course
Working with the OpenAI API
3 timmar
141.6K
OpenAI har precis släppt sin första omtränade basmodell sedan GPT-4.5. Det låter motsägelsefullt, men GPT-5 och alla dess efterföljare var inkrementella uppdateringar.
Den här är annorlunda: Den är byggd från grunden för agentiska arbetsflöden, med stark prestanda på två kritiska benchmarktester som är viktigast för utvecklare.
I den här artikeln jämför jag nysläppta GPT-5.5 med Gemini 3.1 Pro för att hjälpa dig välja vad som passar dig bäst. Vi tittar på benchmarkresultat, kostnad och användningsfall.
GPT-5.5 är OpenAI:s senaste omnimodala flaggskeppsmodell, med kodnamnet ”Spud”. Det är inte en finjustering av en tidigare modell, utan en som har byggts om från grunden för autonom, fleruppgiftskörning med lite eller ingen handhållning.
GPT-5.5 levereras med tre varianter:
Läs mer om modellen i vår artikel OpenAI GPT-5.5 och i vår jämförelse Claude Opus 4.7 vs GPT-5.5.
Kärnfunktionerna och kapabiliteterna i GPT-5.5 är:
En av de största nyheterna är den starka förbättringen för lång kontext mellan 512K och 1M; prestandan mer än fördubblades från 36,6% i GPT 5.4 till 74,0% i GPT 5.5.
Modellen är också för närvarande starkast i matematik. På FrontierMath Tier 4 får GPT 5.5 35,4%, och GPT 5.5 Pro höjer det till 39,6%. Som jämförelse fick GPT 5.4 27,1%, Claude Opus 4.7 22,9% och Gemini 3.1 Pro 16,7%.
GPT-5.5:s resultat på OSWorld-Verified gör den till den bästa modellen för datoranvändning bland dem som redovisat resultat för detta benchmarktest. Den slår också alla andra modeller i avancerad matematik. Tokeneffektivitet är en annan fördel för långvariga agentiska uppgifter.
Nackdelen är att GPT-5.5 är dyrare än föregående modell, med 5 dollar för en miljon inputtoken och 30 dollar per miljon outputtoken. Företaget säger att den kan bli billigare eftersom den är mer tokeneffektiv, men det beror på dina arbetsflöden om det stämmer eller inte.
Gemini 3.1 Pro är Googles nuvarande toppmodell byggd på en Mixture-of-Experts (MoE)-arkitektur. Google har designat den för att erbjuda stark multimodal och resonemangsförmåga till ett konkurrenskraftigt pris.
För en jämförelse med Anthropics senaste frontier-modell, läs vår blogg om Claude Opus 4.7 vs Gemini 3.1 Pro.
Här är Gemini 3.1 Pros viktigaste funktioner och kapabiliteter:
Nativt multimodal med stöd för text och bilder. Ljud, video och PDF:er.
Trettonat tänkandesystem som erbjuder nivåerna low, medium och high.
1M tokens kontextfönster, med 65K max outputtoken och 8,4 timmars ljud eller en hel timmes video i en enda prompt.
77,1% på ARC-AGI-2, vilket visar stark abstrakt visuellt resonemang som mer än fördubblar Gemini 3 Pros 31,1%.
33,5% på APEX-Agents som mäter långsiktiga professionella uppgifter, vilket är nästan dubbelt så mycket som Gemini 3 Pros 18,4%.
I vår guide Bygga med Gemini 3.1 Pro går vi igenom hur du bygger en produktionsklar app med Gemini 3.1 Pro och Gemini CLI.
Gemini 3.1 Pro glänser i komplexa visuella resonemangsuppgifter och har ett övertag gentemot konkurrenterna med sin nativt multimodala design, som hanterar text, bilder, video och ljud i en enda prompt. Kombinera det med ett enormt kontextfönster på 1M token, så kan du analysera hela kodbaser, långa PDF:er eller timmar av video i ett svep. Gemini 3.1 Pro driver också Nano Banana 2 och Veo 3.1 för bild- och videoutdata.
Nackdelen är att Gemini 3.1 Pro har 65K outputtoken, vilket kanske inte räcker för långvariga agentiska uppgifter. Det betyder att den kanske inte passar för lång dokumentgenerering och agentiska loopar som producerar stora utdata.
Lär dig bygga en finansdashboard med Gemini 3 och AI-driven webbläsartestning i vår guide Google Antigravity.
Enligt Artificial Analysis Intelligence Index är GPT 5.5 den bästa modellen överlag just nu, och den leder också deras kodnings- och agentindex.
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
Utgivningsdatum |
23 april 2026 |
19 februari 2026 |
|
Arkitektur |
Omnimodal (enhetlig) |
MoE (Transformer) |
|
Kontextfönster |
1M token |
1M token |
|
Maxutdata |
128K token |
65K token |
|
OSWorld |
78,7% |
|
|
BrowseComp |
84,4% |
85,9% |
|
ARC-AGI-2 |
85,0% |
77,1% |
|
GPQA Diamond |
93,6% |
94,3% |
|
Terminal-Bench 2.0 |
82,7% |
68,5% |
|
FrontierMath Tier 4 |
35,4% (Pro 39,6%) |
16,7% |
|
SWE-Bench Pro |
58,6% |
54,2% |
|
API-priser (input/output per 1M) |
$5/$30 (Pro $30/$180) |
$2/$12 |
Låt oss titta på några olika användningsfall.
GPT-5.5 får 78,7% på OSWorld-Verified-benchmarktestet för datoranvändning, även om det inte finns något offentligt Gemini-resultat att jämföra med. I praktiken är GPT-5.5:s datoranvändning inbyggd i Codex-appen, där den kan navigera och testa webbplatser. Google erbjuder liknande funktionalitet genom sin Antigravity-app.
När det gäller webbagent-uppgifter blir bilden mer intressant. Gemini 3.1 Pro ligger något före med 85,9% på BrowseComp jämfört med GPT-5.5:s 84,4%, och den presterar också bättre på MCP Atlas (ett benchmarktest som prövar verktygsanvändning över 36 MCP-servrar), med 78,2% mot GPT-5.5:s 75,3%.
Samtidigt slår GPT-5.5 tillbaka på Toolathon, som kastar över 600 verkliga verktyg på en modell, med 55,6% jämfört med Geminis 48,8%. GPT-5.5 tar också ledningen på Artificial Analysis Agentic Index där Gemini 3.1 Pro halkar efter markant, som visas i diagrammet nedan.
När det gäller kodning slår GPT-5.5 Gemini 3.1 Pro med 58,6% på SWE-Bench Pro och 82,7% på Terminal-Bench 2.0, jämfört med Gemini 3.1 Pros 54,2% respektive 68,5%. Särskilt på Terminal-Bench 2.0 leder GPT-5.5 med god marginal.
GPT-5.5 leder Artificial Analysis Coding Index med Gemini 3.1 Pro strax bakom.
På ARC-AGI-2, som mäter en modells förmåga att lära och lösa problem utan förträning, slår GPT-5.5 Gemini 3.1 Pro med en skillnad på nära 8 poäng (85,0% vs 77,1%).
GPT-5.5 tar också ledningen i avancerad matematik med en skillnad på 18 poäng jämfört med Gemini 3.1 Pro enligt FrontierMath-benchmarktestet, som prövar en modells resonemangsförmåga på expertnivå.
Gemini 3.1 Pro kostar 2 dollar per 1M inputtoken och 12 dollar per 1M outputtoken. GPT-5.5 börjar på en avsevärt högre nivå, med 5 dollar för 1M inputtoken och 30 dollar för 1M outputtoken (och sex gånger det för Pro-modellen). Det gör GPT 5.5 mer än dubbelt så dyr som Gemini 3.1 Pro.
GPT-5.5 och Gemini 3.1 Pro har båda ett kontextfönster på 1M. Däremot erbjuder GPT 5.5 128 K outputtoken, jämfört med Geminis 65K.
