
Corso
Lavorare con l'API di OpenAI
3 h
141.6K
OpenAI ha appena rilasciato il primo modello base riaddestrato dai tempi di GPT-4.5. Può sembrare controintuitivo, ma GPT-5 e tutti i suoi successori sono stati aggiornamenti incrementali.
Questo è diverso: è stato costruito da zero per i workflow agentici, con solide prestazioni su due benchmark critici che contano di più per gli sviluppatori.
In questo articolo confronterò il nuovo GPT-5.5 con Gemini 3.1 Pro per aiutarti a decidere quale sia il migliore per te. Vedremo benchmark, costi e casi d’uso.
GPT-5.5 è l’ultimo modello di punta omnimodale di OpenAI, nome in codice “Spud”. Non è un fine-tuning di un modello precedente, ma un modello ricostruito da zero per l’esecuzione autonoma e multi-task con pochissima supervisione.
GPT-5.5 arriva in tre varianti:
Scopri di più sul modello nel nostro articolo OpenAI GPT-5.5 e nel nostro confronto Claude Opus 4.7 vs GPT-5.5.
Le funzionalità e capacità principali di GPT-5.5 sono:
Una delle novità più importanti è il forte miglioramento sul lungo contesto tra 512K e 1M: le prestazioni sono più che raddoppiate dal 36,6% di GPT 5.4 al 74,0% di GPT 5.5.
Il modello è attualmente anche il più forte in matematica. Su FrontierMath Tier 4, GPT 5.5 ottiene il 35,4% e GPT 5.5 Pro spinge fino al 39,6%. Per contesto, GPT 5.4 ha ottenuto il 27,1%, Claude Opus 4.7 il 22,9% e Gemini 3.1 Pro il 16,7%.
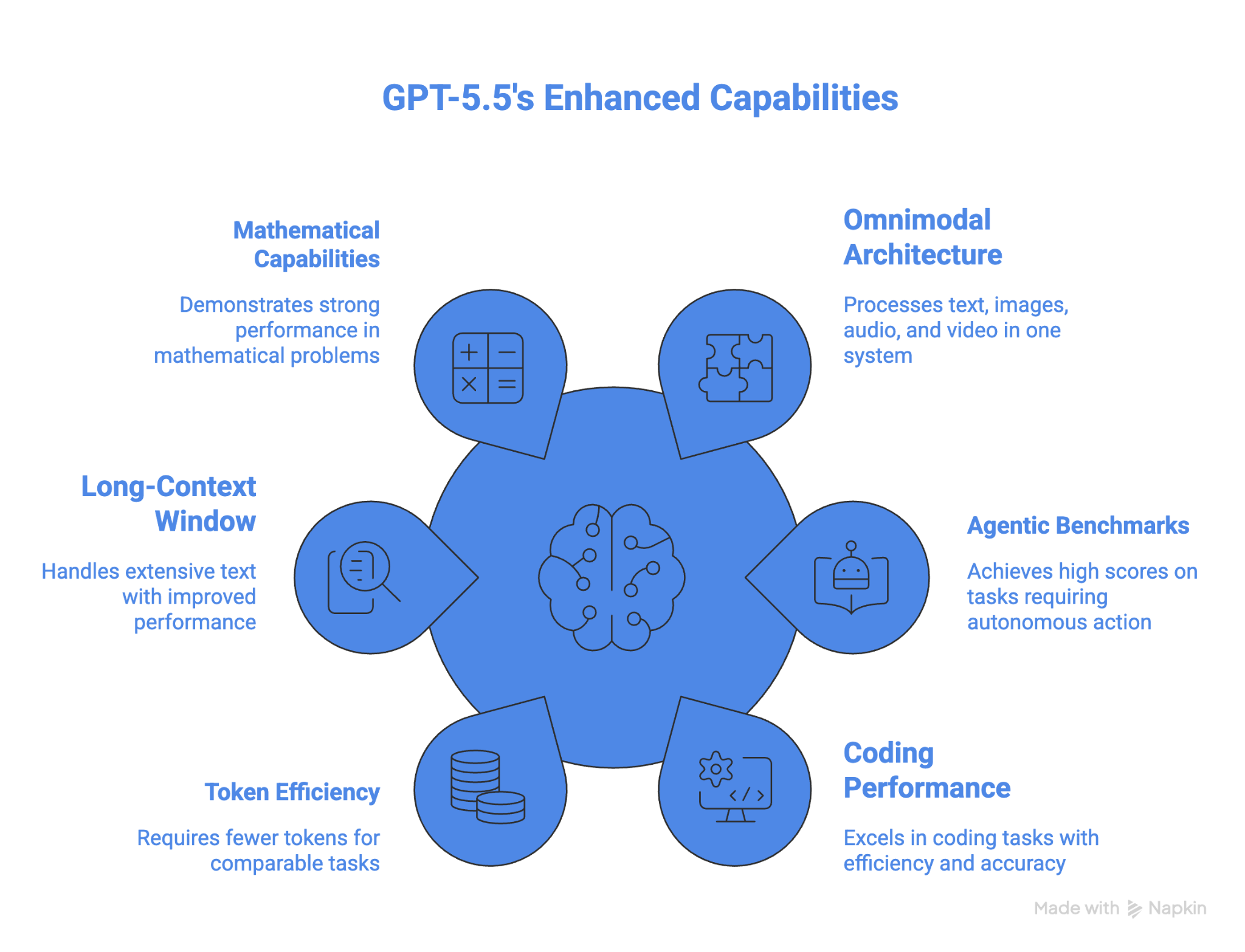
Le prestazioni di GPT-5.5 su OSWorld-Verified lo rendono il miglior modello per l’uso del computer tra quelli che hanno fornito risultati su questo benchmark. Supera anche tutti gli altri modelli in matematica avanzata. L’efficienza dei token è un altro vantaggio per task agentici di lunga durata.
Di contro, GPT-5.5 è più costoso del modello precedente: 5 $ per un milione di token in input e 30 $ per un milione di token in output. L’azienda afferma che potrebbe risultare più economico grazie alla maggiore efficienza dei token, ma dipende dai tuoi workflow se questo si verifica o meno.
