
Curso
Introdução a LLMs em Python
3 h
33.7K
A DeepSeek revolucionou o cenário da IA, desafiando o domínio da OpenAI ao lançar uma nova série de modelos de raciocínio avançado. A melhor parte? Esses modelos são totalmente gratuitos, sem restrições, o que os torna acessíveis a todos.
Neste tutorial, faremos o ajuste fino do modelo DeepSeek-R1-Distill-Llama-8B no conjunto de dados Medical Chain-of-Thought da Hugging Face. Esse modelo destilado do DeepSeek-R1 foi criado por meio do ajuste fino do modelo Llama 3.1 8B nos dados gerados com o DeepSeek-R1. Ele apresenta recursos de raciocínio semelhantes aos do modelo original.
Se você não tem experiência com LLMs e ajuste fino, recomendo enfaticamente que faça o curso Introdução aos LLMs em Python para você.

Imagem do autor
A empresa chinesa de IA DeepSeek AI abriu o código aberto de seus modelos de raciocínio de primeira geração, DeepSeek-R1 e DeepSeek-R1-Zero, que rivalizam com o o1 da OpenAI em termos de desempenho em tarefas de raciocínio como matemática, codificação e lógica. Você pode ler nosso guia completo do DeepSeek R1 para que você saiba mais.
O DeepSeek-R1-Zero é o primeiro modelo de código aberto treinado exclusivamente com aprendizagem por reforço em larga escala. aprendizado por reforço (RL) em vez de ajuste fino supervisionado (SFT) como uma etapa inicial. Essa abordagem permite que o modelo explore de forma independente cadeia de raciocínio (CoT), resolver problemas complexos e refinar iterativamente seus resultados. No entanto, ele apresenta desafios como etapas de raciocínio repetitivas, baixa legibilidade e mistura de idiomas que podem afetar sua clareza e usabilidade.
O DeepSeek-R1 foi introduzido para superar as limitações do DeepSeek-R1-Zero, incorporando dados de início frio antes do aprendizado por reforço, fornecendo uma base sólida para tarefas de raciocínio e não raciocínio.
Esse treinamento em vários estágios permite que o modelo atinja um desempenho de última geração, comparável ao do OpenAI-o1, em benchmarks de matemática, código e raciocínio, ao mesmo tempo em que melhora a legibilidade e a coerência de seus resultados.
Juntamente com modelos de linguagem grandes que requerem grande capacidade de computação e memória para operar, o DeepSeek também introduziu modelos destilados. Esses modelos menores e mais eficientes demonstraram que ainda podem alcançar um desempenho de raciocínio notável.
