
Curso
Trabajar con la API de OpenAI
3 h
141.6K
OpenAI acaba de lanzar su primer modelo base reentrenado desde GPT-4.5. Suena contraintuitivo, pero GPT-5 y el resto de sus sucesores fueron actualizaciones incrementales.
Este es distinto: se ha creado desde cero para flujos de trabajo agentic, con un gran rendimiento en dos benchmarks críticos que más importan a los desarrolladores.
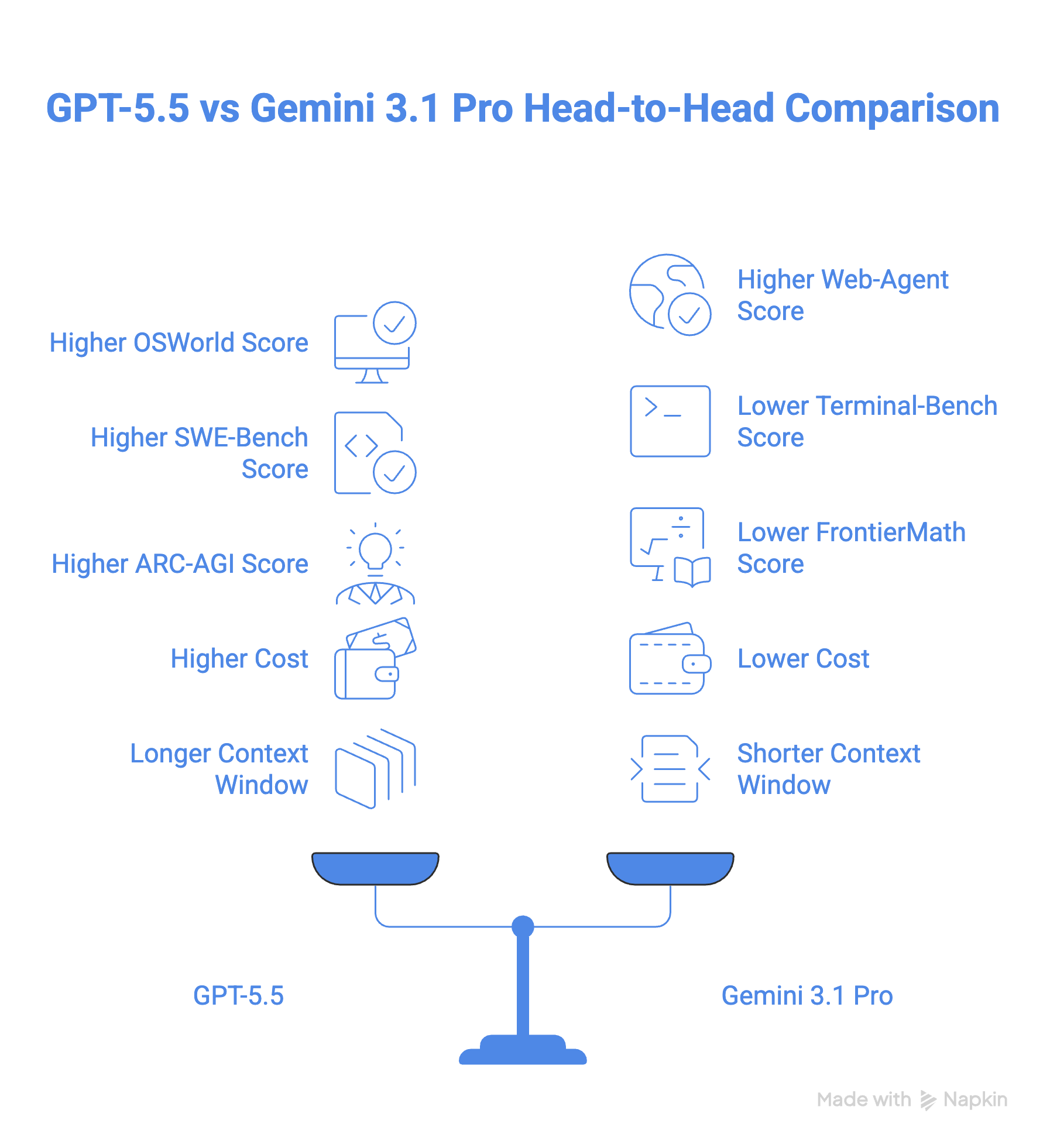
En este artículo, compararé el recién lanzado GPT-5.5 con Gemini 3.1 Pro para ayudarte a decidir cuál te conviene más. Veremos los benchmarks, el coste y los casos de uso.
GPT-5.5 es el último modelo insignia omnimodal de OpenAI, con nombre en clave "Spud". No es un ajuste fino de un modelo anterior, sino uno reconstruido desde cero para la ejecución autónoma y multitarea con poca o ninguna guía.
GPT-5.5 llega en tres variantes:
Descubre más sobre el modelo en nuestro artículo OpenAI GPT-5.5 y en nuestra comparativa Claude Opus 4.7 vs GPT-5.5.
Las funciones y capacidades principales de GPT-5.5 son:
Una de las mayores novedades es la fuerte mejora en trabajos de contexto largo entre 512K y 1M; el rendimiento más que se duplicó del 36,6% en GPT-5.4 al 74,0% en GPT-5.5.
El modelo también es actualmente el más fuerte en matemáticas. En FrontierMath Tier 4, GPT-5.5 obtiene un 35,4%, y GPT-5.5 Pro lo eleva al 39,6%. Como referencia, GPT-5.4 logró un 27,1%, Claude Opus 4.7 un 22,9% y Gemini 3.1 Pro un 16,7%.
El rendimiento de GPT-5.5 en OSWorld-Verified lo convierte en el mejor modelo para uso de ordenador entre los que han publicado resultados en este benchmark. También supera al resto en matemáticas avanzadas. La eficiencia de tokens es otra ventaja para tareas agentic de larga duración.
Como contrapartida, GPT-5.5 es más caro que el modelo anterior: 5 $ por millón de tokens de entrada y 30 $ por millón de tokens de salida. La empresa afirma que podría salir más barato porque es más eficiente en tokens, pero depende de tus flujos de trabajo que esto se cumpla o no.
Gemini 3.1 Pro es el modelo insignia de última generación de Google, basado en una arquitectura Mixture-of-Experts (MoE). Google lo diseñó para ofrecer un sólido desempeño multimodal y de razonamiento a un precio competitivo.
Para una comparación con el último modelo frontier de Anthropic, lee nuestro blog Claude Opus 4.7 vs Gemini 3.1 Pro.
Estas son sus funciones y capacidades clave:
Nativamente multimodal con soporte para texto e imágenes. Audio, vídeo y PDF.
Sistema de razonamiento en tres niveles que ofrece niveles low, medium y high.
Ventana de contexto de 1M de tokens, con 65K tokens máximos de salida y acepta 8,4 horas de audio o una hora completa de vídeo en un único prompt.
77,1% en ARC-AGI-2, mostrando un razonamiento visual abstracto sólido que más que duplica el 31,1% de Gemini 3 Pro.
33,5% en APEX-Agents, que mide tareas profesionales de largo recorrido, casi el doble del 18,4% de Gemini 3 Pro.
En nuestro tutorial Building with Gemini 3.1 Pro, cubrimos cómo crear una app lista para producción con Gemini 3.1 Pro y la Gemini CLI.
Gemini 3.1 Pro destaca en tareas complejas de razonamiento visual y tiene ventaja frente a la competencia por su diseño nativamente multimodal, que gestiona texto, imágenes, vídeo y audio en un único prompt. Súmalo a una enorme ventana de contexto de 1M de tokens, y puedes analizar bases de código enteras, PDFs extensos u horas de vídeo de una sola vez. Gemini 3.1 Pro también impulsa Nano Banana 2 y Veo 3.1 para salida de imagen y vídeo.
Como punto débil, Gemini 3.1 Pro cuenta con 65K tokens de salida, que pueden no bastar para tareas agentic de larga duración. Esto significa que puede no encajar bien en generación de documentos largos y bucles de agentes que producen grandes volúmenes de salida.
Aprende a crear un panel financiero con Gemini 3 y pruebas de navegador con IA en nuestro tutorial Google Antigravity.
Según el Artificial Analysis Intelligence Index, GPT-5.5 es actualmente el mejor modelo global, y también lidera su índice de código y de agentes.
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
Fecha de lanzamiento |
23 de abril de 2026 |
19 de febrero de 2026 |
|
Arquitectura |
Omnimodal (unificada) |
MoE (Transformer) |
|
Ventana de contexto |
1M tokens |
1M tokens |
|
Salida máxima |
128K tokens |
65K tokens |
|
OSWorld |
78,7% |
|
|
BrowseComp |
84,4% |
85,9% |
|
ARC-AGI-2 |
85,0% |
77,1% |
|
GPQA Diamond |
93,6% |
94,3% |
|
Terminal-Bench 2.0 |
82,7% |
68,5% |
|
FrontierMath Tier 4 |
35,4% (Pro 39,6%) |
16,7% |
|
SWE-Bench Pro |
58,6% |
54,2% |
|
Precio de API (entrada/salida por 1M) |
$5/$30 (Pro $30/$180) |
$2/$12 |
Echemos un vistazo a varios casos de uso.
GPT-5.5 obtiene un 78,7% en el benchmark OSWorld-Verified para uso de ordenador, aunque no hay puntuación pública de Gemini para compararlo. En la práctica, el uso de ordenador de GPT-5.5 está integrado en la app Codex, donde puede navegar y probar sitios web. Google ofrece una funcionalidad similar con su app Antigravity.
En tareas de agentes web, el panorama se pone interesante. Gemini 3.1 Pro se adelanta con un 85,9% en BrowseComp frente al 84,4% de GPT-5.5, y también rinde mejor en MCP Atlas (un benchmark que prueba el uso de herramientas a través de 36 servidores MCP), con un 78,2% frente al 75,3% de GPT-5.5.
Dicho esto, GPT-5.5 contraataca en Toolathon, que somete al modelo a más de 600 herramientas reales, con un 55,6% frente al 48,8% de Gemini. GPT-5.5 también lidera el Artificial Analysis Agentic Index, donde Gemini 3.1 Pro queda bastante por detrás, como muestra el gráfico siguiente.
En código, GPT-5.5 supera a Gemini 3.1 Pro con un 58,6% en SWE-Bench Pro y un 82,7% en Terminal-Bench 2.0, frente al 54,2% y 68,5% de Gemini 3.1 Pro. Especialmente en Terminal-Bench 2.0, GPT-5.5 lidera con un gran margen.
GPT-5.5 lidera el Artificial Analysis Coding Index, con Gemini 3.1 Pro justo detrás.
En ARC-AGI-2, que mide la capacidad de un modelo para aprender y resolver problemas sin entrenamiento previo, GPT-5.5 supera a Gemini 3.1 Pro con una diferencia cercana a 8 puntos (85,0% vs 77,1%).
GPT-5.5 también lidera en matemáticas avanzadas con una diferencia de 18 puntos frente a Gemini 3.1 Pro, según el benchmark FrontierMath, que evalúa el razonamiento a nivel experto.
Gemini 3.1 Pro cuesta 2 $ por 1M de tokens de entrada y 12 $ por 1M de tokens de salida. GPT-5.5 parte de un precio sensiblemente mayor: 5 $ por 1M de tokens de entrada y 30 $ por 1M de tokens de salida (y seis veces más en el modelo Pro). Esto hace que GPT-5.5 sea más del doble de caro que Gemini 3.1 Pro.
GPT-5.5 y Gemini 3.1 Pro comparten una ventana de contexto de 1M. Sin embargo, GPT-5.5 ofrece 128K tokens de salida, frente a los 65K de Gemini.
Esto nos lleva a la pregunta de cuál de los dos modelos elegir.

GPT-5.5 es el modelo más fuerte sobre el papel y, para la mayoría de desarrolladores, probablemente también en la práctica, especialmente si tu trabajo vive en terminales o usa matemáticas complejas. La reconstrucción desde cero ha dado frutos: no es un modelo parcheado, y las diferencias en Terminal-Bench 2.0 y FrontierMath lo dejan claro.
Pero "más fuerte" no siempre significa "mejor para ti". A 2,5 veces el precio de Gemini 3.1 Pro, GPT-5.5 supone un compromiso real de presupuesto, y el argumento de la eficiencia de tokens solo se sostiene si tus flujos son lo bastante largos como para beneficiarse.
Gemini 3.1 Pro no es el segundón aquí. Es un modelo competitivo que lidera en BrowseComp, MCP Atlas y GPQA Diamond, y su manejo nativo de vídeo y audio sigue por delante de lo que GPT-5.5 ofrece de forma nativa.
La jugada más inteligente para la mayoría de equipos probablemente no sea elegir uno u otro: usa Gemini 3.1 Pro como caballo de batalla para tareas de alto volumen o con mucho contenido multimedia, y recurre a GPT-5.5 donde el margen realmente importa. Ese enfoque híbrido te da lo mejor de ambos sin pagar precios frontier en toda la línea.
Si quieres aprender a crear aplicaciones con IA usando LLMs, prompts, cadenas y agentes en LangChain, te recomiendo mucho nuestro curso Developing LLM Applications with LangChain.
¡Aprende IA con DataCamp!
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
9 min
blog
Josep Ferrer
8 min
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan


