Fotos e vídeos estão por toda parte. Como seres humanos, dependemos de nossa visão para várias tarefas, como dirigir, reconhecer nossos amigos e diagnosticar problemas. À medida que os computadores se tornam mais envolvidos em nossas tarefas diárias, é cada vez mais importante que eles também possam usar imagens. A análise de imagens é o meio pelo qual os computadores podem "ver" e entender uma imagem. Quando a análise de imagens é feita com base no aprendizado de máquina, nós a chamamos de visão computacional.
Este tutorial mostrará como os computadores "veem" as imagens, abordará os conceitos básicos de manipulação de imagens e, por fim, discutirá como o aprendizado de máquina e a IA generativa podem ser aplicados às imagens. Vamos começar!
Se estiver interessado em saber mais sobre classificação de imagens, confira nosso code-along sobre Classificação de imagens com Hugging Face.
O que é visão computacional?
A visão computacional é um campo da inteligência artificial que permite que computadores e sistemas obtenham informações significativas de imagens digitais, vídeos e outras entradas visuais. É a ciência e a tecnologia de máquinas que podem ver. Como uma disciplina científica, a visão computacional busca aplicar suas teorias e modelos à construção de sistemas de visão computacional.
Em sua essência, a visão computacional tem tudo a ver com a interpretação de dados visuais. Envolve a aquisição, o processamento, a análise e a compreensão de imagens digitais para extrair dados de alta dimensão do mundo real a fim de produzir informações numéricas ou simbólicas que possam ser usadas por uma máquina. Ele emprega vários métodos e técnicas de uma ampla gama de disciplinas, como física, matemática, engenharia elétrica e ciência da computação.
Introdução à análise de imagens
No nível mais baixo, os computadores operam com 1 e 0. Isso não é diferente quando se trabalha com imagens. Os computadores podem representar uma imagem como uma matriz de 1's e 0's. Quando um computador exibe uma imagem, ele exibe uma grade de pixels, cada um preenchido com uma cor. Considere uma forma muito simples, como o triângulo preto abaixo.
![]()
Figura 1: Um triângulo simples, de baixa resolução, composto de 28 pixels.
Essa forma é composta de 28 pixels: 16 pixels pretos e 12 pixels brancos. Você pode ver cada um dos pixels delineados na imagem abaixo.
![]()
Figura 2: Triângulo preto com cada pixel delineado.
Mas essa imagem é apenas uma representação da matriz de números armazenada pelo computador.
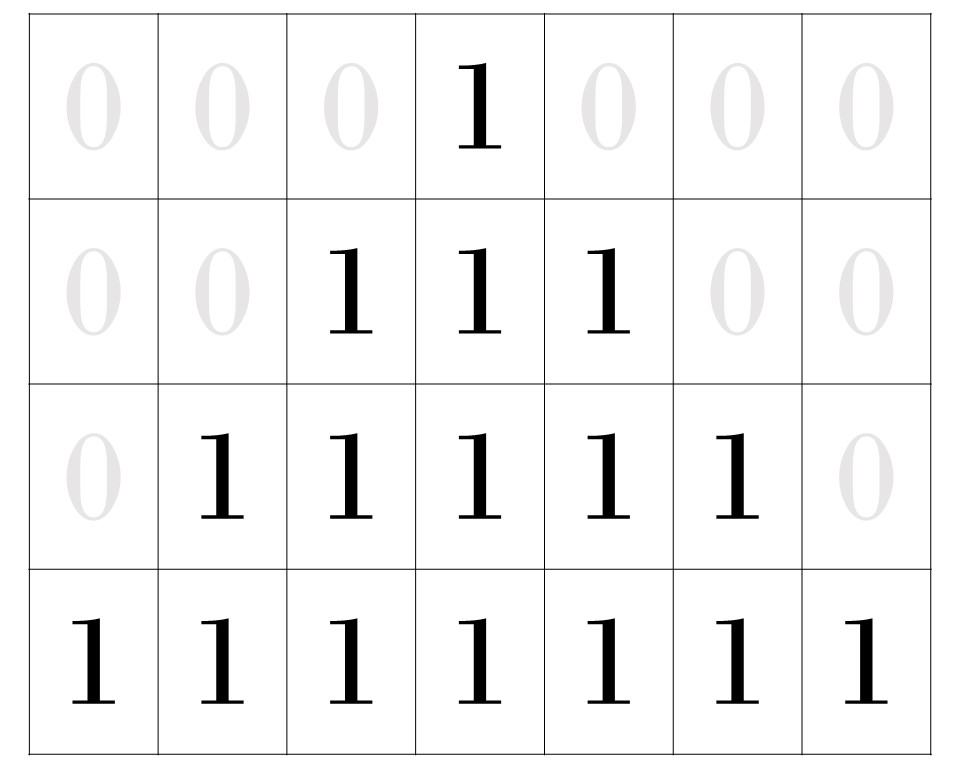
Figura 3: Uma demonstração dos 1's e 0's na matriz que compõe a imagem do triângulo.