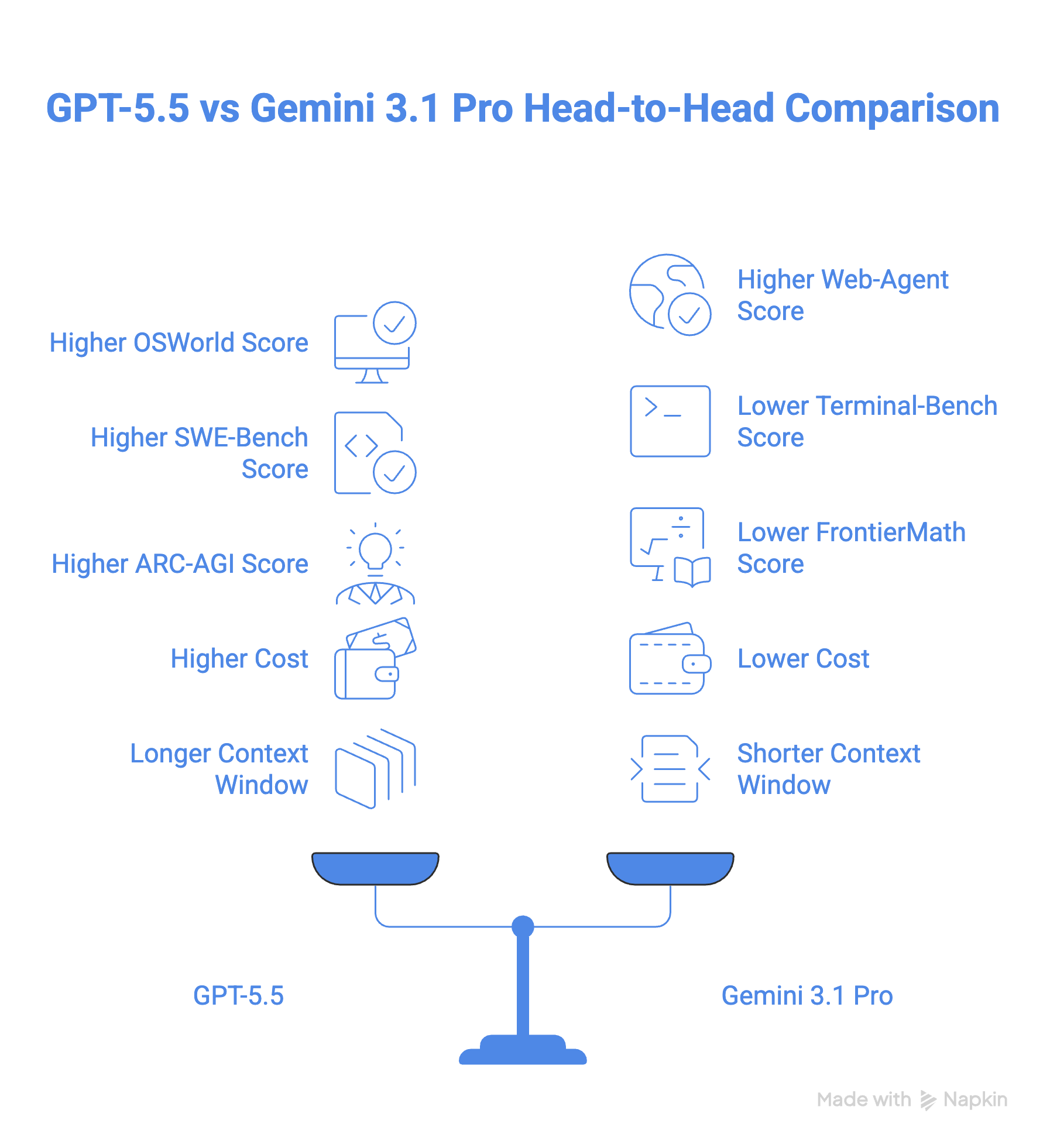
Det för oss till frågan vilken av de två modellerna du ska välja.

GPT-5.5 är den starkare modellen på pappret, och för de flesta utvecklare är den det sannolikt i praktiken också, särskilt om ditt arbete sker i terminalmiljöer eller använder komplex matematik. Obygget från grunden gav utdelning: det här är inte en modell som lappats ihop, och gapen i benchmarkresultaten på Terminal-Bench 2.0 och FrontierMath visar det tydligt.
Men ”starkare” betyder inte alltid ”bättre för dig”. Till 2,5 gånger priset av Gemini 3.1 Pro är GPT-5.5 ett verkligt budgetåtagande, och argumentet om tokeneffektivitet håller bara om dina arbetsflöden är tillräckligt långa för att dra nytta av det.
Gemini 3.1 Pro är inte tvåa här. Det är en konkurrenskraftig modell som leder på BrowseComp, MCP Atlas och GPQA Diamond, och dess inbyggda hantering av video och ljud ligger fortfarande före vad GPT-5.5 erbjuder nativt.
Det smartaste valet för de flesta team är förmodligen inte ett binärt beslut: använd Gemini 3.1 Pro som arbetshäst för volymtunga eller mediaintensiva uppgifter, och ta in GPT-5.5 där marginalen faktiskt spelar roll. Det hybridupplägget ger dig det bästa av båda utan att betala frontier-priser rakt igenom.
Om du vill lära dig att bygga AI-drivna applikationer med LLM:er, promptar, kedjor och agenter i LangChain rekommenderar jag varmt vår kurs Developing LLM Applications with LangChain.
Lär dig AI med DataCamp!
course
course
course