courses
OpenAI API 활용하기
3
141.6K
OpenAI가 GPT-4.5 이후 처음으로 재학습된 베이스 모델을 공개했습니다. 직관에 반할 수 있지만, GPT-5와 그 후속 모델들은 점진적 업데이트에 가깝습니다.
이번 모델은 다릅니다. 에이전트형 워크플로를 위해 처음부터 구축되었으며, 개발자에게 가장 중요한 두 가지 핵심 벤치마크에서 강력한 성능을 보입니다.
이 글에서는 새롭게 공개된 GPT-5.5와 Gemini 3.1 Pro를 비교해 어떤 모델이 더 적합한지 살펴보겠습니다. 벤치마크, 비용, 활용 사례를 살펴봅니다.
GPT-5.5는 OpenAI의 최신 플래그십 옴니모달 모델로, 코드네임은 “Spud”입니다. 이전 모델의 파인튜닝이 아니라, 최소한의 지시만으로도 자율적이고 다중 작업을 수행하도록 처음부터 다시 만든 모델입니다.
GPT-5.5는 세 가지 버전으로 제공됩니다:
모델에 대한 자세한 내용은 우리의 OpenAI GPT-5.5 기사와 Claude Opus 4.7 vs GPT-5.5 비교 글에서 확인하세요.
GPT-5.5의 핵심 기능과 역량은 다음과 같습니다.
가장 큰 개선 중 하나는 512K~1M 구간의 장문 컨텍스트 작업 성능 향상입니다. GPT 5.4의 36.6%에서 GPT 5.5는 74.0%로 두 배 이상 상승했습니다.
수학에서도 현재 가장 강력한 모델입니다. FrontierMath Tier 4에서 GPT 5.5는 35.4%, GPT 5.5 Pro는 39.6%를 기록했습니다. 참고로 GPT 5.4는 27.1%, Claude Opus 4.7은 22.9%, Gemini 3.1 Pro는 16.7%였습니다.
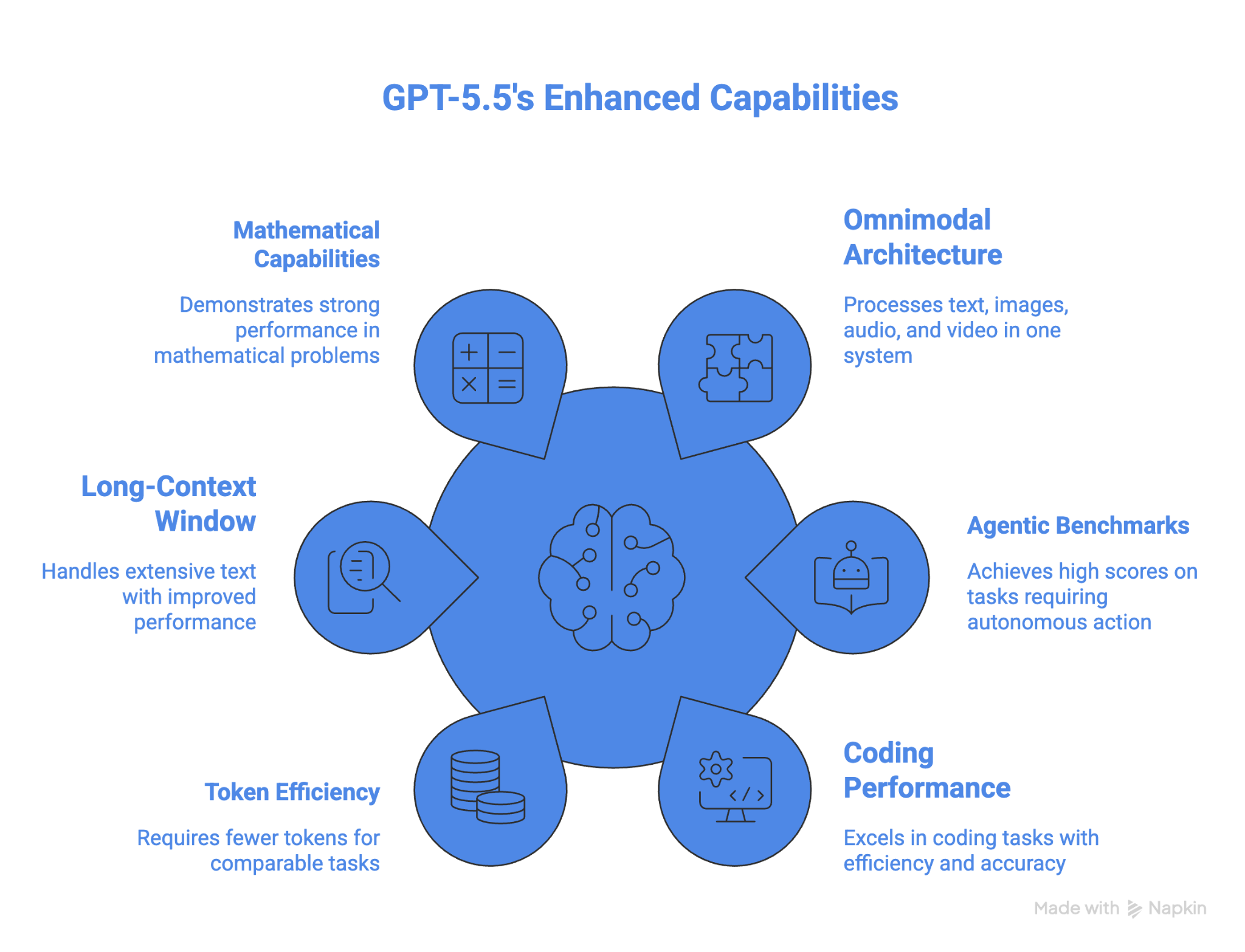
GPT-5.5는 OSWorld-Verified에서의 성능으로, 이 벤치마크 결과를 공개한 모델 중 컴퓨터 사용 측면에서 최고입니다. 고급 수학에서도 모든 모델을 능가합니다. 장시간 에이전트 작업에서 토큰 효율성 역시 장점입니다.