Isso é bastante simples para imagens com apenas duas cores: preto e branco. Se sua imagem tiver tons de cinza, você precisará adicionar mais nuances. Em vez disso, você pode acabar com números como 0,015 nas caixas. Esse número basicamente informa ao computador qual luminância deve ser dada a cada pixel na tela. Ele define um valor entre preto (1) e branco (0).
Análise de imagens coloridas
Mas as imagens raramente são tão monótonas. O que os computadores fazem com imagens coloridas? Vamos tornar esse triângulo verde!
![]()
Figura 4: O mesmo triângulo de 28 pixels de antes, mas com um toque de cor!
Nesse caso, não é possível usar um número entre zero e um para descrever essa cor. Há um número excessivo de cores disponíveis para atribuir a cada uma delas um número único que seja intuitivo.
Em vez disso, alguns sistemas foram desenvolvidos para separar os componentes individuais de uma cor e atribuir números a cada componente.
Por exemplo, você pode ter ouvido falar de RGB. Esse é um modelo de cor que divide cada cor na quantidade de vermelho, verde e azul, respectivamente, que se combinam para criar a cor que você está buscando.
O modelo RGB tem origem no uso de telas que têm pixels vermelhos, verdes e azuis, como as televisões. Esse modelo permite o tipo de mistura de cores aditiva usada pela luz nesses dispositivos.
Nesse sistema, o vermelho, o azul e o verde são chamados de "canais". Para uma imagem de 8 bits, cada canal recebe um valor entre 0 e 255 (que é o valor máximo que um número binário de 8 dígitos pode ter).
Vamos examinar o que isso significa para o nosso triângulo verde simples.
Os valores RGB para esse tom de verde são 154, 205 e 50, respectivamente. Observe que, se esse fosse um verde puro, os canais vermelho e azul seriam 0. Essa representação RGB nos mostra que há muito vermelho e um pouco de azul misturados ao verde para criar essa tonalidade. Cada pixel tem três canais de valores que o descrevem. Cada pixel verde é representado por 154, 205, 50, e cada pixel branco é representado por 0, 0, 0.
Isso significa que esse triângulo verde simples de 28 pixels é representado por três matrizes 7x4.
Você pode imaginar essas três matrizes empilhadas umas sobre as outras para criar essa imagem.
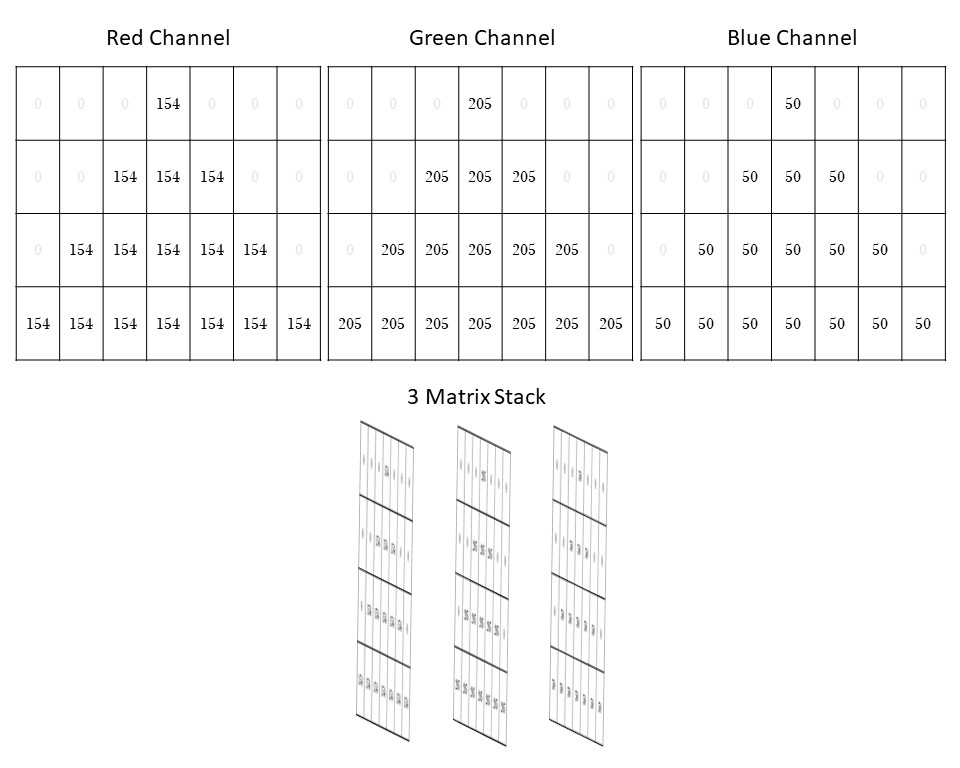
Figura 5: Para esse triângulo verde simples, cada canal de cor no sistema de cores RGB contém uma matriz de valores de pixel que representa a imagem. Quando combinadas, essas três matrizes se acumulam para criar essa única imagem!
Você pode ver como as imagens podem rapidamente começar a ocupar muito espaço em um computador se cada pixel exigir três números para defini-lo. Reserve um momento para pensar em quantos números compõem uma imagem de alta resolução, por exemplo, uma imagem 4K (que tem 4.000 pixels).
