
Cours
Travailler avec l'API OpenAI
3 h
141.6K
OpenAI vient de publier son premier modèle de base réentraîné depuis GPT-4.5. Cela peut sembler contre-intuitif, mais GPT-5 et ses autres successeurs étaient des mises à jour incrémentales.
Celui-ci est différent : il a été repensé de fond en comble pour les workflows agentiques, avec d’excellents résultats sur deux benchmarks clés qui comptent le plus pour les développeurs.
Dans cet article, je compare le tout nouveau GPT-5.5 à Gemini 3.1 Pro afin de vous aider à choisir le plus adapté. Nous passerons en revue les benchmarks, les coûts et les cas d’usage.
GPT-5.5 est le dernier modèle amiral omnimodal d’OpenAI, nom de code « Spud ». Ce n’est pas un affinement d’un modèle précédent, mais un modèle reconstruit de zéro pour exécuter de manière autonome plusieurs tâches avec un minimum d’assistance.
GPT-5.5 est proposé en trois variantes :
Découvrez-en plus sur le modèle dans notre article OpenAI GPT-5.5 et dans notre comparaison Claude Opus 4.7 vs GPT-5.5.
Les principales fonctionnalités et capacités de GPT-5.5 sont :
L’un des points forts est la nette progression sur le long contexte entre 512K et 1M : les performances ont plus que doublé, passant de 36,6 % sur GPT-5.4 à 74,0 % sur GPT-5.5.
Le modèle est également le plus performant en mathématiques. Sur FrontierMath Tier 4, GPT-5.5 obtient 35,4 %, et GPT-5.5 Pro monte à 39,6 %. À titre de comparaison, GPT-5.4 atteignait 27,1 %, Claude Opus 4.7 22,9 % et Gemini 3.1 Pro 16,7 %.
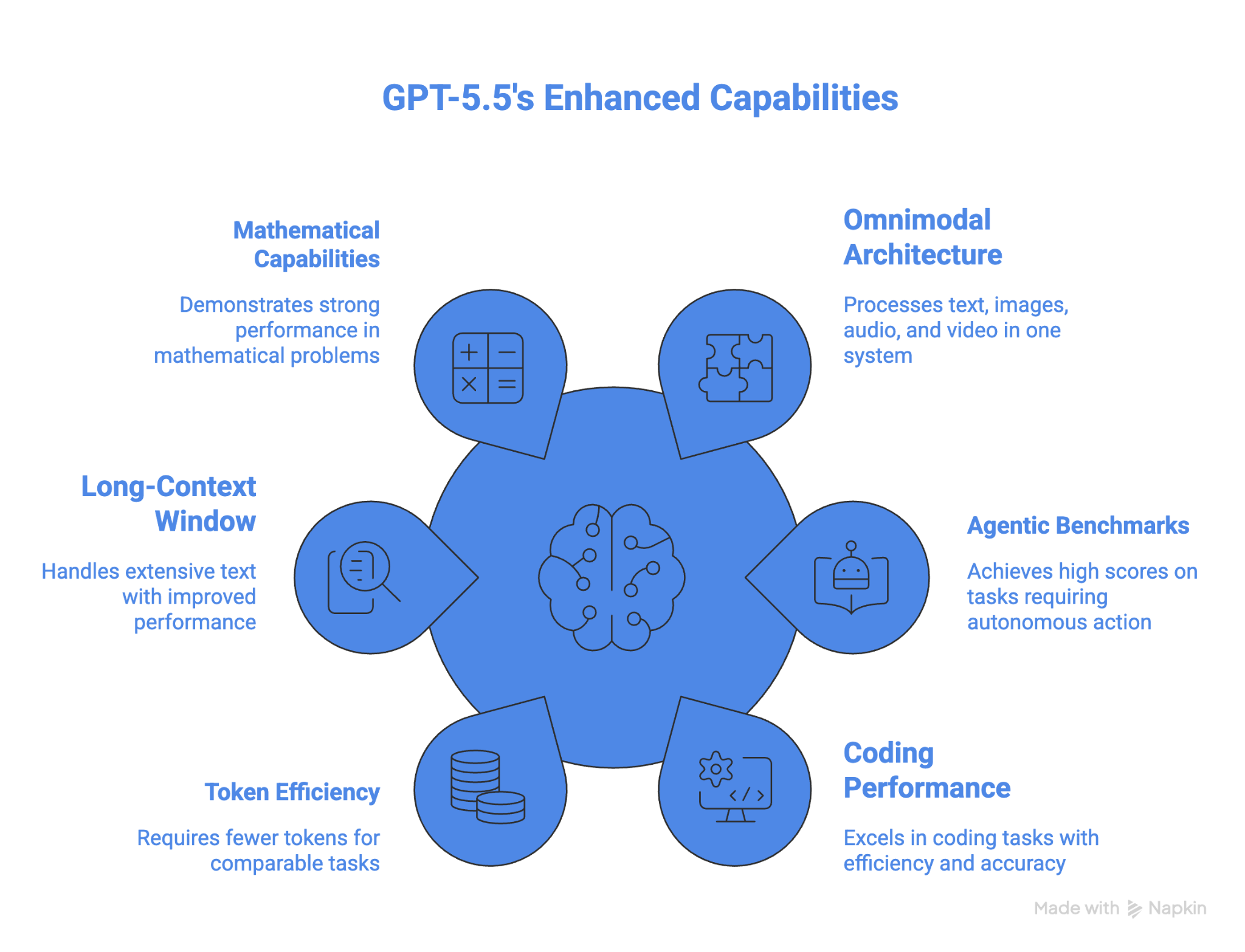
La performance de GPT-5.5 sur OSWorld-Verified en fait le meilleur modèle pour l’usage ordinateur parmi ceux ayant publié des résultats sur ce benchmark. Il surpasse également tous les autres modèles en mathématiques avancées. L’efficacité en jetons est un autre atout pour les tâches agentiques de longue durée.
Côté inconvénients, GPT-5.5 est plus cher que le modèle précédent, avec 5 $ pour un million de jetons en entrée et 30 $ pour un million de jetons en sortie. OpenAI indique que cela pourrait revenir moins cher grâce à l’efficacité en jetons, mais cela dépendra de vos workflows.
Gemini 3.1 Pro est l’actuel modèle amiral de Google, bâti sur une architecture Mixture-of-Experts (MoE). Google l’a conçu pour offrir de solides performances multimodales et en raisonnement à un prix compétitif.
Pour une comparaison avec le dernier modèle de pointe d’Anthropic, consultez notre article Claude Opus 4.7 vs Gemini 3.1 Pro.
Voici les fonctionnalités et capacités clés de Gemini 3.1 Pro :
Nativement multimodal avec prise en charge du texte et des images, ainsi que de l’audio, de la vidéo et des PDF.
Système de raisonnement à trois niveaux proposant des niveaux low, medium et high.
Fenêtre de contexte d’1 million de jetons, avec 65K jetons max en sortie, et acceptant 8,4 heures d’audio ou une heure complète de vidéo dans une seule invite.
77,1 % sur ARC-AGI-2, démontrant un fort raisonnement visuel abstrait, plus de deux fois supérieur aux 31,1 % de Gemini 3 Pro.
33,5 % sur APEX-Agents qui mesure des tâches professionnelles de longue durée, soit près du double des 18,4 % de Gemini 3 Pro.
Dans notre tutoriel Building with Gemini 3.1 Pro, nous expliquons comment créer une application prête pour la production avec Gemini 3.1 Pro et la Gemini CLI.
Gemini 3.1 Pro excelle sur les tâches de raisonnement visuel complexes et se distingue par sa conception nativement multimodale, qui gère texte, images, vidéo et audio dans une seule invite. Associé à une vaste fenêtre de contexte d’1 million de jetons, vous pouvez analyser des bases de code entières, de longs PDF ou des heures de vidéo d’un seul tenant. Gemini 3.1 Pro alimente également Nano Banana 2 et Veo 3.1 pour la génération d’images et de vidéos.
À l’inverse, Gemini 3.1 Pro est limité à 65K jetons en sortie, ce qui peut s’avérer insuffisant pour des tâches agentiques longues. Il sera donc moins adapté à la génération de documents étendus et aux boucles agentiques produisant de gros volumes de texte.
Apprenez à créer un tableau de bord finance avec Gemini 3 et des tests navigateur pilotés par l’IA dans notre tutoriel Google Antigravity.
Selon l’Artificial Analysis Intelligence Index, GPT-5.5 est actuellement le meilleur modèle global, et il prend aussi la tête de leurs index code et agentique.