Gemini 3.1 Pro è il modello di punta allo stato dell’arte di Google, costruito su un’architettura Mixture-of-Experts (MoE). Google l’ha progettato per offrire solide prestazioni multimodali e di reasoning a un prezzo competitivo.
Per un confronto con l’ultimo modello frontier di Anthropic, leggi il nostro blog su Claude Opus 4.7 vs Gemini 3.1 Pro.
Ecco le funzionalità e capacità chiave di Gemini 3.1 Pro:
Nativamente multimodale con supporto per testo e immagini. Audio, video e PDF.
Sistema di thinking a tre livelli che offre livelli di pensiero low, medium e high.
Finestra di contesto da 1M di token, con massimo 65K token in output e accetta in un singolo prompt 8,4 ore di audio o un’ora intera di video.
77,1% su ARC-AGI-2, a dimostrazione di un forte reasoning visivo astratto che più che raddoppia il 31,1% di Gemini 3 Pro.
33,5% su APEX-Agents, che misura task professionali a lungo orizzonte, quasi il doppio del 18,4% di Gemini 3 Pro.
Nel nostro tutorial Costruire con Gemini 3.1 Pro trattiamo come creare un’app pronta per la produzione con Gemini 3.1 Pro e la Gemini CLI.
Gemini 3.1 Pro brilla nei task di reasoning visivo complesso e ha un vantaggio sulla concorrenza grazie al design nativamente multimodale, che gestisce testo, immagini, video e audio in un unico prompt. Insieme a una finestra di contesto enorme da 1M di token, puoi analizzare interi codebase, PDF lunghi o ore di video in una sola volta. Gemini 3.1 Pro alimenta anche Nano Banana 2 e Veo 3.1 per output di immagini e video.
Di contro, Gemini 3.1 Pro offre 65K token in output, che potrebbero non bastare per task agentici di lunga durata. Questo significa che potrebbe non essere adatto a generazione di documenti lunghi e loop agentici che producono output voluminosi.
Scopri come creare una dashboard finanziaria con Gemini 3 e test del browser guidati dall’IA nel nostro tutorial Google Antigravity.
Secondo l’Artificial Analysis Intelligence Index, GPT 5.5 è attualmente il miglior modello in assoluto e guida anche i loro indici su coding e agentic.
