Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
99.8K
O Snowflake Arctic é um desenvolvimento inovador na área de incorporação de textos, oferecendo um conjunto avançado de ferramentas projetadas para simplificar o processo de adoção de IA com dados corporativos.
Neste tutorial, vamos apresentar uma visão geral do Snowflake Arctic, passar pelo processo de configuração, analisar técnicas de integração e falar de práticas recomendadas e dicas de solução de problemas. Também vamos apresentar casos de uso reais, discutir desenvolvimentos futuros e disponibilizar recursos para suporte e aprendizado contínuos.
Se você quiser saber mais sobre o Snowflake, confira este curso de Introdução ao Snowflake.
Então, o que é exatamente o Snowflake Arctic? É um conjunto abrangente de ferramentas projetado para simplificar a integração e a implantação de IA no Snowflake Data Cloud. Em sua essência, o Snowflake Arctic oferece uma coleção de modelos de incorporação que nos permitem extrair com eficiência insights valiosos dos dados.
Além disso, ele inclui um grande modelo de linguagem (LLM, Large Language Model) versátil e de uso geral, capaz de lidar com uma ampla gama de tarefas, desde a geração de consultas SQL e códigos de programação até o acompanhamento de instruções complexas.
Um dos recursos de destaque do Arctic é sua integração perfeita com o Snowflake Data Cloud. Essa combinação nos permite aproveitar o poder da IA diretamente em nossa infraestrutura de dados existente, garantindo uma experiência segura e simplificada.
É importante ressaltar que todos os modelos da família Snowflake Arctic estão disponíveis com uma licença Apache 2.0, o que nos permite usá-los para fins acadêmicos e comerciais.
O Snowflake Arctic tem três componentes principais:

Componentes do Snowflake Arctic.
A arquitetura do Snowflake Arctic é construída com base em um projeto híbrido de transformadores Dense Mixture of Experts (MoE), uma inovação fundamental que permite dimensionamento e adaptabilidade eficientes. Essa abordagem utiliza uma vasta rede de 480 bilhões de parâmetros distribuídos entre 128 especialistas, cada um ajustado para tarefas específicas.
No entanto, nem todos os especialistas são ativados para cada consulta. O Arctic emprega um mecanismo de seleção top-2, escolhendo apenas os dois especialistas mais relevantes para cada entrada, ativando assim apenas 17 bilhões de parâmetros. Essa otimização reduz significativamente o uso de recursos computacionais e, ao mesmo tempo, mantém o desempenho de alto nível em uma ampla gama de tarefas voltadas para a empresa.
O Snowflake Arctic se destaca pelas quatro características principais a seguir:
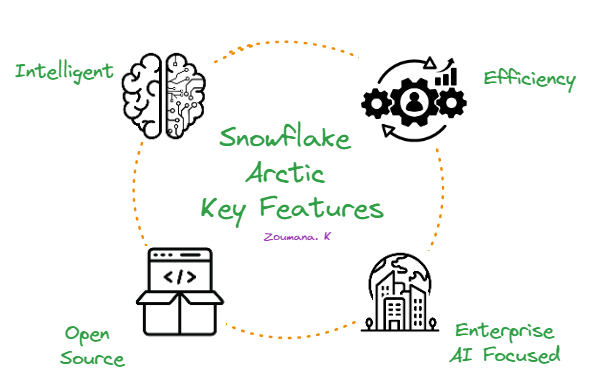
As quatro principais características do Snowflake Arctic.
Em primeiro lugar, ele é extremamente inteligente. O Arctic se destaca em tarefas complexas, como gerar consultas SQL, escrever códigos e seguir instruções detalhadas. Em testes de benchmark do setor, ele supera de forma sistemática modelos semelhantes, demonstrando sua capacidade de lidar com situações complexas do mundo real.
Em segundo lugar, o Arctic foi projetado para ser eficiente. Sua arquitetura exclusiva permite que ele ofereça desempenho de alto nível e consuma menos recursos computacionais. Isso significa uma economia expressiva de custos, tornando-o uma opção atraente para organizações de todos os tamanhos.
Em terceiro lugar, o Snowflake Arctic adota o código aberto. Ele está disponível com uma licença Apache 2.0, concedendo a todos acesso ao seu código e aos pesos do modelo.
Por fim, o Arctic está focado na IA empresarial. Foi desenvolvido para atender às necessidades específicas das empresas, apresentando resultados de alta qualidade em tarefas como análise de dados, automação de processos e suporte a decisões.
Para atender aos diversos requisitos de IA corporativa, o Snowflake introduziu dois modelos principais na família Snowflake Arctic:
Além dos modelos principais, o Snowflake oferece uma família de cinco modelos de incorporação de textos com a licença Apache 2.0, todos voltados para tarefas de recuperação de informações. A tabela abaixo ilustra o desempenho de vários modelos do Snowflake Arctic na tarefa de recuperação Massive Text Embedding Benchmark (MTEB), avaliada pelo NDCG@10.