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
Date de sortie |
23 avril 2026 |
19 février 2026 |
|
Architecture |
Omnimodale (unifiée) |
MoE (Transformer) |
|
Fenêtre de contexte |
1 million de jetons |
1 million de jetons |
|
Sortie max |
128K jetons |
65K jetons |
|
OSWorld |
78,7 % |
|
|
BrowseComp |
84,4 % |
85,9 % |
|
ARC-AGI-2 |
85,0 % |
77,1 % |
|
GPQA Diamond |
93,6 % |
94,3 % |
|
Terminal-Bench 2.0 |
82,7 % |
68,5 % |
|
FrontierMath Tier 4 |
35,4 % (Pro 39,6 %) |
16,7 % |
|
SWE-Bench Pro |
58,6 % |
54,2 % |
|
Tarifs API (entrée/sortie pour 1M) |
5 $/30 $ (Pro 30 $/180 $) |
2 $/12 $ |
Voyons quelques cas d’usage concrets.
GPT-5.5 obtient 78,7 % sur le benchmark OSWorld-Verified pour l’usage ordinateur, même s’il n’y a pas de score public pour Gemini à comparer. En pratique, l’usage ordinateur de GPT-5.5 est intégré à l’application Codex, où il peut naviguer et tester des sites web. Google propose une fonctionnalité similaire via son application Antigravity.
Sur les tâches d’agents web, l’écart devient intéressant. Gemini 3.1 Pro prend une courte avance avec 85,9 % sur BrowseComp contre 84,4 % pour GPT-5.5, et il fait mieux sur MCP Atlas (un benchmark qui évalue l’usage d’outils à travers 36 serveurs MCP), avec 78,2 % contre 75,3 % pour GPT-5.5.
Cela dit, GPT-5.5 reprend l’avantage sur Toolathon, qui soumet un modèle à plus de 600 outils réels, avec 55,6 % contre 48,8 % pour Gemini. GPT-5.5 mène aussi sur l’Artificial Analysis Agentic Index, où Gemini 3.1 Pro est nettement derrière, comme le montre le graphique ci-dessous.
En programmation, GPT-5.5 devance Gemini 3.1 Pro avec 58,6 % sur SWE-Bench Pro et 82,7 % sur Terminal-Bench 2.0, contre 54,2 % et 68,5 % pour Gemini 3.1 Pro. En particulier sur Terminal-Bench 2.0, l’avance de GPT-5.5 est très nette.
GPT-5.5 est en tête sur l’Artificial Analysis Coding Index, juste devant Gemini 3.1 Pro.
Sur ARC-AGI-2, qui mesure la capacité d’un modèle à apprendre et résoudre des problèmes sans entraînement préalable, GPT-5.5 surpasse Gemini 3.1 Pro d’environ 8 points (85,0 % vs 77,1 %).
GPT-5.5 prend aussi la tête en mathématiques avancées, avec 18 points d’écart par rapport à Gemini 3.1 Pro, selon le benchmark FrontierMath qui évalue la capacité de raisonnement à un niveau expert.
Gemini 3.1 Pro coûte 2 $ par million de jetons en entrée et 12 $ par million de jetons en sortie. GPT-5.5 démarre nettement plus haut, à 5 $ pour 1M de jetons en entrée et 30 $ pour 1M en sortie (et six fois plus pour la version Pro). GPT-5.5 est donc plus de deux fois plus cher que Gemini 3.1 Pro.
GPT-5.5 et Gemini 3.1 Pro disposent tous deux d’une fenêtre de contexte d’1 million. En revanche, GPT-5.5 offre jusqu’à 128K jetons en sortie, contre 65K pour Gemini.
