Curso
Visualização de Dados no Google Sheets
4 h
45.8K
Vamos começar com os gráficos de dados mais comuns, que são amplamente usados em muitos campos e podem ser criados na maioria das bibliotecas de visualização de dados do Python (exceto em algumas muito especializadas).
Um gráfico de barras é a visualização de dados mais comum para exibir os valores numéricos de dados categóricos para comparar várias categorias entre si. As categorias são representadas por barras retangulares da mesma largura e com alturas (para gráficos de barras verticais) ou comprimentos (para gráficos de barras horizontais) proporcionais aos valores numéricos a que correspondem.
Para criar um gráfico de barras básico no matplotlib, usamos a função matplotlib.pyplot.bar(), como segue:
# Data preparation
penguins_grouped = penguins[['species', 'bill_length_mm']].groupby('species').mean().reset_index()
# Creating a bar chart
plt.bar(penguins_grouped['species'], penguins_grouped['bill_length_mm'])
plt.title('Average penguin bill length by species')
plt.show()
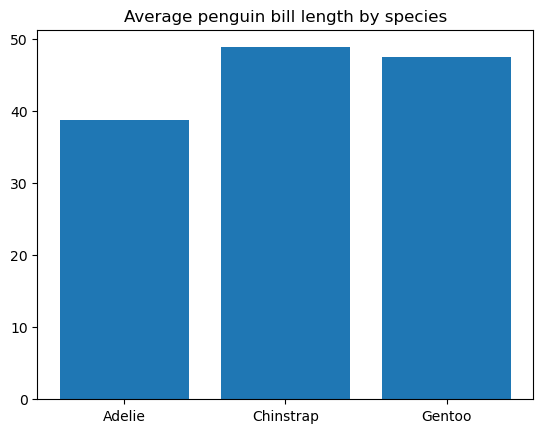
Você pode personalizar ainda mais a largura e a cor da barra, a largura e a cor da borda da barra, adicionar rótulos de tick às barras, preencher as barras com padrões etc.
Para se atualizar rapidamente sobre como trabalhar com o matplotlib, dê uma olhada na nossa Folha de dicas do Matplotlib: Plotagem em Python.
Um gráfico de linhas é um tipo de gráfico de dados que mostra a progressão de uma variável da esquerda para a direita ao longo do eixo x por meio de pontos de dados conectados por segmentos de linha reta. Em geral, a alteração de uma variável é traçada ao longo do tempo. De fato, os gráficos de linha são usados com frequência para visualizar séries temporais, conforme discutido no tutorial sobre gráficos de linha de séries temporais do Matplotlib.
Você pode criar um gráfico de linha básico no matplotlib usando a função matplotlib.pyplot.plot(), como segue:
# Data preparation
flights_grouped = flights[['year', 'passengers']].astype({'year': 'string'}).groupby('year').sum().reset_index()
# Creating a line plot
plt.plot(flights_grouped['year'], flights_grouped['passengers'])
plt.title('Total number of passengers by year')
plt.show()
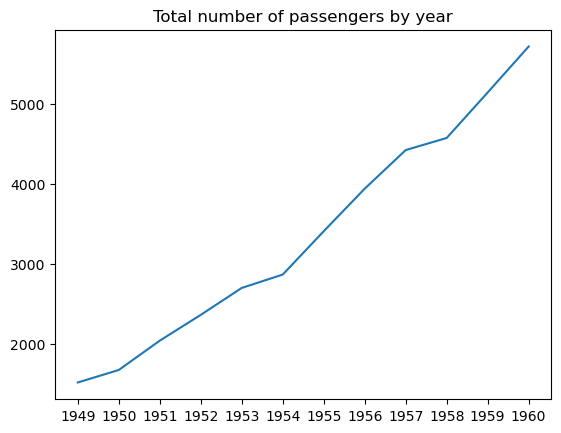
É possível ajustar a largura, o estilo, a cor e a transparência da linha, adicionar e personalizar marcadores, etc.
O tutorial sobre gráficos de linhas no MatplotLib com Python fornece mais explicações e exemplos sobre como criar e personalizar um gráfico de linhas no matplotlib. Para saber como criar e personalizar um gráfico de linhas no seaborn, leia Python Seaborn Line Plot Tutorial: Criar visualizações de dados.
