course
Praca z API OpenAI
3 godz.
141.9K
OpenAI właśnie wydało pierwszy od czasu GPT-4.5 ponownie wytrenowany model bazowy. Brzmi to paradoksalnie, ale GPT-5 i wszyscy jego następcy były jedynie aktualizacjami przyrostowymi.
Ten jest inny: został zbudowany od podstaw z myślą o przepływach pracy agentowych, z wysoką wydajnością w dwóch kluczowych benchmarkach, które najbardziej liczą się dla deweloperów.
W tym artykule porównam nowo wydany GPT-5.5 z Gemini 3.1 Pro, aby pomóc zdecydować, który będzie dla Państwa najlepszy. Przyjrzymy się benchmarkom, kosztom i przypadkom użycia.
GPT-5.5 to najnowszy flagowy model omnimodalny OpenAI, o kryptonimie „Spud”. Nie jest to dostrajanie wcześniejszego modelu, lecz konstrukcja zbudowana od podstaw do autonomicznego wykonywania wielu zadań przy minimalnym nadzorze.
GPT-5.5 jest dostępny w trzech wariantach:
Więcej o modelu można przeczytać w naszym artykule OpenAI GPT-5.5 oraz w porównaniu Claude Opus 4.7 vs GPT-5.5.
Najważniejsze cechy i możliwości GPT-5.5 to:
Jedną z największych nowości jest wyraźna poprawa w pracy na długim kontekście między 512 K a 1 M; wydajność ponad dwukrotnie wzrosła z 36,6% w GPT 5.4 do 74,0% w GPT 5.5.
Model jest też obecnie najsilniejszy w matematyce. Na FrontierMath Tier 4 GPT 5.5 osiąga 35,4%, a GPT 5.5 Pro podnosi wynik do 39,6%. Dla porównania: GPT 5.4 uzyskał 27,1%, Claude Opus 4.7 — 22,9%, a Gemini 3.1 Pro — 16,7%.
Wynik GPT-5.5 na OSWorld-Verified czyni go najlepszym modelem do obsługi komputera wśród tych, które opublikowały rezultaty dla tego benchmarku. Przewyższa też pozostałe modele w zaawansowanej matematyce. Efektywność tokenów to kolejna przewaga przy długotrwałych zadaniach agentowych.
Z drugiej strony GPT-5.5 jest droższy niż poprzedni model: 5 USD za milion tokenów wejściowych i 30 USD za milion tokenów wyjściowych. Firma twierdzi, że może wyjść taniej dzięki wyższej efektywności tokenów, ale zależy to od Państwa przepływów pracy.
Gemini 3.1 Pro to obecny, najnowocześniejszy flagowy model Google zbudowany w architekturze Mixture-of-Experts (MoE). Google zaprojektowało go, aby zapewniał silną wydajność multimodalną i w rozumowaniu w konkurencyjnej cenie.
Aby porównać z najnowszym modelem czołowym Anthropic, proszę przeczytać nasz wpis Claude Opus 4.7 vs Gemini 3.1 Pro.
Oto kluczowe funkcje i możliwości Gemini 3.1 Pro:
Natywnie multimodalny z obsługą tekstu i obrazów. Dźwięku, wideo i plików PDF.
Trójpoziomowy system „myślenia” oferujący poziomy low, medium i high.
Okno kontekstu 1M tokenów, z maksymalnie 65K tokenów wyjściowych oraz możliwością przyjęcia w pojedynczym promptcie 8,4 godziny audio lub pełnej godziny wideo.
77,1% na ARC-AGI-2, co pokazuje silne abstrakcyjne rozumowanie wizualne, ponad dwukrotnie przewyższające 31,1% Gemini 3 Pro.
33,5% na APEX-Agents mierzącym długohoryzontalne zadania zawodowe — prawie dwukrotnie więcej niż 18,4% Gemini 3 Pro.
W naszym samouczku Building with Gemini 3.1 Pro omawiamy, jak zbudować gotową do produkcji aplikację z użyciem Gemini 3.1 Pro i Gemini CLI.
Gemini 3.1 Pro błyszczy w złożonych zadaniach rozumowania wizualnego i ma przewagę nad konkurencją dzięki natywnie multimodalnej konstrukcji, która obsługuje tekst, obrazy, wideo i dźwięk w jednym promptcie. W połączeniu z ogromnym oknem kontekstu 1M tokenów można jednorazowo analizować całe bazy kodu, obszerne pliki PDF lub godziny materiału wideo. Gemini 3.1 Pro napędza także Nano Banana 2 i Veo 3.1 do generowania obrazów i wideo.
Minusem jest limit 65K tokenów wyjściowych w Gemini 3.1 Pro, co może nie wystarczyć przy długotrwałych zadaniach agentowych. Oznacza to, że może nie być dobrym wyborem do długiej generacji dokumentów i pętli agentowych produkujących duże wyjścia.
Z naszego samouczka Google Antigravity można się dowiedzieć, jak zbudować pulpit finansowy z Gemini 3 oraz testowanie przeglądarkowe oparte na AI.
Według Artificial Analysis Intelligence Index, GPT 5.5 to obecnie najlepszy model ogółem, a także lider ich indeksów kodowania i agentowych.
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
Data wydania |
23 kwietnia 2026 |
19 lutego 2026 |
|
Architektura |
Omnimodalna (ujednolicona) |
MoE (Transformer) |
|
Okno kontekstu |
1M tokenów |
1M tokenów |
|
Maks. wyjście |
128K tokenów |
65K tokenów |
|
OSWorld |
78,7% |
|
|
BrowseComp |
84,4% |
85,9% |
|
ARC-AGI-2 |
85,0% |
77,1% |
|
GPQA Diamond |
93,6% |
94,3% |
|
Terminal-Bench 2.0 |
82,7% |
68,5% |
|
FrontierMath Tier 4 |
35,4% (Pro 39,6%) |
16,7% |
|
SWE-Bench Pro |
58,6% |
54,2% |
|
Cennik API (wejście/wyjście za 1M) |
5 USD/30 USD (Pro 30 USD/180 USD) |
2 USD/12 USD |
Przyjrzyjmy się kilku różnym przypadkom użycia.
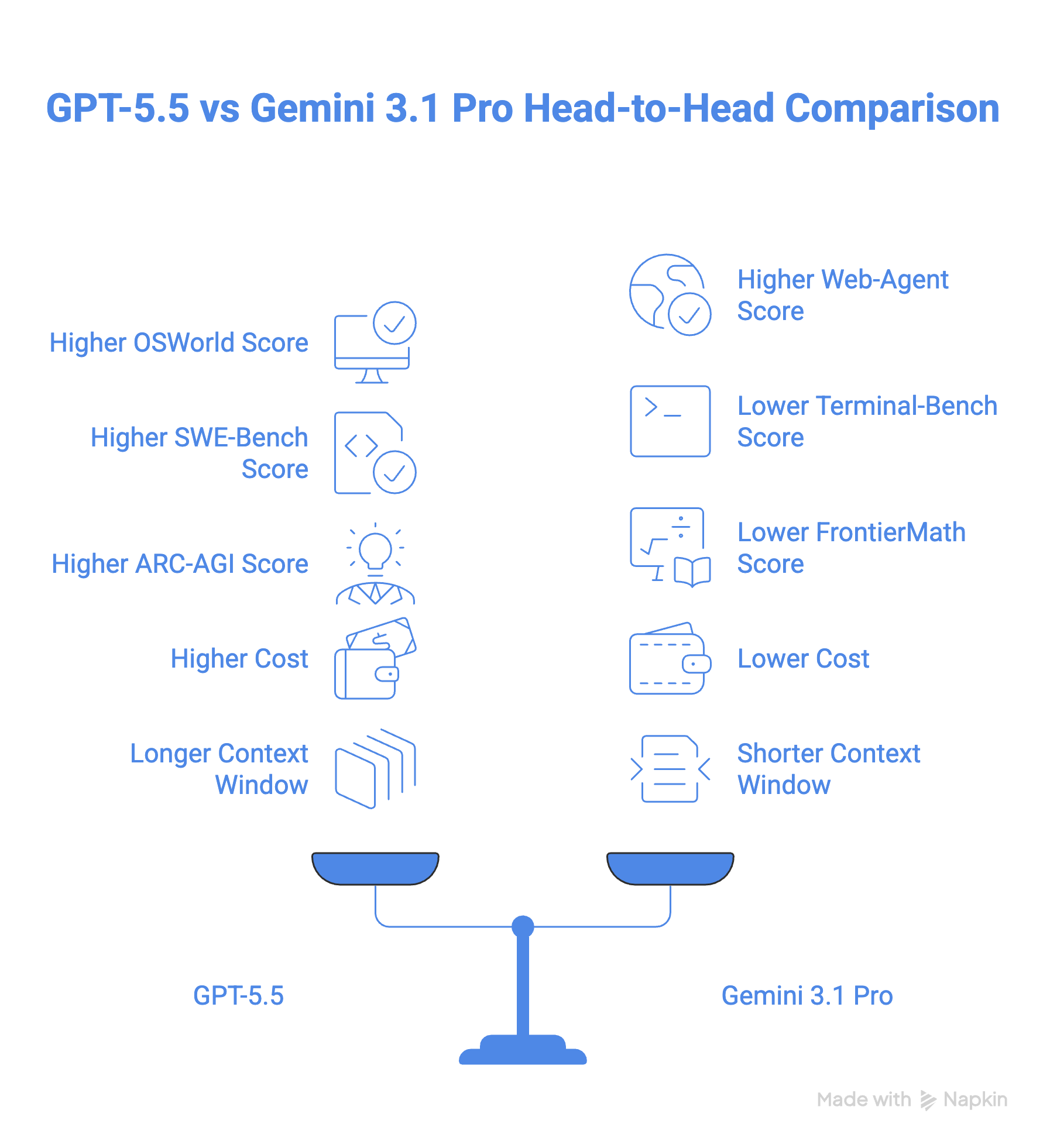
GPT-5.5 uzyskuje 78,7% w benchmarku OSWorld-Verified dotyczącym obsługi komputera, choć nie ma publicznego wyniku Gemini do porównania. W praktyce obsługa komputera przez GPT-5.5 jest wbudowana w aplikację Codex, w której potrafi nawigować i testować strony WWW. Google oferuje podobną funkcjonalność poprzez aplikację Antigravity.
Jeśli chodzi o zadania agentów sieciowych, obraz staje się ciekawszy. Gemini 3.1 Pro minimalnie wyprzedza z 85,9% na BrowseComp wobec 84,4% GPT-5.5, a także wypada lepiej na MCP Atlas (benchmark testujący korzystanie z narzędzi na 36 serwerach MCP), osiągając 78,2% wobec 75,3% GPT-5.5.
Z kolei GPT-5.5 odbija na Toolathonie, który rzuca modelowi ponad 600 narzędzi ze świata rzeczywistego — 55,6% w porównaniu z 48,8% Gemini. GPT-5.5 prowadzi też w Artificial Analysis Agentic Index, gdzie Gemini 3.1 Pro wyraźnie odstaje, co pokazuje poniższy wykres.
W kodowaniu GPT-5.5 wygrywa z Gemini 3.1 Pro, osiągając 58,6% na SWE-Bench Pro i 82,7% na Terminal-Bench 2.0, podczas gdy Gemini 3.1 Pro ma odpowiednio 54,2% i 68,5%. Zwłaszcza na Terminal-Bench 2.0 GPT-5.5 prowadzi z dużą przewagą.
GPT-5.5 prowadzi w Artificial Analysis Coding Index, a Gemini 3.1 Pro depcze mu po piętach.
W ARC-AGI-2, który mierzy zdolność modelu do uczenia się i rozwiązywania problemów bez wcześniejszego szkolenia, GPT-5.5 pokonuje Gemini 3.1 Pro o blisko 8 punktów (85,0% vs 77,1%).
GPT-5.5 prowadzi też w zaawansowanej matematyce z 18-punktową przewagą względem Gemini 3.1 Pro, mierzoną benchmarkiem FrontierMath, który testuje zdolności rozumowania na poziomie eksperckim.
Gemini 3.1 Pro kosztuje 2 USD za 1M tokenów wejściowych i 12 USD za 1M tokenów wyjściowych. GPT-5.5 startuje z wyraźnie wyższą stawką — 5 USD za 1M tokenów wejściowych i 30 USD za 1M tokenów wyjściowych (a wariant Pro sześciokrotnie więcej). To sprawia, że GPT 5.5 jest ponad dwukrotnie droższy od Gemini 3.1 Pro.
Zarówno GPT-5.5, jak i Gemini 3.1 Pro mają okno kontekstu 1M. Jednak GPT 5.5 oferuje 128 K tokenów wyjściowych w porównaniu z 65K w Gemini.
To prowadzi nas do pytania, który z tych dwóch modeli wybrać.

GPT-5.5 to na papierze silniejszy model, a dla większości deweloperów prawdopodobnie także w praktyce — zwłaszcza jeśli Państwa praca toczy się w środowiskach terminalowych lub wykorzystuje złożoną matematykę. Przebudowa od podstaw się opłaciła: to nie jest model „załatany” do formy, a różnice w benchmarkach Terminal-Bench 2.0 i FrontierMath jasno to pokazują.
Ale „silniejszy” nie zawsze znaczy „lepszy dla Państwa”. Przy cenie 2,5 raza wyższej niż Gemini 3.1 Pro, GPT-5.5 to realne zobowiązanie budżetowe, a argument o efektywności tokenów ma sens tylko wtedy, gdy przepływy pracy są na tyle długie, by na tym skorzystać.
Gemini 3.1 Pro nie jest tu „drugie w kolejności”. To konkurencyjny model, który prowadzi na BrowseComp, MCP Atlas i GPQA Diamond, a jego natywna obsługa wideo i audio wciąż wyprzedza to, co GPT-5.5 oferuje natywnie.
Dla większości zespołów rozsądniejszym ruchem nie będzie wybór zero-jedynkowy: proszę używać Gemini 3.1 Pro jako „woła roboczego” do zadań o dużej skali lub bogatych w media, a sięgać po GPT-5.5 tam, gdzie przewaga naprawdę ma znaczenie. Takie hybrydowe podejście daje to, co najlepsze z obu światów, bez płacenia cen czołowych modeli za wszystko.
Jeśli chcą się Państwo nauczyć budowania aplikacji zasilanych AI przy użyciu LLM-ów, promptów, łańcuchów i agentów w LangChain, gorąco polecamy nasz kurs Developing LLM Applications with LangChain.
Naucz się AI z DataCamp!
course
course
course