
Cours
Visualisation de données avec Google Sheets
4 h
45.8K
Nos programmes de certification vous aident à vous démarquer et à prouver aux employeurs potentiels que vos compétences sont adaptées à l'emploi.

Commençons par les graphiques de données les plus courants, qui sont largement utilisés dans de nombreux domaines et peuvent être construits dans la majorité des bibliothèques de visualisation de données Python (à l'exception de certaines très spécialisées).
Un diagramme à barres est la visualisation de données la plus courante pour afficher les valeurs numériques de données catégorielles afin de comparer les différentes catégories entre elles. Les catégories sont représentées par des barres rectangulaires de même largeur et de hauteur (pour les histogrammes verticaux) ou de longueur (pour les histogrammes horizontaux) proportionnelle aux valeurs numériques auxquelles elles correspondent.
Pour créer un diagramme à barres de base dans matplotlib, nous utilisons la fonction matplotlib.pyplot.bar(), comme suit :
# Data preparation
penguins_grouped = penguins[['species', 'bill_length_mm']].groupby('species').mean().reset_index()
# Creating a bar chart
plt.bar(penguins_grouped['species'], penguins_grouped['bill_length_mm'])
plt.title('Average penguin bill length by species')
plt.show()
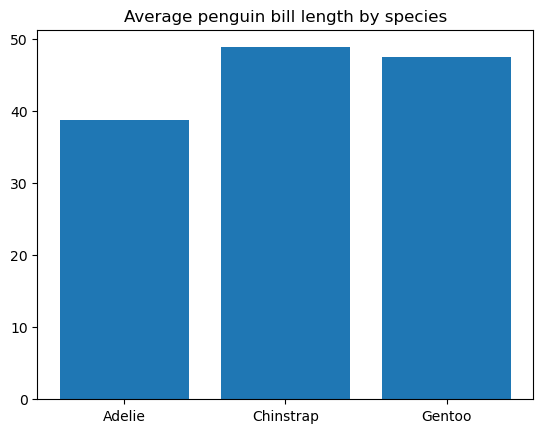
Nous pouvons également personnaliser la largeur et la couleur des barres, la largeur et la couleur des bords des barres, ajouter des étiquettes aux barres, remplir les barres avec des motifs, etc.
Pour vous rafraîchir la mémoire sur la façon de travailler avec matplotlib, jetez un coup d'œil à notre Matplotlib Cheat Sheet : Tracé en Python.
Un graphique linéaire est un type de graphique de données qui montre la progression d'une variable de gauche à droite le long de l'axe des x par le biais de points de données reliés par des segments de lignes droites. Le plus souvent, l'évolution d'une variable est tracée dans le temps. En effet, les tracés linéaires sont souvent utilisés pour visualiser les séries temporelles, comme le montre le tutoriel sur les tracés linéaires des séries temporelles de Matplotlib.
Nous pouvons créer un graphique linéaire de base dans matplotlib en utilisant la fonction matplotlib.pyplot.plot(), comme suit :
# Data preparation
flights_grouped = flights[['year', 'passengers']].astype({'year': 'string'}).groupby('year').sum().reset_index()
# Creating a line plot
plt.plot(flights_grouped['year'], flights_grouped['passengers'])
plt.title('Total number of passengers by year')
plt.show()
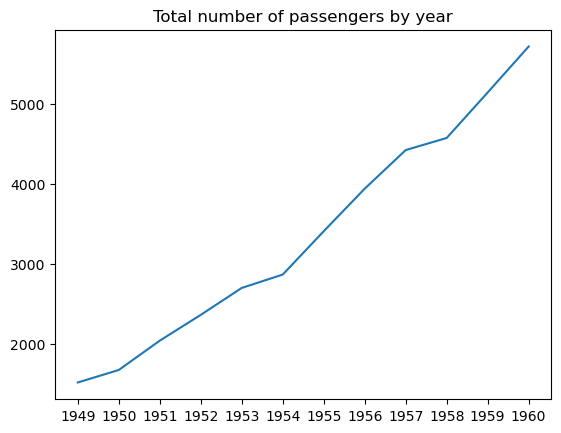
Il est possible d'ajuster la largeur, le style, la couleur et la transparence des lignes, d'ajouter et de personnaliser des marqueurs, etc.
Le tutoriel sur les tracés linéaires dans MatplotLib avec Python fournit plus d'explications et d'exemples sur la façon de créer et de personnaliser un tracé linéaire dans matplotlib. Pour apprendre à créer et à personnaliser un tracé linéaire dans seaborn, lisez Python Seaborn Line Plot Tutorial : Créer des visualisations de données.