Um gráfico de dispersão é um tipo de visualização de dados que exibe as relações entre duas variáveis plotadas como pontos de dados no plano de coordenadas. Esse tipo de gráfico de dados é usado para verificar se as duas variáveis estão correlacionadas entre si, qual é a intensidade dessa correlação e se há grupos distintos nos dados.
O código abaixo ilustra como você pode criar um gráfico de dispersão básico no matplotlib usando a função matplotlib.pyplot.scatter():
# Creating a scatter plot
plt.scatter(penguins['bill_length_mm'], penguins['bill_depth_mm'])
plt.title('Penguin bill length vs. bill depth')
plt.show()
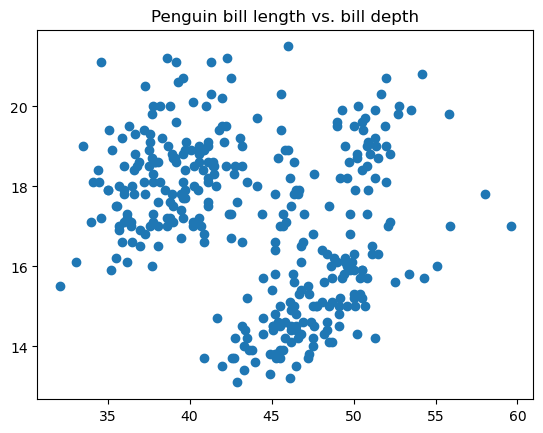
Você pode ajustar o tamanho do ponto, o estilo, a cor, a transparência, a largura da borda, a cor da borda, etc.
Você pode ler mais sobre gráficos de dispersão (e não só!) neste tutorial: Dados desmistificados: Visualizações de dados que capturam relacionamentos.
Um histograma é um tipo de gráfico de dados que representa a distribuição de frequência dos valores de uma variável numérica. Por trás disso, ele divide os dados em grupos de intervalos de valores chamados de compartimentos, conta o número de pontos relacionados a cada compartimento e exibe cada compartimento como uma barra vertical, com a altura proporcional ao valor de contagem desse compartimento. Um histograma pode ser considerado um tipo específico de gráfico de barras, só que suas barras adjacentes são anexadas sem intervalos, dada a natureza contínua dos compartimentos.
Você pode criar facilmente um histograma básico no matplotlib usando a função matplotlib.pyplot.hist():
# Creating a histogram
plt.hist(penguins['bill_length_mm'])
plt.title('Penguin bill length distribution')
plt.show()
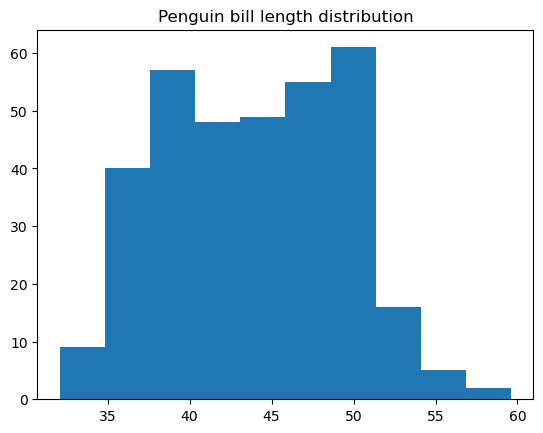
É possível personalizar muitas coisas dentro dessa função, inclusive a cor e o estilo do histograma, o número de compartimentos, as bordas dos compartimentos, o intervalo inferior e superior dos compartimentos, se o histograma é regular ou cumulativo etc.
No tutorial sobre Como criar um histograma com o Plotly, você pode explorar outra maneira de criar um histograma em Python.
Um gráfico de caixa é um tipo de gráfico de dados que mostra um conjunto de cinco estatísticas descritivas dos dados: os valores mínimo e máximo (excluindo os outliers), a mediana e o primeiro e terceiro quartis. Opcionalmente, você também pode mostrar o valor médio. Um gráfico de caixa é a escolha certa se você estiver interessado apenas nessas estatísticas, sem se aprofundar na distribuição real dos dados subjacentes.
No tutorial 11 técnicas de visualização de dados para cada caso de uso com exemplos, você encontrará, entre outras coisas, explicações mais detalhadas sobre o tipo de informação estatística que pode ser obtida em um gráfico de caixa.