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
Data di rilascio |
23 aprile 2026 |
19 febbraio 2026 |
|
Architettura |
Omnimodale (unificata) |
MoE (Transformer) |
|
Finestra di contesto |
1M token |
1M token |
|
Output massimo |
128K token |
65K token |
|
OSWorld |
78,7% |
|
|
BrowseComp |
84,4% |
85,9% |
|
ARC-AGI-2 |
85,0% |
77,1% |
|
GPQA Diamond |
93,6% |
94,3% |
|
Terminal-Bench 2.0 |
82,7% |
68,5% |
|
FrontierMath Tier 4 |
35,4% (Pro 39,6%) |
16,7% |
|
SWE-Bench Pro |
58,6% |
54,2% |
|
Prezzi API (input/output per 1M) |
$5/$30 (Pro $30/$180) |
$2/$12 |
Diamo un’occhiata ad alcuni casi d’uso.
GPT-5.5 ottiene il 78,7% sul benchmark OSWorld-Verified per l’uso del computer, sebbene non ci sia un punteggio pubblico di Gemini per il confronto. In pratica, l’uso del computer in GPT-5.5 è integrato nell’app Codex, dove può navigare e testare siti web. Google offre funzionalità simili con la sua app Antigravity.
Quando si tratta di task da web-agent, lo scenario si fa più interessante. Gemini 3.1 Pro passa avanti con l’85,9% su BrowseComp contro l’84,4% di GPT-5.5, e va meglio anche su MCP Atlas (un benchmark che testa l’uso di tool su 36 server MCP), con il 78,2% contro il 75,3% di GPT-5.5.
Detto questo, GPT-5.5 si rifà su Toolathon, che sottopone un modello a oltre 600 tool reali, ottenendo il 55,6% rispetto al 48,8% di Gemini. GPT-5.5 prende anche il comando sull’Artificial Analysis Agentic Index, dove Gemini 3.1 Pro è nettamente indietro, come mostra il grafico qui sotto.
Nel coding, GPT-5.5 batte Gemini 3.1 Pro con un punteggio del 58,6% su SWE-Bench Pro e dell’82,7% su Terminal-Bench 2.0, rispetto al 54,2% e 68,5% di Gemini 3.1 Pro. In particolare su Terminal-Bench 2.0, GPT-5.5 conduce con un ampio margine.
GPT-5.5 guida l’Artificial Analysis Coding Index con Gemini 3.1 Pro subito dietro.
Su ARC-AGI-2, che misura la capacità di un modello di apprendere e risolvere problemi senza training precedente, GPT-5.5 batte Gemini 3.1 Pro con una differenza di quasi 8 punti (85,0% vs 77,1%).
GPT-5.5 è in testa anche in matematica avanzata con una differenza di 18 punti rispetto a Gemini 3.1 Pro, come misurato dal benchmark FrontierMath, che testa la capacità di reasoning a livello esperto.
Gemini 3.1 Pro costa 2 $ per 1M di token in input e 12 $ per 1M di token in output. GPT-5.5 parte da una tariffa significativamente più alta, con 5 $ per 1M di token in input e 30 $ per 1M di token in output (e sei volte tanto per il modello Pro). Questo rende GPT 5.5 più del doppio più costoso di Gemini 3.1 Pro.
GPT-5.5 e Gemini 3.1 Pro hanno entrambi una finestra di contesto da 1M. Tuttavia, GPT 5.5 offre 128K token in output, rispetto ai 65K di Gemini.