Variando de 1,5 bilhão a 70 bilhões de parâmetros, esses modelos mantêm fortes recursos de raciocínio, com o DeepSeek-R1-Distill-Qwen-32B superando o OpenAI-o1-mini em vários benchmarks.
Os modelos menores herdam os padrões de raciocínio dos modelos maiores, demonstrando a eficácia do processo de destilação.
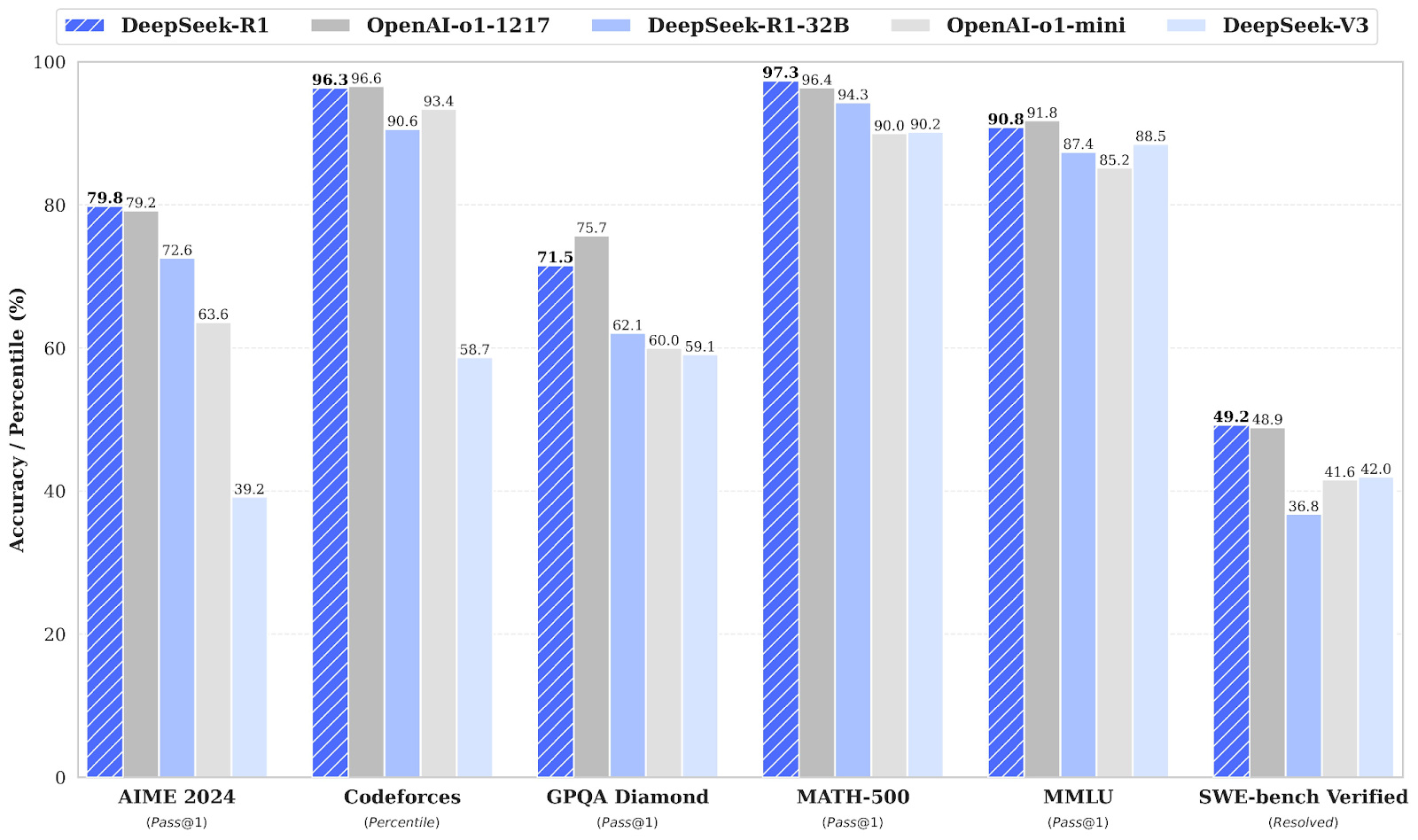
Fonte: deepseek-ai/DeepSeek-R1
Leia O site DeepSeek-R1: Recursos, comparação com o1, modelos destilados e mais blog para que você saiba mais sobre seus principais recursos, processo de desenvolvimento, modelos destilados, acesso, preços e comparação com o OpenAI o1.
Para fazer o ajuste fino do modelo DeepSeek R1, você pode seguir as etapas abaixo:
Para este projeto, estamos usando o Kaggle como nosso Cloud IDE porque ele fornece acesso gratuito a GPUs, que geralmente são mais potentes do que as disponíveis no Google Colab. Para começar, abra um novo notebook do Kaggle e adicione o token Hugging Face e o token Weights & Biases como segredos.
Você pode adicionar segredos navegando até a guia Add-ons na interface do notebook do Kaggle e selecionando a opção Secrets.
Depois de configurar os segredos, instale o pacote unsloth Python. O Unsloth é uma estrutura de código aberto projetada para tornar o ajuste fino de grandes modelos de linguagem (LLMs) duas vezes mais rápido e mais eficiente em termos de memória.
Leia nosso guia Unsloth: Otimize e acelere o LLM Fine-Tuning para saber mais sobre os principais recursos do Unsloth, várias funções e como otimizar seu fluxo de trabalho de ajuste fino .
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.gitFaça login na CLI da Hugging Face usando a API da Hugging Face que extraímos com segurança do Kaggle Secrets.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)Faça login no Weights & Biases (wandb) usando sua chave de API e crie um novo projeto para acompanhar os experimentos e o progresso do ajuste fino.
import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune-DeepSeek-R1-Distill-Llama-8B on Medical COT Dataset',
job_type="training",
anonymous="allow"
)Para este projeto, estamos carregando a versão Unsloth do DeepSeek-R1-Distill-Llama-8B. Além disso, carregaremos o modelo em quantização de 4 bits para otimizar o uso da memória e o desempenho.
