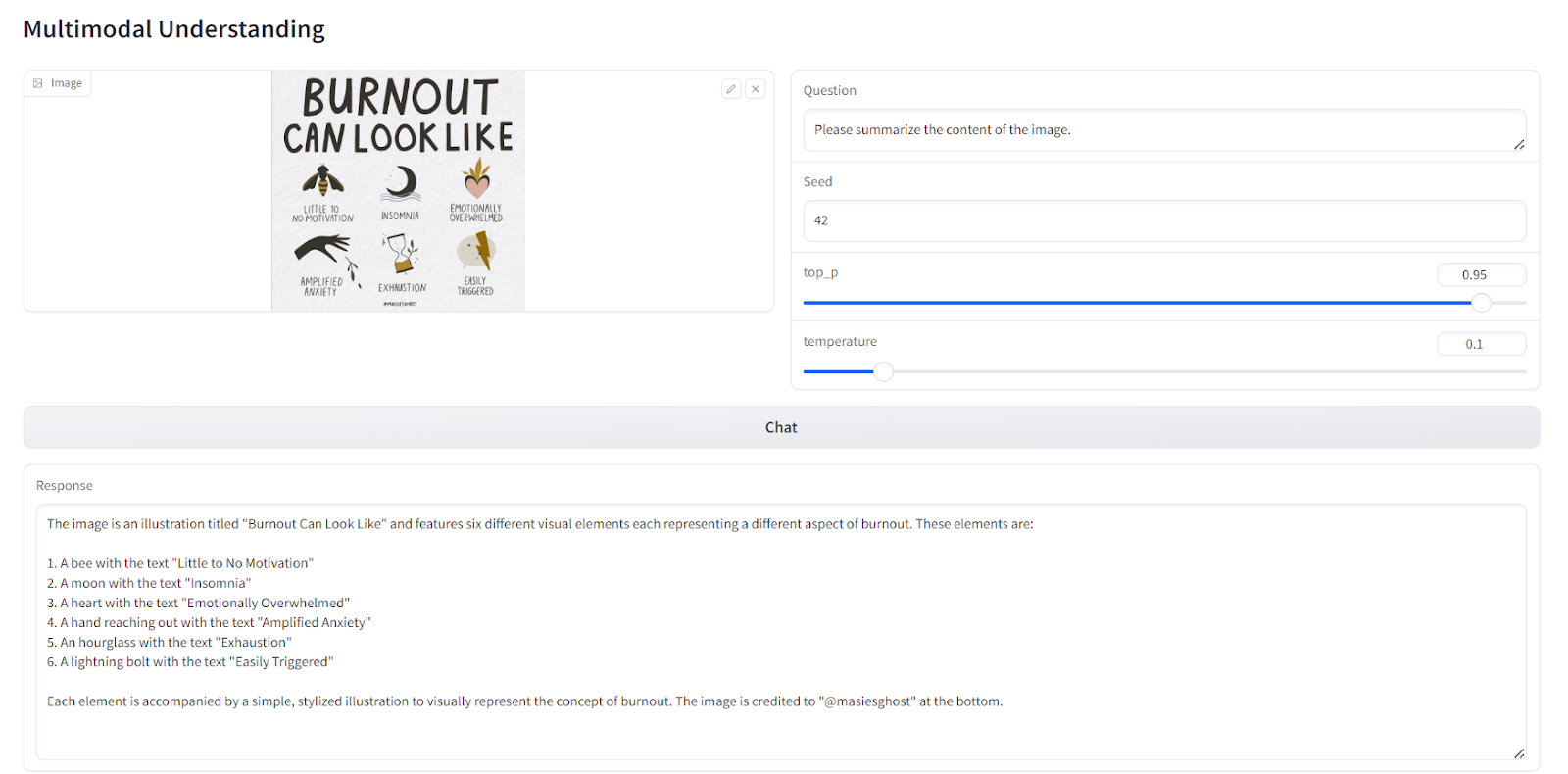
Em seguida, carregamos outra imagem e pedimos ao modelo que resuma o conteúdo de um infográfico. O modelo entende com sucesso o texto dentro da imagem e fornece uma resposta altamente precisa e coerente. Isso demonstra a forte capacidade do modelo de processar e interpretar elementos visuais e textuais.
Rolando o aplicativo para baixo, você encontrará a seção "Text-to-Image Generation" (Geração de texto para imagem). Aqui, você pode inserir um prompt de sua escolha e clicar no botão "Generate Images" (Gerar imagens). O modelo gera cinco variações da imagem, o que pode levar alguns minutos para ser concluído.
Os resultados são notáveis, produzindo resultados que são comparáveis ao Stable Diffusion XL em termos de qualidade e detalhes.
Você pode aprender a Ajustar o Stable Diffusion XL com o DreamBooth e o LoRA em suas imagens pessoais.
Vamos tentar outro prompt:
Prompt:
"A imagem apresenta um olho intrincadamente projetado em um fundo circular adornado com padrões de redemoinhos ornamentados que evocam tanto o realismo quanto o surrealismo. No centro das atenções está uma íris azul extremamente vívida, cercada por veias delicadas que se irradiam para fora da pupila para criar profundidade e intensidade. Os cílios são longos e escuros, lançando sombras sutis sobre a pele ao redor deles, que parece lisa, mas levemente texturizada, como se tivesse envelhecido ou passado pelo tempo.
Acima do olho, há uma estrutura semelhante a uma pedra que lembra parte da arquitetura clássica, acrescentando camadas de mistério e elegância atemporal à composição. Esse elemento arquitetônico contrasta de forma acentuada, mas harmoniosa, com as curvas orgânicas que o cercam. Abaixo do olho, há outro motivo decorativo que lembra a arte barroca, aumentando ainda mais a sensação geral de eternidade encapsulada em cada detalhe meticulosamente trabalhado.
De modo geral, a atmosfera exala uma aura misteriosa entrelaçada perfeitamente com elementos que sugerem atemporalidade, obtida por meio da justaposição de texturas realistas e floreios artísticos surreais. Cada componente, desde os intrincados designs que emolduram o olho até a peça de pedra de aparência antiga acima, contribui de forma exclusiva para criar um quadro visualmente cativante, imbuído de fascínio enigmático."
Mais uma vez, os resultados são impressionantes. As imagens geradas capturam os detalhes intrincados e os elementos artísticos surreais descritos no prompt.
Para testar todos os recursos do modelo, o DeepSeek implantou a mesma versão do aplicativo web no Hugging Face Spaces. Você pode acessá-lo em Bate-papo com Janus-Pro-7B. Um dos recursos de destaque do modelo Janus Pro é sua alta precisão, mesmo quando você usa variantes menores, como o modelo 1B.
Neste tutorial, exploramos o Janus Pro, um modelo multimodal capaz de compreender imagens e gerar imagens a partir de solicitações de texto. Além disso, criamos nossa própria solução local para usar o modelo de forma privada em uma GPU de laptop. Essa configuração é rápida, eficiente e permite que você faça experimentos livremente com recursos limitados.
Confira nosso guia mais recente sobre Ajuste fino do DeepSeek R1 (modelo de raciocínio). Você aprenderá a treinar o modelo de raciocínio no conjunto de dados da cadeia de pensamento médico para criar melhores médicos de IA para o futuro.
Principais cursos de IA
Curso
Curso
Curso
blog
Abid Ali Awan
8 min
Tutorial
Dimitri Didmanidze
Tutorial
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