O RGB não é o único sistema usado para atribuir cores a imagens. Talvez você já tenha ouvido falar do CYMK, que usa quatro números para descrever cada cor. Esse modelo usa quatro cores: ciano, magenta, amarelo e preto. Isso é útil em situações em que você precisa de um modelo de cor subtrativo, por exemplo, na impressão.
Cada sistema de cores tem vantagens e desvantagens, e pode valer a pena investigar alguns deles se você estiver enfrentando problemas de memória ao analisar imagens. Para fins deste tutorial, vamos nos ater ao RGB.
Então, o que você pode fazer com essas matrizes de valores de pixel?
Técnicas de análise manual de imagens
Isolamento de objetos com limiarização
Como um computador determina quais pixels representam um rosto ou outro objeto? Atualmente, grande parte desse trabalho de identificação é feita usando modelos de aprendizado de máquina. Mas, para entendê-las, é útil entender primeiro como isolar manualmente uma figura em uma imagem.
Imagine que você tenha um vídeo de dois lagartos em um fundo claro. Para simplificar, você transforma o vídeo em escala de cinza, portanto, há apenas um canal a ser considerado. Você está interessado em rastrear o movimento do lagarto durante o vídeo.
Um vídeo é apenas uma série de fotos (ou quadros) empilhadas. Portanto, a primeira coisa que você precisa fazer é separar essa pilha e tirar uma foto de cada vez. Agora que você tem uma foto em escala de cinza, precisa mostrar ao computador qual parte da foto é um lagarto e qual não é.
Teoricamente, você poderia usar o mouse para apontar para cada pixel que compõe o lagarto e rotulá-lo como "lagarto". Mas, considerando a resolução da maioria das fotos e o fato de que você tem muitas fotos que compõem o seu vídeo, essa é uma proposta irracional.
Em vez disso, você pode criar uma regra que informe ao computador o que faz parte do lagarto e o que não faz. A maneira mais simples de fazer isso é por meio de limiarização.

Figura 6: Para simplificar, trabalharemos com essa foto em escala de cinza.
O que é limiarização?
Limiarização é o processo de segmentação de uma imagem com base no valor numérico atribuído a cada pixel. Observe novamente a imagem em escala de cinza dos lagartos. Observe como os lagartos parecem mais escuros do que o fundo. Em muitas imagens, haverá uma diferença de luminância entre o objeto que queremos isolar e seu plano de fundo.
Limiarização é o processo de encontrar a borda do objeto, nesse caso os lagartos, usando essa diferença de luminância. Essa técnica visa definir um limiar de luminância que separa os pixels claros dos escuros.
Criação de uma imagem binária
Imagine a matriz de números que define essa imagem em escala de cinza. Cada pixel é definido por um número entre 0 e 255.
Com o limite, você pode definir uma regra segundo a qual qualquer coisa suficientemente escura é um lagarto. Por exemplo, você poderia dizer que qualquer pixel com valor igual ou superior a 130 é um lagarto, e qualquer pixel com valor inferior a 130 não é um lagarto.
Tecnicamente, você definiria qualquer coisa com nosso valor de limite ou superior como 255 e todo o resto como 0. Isso cria uma imagem binária com pixels em preto e branco. Se você tiver escolhido um bom valor de limite, os lagartos ficarão pretos em um fundo branco.

Figura 7: Imagem binária gerada pela definição de um limite de 130.
Neste exemplo, escolhemos apenas um número arbitrário como nosso limite: 130. No entanto, para isolar com precisão nossos lagartos, você deve escolher um número que capture a grande maioria dos lagartos e, ao mesmo tempo, minimize os pixels que não fazem parte dos lagartos.
Esse processo de escolha de um valor de limiar para toda a imagem é chamado de limiarização global. É uma maneira grosseira de isolar seu alvo e, muitas vezes, é altamente imperfeita. Se você tiver um lagarto perfeitamente silhuetado em um fundo perfeitamente branco, a limiarização global funcionará perfeitamente. Mas, como você pode ver no exemplo do lagarto, as imagens reais raramente são tão fáceis. Provavelmente, você precisará de um método mais complexo de limiarização.
Um desses métodos é chamado de limiarização local. Nessa técnica, você escolhe diferentes valores de limiar para diferentes partes da imagem. Isso é especialmente útil quando você tem um gradiente de iluminação no plano de fundo. Há muitos outros métodos de otimização que variam em complexidade, e o que você escolher dependerá de suas circunstâncias.
Também é possível limar imagens coloridas. Fazer isso é muito mais complicado e está fora do escopo deste tutorial.
Análise morfológica
Embora a limiarização possa ajudar bastante a isolar esses lagartos, ela não é perfeita. Você ainda pode acabar com partes do plano de fundo sendo definidas como um lagarto ou com partes do lagarto faltando. Você precisa de outra ferramenta para isolar ainda mais os animais. Com a limitação, você definiu uma regra com base na cor ou na iluminância. Agora você definirá uma regra com base na forma, usando operações morfológicas.