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
token = hf_token,
)Para criar um estilo de prompt para o modelo, definiremos um prompt do sistema e incluiremos espaços reservados para a geração de perguntas e respostas. O prompt orientará o modelo a pensar passo a passo e a fornecer uma resposta lógica e precisa.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""Neste exemplo, forneceremos uma pergunta médica ao prompt_style, a converteremos em tokens e, em seguida, passaremos os tokens ao modelo para a geração de respostas.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])Mesmo sem ajuste fino, nosso modelo gerou com sucesso uma cadeia de pensamento e forneceu raciocínio antes de fornecer a resposta final. O processo de raciocínio é encapsulado nas tags <think></think>.
Então, por que ainda precisamos de um ajuste fino? O processo de raciocínio, embora detalhado, foi longo e não conciso. Além disso, a resposta final foi apresentada em um formato de marcador, que se desvia da estrutura e do estilo do conjunto de dados que queremos ajustar.
<think>
Okay, so I have this medical question to answer. Let me try to break it down. The patient is a 61-year-old woman with a history of involuntary urine loss during activities like coughing or sneezing, but she doesn't leak at night. She's had a gynecological exam and a Q-tip test. I need to figure out what cystometry would show regarding her residual volume and detrusor contractions.
First, I should recall what I know about urinary incontinence. Involuntary urine loss during activities like coughing or sneezing makes me think of stress urinary incontinence. Stress incontinence typically happens when the urethral sphincter isn't strong enough to resist increased abdominal pressure from activities like coughing, laughing, or sneezing. This usually affects women, especially after childbirth when the pelvic muscles and ligaments are weakened.
The Q-tip test is a common diagnostic tool for stress urinary incontinence. The test involves inserting a Q-tip catheter, which is a small balloon catheter, into the urethra. The catheter is connected to a pressure gauge. The patient is asked to cough, and the pressure reading is taken. If the pressure is above normal (like above 100 mmHg), it suggests that the urethral sphincter isn't closing properly, which is a sign of stress incontinence.
So, based on the history and the Q-tip test, the diagnosis is likely stress urinary incontinence. Now, moving on to what cystometry would show. Cystometry, also known as a filling cystometry, is a diagnostic procedure where a catheter is inserted into the bladder, and the bladder is filled with a liquid to measure how much it can hold (residual volume) and how it responds to being filled (like during a cough or sneeze). This helps in assessing the capacity and compliance of the bladder.
In a patient with stress incontinence, the bladder's capacity might be normal, but the sphincter's function is impaired. So, during the cystometry, the residual volume might be within normal limits because the bladder isn't overfilled. However, when the patient is asked to cough or perform a Valsalva maneuver, the detrusor muscle (the smooth muscle layer of the bladder) might not contract effectively, leading to an increase in intra-abdominal pressure, which might cause leakage.
Wait, but detrusor contractions are usually associated with voiding. In stress incontinence, the issue isn't with the detrusor contractions but with the sphincter's inability to prevent leakage. So, during cystometry, the detrusor contractions would be normal because they are part of the normal voiding process. However, the problem is that the sphincter doesn't close properly, leading to leakage.
So, putting it all together, the residual volume might be normal, but the detrusor contractions would be normal as well. The key finding would be the impaired sphincter function leading to incontinence, which is typically demonstrated during the Q-tip test and clinical history. Therefore, the cystometry would likely show normal residual volume and normal detrusor contractions, but the underlying issue is the sphincter's inability to prevent leakage.
</think>
Based on the provided information, the cystometry findings in this 61-year-old woman with stress urinary incontinence would likely demonstrate the following:
1. **Residual Volume**: The residual volume would be within normal limits. This is because the bladder's capacity is typically normal in cases of stress incontinence, where the primary issue lies with the sphincter function rather than the bladder's capacity.
2. **Detrusor Contractions**: The detrusor contractions would also be normal. These contractions are part of the normal voiding process and are not impaired in stress urinary incontinence. The issue is not with the detrusor muscle but with the sphincter's inability to prevent leakage.
In summary, the key findings of the cystometry would be normal residual volume and normal detrusor contractions, highlighting the sphincteric defect as the underlying cause of the incontinence.<|end▁of▁sentence|>Alteraremos um pouco o estilo do prompt para processar o conjunto de dados, adicionando o terceiro espaço reservado para a coluna de cadeia de pensamento complexa.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Escreva a função Python que criará uma coluna de "texto" no conjunto de dados, que consiste no estilo do prompt de treinamento. Preencha os espaços reservados com perguntas, cadeias de texto e respostas.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}Carregaremos as primeiras 500 amostras do arquivo FreedomIntelligence/medical-o1-reasoning-SFT que está disponível no hub Hugging Face. Depois disso, mapearemos a coluna text usando a função formatting_prompts_func.