Un diagramme de dispersion est un type de visualisation de données qui affiche les relations entre deux variables représentées par des points de données sur le plan de coordonnées. Ce type de graphique est utilisé pour vérifier si les deux variables sont corrélées entre elles, quelle est l'intensité de cette corrélation et s'il existe des groupes distincts dans les données.
Le code ci-dessous illustre comment créer un diagramme de dispersion de base dans matplotlib à l'aide de la fonction matplotlib.pyplot.scatter():
# Creating a scatter plot
plt.scatter(penguins['bill_length_mm'], penguins['bill_depth_mm'])
plt.title('Penguin bill length vs. bill depth')
plt.show()
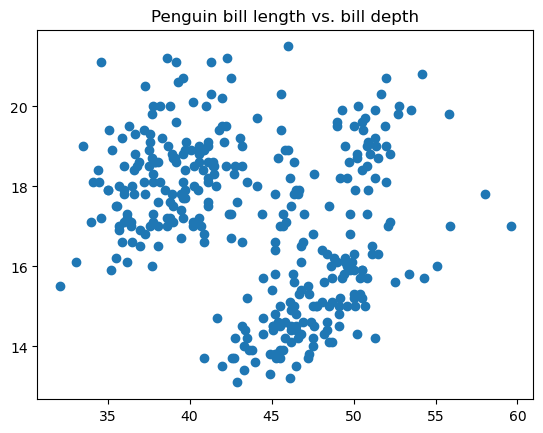
Nous pouvons ajuster la taille des points, le style, la couleur, la transparence, la largeur des bords, la couleur des bords, etc.
Vous pouvez en savoir plus sur les diagrammes de dispersion (et pas seulement !) dans ce tutoriel : Les données démystifiées : Visualisations de données permettant de saisir les relations.
Un histogramme est un type de graphique de données qui représente la distribution de fréquence des valeurs d'une variable numérique. Sous le capot, il divise les données en groupes de valeurs appelés "bacs", compte le nombre de points liés à chaque bac et affiche chaque bac sous la forme d'une barre verticale, dont la hauteur est proportionnelle à la valeur de comptage de ce bac. Un histogramme peut être considéré comme un type particulier de diagramme à barres, à ceci près que les barres adjacentes sont attachées sans espace, étant donné la nature continue des cellules.
Nous pouvons facilement construire un histogramme de base dans matplotlib en utilisant la fonction matplotlib.pyplot.hist():
# Creating a histogram
plt.hist(penguins['bill_length_mm'])
plt.title('Penguin bill length distribution')
plt.show()
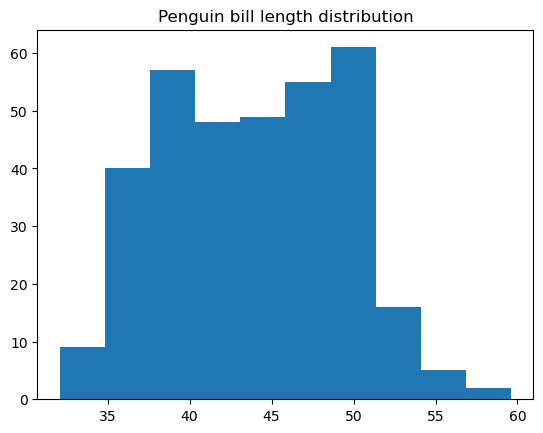
Il est possible de personnaliser de nombreux éléments dans cette fonction, notamment la couleur et le style de l'histogramme, le nombre de cellules, les bords des cellules, les limites inférieure et supérieure des cellules, le caractère régulier ou cumulatif de l'histogramme, etc.
Dans le tutoriel sur la création d'un histogramme avec Plotly, vous pouvez explorer une autre façon de créer un histogramme en Python.
Un diagramme en boîte est un type de diagramme de données qui présente un ensemble de cinq statistiques descriptives des données : les valeurs minimales et maximales (à l'exclusion des valeurs aberrantes), la médiane et les premier et troisième quartiles. En option, il peut également afficher la valeur moyenne. Le diagramme en boîte est le bon choix si vous ne vous intéressez qu'à ces statistiques, sans chercher à connaître la véritable distribution des données sous-jacentes.
Dans le tutoriel sur les 11 techniques de visualisation de données pour chaque cas d'utilisation avec des exemples, vous trouverez, entre autres, des explications plus détaillées sur le type d'informations statistiques que vous pouvez obtenir à partir d'un diagramme en boîte.