Podemos criar um gráfico de caixa básico no matplotlib usando a função matplotlib.pyplot.boxpot(), conforme abaixo:
# Data preparation
penguins_cleaned = penguins.dropna()
# Creating a box plot
plt.boxplot(penguins_cleaned['bill_length_mm'])
plt.title('Penguin bill length distribution')
plt.show()
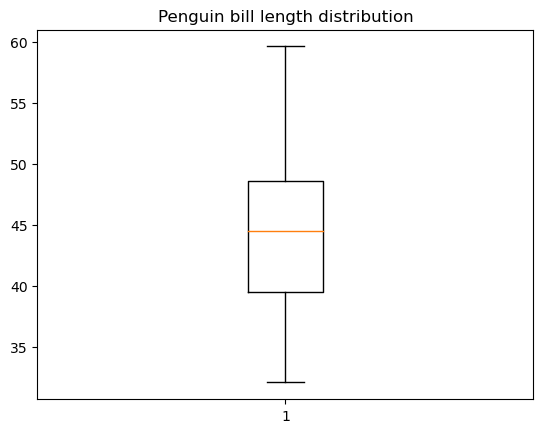
Há muito espaço para a personalização de um gráfico de caixa: a largura e a orientação da caixa, a posição da caixa e do whisker, a visibilidade e o estilo de vários elementos do gráfico de caixa etc.
Observe que, para criar um gráfico de caixa usando essa função, precisamos primeiro garantir que os dados não contenham valores ausentes. De fato, no exemplo acima, eliminamos os valores ausentes dos dados antes da plotagem. Para fins de comparação, a biblioteca Seaborn não tem essa limitação e lida com os valores ausentes nos bastidores, conforme abaixo:
# Creating a box plot
sns.boxplot(data=penguins, y='bill_length_mm')
plt.title('Penguin bill length distribution')
plt.show()
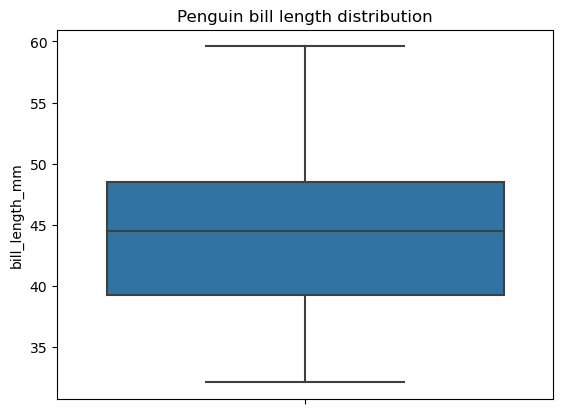
Um gráfico de pizza é um tipo de visualização de dados representado por um círculo dividido em setores, em que cada setor corresponde a uma determinada categoria dos dados categóricos, e o ângulo de cada setor reflete a proporção dessa categoria como parte do todo. Diferentemente dos gráficos de barras, os gráficos de pizza devem representar as categorias que constituem o todo, por exemplo, os passageiros de um navio.
Os gráficos de pizza têm algumas desvantagens:
Portanto, os gráficos de pizza devem ser usados com moderação e cautela.
Para criar um gráfico de pizza básico no matplotlib, precisamos aplicar a função matplotlib.pyplot.pie(), como segue:
# Data preparation
titanic_grouped = titanic.groupby('class')['pclass'].count().reset_index()
# Creating a pie chart
plt.pie(titanic_grouped['pclass'], labels=titanic_grouped['class'])
plt.title('Number of passengers by class')
plt.show()
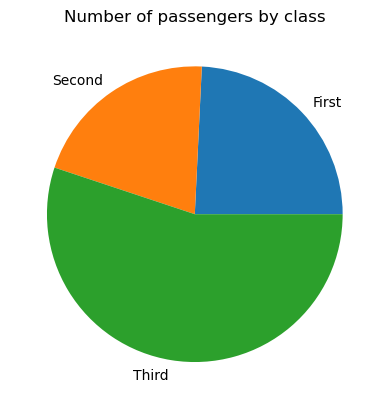
Se necessário, podemos ajustar nosso gráfico de pizza: alterar as cores de suas fatias, adicionar um deslocamento a algumas fatias (geralmente as muito pequenas), alterar o raio do círculo, personalizar o formato dos rótulos, preencher algumas ou todas as fatias com padrões etc.
Nesta seção, exploraremos vários gráficos de dados avançados. Algumas delas representam uma variação sofisticada de tipos comuns de visualizações de dados que consideramos na seção anterior, outras são apenas tipos independentes.
Enquanto um gráfico de barras comum é usado para exibir os valores numéricos de uma variável categórica por categoria, um gráfico de barras agrupadas tem a mesma finalidade, mas em duas variáveis categóricas. Graficamente, isso significa que temos vários grupos de barras, com cada grupo relacionado a uma determinada categoria de uma variável e cada barra desses grupos relacionada a uma determinada categoria da segunda variável. Os gráficos de barras agrupados funcionam melhor quando a segunda variável não tem mais de três categorias. No caso oposto, eles se tornam muito lotados e, portanto, menos úteis.
Assim como um gráfico de barras comum, podemos criar um gráfico de barras agrupadas com o matplotlib. No entanto, a biblioteca Seaborn oferece uma funcionalidade mais conveniente de sua função seaborn.barplot() para criar esses gráficos. Vejamos um exemplo de criação de um gráfico de barras agrupado básico para o comprimento do bico do pinguim em duas variáveis categóricas: espécie e sexo.
# Creating a grouped bar chart
sns.barplot(data=penguins, x='species', y='bill_length_mm', hue='sex')
plt.title('Penguin bill length by species and sex')
plt.show()
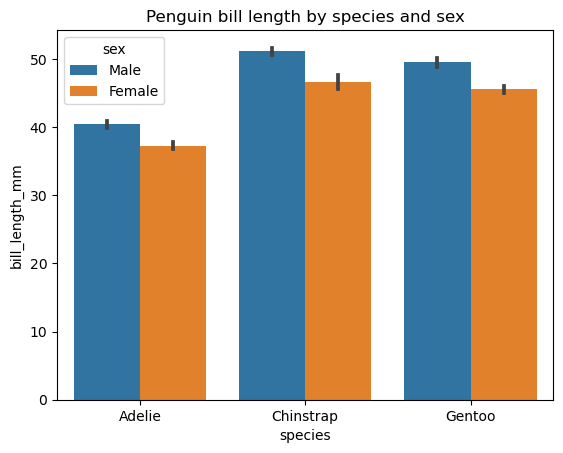
A segunda variável categórica é introduzida por meio do parâmetro de matiz. Outros parâmetros opcionais dessa função permitem alterar a orientação, a largura e a cor da barra, a ordem das categorias, o estimador estatístico etc.
Para se aprofundar no planejamento com o Seaborn, considere o seguinte curso: Visualização intermediária de dados com o Seaborn.
Um gráfico de área empilhada é uma extensão de um gráfico de área comum (que é simplesmente um gráfico de linhas com a área abaixo da linha colorida ou preenchida com um padrão) com várias áreas, cada uma correspondendo a uma variável específica, empilhadas umas sobre as outras. Esses gráficos são úteis quando precisamos monitorar o progresso geral de um conjunto de variáveis e a contribuição individual de cada variável para esse progresso. Assim como os gráficos de linha, os gráficos de área empilhada geralmente refletem a mudança de variáveis ao longo do tempo.
É importante ter em mente a principal limitação dos gráficos de áreas empilhadas: eles ajudam principalmente a capturar a tendência geral, mas não os valores exatos das áreas empilhadas.
Para criar um gráfico de área empilhada básico no matplotlib, usamos a função matplotlib.pyplot.stackplot, conforme abaixo:
# Data preparation
flights_grouped = flights.groupby(['year', 'month']).mean().reset_index()
flights_49_50 = pd.DataFrame(list(zip(flights_grouped.loc[:11, 'month'].tolist(), flights_grouped.loc[:11, 'passengers'].tolist(), flights_grouped.loc[12:23, 'passengers'].tolist())), columns=['month', '1949', '1950'])
# Creating a stacked area chart
plt.stackplot(flights_49_50['month'], flights_49_50['1949'], flights_49_50['1950'], labels=['1949', '1950'])
plt.title('Number of passengers in 1949 and 1950 by month')
plt.legend()
plt.show()
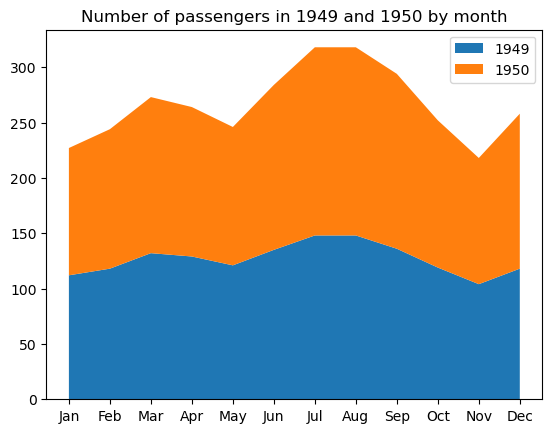
Algumas propriedades personalizáveis desse tipo de gráfico são as cores da área, a transparência, os padrões de preenchimento, a largura da linha, o estilo, a cor, a transparência etc.
Na seção sobre Tipos comuns de gráficos de dados, definimos um box pot como um tipo de visualização de dados que mostra um conjunto de cinco estatísticas descritivas dos dados. Às vezes, talvez você queira exibir e comparar essas estatísticas separadamente para cada categoria de uma variável categórica. Nesses casos, precisamos plotar várias caixas na mesma área de plotagem, o que pode ser feito facilmente com a função seaborn.boxplot(), como segue:
# Creating multiple box plots
sns.boxplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
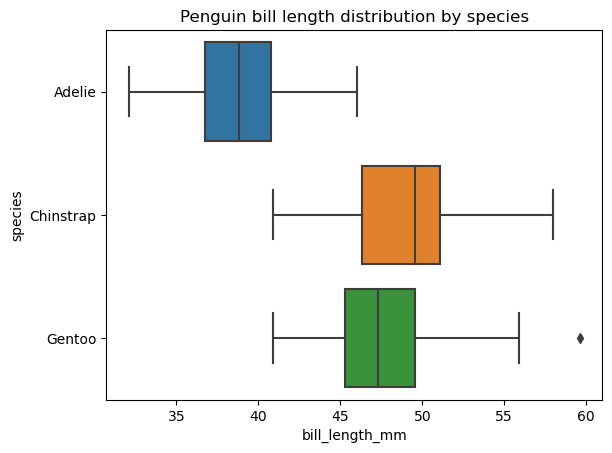
É possível alterar a ordem dos gráficos de caixa, sua orientação, cor, transparência, largura, as propriedades de seus vários elementos, adicionar outra variável categórica na área do gráfico, etc.
Um gráfico de violino é semelhante a um gráfico de caixa e exibe as mesmas estatísticas gerais dos dados, exceto pelo fato de que ele também exibe a forma de distribuição desses dados. Assim como nos gráficos de caixa, podemos criar um único gráfico de violino para os dados de interesse ou, mais frequentemente, vários gráficos de violino, cada um para uma categoria separada de uma variável categórica.
O Seaborn oferece mais espaço para criar e personalizar gráficos de violinos do que o matplotlib. Para criar um gráfico básico de violino no seaborn, precisamos aplicar a função seaborn.violinplot(), conforme abaixo:
Creating a violin plot
sns.violinplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
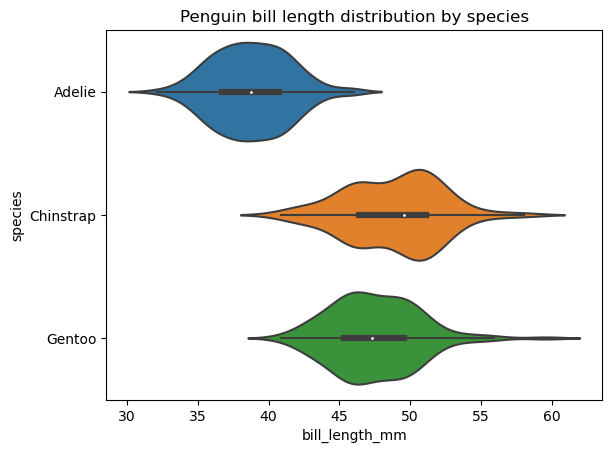
Podemos modificar a ordem dos violinos, sua orientação, cor, transparência, largura, as propriedades de seus vários elementos, estender a distribuição além dos pontos de dados extremos, adicionar outra variável categórica na área do gráfico, selecionar a forma como os pontos de dados são representados no interior do violino etc.
Um mapa de calor é um tipo de visualização de dados em forma de tabela em que cada ponto de dados numéricos é representado com base em uma escala de cores selecionada e de acordo com a magnitude do ponto de dados no conjunto de dados. A principal ideia por trás desses gráficos é ilustrar possíveis pontos quentes e frios dos dados que podem exigir atenção especial.