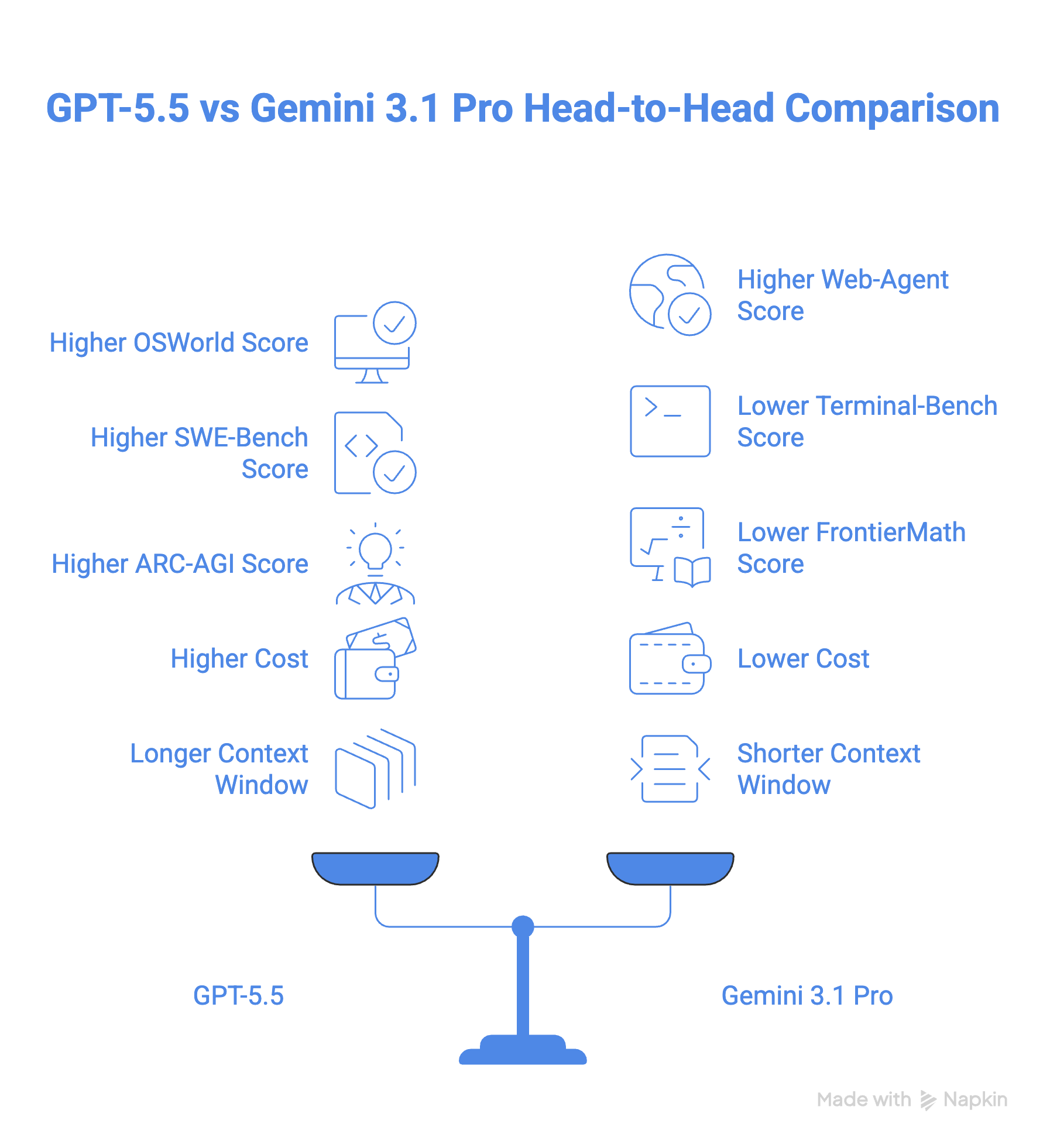
Arriviamo quindi alla domanda: quale dei due modelli scegliere?

GPT-5.5 è il modello più forte sulla carta e, per la maggior parte degli sviluppatori, probabilmente anche in pratica, soprattutto se lavori in ambienti da terminale o usi matematica complessa. La ricostruzione da zero ha pagato: non è un modello “aggiustato” a posteriori, e i distacchi nei benchmark su Terminal-Bench 2.0 e FrontierMath lo dimostrano chiaramente.
Ma “più forte” non significa sempre “migliore per te”. A un prezzo 2,5 volte superiore rispetto a Gemini 3.1 Pro, GPT-5.5 è un impegno reale a livello di budget, e l’argomentazione sull’efficienza dei token regge solo se i tuoi workflow sono abbastanza lunghi da beneficiarne.
Gemini 3.1 Pro non è un comprimario. È un modello competitivo che guida BrowseComp, MCP Atlas e GPQA Diamond, e la gestione nativa di video e audio è ancora avanti rispetto a ciò che GPT-5.5 offre nativamente.
Per la maggior parte dei team, la scelta più intelligente probabilmente non è binaria: usa Gemini 3.1 Pro come cavallo di battaglia per task ad alto volume o ricchi di media e porta in campo GPT-5.5 dove il margine conta davvero. Questo approccio ibrido ti dà il meglio di entrambi senza pagare prezzi da frontier su tutta la linea.
Se vuoi imparare a creare applicazioni basate sull’IA usando LLM, prompt, chain e agent in LangChain, ti consiglio vivamente il nostro corso Developing LLM Applications with LangChain.
Impara l’IA con DataCamp!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

