
Cursus
Werken met de OpenAI API
3 Hr
141.6K
OpenAI heeft zojuist hun eerste opnieuw getrainde basismodel sinds GPT-4.5 uitgebracht. Dat klinkt tegenintuïtief, maar GPT-5 en alle andere opvolgers waren incrementele updates.
Dit model is anders: het is vanaf de grond opgebouwd voor agentische workflows, met sterke prestaties op twee cruciale benchmarks die voor developers het belangrijkst zijn.
In dit artikel vergelijk ik de nieuwe GPT-5.5 met de Gemini 3.1 Pro om je te helpen bepalen welke het beste bij je past. We bekijken de benchmarks, kosten en use-cases.
GPT-5.5 is OpenAI’s nieuwste vlaggenschip-omnimodale model, codenaam “Spud”. Het is geen fine-tune van een eerder model, maar volledig opnieuw opgebouwd voor autonome, multi-task uitvoering met weinig tot geen begeleiding.
GPT-5.5 wordt geleverd in drie varianten:
Ontdek meer over het model in ons artikel OpenAI GPT-5.5 en in onze vergelijking Claude Opus 4.7 vs GPT-5.5.
De kernfeatures en mogelijkheden van GPT-5.5 zijn:
Een van de grootste verbeteringen is de sterke vooruitgang bij long-context werk tussen 512K en 1M; de prestaties zijn meer dan verdubbeld van 36,6% in GPT 5.4 naar 74,0% in GPT 5.5.
Het model is momenteel ook het sterkst in wiskunde. Op FrontierMath Tier 4 haalt GPT 5.5 35,4%, en GPT 5.5 Pro stuwt dat naar 39,6%. Ter context: GPT 5.4 scoorde 27,1%, Claude Opus 4.7 scoorde 22,9% en Gemini 3.1 Pro scoorde 16,7%.
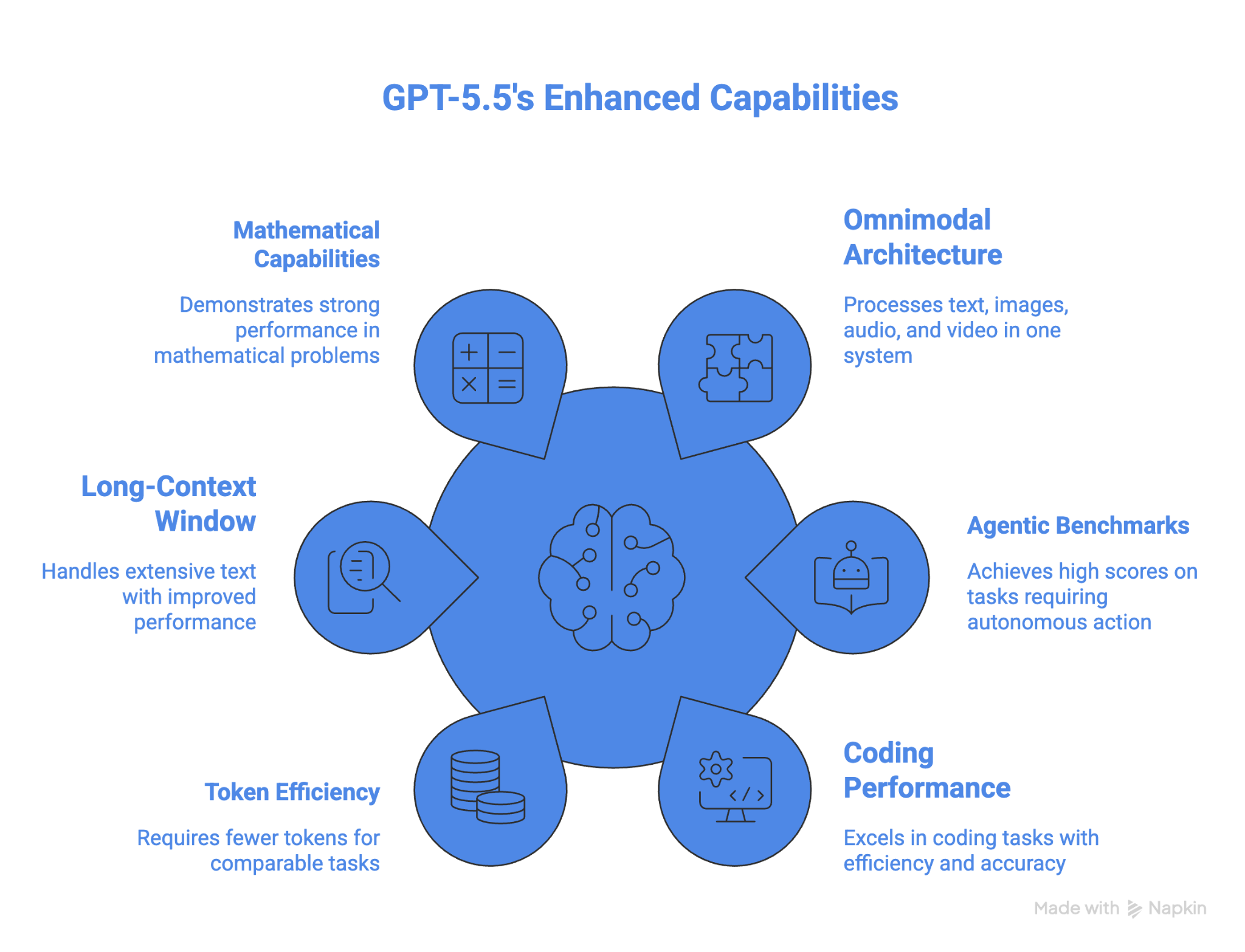
De prestaties van GPT-5.5 op OSWorld-Verified maken het het beste model voor computergebruik onder de modellen die resultaten voor deze benchmark hebben gedeeld. Het verslaat ook alle andere modellen in gevorderde wiskunde. Token-efficiëntie is een ander voordeel voor langlopende agentische taken.
Daar staat tegenover dat GPT-5.5 duurder is dan het vorige model, met $5 per miljoen inputtokens en $30 per miljoen outputtokens. Het bedrijf zegt dat het goedkoper kán uitvallen omdat het token-efficiënter is, maar of dat zo is, hangt af van je workflows.
Gemini 3.1 Pro is Google’s huidige state-of-the-art vlaggenschipmodel, gebouwd op een Mixture-of-Experts (MoE)-architectuur. Google ontwierp het om sterke multimodale en redeneerprestaties te bieden tegen een competitieve prijs.
Voor een vergelijking met het nieuwste frontier-model van Anthropic, lees onze blog over Claude Opus 4.7 vs Gemini 3.1 Pro.
Dit zijn de belangrijkste features en mogelijkheden van Gemini 3.1 Pro:
Natuurlijk multimodaal met ondersteuning voor tekst en afbeeldingen. Audio, video en pdf’s.
Drie niveaus van “thinking” met low, medium en high-niveaus.
Contextvenster van 1M tokens, met 65K maximale outputtokens en acceptatie van 8,4 uur audio of een volledig uur video in één prompt.
77,1% op ARC-AGI-2, wat sterke abstracte visuele redeneerprestaties laat zien die meer dan het dubbele zijn van de 31,1% van Gemini 3 Pro.
33,5% op APEX-Agents die langetermijnprofessionele taken meten, bijna twee keer de 18,4% van Gemini 3 Pro.
In onze tutorial Bouwen met Gemini 3.1 Pro behandelen we hoe je een productieklare app bouwt met Gemini 3.1 Pro en de Gemini CLI.
Gemini 3.1 Pro blinkt uit in complexe visuele redeneertaken en heeft een voorsprong op de concurrentie met zijn natuurlijk multimodale ontwerp, dat tekst, afbeeldingen, video en audio in één enkele prompt verwerkt. In combinatie met een enorm contextvenster van 1M tokens kun je complete codebases, lange pdf’s of uren aan video in één keer analyseren. Gemini 3.1 Pro drijft ook Nano Banana 2 en Veo 3.1 aan voor beeld- en video-output.
Een nadeel is dat Gemini 3.1 Pro 65K outputtokens biedt, wat mogelijk niet genoeg is voor langlopende agentische taken. Dit betekent dat het minder geschikt kan zijn voor het genereren van lange documenten en agentische loops die grote outputs produceren.
Leer hoe je een finance-dashboard bouwt met Gemini 3 en AI-gestuurde browsertests in onze tutorial Google Antigravity.
Volgens de Artificial Analysis Intelligence Index is GPT 5.5 momenteel het beste algehele model, en het neemt ook de leiding op hun coding- en agentische index.
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
Release-datum |
23 april 2026 |
19 februari 2026 |
|
Architectuur |
Omnimodaal (unified) |
MoE (Transformer) |
|
Contextvenster |
1M tokens |
1M tokens |
|
Maximale output |
128K tokens |
65K tokens |
|
OSWorld |
78,7% |
|
|
BrowseComp |
84,4% |
85,9% |
|
ARC-AGI-2 |
85,0% |
77,1% |
|
GPQA Diamond |
93,6% |
94,3% |
|
Terminal-Bench 2.0 |
82,7% |
68,5% |
|
FrontierMath Tier 4 |
35,4% (Pro 39,6%) |
16,7% |
|
SWE-Bench Pro |
58,6% |
54,2% |
|
API-prijzen (input/output per 1M) |
$5/$30 (Pro $30/$180) |
$2/$12 |
Laten we een paar verschillende use-cases bekijken.
GPT-5.5 scoort 78,7% op de OSWorld-Verified benchmark voor computergebruik, al is er geen publieke Gemini-score om mee te vergelijken. In de praktijk is het computergebruik van GPT-5.5 ingebouwd in de Codex-app, waar het websites kan navigeren en testen. Google biedt vergelijkbare functionaliteit via de Antigravity-app.
Bij webagent-taken wordt het interessanter. Gemini 3.1 Pro heeft de overhand met 85,9% op BrowseComp tegenover 84,4% voor GPT-5.5, en het presteert ook beter op MCP Atlas (een benchmark die toolgebruik test over 36 MCP-servers), met 78,2% tegenover 75,3% voor GPT-5.5.
Daar staat tegenover dat GPT-5.5 terugvecht op Toolathon, dat meer dan 600 real-world tools op een model afvuurt, met 55,6% vergeleken met 48,8% voor Gemini. GPT-5.5 neemt ook de leiding op de Artificial Analysis Agentic Index, waar Gemini 3.1 Pro aanzienlijk achterblijft, zoals in de onderstaande grafiek te zien is.
Als het om coderen gaat, verslaat GPT-5.5 Gemini 3.1 Pro met een score van 58,6% op SWE-Bench Pro en 82,7% op Terminal-Bench 2.0, tegenover 54,2% en 68,5% voor Gemini 3.1 Pro. Vooral op Terminal-Bench 2.0 heeft GPT-5.5 een ruime voorsprong.
GPT-5.5 leidt op de Artificial Analysis Coding Index met Gemini 3.1 Pro vlak daarachter.
Op de ARC-AGI-2, die het vermogen van een model meet om zonder voorafgaande training te leren en problemen op te lossen, verslaat GPT-5.5 Gemini 3.1 Pro met een verschil van bijna 8 punten (85,0% vs 77,1%).
GPT-5.5 neemt ook de leiding op gevorderde wiskunde met een verschil van 18 punten ten opzichte van Gemini 3.1 Pro, gemeten met de FrontierMath-benchmark, die het redeneervermogen van een model op expertniveau test.
Gemini 3.1 Pro kost $2 per 1M inputtokens en $12 per 1M outputtokens. GPT-5.5 begint op een aanzienlijk hoger tarief, met $5 per 1M inputtokens en $30 per 1M outputtokens (en zes keer zoveel voor het Pro-model). Daarmee is GPT 5.5 meer dan twee keer zo duur als Gemini 3.1 Pro.
GPT-5.5 en Gemini 3.1 Pro hebben allebei een contextvenster van 1M. GPT 5.5 biedt echter 128K outputtokens, tegenover 65K bij Gemini.
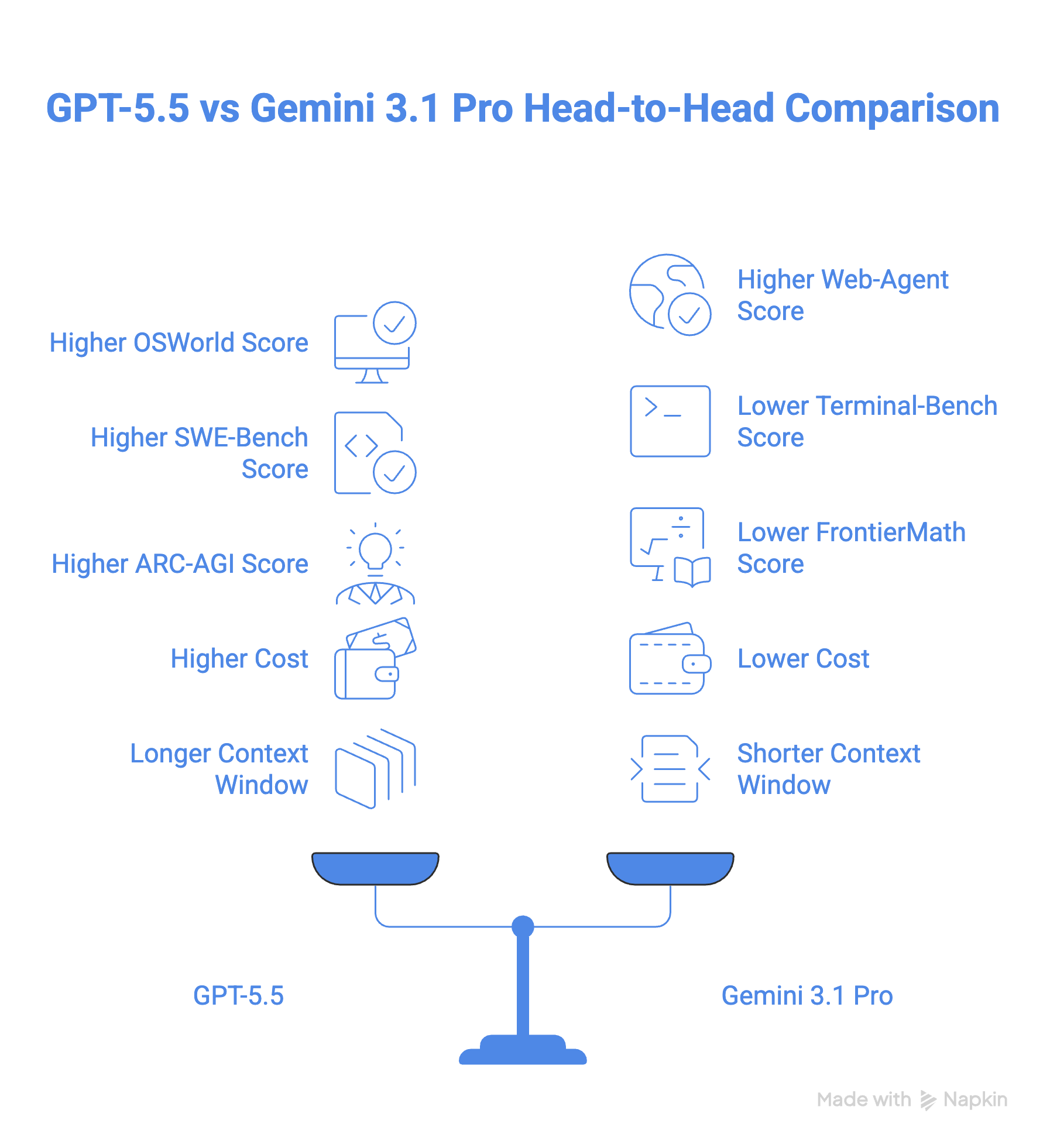
Dan komen we bij de vraag welk van de twee modellen je moet kiezen.

GPT-5.5 is op papier het sterkere model, en voor de meeste developers waarschijnlijk ook in de praktijk, zeker als je werk in terminalomgevingen plaatsvindt of complexe wiskunde gebruikt. De rebuild vanaf de basis heeft geloond: dit is geen model dat bij elkaar is gepatcht, en de benchmarkverschillen op Terminal-Bench 2.0 en FrontierMath maken dat duidelijk.
Maar “sterker” betekent niet altijd “beter voor jou”. Met een prijs die 2,5x die van Gemini 3.1 Pro is, is GPT-5.5 een serieuze budgetkeuze, en het argument over token-efficiëntie gaat alleen op als je workflows lang genoeg zijn om ervan te profiteren.
Gemini 3.1 Pro is hier niet de tweede viool. Het is een competitief model dat leidt op BrowseComp, MCP Atlas en GPQA Diamond, en de native video- en audioverwerking ligt nog steeds voor op wat GPT-5.5 native biedt.
De slimste zet voor de meeste teams is waarschijnlijk geen binaire keuze: gebruik Gemini 3.1 Pro als werkpaard voor grootschalige of media-intensieve taken, en zet GPT-5.5 in waar het verschil echt telt. Die hybride aanpak geeft je het beste van beide zonder overal frontier-prijzen te betalen.
Als je AI-aangedreven applicaties wilt leren bouwen met LLM’s, prompts, chains en agents in LangChain, kan ik onze cursus Developing LLM Applications with LangChain van harte aanraden.
Leer AI met DataCamp!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