반면 GPT-5.5는 이전 모델보다 비쌉니다. 입력 100만 토큰당 5달러, 출력 100만 토큰당 30달러입니다. 회사 측은 더 토큰 효율적이므로 실질적 비용은 낮을 수 있다고 하지만, 이는 워크플로에 따라 달라집니다.
Gemini 3.1 Pro는 Google의 최신 플래그십 모델로, Mixture-of-Experts(MoE) 아키텍처 위에 구축되었습니다. 강력한 멀티모달 처리와 추론 성능을 경쟁력 있는 가격으로 제공하도록 설계되었습니다.
Anthropic의 최신 프런티어 모델과의 비교는 Claude Opus 4.7 vs Gemini 3.1 Pro 블로그를 참고하세요.
Gemini 3.1 Pro의 핵심 기능과 역량은 다음과 같습니다:
텍스트와 이미지에 대한 네이티브 멀티모달 지원. 오디오, 비디오, PDF도 지원.
low, medium, high의 3단계 사고 레벨 제공.
1M 토큰 컨텍스트 윈도, 최대 65K 출력 토큰, 단일 프롬프트로 최대 8.4시간 분량의 오디오 또는 1시간 분량의 비디오 수용.
ARC-AGI-2에서 77.1%로, Gemini 3 Pro의 31.1%를 두 배 이상 웃도는 강력한 추상 시각 추론.
장기 전문 업무를 측정하는 APEX-Agents에서 33.5%로, Gemini 3 Pro의 18.4% 대비 거의 두 배.
Building with Gemini 3.1 Pro 튜토리얼에서는 Gemini 3.1 Pro와 Gemini CLI로 프로덕션급 앱을 만드는 방법을 다룹니다.
Gemini 3.1 Pro는 복잡한 시각 추론 작업에서 강점을 보이며, 텍스트, 이미지, 비디오, 오디오를 단일 프롬프트로 처리하는 네이티브 멀티모달 설계에서 경쟁사 대비 우위를 점합니다. 여기에 방대한 1M 토큰 컨텍스트 윈도가 결합되어, 한 번에 전체 코드베이스, 긴 PDF, 수 시간 분량의 비디오를 분석할 수 있습니다. 또한 Nano Banana 2와 Veo 3.1을 통해 이미지와 비디오 출력도 지원합니다.
단점으로는 출력 토큰이 65K로, 장시간 에이전트 작업에는 충분하지 않을 수 있습니다. 즉, 장문 문서 생성이나 대규모 출력을 내는 에이전트 루프에는 적합하지 않을 수 있습니다.
우리의 Google Antigravity 튜토리얼에서 Gemini 3로 금융 대시보드를 만들고 AI 구동 브라우저 테스트를 수행하는 방법을 배워보세요.
Artificial Analysis Intelligence Index에 따르면, GPT 5.5는 현재 종합 성능 1위이며 코딩과 에이전트 인덱스에서도 선두를 달립니다.
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
출시일 |
April 23, 2026 |
February 19, 2026 |
|
아키텍처 |
옴니모달(통합) |
MoE(트랜스포머) |
|
컨텍스트 윈도 |
1M 토큰 |
1M 토큰 |
|
최대 출력 |
128K 토큰 |
65K 토큰 |
|
OSWorld |
78.7% |
|
|
BrowseComp |
84.4% |
85.9% |
|
ARC-AGI-2 |
85.0% |
77.1% |
|
GPQA Diamond |
93.6% |
94.3% |
|
Terminal-Bench 2.0 |
82.7% |
68.5% |
|
FrontierMath Tier 4 |
35.4% (Pro 39.6%) |
16.7% |
|
SWE-Bench Pro |
58.6% |
54.2% |
|
API 가격(입력/출력 당 1M) |
$5/$30 (Pro $30/$180) |
$2/$12 |
이제 몇 가지 사용 사례를 살펴보겠습니다.
GPT-5.5는 컴퓨터 사용을 위한 OSWorld-Verified 벤치마크에서 78.7%를 기록했지만, 이에 대한 Gemini의 공개 점수는 없습니다. 실제로 GPT-5.5의 컴퓨터 사용 기능은 Codex 앱에 내장되어 있어 웹사이트를 탐색하고 테스트할 수 있습니다. Google은 Antigravity 앱을 통해 유사한 기능을 제공합니다.
웹 에이전트 작업으로 오면 상황은 더 흥미로워집니다. Gemini 3.1 Pro는 BrowseComp에서 85.9%로 GPT-5.5의 84.4%를 근소하게 앞서며, 36개의 MCP 서버 전반의 도구 사용을 테스트하는 벤치마크인 MCP Atlas에서도 78.2%로 GPT-5.5의 75.3%보다 좋은 성능을 보입니다.
반면, 실제 도구 600여 개를 모델에 던지는 Toolathon에서는 GPT-5.5가 55.6%로 Gemini의 48.8%를 앞섭니다. 또한 아래 차트에서 보이듯, Artificial Analysis Agentic Index에서도 GPT-5.5가 선두를 달리는 반면 Gemini 3.1 Pro는 상대적으로 뒤처집니다.
코딩에서는 GPT-5.5가 SWE-Bench Pro 58.6%, Terminal-Bench 2.0 82.7%로, Gemini 3.1 Pro의 54.2%와 68.5%를 앞섭니다. 특히 Terminal-Bench 2.0에서 GPT-5.5는 큰 격차로 선도합니다.
Artificial Analysis 코딩 인덱스에서는 GPT-5.5가 선두이고, Gemini 3.1 Pro가 그 뒤를 잇습니다.
사전 학습 없이 학습하고 문제를 해결하는 능력을 측정하는 ARC-AGI-2에서 GPT-5.5는 약 8포인트 차이(85.0% vs 77.1%)로 Gemini 3.1 Pro를 앞섭니다.
또한 전문가 수준의 추론 능력을 측정하는 FrontierMath 벤치마크에서도 GPT-5.5가 Gemini 3.1 Pro 대비 18포인트 차이로 앞서 고급 수학에서 우위를 보입니다.
Gemini 3.1 Pro의 비용은 입력 100만 토큰당 2달러, 출력 100만 토큰당 12달러입니다. GPT-5.5는 이보다 훨씬 높은 가격으로, 입력 100만 토큰당 5달러, 출력 100만 토큰당 30달러(프로 모델은 그 6배)를 받습니다. 즉 GPT 5.5는 Gemini 3.1 Pro 대비 두 배 이상 비쌉니다.
GPT-5.5와 Gemini 3.1 Pro는 모두 1M 컨텍스트 윈도를 제공합니다. 다만 GPT 5.5는 128K 출력 토큰을 지원하고, Gemini는 65K를 지원합니다.
이제 두 모델 중 무엇을 선택할지의 문제로 돌아가 봅니다.

문서상 GPT-5.5가 더 강력하며, 대부분의 개발자에게 실제로도 그렇게 느껴질 것입니다. 특히 터미널 환경에서 작업하거나 복잡한 수학을 사용하는 경우 그렇습니다. 처음부터 다시 만든 접근이 효과를 봤습니다. 임시방편으로 손본 모델이 아니며, Terminal-Bench 2.0과 FrontierMath에서의 격차가 이를 분명히 보여줍니다.
하지만 “강력함”이 항상 “당신에게 더 나음”을 뜻하진 않습니다. Gemini 3.1 Pro 대비 2.5배 가격인 GPT-5.5는 예산 측면에서 부담이 크며, 토큰 효율성에 대한 주장은 워크플로가 그 이점을 체감할 만큼 충분히 길 때만 성립합니다.
Gemini 3.1 Pro는 준우승이 아닙니다. BrowseComp, MCP Atlas, GPQA Diamond에서 선도하고, 네이티브 비디오·오디오 처리도 여전히 GPT-5.5의 네이티브 기능보다 앞섭니다.
대부분의 팀에 더 현명한 전략은 이분법적 선택이 아닙니다. 대량 또는 미디어 중심 작업에는 Gemini 3.1 Pro를 일꾼으로 쓰고, 성능 격차가 실제로 중요한 지점에 GPT-5.5를 투입하세요. 이렇게 혼합하면 전 영역에서 프런티어 가격을 지불하지 않고도 두 모델의 장점을 모두 취할 수 있습니다.
LLM, 프롬프트, 체인, 에이전트를 LangChain에서 활용해 AI 애플리케이션을 만드는 방법을 배우고 싶다면, 우리의 Developing LLM Applications with LangChain 과정을 강력히 추천합니다.
DataCamp로 AI를 배워보세요!
courses
courses
courses