
Courses
Làm việc với OpenAI API
3 giờ
141.6K
OpenAI vừa ra mắt mô hình nền được huấn luyện lại đầu tiên kể từ GPT-4.5. Nghe có vẻ trái ngược, nhưng GPT-5 và các phiên bản kế tiếp khác chỉ là các bản cập nhật gia tăng.
Lần này thì khác: mô hình được xây dựng lại từ đầu cho các quy trình agentic, với hiệu năng mạnh trên hai chuẩn đánh giá quan trọng nhất đối với nhà phát triển.
Trong bài viết này, tôi sẽ so sánh GPT-5.5 vừa phát hành với Gemini 3.1 Pro để giúp bạn quyết định mô hình nào phù hợp hơn. Chúng ta sẽ xem các chuẩn đánh giá, chi phí và trường hợp sử dụng.
GPT-5.5 là mô hình Omnimodal đầu bảng mới nhất của OpenAI, tên mã “Spud”. Đây không phải là bản tinh chỉnh của mô hình trước đó, mà là một mô hình được xây dựng lại từ đầu cho việc thực thi tự động, đa nhiệm với rất ít hoặc không cần chỉ dẫn chi tiết.
GPT-5.5 có ba biến thể:
Tìm hiểu thêm về mô hình trong bài viết OpenAI GPT-5.5 của chúng tôi và phần so sánh Claude Opus 4.7 vs GPT-5.5.
Các tính năng và năng lực cốt lõi của GPT-5.5 gồm:
Một trong những điểm nổi bật nhất là cải thiện mạnh ở công việc ngữ cảnh dài giữa 512K và 1M; hiệu năng tăng hơn gấp đôi từ 36,6% ở GPT 5.4 lên 74,0% ở GPT 5.5.
Mô hình hiện cũng mạnh nhất về toán học. Trên FrontierMath Tier 4, GPT 5.5 đạt 35,4%, và GPT 5.5 Pro nâng lên 39,6%. Để so sánh, GPT 5.4 đạt 27,1%, Claude Opus 4.7 đạt 22,9%, và Gemini 3.1 Pro đạt 16,7%.
Hiệu năng của GPT-5.5 trên OSWorld-Verified khiến nó trở thành mô hình tốt nhất cho việc sử dụng máy tính trong số các mô hình đã công bố kết quả trên chuẩn này. Nó cũng vượt mọi mô hình khác ở toán học nâng cao. Hiệu quả token là một lợi thế khác cho các tác vụ agentic chạy dài.
Điểm trừ là GPT-5.5 đắt hơn mô hình trước, với $5 cho một triệu token đầu vào và $30 cho một triệu token đầu ra. Công ty nói rằng tổng chi phí có thể rẻ hơn nhờ hiệu quả token cao, nhưng điều đó còn tùy quy trình công việc của bạn.
Gemini 3.1 Pro là mô hình đầu bảng tối tân hiện nay của Google, xây dựng trên kiến trúc Mixture-of-Experts (MoE). Google thiết kế nó để mang lại hiệu năng đa phương thức và suy luận mạnh với mức giá cạnh tranh.
Để so sánh với mô hình frontier mới nhất của Anthropic, hãy đọc bài Claude Opus 4.7 vs Gemini 3.1 Pro của chúng tôi.
Dưới đây là các tính năng và năng lực chính của Gemini 3.1 Pro:
Đa phương thức nguyên bản, hỗ trợ văn bản và hình ảnh. Âm thanh, video và PDF.
Hệ thống suy nghĩ ba mức cung cấp các cấp low, medium và high.
Cửa sổ ngữ cảnh 1M token, tối đa 65K token đầu ra và chấp nhận 8,4 giờ âm thanh hoặc một giờ video trong một prompt.
77,1% trên ARC-AGI-2, thể hiện khả năng suy luận hình ảnh trừu tượng mạnh, hơn gấp đôi mức 31,1% của Gemini 3 Pro.
33,5% trên APEX-Agents đo lường các tác vụ chuyên môn tầm xa, gần gấp đôi mức 18,4% của Gemini 3 Pro.
Trong hướng dẫn Xây dựng với Gemini 3.1 Pro, chúng tôi trình bày cách xây dựng ứng dụng sẵn sàng cho sản xuất với Gemini 3.1 Pro và Gemini CLI.
Gemini 3.1 Pro nổi bật ở các tác vụ suy luận hình ảnh phức tạp và có lợi thế so với đối thủ nhờ thiết kế đa phương thức nguyên bản, xử lý văn bản, hình ảnh, video và âm thanh trong một prompt duy nhất. Kết hợp với cửa sổ ngữ cảnh khổng lồ 1M token, bạn có thể phân tích cả bộ mã nguồn, các tệp PDF dài hoặc hàng giờ video trong một lần. Gemini 3.1 Pro cũng cung cấp sức mạnh cho Nano Banana 2 và Veo 3.1 để xuất hình ảnh và video.
Nhược điểm là Gemini 3.1 Pro chỉ hỗ trợ 65K token đầu ra, có thể không đủ cho các tác vụ agentic chạy dài. Điều này có nghĩa nó có thể không phù hợp cho việc tạo tài liệu dài và các vòng lặp agentic tạo ra lượng đầu ra lớn.
Hãy học cách xây dựng bảng điều khiển tài chính với Gemini 3 và kiểm thử trình duyệt do AI dẫn dắt từ hướng dẫn Google Antigravity của chúng tôi.
Theo Artificial Analysis Intelligence Index, GPT 5.5 hiện là mô hình tổng thể tốt nhất, đồng thời dẫn đầu ở chỉ số lập trình và agentic của họ.
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
Ngày phát hành |
23 tháng 4, 2026 |
19 tháng 2, 2026 |
|
Kiến trúc |
Omnimodal (thống nhất) |
MoE (Transformer) |
|
Cửa sổ ngữ cảnh |
1M token |
1M token |
|
Đầu ra tối đa |
128K token |
65K token |
|
OSWorld |
78,7% |
|
|
BrowseComp |
84,4% |
85,9% |
|
ARC-AGI-2 |
85,0% |
77,1% |
|
GPQA Diamond |
93,6% |
94,3% |
|
Terminal-Bench 2.0 |
82,7% |
68,5% |
|
FrontierMath Tier 4 |
35,4% (Pro 39,6%) |
16,7% |
|
SWE-Bench Pro |
58,6% |
54,2% |
|
Giá API (đầu vào/đầu ra trên 1M) |
$5/$30 (Pro $30/$180) |
$2/$12 |
Hãy cùng xem qua một vài trường hợp sử dụng khác nhau.
GPT-5.5 đạt 78,7% trên chuẩn OSWorld-Verified cho việc sử dụng máy tính, dù hiện chưa có điểm công khai của Gemini để so. Trên thực tế, khả năng sử dụng máy tính của GPT-5.5 được tích hợp trong ứng dụng Codex, nơi nó có thể điều hướng và kiểm thử website. Google cung cấp chức năng tương tự qua ứng dụng Antigravity.
Khi xét đến tác vụ web-agent, bức tranh trở nên thú vị hơn. Gemini 3.1 Pro nhỉnh hơn với 85,9% trên BrowseComp so với 84,4% của GPT-5.5, và cũng thể hiện tốt hơn trên MCP Atlas (chuẩn đánh giá việc dùng công cụ trên 36 máy chủ MCP), đạt 78,2% so với 75,3% của GPT-5.5.
Tuy vậy, GPT-5.5 phản công trên Toolathon, nơi ném hơn 600 công cụ thực tế vào mô hình, đạt 55,6% so với 48,8% của Gemini. GPT-5.5 cũng dẫn đầu trên Artificial Analysis Agentic Index trong khi Gemini 3.1 Pro tụt lại đáng kể, như thể hiện ở biểu đồ dưới đây.
Về lập trình, GPT-5.5 vượt Gemini 3.1 Pro với 58,6% trên SWE-Bench Pro và 82,7% trên Terminal-Bench 2.0, so với 54,2% và 68,5% của Gemini 3.1 Pro. Đặc biệt trên Terminal-Bench 2.0, GPT-5.5 dẫn trước với khoảng cách lớn.
GPT-5.5 dẫn đầu trên Artificial Analysis Coding Index, với Gemini 3.1 Pro bám sát phía sau.
Trên ARC-AGI-2, đo khả năng học và giải quyết vấn đề mà không cần huấn luyện trước, GPT-5.5 vượt Gemini 3.1 Pro với chênh lệch gần 8 điểm (85,0% so với 77,1%).
GPT-5.5 cũng dẫn đầu về toán nâng cao với khoảng cách 18 điểm so với Gemini 3.1 Pro theo chuẩn FrontierMath, vốn kiểm tra khả năng suy luận ở mức chuyên gia.
Gemini 3.1 Pro có giá $2 cho 1M token đầu vào và $12 cho 1M token đầu ra. GPT-5.5 khởi điểm cao hơn đáng kể, tính $5 cho 1M token đầu vào và $30 cho 1M token đầu ra (và gấp sáu lần cho bản Pro). Điều này khiến GPT 5.5 đắt hơn hơn gấp đôi so với Gemini 3.1 Pro.
GPT-5.5 và Gemini 3.1 Pro đều có cửa sổ ngữ cảnh 1M. Tuy nhiên, GPT 5.5 cung cấp 128K token đầu ra, so với 65K của Gemini.
