course
Lucrul cu OpenAI API
3 oră
141.6K
OpenAI tocmai a lansat primul său model de bază reantrenat de la GPT-4.5 încoace. Sună contraintuitiv, dar GPT-5 și toți succesorii săi au fost actualizări incrementale.
Acesta este diferit: a fost construit de la zero pentru fluxuri de lucru agentice, cu performanțe solide la două repere critice care contează cel mai mult pentru dezvoltatori.
În acest articol, voi compara noul GPT-5.5 cu Gemini 3.1 Pro pentru a vă ajuta să decideți care vi se potrivește. Vom analiza reperele, costurile și cazurile de utilizare.
GPT-5.5 este cel mai recent model Omnimodal de vârf al OpenAI, cu numele de cod „Spud”. Nu este un fine-tune al unui model anterior, ci unul reconstruit de la zero pentru execuție autonomă, multi-task, cu puțină sau deloc ghidare.
GPT-5.5 este livrat în trei variante:
Aflați mai multe despre model în articolul nostru OpenAI GPT-5.5 și în comparația noastră Claude Opus 4.7 vs GPT-5.5.
Funcțiile și capabilitățile de bază ale GPT-5.5 sunt:
Una dintre cele mai mari noutăți este îmbunătățirea puternică pe sarcini cu context lung între 512K și 1M; performanța s-a mai mult decât dublat de la 36,6% în GPT 5.4 la 74,0% în GPT 5.5.
Modelul este, de asemenea, în prezent cel mai puternic la matematică. Pe FrontierMath Tier 4, GPT 5.5 obține 35,4%, iar GPT 5.5 Pro urcă la 39,6%. Pentru context, GPT 5.4 a obținut 27,1%, Claude Opus 4.7 a obținut 22,9%, iar Gemini 3.1 Pro a obținut 16,7%.
Performanța GPT-5.5 pe OSWorld-Verified îl face cel mai bun model pentru utilizarea computerului dintre cele care au oferit rezultate pentru acest reper. Depășește, de asemenea, toate celelalte modele la matematică avansată. Eficiența tokenilor este un alt avantaj pentru sarcini agentice de lungă durată.
Pe de altă parte, GPT-5.5 este mai scump decât modelul anterior, cu 5 $ pentru un milion de tokeni de intrare și 30 $ pe milion de tokeni de ieșire. Compania spune că ar putea fi mai ieftin datorită eficienței mai bune a tokenilor, dar depinde de fluxurile dumneavoastră de lucru dacă este sau nu cazul.
Gemini 3.1 Pro este modelul de vârf actual al Google, construit pe o arhitectură Mixture-of-Experts (MoE). Google l-a proiectat pentru a oferi performanțe multimodale și de raționament solide la un preț competitiv.
Pentru o comparație cu cel mai recent model de frontieră al Anthropic, citiți articolul nostru despre Claude Opus 4.7 vs Gemini 3.1 Pro.
Iată funcțiile și capabilitățile cheie ale Gemini 3.1 Pro:
Nativ multimodal cu suport pentru text și imagini. Audio, video și PDF-uri.
Sistem de gândire pe trei niveluri, oferind niveluri de gândire low, medium și high.
Fereastră de context de 1M tokeni, cu maximum 65K tokeni de ieșire și acceptare într-un singur prompt a 8,4 ore de audio sau o oră întreagă de video.
77,1% pe ARC-AGI-2, demonstrând un raționament vizual abstract puternic, de peste două ori față de 31,1% al lui Gemini 3 Pro.
33,5% pe APEX-Agents, care măsoară sarcini profesionale de lungă durată, aproape dublu față de 18,4% al lui Gemini 3 Pro.
În tutorialul nostru Construind cu Gemini 3.1 Pro, acoperim cum să creați o aplicație pregătită pentru producție cu Gemini 3.1 Pro și Gemini CLI.
Gemini 3.1 Pro excelează în sarcini complexe de raționament vizual și are un avantaj față de concurență prin designul său nativ multimodal, care gestionează text, imagini, video și audio într-un singur prompt. Combinat cu o fereastră de context masivă de 1M tokeni, puteți analiza baze de cod întregi, PDF-uri voluminoase sau ore de material video dintr-o singură încercare. Gemini 3.1 Pro alimentează, de asemenea, Nano Banana 2 și Veo 3.1 pentru ieșiri de tip imagine și video.
Pe partea minusă, Gemini 3.1 Pro are 65K tokeni de ieșire, ceea ce s-ar putea să nu fie suficient pentru sarcini agentice de lungă durată. Asta înseamnă că ar putea să nu fie potrivit pentru generare de documente lungi și bucle agentice care produc ieșiri mari.
Învățați cum să construiți un tablou de bord financiar cu Gemini 3 și testare de browser asistată de AI din tutorialul nostru Google Antigravity.
Conform Artificial Analysis Intelligence Index, GPT 5.5 este în prezent cel mai bun model per ansamblu și conduce, de asemenea, în indexul lor pentru codare și agentic.
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
Data lansării |
23 aprilie 2026 |
19 februarie 2026 |
|
Arhitectură |
Omnimodal (unificată) |
MoE (Transformer) |
|
Fereastră de context |
1M tokeni |
1M tokeni |
|
Ieșire maximă |
128K tokeni |
65K tokeni |
|
OSWorld |
78,7% |
|
|
BrowseComp |
84,4% |
85,9% |
|
ARC-AGI-2 |
85,0% |
77,1% |
|
GPQA Diamond |
93,6% |
94,3% |
|
Terminal-Bench 2.0 |
82,7% |
68,5% |
|
FrontierMath Tier 4 |
35,4% (Pro 39,6%) |
16,7% |
|
SWE-Bench Pro |
58,6% |
54,2% |
|
Preț API (intrare/ieșire per 1M) |
5 $/30 $ (Pro 30 $/180 $) |
2 $/12 $ |
Să aruncăm o privire la câteva cazuri de utilizare diferite.
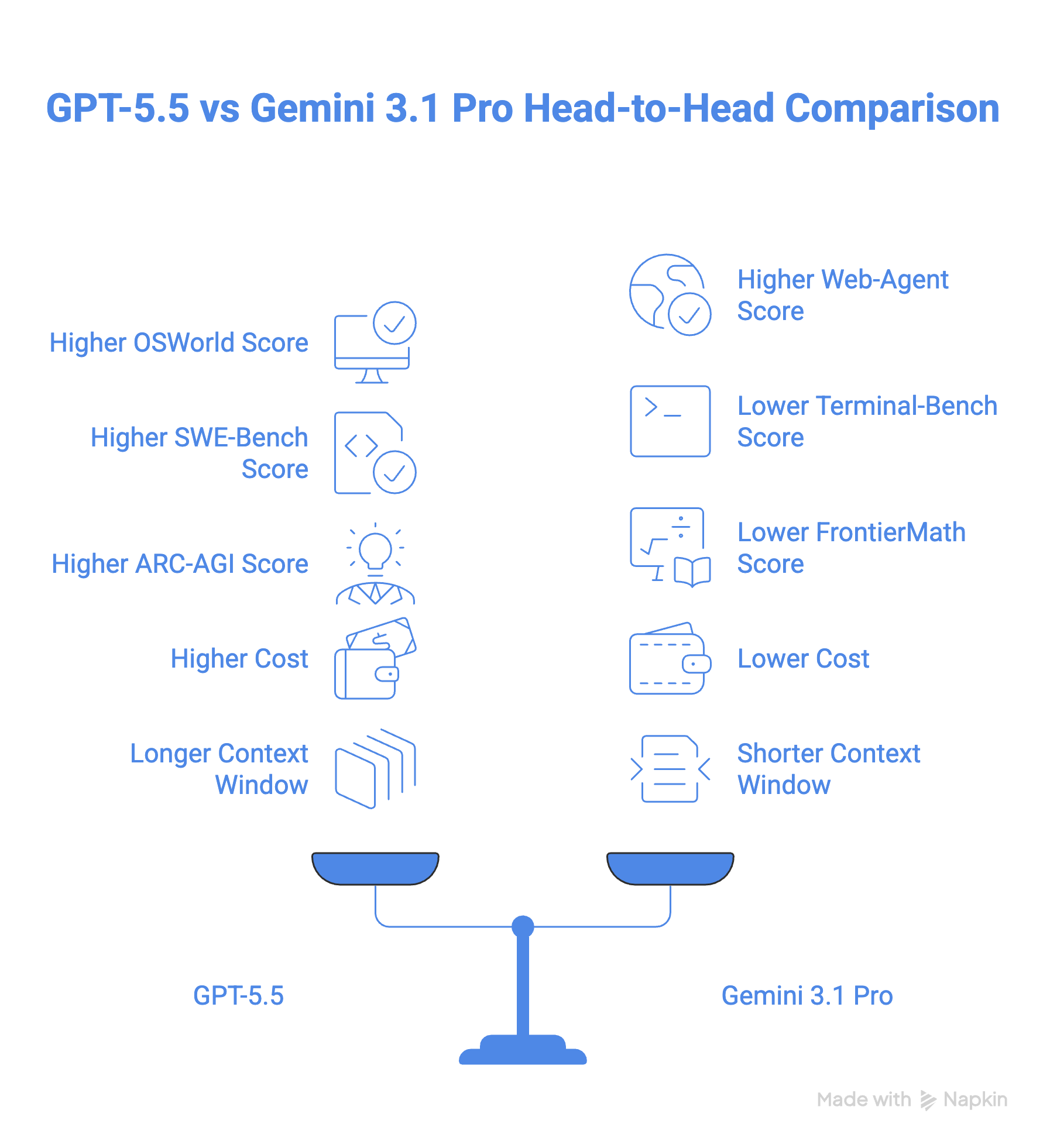
GPT-5.5 obține 78,7% pe reperul OSWorld-Verified pentru utilizarea computerului, deși nu există un scor public Gemini pentru comparație. În practică, utilizarea computerului de către GPT-5.5 este încorporată în aplicația Codex, unde poate naviga și testa site-uri web. Google oferă funcționalități similare prin aplicația sa Antigravity.
Când vine vorba de sarcini pentru agenți web, lucrurile devin mai interesante. Gemini 3.1 Pro trece în față cu 85,9% pe BrowseComp față de 84,4% pentru GPT-5.5 și are, de asemenea, performanțe mai bune pe MCP Atlas (un reper care testează utilizarea instrumentelor pe 36 de servere MCP), cu 78,2% față de 75,3% pentru GPT-5.5.
Cu toate acestea, GPT-5.5 ripostează la Toolathon, care aruncă peste 600 de instrumente reale către un model, obținând 55,6% comparativ cu 48,8% pentru Gemini. GPT-5.5 conduce, de asemenea, pe Artificial Analysis Agentic Index, unde Gemini 3.1 Pro rămâne semnificativ în urmă, așa cum se vede în graficul de mai jos.
La programare, GPT-5.5 îl depășește pe Gemini 3.1 Pro cu un scor de 58,6% pe SWE-Bench Pro și 82,7% pe Terminal-Bench 2.0, comparativ cu 54,2% și 68,5% pentru Gemini 3.1 Pro. În special la Terminal-Bench 2.0, GPT-5.5 conduce detașat.
GPT-5.5 conduce în Artificial Analysis Coding Index, cu Gemini 3.1 Pro imediat în spate.
Pe ARC-AGI-2, care măsoară capacitatea unui model de a învăța și rezolva probleme fără antrenare prealabilă, GPT-5.5 îl depășește pe Gemini 3.1 Pro cu o diferență de aproape 8 puncte (85,0% vs 77,1%).
GPT-5.5 conduce, de asemenea, la matematică avansată cu o diferență de 18 puncte față de Gemini 3.1 Pro, conform reperului FrontierMath, care testează capacitatea de raționament la nivel de expert.
Gemini 3.1 Pro costă 2 $ per 1M tokeni de intrare și 12 $ per 1M tokeni de ieșire. GPT-5.5 pornește la un tarif semnificativ mai mare, percepând 5 $ pentru 1M tokeni de intrare și 30 $ pentru 1M tokeni de ieșire (și de șase ori mai mult pentru modelul Pro). Asta face ca GPT 5.5 să fie de peste două ori mai scump decât Gemini 3.1 Pro.
Atât GPT-5.5, cât și Gemini 3.1 Pro au o fereastră de context de 1M. Totuși, GPT 5.5 oferă 128 K tokeni de ieșire, comparativ cu 65K ai lui Gemini.
Ajungem astfel la întrebarea care dintre cele două modele să fie ales.

GPT-5.5 este modelul mai puternic pe hârtie și, pentru majoritatea dezvoltatorilor, probabil și în practică, mai ales dacă munca dumneavoastră se desfășoară în medii de terminal sau implică matematică complexă. Reconstrucția de la bază a dat roade: acesta nu este un model „cârpit” pe parcurs, iar diferențele de pe Terminal-Bench 2.0 și FrontierMath o arată clar.
Dar „mai puternic” nu înseamnă întotdeauna „mai bun pentru dumneavoastră”. La un preț de 2,5 ori mai mare decât Gemini 3.1 Pro, GPT-5.5 este un angajament bugetar serios, iar argumentul privind eficiența tokenilor stă în picioare doar dacă fluxurile dumneavoastră de lucru sunt suficient de lungi pentru a beneficia de ea.
Gemini 3.1 Pro nu este aici pe locul doi. Este un model competitiv care conduce pe BrowseComp, MCP Atlas și GPQA Diamond, iar gestionarea sa nativă a video și audio este încă înaintea a ceea ce oferă nativ GPT-5.5.
Pentru majoritatea echipelor, mișcarea mai inteligentă probabil nu este o alegere binară: folosiți Gemini 3.1 Pro ca „cal de povară” pentru sarcini cu volum mare sau încărcate media și aduceți GPT-5.5 acolo unde diferența chiar contează. Această abordare hibridă vă oferă ce e mai bun din ambele lumi fără a plăti prețuri de frontieră peste tot.
Dacă doriți să învățați să creați aplicații bazate pe AI folosind LLM-uri, prompturi, lanțuri și agenți în LangChain, vă recomand cu căldură cursul nostru Developing LLM Applications with LangChain.
Învățați AI cu DataCamp!
course
course
course