Definição de uma forma com elementos de estruturação
As operações morfológicas usam elementos estruturantes para determinar as bordas das formas. Um elemento estruturante é uma pequena matriz com um formato específico, geralmente um quadrado, um círculo ou uma cruz. Você também pode alterar o tamanho do elemento de estruturação para obter efeitos diferentes.
Durante uma operação morfológica, cada pixel é comparado com seus vizinhos dentro dessa forma. Há duas operações morfológicas básicas que podem ser usadas para definir a forma do objeto pretendido: dilatação e erosão.
Dilatação
Na dilatação, se qualquer pixel vizinho dentro dos limites do elemento de estruturação estiver escuro (nesse caso, 1), o pixel de destino será transformado em 1 para corresponder.
Imagine examinar uma grade de números com uma lente de aumento quadrada. Você coloca um dos números no meio do quadrado e, em seguida, observa os outros números dentro desse quadrado. Se algum deles for 1, então você rotulará o número no meio como 1, independentemente do que era no início.
Dessa forma, a dilatação pode expandir as bordas dos objetos ou preencher buracos.
Erosão
A erosão funciona da mesma forma que a dilatação, mas com o efeito oposto. Com a erosão, se algum dos vizinhos de um pixel for um 0, esse pixel será redefinido como 0. Isso pode servir para separar objetos, reduzir o ruído e refinar os limites.
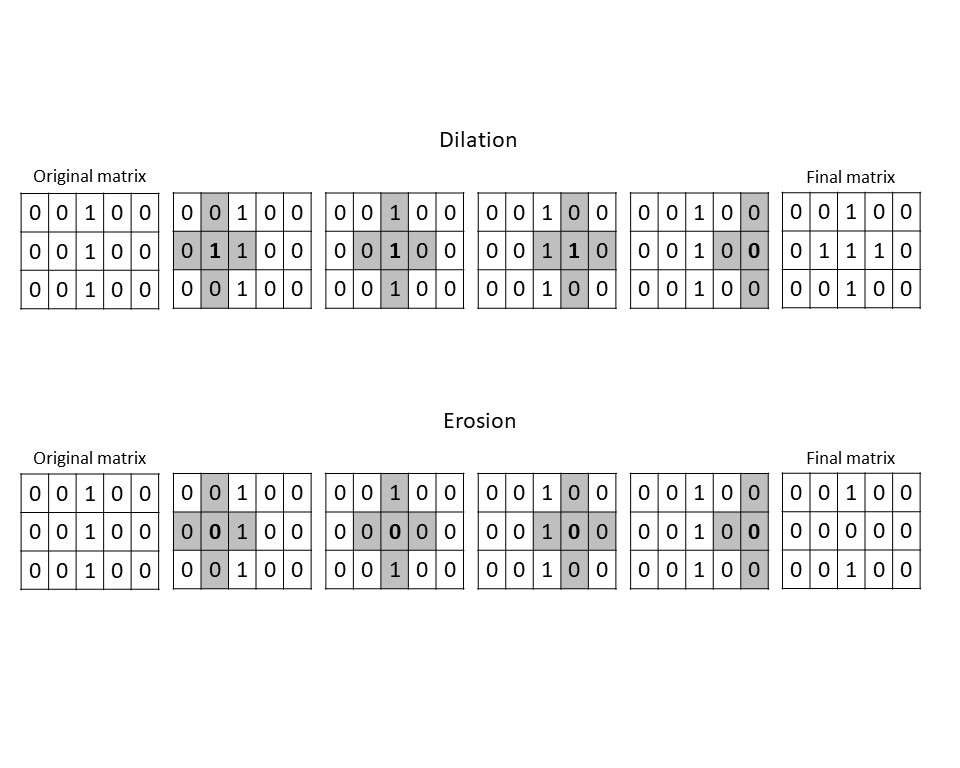
Figura 8: Exemplo visual de dilatação e erosão usando um elemento de estruturação em forma de cruz. Neste exemplo, só realizamos a operação morfológica na segunda linha da matriz. Em uma imagem real, ele seria aplicado a cada pixel. Mas mesmo com esse exemplo simples, você pode ver como a erosão separou as bordas da linha, enquanto a dilatação a engrossou.
Você pode ver como a dilatação e a erosão modificam a imagem binária do lagarto.

Figura 9: Exemplo de erosão e dilatação sendo aplicadas à foto do lagarto. O elemento de estruturação usado aqui foi um quadrado 6x6.
Combinação de dilatação e erosão
A dilatação e a erosão podem ser usadas de forma iterativa ou sequencial para alterar o produto final. É prática comum usar tanto a dilatação quanto a erosão para definir melhor sua imagem isolada.
Quando a erosão é seguida de dilatação, pequenas protuberâncias e ruídos são removidos, e o contorno restante é reforçado. Essa técnica é chamada de abertura.
Quando a dilatação é seguida pela erosão, pequenos buracos e lacunas são preenchidos e as bordas são arrumadas. Essa técnica é chamada de fechamento.