Em muitos casos, os dados precisam de algum pré-processamento antes de você criar um mapa de calor para eles. Isso geralmente implica a limpeza e a normalização dos dados.
O código abaixo mostra como você pode criar um mapa de calor básico (após o pré-processamento de dados necessário) usando a função seaborn.heatmap():
# Data preparation
from sklearn import preprocessing
car_crashes_cleaned = car_crashes.drop(labels='abbrev', axis=1).iloc[0:10]
min_max_scaler = preprocessing.MinMaxScaler()
car_crashes_normalized = pd.DataFrame(min_max_scaler.fit_transform(car_crashes_cleaned.values), columns=car_crashes_cleaned.columns)
# Creating a heatmap
sns.heatmap(car_crashes_normalized, annot=True)
plt.title('Car crash heatmap for the first 10 car crashes')
plt.show()
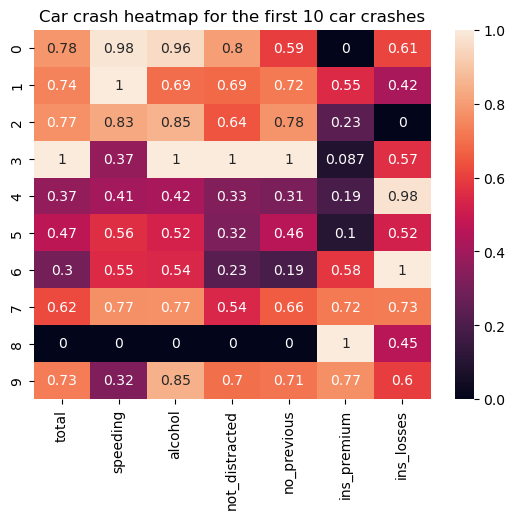
Alguns ajustes possíveis podem incluir a seleção de um mapa de cores, a definição dos valores de ancoragem, a formatação de anotações, a personalização das linhas de separação, a aplicação de uma máscara etc.
Por fim, vamos dar uma olhada em alguns tipos de visualizações de dados raramente usados ou até mesmo menos conhecidos. Muitos deles têm pelo menos um análogo entre os tipos mais populares de gráficos. Entretanto, em alguns casos específicos, essas visualizações de dados não convencionais podem fazer um trabalho mais eficiente do que os gráficos comumente usados.
Um gráfico de haste é praticamente outra forma de representar um gráfico de barras, só que, em vez de barras sólidas, ele consiste em linhas finas com marcadores (opcionais) em cima de cada uma delas. Embora um gráfico de haste possa parecer uma variação redundante de um gráfico de barras, ele é, na verdade, a melhor alternativa quando se trata de visualizar muitas categorias. A vantagem dos gráficos de haste em relação aos gráficos de barras é que eles têm uma melhor relação entre dados e tinta e, portanto, melhor legibilidade.
Para criar um gráfico de haste básico no matplotlib, usamos a função matplotlib.pyplot.stem(), como segue:
# Data preparation
fmri_grouped = fmri.groupby('subject')[['subject', 'signal']].max()
# Creating a stem plot
plt.stem(fmri_grouped['subject'], fmri_grouped['signal'])
plt.title('FMRI maximum signal by subject')
plt.show()
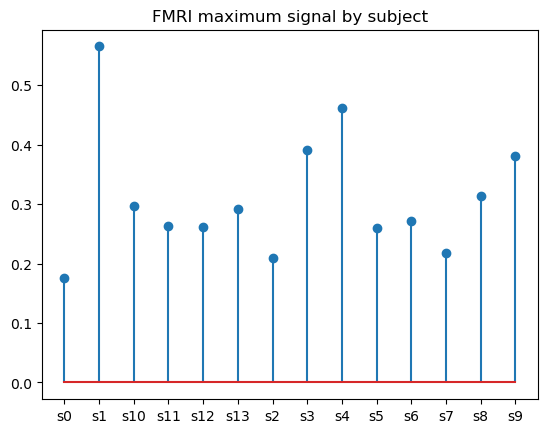
Podemos brincar com os parâmetros opcionais da função para alterar a orientação da haste e personalizar as propriedades da haste, da linha de base e do marcador.
