Course
Working with the OpenAI API
3 hr
141.6K
OpenAI just released their first retrained base model since GPT-4.5. This sounds counterintuitive, but GPT-5 and all its other successors were incremental updates.
This one is different: It's been built from the ground up for agentic workflows, with strong performance on two critical benchmarks that matter most to developers.
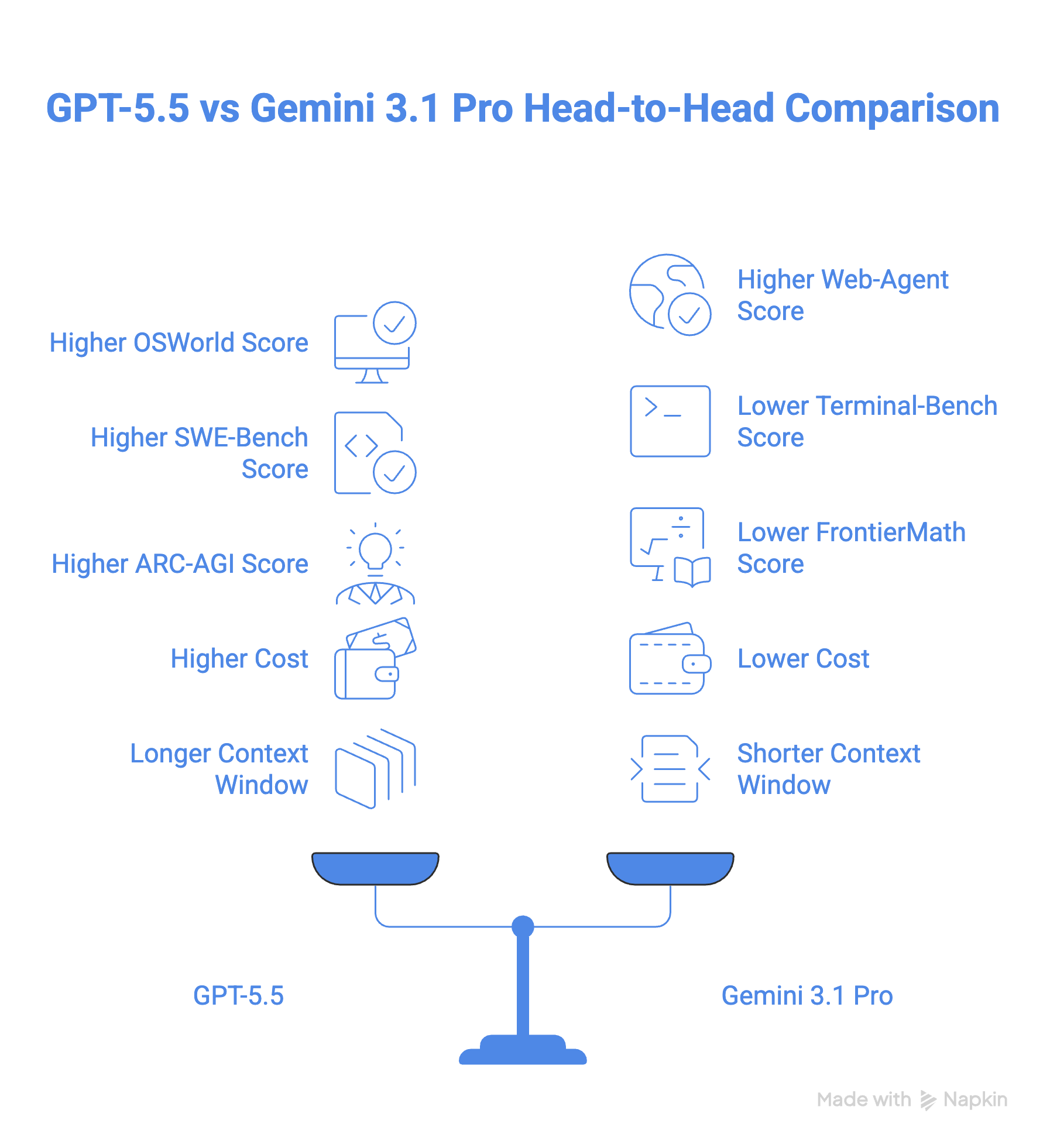
In this article, I will compare the newly released GPT-5.5 to the Gemini 3.1 Pro to help you decide which is best for you. We will look at the benchmarks, cost, and use cases.
GPT-5.5 is OpenAI’s latest flagship Omnimodal model, code-named “Spud”. It’s not a fine-tune of a previous model, but one that’s been rebuilt from the ground up for autonomous, multi-task execution with little to no hand-holding.
GPT-5.5 ships with three variants:
Discover more about the model in our OpenAI GPT-5.5 article and in our comparison of Claude Opus 4.7 vs GPT-5.5.
The core features and capabilities of GPT-5.5 are:
One of the biggest features is the strong improvement on long-context work between 512K and 1M; performance more than doubled from 36.6% in GPT 5.4 to 74.0% in GPT 5.5.
The model is also currently the strongest in mathematics. On FrontierMath Tier 4, GPT 5.5 gets 35.4%, and GPT 5.5 Pro pushes that to 39.6%. For context, GPT 5.4 scored 27.1%, Claude Opus 4.7 scored 22.9%, and Gemini 3.1 Pro scored 16.7%.
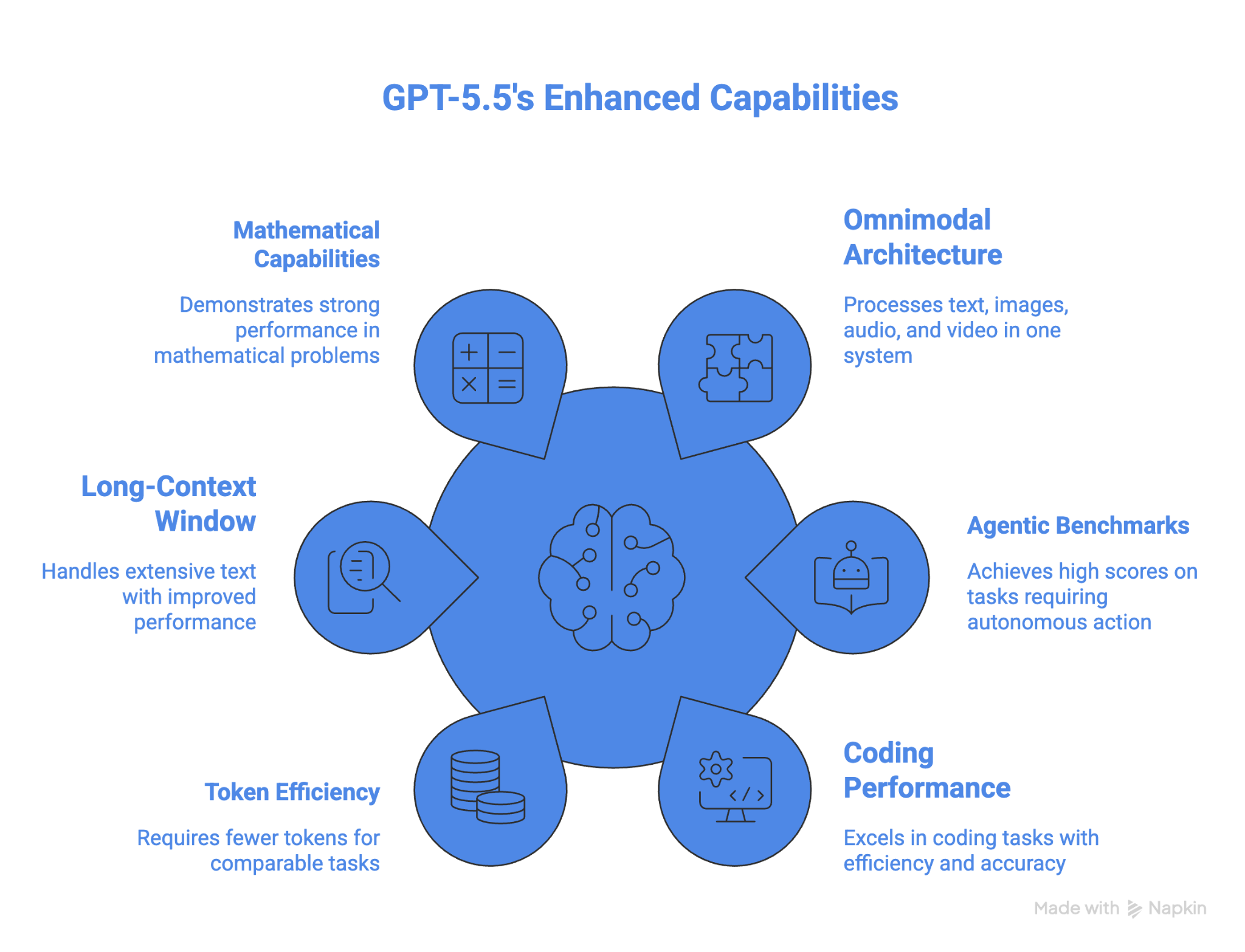
GPT-5.5's performance on OSWorld-Verified makes it the best model for computer use among those that have provided results for this benchmark. It also beats all other models in advanced math. Token efficiency is another advantage for long-running agentic tasks.
On the downside, GPT-5.5 is more expensive than the previous model, with $5 for a million input tokens and $30 per million output tokens. The company says it might be cheaper because it's more token-efficient, but it depends on your workflows whether that is the case or not.
Gemini 3.1 Pro is Google's current state-of-the-art flagship model built on a Mixture-of-Experts (MoE) architecture. Google designed it to offer strong multimodal and reasoning performance at a competitive price.
For a comparison with Anthropic’s latest frontier model, read our blog on Claude Opus 4.7 vs Gemini 3.1 Pro.
Here are Gemini 3.1 Pro key features and capabilities:
Natively multimodal with support for text and images. Audio, video, and PDFs.
Three-tier thinking system offering low, medium, and high thinking levels.
1M token context window, with 65K max output tokens and 8.4 hours of audio or a full hour of video accepted in a single prompt.
77.1% on ARC-AGI-2, showing strong abstract visual reasoning that more than doubles Gemini 3 Pro's 31.1%.
33.5% on APEX-Agents that measure long-horizon professional tasks, which is nearly twice Gemini 3 Pro's 18.4%.
In our Building with Gemini 3.1 Pro tutorial, we cover how to build a production-ready app with Gemini 3.1 Pro and the Gemini CLI.
Gemini 3.1 Pro shines in complex visual reasoning tasks and has an edge over the competition in its natively multimodal design, which handles text, images, video, and audio into a single prompt. Pair that with a massive 1M token context window, and you can analyze entire codebases, lengthy PDFs, or hours of video in one go. Gemini 3.1 Pro also powers Nano Banana 2 and Veo 3.1 for image and video output.
On the downside, Gemini 3.1 Pro features 65K output tokens, which might not be enough for long-running agentic tasks. This means it might not be a good fit for long document generation and agentic loops that produce large outputs.
Learn how to build a finance dashboard with Gemini 3 and AI-driven browser testing from our Google Antigravity tutorial.
According to the Artificial Analysis Intelligence Index, GPT 5.5 is the currently best overall model, and it also takes the lead on their coding and agentic index.
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
Release date |
April 23, 2026 |
February 19, 2026 |
|
Architecture |
Omnimodal (unified) |
MoE (Transformer) |
|
Context window |
1M tokens |
1M tokens |
|
Max output |
128K tokens |
65K tokens |
|
OSWorld |
78.7% |
|
|
BrowseComp |
84.4% |
85.9% |
|
ARC-AGI-2 |
85.0% |
77.1% |
|
GPQA Diamond |
93.6% |
94.3% |
|
Terminal-Bench 2.0 |
82.7% |
68.5% |
|
FrontierMath Tier 4 |
35.4% (Pro 39.6%) |
16.7% |
|
SWE-Bench Pro |
58.6% |
54.2% |
|
API pricing (input/output per 1M) |
$5/$30 (Pro $30/$180) |
$2/$12 |
Let’s take a look at a few different use cases.
GPT-5.5 scores 78.7% on the OSWorld-Verified benchmark for computer use, though there's no public Gemini score to compare it to. In practice, GPT-5.5's computer use is built into the Codex app, where it can navigate and test websites. Google offers similar functionality through its Antigravity app.
When it comes to web-agent tasks, the picture gets more interesting. Gemini 3.1 Pro edges ahead with 85.9% on BrowseComp versus GPT-5.5's 84.4%, and it also performs better on MCP Atlas (a benchmark that tests tool use across 36 MCP servers), scoring 78.2% to GPT-5.5's 75.3%.
That said, GPT-5.5 fights back on Toolathon, which throws over 600 real-world tools at a model, scoring 55.6% compared to Gemini's 48.8%. GPT-5.5 also takes the lead on the Artificial Analysis Agentic Index where Gemini 3.1 Pro lags behind significantly, as shown in the chart below.
When it comes to coding, GPT-5.5 beats Gemini 3.1 Pro with a score of 58.6% on SWE-Bench Pro and 82.7% on Terminal-Bench 2.0, compared to Gemini 3.1 Pro 54.2% and 68.5%. Especially on Terminal-Bench 2.0, GPT-5.5 leads with a big margin.
GPT-5.5 leads on the Artificial Analysis Coding Index with Gemini 3.1 Pro right behind it.
On the ARC-AGI-2, which measures a model's ability to learn and solve problems without prior training, GPT-5.5 beats Gemini 3.1 Pro with a difference of close to 8 points (85.0% vs 77.1%).
GPT-5.5 also takes the lead on advanced maths with an 18-point difference compared to Gemini 3.1 Pro as measured by the FrontierMath benchmark, which tests a model’s reasoning ability at an expert level.
Gemini 3.1 Pro costs $2 per 1M input tokens and $12 per 1M output tokens. GPT-5.5 starts at a significantly higher rate, charging $5 for 1M input tokens and $30 for 1M output tokens (and six times that for the Pro model). This makes GPT 5.5 more than twice as expensive as Gemini 3.1 Pro.
GPT-5.5 and Gemini 3.1 Pro both have a 1M context window. However, GPT 5.5 offers 128 K output tokens, compared to Gemini’s 65K.
This brings us to the question of which one of the two models to choose.

GPT-5.5 is the stronger model on paper, and for most developers, it probably is in practice too, especially if your work lives in terminal environments or uses complex math. The ground-up rebuild paid off: this isn't a model that was patched into shape, and the benchmark gaps on Terminal-Bench 2.0 and FrontierMath make that clear.
But "stronger" doesn't always mean "better for you." At 2.5x the price of Gemini 3.1 Pro, GPT-5.5 is a real budget commitment, and the token efficiency argument only holds if your workflows are long enough to benefit from it.
Gemini 3.1 Pro is not the runner-up here. It's a competitive model that leads on BrowseComp, MCP Atlas, and GPQA Diamond, and its native video and audio handling is still ahead of what GPT-5.5 offers natively.
The smarter play for most teams is probably not a binary choice: use Gemini 3.1 Pro as your workhorse for high-volume or media-heavy tasks, and bring in GPT-5.5 where the margin actually matters. That hybrid approach gets you the best of both without paying frontier prices across the board.
If you want to learn building AI-powered applications using LLMs, prompts, chains, and agents in LangChain, I highly recommend taking our Developing LLM Applications with LangChain course.
Learn AI with DataCamp!
Course
Course
Course
blog
Tom Farnschläder
11 min
blog
Tom Farnschläder
11 min
blog
Derrick Mwiti
10 min
blog
Khalid Abdelaty
11 min
blog
Khalid Abdelaty
11 min
blog
Vinod Chugani
10 min