Figura 10: Demonstração de técnicas de abertura e fechamento usando um elemento de estruturação quadrado 6x6 na foto do lagarto.
Você pode ver que nenhuma dessas imagens isola completamente nossos lagartos do fundo. Mas com cada ajuste e iteração, você pode chegar cada vez mais perto.
Na próxima iteração, você poderia dizer ao computador para ignorar qualquer coisa fora de uma determinada faixa de tamanho. Isso removeria a maior parte das manchas e deixaria os lagartos intactos. Aprenda a fazer isso você mesmo no curso Processamento de imagens em Python no DataCamp!
Para cada imagem ou série de imagens, você pode configurar uma série de regras como essas para informar ao computador como é o seu alvo. Em seguida, o computador pode usar essas informações para tomar decisões.
Essas decisões influenciam tudo, desde a identificação de galáxias até a localização de tecidos doentes. Mas criar uma série de regras para cada imagem individualmente é demorado e tedioso. É aí que o aprendizado de máquina entra em ação.
Aprendizado de máquina supervisionado para análise de imagens
Treinamento de um modelo de ML supervisionado
Como você viu, a análise manual de imagens pode ser exigente, pois há um número enorme de variáveis em jogo. Felizmente, o aprendizado de máquina (ML) pode ajudar a automatizar esse processo. Para uma análise aprofundada do aprendizado de máquina, você pode conferir Machine Learning Scientist with Python ou Supervised Machine Learning. Este tutorial abordará apenas brevemente os aspectos de aprendizado de máquina úteis para entender o processamento de imagens.
Há duas grandes categorias de AM: AM supervisionado e AM não supervisionado.
Com o ML supervisionado, você basicamente fornece ao computador um grande número de imagens e as rotula antecipadamente. É um pouco como ensinar a um bebê a aparência dos animais apontando para eles e dizendo: "Este é um elefante". Cabe ao bebê descobrir um padrão para as coisas que chamamos de elefantes e as coisas que chamamos de peixes.
No ML supervisionado, o computador está fazendo um trabalho semelhante ao do bebê.

Figura 11: O DALLE-E gerou uma imagem da mãe apontando para animais de brinquedo para ensinar ao bebê como eles são. O aprendizado supervisionado funciona de maneira semelhante, em que são fornecidos exemplos com a resposta correta.
Anotação e extração de recursos
Vamos supor que você queira treinar um modelo de aprendizado de máquina para identificar objetos em uma imagem que ele nunca encontrou. A primeira etapa do treinamento desse modelo de aprendizado de máquina supervisionado é anotar e rotular uma coleção de imagens, chamada de conjunto de dados de treinamento. A anotação envolve a identificação e a marcação manual das regiões de interesse em uma imagem.
Por exemplo, se quisermos treinar um modelo para classificar diferentes tipos de animais, anotaríamos cada imagem delineando os animais presentes na imagem e atribuindo a eles o rótulo da classe correspondente, "vaca", "gato" etc. Esse conjunto de dados anotados torna-se a base para o treinamento do modelo. Há também muitos conjuntos de dados já rotulados que estão disponíveis publicamente para você trabalhar.
Depois de ter o conjunto de dados de treinamento rotulado, você precisa extrair os recursos relevantes das imagens. A extração de recursos envolve a identificação e a captura de características ou padrões importantes que distinguem uma classe de outra.
Em nosso exemplo de animal, você pode definir uma característica importante das vacas como ter quatro patas e manchas.
Redes neurais convolucionais
Há várias técnicas disponíveis para a extração de recursos no processamento de imagens, desde métodos simples, como histogramas de cores e descritores de textura, até abordagens mais avançadas, como redes neurais convolucionais (CNNs).
As CNNs são um algoritmo popular de aprendizado supervisionado que aprende automaticamente características e padrões importantes de imagens rotuladas durante o treinamento. Eles são compostos de camadas, sendo que cada camada realiza operações específicas nos dados da imagem.
As camadas convolucionais aplicam filtros para capturar padrões locais, enquanto as camadas de agrupamento reduzem as dimensões espaciais. As camadas totalmente conectadas combinam informações das camadas anteriores. Por meio dessas operações sequenciais, a rede extrai e combina recursos para fazer previsões precisas sobre o que há na imagem.
Escolha de uma arquitetura
O processo de treinamento de um modelo de ML supervisionado, como uma CNN, envolve várias etapas. Primeiro, os dados precisam ser pré-processados para garantir a consistência e a qualidade. Isso pode envolver o redimensionamento das imagens, a normalização dos valores de pixel e o aumento do conjunto de dados com a aplicação de transformações como rotações ou inversões para aumentar sua diversidade.
Em seguida, você projetará a arquitetura do modelo CNN. Essencialmente, a arquitetura é apenas o número e o tipo de camadas que você usa e as configurações em que as usa. A arquitetura deve ser cuidadosamente escolhida para equilibrar complexidade e simplicidade, permitindo que o modelo capture os recursos essenciais e, ao mesmo tempo, evite o ajuste excessivo. Pode ser útil começar com uma arquitetura estabelecida e ajustá-la às suas necessidades. Você pode encontrar uma lista útil de arquiteturas em um recurso externo.
