
Course
Introduction to LLMs in Python
3 hr
33.6K
DeepSeek, a Chinese AI startup, has disrupted the global AI industry, wiping $1 trillion from U.S. stock exchanges and shaking tech giants like Nvidia and OpenAI. It has quickly emerged as a leader in text generation, reasoning, vision models, and image generation. DeepSeek recently launched state-of-the-art models, including Janus, a multimodal model capable of understanding visual data and generating images from text.
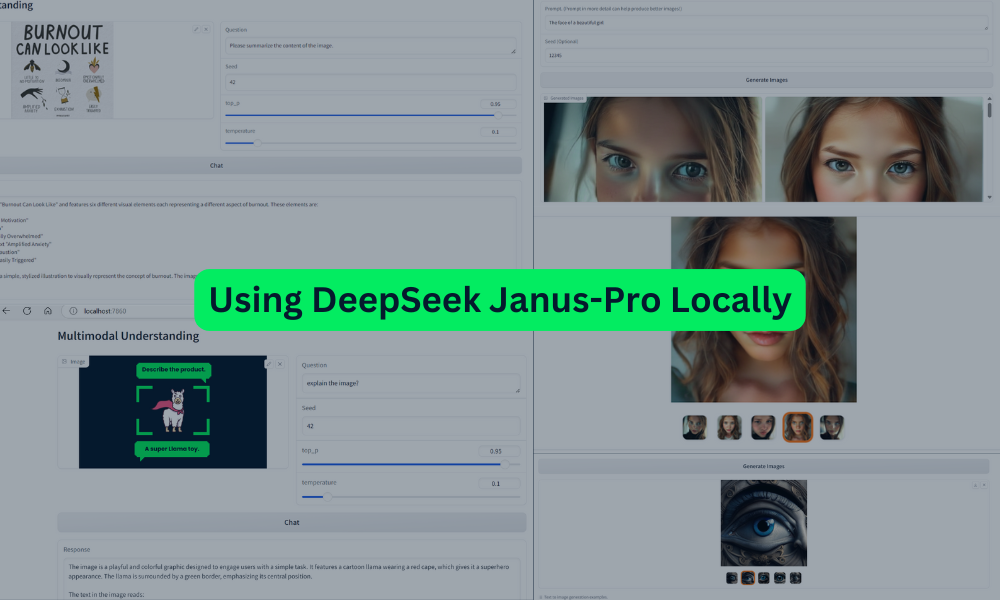
Image by Author
In this tutorial, we will learn about the Janus Series, set up the Janus project, build a Docker container to run the model locally, and test its capabilities with various image and text prompts.
Learn about DeepSeek models that are disrupting the global AI industry:
The DeepSeek Janus-Series is a new line of multimodal models designed to unify visual understanding and generation tasks using innovative frameworks. The series includes Janus, JanusFlow, and the advanced Janus-Pro, each building upon the previous iteration with notable improvements in efficiency, performance, and multimodal capabilities.
Janus is an innovative autoregressive framework that separates visual encoding into distinct pathways for understanding and generation tasks, while using a unified transformer architecture. This approach resolves conflicts between these roles, enhancing flexibility and effectiveness. Janus matches or surpasses task-specific models, making it a strong candidate for next-generation multimodal systems.
JanusFlow combines autoregressive language modeling with rectified flow, a state-of-the-art generative modeling technique. Its minimalist design enables easy training within large language model frameworks without the need for complicated modifications. JanusFlow demonstrates superior performance on benchmarks when compared to both specialized and unified approaches, effectively pushing the boundaries of vision-language modeling.
Janus-Pro enhances the previous models by introducing optimized training strategies, expanded training datasets, and scaling to larger model sizes. These advancements significantly improve multimodal understanding and text-to-image instruction-following while ensuring more stable text-to-image generation.
Source: deepseek-ai/Janus
Read DeepSeek's Janus-Pro: Features, DALL-E 3 Comparison & More to learn more about the Janus series, how to access it, and how it compares to OpenAI's DALL-E 3.
Janus is a relatively new model, and currently, there are no quantized versions or local AI applications available for easy use on laptops or desktops.
However, the Janus repository on GitHub provides an excellent Gradio web application demo for anyone to try. The challenge, however, is that the demo often fails to work due to multiple package conflicts.
To overcome this issue, in this project, we will modify the original code, build our own Docker image, and run the container locally using the Docker Desktop application.
To get started, download and install the latest version of Docker Desktop from the official Docker website.
Note for Windows users:
If you are using Windows, you will also need to install the Windows Subsystem for Linux (WSL). Open your terminal and run the following command to install WSL:
wsl --installNext, clone the Janus repository from GitHub and navigate to the project directory:
git clone https://github.com/deepseek-ai/Janus.git
cd JanusNavigate to the demo folder and open the file app_januspro.py in your preferred code editor. Make the following changes:
deepseek-ai/Janus-Pro-7B with deepseek-ai/Janus-Pro-1B.This will load the lighter version of the model, which is only 4.1 GB in size, making it more suitable for local use.
demo.queue function to the following:demo.queue(concurrency_count=1, max_size=10).launch(
server_name="0.0.0.0", server_port=7860
)
This change ensures compatibility with the Docker URL and port.
To containerize the application, create a Dockerfile in the root directory of the project. Use the following content for the Dockerfile:
# Use the PyTorch base image
FROM pytorch/pytorch:latest
# Set the working directory inside the container
WORKDIR /app
# Copy the current directory into the container
COPY . /app
# Install necessary Python packages
RUN pip install -e .[gradio]
# Set the entrypoint for the container to launch your Gradio app
CMD ["python", "demo/app_januspro.py"]The Dockerfile will:
Once the Dockerfile is ready, we will build the Docker image and run the container.
You can take the Introduction to Docker course to learn about the basics of building and deploying a Docker image.
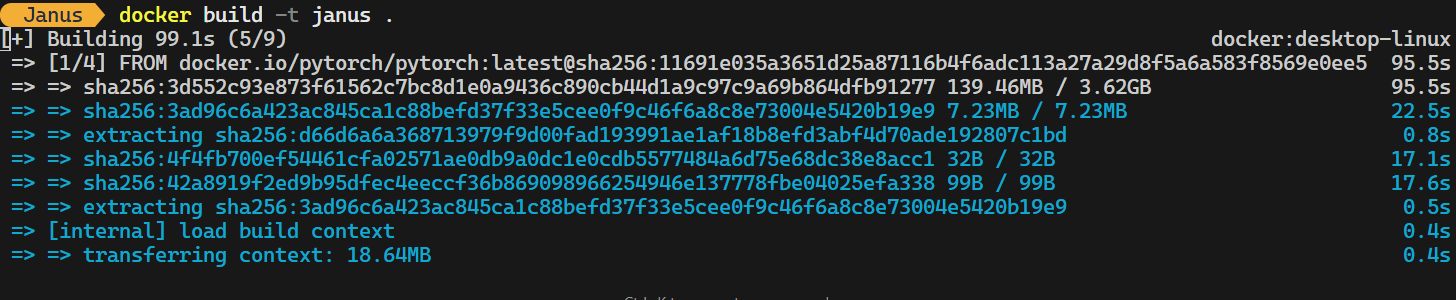
Type the following command in the terminal to create the Docker image. This command will use the Dockerfile located in the root folder and assign the name janus to the image:
docker build -t janus . It takes 10 to 15 minutes, based on your internet speed, to build the image from scratch.
The following command starts a Docker container for the Janus application. It enables GPU support, maps port 7860 for accessing the Gradio app, and ensures persistent storage for Hugging Face model files.
docker run -it -p 7860:7860 -d -v huggingface:/root/.cache/huggingface -w /app --gpus all --name janus janus:latestIf you open the Docker Desktop application and navigate to the “Containers” tab, you will see that the janus container is running. However, it is not yet ready to use.
To check its progress, click on the janus container and then go to the “Logs” tab. Here, you will notice that the container is downloading the model file from the Hugging Face Hub.
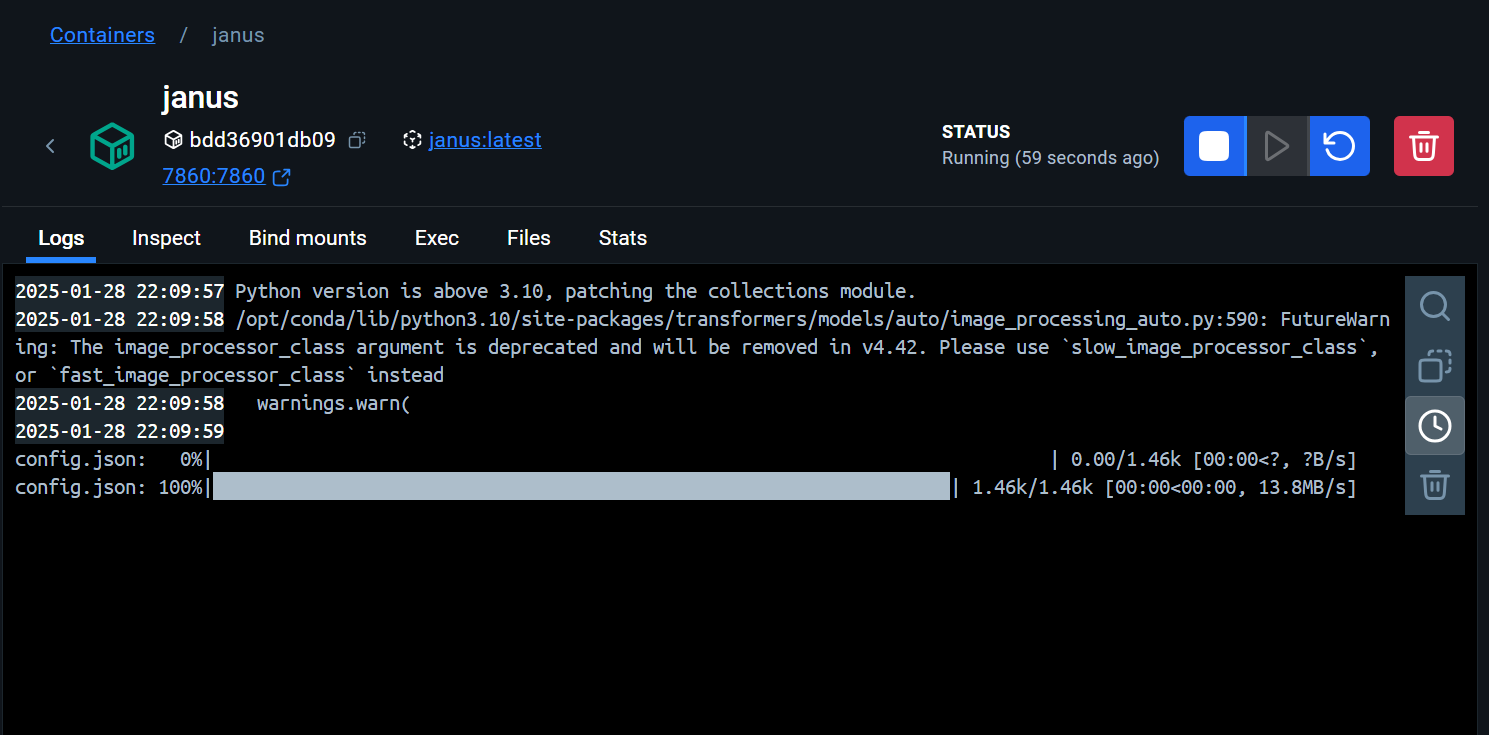
Once the model has been successfully downloaded, the logs will display a message indicating that the application is running.

You can then access your application by visiting the following URL in your browser: http://localhost:7860/.
If you are experiencing issues, please check the updated version of the Janus project at kingabzpro/Janus: Janus-Series.
The web app has a clean interface, and everything appears to be working smoothly. In this section, we will test the Janus Pro's multimodal understanding and text-to-image generation capabilities.
To evaluate the model's multimodal understanding, we first load an image from the DataCamp tutorial and ask the model to explain it. The results are impressive—even with the smaller 1B model, the response is highly accurate and detailed.
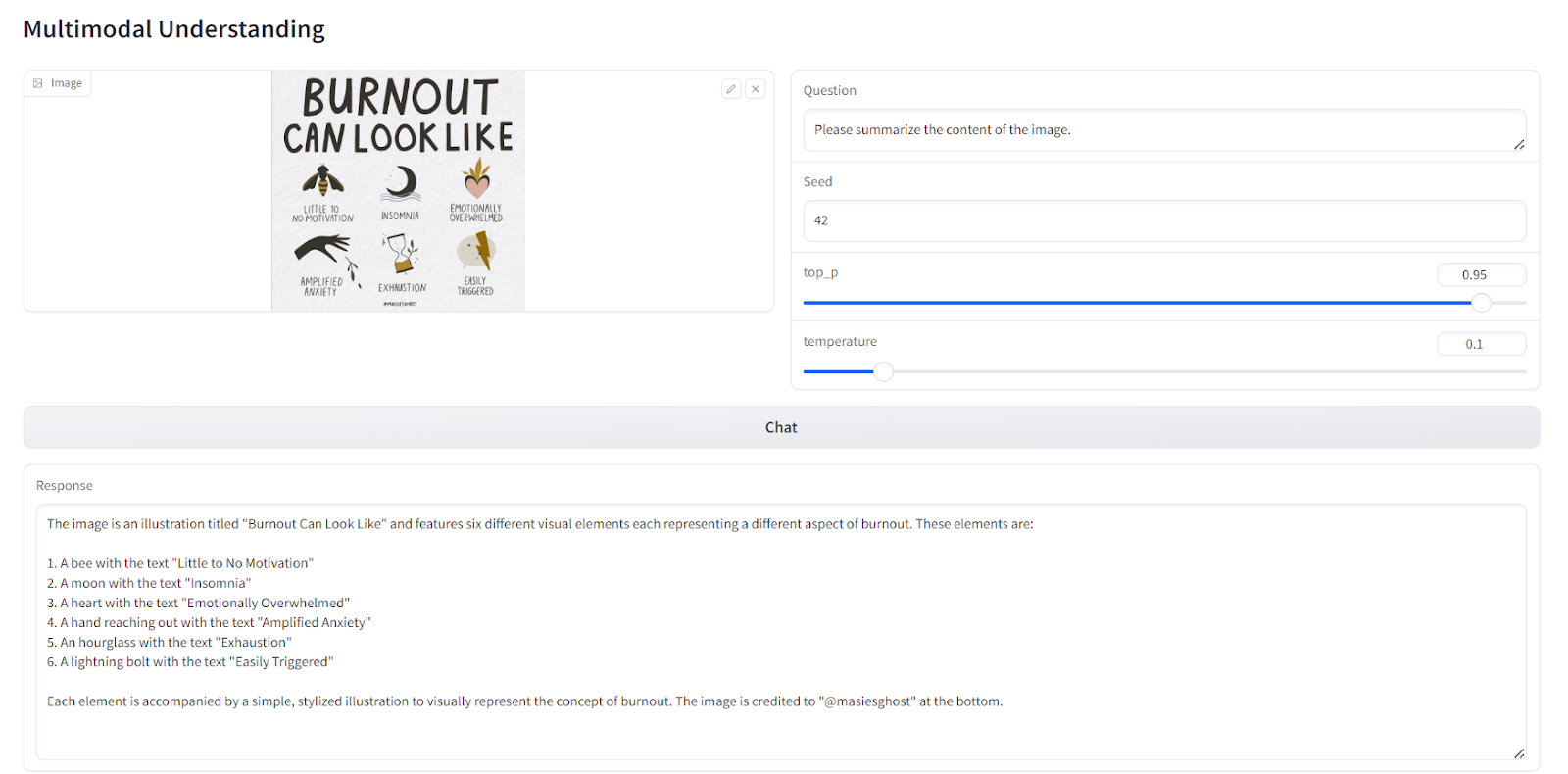
Next, we load another image and ask the model to summarize the content of an infographic. The model successfully understands the text within the image and provides a highly accurate and coherent response. This demonstrates the model's strong ability to process and interpret both visual and textual elements.
Scrolling down the app, you’ll find the “Text-to-Image Generation” section. Here, you can enter a prompt of your choice and click the “Generate Images” button. The model generates five variations of the image, which may take a few minutes to complete.
The results are remarkable, producing outputs that are comparable to Stable Diffusion XL in terms of quality and detail.
You can learn how to Fine-tune Stable Diffusion XL with DreamBooth and LoRA on your personal images.
Let’s try another prompt:
Prompt:
“The image features an intricately designed eye set against a circular backdrop adorned with ornate swirl patterns that evoke both realism and surrealism. At the center of attention is a strikingly vivid blue iris surrounded by delicate veins radiating outward from the pupil to create depth and intensity. The eyelashes are long and dark, casting subtle shadows on the skin around them, which appears smooth yet slightly textured as if aged or weathered over time.
Above the eye, there's a stone-like structure resembling part of classical architecture, adding layers of mystery and timeless elegance to the composition. This architectural element contrasts sharply but harmoniously with the organic curves surrounding it. Below the eye lies another decorative motif reminiscent of baroque artistry, further enhancing the overall sense of eternity encapsulated within each meticulously crafted detail.
Overall, the atmosphere exudes a mysterious aura intertwined seamlessly with elements suggesting timelessness, achieved through the juxtaposition of realistic textures and surreal artistic flourishes. Each component—from the intricate designs framing the eye to the ancient-looking stone piece above—contributes uniquely towards creating a visually captivating tableau imbued with enigmatic allure.”
Once again, the results are stunning. The generated images capture the intricate details and surreal artistic elements described in the prompt.
To test the full capabilities of the model, DeepSeek has deployed the same version of the web application on Hugging Face Spaces. You can access it at Chat With Janus-Pro-7B. One of the standout features of the Janus Pro model is its high accuracy, even when using smaller variants like the 1B model.
In this tutorial, we explored Janus Pro, a multimodal model capable of both understanding images and generating images from text prompts. Additionally, we built our own local solution to use the model privately on a laptop GPU. This setup is fast, efficient, and allows you to experiment freely with limited resources.
Check out our latest guide on Fine-Tuning DeepSeek R1 (Reasoning Model). You will learn to train the reasoning model on the medical chain of thought dataset to build better AI doctors for the future.
Top AI Courses
Course
Course
Course
blog
Alex Olteanu
8 min
blog
Dr Ana Rojo-Echeburúa
8 min
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan
