Courses
Working with the OpenAI API
3 ชม.
142.5K
OpenAI เพิ่งเปิดตัวโมเดลฐานที่ฝึกใหม่ครั้งแรกนับตั้งแต่ GPT-4.5 ฟังดูขัดแย้งเล็กน้อย แต่ GPT-5 และรุ่นถัด ๆ มาล้วนเป็นการอัปเดตแบบค่อยเป็นค่อยไป
ครั้งนี้ต่างออกไป: โมเดลถูกสร้างใหม่ทั้งหมดเพื่อเวิร์กโฟลว์แบบเอเจนต์ โดยทำผลงานได้โดดเด่นในสองเกณฑ์ชี้วัดสำคัญที่นักพัฒนาสนใจมากที่สุด
ในบทความนี้ ฉันจะเปรียบเทียบ GPT-5.5 รุ่นใหม่กับ Gemini 3.1 Pro เพื่อช่วยตัดสินใจว่าแบบใดเหมาะกับคุณ เราจะดูทั้งเกณฑ์วัด ราคา และกรณีการใช้งานต่าง ๆ
GPT-5.5 คือโมเดล Omnimodal แฟลกชิปล่าสุดของ OpenAI โค้ดเนม “Spud” ไม่ใช่งานจูนละเอียดจากโมเดลก่อนหน้า แต่ถูกสร้างใหม่ตั้งแต่ต้นเพื่อการดำเนินงานแบบอัตโนมัติ ทำงานหลายงานพร้อมกัน โดยแทบไม่ต้องคอยกำกับ
GPT-5.5 มาพร้อม 3 เวอร์ชัน:
ดูรายละเอียดเพิ่มเติมในบทความ OpenAI GPT-5.5 และการเปรียบเทียบของเรา Claude Opus 4.7 vs GPT-5.5
คุณลักษณะและความสามารถหลักของ GPT-5.5 ได้แก่:
หนึ่งในจุดเด่นคือการปรับปรุงงานบริบทยาวช่วง 512K ถึง 1M อย่างมาก ผลงานเพิ่มขึ้นมากกว่าสองเท่าจาก 36.6% ใน GPT 5.4 เป็น 74.0% ใน GPT 5.5
โมเดลนี้ยังแข็งแกร่งที่สุดในด้านคณิตศาสตร์ ขณะนี้ บน FrontierMath ชั้น 4 GPT 5.5 ได้ 35.4% และ GPT 5.5 Pro ดันขึ้นไปที่ 39.6% เพื่อเปรียบเทียบ GPT 5.4 ได้ 27.1% Claude Opus 4.7 ได้ 22.9% และ Gemini 3.1 Pro ได้ 16.7%
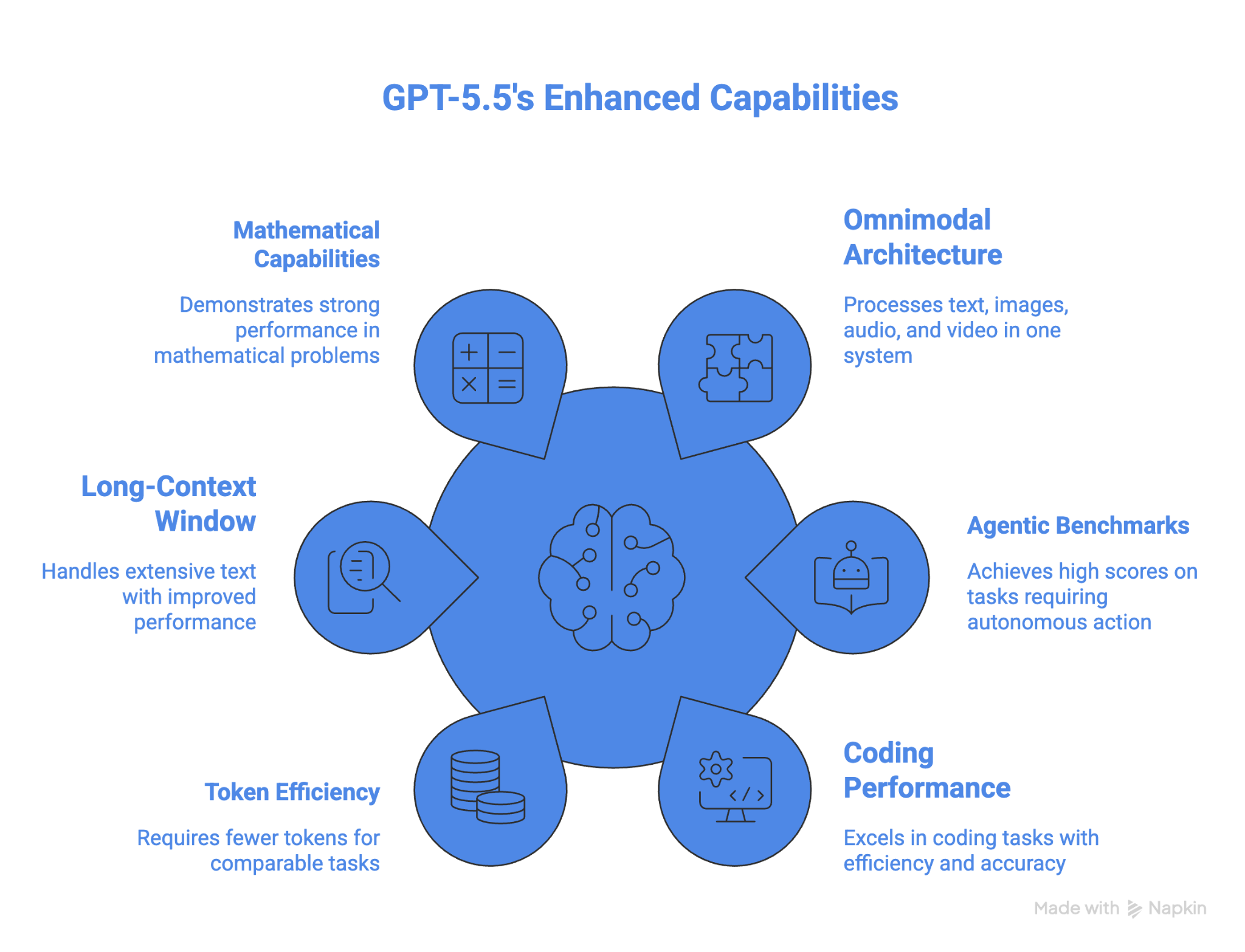
ผลงานของ GPT-5.5 บน OSWorld-Verified ทำให้เป็นโมเดลที่ดีที่สุดสำหรับการใช้งานคอมพิวเตอร์ ในบรรดาโมเดลที่มีการรายงานผลเกณฑ์นี้ นอกจากนี้ยังเหนือกว่าโมเดลอื่นทั้งหมดในคณิตศาสตร์ระดับสูง ประสิทธิภาพโทเค็นก็เป็นข้อได้เปรียบสำหรับงานเอเจนต์ที่ทำงานยาว
ด้านข้อเสีย GPT-5.5 มีราคาแพงกว่ารุ่นก่อน โดยคิด $5 ต่อหนึ่งล้านโทเค็นขาเข้า และ $30 ต่อหนึ่งล้านโทเค็นขาออก บริษัทระบุว่าอาจคุ้มกว่าเพราะใช้โทเค็นมีประสิทธิภาพขึ้น แต่จะจริงหรือไม่ขึ้นกับเวิร์กโฟลว์ของคุณเอง
Gemini 3.1 Pro คือโมเดลแฟลกชิปรุ่นล้ำหน้าของ Google ที่สร้างบนสถาปัตยกรรม Mixture-of-Experts (MoE) ออกแบบมาเพื่อมอบประสิทธิภาพมัลติโมดัลและการให้เหตุผลที่แข็งแกร่ง ในราคาที่แข่งขันได้
สำหรับการเปรียบเทียบกับโมเดลแนวหน้าล่าสุดของ Anthropic อ่านบล็อกของเราเรื่อง Claude Opus 4.7 vs Gemini 3.1 Pro
คุณลักษณะและความสามารถหลักของ Gemini 3.1 Pro ได้แก่:
มัลติโมดัลโดยกำเนิด รองรับข้อความและรูปภาพ เสียง วิดีโอ และไฟล์ PDF
ระบบคิดสามระดับ ได้แก่ low, medium และ high
หน้าต่างบริบท 1M โทเค็น เอาต์พุตสูงสุด 65K โทเค็น และรับเสียงได้ 8.4 ชั่วโมงหรือวิดีโอเต็ม 1 ชั่วโมงในพรอมต์เดียว
ได้ 77.1% บน ARC-AGI-2 แสดงความสามารถด้านการให้เหตุผลเชิงนามธรรมจากภาพที่แข็งแกร่ง มากกว่าสองเท่าของ Gemini 3 Pro ที่ได้ 31.1%
ได้ 33.5% บน APEX-Agents ที่วัดงานมืออาชีพระยะยาว เกือบสองเท่าของ Gemini 3 Pro ที่ได้ 18.4%
ในบทเรียน Building with Gemini 3.1 Pro เราครอบคลุมวิธีสร้างแอปพร้อมใช้งานจริงด้วย Gemini 3.1 Pro และ Gemini CLI
Gemini 3.1 Pro โดดเด่นในงานให้เหตุผลจากภาพที่ซับซ้อน และได้เปรียบคู่แข่งด้วยการออกแบบมัลติโมดัลโดยกำเนิด ที่จัดการข้อความ รูปภาพ วิดีโอ และเสียงในพรอมต์เดียว จับคู่กับหน้าต่างบริบทขนาดยักษ์ 1M โทเค็น แล้วคุณสามารถวิเคราะห์โค้ดเบสทั้งก้อน ไฟล์ PDF ยาว ๆ หรือวิดีโอหลายชั่วโมงได้ในครั้งเดียว Gemini 3.1 Pro ยังเป็นขุมพลังของ Nano Banana 2 และ Veo 3.1 สำหรับเอาต์พุตภาพและวิดีโอ
ข้อเสียคือ Gemini 3.1 Pro ให้เอาต์พุตได้ 65K โทเค็น ซึ่งอาจไม่พอสำหรับงานเอเจนต์ที่รันยาว หมายความว่าอาจไม่เหมาะกับการสร้างเอกสารยาวและลูปเอเจนต์ที่ผลิตเอาต์พุตขนาดใหญ่
เรียนรู้การสร้างแดชบอร์ดการเงินด้วย Gemini 3 และการทดสอบเบราว์เซอร์ด้วย AI จากบทเรียน Google Antigravity ของเรา
ตามดัชนี Artificial Analysis Intelligence GPT 5.5 คือโมเดลโดยรวมที่ดีที่สุดในปัจจุบัน และยังนำบนดัชนีด้านการเขียนโค้ดและเอเจนต์ของพวกเขาด้วย
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
วันเปิดตัว |
23 เมษายน 2026 |
19 กุมภาพันธ์ 2026 |
|
สถาปัตยกรรม |
Omnimodal (แบบรวม) |
MoE (Transformer) |
|
หน้าต่างบริบท |
1M โทเค็น |
1M โทเค็น |
|
เอาต์พุตสูงสุด |
128K โทเค็น |
65K โทเค็น |
|
OSWorld |
78.7% |
|
|
BrowseComp |
84.4% |
85.9% |
|
ARC-AGI-2 |
85.0% |
77.1% |
|
GPQA Diamond |
93.6% |
94.3% |
|
Terminal-Bench 2.0 |
82.7% |
68.5% |
|
FrontierMath ชั้น 4 |
35.4% (Pro 39.6%) |
16.7% |
|
SWE-Bench Pro |
58.6% |
54.2% |
|
ราคา API (ขาเข้า/ขาออก ต่อ 1M) |
$5/$30 (Pro $30/$180) |
$2/$12 |
มาลองดูกรณีใช้งานที่แตกต่างกันสักเล็กน้อย
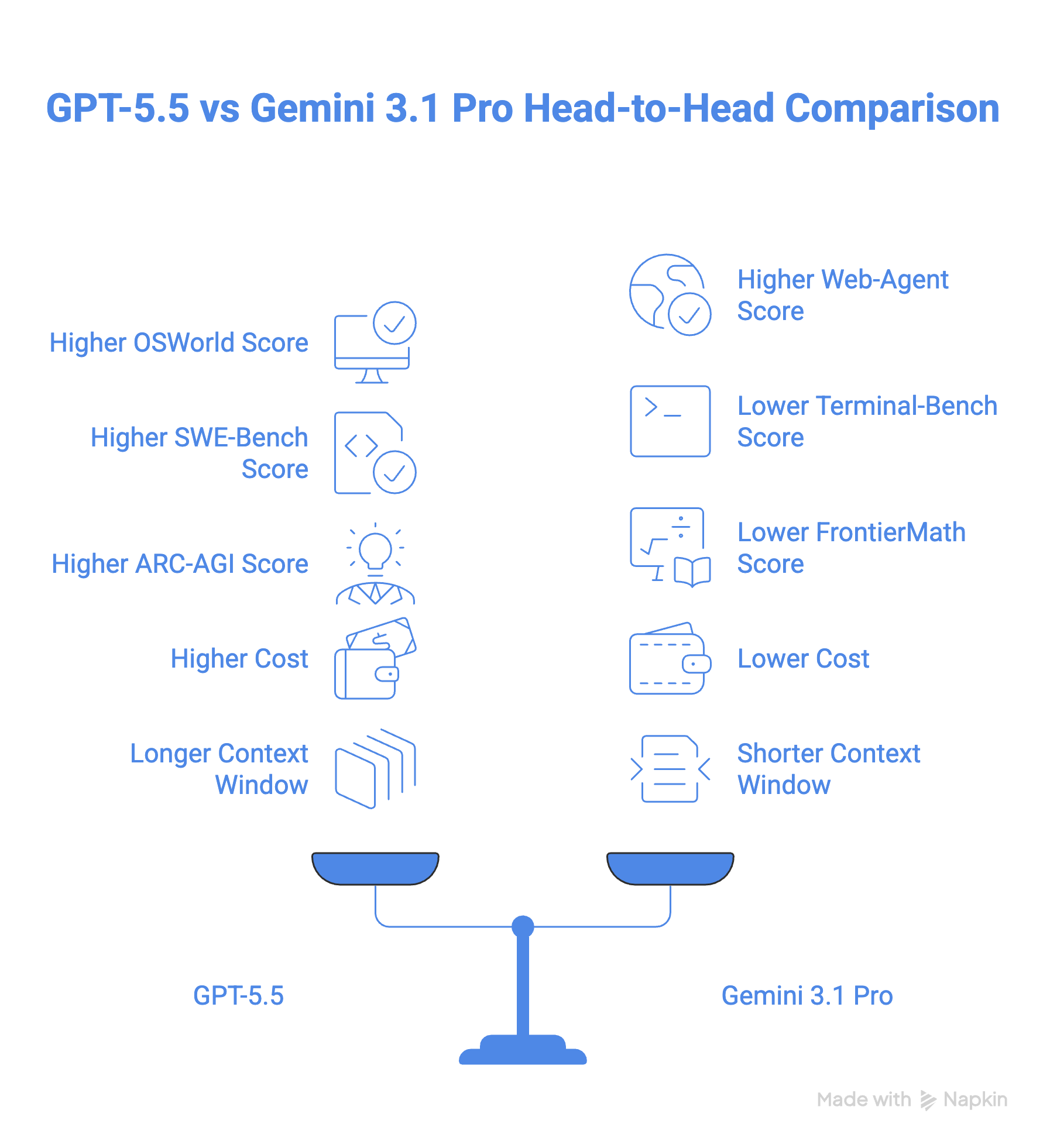