Nous pouvons créer un diagramme en boîte de base dans matplotlib à l'aide de la fonction matplotlib.pyplot.boxpot(), comme indiqué ci-dessous :
# Data preparation
penguins_cleaned = penguins.dropna()
# Creating a box plot
plt.boxplot(penguins_cleaned['bill_length_mm'])
plt.title('Penguin bill length distribution')
plt.show()
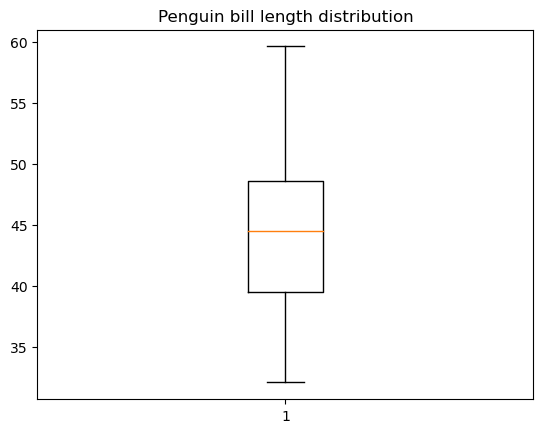
Il existe de nombreuses possibilités de personnalisation d'un diagramme en boîte : la largeur et l'orientation de la boîte, la position de la boîte et des moustaches, la visibilité et le style des différents éléments du diagramme en boîte, etc.
Notez que pour créer un diagramme en boîte à l'aide de cette fonction, nous devons d'abord nous assurer que les données ne contiennent pas de valeurs manquantes. En effet, dans l'exemple ci-dessus, nous avons supprimé les valeurs manquantes des données avant de les tracer. À titre de comparaison, la bibliothèque Seaborn n'a pas cette limitation et traite les valeurs manquantes en coulisses, comme indiqué ci-dessous :
# Creating a box plot
sns.boxplot(data=penguins, y='bill_length_mm')
plt.title('Penguin bill length distribution')
plt.show()
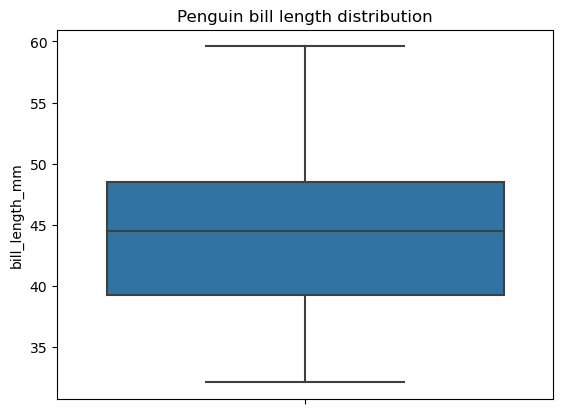
Un diagramme circulaire est un type de visualisation de données représenté par un cercle divisé en secteurs, où chaque secteur correspond à une certaine catégorie de données catégorielles, et l'angle de chaque secteur reflète la proportion de cette catégorie par rapport à l'ensemble. Contrairement aux diagrammes à barres, les diagrammes circulaires sont censés représenter les catégories qui constituent l'ensemble, par exemple les passagers d'un navire.
Les diagrammes circulaires présentent quelques inconvénients :
C'est pourquoi les diagrammes circulaires doivent être utilisés avec parcimonie et prudence.
Pour créer un diagramme circulaire de base dans matplotlib, nous devons appliquer la fonction matplotlib.pyplot.pie(), comme suit :
# Data preparation
titanic_grouped = titanic.groupby('class')['pclass'].count().reset_index()
# Creating a pie chart
plt.pie(titanic_grouped['pclass'], labels=titanic_grouped['class'])
plt.title('Number of passengers by class')
plt.show()
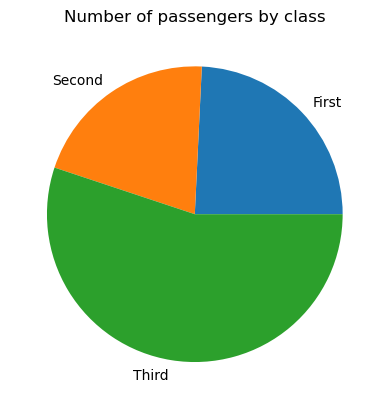
Si nécessaire, nous pouvons ajuster notre camembert : changer les couleurs de ses segments, ajouter un décalage à certains segments (généralement très petits), changer le rayon du cercle, personnaliser le format des étiquettes, remplir certains ou tous les segments avec des motifs, etc.
Dans cette section, nous allons explorer différents tracés de données avancés. Certains d'entre eux représentent une variation fantaisiste des types courants de visualisation de données que nous avons examinés dans la section précédente, tandis que d'autres sont des types autonomes.
Alors qu'un diagramme à barres commun est utilisé pour afficher les valeurs numériques d'une variable catégorielle par catégorie, un diagramme à barres groupées sert le même objectif, mais pour deux variables catégorielles. Graphiquement, cela signifie que nous avons plusieurs groupes de barres, chaque groupe étant lié à une certaine catégorie d'une variable et chaque barre de ces groupes étant liée à une certaine catégorie de la deuxième variable. Les diagrammes en barres groupées sont plus efficaces lorsque la deuxième variable ne comporte pas plus de trois catégories. Dans le cas contraire, ils deviennent trop encombrés et donc moins utiles.
Comme pour un diagramme à barres classique, nous pouvons créer un diagramme à barres groupées avec matplotlib. Cependant, la bibliothèque Seaborn offre une fonctionnalité plus pratique de sa fonction seaborn.barplot() pour créer de tels tracés. Examinons un exemple de création d'un diagramme à barres groupées de base pour la longueur du bec des manchots en fonction de deux variables catégorielles : l'espèce et le sexe.
# Creating a grouped bar chart
sns.barplot(data=penguins, x='species', y='bill_length_mm', hue='sex')
plt.title('Penguin bill length by species and sex')
plt.show()
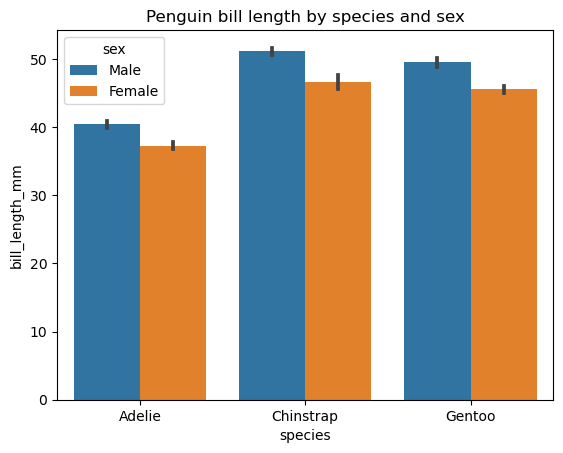
La deuxième variable catégorielle est introduite par le paramètre de la teinte. D'autres paramètres facultatifs de cette fonction permettent de modifier l'orientation, la largeur et la couleur des barres, l'ordre des catégories, l'estimateur statistique, etc.
Pour approfondir l'utilisation de Seaborn dans le domaine de l'intrigue, vous pouvez suivre le cours suivant : Visualisation intermédiaire des données avec Seaborn.
Un diagramme à aires empilées est une extension d'un diagramme à aires commun (qui est simplement un tracé linéaire dont la zone située sous la ligne est colorée ou remplie d'un motif) avec plusieurs zones, chacune correspondant à une variable particulière, empilées les unes sur les autres. De tels cursus sont utiles lorsqu'il s'agit de suivre à la fois l'évolution globale d'un ensemble de variables et la contribution individuelle de chaque variable à cette évolution. Comme les diagrammes linéaires, les diagrammes à aires empilées reflètent généralement l'évolution des variables dans le temps.
Il est important de garder à l'esprit la principale limite des graphiques à aires empilées : ils permettent principalement de saisir la tendance générale, mais pas les valeurs exactes des aires empilées.