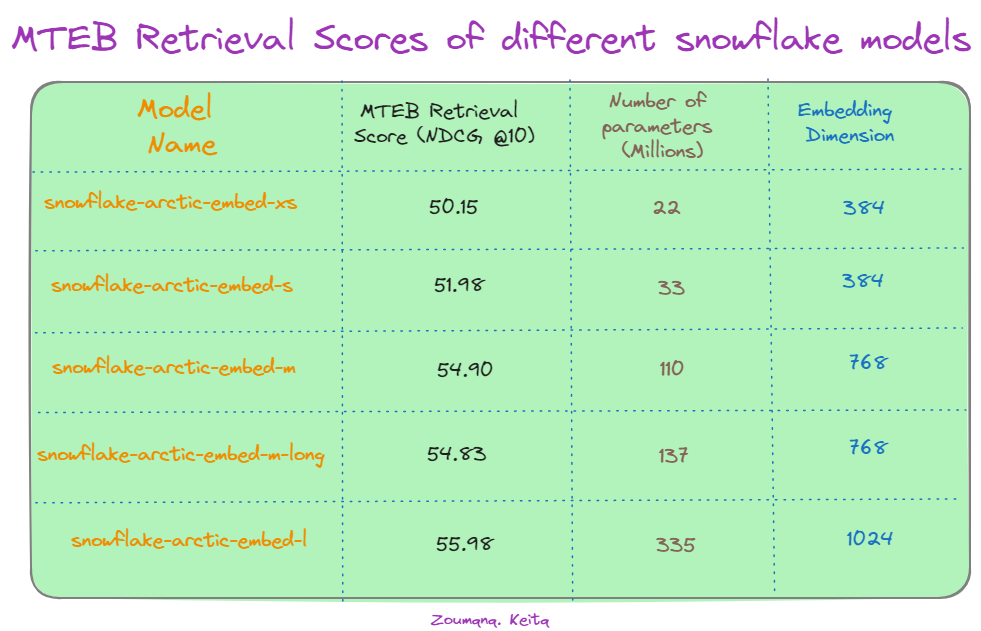
Pontuações na recuperação MTEB de diferentes modelos do Snowflake. Fonte: Hugging Face.
Primeiro, notamos que há uma tendência geral de melhoria do desempenho com o aumento do tamanho do modelo. O maior modelo, "snowflake-arctic-embed-l", atinge a maior pontuação NDCG@10, 55,98, utilizando 335 milhões de parâmetros e 1024 dimensões de incorporação. Isso sugere que a escala do modelo desempenha um papel significativo na captura de relações semânticas complexas nos dados de textos.
É interessante notar que o aumento da dimensão de incorporação de 384 para 1024 leva a melhores pontuações para o modelo "snowflake-arctic-embed-l", destacando o impacto do tamanho da incorporação na precisão da recuperação. No entanto, uma exceção notável é o modelo "snowflake-arctic-embed-xs". Apesar de ter um número de parâmetros consideravelmente menor (22 milhões), seu desempenho é comparável ao de modelos maiores com a mesma dimensão de incorporação, ou seja, 384. Isso sugere que a eficiência do modelo e as otimizações de arquitetura podem compensar os benefícios do número de parâmetros em determinadas situações.
Antes de colocar a mão na massa para fazer a implementação técnica, vamos ver o modelo em ação, executando diferentes tarefas, como geração de SQL, codificação e seguimento de instruções.
Na demonstração do Streamlit na Hugging Face, podemos apresentar ao modelo algumas solicitações, ajustar os parâmetros do modelo e obter uma resposta.
Demonstração do Snowflake Arctic.
Vamos primeiro pedir ao modelo que gere uma consulta SQL:
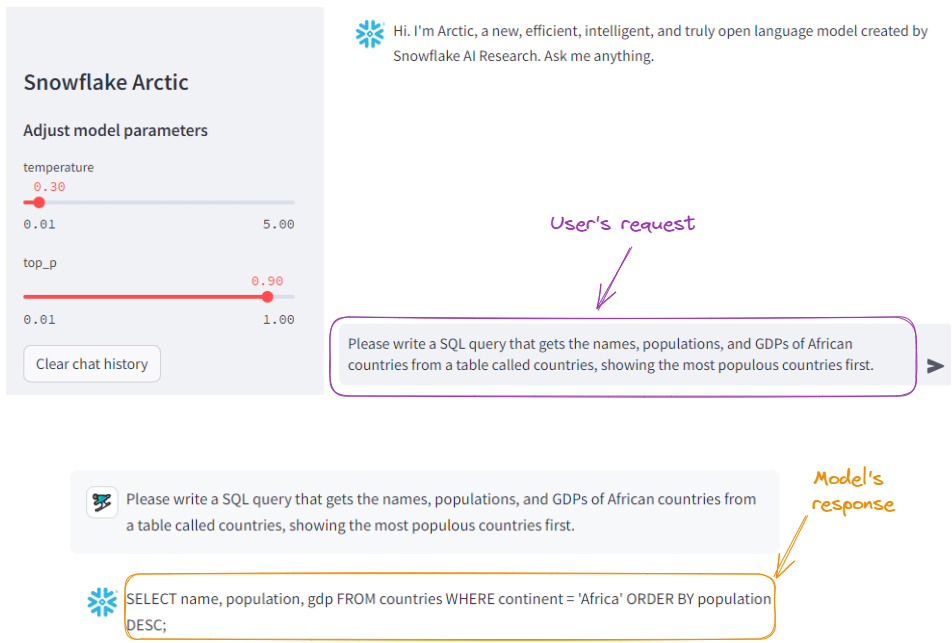
Exemplo de geração de SQL com o Snowflake Arctic.