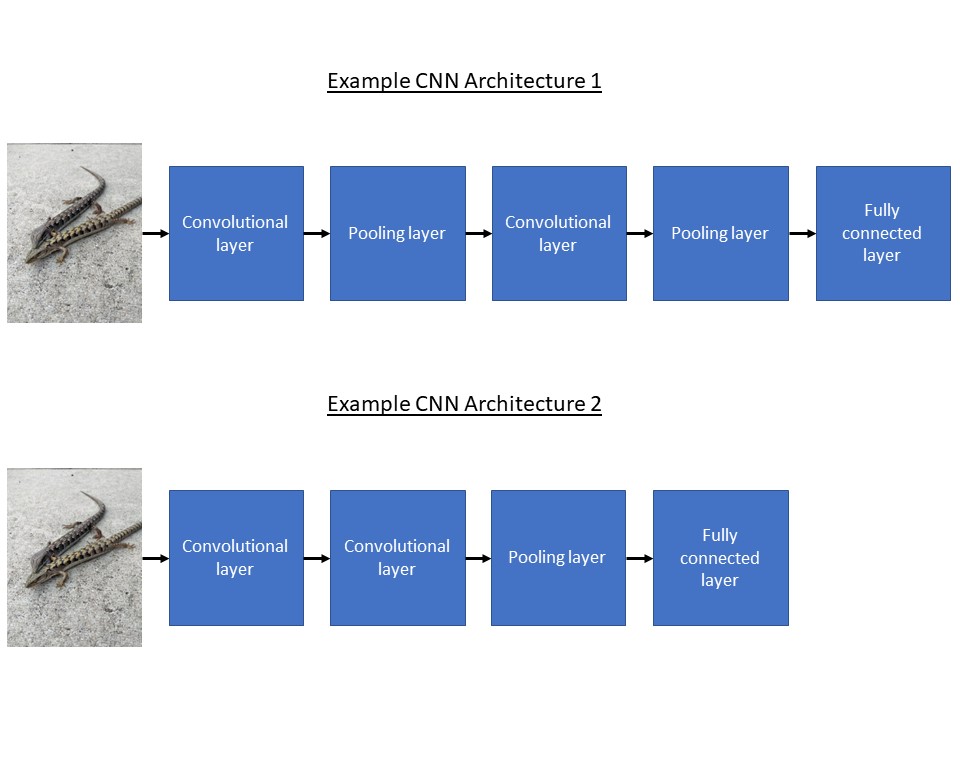
Figura 12: Exemplos simples de arquiteturas de CNN.
Ajuste excessivo
Overfitting é quando o computador se torna muito bom em rotular as imagens no conjunto de dados de treinamento, mas não consegue identificar com precisão as imagens que não estão no conjunto de treinamento.
Esse ajuste excessivo geralmente ocorre porque o computador detectou algum viés que nós, humanos, introduzimos acidentalmente no conjunto de treinamento que não representa a vida real (como a maioria das fotos de gatos com fundo azul, por exemplo). Há muitas técnicas para ajudar a evitar que o modelo memorize os dados de treinamento e, em vez disso, incentivá-lo a aprender padrões mais generalizáveis.
Treinamento de um modelo ML supervisionado
Depois que a arquitetura do modelo for definida, você precisará inicializar os parâmetros do modelo e iniciar o processo de treinamento.
Durante o treinamento, o modelo ajusta iterativamente seus parâmetros usando técnicas de otimização, como a descida de gradiente, para minimizar a diferença entre suas previsões e os rótulos da verdade básica que você definiu anteriormente.
Esse processo envolve o cálculo da função de perda, que quantifica o erro de previsão do modelo, e a atualização dos parâmetros de acordo.
O treinamento de um modelo de ML supervisionado para análise de imagens é um processo iterativo. Você treina o modelo usando o conjunto de dados rotulados, avalia seu desempenho em um conjunto de validação e faz ajustes para melhorar sua precisão. Esse loop iterativo continua até que o modelo alcance resultados satisfatórios.
Aplicação de modelos ML supervisionados na análise de imagens
Depois que o modelo de ML supervisionado tiver sido treinado em dados de imagem rotulados, ele poderá ser aplicado a várias tarefas na análise de imagens. Abaixo estão alguns aplicativos comuns que destacam a eficácia dos modelos de ML supervisionados em tarefas de processamento de imagens.
Classificação de imagens
A classificação de imagens é uma tarefa fundamental em que o objetivo é atribuir um rótulo ou classe a uma imagem de entrada.
Por exemplo, um modelo de ML supervisionado pode ser treinado para classificar imagens de animais em diferentes categorias, como "peixe", "lagarto" ou "besouro".

Figura 13: Um exemplo de classificação de imagens. Esta imagem foi classificada como "Jantar".
Ao aprender com um conjunto de dados diversificado com exemplos rotulados, o modelo pode generalizar e classificar com precisão as imagens com um alto nível de exatidão. Essa técnica pode ser usada em tarefas como a identificação de doenças em imagens médicas, o reconhecimento de objetos em imagens de satélite e até mesmo a classificação de emoções a partir de expressões faciais. Confira este webinar do DataCamp sobre o assunto para obter mais detalhes.
Detecção de objetos
A detecção de objetos é outra aplicação importante dos modelos supervisionados de ML na análise de imagens. Diferentemente da classificação de imagens, a detecção de objetos envolve não apenas a identificação dos objetos presentes em uma imagem, mas também sua localização, desenhando caixas delimitadoras ao redor deles.
Esse processo permite que o modelo identifique vários objetos de interesse em uma imagem.

Figura 14: Um exemplo de detecção de objetos. Vários objetos nessa imagem foram identificados.
As aplicações da detecção de objetos incluem direção autônoma, em que os modelos podem detectar e rastrear pedestres, veículos e sinais de trânsito, bem como sistemas de vigilância para identificar e rastrear indivíduos ou objetos de interesse. O Facebook e o Instagram também usam esse método quando encontram seu rosto em fotos.
Desafios dos modelos de ML supervisionados
Embora os recursos dos modelos de ML supervisionados na análise de imagens sejam impressionantes, é preciso estar ciente das limitações e dos desafios.
Um dos principais desafios é a necessidade de grandes quantidades de dados de treinamento rotulados. O processo de anotação e rotulagem de imagens pode consumir muito tempo e recursos.
Os modelos de ML supervisionados também são sensíveis às tendências presentes nos dados de treinamento, o que pode levar a previsões tendenciosas ou resultados injustos. A adaptação dos modelos a novos domínios ou a novas categorias de imagens pode exigir treinamento adicional ou ajuste fino.
E interpretar as representações aprendidas e os processos de tomada de decisão de modelos complexos como as CNNs pode ser um desafio, tornando mais difícil entender por que um modelo fez uma previsão específica.
Apesar desses desafios, os modelos supervisionados de ML continuam a ampliar os limites da análise de imagens, permitindo avanços notáveis em áreas como saúde, agricultura e segurança.
Com o avanço da pesquisa e do desenvolvimento no campo, a abordagem desses desafios e o refinamento dos modelos abrirão caminho para soluções de processamento de imagens ainda mais precisas e confiáveis.
Aprendizado de máquina não supervisionado para análise de imagens
Uso do aprendizado não supervisionado
Uma alternativa ao aprendizado supervisionado é o aprendizado de máquina não supervisionado. Diferentemente do aprendizado supervisionado, o aprendizado não supervisionado não depende de dados rotulados, mas tem como objetivo descobrir padrões, estruturas ou relacionamentos ocultos nos próprios dados.
O objetivo do aprendizado não supervisionado na análise de imagens é descobrir estruturas e percepções significativas a partir de dados de imagem não rotulados. Ao utilizar técnicas de aprendizado não supervisionado, você pode extrair informações valiosas e obter uma compreensão mais profunda das características subjacentes das imagens.
O aprendizado não supervisionado pode ajudar a identificar grupos de imagens semelhantes, descobrir padrões ou texturas que são característicos de determinadas classes de imagens e detectar anomalias ou discrepâncias nos dados.
Como o aprendizado não supervisionado é diferente
Se o aprendizado supervisionado é como dizer a um bebê o que é uma vaca e o que é um peixe, então o aprendizado não supervisionado é como dar a um bebê um monte de animais e deixar que ele os classifique como achar melhor. Eles podem classificar os animais em categorias por tamanho, número de patas, textura ou cor.
O resultado final pode ser semelhante ao que você teria obtido ao separá-los por espécie, ou pode ser muito diferente! No entanto, o exame das características das categorias resultantes pode lhe fornecer informações úteis.

Figura 15: Imagem gerada pelo DALL-E de um bebê classificando brinquedos de animais em um ambiente de aprendizado não supervisionado.
Análise de imagens com modelos ML não supervisionados
Os modelos de aprendizado de máquina não supervisionados oferecem possibilidades interessantes para a análise de imagens, permitindo a classificação de imagens em compartimentos ou categorias sem a necessidade de dados rotulados.
Imagine ter uma vasta coleção de imagens e querer organizá-las em grupos significativos. Os modelos de ML não supervisionados podem analisar os recursos visuais das imagens e agrupá-las com base em características compartilhadas, como cor ou forma. Isso proporciona percepções valiosas e simplifica as tarefas de análise de imagens.
Algoritmos de agrupamento
Os algoritmos de agrupamento agrupam imagens semelhantes com base em suas características compartilhadas. Um algoritmo de agrupamento amplamente usado é o agrupamento k-means, que divide os dados em um número predeterminado de agrupamentos, minimizando iterativamente a distância matemática entre cada imagem em um conjunto.
O agrupamento hierárquico é outra abordagem que cria uma estrutura hierárquica de conjuntos de imagens por meio da fusão ou divisão recursiva de conjuntos com base em sua similaridade. Esses algoritmos de agrupamento nos permitem descobrir agrupamentos naturais em conjuntos de dados de imagens não rotulados, fornecendo informações sobre a similaridade e a diversidade das imagens.
Segmentação de imagens
O aprendizado não supervisionado é particularmente valioso para a segmentação de imagens, que envolve a divisão de uma imagem em regiões ou objetos significativos.
Ao aplicar técnicas de agrupamento ou outros métodos de aprendizado não supervisionado, você pode separar uma imagem em regiões distintas com base na cor, na textura ou em outras características.
Essa técnica pode ser útil em imagens médicas para localizar tumores, em imagens de satélite para classificação de cobertura de terra ou em gráficos de computador para extrair elementos de primeiro e segundo plano.
Reconhecimento de padrões
O reconhecimento de padrões é outra área em que o aprendizado não supervisionado é excelente.
Os algoritmos de aprendizado não supervisionado podem aprender representações ou recursos que capturam os padrões ou estruturas subjacentes presentes nos dados. Ao extrair esses recursos aprendidos, as imagens podem ser classificadas ou agrupadas com base em seus padrões compartilhados ou semelhanças visuais. Isso possibilita tarefas como recuperação de imagens ou síntese de imagens.
Detecção de anomalias
O aprendizado não supervisionado também é usado na detecção de anomalias. Ao aprender os padrões ou as características normais de um conjunto de dados, os algoritmos não supervisionados podem identificar imagens ou regiões que são diferentes das demais. Isso é particularmente útil em áreas como a vigilância, em que a detecção de atividades incomuns ou suspeitas pode ajudar no monitoramento da segurança.
Desafios dos modelos de ML não supervisionados
O aprendizado não supervisionado enfrenta seu próprio conjunto de desafios. Um dos principais desafios é entender os resultados, pois não há dados de verdade ou rotulados para comparação.
Voltando ao exemplo da classificação de animais, você pode acabar com uma categoria que contém um cavalo, um besouro e um polvo, todos marrons, enquanto outra categoria contém um cavalo branco, um coelho e uma flor. Como você não especificou como classificar os animais, pode acabar com grupos que não são tão significativos.
Pode ser um desafio avaliar a qualidade e a precisão dos clusters ou padrões descobertos pelo modelo de ML não supervisionado.
Benefícios dos modelos de ML não supervisionados
Os modelos de ML não supervisionados oferecem vários benefícios no processamento de imagens. Mais importante ainda, eles eliminam a necessidade de rotulagem manual extensiva, tornando mais fácil e econômico trabalhar com conjuntos de dados de imagens em grande escala.
Imagine classificar e rotular manualmente cada imagem no Instagram. Os modelos de aprendizado de máquina não supervisionados eliminam a necessidade de um esforço tão longo e trabalhoso.
Os modelos de ML não supervisionados também podem revelar padrões e estruturas ocultos nos dados, permitindo que as pessoas descubram novos insights e relações visuais que podem não ser imediatamente aparentes.
Essa natureza exploratória da aprendizagem não supervisionada abre novos caminhos para a análise de imagens e pode levar a avanços em vários domínios, incluindo exploração espacial, robótica e medicina.
|
ML supervisionado |
ML não supervisionado |
|
|
Tarefas |
|
|
|
Vantagens |
|
|
|
Disadvantages |
|
|
Figura 16: Comparação do aprendizado de máquina supervisionado e não supervisionado no processamento de imagens.
Geração de novas imagens com IA generativa
Depois que um modelo determina quais características definem diferentes objetos nas imagens, ele pode usar essas informações para criar novas imagens.
DALL-E e Midjourney são exemplos notáveis de modelos de ML não supervisionados que aproveitam o poder da modelagem generativa para gerar novas imagens. Ao treinar em conjuntos de dados massivos, esses modelos aprenderam os componentes necessários para criar imagens com determinados classificadores.
Portanto, se você pedir ao DALL-E para criar uma imagem de um panda robô, o modelo recorrerá à sua definição interna do que compõe os robôs e os pandas e juntará essas peças para criar a imagem solicitada.
Por exemplo, ele pode determinar que os robôs têm metal e engrenagens, enquanto os pandas são pretos e brancos. Ele usará essas informações para criar para você um robô panda de metal, preto e branco, com engrenagens.

Figura 17: Imagem gerada pelo DALL-E usando o prompt 'Panda Robot'.
Conclusão
Este tutorial é uma exploração de alto nível da análise de imagens com o objetivo de entender melhor sua função no aprendizado de máquina. Você deve ter uma melhor intuição de como os computadores "veem" e manipulam imagens e ter uma compreensão básica dos principais conceitos de aprendizado de máquina, como pré-processamento, extração de recursos e algoritmos de classificação.
O processamento de imagens desempenha um papel enorme em nossas vidas, desde a mídia social até a geração de imagens médicas, a exploração espacial e a vigilância. Se você estiver interessado em se aprofundar nesse tópico fascinante, confira Processamento de imagens com Python, Processamento de imagens com Keras em Python e Aprendizado profundo para imagens com PyTorch no DataCamp.




