
Kursus
Bekerja dengan OpenAI API
3 Hr
142.5K
OpenAI baru saja merilis model dasar hasil pelatihan ulang pertama sejak GPT-4.5. Ini terdengar berlawanan dengan intuisi, tetapi GPT-5 dan semua penerus lainnya merupakan pembaruan inkremental.
Yang satu ini berbeda: Dibangun dari nol untuk alur kerja agen, dengan performa kuat pada dua tolok ukur krusial yang paling penting bagi pengembang.
Dalam artikel ini, saya akan membandingkan GPT-5.5 yang baru dirilis dengan Gemini 3.1 Pro untuk membantu Anda memutuskan mana yang terbaik untuk Anda. Kita akan melihat tolok ukur, biaya, dan use case.
GPT-5.5 adalah model Omnimodal unggulan terbaru OpenAI, berkode nama “Spud”. Ini bukan hasil fine-tune dari model sebelumnya, melainkan dibangun ulang dari nol untuk eksekusi multi-tugas secara otonom dengan sedikit hingga tanpa pendampingan.
GPT-5.5 hadir dengan tiga varian:
Pelajari lebih lanjut tentang model ini di artikel kami OpenAI GPT-5.5 dan di perbandingan kami Claude Opus 4.7 vs GPT-5.5.
Fitur dan kapabilitas inti GPT-5.5 adalah:
Salah satu fitur terbesar adalah peningkatan kuat pada pekerjaan konteks panjang antara 512K dan 1M; performa lebih dari dua kali lipat dari 36,6% di GPT 5.4 menjadi 74,0% di GPT 5.5.
Model ini saat ini juga yang terkuat dalam matematika. Pada FrontierMath Tier 4, GPT 5.5 meraih 35,4%, dan GPT 5.5 Pro mendorongnya hingga 39,6%. Sebagai konteks, GPT 5.4 meraih 27,1%, Claude Opus 4.7 meraih 22,9%, dan Gemini 3.1 Pro meraih 16,7%.
Performa GPT-5.5 pada OSWorld-Verified menjadikannya model terbaik untuk penggunaan komputer di antara model yang menyediakan hasil untuk tolok ukur ini. Model ini juga mengungguli semua model lain dalam matematika tingkat lanjut. Efisiensi token menjadi keunggulan lain untuk tugas agentic yang berjalan lama.
Di sisi lain, GPT-5.5 lebih mahal daripada model sebelumnya, yaitu $5 untuk satu juta token input dan $30 per satu juta token output. Perusahaan mengatakan mungkin lebih murah karena lebih efisien dalam penggunaan token, tetapi hal itu bergantung pada alur kerja Anda apakah benar demikian atau tidak.
Gemini 3.1 Pro adalah model unggulan mutakhir Google yang dibangun di atas arsitektur Mixture-of-Experts (MoE). Google merancangnya untuk menawarkan performa multimodal dan penalaran yang kuat dengan harga kompetitif.
Untuk perbandingan dengan model frontier terbaru dari Anthropic, baca blog kami Claude Opus 4.7 vs Gemini 3.1 Pro.
Berikut fitur dan kapabilitas utama Gemini 3.1 Pro:
Multimodal native dengan dukungan untuk teks dan gambar. Audio, video, dan PDF.
Sistem penalaran tiga tingkat yang menawarkan level penalaran low, medium, dan high.
Jendela konteks 1 juta token, dengan 65K token output maksimum serta menerima 8,4 jam audio atau satu jam penuh video dalam satu prompt.
77,1% pada ARC-AGI-2, menunjukkan penalaran visual abstrak yang kuat, lebih dari dua kali lipat Gemini 3 Pro yang 31,1%.
33,5% pada APEX-Agents yang mengukur tugas profesional berjangka panjang, hampir dua kali Gemini 3 Pro yang 18,4%.
Dalam tutorial Membangun dengan Gemini 3.1 Pro, kami membahas cara membangun aplikasi siap produksi dengan Gemini 3.1 Pro dan Gemini CLI.
Gemini 3.1 Pro unggul pada tugas penalaran visual yang kompleks dan memiliki kelebihan atas kompetitor melalui desain multimodal native, yang menangani teks, gambar, video, dan audio dalam satu prompt. Dipadukan dengan jendela konteks raksasa 1 juta token, Anda dapat menganalisis seluruh basis kode, PDF panjang, atau berjam-jam video sekaligus. Gemini 3.1 Pro juga mendukung Nano Banana 2 dan Veo 3.1 untuk keluaran gambar dan video.
Di sisi kekurangan, Gemini 3.1 Pro menyediakan 65K token output, yang mungkin tidak cukup untuk tugas agentic jangka panjang. Ini berarti mungkin kurang cocok untuk pembuatan dokumen panjang dan loop agentic yang menghasilkan keluaran besar.
Pelajari cara membangun dasbor keuangan dengan Gemini 3 dan pengujian browser berbasis AI dari tutorial Google Antigravity kami.
Menurut Artificial Analysis Intelligence Index, GPT 5.5 saat ini adalah model terbaik secara keseluruhan, dan juga memimpin pada indeks coding dan agentic mereka.
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
Tanggal rilis |
23 April 2026 |
19 Februari 2026 |
|
Arsitektur |
Omnimodal (terpadu) |
MoE (Transformer) |
|
Jendela konteks |
1 juta token |
1 juta token |
|
Output maksimum |
128K token |
65K token |
|
OSWorld |
78,7% |
|
|
BrowseComp |
84,4% |
85,9% |
|
ARC-AGI-2 |
85,0% |
77,1% |
|
GPQA Diamond |
93,6% |
94,3% |
|
Terminal-Bench 2.0 |
82,7% |
68,5% |
|
FrontierMath Tier 4 |
35,4% (Pro 39,6%) |
16,7% |
|
SWE-Bench Pro |
58,6% |
54,2% |
|
Harga API (input/output per 1M) |
$5/$30 (Pro $30/$180) |
$2/$12 |
Mari kita lihat beberapa use case yang berbeda.
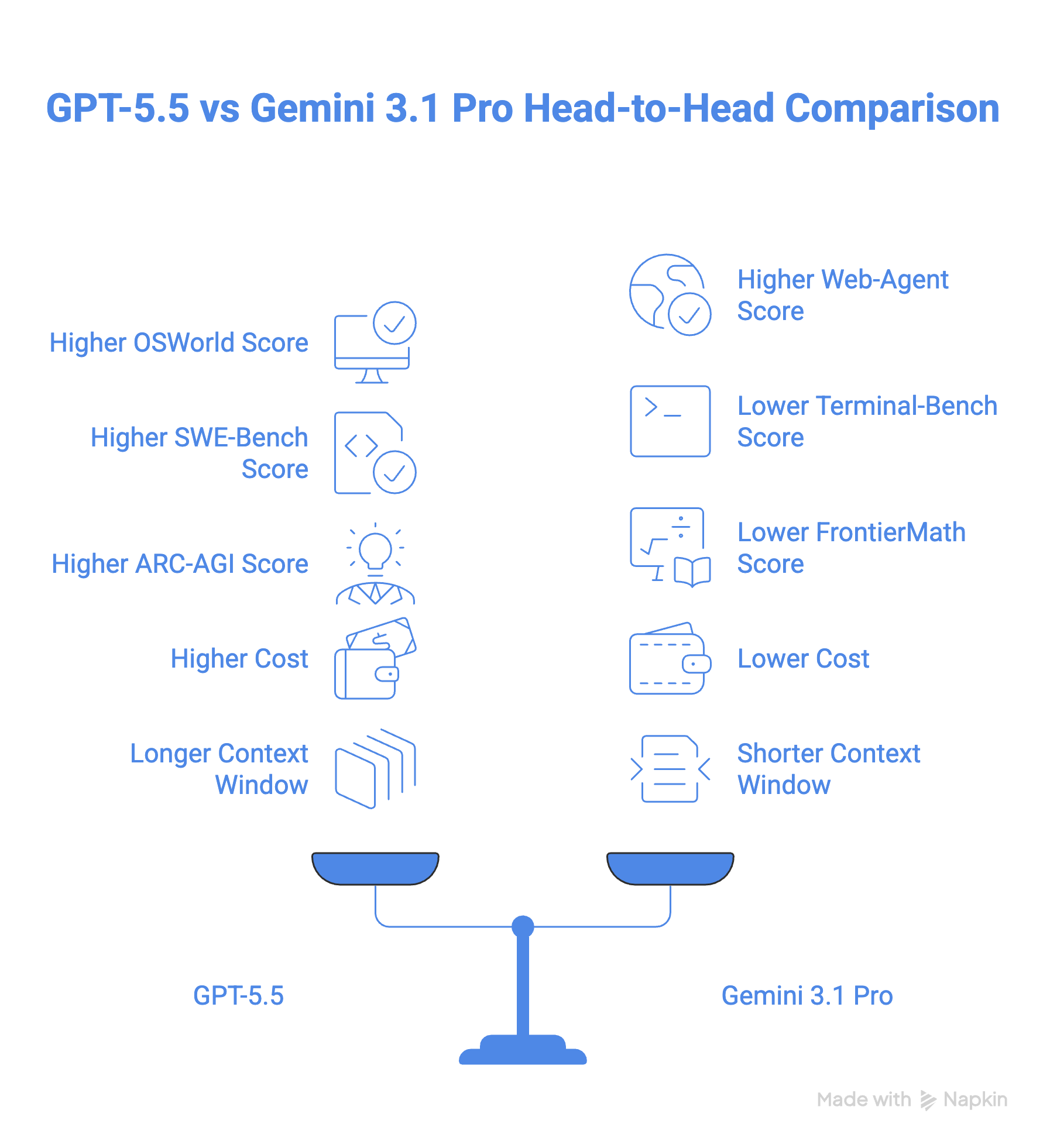
GPT-5.5 meraih 78,7% pada tolok ukur OSWorld-Verified untuk penggunaan komputer, meski tidak ada skor Gemini publik untuk dibandingkan. Dalam praktiknya, kemampuan penggunaan komputer GPT-5.5 diimplementasikan dalam aplikasi Codex, yang dapat menavigasi dan menguji situs web. Google menawarkan fungsi serupa melalui aplikasinya, Antigravity.
Ketika berbicara tentang tugas web-agent, gambarnya menjadi lebih menarik. Gemini 3.1 Pro unggul tipis dengan 85,9% pada BrowseComp dibanding 84,4% milik GPT-5.5, dan juga berkinerja lebih baik pada MCP Atlas (tolok ukur yang menguji penggunaan alat di 36 server MCP), meraih 78,2% dibanding 75,3% milik GPT-5.5.
Meski begitu, GPT-5.5 membalas pada Toolathon, yang memaparkan lebih dari 600 alat dunia nyata ke model, dengan skor 55,6% dibanding 48,8% milik Gemini. GPT-5.5 juga memimpin pada Artificial Analysis Agentic Index di mana Gemini 3.1 Pro tertinggal signifikan, seperti terlihat pada grafik di bawah.
Dalam hal coding, GPT-5.5 mengalahkan Gemini 3.1 Pro dengan skor 58,6% pada SWE-Bench Pro dan 82,7% pada Terminal-Bench 2.0, dibanding 54,2% dan 68,5% milik Gemini 3.1 Pro. Terutama pada Terminal-Bench 2.0, GPT-5.5 memimpin dengan margin besar.
GPT-5.5 memimpin pada Artificial Analysis Coding Index dengan Gemini 3.1 Pro tepat di belakangnya.
Pada ARC-AGI-2, yang mengukur kemampuan model untuk belajar dan memecahkan masalah tanpa pelatihan sebelumnya, GPT-5.5 mengalahkan Gemini 3.1 Pro dengan selisih hampir 8 poin (85,0% vs 77,1%).
GPT-5.5 juga memimpin pada matematika tingkat lanjut dengan selisih 18 poin dibanding Gemini 3.1 Pro sebagaimana diukur oleh tolok ukur FrontierMath, yang menguji kemampuan penalaran model pada level pakar.
Gemini 3.1 Pro berharga $2 per 1M token input dan $12 per 1M token output. GPT-5.5 mulai pada tarif yang jauh lebih tinggi, yaitu $5 untuk 1M token input dan $30 untuk 1M token output (dan enam kali lipat untuk model Pro). Ini membuat GPT 5.5 lebih dari dua kali lebih mahal daripada Gemini 3.1 Pro.
GPT-5.5 dan Gemini 3.1 Pro sama-sama memiliki jendela konteks 1 juta. Namun, GPT 5.5 menawarkan 128 K token output, dibanding 65K milik Gemini.
Ini membawa kita pada pertanyaan: model mana yang sebaiknya dipilih.

GPT-5.5 lebih kuat di atas kertas, dan bagi sebagian besar pengembang, kemungkinan besar juga demikian dalam praktik, terutama jika pekerjaan Anda berada di lingkungan terminal atau menggunakan matematika kompleks. Pembangunan ulang dari dasar terbayar: ini bukan model yang “ditambal” agar pas, dan kesenjangan tolok ukur pada Terminal-Bench 2.0 dan FrontierMath menjelaskannya.
Namun “lebih kuat” tidak selalu berarti “lebih cocok untuk Anda.” Dengan harga 2,5 kali lipat dari Gemini 3.1 Pro, GPT-5.5 benar-benar komitmen anggaran, dan argumen efisiensi token hanya berlaku jika alur kerja Anda cukup panjang untuk mendapatkan manfaatnya.
Gemini 3.1 Pro bukan juara kedua di sini. Ini adalah model yang kompetitif, memimpin pada BrowseComp, MCP Atlas, dan GPQA Diamond, dan penanganan video serta audio native-nya masih selangkah lebih maju dibanding apa yang ditawarkan GPT-5.5 secara native.
Langkah yang lebih cerdas bagi sebagian besar tim mungkin bukan pilihan biner: gunakan Gemini 3.1 Pro sebagai andalan untuk tugas ber-volume tinggi atau sarat media, dan hadirkan GPT-5.5 saat margin benar-benar penting. Pendekatan hibrida itu memberi Anda yang terbaik dari keduanya tanpa harus membayar harga frontier di seluruh lini.
Jika Anda ingin belajar membangun aplikasi bertenaga AI menggunakan LLM, prompt, chain, dan agent di LangChain, saya sangat merekomendasikan mengikuti kursus Developing LLM Applications with LangChain kami.
Belajar AI bersama DataCamp!
Kursus
Kursus
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