Para fins de comparação, vamos enviar a mesma solicitação ao ChatGPT-4o: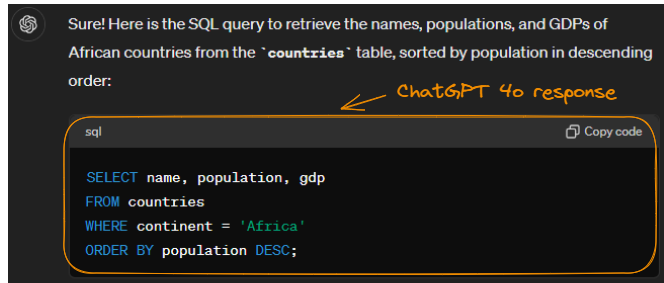
Exemplo de geração de SQL com o ChatGPT-4o.
Observe que ele gerou o mesmo resultado (com formatação mais limpa). Podemos concluir que a Arctic fez um bom trabalho.
Vamos solicitar ao Arctic que escreva um código Python:

O Snowflake Arctic gera código Python.
Ao disponibilizar o mesmo prompt ao ChatGPT-4o, obtemos o seguinte resultado, que também é preciso:
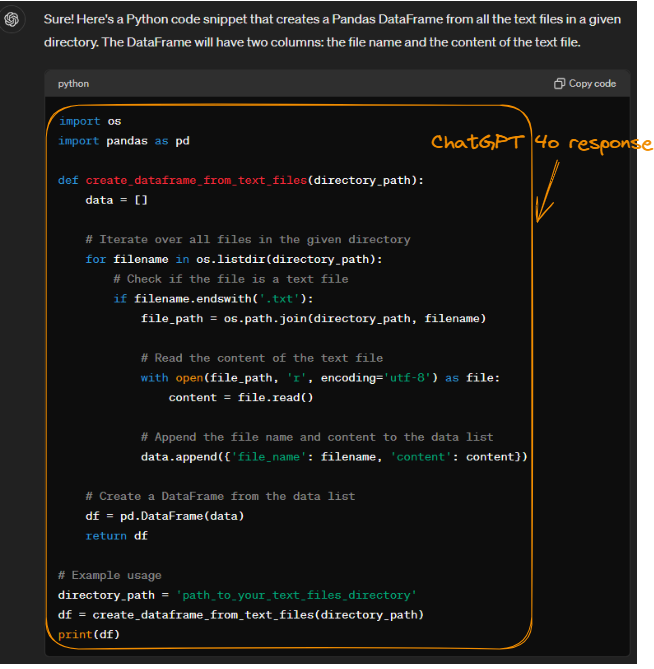
Código Python gerado pelo ChatGPT-4o.
Embora o Arctic e o ChatGPT-4o realizem a mesma tarefa, suas abordagens diferem em termos de eficiência e uso de memória. Ambos os modelos leem arquivos com eficiência usando os.listdir() e open().
No entanto, a abordagem do ChatGPT-4o de criar um DataFrame a partir de uma lista de dicionários pode consumir um pouco mais de memória do que o método do Arctic de usar uma lista de listas. Isso porque o Pandas pode realizar mais processamento para lidar com dicionários. Apesar dessa pequena diferença, a estrutura de código modular do ChatGPT-4o aumenta a legibilidade e a facilidade de manutenção.
Se você quiser saber mais sobre como escolher o LLM ideal, confira este tutorial sobre Classificação de LLMs: Como Selecionar o Melhor LLM.
Agora que conhecemos os recursos do modelo do Snowflake Arctic, vamos nos concentrar em acessar e configurar o Snowflake Arctic.
O uso de modelos do Arctic consome muitos recursos, portanto vamos utilizar o menor dos modelos da família Arctic, o snowflake-arctic-embed-xs, que consome menos recursos de computação.
Abaixo, vemos as características do ambiente que estamos usando para este tutorial – exibimos as características executando o comando nvidia-smi:
!nvidia-smi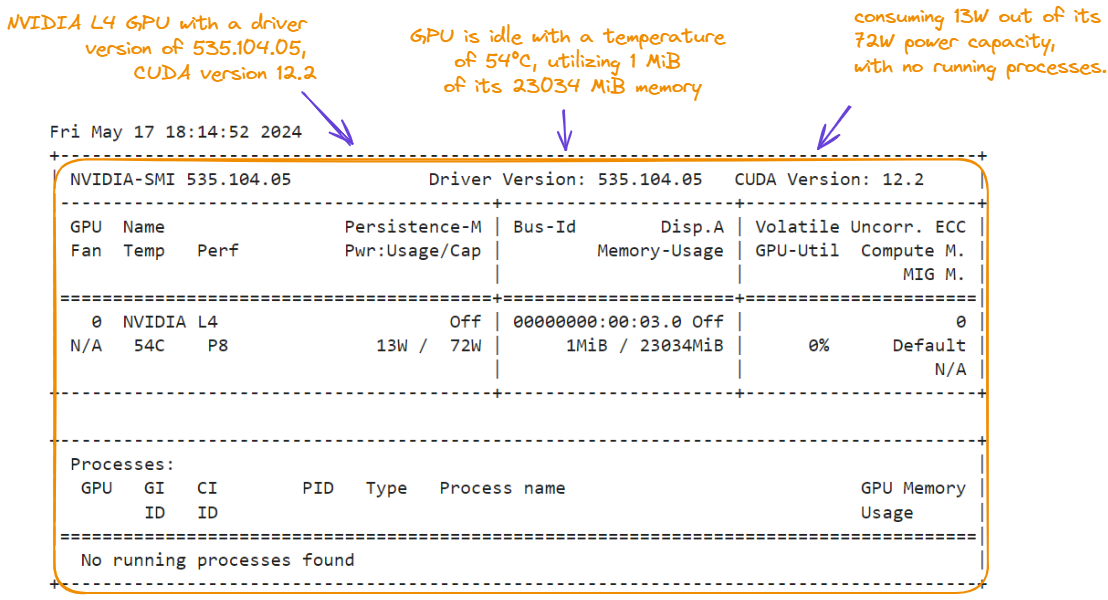
Características da GPU para o tutorial do Snowflake Arctic.
Além da GPU NVIDIA L4, o ambiente tem as seguintes características, que podem ser encontradas na seção Recursos:
Características do backend do mecanismo de computação.
Duas bibliotecas principais são necessárias para este tutorial prático: torch e transformers (executamos o código abaixo em um notebook):
%%bash
pip -qqq install transformers>=4.39.0
pip -qqq install torchEm seguida, importamos as sub-bibliotecas necessárias:
import torch
from transformers import AutoTokenizer, AutoModel
from torch.nn.functional import cosine_similarityVamos continuar carregando o modelo de incorporação snowflake-arctic-embed-xs e seu tokenizador correspondente:
model_checkpoint = "Snowflake/snowflake-arctic-embed-xs"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModel.from_pretrained(model_checkpoint, add_pooling_layer=False)Carregamos o modelo pré-treinado especificado por model_checkpoint sem uma camada de pooling adicional, que é usada para reduzir a dimensionalidade da saída do modelo.
Com todos os requisitos configurados com sucesso, o caso de uso principal desta seção é encontrar os N documentos mais semelhantes a um determinado documento, juntamente com suas pontuações de similaridade de cosseno. Para isso, seguimos estas cinco etapas principais:
Pesquisa de similaridade de documentos usando o Snowflake Arctic.
Podemos implementar as etapas acima usando as seguintes funções auxiliares: generate_embedding() e find_similar_documents().
def generate_embedding(document):
inputs = tokenizer(document, padding=True, truncation=True,
return_tensors='pt', max_length=512)
embedding = model(**inputs)[0][:, 0]
return embedding
def find_similar_documents(query_document, document_embeddings , top_n=5):
query_embedding = generate_embedding(query_document)
similarity_scores = [cosine_similarity(query_embedding,
doc_embedding).item() for doc_embedding in document_embeddings]
sorted_indices = torch.argsort(torch.tensor(similarity_scores),
descending=True)
top_documents = [documents[idx] for idx in sorted_indices[:top_n]]
top_scores = [similarity_scores[idx] for idx in sorted_indices[:top_n]]
return top_documents, top_scoresA função generate_embedding() recebe um documento e uma entrada e gera sua incorporação. Já find_similar_documents() recebe um documento de consulta, as incorporações dos documentos existentes e o número desejado de documentos semelhantes a serem retornados.
Para simplificar, usamos cinco exemplos simples:
documents = [
"This is a tutorial about Snowflake Arctic Embedding models",
"Arctic-embed is a state-of-the-art text embedding model.",
"Snowflake provides various cloud data warehousing solutions.",
"Embedding models are used for representing text as dense vectors.",
"The Arctic-embed model is based on the transformer architecture."
]Em seguida, geramos as incorporações:
document_embeddings = [generate_embedding(doc) for doc in documents]Vamos escolher "What is the Arctic-embed model?" como nosso documento de consulta e encontrar documentos semelhantes:
query_document = "What is the Arctic-embed model?"
top_documents, top_scores = find_similar_documents(query_document, document_embeddings)Por fim, percorremos os principais documentos para imprimir o conteúdo do documento e sua pontuação de similaridade com o documento de consulta.
print("Query Document:")
print(query_document)
print("\nTop Similar Documents:")
for doc, score in zip(top_documents, top_scores):
print(f"Document: {doc}")
print(f"Similarity Score: {score:.4f}")
print()
O segundo documento é o mais semelhante porque tem a maior pontuação de similaridade de cosseno (94,99%).
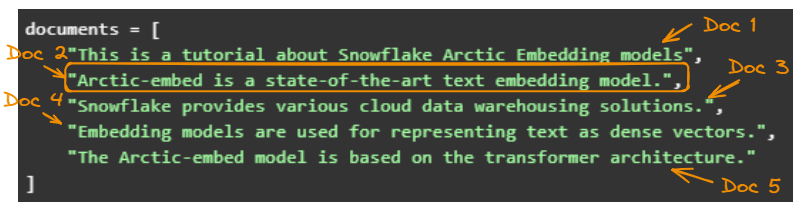
Os cinco documentos originais.
Quando visualizamos os documentos em um espaço 3D, podemos ver os documentos que estão mais próximos uns dos outros.
As incorporações originais têm 512 dimensões, o que é impossível de visualizar. A maneira mais fácil é reduzir as dimensões usando a análise de componentes principais (PCA). Se você quiser saber mais sobre a PCA, confira este tutorial sobre Análise de Componentes Principais (PCA) em Python.
Antes de usar a PCA, precisamos modificar a função find_similar_documents() para que ela retorne as incorporações do documento que a PCA usará.
def find_similar_documents(query_document, documents, top_n=5):
query_embedding = generate_embedding(query_document)
document_embeddings = [generate_embedding(doc) for doc in documents]
similarity_scores = [cosine_similarity(query_embedding, doc_embedding).item() for doc_embedding in document_embeddings]
sorted_indices = torch.argsort(torch.tensor(similarity_scores), descending=True)
top_documents = [documents[idx] for idx in sorted_indices[:top_n]]
top_scores = [similarity_scores[idx] for idx in sorted_indices[:top_n]]
return top_documents, top_scores, document_embeddingsTambém importamos alguns módulos que são necessários para gerar a visualização.
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3DAgora vamos criar a visualização 3D:
top_documents, top_scores, document_embeddings = find_similar_documents(query_document, documents)
# Reshape the embeddings
reshaped_embeddings = torch.stack(document_embeddings).detach().numpy()
reshaped_embeddings = reshaped_embeddings.reshape(reshaped_embeddings.shape[0], -1)
# Apply PCA to reduce the embeddings to 3 dimensions
pca = PCA(n_components=3)
reduced_embeddings = pca.fit_transform(reshaped_embeddings)
# Create a 3D plot
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
# Plot the document embeddings
for i, doc in enumerate(documents):
ax.scatter(reduced_embeddings[i, 0], reduced_embeddings[i, 1], reduced_embeddings[i, 2], marker='o', label=f"Document {i+1}")
# Plot the query document embedding
query_embedding = generate_embedding(query_document)
reshaped_query_embedding = query_embedding.detach().numpy().reshape(1, -1)
reduced_query_embedding = pca.transform(reshaped_query_embedding)
ax.scatter(reduced_query_embedding[0, 0], reduced_query_embedding[0, 1],
reduced_query_embedding[0, 2], marker='*', s=100, color='red',
label="Query Document")
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.set_zlabel('PC3')
ax.legend()
plt.title('Document Embeddings in 3D Space')
plt.show()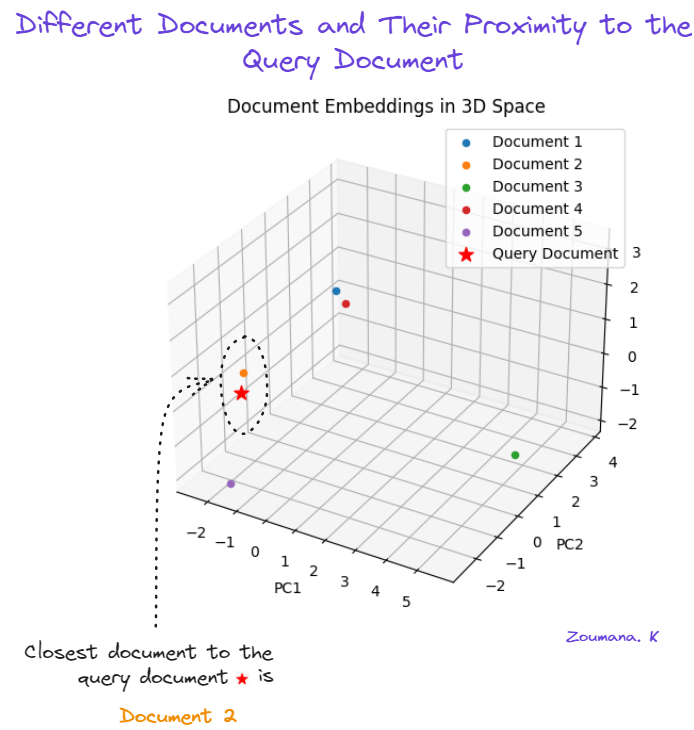
Uso da PCA para visualizar a similaridade de documentos.
O segundo documento (laranja) é o mais próximo do documento de consulta (estrela vermelha). O quinto documento (roxo) é o segundo documento mais próximo, enquanto o terceiro documento (verde) é o mais distante.
Os notebooks são ferramentas poderosas para experimentação e visualização rápida, o que os torna populares entre cientistas de dados e pesquisadores. No entanto, os notebooks podem não ser a opção mais adequada quando se trata de implantar modelos ou aplicativos em ambientes de produção. É nesse ponto que o Streamlit entra em ação.
O Streamlit é uma biblioteca Python que facilita o desenvolvimento de aplicativos interativos web para projetos de ciência de dados e aprendizado de máquina. Facilita a transformação de projetos de ciência de dados em aplicativos prontos para produção, sem a necessidade de grandes conhecimentos de desenvolvimento web.
Abaixo está a página inicial do que criaremos nesta seção.
Página de destino do aplicativo Streamlit.
O ensino do Streamlit está fora do escopo deste tutorial, mas você pode aprendê-lo do zero neste Tutorial de Python: Streamlit.
Nesta seção, vamos analisar como usar o Streamlit para criar um aplicativo web para o nosso projeto de pesquisa de similaridade de documentos. Para executar um aplicativo Streamlit, o código precisa estar em um arquivo Python (com extensão .py) e executar o seguinte comando no terminal:
streamlit run app.pyNo entanto, a primeira etapa para usar o Streamlit é instalá-lo com o comando pip:
pip install streamlitO código que usamos para criar o aplicativo Streamlit é um pouco grande, por isso dedique um tempo para analisá-lo. Também vamos explicá-lo após o bloco de código.
import streamlit as st
from transformers import AutoTokenizer, AutoModel
import torch
from torch.nn.functional import cosine_similarity
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
model_checkpoint = "Snowflake/snowflake-arctic-embed-xs"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModel.from_pretrained(model_checkpoint, add_pooling_layer=False)
def generate_embedding(document):
inputs = tokenizer(document, padding=True, truncation=True, return_tensors='pt', max_length=512)
embedding = model(**inputs)[0][:, 0]
return embedding
def find_similar_documents(query_document, documents, top_n=5):
query_embedding = generate_embedding(query_document)
document_embeddings = [generate_embedding(doc) for doc in documents]
similarity_scores = [cosine_similarity(query_embedding, doc_embedding).item() for doc_embedding in document_embeddings]
sorted_indices = torch.argsort(torch.tensor(similarity_scores), descending=True)
top_documents = [documents[idx] for idx in sorted_indices[:top_n]]
top_scores = [similarity_scores[idx] for idx in sorted_indices[:top_n]]
return top_documents, top_scores, document_embeddings
# Sample documents
documents = [
"This is a tutorial about Snowflake Arctic Embedding models",
"Arctic-embed is a state-of-the-art text embedding model.",
"Snowflake provides various cloud data warehousing solutions.",
"Embedding models are used for representing text as dense vectors.",
"The Arctic-embed model is based on the transformer architecture."
]
# Streamlit app
st.title("Document Similarity Search With Snowflake Arctic")
query_document = st.text_input("Enter your query document:")
top_k = st.number_input("Enter the number of top documents to retrieve (K):", min_value=1, value=3, step=1)
if st.button("Search"):
top_documents, top_scores, document_embeddings = find_similar_documents(query_document, documents, top_n=top_k)
st.subheader("Top {} Similar Documents:".format(top_k))
for i, (doc, score) in enumerate(zip(top_documents, top_scores)):
st.write("{}. Document: {}".format(i+1, doc))
st.write(" Similarity Score: {:.4f}".format(score))
# Reshape the embeddings
reshaped_embeddings = torch.stack(document_embeddings).detach().numpy()
reshaped_embeddings = reshaped_embeddings.reshape(reshaped_embeddings.shape[0], -1)
# Apply PCA to reduce the embeddings to 3 dimensions
pca = PCA(n_components=3)
reduced_embeddings = pca.fit_transform(reshaped_embeddings)
# Create a 3D plot
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
# Plot the document embeddings
for i, doc in enumerate(documents):
ax.scatter(reduced_embeddings[i, 0], reduced_embeddings[i, 1], reduced_embeddings[i, 2], marker='o', label=f"Document {i+1}")
# Plot the query document embedding
query_embedding = generate_embedding(query_document)
reshaped_query_embedding = query_embedding.detach().numpy().reshape(1, -1)
reduced_query_embedding = pca.transform(reshaped_query_embedding)
ax.scatter(reduced_query_embedding[0, 0], reduced_query_embedding[0, 1], reduced_query_embedding[0, 2], marker='*', s=100, color='red', label="Query Document")
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.set_zlabel('PC3')
ax.legend()
plt.title('Document Embeddings in 3D Space')
st.pyplot(fig)Usando o código acima, criamos um aplicativo Streamlit chamado "Document Similarity Search With Snowflake Arctic". Vamos fazer algumas observações sobre o código:
st.text_input() e especifique o número de documentos principais a serem recuperados (K) usando st.number_input().st.button("Search")), a função find_similar_documents() é chamada com o documento de consulta, a lista de documentos e o valor de top_k especificado.st.subheader() e st.write().st.pyplot(fig).A seção do Streamlit do código concentra-se na criação de uma interface de usuário interativa em que os usuários podem inserir um documento de consulta, especificar o número dos principais documentos semelhantes a serem recuperados e exibir os resultados juntamente com uma visualização em 3D das incorporações dos documentos.
O código completo do artigo está disponível neste Notebook Jupyter.
Podemos iniciar o aplicativo com o comando streamlit run app.py, que nos leva à página de destino. Ao disponibilizar o mesmo documento de consulta e definir Top K igual a 3, obtemos o seguinte resultado:

Integração do Snowflake Arctic usando o Streamlit.
Ao trabalhar com grandes modelos de linguagem como o Arctic, é fundamental testar e validar detalhadamente as configurações no ambiente de destino. Isso garante o desempenho e a confiabilidade ideais. Aqui vão algumas dicas de configuração que você deve ter em mente:
Para garantir o desempenho ideal e a operação sem percalços do Snowflake Arctic, é fundamental seguir as práticas recomendadas e estar preparado para solucionar possíveis problemas. Nesta seção, vamos analisar dicas e truques para melhorar o desempenho com base em pesquisas acadêmicas e benchmarks reais.
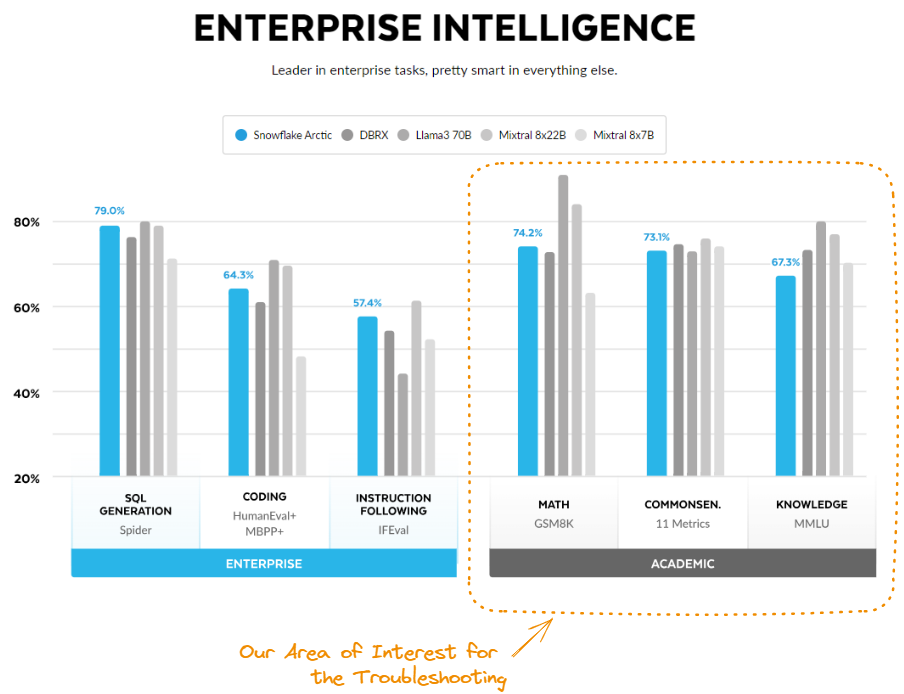
Fonte: Arctic Cloud.
Aqui vão algumas dicas e truques para aprimorar seus recursos:
O desempenho do Snowflake Arctic se destaca nas situações de inferência e treinamento. Durante a inferência, ele oferece de maneira sistemática uma relação desempenho/custo superior em comparação com outros modelos. Essa eficiência melhora à medida que mais parâmetros são ativados, mantendo uma vantagem significativa mesmo com cerca de 60 bilhões de parâmetros ativos, superando concorrentes como o Mixral e o Llama 3.
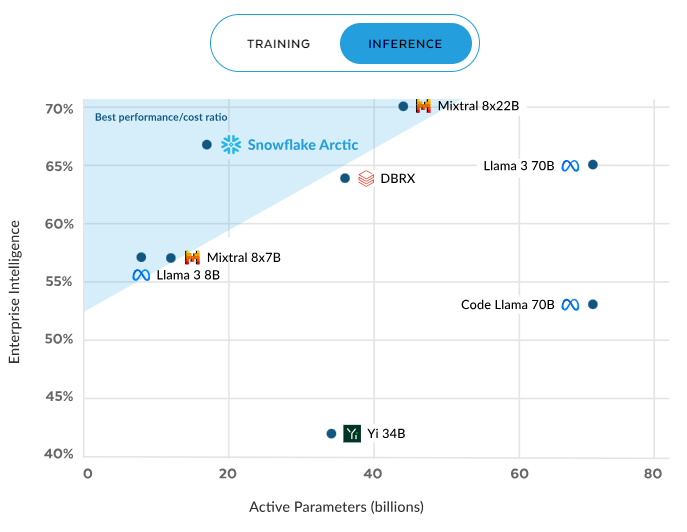
Eficiência do Arctic na inferência. Fonte: Snowflake.com.
A tendência continua no treinamento, em que a Arctic novamente apresenta a melhor relação desempenho/custo. Essa eficiência melhora com o aumento da computação, chegando a aproximadamente 70% com computação de 16X, muito acima de modelos como DBRX, Llama 3, Code Llama e Yi. Esses resultados ressaltam a proposta de valor do Arctic: desempenho de alta qualidade por uma fração do custo computacional, o que o torna uma opção atraente para empresas preocupadas com recursos.
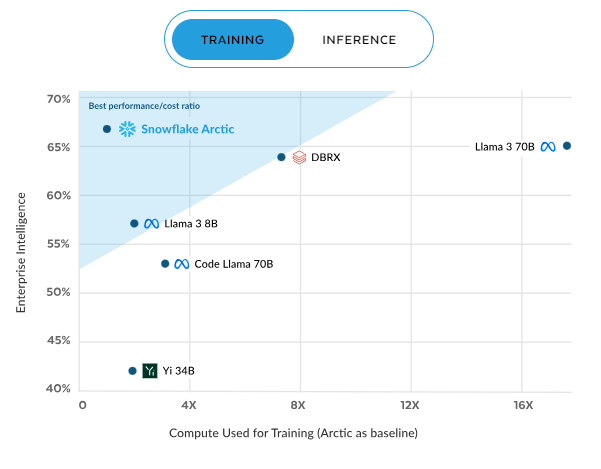
Eficiência do Arctic no treinamento. Fonte: Snowflake.com.
Estas são algumas dicas e truques para otimizar o desempenho da inferência e do treinamento:
O desempenho impressionante e a economia do Snowflake Arctic estabeleceram um novo padrão para os modelos de linguagem. O desenvolvimento futuro pode incluir compreensão avançada de linguagem natural, aprendizado multitarefa aprimorado e melhor suporte para aplicativos específicos de domínios. À medida que o Snowflake inova, os usuários podem esperar ferramentas ainda mais poderosas e versáteis.
O Snowflake oferece uma excelente comunidade e recursos de suporte abrangentes. Os usuários podem se conectar, dividir conhecimentos e aprender uns com os outros nos fóruns da comunidade Snowflake. Há uma documentação detalhada e tutoriais disponíveis no site oficial para ajudar os usuários a conhecer e aproveitar ao máximo os recursos do Snowflake Arctic.
O Snowflake Arctic é um divisor de águas na área de incorporações de textos, oferecendo uma solução avançada e eficiente para empresas que buscam liberar todo o potencial de seus dados. Sua integração perfeita com o Snowflake Data Cloud e a arquitetura escalável o tornam a escolha ideal para organizações que buscam otimizar processos de recuperação e análise de dados.
Ao longo deste guia, vimos os principais recursos do Snowflake Arctic, abordando de tudo, desde sua instalação e configuração até técnicas avançadas de integração e aplicações práticas. Ao utilizar seus recursos avançados e otimizações de desempenho, as empresas podem obter mais eficiência e precisão em suas operações de incorporação de textos.
Se quiser saber mais sobre o Snowflake, confira este Tutorial de Snowflake para Iniciantes.
Saiba mais sobre Python
Curso
Curso
blog
Abid Ali Awan
8 min
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan