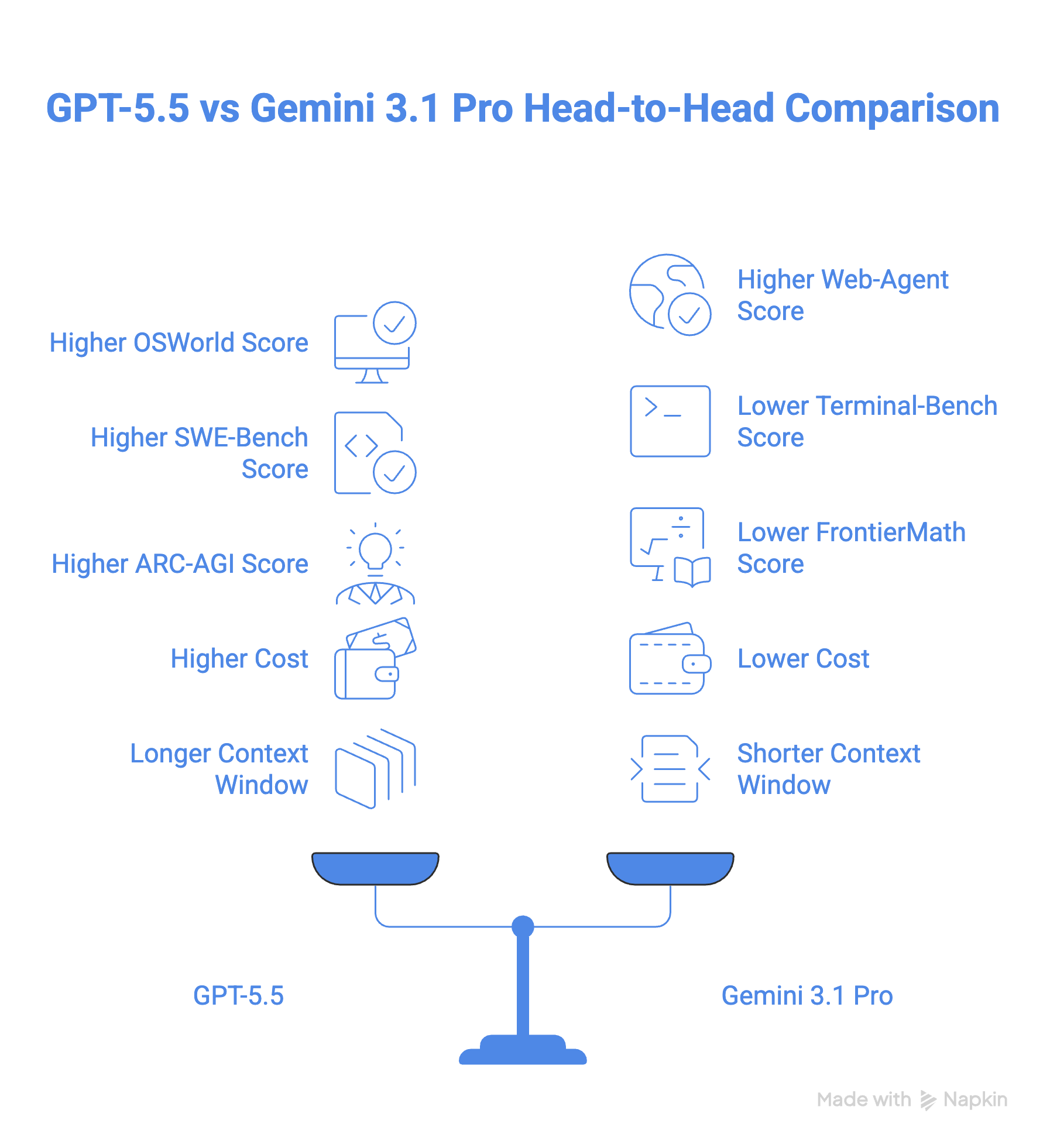
Reste à savoir lequel des deux modèles retenir.

Sur le papier, GPT-5.5 est le plus solide, et pour la plupart des développeurs, il le sera sans doute aussi en pratique, surtout si votre travail se fait en environnement terminal ou requiert des mathématiques complexes. La reconstruction en profondeur a payé : ce n’est pas un modèle rafistolé, et les écarts sur Terminal-Bench 2.0 et FrontierMath le confirment.
Mais « plus fort » ne veut pas toujours dire « mieux pour vous ». À 2,5 fois le prix de Gemini 3.1 Pro, GPT-5.5 représente un vrai engagement budgétaire, et l’argument de l’efficacité en jetons ne tient que si vos workflows sont suffisamment longs pour en bénéficier.
Gemini 3.1 Pro n’est pas un second choix. C’est un modèle compétitif, en tête sur BrowseComp, MCP Atlas et GPQA Diamond, et sa gestion native de la vidéo et de l’audio reste en avance sur ce que GPT-5.5 propose nativement.
Pour la plupart des équipes, la stratégie gagnante n’est probablement pas un choix binaire : utilisez Gemini 3.1 Pro comme cheval de bataille pour les tâches à grand volume ou riches en médias, et mobilisez GPT-5.5 là où l’écart de performance compte vraiment. Cette approche hybride vous offre le meilleur des deux mondes sans payer le prix des modèles de pointe partout.
Si vous souhaitez apprendre à créer des applications d’IA avec des LLM, des prompts, des chaînes et des agents sous LangChain, nous vous recommandons vivement notre cours Developing LLM Applications with LangChain.
Apprenez l’IA avec DataCamp !
Cours
Cours
Cours
blog
Kurtis Pykes
9 min
blog
blog
Lynn Heidmann
Tutoriel
Tutoriel
Matt Crabtree