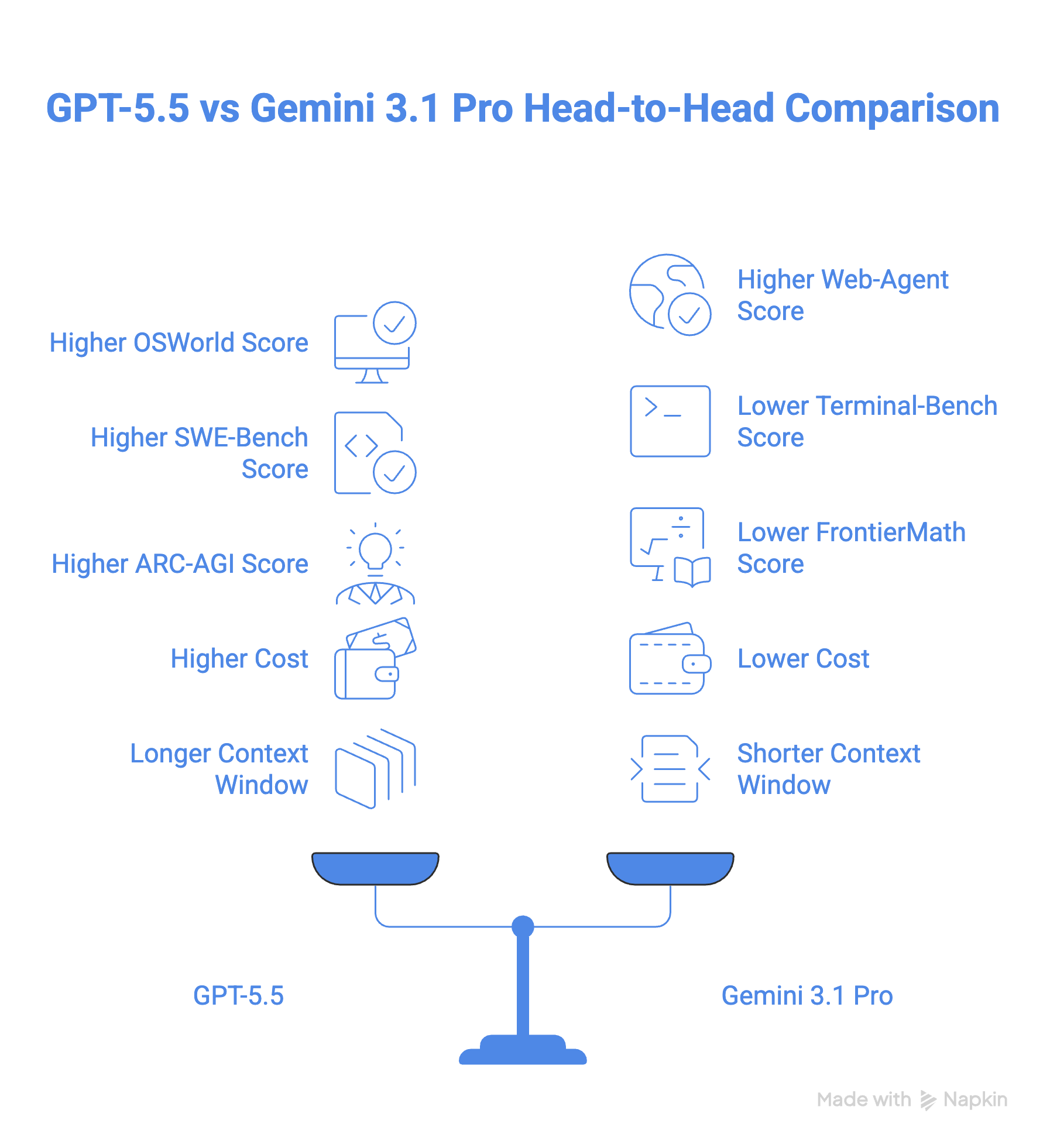
Và đây là câu hỏi: nên chọn mô hình nào trong hai mô hình này.

GPT-5.5 mạnh hơn trên giấy tờ, và với đa số nhà phát triển, có lẽ cũng đúng trong thực tế, đặc biệt nếu công việc của bạn chạy trong môi trường terminal hoặc dùng toán học phức tạp. Việc xây dựng lại từ gốc đã phát huy: đây không phải mô hình được “vá” cho ổn, và khoảng cách trên Terminal-Bench 2.0 lẫn FrontierMath cho thấy điều đó.
Nhưng “mạnh hơn” không phải lúc nào cũng đồng nghĩa “tốt hơn cho bạn”. Với mức giá gấp 2,5 lần Gemini 3.1 Pro, GPT-5.5 là một cam kết ngân sách đáng kể, và lập luận về hiệu quả token chỉ đúng nếu quy trình của bạn đủ dài để hưởng lợi.
Gemini 3.1 Pro không phải kẻ về nhì ở đây. Đây là một mô hình cạnh tranh, dẫn đầu trên BrowseComp, MCP Atlas và GPQA Diamond, và khả năng xử lý video, âm thanh nguyên bản của nó vẫn vượt những gì GPT-5.5 hỗ trợ nguyên bản.
Nước đi thông minh cho hầu hết đội ngũ có lẽ không phải chọn một trong hai: dùng Gemini 3.1 Pro làm “ngựa thồ” cho các tác vụ khối lượng lớn hoặc nặng media, và gọi GPT-5.5 khi biên độ thực sự quan trọng. Cách lai này giúp bạn tận dụng ưu điểm của cả hai mà không phải trả giá frontier trên diện rộng.
Nếu bạn muốn học xây dựng ứng dụng dùng AI với LLM, prompt, chain và agent trong LangChain, tôi rất khuyến nghị khóa Developing LLM Applications with LangChain của chúng tôi.
Học AI với DataCamp!
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút