
Kurs
Arbeiten mit der OpenAI-API
3 Std.
141.6K
OpenAI hat gerade sein erstes neu trainiertes Basismodell seit GPT-4.5 veröffentlicht. Das klingt kontraintuitiv, aber GPT-5 und alle weiteren Nachfolger waren inkrementelle Updates.
Diesmal ist es anders: Es wurde von Grund auf für agentische Workflows gebaut und glänzt auf zwei entscheidenden Benchmarks, die für Entwickler am meisten zählen.
In diesem Artikel vergleiche ich das neu veröffentlichte GPT-5.5 mit dem Gemini 3.1 Pro, damit du die beste Wahl für dich treffen kannst. Wir betrachten Benchmarks, Kosten und Einsatzszenarien.
GPT-5.5 ist OpenAIs aktuelles Omnimodal-Flaggschiff mit dem Codenamen „Spud“. Es ist kein Feintuning eines Vorgängers, sondern ein komplett neu aufgebautes Modell für autonome, mehrstufige Ausführung mit wenig bis keiner Anleitung.
GPT-5.5 kommt in drei Varianten:
Mehr über das Modell findest du in unserem Artikel zu OpenAI GPT-5.5 und im Vergleich Claude Opus 4.7 vs GPT-5.5.
Die zentralen Stärken von GPT-5.5 sind:
Eines der größten Features ist der deutliche Sprung bei Langkontext-Aufgaben zwischen 512K und 1M; die Performance hat sich von 36,6% bei GPT 5.4 auf 74,0% bei GPT 5.5 mehr als verdoppelt.
Auch in Mathematik ist das Modell aktuell führend. Auf FrontierMath Tier 4 erreicht GPT 5.5 35,4%, GPT 5.5 Pro sogar 39,6%. Zum Vergleich: GPT 5.4 lag bei 27,1%, Claude Opus 4.7 bei 22,9% und Gemini 3.1 Pro bei 16,7%.
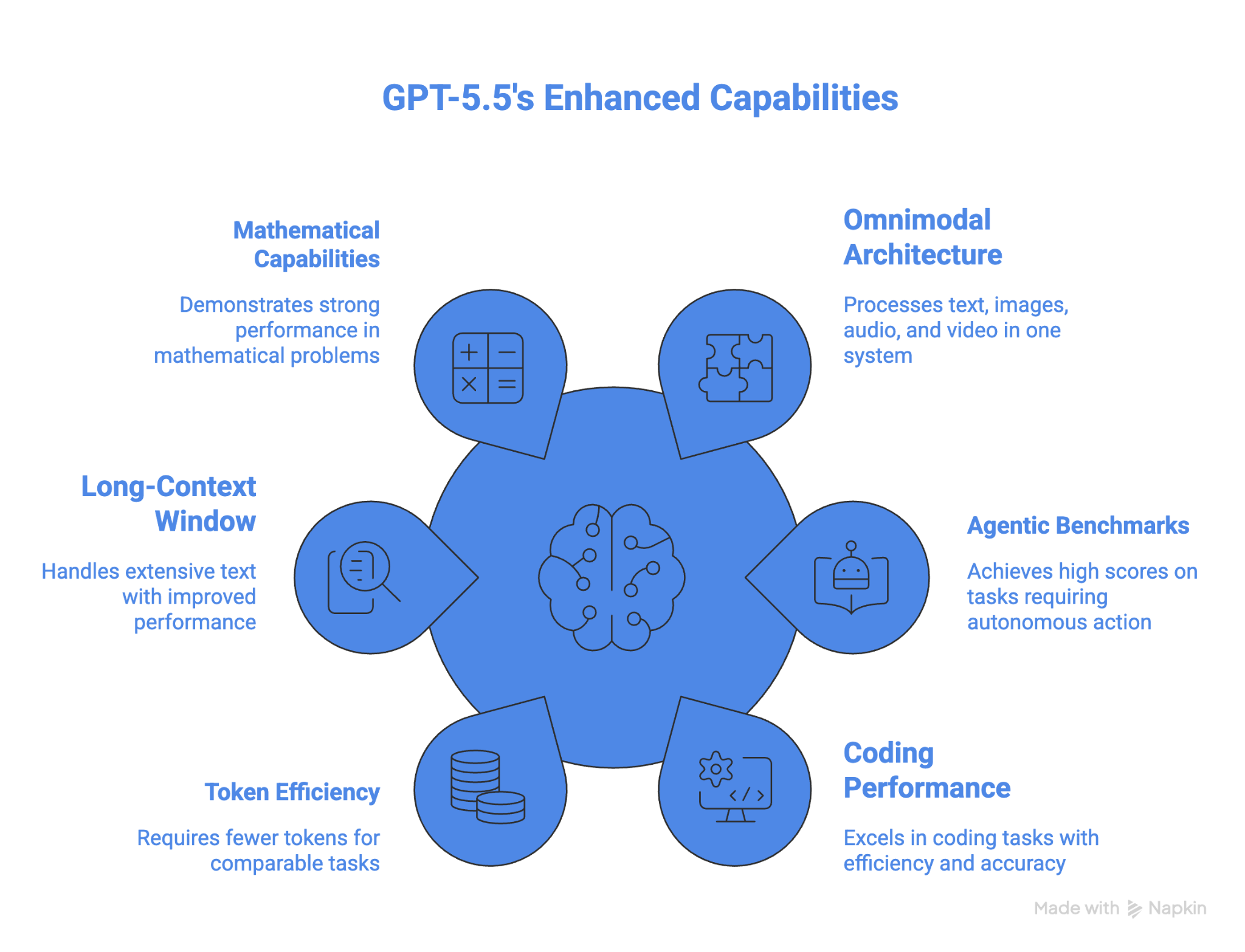
Die Leistung von GPT-5.5 auf OSWorld-Verified macht es zum besten Modell für Computerbedienung unter denen, die Ergebnisse für diesen Benchmark veröffentlicht haben. Auch in höherer Mathematik schlägt es alle anderen Modelle. Tokeneffizienz ist ein weiterer Pluspunkt für lang laufende agentische Tasks.
Auf der Minus-Seite ist GPT-5.5 teurer als das Vorgängermodell: $5 pro Million Eingabetokens und $30 pro Million Ausgabetokens. OpenAI sagt, es könne durch höhere Tokeneffizienz günstiger sein – ob das stimmt, hängt jedoch von deinen Workflows ab.
Gemini 3.1 Pro ist Googles aktuelles State-of-the-Art-Flaggschiff auf einer Mixture-of-Experts (MoE)-Architektur. Google hat es entwickelt, um starke multimodale Leistungen und Reasoning zu einem wettbewerbsfähigen Preis zu liefern.
Für den Vergleich mit Anthropics neuestem Frontier-Modell lies unseren Blog zu Claude Opus 4.7 vs Gemini 3.1 Pro.
Hier sind die wichtigsten Features und Fähigkeiten von Gemini 3.1 Pro:
Nativ multimodal mit Unterstützung für Text und Bilder. Audio, Video und PDFs.
Dreistufiges Denksystem mit den Levels low, medium und high.
1M Token Kontextfenster, bis zu 65K Ausgabetokens und Annahme von 8,4 Stunden Audio oder einer vollen Stunde Video in einer einzelnen Eingabe.
77,1% auf ARC-AGI-2 mit starkem abstrakten visuellem Denken, mehr als doppelt so hoch wie die 31,1% von Gemini 3 Pro.
33,5% auf APEX-Agents, die lang laufende professionelle Aufgaben messen – fast doppelt so viel wie die 18,4% von Gemini 3 Pro.
In unserem Tutorial Building with Gemini 3.1 Pro zeigen wir, wie du mit Gemini 3.1 Pro und der Gemini CLI eine produktionsreife App baust.
Gemini 3.1 Pro überzeugt bei komplexem visuellen Reasoning und punktet mit seiner nativ multimodalen Architektur, die Text, Bilder, Video und Audio in einer einzigen Eingabe verarbeitet. Kombiniert mit einem riesigen Kontextfenster von 1M Tokens kannst du komplette Codebasen, lange PDFs oder stundenlanges Video auf einmal analysieren. Gemini 3.1 Pro treibt außerdem Nano Banana 2 und Veo 3.1 für Bild- und Videoausgaben an.
Auf der Minus-Seite ist die Ausgabe bei Gemini 3.1 Pro auf 65K Tokens begrenzt, was für lang laufende agentische Tasks knapp werden kann. Für lange Dokumenterstellung und agentische Loops mit großen Outputs ist das eventuell nicht ideal.
Lerne in unserem Google Antigravity-Tutorial, wie du mit Gemini 3 ein Finanz-Dashboard baust und KI-gestütztes Browser-Testing einsetzt.
Laut dem Artificial Analysis Intelligence Index ist GPT 5.5 aktuell das beste Gesamtmodell und führt auch deren Coding- und Agentic-Index an.
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
Veröffentlichung |
23. April 2026 |
19. Februar 2026 |
|
Architektur |
Omnimodal (vereinheitlicht) |
MoE (Transformer) |
|
Kontextfenster |
1M Tokens |
1M Tokens |
|
Max. Ausgabe |
128K Tokens |
65K Tokens |
|
OSWorld |
78,7% |
|
|
BrowseComp |
84,4% |
85,9% |
|
ARC-AGI-2 |
85,0% |
77,1% |
|
GPQA Diamond |
93,6% |
94,3% |
|
Terminal-Bench 2.0 |
82,7% |
68,5% |
|
FrontierMath Tier 4 |
35,4% (Pro 39,6%) |
16,7% |
|
SWE-Bench Pro |
58,6% |
54,2% |
|
API-Preise (Input/Output pro 1M) |
$5/$30 (Pro $30/$180) |
$2/$12 |
Schauen wir uns einige typische Anwendungsfälle an.
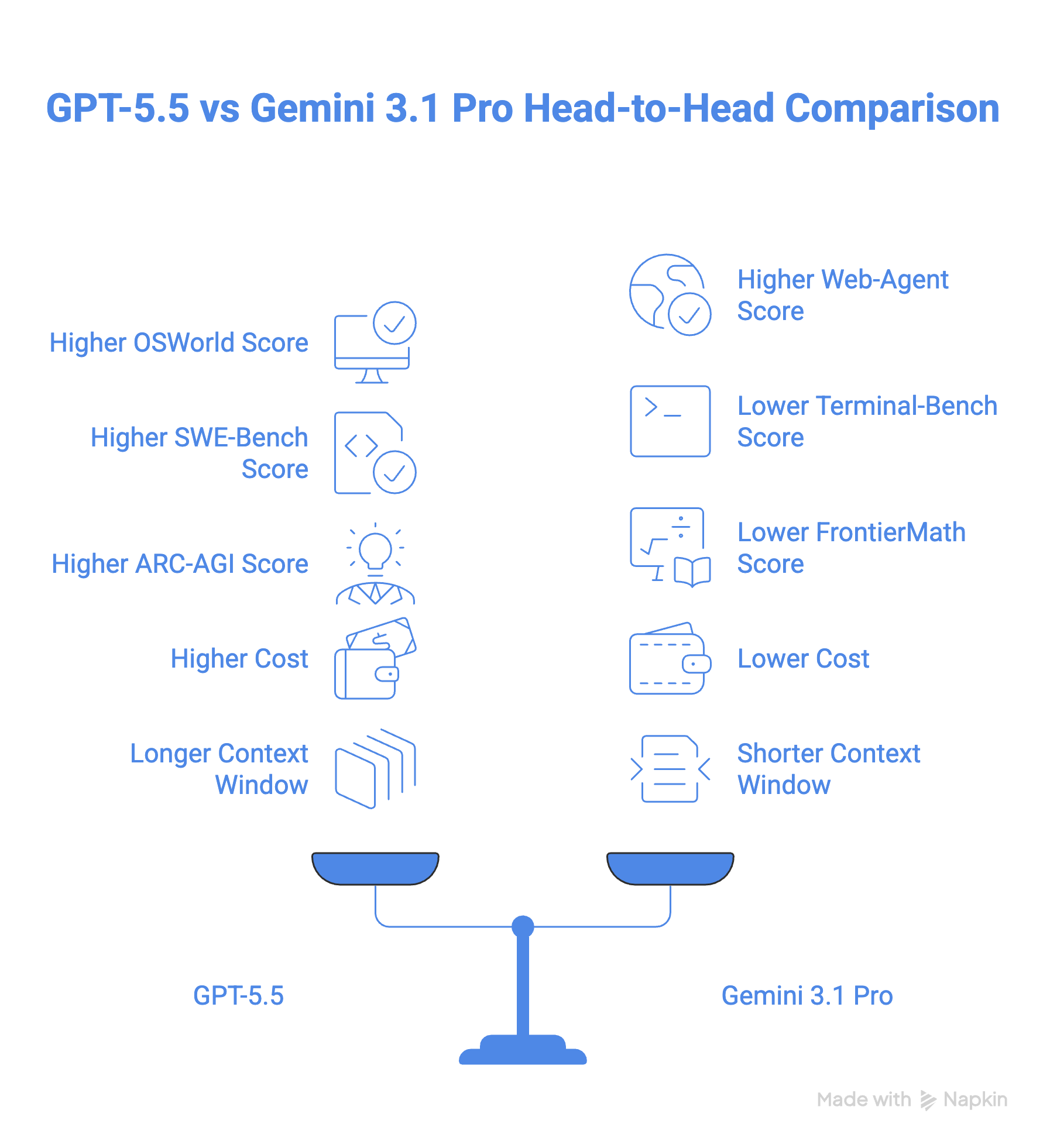
GPT-5.5 erzielt 78,7% auf dem OSWorld-Verified-Benchmark für Computerbedienung, auch wenn es für Gemini keinen öffentlichen Vergleichswert gibt. In der Praxis ist die Computerbedienung von GPT-5.5 im Codex-App integriert, wo es Websites navigieren und testen kann. Google bietet Ähnliches mit der Antigravity-App.
Bei Web-Agent-Aufgaben wird es interessanter. Gemini 3.1 Pro liegt mit 85,9% auf BrowseComp knapp vor GPT-5.5 mit 84,4% und schneidet auch auf MCP Atlas (ein Benchmark für Toolnutzung über 36 MCP-Server) besser ab: 78,2% gegenüber 75,3% bei GPT-5.5.
Allerdings kontert GPT-5.5 beim Toolathon, der ein Modell mit über 600 realen Tools konfrontiert: 55,6% gegenüber 48,8% bei Gemini. Auch im Artificial Analysis Agentic Index liegt GPT-5.5 vorn, während Gemini 3.1 Pro dort deutlich zurückfällt, wie die Grafik unten zeigt.
Beim Coding schlägt GPT-5.5 Gemini 3.1 Pro mit 58,6% auf SWE-Bench Pro und 82,7% auf Terminal-Bench 2.0, verglichen mit 54,2% bzw. 68,5% bei Gemini 3.1 Pro. Besonders auf Terminal-Bench 2.0 liegt GPT-5.5 deutlich vorn.
GPT-5.5 führt im Artificial Analysis Coding Index, dicht gefolgt von Gemini 3.1 Pro.
Auf dem ARC-AGI-2, der die Fähigkeit eines Modells misst, ohne vorheriges Training zu lernen und Probleme zu lösen, schlägt GPT-5.5 Gemini 3.1 Pro um knapp 8 Punkte (85,0% vs. 77,1%).
Auch in fortgeschrittener Mathematik liegt GPT-5.5 vorn – mit einem Abstand von 18 Punkten gegenüber Gemini 3.1 Pro laut FrontierMath, das die Reasoning-Fähigkeit auf Expertenniveau testet.
Gemini 3.1 Pro kostet $2 pro 1M Eingabetokens und $12 pro 1M Ausgabetokens. GPT-5.5 startet deutlich höher mit $5 für 1M Eingabetokens und $30 für 1M Ausgabetokens (beim Pro-Modell sechsmal so viel). Damit ist GPT 5.5 mehr als doppelt so teuer wie Gemini 3.1 Pro.
GPT-5.5 und Gemini 3.1 Pro bieten beide ein Kontextfenster von 1M. GPT 5.5 liefert jedoch bis zu 128K Ausgabetokens, Gemini 65K.
Damit stellt sich die Frage, welches der beiden Modelle für dich die bessere Wahl ist.

GPT-5.5 ist auf dem Papier das stärkere Modell – und für die meisten Entwickler wahrscheinlich auch in der Praxis, besonders wenn du im Terminal arbeitest oder komplexe Mathematik im Spiel ist. Der Neuaufbau hat sich gelohnt: Das ist kein Modell, das nur zurechtgepatcht wurde, und die Benchmark-Abstände bei Terminal-Bench 2.0 und FrontierMath zeigen das deutlich.
Aber „stärker“ heißt nicht automatisch „besser für dich“. Mit dem 2,5-fachen Preis von Gemini 3.1 Pro ist GPT-5.5 eine echte Budgetentscheidung, und das Argument der Tokeneffizienz zählt nur, wenn deine Workflows lang genug sind, um davon zu profitieren.
Gemini 3.1 Pro ist hier kein bloßer Zweiter. Es ist ein konkurrenzfähiges Modell, das bei BrowseComp, MCP Atlas und GPQA Diamond führt, und seine native Video- und Audioverarbeitung ist weiterhin dem nativ Gebotenen von GPT-5.5 voraus.
Die smartere Strategie für die meisten Teams ist wahrscheinlich keine Entweder-oder-Entscheidung: Nutze Gemini 3.1 Pro als Arbeitspferd für hochvolumige oder medienlastige Aufgaben und setze GPT-5.5 dort ein, wo der Leistungsabstand wirklich zählt. So bekommst du das Beste aus beiden Welten, ohne überall Frontier-Preise zu zahlen.
Wenn du lernen willst, KI-gestützte Anwendungen mit LLMs, Prompts, Chains und Agents in LangChain zu bauen, empfehle ich dir unseren Kurs Developing LLM Applications with LangChain.
Lerne KI mit DataCamp!
Kurs
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Matt Crabtree