Esses dois tipos muito semelhantes de visualização de dados podem ser considerados como uma implementação de um gráfico de dispersão para uma variável categórica: os gráficos de faixa e de enxame exibem o interior da distribuição de dados, incluindo o tamanho da amostra e a posição dos pontos de dados individuais, mas excluindo as estatísticas descritivas. A principal diferença entre esses gráficos é que, em um gráfico de faixa, os pontos de dados podem se sobrepor, enquanto em um gráfico de enxame, não. Em vez disso, em um gráfico de enxame, os pontos de dados são alinhados ao longo do eixo categórico.
Lembre-se de que os gráficos de faixa e de enxame podem ser úteis apenas para conjuntos de dados relativamente pequenos.
Veja como podemos criar um gráfico de faixas com a função seaborn.stripplot():
# Creating a strip plot
sns.stripplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
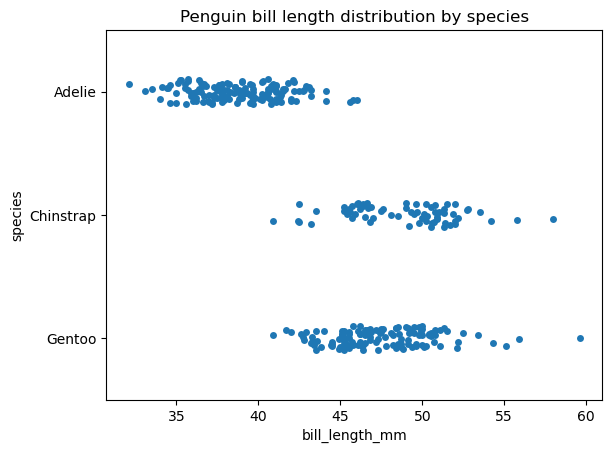
Agora, vamos criar um gráfico de enxame com a função seaborn.swarmplot() para os mesmos dados e observar a diferença:
# Creating a swarm plot
sns.swarmplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
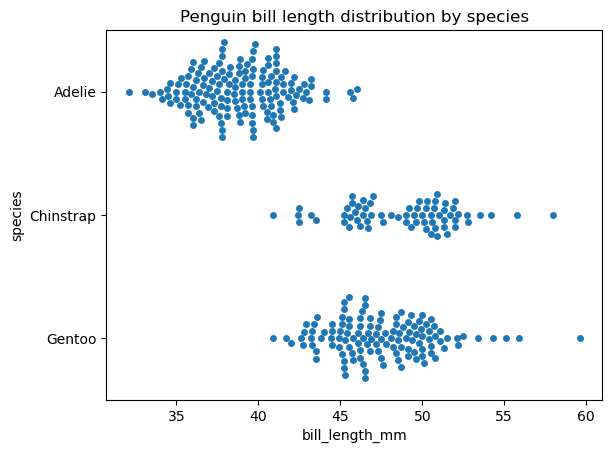
As funções seaborn.stripplot() e seaborn.swarmplot() têm sintaxe muito semelhante. Algumas propriedades personalizáveis em ambas as funções são a ordem e a orientação do gráfico e as propriedades do marcador, como o estilo, o tamanho, a cor, a transparência etc. do marcador. Vale a pena mencionar que a regulação da transparência do marcador ajuda a corrigir parcialmente o problema de sobreposição de pontos em um gráfico de faixas.
Um mapa de árvore é um tipo de gráfico de dados usado para visualizar os valores numéricos dos dados categóricos por categoria como um conjunto de retângulos colocados dentro de uma moldura retangular, com a área de cada retângulo proporcional ao valor da categoria correspondente. Por sua finalidade, os mapas de árvore são idênticos aos gráficos de barras e de pizza. Assim como os gráficos de pizza, eles devem representar principalmente as categorias que constituem o todo. Os mapas de árvore podem parecer eficazes e atraentes quando há até dez categorias com uma diferença perceptível em seus valores numéricos.
As desvantagens dos mapas de árvore são muito semelhantes às dos gráficos de pizza:
Devemos ter em mente esses pontos e usar os mapas de árvore com moderação e somente quando eles funcionarem melhor.
Para criar um mapa de árvore em Python, primeiro precisamos instalar e importar a biblioteca squarify: pip install squarify e, em seguida, import squarify. O código abaixo cria um mapa de árvore básico:
import squarify
# Data preparation
diamonds_grouped = diamonds[['cut', 'price']].groupby('cut').mean().reset_index()
# Creating a treemap
squarify.plot(sizes=diamonds_grouped['price'], label=diamonds_grouped['cut'])
plt.title('Average diamond price by cut')
plt.show()
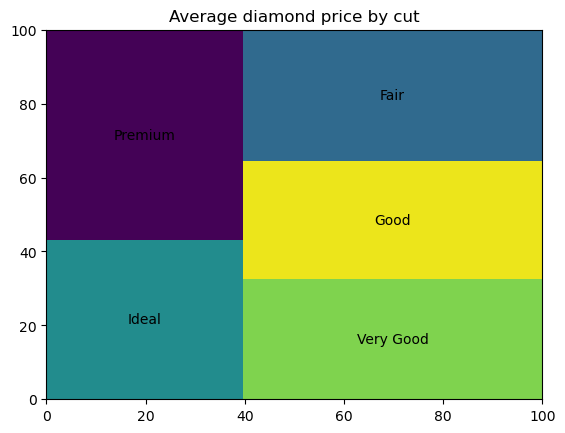
Podemos personalizar as cores e a transparência dos retângulos, preenchê-los com padrões, ajustar as propriedades da borda do retângulo, adicionar um pequeno espaço entre os retângulos e ajustar as propriedades do texto do rótulo.
Há outra abordagem para criar um mapa de árvore em Python: usar a biblioteca plotly. Você pode ler mais sobre isso no tutorial . O que é visualização de dados? Um guia para cientistas de dados.
Uma nuvem de palavras é um tipo de visualização de dados de texto em que o tamanho da fonte de cada palavra corresponde à frequência de sua aparição em um texto de entrada. O uso de nuvens de palavras ajuda você a encontrar as palavras mais importantes em um texto.
Embora as nuvens de palavras sejam sempre atraentes e intuitivamente compreensíveis para qualquer tipo de público-alvo, devemos estar cientes de algumas limitações intrínsecas desse tipo de gráfico de dados:
Uma aplicação interessante e menos conhecida das nuvens de palavras é que podemos criá-las com base não na frequência da palavra, mas em qualquer outro atributo atribuído a cada palavra. Por exemplo, podemos criar um dicionário de países, atribuir a cada país o valor de sua população e exibir esses dados.
Para criar uma nuvem de palavras em Python, precisamos usar uma biblioteca especializada em nuvem de palavras. Primeiro, precisamos instalá-lo (pip install wordcloud) e, em seguida, importar a classe WordCloud e as stopwords: from wordcloud import WordCloud, STOPWORDS. O código a seguir gera uma nuvem de palavras básica:
from wordcloud import WordCloud, STOPWORDS
text = 'cat cat cat cat cat cat dog dog dog dog dog panda panda panda panda koala koala koala rabbit rabbit fox'
# Creating a word cloud
wordcloud = WordCloud().generate(text)
plt.imshow(wordcloud)
plt.title('Words by their frequency in the text')
plt.axis('off')
plt.show()

É possível ajustar as dimensões de uma nuvem de palavras, alterar a cor do plano de fundo, atribuir um mapa de cores para a exibição de palavras, definir a preferência por palavras horizontais em vez de verticais, limitar o número máximo de palavras exibidas, atualizar a lista de stopwords, limitar o tamanho das fontes, levar em conta as colocações de palavras, garantir a reprodutibilidade do gráfico etc.
Se você quiser saber mais sobre nuvens de palavras em Python, aqui está uma ótima leitura: Tutorial de geração de WordClouds em Python. Além disso, você pode usar um modelo gratuito para praticar a criação desse tipo de visualização de dados: Modelo: Crie uma nuvem de palavras.
Neste artigo, discutimos vários tipos de gráficos de dados, suas áreas de uso, suas limitações e como criá-los e personalizá-los em Python. Começamos com as visualizações de dados mais comuns, prosseguimos com as mais avançadas e concluímos com alguns tipos de gráficos de dados não convencionais, mas às vezes muito úteis.
Como um breve resumo de quando usar cada um dos gráficos de dados que abordamos, você pode encontrar nossa útil Folha de dicas de visualização de dados.
Além do Python, há muitas outras ferramentas para que você possa criar visualizações de dados interessantes. Abaixo está uma seleção de cursos para iniciantes, abrangentes e exaustivos que podem ser úteis para você:
Comece sua jornada de visualização de dados hoje mesmo!
Curso
Curso
Curso
Tutorial
Arunn Thevapalan
Tutorial
Kevin Babitz
Tutorial
Elena Kosourova
Tutorial
Aditya Sharma
Tutorial
Elena Kosourova
Tutorial
Moez Ali