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT","en", split = "train[0:500]",trust_remote_code=True)
dataset = dataset.map(formatting_prompts_func, batched = True,)
dataset["text"][0]Como você pode ver, a coluna de texto tem um prompt do sistema, instruções, cadeia de raciocínio e a resposta.
"Below is an instruction that describes a task, paired with an input that provides further context. \nWrite a response that appropriately completes the request. \nBefore answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.\n\n### Instruction:\nYou are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning. \nPlease answer the following medical question. \n\n### Question:\nA 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?\n\n### Response:\n<think>\nOkay, let's think about this step by step. There's a 61-year-old woman here who's been dealing with involuntary urine leakages whenever she's doing something that ups her abdominal pressure like coughing or sneezing. This sounds a lot like stress urinary incontinence to me. Now, it's interesting that she doesn't have any issues at night; she isn't experiencing leakage while sleeping. This likely means her bladder's ability to hold urine is fine when she isn't under physical stress. Hmm, that's a clue that we're dealing with something related to pressure rather than a bladder muscle problem. \n\nThe fact that she underwent a Q-tip test is intriguing too. This test is usually done to assess urethral mobility. In stress incontinence, a Q-tip might move significantly, showing urethral hypermobility. This kind of movement often means there's a weakness in the support structures that should help keep the urethra closed during increases in abdominal pressure. So, that's aligning well with stress incontinence.\n\nNow, let's think about what would happen during cystometry. Since stress incontinence isn't usually about sudden bladder contractions, I wouldn't expect to see involuntary detrusor contractions during this test. Her bladder isn't spasming or anything; it's more about the support structure failing under stress. Plus, she likely empties her bladder completely because stress incontinence doesn't typically involve incomplete emptying. So, her residual volume should be pretty normal. \n\nAll in all, it seems like if they do a cystometry on her, it will likely show a normal residual volume and no involuntary contractions. Yup, I think that makes sense given her symptoms and the typical presentations of stress urinary incontinence.\n</think>\nCystometry in this case of stress urinary incontinence would most likely reveal a normal post-void residual volume, as stress incontinence typically does not involve issues with bladder emptying. Additionally, since stress urinary incontinence is primarily related to physical exertion and not an overactive bladder, you would not expect to see any involuntary detrusor contractions during the test.<|end▁of▁sentence|>"Usando os módulos de destino, configuraremos o modelo adicionando o adotante de baixa classificação ao modelo.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)Em seguida, configuraremos os argumentos de treinamento e o instrutor, fornecendo o modelo, os tokenizadores, o conjunto de dados e outros parâmetros de treinamento importantes que otimizarão nosso processo de ajuste fino.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)Execute o seguinte comando para iniciar o treinamento.
trainer_stats = trainer.train()O processo de treinamento levou 44 minutos para ser concluído. A perda de treinamento foi reduzida gradualmente, o que é um bom sinal de melhor desempenho do modelo.
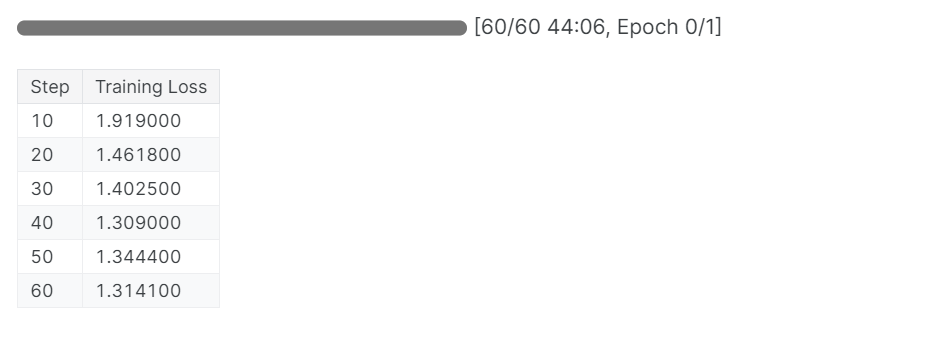
Você pode visualizar o relatório de avaliação do modelo de preenchimento no painel de pesos e medidas fazendo login no site e visualizando o projeto.
Se você tiver problemas ao executar o código acima, consulte a seção Ajuste fino do DeepSeek R1 (modelo de raciocínio) Caderno do Kaggle.
Para comparar os resultados, faremos ao modelo ajustado a mesma pergunta que fizemos antes para ver o que mudou.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
Isso é muito melhor e mais preciso. A cadeia de pensamento foi direta, e a resposta foi direta e em um parágrafo. O ajuste fino foi bem-sucedido.
<think>
Okay, so let's think about this. We have a 61-year-old woman who's been dealing with involuntary urine loss during things like coughing or sneezing, but she's not leaking at night. That suggests she might have some kind of problem with her pelvic floor muscles or maybe her bladder.
Now, she's got a gynecological exam and a Q-tip test. Let's break that down. The Q-tip test is usually used to check for urethral obstruction. If it's positive, that means there's something blocking the urethra, like a urethral stricture or something else.
Given that she's had a positive Q-tip test, it's likely there's a urethral obstruction. That would mean her urethra is narrow, maybe due to a stricture or some kind of narrowing. So, her bladder can't empty properly during activities like coughing because the urethral obstruction is making it hard.
Now, let's think about what happens when her bladder can't empty. If there's a urethral obstruction, the bladder is forced to hold more urine, increasing the residual volume. That's because her bladder doesn't empty completely. So, her residual volume is probably increased.
Also, if her bladder can't empty properly, she might have increased detrusor contractions. These contractions are usually stronger to push the urine out. So, we expect her detrusor contractions to be increased.
Putting it all together, if she has a urethral obstruction and a positive Q-tip test, we'd expect her cystometry results to show increased residual volume and increased detrusor contractions. That makes sense because of the obstruction and how her bladder is trying to compensate by contracting more.
</think>
Based on the findings of the gynecological exam and the positive Q-tip test, it is most likely that the cystometry would reveal increased residual volume and increased detrusor contractions. The positive Q-tip test indicates urethral obstruction, which would force the bladder to retain more urine, thereby increasing the residual volume. Additionally, the obstruction can lead to increased detrusor contractions as the bladder tries to compensate by contracting more to expel the urine.<|end▁of▁sentence|>
Agora, vamos salvar o adotador, o modelo completo e o tokenizador localmente para que possamos usá-los em outros projetos.
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method = "merged_16bit",)
Também enviaremos o adotador, o tokenizador e o modelo para o Hugging Face Hub para que a comunidade de IA possa aproveitar esse modelo integrando-o aos seus sistemas.
new_model_online = "kingabzpro/DeepSeek-R1-Medical-COT"
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method = "merged_16bit")
Fonte: kingabzpro/DeepSeek-R1-Medical-COT - Cara de Abraço
A próxima etapa de sua jornada de aprendizado é servir e implementar seu modelo na nuvem. Você pode seguir o guia Como implantar LLMs com o BentoML que fornece um processo passo a passo para você implantar grandes modelos de linguagem de forma eficiente e econômica usando o BentoML e ferramentas como o vLLM.
Como alternativa, se preferir usar o modelo localmente, você pode convertê-lo no formato GGUF e executá-lo em seu computador. Para isso, confira o artigo Como ajustar a Llama 3.2 e usá-la localmente que fornece instruções detalhadas sobre o uso local.
As coisas estão mudando rapidamente no campo da IA. A comunidade de código aberto agora está assumindo o controle, desafiando o domínio dos modelos proprietários que dominaram o cenário da IA nos últimos três anos.
Os modelos de linguagem de grande porte (LLMs) de código aberto estão se tornando melhores, mais rápidos e mais eficientes, o que torna mais fácil do que nunca ajustá-los com menos recursos de computação e memória.
Neste tutorial, exploramos o modelo de raciocínio DeepSeek R1 e aprendemos a ajustar sua versão destilada para tarefas de perguntas e respostas médicas. Um modelo de raciocínio bem ajustado não apenas melhora o desempenho, mas também permite sua aplicação em campos essenciais, como medicina, serviços de emergência e saúde.
Para compensar o lançamento do DeepSeek R1, a OpenAI introduziu duas ferramentas poderosas: O o3 da OpenAI, um modelo de raciocínio mais avançado, e o agente Operator AI da OpenAI, com tecnologia do novo modelo Computer-Using Agent (CUA), que pode navegar de forma autônoma em sites e executar tarefas.
Principais cursos da DataCamp
Curso
Curso
Curso
blog
DataCamp Team
4 min
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Aashi Dutt
Tutorial
Josep Ferrer
Tutorial
Moez Ali