Pour construire un graphique de base à aires empilées dans matplotlib, nous utilisons la fonction matplotlib.pyplot.stackplot, comme ci-dessous :
# Data preparation
flights_grouped = flights.groupby(['year', 'month']).mean().reset_index()
flights_49_50 = pd.DataFrame(list(zip(flights_grouped.loc[:11, 'month'].tolist(), flights_grouped.loc[:11, 'passengers'].tolist(), flights_grouped.loc[12:23, 'passengers'].tolist())), columns=['month', '1949', '1950'])
# Creating a stacked area chart
plt.stackplot(flights_49_50['month'], flights_49_50['1949'], flights_49_50['1950'], labels=['1949', '1950'])
plt.title('Number of passengers in 1949 and 1950 by month')
plt.legend()
plt.show()
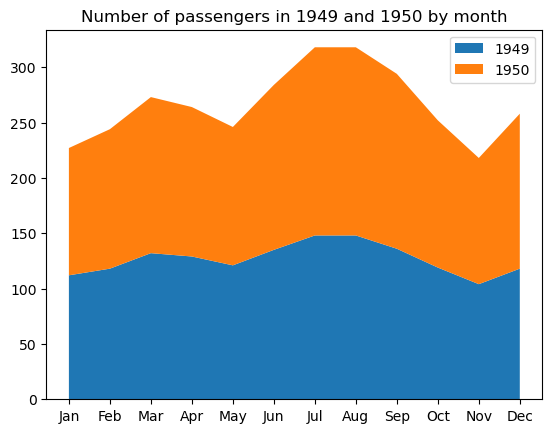
Les propriétés personnalisables de ce type de graphique sont les couleurs de la zone, la transparence, les motifs de remplissage, la largeur des lignes, le style, la couleur, la transparence, etc.
Dans la section sur les types courants de diagrammes de données, nous avons défini le diagramme en boîte comme un type de visualisation de données qui présente un ensemble de cinq statistiques descriptives des données. Il arrive que l'on veuille afficher et comparer ces statistiques séparément pour chaque catégorie d'une variable catégorielle. Dans ce cas, nous devons tracer plusieurs boîtes sur la même zone de tracé, ce que nous pouvons facilement faire à l'aide de la fonction seaborn.boxplot(), comme suit :
# Creating multiple box plots
sns.boxplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
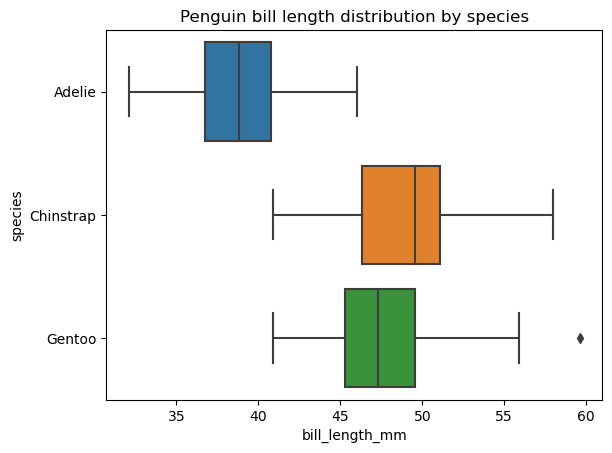
Il est possible de modifier l'ordre des box plots, leur orientation, leur couleur, leur transparence, leur largeur, les propriétés de leurs différents éléments, d'ajouter une autre variable catégorielle sur la zone du plot, etc.
Un diagramme de violon est similaire à un diagramme en boîte et affiche les mêmes statistiques globales des données, sauf qu'il affiche également la forme de la distribution de ces données. Comme pour les diagrammes en boîte, nous pouvons créer un seul diagramme en violon pour les données en question ou, plus souvent, plusieurs diagrammes en violon, chacun pour une catégorie distincte d'une variable catégorielle.
Seaborn offre plus de possibilités de créer et de personnaliser des graphiques de violon que matplotlib. Pour construire un diagramme de violon de base dans seaborn, nous devons appliquer la fonction seaborn.violinplot(), comme indiqué ci-dessous :
Creating a violin plot
sns.violinplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
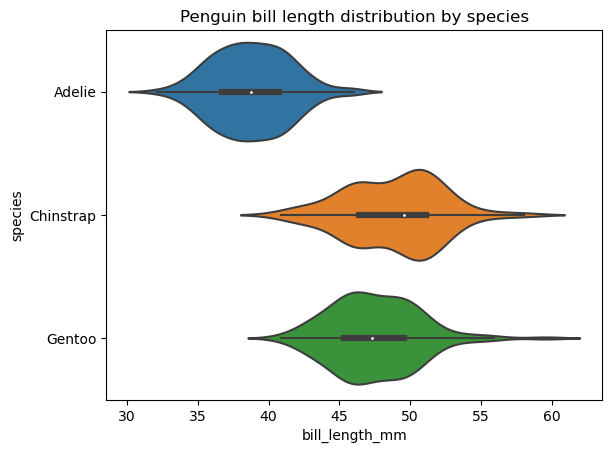
Nous pouvons modifier l'ordre des violons, leur orientation, leur couleur, leur transparence, leur largeur, les propriétés de leurs différents éléments, étendre la distribution au-delà des points de données extrêmes, ajouter une autre variable catégorielle sur la zone de tracé, choisir la manière dont les points de données sont représentés à l'intérieur du violon, etc.
Une carte thermique est un type de visualisation de données sous forme de tableau où chaque point de données numériques est représenté selon une échelle de couleurs sélectionnée et en fonction de l'importance du point de données dans l'ensemble de données. L'idée principale de ces graphiques est d'illustrer les points chauds et froids potentiels des données qui peuvent nécessiter une attention particulière.
Dans de nombreux cas, les données doivent être prétraitées avant de créer une carte thermique. Cela implique généralement le nettoyage et la normalisation des données.
Le code ci-dessous montre comment créer une carte thermique de base (après le prétraitement nécessaire des données) à l'aide de la fonction seaborn.heatmap():
# Data preparation
from sklearn import preprocessing
car_crashes_cleaned = car_crashes.drop(labels='abbrev', axis=1).iloc[0:10]
min_max_scaler = preprocessing.MinMaxScaler()
car_crashes_normalized = pd.DataFrame(min_max_scaler.fit_transform(car_crashes_cleaned.values), columns=car_crashes_cleaned.columns)
# Creating a heatmap
sns.heatmap(car_crashes_normalized, annot=True)
plt.title('Car crash heatmap for the first 10 car crashes')
plt.show()
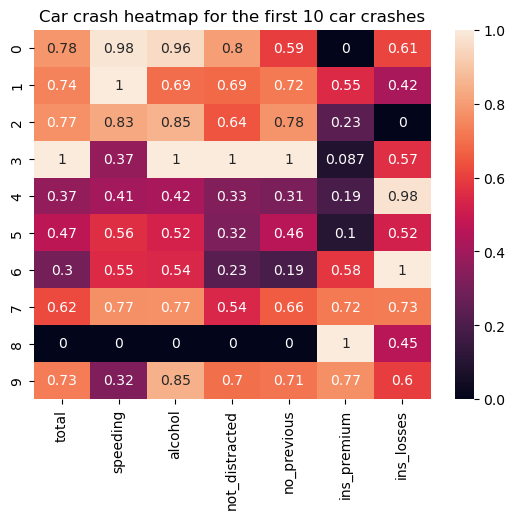
Parmi les ajustements possibles, citons la sélection d'une carte de couleurs, la définition des valeurs d'ancrage, le formatage des annotations, la personnalisation des lignes de séparation, l'application d'un masque, etc.
Enfin, examinons quelques types de visualisation de données rarement utilisés, voire moins connus. Nombre d'entre eux ont au moins un analogue parmi les types de graphiques les plus courants. Cependant, dans certains cas particuliers, ces visualisations de données non conventionnelles peuvent être plus efficaces que les graphiques couramment utilisés.
Un diagramme à tiges est pratiquement une autre façon de représenter un diagramme à barres, sauf qu'au lieu de barres pleines, il se compose de lignes fines surmontées de marqueurs (facultatifs). Si le diagramme à tiges peut sembler être une variante redondante du diagramme à barres, il est en fait sa meilleure alternative lorsqu'il s'agit de visualiser de nombreuses catégories. L'avantage des diagrammes à tiges par rapport aux diagrammes à barres est qu'ils présentent un meilleur rapport données-encre et, par conséquent, une meilleure lisibilité.
Pour créer un diagramme à tiges de base dans matplotlib, nous utilisons la fonction matplotlib.pyplot.stem(), comme suit :
# Data preparation
fmri_grouped = fmri.groupby('subject')[['subject', 'signal']].max()
# Creating a stem plot
plt.stem(fmri_grouped['subject'], fmri_grouped['signal'])
plt.title('FMRI maximum signal by subject')
plt.show()
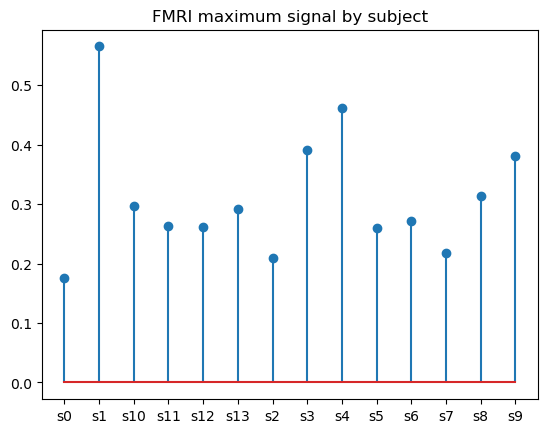
Nous pouvons jouer avec les paramètres optionnels de la fonction pour modifier l'orientation de la tige et personnaliser les propriétés de la tige, de la ligne de base et du marqueur.
Ces deux types de visualisation de données très similaires peuvent être considérés comme une mise en œuvre d'un diagramme de dispersion pour une variable catégorielle : les diagrammes en bandes et en essaims affichent tous deux l'intérieur de la distribution des données, y compris la taille de l'échantillon et la position des points de données individuels, mais pas les statistiques descriptives. La principale différence entre ces diagrammes est que dans un diagramme en bandes, les points de données peuvent se chevaucher, alors que dans un diagramme en essaim, ils ne le peuvent pas. Au lieu de cela, dans un diagramme en essaim, les points de données sont alignés le long de l'axe catégorique.
Gardez à l'esprit que les diagrammes en bandes et en essaims ne peuvent être utiles que pour des ensembles de données relativement petits.
Voici comment créer un graphique en bandes à l'aide de la fonction seaborn.stripplot():
# Creating a strip plot
sns.stripplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
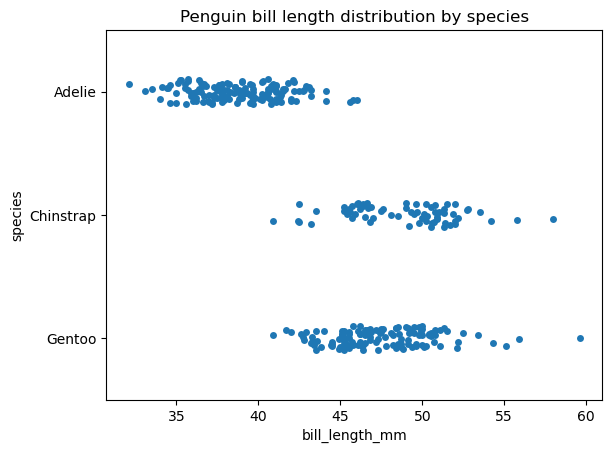
Maintenant, créons un graphique en essaim avec la fonction seaborn.swarmplot() pour les mêmes données et observons la différence :
# Creating a swarm plot
sns.swarmplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
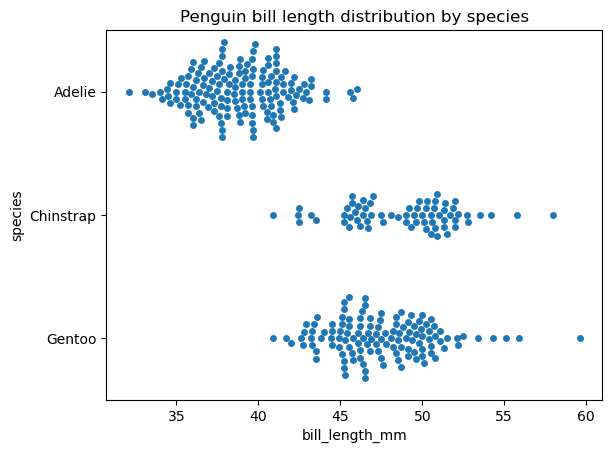
Les fonctions seaborn.stripplot() et seaborn.swarmplot() ont une syntaxe très similaire. Certaines propriétés personnalisables dans les deux fonctions sont l'ordre et l'orientation du tracé et les propriétés du marqueur, telles que le style, la taille, la couleur, la transparence, etc. du marqueur. Il convient de mentionner que la réglementation de la transparence des marqueurs permet de résoudre en partie le problème du chevauchement des points dans une parcelle en bandes.
Un treemap est un type de graphique de données utilisé pour visualiser les valeurs numériques des données catégorielles par catégorie sous la forme d'un ensemble de rectangles placés à l'intérieur d'un cadre rectangulaire, la surface de chaque rectangle étant proportionnelle à la valeur de la catégorie correspondante. De par leur fonction, les arborescences sont identiques aux diagrammes à barres et aux diagrammes circulaires. Comme les diagrammes circulaires, ils sont principalement censés représenter les catégories qui constituent l'ensemble. Les arborescences peuvent être efficaces et convaincantes lorsqu'il y a jusqu'à dix catégories avec une différence perceptible dans leurs valeurs numériques.
Les inconvénients des cartes arborescentes sont très similaires à ceux des diagrammes circulaires :
Nous devrions garder ces points à l'esprit et utiliser les cartes arborescentes avec parcimonie et uniquement lorsqu'elles sont les plus efficaces.
Pour construire un treemap en Python, nous devons d'abord installer et importer la bibliothèque squarify : pip install squarify, puis import squarify. Le code ci-dessous crée une arborescence de base :
import squarify
# Data preparation
diamonds_grouped = diamonds[['cut', 'price']].groupby('cut').mean().reset_index()
# Creating a treemap
squarify.plot(sizes=diamonds_grouped['price'], label=diamonds_grouped['cut'])
plt.title('Average diamond price by cut')
plt.show()
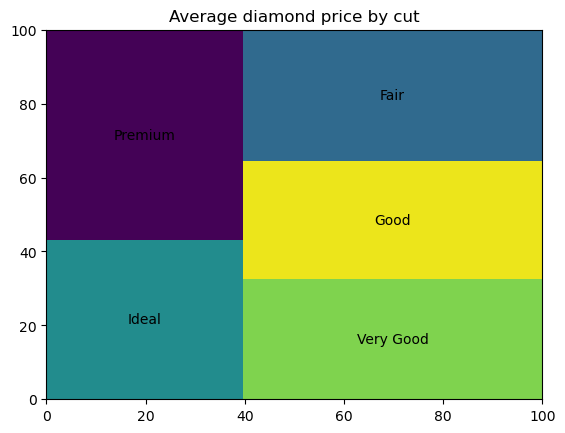
Nous pouvons personnaliser les couleurs et la transparence des rectangles, les remplir de motifs, ajuster les propriétés des bords des rectangles, ajouter un petit espace entre les rectangles et ajuster les propriétés du texte de l'étiquette.
Il existe une autre approche pour créer un treemap en Python - en utilisant la bibliothèque plotly. Pour en savoir plus, consultez le didacticiel Qu'est-ce que la visualisation de données ? Un guide pour les scientifiques des données.
Un nuage de mots est un type de visualisation de données textuelles où la taille de la police de chaque mot correspond à la fréquence de son apparition dans un texte d'entrée. L'utilisation de nuages de mots permet de repérer les mots les plus importants dans un texte.
Si les nuages de mots attirent toujours l'attention et sont intuitivement compréhensibles pour tout type de public cible, nous devons être conscients de certaines limites intrinsèques de ce type de graphiques de données :
Une application intéressante et moins connue des nuages de mots est que nous pouvons les créer en nous basant non pas sur la fréquence des mots, mais sur n'importe quel autre attribut attribué à chaque mot. Par exemple, nous pouvons créer un dictionnaire de pays, attribuer à chaque pays la valeur de sa population et afficher ces données.
Pour créer un nuage de mots en Python, nous devons utiliser une bibliothèque spécialisée dans les nuages de mots. Tout d'abord, nous devons l'installer (pip install wordcloud), puis importer la classe WordCloud et les mots-clés : from wordcloud import WordCloud, STOPWORDS. Le code suivant génère un nuage de mots de base :
from wordcloud import WordCloud, STOPWORDS
text = 'cat cat cat cat cat cat dog dog dog dog dog panda panda panda panda koala koala koala rabbit rabbit fox'
# Creating a word cloud
wordcloud = WordCloud().generate(text)
plt.imshow(wordcloud)
plt.title('Words by their frequency in the text')
plt.axis('off')
plt.show()

Il est possible d'ajuster les dimensions d'un nuage de mots, de changer sa couleur de fond, d'attribuer une carte de couleurs pour l'affichage des mots, de préférer les mots horizontaux aux mots verticaux, de limiter le nombre maximum de mots affichés, de mettre à jour la liste des mots d'arrêt, de limiter la taille des polices, de prendre en compte les collocations de mots, d'assurer la reproductibilité du graphique, etc.
Si vous voulez en savoir plus sur les nuages de mots en Python, voici une excellente lecture : Tutoriel sur la génération de nuages de mots en Python. Vous pouvez également utiliser un modèle gratuit pour vous entraîner à créer ce type de visualisation de données : Modèle : Créez un nuage de mots.
Commencez dès aujourd'hui votre voyage de visualisation de données !
Cours
Cours
Cours
Tutoriel
Sejal Jaiswal
Tutoriel
DataCamp Team
Tutoriel
Allan Ouko
Tutoriel
Laiba Siddiqui
Tutoriel
Abid Ali Awan
Tutoriel
Moez Ali