GPT-5.5 ได้คะแนน 78.7% บนเกณฑ์ OSWorld-Verified สำหรับการใช้งานคอมพิวเตอร์ แม้ไม่มีคะแนนสาธารณะของ Gemini ให้เปรียบเทียบ ในทางปฏิบัติ ความสามารถใช้งานคอมพิวเตอร์ของ GPT-5.5 ถูกรวมไว้ในแอป Codex ซึ่งสามารถนำทางและทดสอบเว็บไซต์ได้ ขณะที่ Google มีความสามารถคล้ายกันผ่านแอป Antigravity
เมื่อเป็นงานตัวแทนบนเว็บ ภาพรวมเริ่มน่าสนใจขึ้น Gemini 3.1 Pro นำหน้าเล็กน้อยด้วย 85.9% บน BrowseComp เทียบกับ 84.4% ของ GPT-5.5 และยังทำได้ดีกว่าบน MCP Atlas (เกณฑ์ที่ทดสอบการใช้เครื่องมือข้ามเซิร์ฟเวอร์ MCP 36 ตัว) โดยได้ 78.2% เทียบกับ 75.3% ของ GPT-5.5
อย่างไรก็ดี GPT-5.5 โต้กลับบน Toolathon ซึ่งโยนเครื่องมือจริงกว่า 600 รายการให้โมเดล โดยได้ 55.6% เทียบกับ 48.8% ของ Gemini GPT-5.5 ยังนำบนดัชนี Artificial Analysis Agentic ที่ Gemini 3.1 Pro ตามหลังอยู่มาก ดังแสดงในกราฟด้านล่าง
ด้านการเขียนโค้ด GPT-5.5 ชนะ Gemini 3.1 Pro ด้วยคะแนน 58.6% บน SWE-Bench Pro และ 82.7% บน Terminal-Bench 2.0 เทียบกับ 54.2% และ 68.5% ของ Gemini 3.1 Pro โดยเฉพาะบน Terminal-Bench 2.0 GPT-5.5 นำแบบทิ้งห่าง
GPT-5.5 นำบน Artificial Analysis Coding Index โดยมี Gemini 3.1 Pro ตามมาติด ๆ
บน ARC-AGI-2 ซึ่งวัดความสามารถของโมเดลในการเรียนรู้และแก้ปัญหาโดยไม่ผ่านการฝึกมาก่อน GPT-5.5 เอาชนะ Gemini 3.1 Pro ไปเกือบ 8 คะแนน (85.0% เทียบกับ 77.1%)
GPT-5.5 ยังนำในคณิตศาสตร์ขั้นสูงด้วยช่องว่าง 18 คะแนนเมื่อเทียบกับ Gemini 3.1 Pro ตามเกณฑ์ FrontierMath ซึ่งทดสอบความสามารถในการให้เหตุผลระดับผู้เชี่ยวชาญ
Gemini 3.1 Pro มีค่าใช้จ่าย $2 ต่อ 1M โทเค็นขาเข้า และ $12 ต่อ 1M โทเค็นขาออก ขณะที่ GPT-5.5 เริ่มที่แพงกว่ามาก โดยคิด $5 ต่อ 1M โทเค็นขาเข้า และ $30 ต่อ 1M โทเค็นขาออก (และรุ่น Pro แพงกว่านั้นหกเท่า) ทำให้ GPT 5.5 มีราคามากกว่าสองเท่าของ Gemini 3.1 Pro
ทั้ง GPT-5.5 และ Gemini 3.1 Pro มีหน้าต่างบริบท 1M แต่ GPT 5.5 ให้เอาต์พุต 128K โทเค็น เทียบกับ 65K ของ Gemini
สรุปแล้ว ควรเลือกโมเดลใดในสองตัวนี้

บนกระดาษ GPT-5.5 แข็งแกร่งกว่า และสำหรับนักพัฒนาส่วนใหญ่ ในทางปฏิบัติก็น่าจะใช่ โดยเฉพาะหากงานอยู่ในสภาพแวดล้อมเทอร์มินัลหรือใช้คณิตศาสตร์ซับซ้อน การสร้างใหม่ตั้งแต่ต้นเห็นผลชัดเจน: นี่ไม่ใช่โมเดลที่อุดช่องโหว่เอาไว้เฉย ๆ และช่องว่างบน Terminal-Bench 2.0 กับ FrontierMath ก็ยืนยันได้ชัด
แต่ “แข็งแกร่งกว่า” ไม่ได้แปลว่า “เหมาะกับคุณมากกว่า” เสมอไป ที่ราคาแพงกว่า Gemini 3.1 Pro ราว 2.5 เท่า GPT-5.5 เป็นภาระงบประมาณจริง และข้อโต้แย้งเรื่องประสิทธิภาพโทเค็นจะจริงก็ต่อเมื่อเวิร์กโฟลว์ของคุณยาวพอจะได้ประโยชน์จากมัน
Gemini 3.1 Pro ไม่ใช่ตัวรองที่นี่ มันเป็นโมเดลที่แข่งขันได้ นำบน BrowseComp, MCP Atlas และ GPQA Diamond และความสามารถจัดการวิดีโอและเสียงแบบเนทีฟยังคงนำหน้าสิ่งที่ GPT-5.5 มีให้แบบเนทีฟ
กลยุทธ์ที่ฉลาดสำหรับหลายทีมอาจไม่ใช่ตัวเลือกแบบทวิภาคี: ใช้ Gemini 3.1 Pro เป็นม้าทำงานสำหรับงานปริมาณมากหรือสื่อหนัก และเรียกใช้ GPT-5.5 ในจุดที่ส่วนต่างมีความหมาย วิธีผสมผสานนี้จะได้ข้อดีทั้งสองด้าน โดยไม่ต้องจ่ายราคาโมเดลแนวหน้าทุกที่
หากต้องการเรียนรู้การสร้างแอปพลิเคชันที่ขับเคลื่อนด้วย AI โดยใช้ LLM, พรอมต์, เชน และเอเจนต์ใน LangChain ขอแนะนำหลักสูตร Developing LLM Applications with LangChain ของเรา
เรียนรู้ AI กับ DataCamp!
Courses
Courses
Courses